基于改進Dijkstra算法的配用電通信網流量調度策略
2018-08-28 08:52:48向敏,陳誠
計算機應用 2018年6期
向 敏,陳 誠
(重慶郵電大學自動化學院,重慶400065)(*通信作者電子郵箱804652105@qq.com)
0 引言
隨著智能電網的發展,允許用戶積極參與到用電管理和故障報告中,以提高電網的自愈能力、即插即用能力和互操作性[1]。配用電通信網包含多層體系結構,為了確保電網的安全可靠運行,建立一個高效、可靠、安全的實時電力數據采集雙向通信系統將成為支撐智能電網快速發展的關鍵技術之一[2-3]。
有線和無線相結合是現有電力數據采集使用最廣泛的通信方式,由于現有業務量的大量增加,已無法滿足配用電通信網的發展要求[4]。無線通信技術的發展使配用電通信網具備了靈活、易接入、低成本等優勢,已逐漸成為配用電網通信基礎設施的首選。為了實現配用電通信網對用戶區域無縫覆蓋,無線多跳通信具有網絡自組織、自愈性以及可靠性等性能,相較于單跳長距離傳輸更能滿足智能電網通信需求[5-6]。
基于無線mesh網絡的智能電網數據采集網絡,安裝集成無線通信模塊且具有路由和一定緩存功能的中繼節點,可以視為一個mesh節點[7]。對于居民區按照一定數據采集規模分為多個子網區域,每個子網區域存在一個子網網關,最后所有數據匯聚到主網關并與遠程數據管理中心通信。該網絡架構下不僅要考慮物理層、多路訪問控制(Multi-Access Protocol,MAC)協議等滿足智能電網通信網絡需求,還應考慮應用層時變的數據流量對網絡性能的影響[4]。例如,電力故障情況下,大量故障信息的產生和傳輸導致網絡數據流量負載迅速增大,這樣就可能造成某些中繼節點數據量增大,極有可能產生擁塞,導致網絡吞吐量下降,影響數據通信的實時性和可靠性。
由于智能電網的數據均與電網業務相關,是電網決策和數據分析的基礎,因而智能電網通信網需要具有良好的實時性、準確性和可靠性。文獻[7]對多網關聯合網絡進行了分析,以節點隊列長度為主要指標,采用隊列加權的方法提出了流量調度算法。文獻[8]提出了一種多網關mesh結構,將多個局域mesh子網聯合成為一個有主網關進行管理的多網關網絡,任意智能電表既是數據源節點也是中繼節點,且所有電表可以向任一子網關傳輸數據。文獻[9]提出了用于智能電網認知無線電通信基礎設施基于優先級的流量調度方法,考慮了智能電網業務流量的異構性,將數據流量分為了三個優先類別。文獻[10]分析了傳統背壓算法在數據流量負載較大的情況下不能有效減少端到端時延的缺點,提出與最短路徑相結合的背壓算法,通過最小化源節點和目的節點的間路徑長度以減少時延。文獻[11]綜合考慮跳數和mesh節點隊列長度,提出了多網關單級背壓調度算法。文獻[12]提出了隨機切換流量調度算法,以緩解緊急狀況數據流量增大時某些處于關鍵位置智能電表的數據擁塞。文獻[13]提出了一種貪婪背壓路由算法,通過節點到達最近網關的跳數和流量負載計算獲得貪婪背壓度量值,根據最陡梯度方向路由數據包。文獻[14]提出一種確定性路由和機會性路由相結合的路由協議,各節點從其鄰居節點中選擇出候選節點集傳輸數據,以避免瓶頸節點的產生。
隨著智能電網業務的不斷增加,配用電通信網數據采集網絡將面臨極大的數據流量壓力,為緩解智能電網數據流量突增造成擁塞并均衡網絡流量分布,本文提出一種基于改進Dijkstra的路由算法——DDTA(Data-balance and improved Dijkstra Traffic-scheduling Algorithm),以跳數、流量負載率和鏈路利用率作為路徑選擇的綜合指標,優化配用電通信網絡中的下一跳節點選擇。構建業務調度模型,對重度擁塞節點進行業務調度,以保證高優先級業務的服務質量。
1 配用電通信網絡流量調度模型
考慮到對用戶區域的無縫覆蓋,基于無線多跳網絡的配用電數據采集網絡能夠有效提高用戶電力數據采集和傳輸的實時性、完整性和可靠性。每個鄰域網(Neighborhood Area Network,NAN)由多個mesh子網組成,每個mesh節點表示每個子網中可以接入本地網關的數據采集點。數據聚合點即為通過有線或無線鏈路與主網關進行通信的子網關。為了簡化配用電通信網絡的網絡拓撲圖以及便于節點管理,依據源節點到達目的節點的最少跳數對節點進行分層。由于越靠近網關的節點其負載越重,根據節點當前狀態劃分節點擁塞程度,對于重度擁塞節點進行業務調度盡可能避免高優先級業務的丟失。
1.1 配用電數據采集網絡節點分層模型
采用有向圖模型G(N,L)來表示整個配用電通信網的網絡拓撲,N表示網絡中所有節點集,L則表示網絡中節點間鏈路集合。lij表示從節點i到節點j的有向邊,由于網絡中的鏈路均可雙向傳輸數據,則lij∈L,lji∈L。eij表示節點i到節點j的有向鏈路邊權值。設定最大跳數閾值為H,則可將所有數據采集節點分為H層,以到達網關的最少跳數對mesh子網中的數據采集節點進行分層。
以圖1中mesh網絡為例,將配用電數據采集網絡中與主網關直接通信的子網關0作為第0層節點;只需單跳便可把數據傳輸到網關的節點1、2、3和4作為第1層節點;到達網關最少跳數為2的節點5、6和7作為第2層節點;到達網關最少跳數為3的節點8作為第3層節點。

圖1 數據采集網絡節點分層結構Fig.1 Node hierarchical structure for data acquisition network
1.2 配用電通信網業務調度模型
配用電通信業務的QoS需求主要包含時延、丟包率和數據速率等指標。參照《電力系統通信設計技術規定》將智能電網通信業務分為3類,分別用P1、P2、和P3標識業務等級;P1表示智能電網用于控制、保護和管理的緊急型業務,如縱聯網絡保護;P2表示智能電網中對實時性要求較高的關鍵型業務,如高級量測體系(Advanced Metering Infrastructure,AMI);P3表示智能電網中允許一定時延的常規型業務,如用電信息采集。等級標識越低業務優先級越高。三類配用電業務特性如表1所示。

表1 三類配用電業務特性Tab.1 Characteristics of three types of power distribution and utilization service
本文通過預先設置數據包IP報文中差分服務代碼點(Differentiated Service Code Point,DSCP)值以辨識所劃分的業務類型以及優先級,IP包頭中區分服務字段中的TOS字段中DSCP值設置如表2所示,DSCP值的前四位表示配用電業務的優先等級,后四位用以表示配電點業務類別。

表2 DSCP值的二進制編碼Tab.2 Binary encoding for DSCP
設節點i中的緩存隊列長度為Qi,節點i數據到達率為vi,節點i數據生成數據為v0i,數據轉發率為ui,一個數據處理周期為T,節點緩沖區擁塞閾值為QT;則當前時刻節點中緩存隊列長度為:

依據節點數據處理能力和緩存隊列長度將節點擁塞度劃分為3個等級,節點擁塞度等級劃分規則如下:
1)若ui≥(vi+),隨時間增加節點緩存隊列中數據包數量會逐漸減少,節點i不易發生擁塞,其擁塞等級為Ⅲ。
2)若ui<(vi+)且Qi(t)<QT,隨時間增加節點緩存隊列中數據量可能增大至擁塞閾值,節點i可能發生擁塞,其擁塞等級為Ⅱ。
3)若ui<(vi+)且Qi(t)≥QT,隨時間增加節點緩存隊列中數據量可能溢出緩存區,節點i極易產生擁塞,其擁塞等級為Ⅰ。
節點擁塞等級標識越低則節點發生擁塞的可能性越大。
若節點為擁塞等級為Ⅰ或Ⅱ時,則對該節點緩存區中的數據包按照業務優先級進行調度,盡可能減少緊急型業務的丟包率。假設t時刻擁塞節點i緩存隊列中有6個(S1,S2,…,S6)不同優先級的數據包,按照如圖2所示的方法對該節點中的數據進行調度。

圖2 擁塞節點緩存隊列調度過程Fig.2 Scheduling process for cache queue of congestion nodes
對易產生擁塞節點中的數據緩存隊列按照業務優先級進行調度之后,從隊尾丟棄優先級較低的業務,并發送消息通知被丟棄業務的源節點重新進行路由選擇。同時對擁塞節點的上一跳節點重新進行路由選擇,以避免數據的繼續丟失。由于重新路由選擇要避開負載較重的節點并選擇出最優路徑,本文利用鏈路跳數、流量負載率和鏈路利用率求取復合邊權值,利用改進的Dijkstra算法獲得最優路徑。
2 基于復合邊權值的流量調度算法
在智能電網通信網絡中業務流量從終端采集設備逐漸集中至網關,越靠近網關的節點其業務量越大越容易造成數據丟失,為避免擁塞節點的產生并提升網絡性能,對于分層網絡拓撲圖邊值計算引入三個度量值:跳數指標、流量負載率指標和鏈路利用率指標,綜合考慮下一跳路徑的選擇。
2.1 跳數
網絡中的節點定期與其周圍的鄰居節點交換信息,設節點i到達距其最近的網關的最少跳數為。為了簡化智能電網數據采集網絡模型,規定任意節點i的鄰居節點列表中只包含上層和同層鄰居節點,即節點i只能從(-1)層和Hi層的鄰居節點中選擇下一跳節點;且第一層節點只能選min擇網關作為下一跳節點。本文還利用跳數來間接表示節點間的距離。在此將節點i和節點j到達距其最近目的網關的最少跳數之差作為跳數指標,如式(2)所示:

2.2 流量負載率
根據文獻[15]利用梯度模擬節點緩存隊列,節點按照最陡梯度感知節點中的數據流量分布,從而在數據傳輸過程中規避擁塞節點。本文定義節點i到節點j的有向鏈路lij的流量度量為 (lij),令Qij表示節點i到節點j的隊列長度,Mi為節點i的鄰居節點數,且M=max(Mi)。節點i到節點j鏈路lij的流量負載度量如式(3)所示:
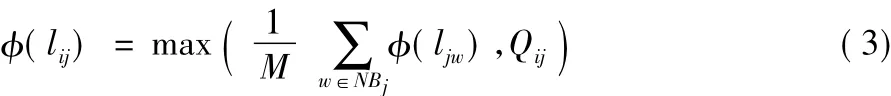
式中:NB(j)為節點j的鄰居節點集合;w為j的鄰居節點即w∈NB(j)。節點i的流量負載度量如式(4)所示:

式中:max和min分別表示節點i的輸出鏈路中流量度量值的最大值和最小值。節點i向j傳輸數據的歸一化流量負載率如(5)所示:

式中:Cij表示鏈路代價度量值。TM越大則表示節點i與其鄰居節點鏈路lij之間流量負載值差異越大,節點i向節點j傳輸數據的趨勢越明顯。
2.3 鏈路利用率
文獻[16]定義鏈路的使用率為鏈路上業務流總速率和鏈路的有效傳輸速率的比值。本文采用鏈路上業務流總速率與網絡傳輸速率的比值作為鏈路度量值。GW為網關集合,P為各業務流到達網關的路徑集合,F為業務流集合,業務流f在路徑p上的速率為,則業務流f的總速率為x(lij,p)=1 表示鏈路 lij在路徑 p上,否則 x(lij,p)=0。經過鏈路lij的業務流總速率為路lij的鏈路度量值,即為鏈路利用率,如式(6)所示:
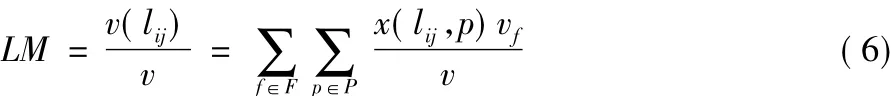
式中v即為網絡數據傳輸速率。
2.4 復合邊權值
有向圖模型G(N,L)中的邊權值綜合考慮了跳數、流量負載率和鏈路利用率,定義網絡拓撲圖中節點i到節點j的有向邊權值為eij,如式(7)所示。

式中α、β和γ分別為跳數、流量負載率和鏈路利用率指標的加權系數,取值范圍為[0,1],且 α + β + γ =1。加權系數 α、β和γ可以依據文獻[18]中的多業務權值分配方法,依據配用電緊急型、關鍵型和常規型三類業務需求偏好求取權值。
3 算法描述
本文結合最少跳數構建節點分層網絡拓撲結構與Dijkstra算法[17],利用跳數、流量負載率和鏈路利用率綜合求取越大越優有向邊權值,求取所有邊權值最大的鏈路相鄰的節點即為下一跳優先節點。最壞情況下需要遍歷網絡中所有節點以選取最優路徑,此時算法的時間復雜度為O(n2)。算法具體步驟如下:
步驟1 網關收集更新網絡中所有節點的信息,并依據源節點到達距網關的最少跳數構建最短路徑節點分層模型,刪除信號強度小于閾值的鄰居節點。
步驟2 初始時刻t,各節點交換狀態信息,維護各節點的鄰居節點信息表。對于Ⅰ級擁塞節點斷開該節點的所有輸入鏈路,并在(t-T)時刻向該節點傳輸數據的所有鄰居節點列表中刪除該擁塞節點;對于Ⅱ級擁塞節點則斷開同層節點的輸入鏈路,并在(t-T)時刻向該節點傳輸數據的同層鄰居節點列表中刪除該中度擁塞節點。T為一個數據處理周期。
步驟3 依據本節點信息和獲取的鄰居節點信息計算有向邊復合權值,并構建鏈路邊權值矩陣Eij,其中的元素eij表示節點i指向節點j鏈路邊權值,若節點i與j沒有直接相鄰,則eij=0。
步驟4 使用Dijkstra算法求取從源節點到達目的網關邊權值之和最大的路徑。
步驟5 網絡因突發狀況產生鏈路中斷時,則在數據源節點與鄰居節點重新交換信息并更新鄰居節點列表,重新調用Dijkstra算法求取新的路徑。
4 仿真結論與分析
采用Matlab對本文算法DDTA進行仿真測試,為驗證算法優越性,在相同條件下與最短路徑(Shortest Path Fast,SPF)算法、貪婪背壓算法(Greedy Backpressure Routing Algorithm,GBRA)的丟包率、端到端平均時延和網絡吞吐量進行對比。
本章采用1個局域網關及36個隨機分布的數據采集節點構建多網關多跳數據采集網絡。仿真過程中,所有節點數據生成速率相同,假設網關不限帶寬。其中α、β和γ的取值參照文獻[18]的權值求取方法,并經過多次仿真獲取最優取值,該系數可以依據業務需求和網絡狀態進行相應調整。依據配用電通信網實際運行過程中配用電業務的數量設置緊急型、關鍵型和常規型業務生成比率。網絡仿真環境的相關參數設置如表3所示。

表3 網絡仿真環境參數Tab.3 Network simulation environment parameters
4.1 平均端到端時延
端到端的時延主要分為傳輸時延和等待時延,傳輸主要與跳數相關,而等待時延即為業務流在傳輸路徑中排隊等待時間。假設節點的數據流f到達網關所經過的跳數為h,單跳傳輸時延為th,節點發送一個數據包的時延tp,則業務流的端到端時延如下:

對仿真區域內的所有節點進行時延性能仿真,仿真結果如圖3所示,圖3中本文算法端到端時延為三類業務從源節點到達目的節點的平均時延。當節點數據生成速率較小時,本文算法DDTA與GBRA平均端到端時延相當;隨著節點數據生成速率增大,節點緩存隊列長度增加使得平均端到端時延增大。本文所提算法路由選擇綜合考慮了跳數和節點數據流量負載,在一定程度上規避了向擁塞節點傳輸數據,從而減少了傳輸時延和等待時延。隨節點數據生成速率增大,本文所提算法平均端到端時延小于GBRA和SPF,提高了配用電通信網絡業務傳輸的可靠性。

圖3 不同算法平均端到端時延對比Fig.3 Comparison of average end-to-end delay of different algorithms
本文算法仿真環境下,緊急型業務、關鍵型業務和常規型業務的平均端到端時延對比如圖4所示。由圖4中可以看出,由于所提算法在擁塞節點處優先傳輸緊急型和關鍵型業務,從而減少了這兩類業務數據包的排隊時延,因而傳輸緊急型和關鍵型業務的平均端到端時延小于常規型業務。隨著節點數據生成速率增大,易擁塞節點優先保障緊急型業務的傳輸,其次才是關鍵型,因而緊急型業務的端到端時延低于關鍵型。本文的流量調度策略通過對易擁塞節點進行業務調度,保證了配用電通信網中重要業務的時延特性。
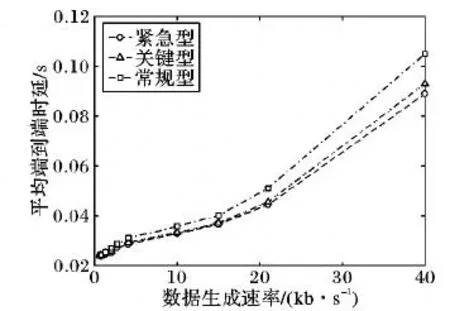
圖4 不同業務平均端到端時延對比Fig.4 Comparison of average end-to-end delay of different services
4.2 丟包率
緊急型、關鍵型和常規型三類配用電業務在本文算法DDTA、最短路徑(SPF)算法和貪婪背壓算法(GBRA)下丟包率仿真結果如圖5所示。
數據生成速率對緊急型業務數據包丟失率的影響,仿真結果如圖5(a)所示。從圖5(a)可知,本文所提算法的緊急型業務數據包丟失率低于SPF和GBRA。具體而言,在數據生成率為80 kb/s時,本文所提算法的緊急型業務丟包率相比SPF和GBRA分別減少了81.3%和67.7%。由于本文研究對擁塞節點進行了業務調度以保證緊急型業務優先傳輸,因而隨數據生成速率的提高本文所提算法中緊急型業務丟包率較小且增長較緩慢。
圖5(b)為三種算法關鍵型業務丟包率仿真結果。從圖5(b)中可知,本文所提算法的關鍵型業務丟包率低于SPF和GBRA。當節點數據生成速率為80 kb/s時,本文算法較SPF和GBRA關鍵型業務丟包率分別減少了79%和63.8%。本文算法在易擁塞節點處優先保證緊急型業務的傳輸,次之保證關鍵型業務的傳輸,因而隨著節點數據生成速率逐漸提高本文所提算法中關鍵型業務丟包率增長較其他兩種算法慢。
圖5(c)為三種算法常規型業務丟包率仿真結果。從圖5(c)中可以看出,本文算法常規型業務丟包率和GBRA相當,低于SPF,這是因為本文所提算法常規型業務優先級最低,在易擁塞節點處以犧牲常規業務而減少緊急型和關鍵型業務丟包可能性。
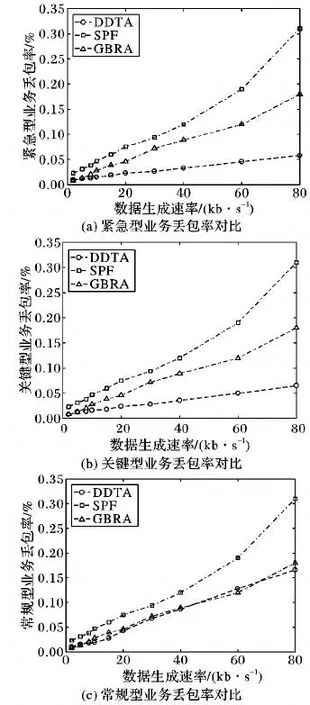
圖5 不同業務丟包率對比Fig.5 Comparison of packet loss rate of different services
4.3 網絡吞吐量
網絡的有效吞吐量為單位時間內目的網關接收的數據量與網絡中所有節點數據生成量的比值。圖6分析了網絡中目的網關有效吞吐量和節點數據生成速率的關系。隨著數據生成速率的增大網絡逐漸趨于飽和,更多的數據滯留在節點緩存隊列中或者丟失,使得網絡的有效吞吐量隨著數據生成速率增大而逐漸降低。由于本文所提算法綜合考慮了鏈路負載和鏈路利用率,因而均衡了配用電通信網絡的流量分布,并提高了網絡利用率。

圖6 不同算法有效吞吐量對比Fig.6 Comparison of effective throughput of different algorithms
5 結語
針對智能電網通信網絡數據采集匯聚過程中,因網絡中業務流量分布不均勻造成某些關鍵節點易產生擁塞的問題,本文提出了一種基于復合邊權值的負載均衡的Dijkstra路由算法。依據節點當前狀態劃分節點擁塞等級,對于中度擁塞節點進行業務調度以保證緊急業務優先傳輸。綜合考慮鏈路跳數、流量負載率和鏈路利用率求取復合邊權值,利用改進的Dijkstra算法求取最優路徑。仿真結果表明本文所提算法在節點數據速率增大的情況下能有效降低網絡端到端平均時延和丟包率,提高網絡吞吐量,改善了電力通信網數據采集網絡的通信性能。本文仿真是在簡化的理想模型中進行仿真,下一步將結合實際的配用電通信網數據進行仿真,測試并完善算法。
