面向航天器綜合測試系統的Web緩存替換策略
2018-09-04 01:59:18杜建海呂江花高世偉李倩倩李勤勇馬世龍
北京航空航天大學學報 2018年8期
杜建海, 呂江花,*, 高世偉, 李倩倩, 李勤勇, 馬世龍
(1. 北京航空航天大學 計算機學院, 北京 100083; 2. 北京航天控制儀器研究所, 北京 100039)
隨著信息技術的發展,設備的自動化測試也越來越完善和便捷,但隨之而來的是測試數據的爆炸式增長。特別是在復雜的安全苛刻系統的綜合測試過程中,如在航天器綜合測試過程中,產生的測試數據更是復雜和龐大。由于其數據類型的多樣性和數據的多維特征,這些測試數據需存放在多個數據表中。對于每個型號,每年的綜合測試數據總量可達到T數量級,每個數據表中有上千萬條數據。而要很好地管理和維護這些龐大復雜的測試數據,就給科研人員帶來了許多挑戰。對測試數據的查詢是一種最頻繁的應用,也是最影響系統性能和管理人員體驗的主要要素。為了改善系統性能和用戶體驗,需要對數據查詢系統的性能進行改進。
傳統的B/S數據查詢系統采用每次查詢都去數據庫服務器中獲取數據的方式。一方面,每次查詢都要在整個數據庫中進行檢索,查詢范圍很大,造成了較大的延遲,且每次查詢去數據庫服務器獲取數據的方式勢必需要在數據庫服務器和應用服務器間反復傳輸大量相同的數據,從而造成了不必要的網絡負擔。另一方面,對于正在測試中的型號,數據庫服務器還需進行動態的海量測試數據錄入工作,而每次查詢都檢索數據庫的方式對數據庫服務器的訪問過于頻繁,嚴重影響系統的性能。為了保證服務器的穩定性和數據錄入的完整性,降低數據查詢對服務器的資源占用是很重要的。
采用Web緩存解決上述問題是一個行之有效的方法,Web緩存在改善Web性能方面有很重要的作用。通過將可能再次被訪問的對象放在距離用戶更近的地方的方式,Web緩存可以很好地提高 Web 性能,如減小響應時間、減小網絡帶寬的使用以及減輕原始服務器的工作負載等[1]。同時,適合特定應用環境的高效緩存替換算法對系統的性能和用戶的體驗也將產生極大的影響。緩存替換算法主要以最小化損耗(如總體損耗、平均延時、失誤率和字節失誤率)為標準[2],根據文獻[3-4]所述,緩存替換算法中設計價值函數的主要影響因素包括:①訪問頻率:對象被引用的總次數;②最近訪問時間:對象被引用的最后一次時間;③花費:從原始服務器獲取對象所需的資源花費;④大小:對象的大小;⑤過期時間:對象過期的時間;⑥修改時間:對象最近被修改的時間。
在緩存替換算法中,可以綜合考慮以上影響因素。根據分析,緩存替換算法主要有5種類型[3]:①基于LRU(Least Recently Used)的算法[5]。這類算法包括LRU、LRU-Threshold、Pitkow/Reckers strategy、SIZE[6]、LRU-Min、EXP1、Value-Aging、HLRU、PSS(Pyramidal Selection Schema)[4]、LRU-LSC、Partitioned LRU等。這類算法的優點是較易實現,且時間復雜度低。但簡單的LRU變體沒有很好地考慮對象大小的影響,也沒有考慮訪問頻率的影響。②基于LFU(Least Frequently Used)的算法。這類算法包括LFU、DS-LFU[7]、LFU-Aging、LFU-DA(LFU with Dynamic Aging)[8]、σ-Aging、swLFU等。這類算法需要一個較為復雜的緩存管理,同時還存在緩存污染的問題。可能同時會有多個對象有相同的頻率計數值,在這種情況下,就得需要另外的因素來確定移除哪個對象。③綜合考慮了最近訪問時間和訪問頻率兩者的影響,有些算法可能還會加入其他因素。這類算法包括[3]LRFU、SLRU、SF-LRU、Generational Replacement、LRU*、LRU-Hot、LRU-SP、CSS(Cubic Selection Scheme)、HYPER-G等。如果設計合理,這類算法就可以避免上述基于訪問頻率的算法和基于最近訪問時間的算法的缺點。但因為特殊的處理過程,大部分這類算法會引入額外的復雜度。只有LRU*和Generational Replacement算法試圖盡量簡單地將頻率和LRU結合起來,但是它們沒考慮對象大小的影響。④基于函數的緩存替換算法,這類算法可以通過選擇合適的加權參數,來優化其性能。這類算法包括GD(Greedy Dual)-Size、GDSF[9]、GD*、Ser-ver-assisted cache replacement、TSP(Taylor Series Prediction)、Bolot/Hoschka’s strategy、MIX、M-Me-tric、HYBRID、LNC-R-W3、LRV、LUV、LR(Logistic Regression)-Model等。它們可以考慮多個影響因素來處理不同的工作負載情況。但這類算法的缺點是如何選擇合適的加權參數,這是一個十分困難的任務。在對函數值的計算中可能會引入新的問題。⑤使用隨機決策來尋找被替換的對象[3]。這類算法包括RAND、HARMONIC、LRU-C[10]、LRU-S、Randomized replacement with general value functions等。這類算法的優點是易于實現,在進行插入和刪除對象時,不需要特殊的數據結構。不足之處在于難于進行評估,如運行在同一個Web請求跟蹤上的不同仿真實例的結果,可能僅存在些細微的差異。
除了上面給出的傳統緩存替換算法之外,近年來,有些研究者提出了一些“智能的”或者“有適應性的”緩存替換算法。例如,文獻[11]提出了一種基于多Markov鏈預測模型的Web緩存替換算法PGDSF-AI,首先將Web中具有不同瀏覽特征的用戶分為多類,為每一類用戶建立類Markov鏈,進一步建立多Markov鏈預測模型,然后利用該模型對當前的用戶請求預測,進而組成預測對象集,當緩存空間不足時,選取鍵值最小且不在預測對象集中的對象替換。文獻[12]通過語義的方式來增加命中率,利用語義分段、探查查詢、剩余查詢等來描述語義緩存,構建了分段感知訪問的動態語義緩存模型。文獻[13]首先通過Web日志挖掘得到預測模型,來獲取每個Web對象將來可能被訪問的頻率,然后將此頻率加入到經典Web緩存替換算法GDSF中。同樣,文獻[14]也通過Web挖掘的方式來改進Web緩存。文獻[15]給出了3個基于機器學習的智能Web代理緩存替換算法:SVM-LRU、C4.5-GDS、SVM-GDSF。在常規的緩存替換算法中加入智能方式,用機器學習的智能來預測和判斷此Web對象是屬于不會被訪問的對象類還是將要被再次訪問的對象類。
上述幾種算法的共同缺點是:計算復雜度和時間復雜度較高,同時占用系統資源也多,且都需要預先進行大數據量的訓練,才能獲取一定的智能性或者適應性,綜合考慮其系統的整體性價比不高[16];并且主要是針對是萬維網中的普通用戶訪問Web網頁、多媒體等的情況下。上述算法都有自己的優勢以及不足,存在所謂的“足夠好”的緩存替換算法[3,17](在基本性能指標上可以取得比較好的結果),但是無法給出一種在任何應用環境中都能表現出較好性能的算法[18],甚至無法給出最好的一些算法[3]。這是因為網絡環境是不確定的、動態的,不同應用的不同 Web 訪問特性,以及工作負載變化不盡相同,且不同緩存系統需要考慮的設計因素及設計目標不盡相同。因此,在設計和選擇緩存替換算法時,需針對具體應用的工作負載變化特點。沒有哪一種緩存替換策略是能夠在任何網絡情況下都能很好地適應的,所以如何使得置換策略能夠依據不同的訪問特性和網絡情況采取最適合的緩存替換算法,成為了緩存替換領域研究的熱點[17]。
航天器綜合測試數據的特征具有:數據量大,數據與時間相關,時間密集,數據結構復雜。用戶對數據查詢的特征包括:所查詢的數據具有很強的時間局域性,即通常主要查詢某段時間內的數據;所查詢的數據具有空間局域性,即所訪問的數據往往只是數據庫中數據很小的一部分數據[19]。而現有的Web緩存替換算法不能很好地適用于如航天器這類安全苛刻系統的綜合測試數據查詢系統。對于這類系統,需要設計和改進一種新的Web緩存替換算法來提高算法的緩存命中率,從而提高數據庫服務器的資源利用率,減輕網絡負載,提升系統的整體性能,改善用戶體驗,提高用戶工作效率。
本文通過對如航天器這類安全苛刻系統綜合測試數據特點和用戶查詢特征的分析,綜合考慮實際應用需求特點,在對現有經典Web緩沖替換算法GDSF研究的基礎上,結合 Web 數據流挖掘的相關技術和滑動時間窗口的思想,基于 GDSF算法,設計面向安全苛刻系統測試數據查詢的緩存替換算法GDSF-STW,并對其進行充分的實驗分析,證明了該算法具有更好的性能,占用較少的系統資源,高效且運行穩定,具有一定的通用性。
1 問題提出
1.1 航天器綜合測試數據特點及其查詢特征
航天器綜合測試數據庫系統中保存著多種類型的測試數據,這些數據被存儲在多種類型的數據庫表中。典型的航天器綜合測試數據表結構示例如表1所示。綜合測試數據以時間為主鍵,存儲了該時間點上各參數的值[20-21]。航天器綜合測試數據具有以下4個特點:
1) 數據量大。每小時產生大約20 GB的數據,一天數據量大約可達500 GB。對于單個航天器型號,一年的數據總量通常能達到T數量級。
2) 數據結構復雜。航天器綜合測試數據的數據類型繁多,所屬分系統繁多且每個分系統又有多種參數,其數據結構十分復雜。這些復雜的數據被存儲于多個數據庫表中。

表1 航天器綜合測試數據表結構示例
3) 數據與時間相關。在數據庫中,業務數據以時間為主鍵;在邏輯上,數據具有時間相關性,即對數據進行查詢分析時以時間為檢索條件,強調一段時間內每個時間點上的數據情況以及整個時間段內數據的變化趨勢。
4) 時間密集。每秒一條甚至多條數據,其導致即使查詢較短時間區間時,仍有較大的查詢結果集,如查詢1 h的數據則至少有3 600條。
從宏觀上來看,用戶對航天器綜合測試數據的查詢具有一定的特征,主要包括在以下4個方面:
1) 所查詢的數據具有很強的時間局域性。對于階段總結時查詢的情況,每天所查詢的數據一般局限于之前的測試階段(7~10 d),通常會按照一定的時間順序對數據進行總結分析;對于邊測試邊查詢的情況,其所查尋的數據一般局限于當天產生的數據,且查詢的數據區間會隨著時間順序的推移而推移。
2) 多次訪問。為了確保測試的準確性和測試的完備性,每個數據都會被多次訪問。
3) 所查詢的數據具有空間局域性。從存儲空間角度來看,雖然數據庫服務器存放當前型號到目前為止所有的綜合測試數據,而用戶所查詢的數據局限在較短的測試時間內,因此所訪問的數據是數據庫中存儲空間里很小的一部分,即具有空間局域性。
4) 存在一些高頻訪問對象。某些對象可能在一段時間內被訪問的頻率要遠遠大于其他對象被訪問的頻率,如對于有問題的地方,會被多人反復檢查。
1.2 航天器綜合測試數據查詢問題分析
在B/S架構的Web應用查詢系統中,數據查詢是“激勵”式的,即一次前端操作一次響應。由于航天系統的保密性要求,其數據是不允許備份在前端的普通PC機上的,同時由于結果數據集較大,也使得瀏覽器緩存結果的方式不可行。因此對于每次查詢操作,必須從后臺返回查詢結果。結合前面對航天器綜合測試數據的特征及用戶查詢特征的分析,為解決多次連接數據庫重復傳輸相同數據的問題,從而減小網絡流量,減輕數據庫服務器的訪問負載,并保證較好的用戶查詢響應時間,應該采用Web服務器緩存數據的方式。對于動態生成結果的應用環境,目前的文獻中給出的常用方法并不完全適用于面向實時環境的航天器綜合測試數據查詢。本文采用的方法是:將用戶在一個工作日內所訪問的所有數據作為一個整體,將一個工作日內訪問的數據的時間區間記為timeInterval=[begin,end],并將每個原始數據庫表中處于區間timeInterval內的數據按整點在邏輯上劃分成不同的小數據表,以這些小數據表為單位從數據庫服務器獲取數據,并將這些小數據表作為一個對象緩存于Web應用服務器上。因此,核心問題是以這些小數據庫表作為Web對象,設計優秀的緩存替換算法,提高系統性能。
根據緩存在Web中所處位置的不同,Web緩存可分為原始服務器緩存、Web代理緩存和瀏覽器緩存[22],如圖1所示。其中,原始服務器緩存是服務器本身的緩存,Web代理緩存位于Web代理服務器上,瀏覽器緩存在用戶端。Web代理服務器位于原始服務器和用戶機之間,接收用戶的請求并向用戶返回請求結果,Web代理緩存被廣泛應用于Web代理服務器上,其性能的好壞直接影響到Web訪問性能。本文關注的緩存類型是Web代理緩存。對于安全苛刻系統這類復雜系統的綜合測試數據系統,如航天器綜合測試數據系統,目前的文獻中給出的常用方法并不完全適用于面向實時環境的航天器綜合測試數據查詢。因此,設計一種優秀的緩存替換算法來提高系統的性能具有重要意義。
2 GDSF算法
GDSF算法是目前應用最廣泛的緩存替換算法之一,是被公認為“足夠好”的緩存替換算法,具有較好的緩存命中率。GDSF算法綜合考慮了Web對象訪問頻率、對象的大小和獲取對象所需的代價的影響,并且通過老化因子的設置,將Web訪問的時間局域性特征對緩存替換的影響很好地融合到了算法中。但GDSF算法不能很好地適應數據流的快速變化,因而不能取得足夠好的緩存命中率。Web應用是典型的數據流應用[23-24],在Web數據流變化較快的環境中(如航天器綜合測試數據查詢應用中)。本文在GDSF算法的基礎上,引入了數據流挖掘中在滑動時間窗口上挖掘頻繁模式所使用的一些方法,提出了GDSF-STW算法,改進了GDSF算法的頻率計數方法,并引入了過期事務的概念,使得算法有一定的適應性,實現較好的緩存命中率,提高緩存系統的性能。
GDSF算法使用以下函數計算每個Web對象的特征值:
(1)
式中:I為Web對象;V(I)為Web對象I的特征值;L為老化因子,初始值為0,當緩存替換發生時,L被賦值為最近一次被替換出去的對象的特征值;ffreq(I)為對象I的頻率計數,即該對象在過去的所有訪問請求中被請求的次數,對象I緩存命中時,其對應的計數加1,否則ffreq(I)=1;Size(I)為對象I的大小;Cost(I)為取回對象I所需花費的代價。
當需要緩存替換時,具有最小特征值的對象將會被替換出去。從式(1)可以明顯看出,GDSF算法綜合考慮了對象訪問頻率ffreq(I)、對象大小Size(I)和獲取對象所需的代價Cost(I)的影響。此外,還考慮了對象訪問的時間局域性特征。每次緩存命中時,都會更新對象的特征值V,在發生緩存替換時,將老化因子L的值更新為被逐出對象中最大的特征值V,由此可見,老化因子L的值將是逐步遞增的,這就使得最近命中的對象要比那些長時間沒有訪問到的對象,在特征值的老化因子部分要大,這就將對象訪問的時間局域性的影響融合到了算法中。但并沒有考慮用戶更關心的是最近的事務,而那些很久的事務對用戶現在所查詢的事務影響很小了,而對那些較遠的歷史事務進行處理所需要的資源開銷卻是巨大的。所以,某一時間段內的事務數據可能更重要。而應用滑動時間窗口模型就能夠應對數據過期的問題。下面給出本文提出的GDSF-STW算法。
3 GDSF-STW算法
3.1 相關概念
設C={I1,I2,…,In,…,Im}為數據項的集合。
定義1事務Tj={Ix,Iy,…,Iz}為C的一個子集,即Tj?C,每個事務有一個標識符,稱為TID。事務中的數據項是無序的,可以任何順序排列。
定義2數據流DS={T1,T2,…,Tj,…,Tm}由按時間順序連續排列的事務組成,事務的數量可能是無限的,且其事務按時間到達的先后順序分配TID,每個事務的TID是唯一的。
定義3滑動時間窗口SW[25-26]是數據流DS中最近N(N≥0)個事務的序列,事務在滑動時間窗口中的先后順序與其在數據流DS中的先后順序是一致的。根據N是可變的還是固定的,可將滑動時間窗口分為可變長度滑動時間窗口和固定長度滑動時間窗口。常用的可變長度滑動時間窗口主要是基于時間的滑動時間窗口,即窗口中保存最近時間范圍(如1 h)內的事務。可對滑動時間窗口進行的操作應該包括從滑動時間窗口中刪除最舊的事務以及向滑動時間窗口中添加新的事務,但對于固定長度滑動時間窗口,當窗口中的事務數量達到N之后刪除和插入操作必須是成對進行的,可變長度滑動時間窗口[27]則沒有這方面的限制。
本文對Web點擊流進行分析,用戶一次Web點擊所請求的對象的集合用一個事務來表示,而集合中的每個數據項用一個Web對象來表示。所有事務按請求到達的先后順序所組成的數據流就稱為Web點擊流。
3.2 算法描述
GDSF-STW算法的特征值函數可以表述為
V(In,Tj)=
(2)
式中:V(In,Tj)為事務Tj到達時對象In的特征值;fd(In,Tj)為事務Tj到達時對象In的衰減支持數;Toldest≤Tj≤Tlast和Tj
(3)
其中:
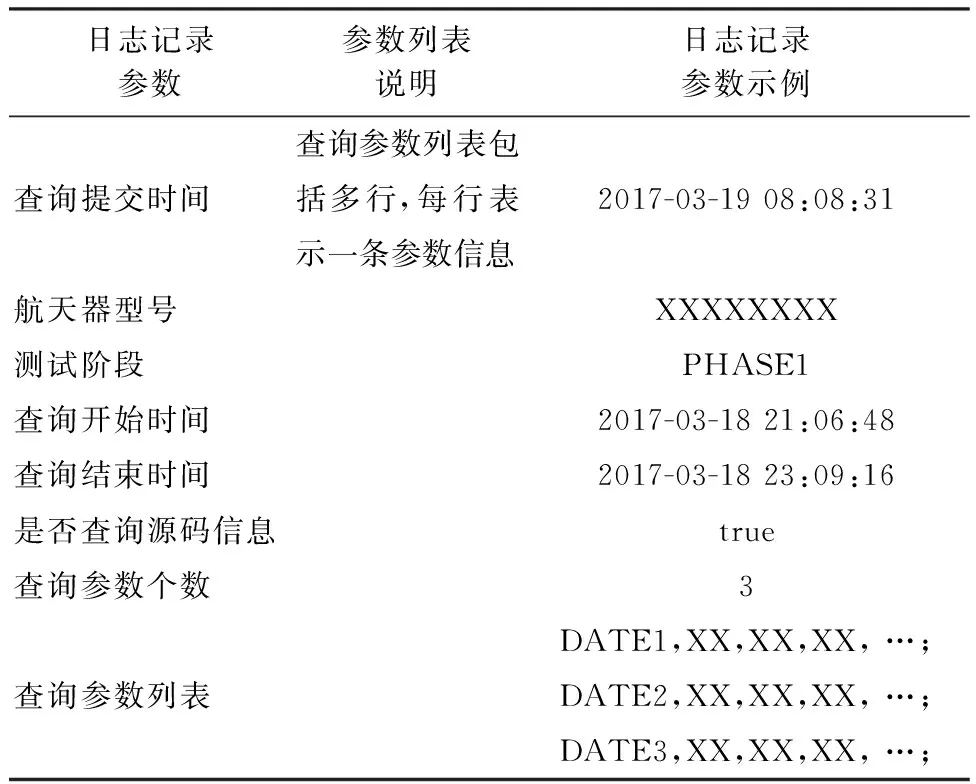
Web對象訪問具有時間局域性,即被訪問的對象距現在越近,將來被訪問的可能性越越大。也就是說,Web點擊流總會隨著時間的推移發生變化,最近產生的事務所蘊含的知識通常比歷史事務中所蘊含的知識更有價值[28]。因此,可采用文獻[29-30]中提出的時間衰減模型支持數計算方法來逐步減輕歷史事務的影響。記數據項在單位時間內的衰減比率為衰減因子f(0 在介紹算法流程之前,先給出算法中用到的數據結構。 1) 滑動時間窗口。基于時間的滑動時間窗口用于保存最近可變時間段time內到達的事務隊列。滑動時間窗口的成員用一個數據結構SwItem來表示,字段包括提交時間subTime和事務TID。當一個新的事務Tj到達時,則需要更新滑動時間窗口,將該事務的提交時間及該事務的TID封裝到SwItem對象,并將其插入隊列尾部。然后從隊首開始檢查,刪除所有已經過期的事務。用oldestTid和newestTid分別表示滑動時間窗口隊首事務和隊尾事務TID(newestTid減去oldestTid等于滑動時間窗口的長度time)。 2) 對象信息Hash表fdHash。用來保存Web對象的衰減支持數及相關的其他信息,以鍵值對的形式表示。以Web對象名稱為主鍵,值是一個稱為Item_Node的數據結構,即 當一個新的事務Tj到達時,對于該事務中的每一個對象In,GDFS-STW算法流程描述如下: 步驟1若對象In緩存命中,即In已存在于緩存中,則更新對象In的衰減支持數fd(In,Tj)=fd(In,Tj)fj-tid+1(f值為1時表示不衰減)。更新對象In最近被包含的TID:tid=j。使用式(2)更新對象In的特征值V(In,Tj)。Used值保證不變。算法對該對象的處理結束。 若對象In不存在于緩存中,則對象In的衰減支持數fd(In,Tj)=1;對象In最近被包含的TID:tid=j;使用式(2)計算對象In的特征值V(In,Tj);將對象In的相關信息保存至對象信息Hash表fdHash中;Used=Used+Size(In)。 步驟2若Used≤TotalSize,表示緩存中有足夠的空間保存對象In,此時直接將對象In存入緩存中,算法對該對象的處理結束。 若Used>TotalSize,表示緩存空間不夠,此時需進行緩存替換。從對象信息Hash表fdHash中逐個找出過期對象(對于fdHash中的一個Item_Node,若Item_Node.tid 步驟3若Used≤TotalSize,說明移除過期對象Ie后,有足夠大的緩存空間存儲對象In。將對象In放入緩存中,算法對該對象的處理結束。 若Used>TotalSize,說明移除所有的過期對象后,仍沒有足夠的緩存空間存儲對象In。此時,遍歷對象信息Hash表fdHash,選擇最小的k(k≥1)個特征值(特征值相同時優先選擇最近包含tid最小的對象),找到其對應的對象I1,I2,…,Ik,它們滿足如下3個條件: V(I1,Tj)≤V(I2,Tj)≤…≤V(Ik,Tj) (4) (5) (6) 步驟4老化因子L被賦值為V(I1,Tj),V(I2,Tj),…,V(Ik,Tj)中的最大值V(Ik,Tj),即 (7) 步驟5從緩存中移除對象I1,I2,…,Ik,并按式(8)更新Used的值: (8) 從對象信息Hash表fdHash中,清除對象I1,I2,…,Ik的相關信息。 將對象In存入緩存中,算法對該對象的處理結束。如此循環,直至對事務Tj中所有的對象處理完畢后,返回事務請求的對象集合,算法結束。 GDSF-STW算法的流程如圖2所示。 GDSF-STW算法使用了數據流挖掘中滑動時間窗口模型的相關概念。滑動時間窗口模型的最初靈感來源是:由于內存大小有限,保存數據流中的所有事務是不可行的,且對所有歷史事務進行處理的時間開銷也是不可接受的,而用戶更關心最近的事務。應用滑動時間窗口模型能夠應對數據過期的問題。 4.1.1 實驗環境 本文中,算法實驗運行在DELL臺式機上,CPU型號為Intel酷睿四核i5,型號7500,CPU頻率為3.4 GHz,4 GB物理內存,500 G SATA3硬盤,硬盤轉速為7 200 r/min。操作系統為Microsoft Windows 7,實驗中的算法均采用Java語言實現。 4.1.2 實驗數據 本文采用軌跡驅動[1,31]的方法來對GDSF-STW算法進行仿真實驗。實驗數據來源于航天器綜合測試數據查詢系統的服務器所記錄的查詢日志信息。由于原始的查詢日志信息中有些信息不能夠對外公布,且有很多冗余信息需要去除。本文中使用經過處理的Web查詢日志文件,文件命名規范為:WebLog_+日志編號,每個日志文件中存放21條查詢記錄,記錄格式如表2所示。航天器綜合測試數據有很多數據類型(即數據流),數據量巨大,為了方便實驗操作,選取其中一部分具有代表性的數據流數據進行實驗。上述日志文件中,每條記錄代表一次查詢,被看作是一個事務,一個事務通常需要訪問多個Web對象。為了方便緩存替換算法處理,將上述日志文件進行解析得到事務文件,每個日志文件對應解析為一個事務文件,事務文件命名格式為:TransactionFlow+對應日志文件的編號,每條日志記錄解析為一條事務記錄,事務記錄的格式如表3所示。實驗中使用2017-03-10—2017-03-24共15天的日志數據,由于日志數據統計信息表占用篇幅過大,此處省略。 表2 日志記錄格式 表3 事務記錄格式 4.1.3 性能指標 常用的衡量緩存性能的指標[13,17,32]主要包括命中率 HR(Hit Ratio)、字節命中率BHR(Byte Hit Ratio)和延遲節省率 DSR(Delay Saving Radio)。本文使用最常用的命中率HR作為衡量緩存替換算法的性能指標。請求的Web對象總數目用N表示,σi表示第i個對象是否在緩存中命中,若命中則σi=1,否則σi=0。 命中率HR定義為:在緩存中命中的對象數與總請求對象數的百分比,計算公式為 從3.2節的算法描述中可知,GDSF算法與GDSF-STW算法所使用的參數中,老化因子L、對象的頻率計數ffreq(In)、對象的衰減支持數fd(In,Tj)及對象大小Size(In)的定義都很明確,而取回對象所需花費代價Cost(In)的度量比較復雜,花費可以使用從原始服務器獲取對象的時間延遲、取回對象需要的經濟花費(如一些付費的對象和付費鏈路)、需要經歷的跳數(hops)等,也可以綜合考慮多種花費信息,實際應用中往往是根據緩存系統的目標來定義Cost(In)的值,根據文獻[33],如果要使命中率最大化,則定義Cost(In)=1。在航天器綜合測試數據查詢中,由于原始數據存放于同一臺服務器,Web服務器與數據服務器同處于內網環境,因此從原始服務器取回不同對象的時間花費相差不大,且無需考慮收費情況,為了取得較高的命中率,Cost(In)的值被定義為1。下面通過實驗分析衰減因子f及滑動時間窗口大小STW_SIZE對GDSF-STW算法性能的影響。 4.2.1 命中率與衰減因子的關系 在考慮衰減因子f對算法性能的影響時,應先屏蔽滑動時間窗口大小STW_SIZE的影響。根據航天器綜合測試數據查詢系統的實際查詢特征,用戶每天查詢的時間通常在8:00—20:30之間,當STW_SIZE被設置為780 min,一天之內就不存在過期事務,即滑動時間窗口不會發揮作用。因此本節實驗中,STW_SIZE被設置為780 min。文獻[17]顯示,在緩存相對容量達到20%時,緩存替換算法可以取得較好的命中率,因此,本節實驗中,設置緩存容量TotalSize的相對大小為20%。GDSF-STW算法針對2017-03-10—2017-03-19每天的日志數據進行實驗,在衰減因子分別設置為0.94、0.95、0.96、0.97、0.98、0.99、0.991、0.992、0.993、0.994、0.995、0.996、0.997、0.998、0.999、1時,緩存的命中率HR值如圖3所示。可以清晰地看出命中率隨衰減因子的變化趨勢。衰減因子取值在0.996~0.997范圍內時,可以取得最好的命中率。衰減因子取值在0.94~0.996時,命中率隨著衰減因子的增加而遞增。衰減因子取值在0.997~1時,命中率隨著衰減因子的增加而遞減,平均命中率也呈現相同的規律。衰減因子對算法命中率的影響比較明顯的主要原因是:航天器綜合測試數據查詢系統的用戶所查詢的數據具有很強的時間局域性,而衰減因子可以加速將歷史較久數據的特征值減小,從而更好地適應航天器綜合測試數據查詢系統的用戶查詢特征。 4.2.2 命中率與滑動時間窗口大小的關系 通過4.2.1節的實驗分析可知,衰減因子取值在0.996~0.997范圍內時,GDSF-STW算法可以取得最好的命中率,本節實驗中,取f=0.996。緩存容量TotalSize仍取總訪問量的20%。本實驗使用2017-03-10—2017-03-19共10天的日志數據進行實驗。根據4.2.1節所述系統的查詢特點,當STW_SIZE大于或等于780 min,系統不存在過期事務,因此,本實驗取STW_SIZE分別為780、720、660、600、540、480、420、360、300、240、180、120、60、30、20、10、9、8、7、6、5、4、3、2 min。圖4為命中率與滑動時間窗口大小的關系曲線。可以明顯看出,滑動時間窗口大小在600 min遞減至8 min的過程中,GDSF-STW算法都能取得較好的命中率,且性能指標保持穩定。當滑動時間窗口大于600 min,命中率下降,說明通過添加滑動時間窗口來判斷過期事務,在一定程度上可以提高算法的性能指標。當滑動時間窗口小于2 min時,命中率變得極不穩定,迅速下降。這是因為時間過短,許多與用戶正在查詢的事務有關的其他事務也被過早地扔出去了;而當滑動時間窗口大小達到8 min時,GDSF-STW算法就能取得較好的命中率,且性能指標保持穩定。這說明航天器綜合測試數據查詢系統的用戶查詢某相關事務的時間一般會維持在2 min以上、8 min以下,且經常在某一小段時間內存在一些高頻訪問對象。滑動時間窗口在600 min遞減至8 min的過程中,命中率指標保持穩定狀態,這是因為一次事務查詢中通常涉及到很多的對象,因此較短時間范圍內的事務中便包含了大多數的對象,這樣就使得較短時間范圍內有較多對象為非過期對象。而在較小的滑動時間窗口情況下,算法所需的存儲空間和需要被存儲事務數量都較少,從而可以降低算法的空間復雜度,因此在保證算法性能基本不變的前提下,應盡量選擇較小的時間窗口。從圖4可以看出,滑動時間窗口大小為10 min時,此時間點的前后算法性能均很穩定,因此對于航天器綜合測試數據查詢系統中的特征,滑動時間窗口大小可選擇為10 min。 4.2.3 命中率與緩存容量的關系 根據4.2.1節和4.2.2節對GDSF-STW算法不同參數的實驗分析,本節實驗中,設置滑動時間窗口大小為10 min,衰減因子f=0.996,分別對緩存容量1%、2%、3%、4%、5%、10%、15%、20%、25%、30%進行實驗。實驗使用的日志數據為2017-03-20—2017-03-24共5天的日志記錄。由圖5看出,命中率隨著緩存容量的增加快速增加,當緩存相對容量達到30%時,命中率可超過0.7。 4.2.4 與其他算法對比 本節實驗中,設置GDSF-STW算法中的滑動時間窗口大小為10 min,衰減因子f=0.996。實驗中使用的日志數據為2017-03-20—2017-03-24共5天的日志記錄。分別對GDSF-STW、GDSF、LFU、LFU-DA、LRU設置緩存容量為1%、2%、3%、4%、5%、10%、15%、20%、25%、30%進行實驗。圖6為各算法命中率隨緩存容量變化的曲線。因為針對航天器綜合測試數據查詢系統的用戶查詢特征引入了衰減因子和滑動時間窗口機制,所以從圖中可以看出,GDSF-STW算法的命中率優于其他算法。 本文針對航天器綜合測試數據查詢系統中數據的特征,分析了用戶的查詢特征,在充分調研了國內外緩存技術研究進展的前提下,結合Web數據流挖掘的相關技術,設計了一個面向航天器綜合測試數據查詢系統的緩存替換算法——GDSF-STW。 1) 給出了算法實現的具體流程,并使用實際運行環境中的查詢日志記錄數據,進行了軌跡驅動的仿真實驗。 2) 進行了充分的實驗分析,并與現有的典型緩存替換算法進行實驗對比,證明了本文算法具有更好的性能。 進一步的主要工作有:①采用DEA(Data Envelopment Analysis)方法對算法的有效性進行系統性評估研究;②收集除航天器綜合測試數據外的其他領域數據,如股票交易、視頻網站、新聞網站等一些數據量大、變化快且大眾用戶更關心的最新數據變化情況的應用,探討本文提出的GDSF-STW算法在這些領域數據的應用和擴展。3.3 算法流程
4 實驗設計及分析
4.1 實驗設計

4.2 實驗分析
5 結 論
