基于3PLM和GRM混合模型的等值方法比較
2018-09-04 10:32:12黎光明
心理研究 2018年4期
黎光明
(華南師范大學(xué)心理學(xué)院、心理應(yīng)用研究中心,廣州 510631)
1 引言
等值是心理與教育測量領(lǐng)域的一個重要組成部分,是測驗標(biāo)準(zhǔn)化過程中的一個必備程序(漆書青,戴海崎,丁樹良,2002)。具體而言,測驗等值是指將測量同一心理品質(zhì)的多個測驗形式上的測驗分數(shù)或項目參數(shù)的單位系統(tǒng)進行轉(zhuǎn)換,以達到相互間對應(yīng)指標(biāo)可比的過程。進行等值處理后,同一考生在不同測驗版本上的得分相同。一般來說,進行等值必須滿足四個前提條件,即同質(zhì)性、等價性、樣本一致性及對稱性(張敏強,1998)。
在題庫的建設(shè)中,項目參數(shù)估計和等值是兩個突出的技術(shù)問題。傳統(tǒng)的基于經(jīng)典測量理論的等值方法只能實現(xiàn)不同試卷之間的等值,而隨著項目反應(yīng)理論(Item Response Theory,IRT)在心理與教育測量領(lǐng)域越來越廣泛的應(yīng)用 (黎光明,張敏強,2012),基于IRT的等值方法實現(xiàn)了將試題的難度、區(qū)分度、猜測水平等題目參數(shù)置于同一尺度上,從而滿足大規(guī)模題庫建設(shè)的需要。
按照項目反應(yīng)理論,同一項目在不同的單位系統(tǒng)上雖然參數(shù)值的數(shù)字表現(xiàn)形式不同,但實質(zhì)卻一樣。假設(shè)有兩個測驗X和Y,且兩測驗有M個錨題,同一項目的兩套參數(shù)間必然存在如下的線性轉(zhuǎn)換關(guān)系 (Sayaka & Shinichi,2011; Kolen & Brennan,2013):


在公式(1)~(4)中,A 和 B 為線性轉(zhuǎn)換參數(shù)(等值常數(shù)),θxi,axj,bxj,cxj表示在群體 x 上估計出的參數(shù),θyi,ayj,byj,cyj為在群體 y 上估計出的參數(shù)。除非另外有申明,一般假設(shè) i=1,2,…,N;j=1,2,…,M。
上述這些公式反映了在項目反應(yīng)理論模型下,不同單位系統(tǒng)的各種參數(shù)之間的等值轉(zhuǎn)換模式,A和B為等值轉(zhuǎn)換系數(shù)。
在項目反應(yīng)理論的指導(dǎo)下,研究者建立了眾多的計量模型,這些模型都有各自的特點和所適用的范圍。在實際的應(yīng)用過程中,研究者往往會根據(jù)情況進行選擇以達到模型對數(shù)據(jù)的最佳擬合。在實際的研究工作中我們常常會遇到一份測驗材料既有0-1評分的多重選擇題 (Multiple-Choice items,MC)又有多級評分的簡答題或解答題(Construct-Response items,CR)的情況。傳統(tǒng)的做法通常是選用多級評分模型,因為0-1計分是多級評分的一個特例。但是,該做法忽略了0-1計分題目中的猜測行為,使得分析結(jié)果的準(zhǔn)確性和科學(xué)性受到了影響 (張敏強,黎光明,王小婷,黃春汝,王幸君,2015)。事實上,在這種情況下應(yīng)該考慮“混合模型”,即0-1計分的試題選用0-1計分模型,多級評分的試題選用多級評分模型,兩個模型結(jié)合共同完成對測試材料的分析(周世科,2008)。“混合模型”是指測驗分數(shù)中既包含有二級記分題型,又包含多級記分題型的混合題型,需要用不同的項目反應(yīng)理論模型來區(qū)別對待的模型。“混合模型”在參數(shù)估計過程中,所有參數(shù)均是同時估計的。
目前關(guān)于“混合模型”各方面的研究并不多。國外對于混合題型測驗等值的研究大多僅采用MC作為錨題,主要是因為當(dāng)MC和CR得分相關(guān)高、錨題得分和總分相關(guān)高、MC占得分值比例高及被試能力水平差異小時,得到的等值精度更高。也就是說,為了追求較高的等值精度,CR題型的數(shù)量和所占的分值要盡可能少。但是,Tate(2000)指出僅采用MC題型作為錨題會產(chǎn)生大的等值誤差。另外,Tate也認為,錨題僅包含MC題目也并不符合錨題為原測驗的 “縮影”這一原則,不具備代表性。
國外也有少量的研究將MC和CR共同作為錨題來進行混合題型測驗的等值。Tian(2011)對混合題型測驗的等值進行了模擬研究,比較了僅用MC項目作為錨題、僅用CR項目作為錨題以及用MC和CR項目共同作為錨題這三種不同的錨題題型設(shè)置情況,結(jié)果發(fā)現(xiàn)同時參數(shù)標(biāo)定比SLcrit法的等值在三種不同的錨題題型設(shè)置情況下精確性都更高。Kim 和 Lee(2006)也進行了基于 3PLM(Three-Parameter Logistic Model)和 GPCM(Generalized Partial Credit Model)混合模型下的研究,結(jié)果得出特征曲線法要優(yōu)于矩估計法,而Habera法又略優(yōu)于SL法。實際上,基于3PLM和GPCM混合模型比較還受到其它因素影響,如題目數(shù)量、記分模型等。Saen-amnuaiphon, Tuksino 和 NIchanong (2012)認為,在3PLM和GPCM混合模型下CR項目數(shù)量比MC項目數(shù)量越多,測驗信息量越大,測驗越有效。Kim 和 Walker(2012)認為,在錨題為 MC 和 CR時對模型選擇進行比較,僅采用多級記分模型的等值誤差很大。
而對于混合題型的等值研究,國內(nèi)僅有周世科(2008)對此進行了專門研究,采用的是測驗特征曲線法,比較了混合模型和GRM (Graded Response Model)模型對混合題型的等值精度。結(jié)果得出錨題為混合題型時,僅采用多級計分模型誤差會增大,采用混合模型會比僅用GRM更適合。特征曲線法是一種項目參數(shù)等值方法,而GRM是一種IRT數(shù)學(xué)模型。涂冬波、蔡艷、戴海琦和丁樹良(2011)也認同一個模型往往很難反映所有數(shù)據(jù)資料本身的特點,可考慮應(yīng)用多個IRT模型(即混合模型)來分析,以達到對數(shù)據(jù)的最佳擬合,并對基于3PLM和GRM的混合模型的思想方法及原理、參數(shù)估計的實現(xiàn)以及模型性能進行了研究。
綜合前人在相關(guān)領(lǐng)域的研究結(jié)果,本研究著重討論基于3PLM和GRM的混合模型下的多種IRT等值方法,并比較它們的性能優(yōu)劣,以期為相關(guān)理論研究和實際應(yīng)用提供參考。
2 研究方法
2.1 數(shù)據(jù)來源
數(shù)據(jù)來源為廣東省佛山市 “升中”考試實測數(shù)據(jù),分為“課改實驗區(qū)”和“非課改實驗區(qū)”。“升中”數(shù)學(xué)考試相應(yīng)地分為課改區(qū)的測驗X和非課改區(qū)的測驗Y。從課改區(qū)和非課改區(qū)隨機各抽取10000人。測驗X和測驗Y各有24道題,其中客觀題15道,主觀題9道。測驗X和測驗Y有一個錨測驗V,測驗V的主客觀題共9道題。
2.2 等值設(shè)計與方法
由于課改區(qū)與非課改區(qū)考生的能力有所差異,且課改區(qū)和非課改區(qū)的測驗中有共用的錨題,因此本研究采用非等組錨測驗設(shè)計。等值方法選用平均數(shù)-平均數(shù)法(Mean/Mean Method,MM)、平均數(shù)-標(biāo)準(zhǔn)差法(Mean/Sigma Method,MS)、穩(wěn)健的平均數(shù)-標(biāo)準(zhǔn)差法(Robust Mean and Sigma Method,RMS)、Haebara法(HA)以及 Stocking-Lord 法(SL)。
2.3 等值步驟
2.3.1 參數(shù)估計
依據(jù)3PLM和GRM的混合模型分別對混合題型的測驗X和測驗Y進行參數(shù)估計。其中,依據(jù)3PLM模型分別對兩測驗的客觀題進行參數(shù)估計,依據(jù)GRM模型分別對兩測驗的主觀題進行參數(shù)估計。所使用的參數(shù)估計軟件是Parscale4.1。
2.3.2 測驗等值
分別將混合題型、只有客觀題以及只有主觀題的測驗X和測驗Y通過IRTEQ進行等值轉(zhuǎn)換,得到以下三種結(jié)果:一是3PLM和GRM混合模型下五種等值方法的混合題型測驗觀察分數(shù)等值結(jié)果、二是3PLM模型下五種等值方法的客觀題測驗觀察分數(shù)等值結(jié)果、三是GRM模型下五種等值方法的主觀題測驗觀察分數(shù)等值結(jié)果。
2.3.3 數(shù)據(jù)分析
使用軟件SPSS19.0對等值的結(jié)果進行方差分析。
2.4 比較基準(zhǔn)和標(biāo)準(zhǔn)
2.4.1 比較基準(zhǔn)
模擬研究中可以設(shè)置測驗項目的指標(biāo),然而實證研究在現(xiàn)實中往往是無法設(shè)置測驗項目的真實指標(biāo)。 在 Lord (1977)、Marco 等人 (1979)、謝小慶(2000)、焦麗亞和辛濤等人(2006)的研究中,經(jīng)典測量理論(Classical Test Theory, CTT)中的 Tucker線性等值方法都是比較出色的。因此,本研究選用CTT等值方法中的Tucker線性等值結(jié)果作為五種IRT等值方法的分數(shù)等值的比較基準(zhǔn)。
2.4.2 比較標(biāo)準(zhǔn)
五種IRT等值方法觀察分數(shù)的比較標(biāo)準(zhǔn)是計算這五種IRT等值方法測驗觀察分數(shù)等值結(jié)果與作為比較基準(zhǔn)的Tucker等值觀察分數(shù)等值結(jié)果的兩種差異量 (謝小慶,2000;黎光明,張敏強,2012; Kang & Petersen, 2012):
一是誤差平均差,用于方差分析,觀察題型與等值方法之間是否存在交互作用。誤差平均差由下式定義:
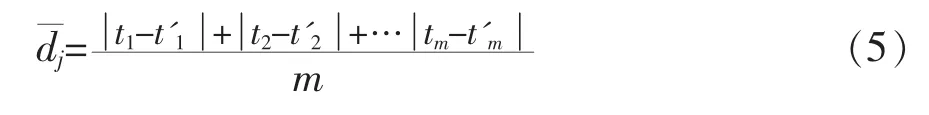
在公式 (5)中,m為測驗的題目數(shù),j是原始分數(shù),t'm是作為評價標(biāo)準(zhǔn),tm是估計的等值分是原始分數(shù)對應(yīng)的五種IRT等值方法結(jié)果與作為評價標(biāo)準(zhǔn)的等值分相減后所得的平均誤差。
二是標(biāo)準(zhǔn)加權(quán)均方差或總誤差的平方根,用于對混合模型下五種IRT等值方法結(jié)果的精確性排名。總誤差平方根由下式定義:
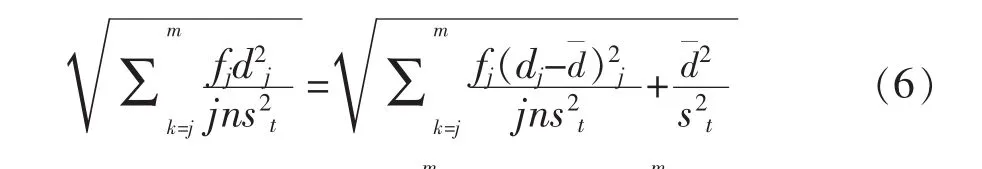
3 結(jié)果與分析
3.1 測驗觀察分數(shù)等值結(jié)果
五種IRT等值方法下的混合題型、客觀題以及主觀題測驗觀察分數(shù)部分等值結(jié)果及作為評價標(biāo)準(zhǔn)的Tucker觀察分數(shù)部分等值結(jié)果列于表1~表3。
3.2 誤差平均差的方差分析
根據(jù)誤差平均差的定義,分別計算五種等值方法結(jié)果誤差平均差,并把所得的誤差平均差作為因變量,五種IRT等值法和題型作為自變量,進行兩因素方差分析,描述統(tǒng)計結(jié)果如表4所示。
表4是五種等值法與三種題型條件下的描述統(tǒng)計,其平均數(shù)M是根據(jù)公式(5)求取的,標(biāo)準(zhǔn)差是根據(jù)每個絕對離差值計算得到的,主要為了反映絕對離差值的離散趨勢。
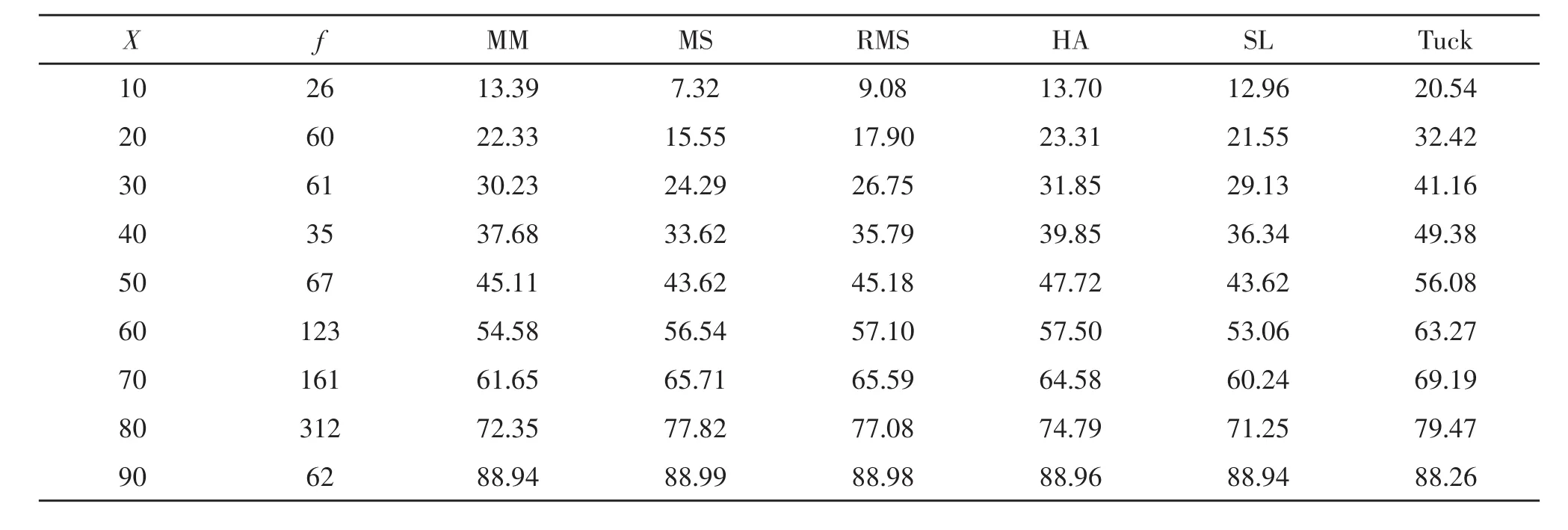
表1 五種IRT等值方法下的混合題型測驗觀察分數(shù)等值結(jié)果

表2 五種IRT等值方法下的客觀題測驗觀察分數(shù)等值結(jié)果
對五種IRT等值方法測驗觀察分數(shù)等值進行方差分析,結(jié)果如表5所示。
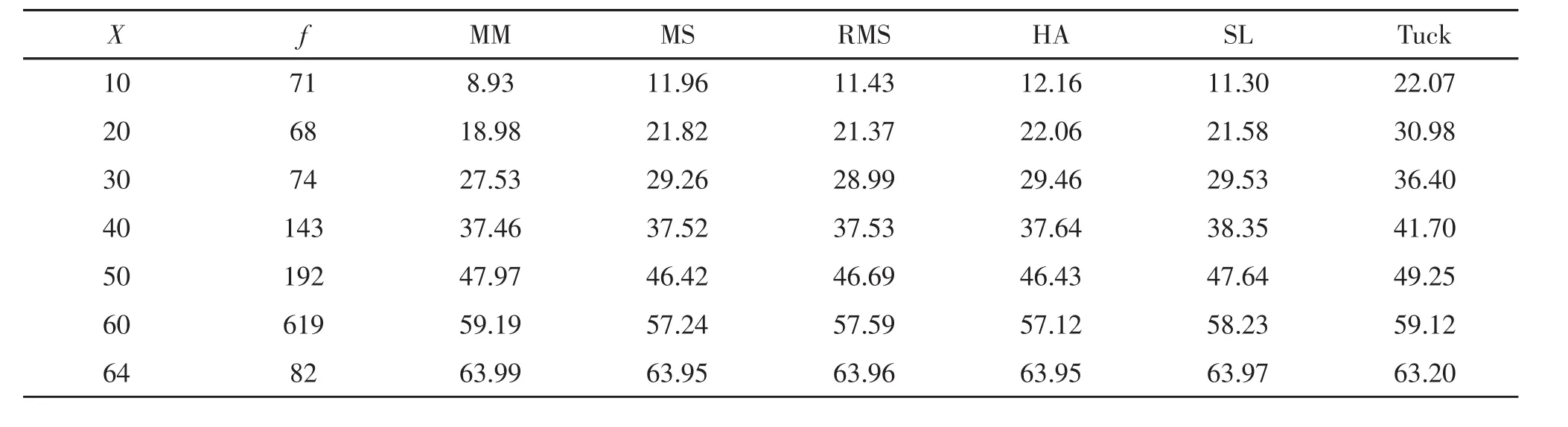
表3 五種IRT等值方法下的主觀題測驗觀察分數(shù)等值結(jié)果
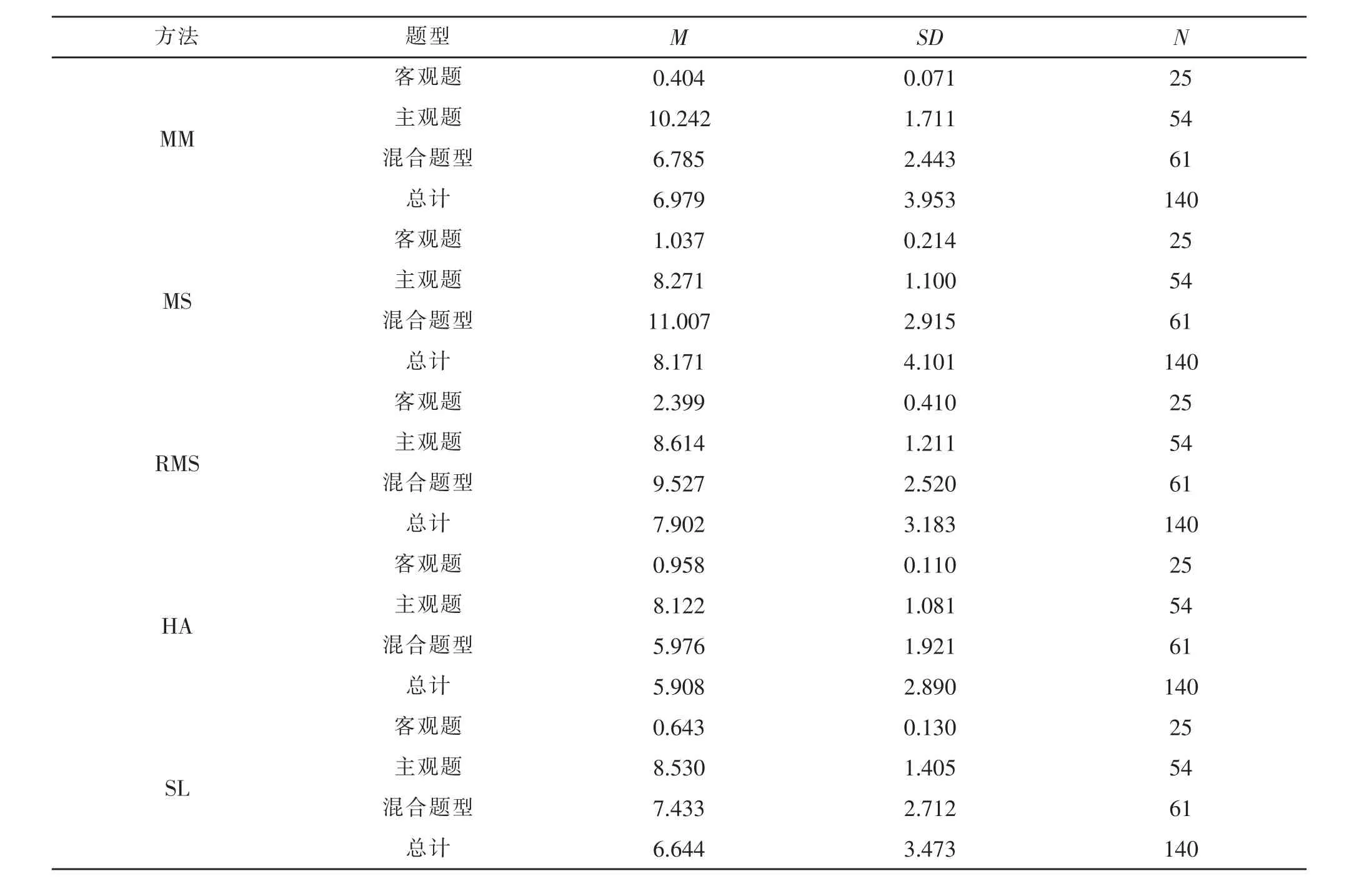
表4 五種等值法與3種題型條件下的描述統(tǒng)計
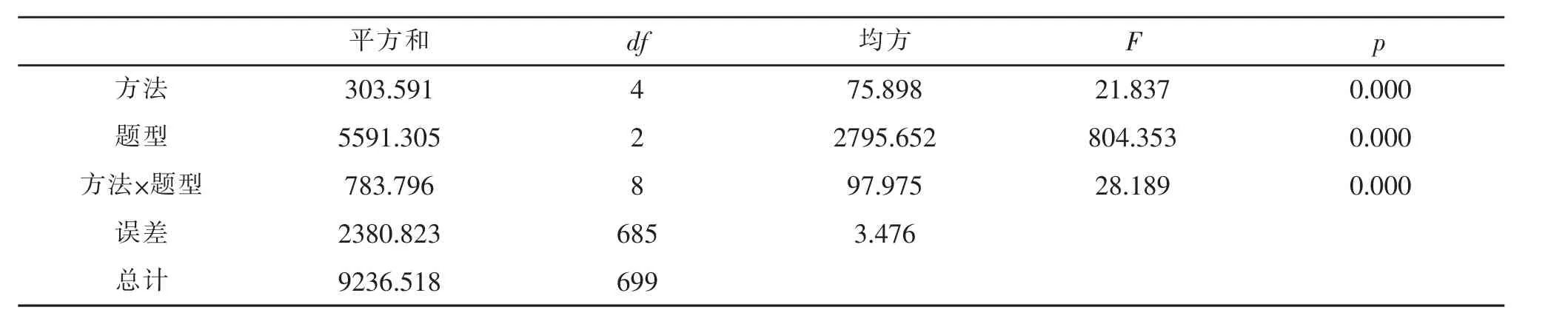
表5 五種等值法與三種題型條件下方差分析的主效應(yīng)檢驗
從表5可知,五種IRT等值方法的主效應(yīng)顯著,F(xiàn)(4,660)=21.837,p<0.001;題型的主效應(yīng)顯著 F(2,660)=804.353,p<0.001;兩因素間的交互作用也顯著 F(8,660)=97.975,p<0.001。 因此,需要進一步作事后檢驗。
多重比較分析后發(fā)現(xiàn),五種IRT等值方法中,HA法與MS、RMS這兩種方法差異顯著 (p<0.001;p<0.001),且HA法的誤差最小,而與 MM 法和 SL法的差異并不顯著(p=0.097;p=0.429);同時,HL 法與MS、RMS這兩種方法的差異也是顯著的(p<0.05;p<0.05),且SL法的誤差比較小,但SL法與MM法差異并不顯著(p=0.997);其他的情況包括,MM 法與MS法、MM法與RMS法、MS法與RMS法,結(jié)果顯示差異均不顯著(p=0.129;p=0.278;p=1.000)。
而在客觀題、主觀題、混合題型中,客觀題與主觀題的差異顯著(p<0.001),與混合題型的差異也顯著 (p<0.001),且客觀題的誤差要小于另外兩種題型;主觀題與混合題型間差異也顯著(p<0.05),且混合題型誤差小于主觀題。
從表5還能看出,IRT方法與題型的交互作用顯著,作進一步簡單效應(yīng)檢驗后發(fā)現(xiàn),在題型因素下,各種IRT方法在只有客觀題時的差異不顯著,而在主觀題和混合題型中都有顯著差異。具體地,客觀題時 F(4,699)=1.30,p=0.270;主觀題時 F(4,699)=3.39,p<0.05;混合題型時 F(4,699)=22.55,p<0.001。3.3 混合題型下總誤差平方根比較結(jié)果
混合題型下總誤差平方根比較結(jié)果如表6所示。表6是五種等值法的總誤差平方根,是根據(jù)公式(6)求取的,主要反映總誤差的相對大小。
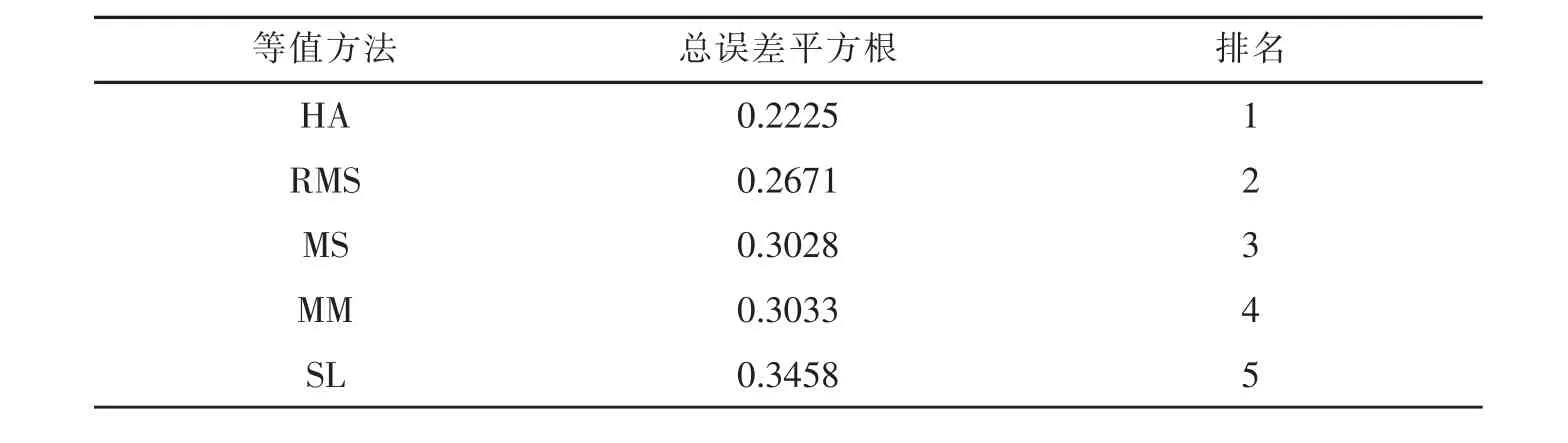
表6 五種方法的等值結(jié)果比較
從表6可以看出,Haebara特征曲線法 (HA)最為精確,其次是穩(wěn)健的MS方法(RMS),再次是MS法,MM 方法列第四,而 Stocking-Lord 法(SL)的等值誤差最大。?
4 討論
本研究采用非隨機錨測驗設(shè)計,選用3PLM和GRM的混合模型對數(shù)據(jù)進行測驗等值。本研究之所以選用非隨機錨測驗設(shè)計,是因為測驗X和測驗Y有共同錨題。錨題數(shù)量有9道,總題量共24道,占37.5%;錨題分值為39分,總分值為89分,錨題分值占總分值約為44%;錨題題型既有二級記分,也有多級記分,這表明錨測驗設(shè)計是科學(xué)的,符合錨測驗是原測驗的“縮影”這一要求,具備代表性。
測驗X與測驗Y都是混合題型測驗,即既有客觀題也有主觀題,其中客觀題數(shù)量是15題,占總題量62.5%,分值為25分,占總分28.1%;主觀題數(shù)量是9題,占總題量37.5%,分值為64分,占總分71.9%。由于不同的題型擬合不同的模型,所以本研究選取了3PLM和GRM混合模型,對于0-1評分項目用3PLM模型,多級評分項目用GRM模型。本研究選用3PLM和GRM的混合模型對數(shù)據(jù)進行測驗等值,是因為這樣做能夠使得模型達到對數(shù)據(jù)的最佳擬合。
從表5的結(jié)果可知,在三種題型中,客觀題的誤差平均差值最小,優(yōu)于混合題型和主觀題,而混合題又優(yōu)于主觀題。但是,由于客觀題本身的分值較小,等值后其分數(shù)誤差可浮動的范圍并不大,所以使得在只有客觀題的情況下,其等值后的誤差平均差值相對較小。因此,當(dāng)測驗中只有客觀題時,采用IRT方法進行等值的結(jié)果要比含有主觀題時更加精確。但是,應(yīng)該注意的是,這并不表示只有客觀題的測驗的等值結(jié)果才最能反映被試的真實水平。事實上,最能反映被試真實水平并具有現(xiàn)實意義的測驗是混合題型,這里所反映的僅僅只是等值結(jié)果的精確性。
從表5的方差分析結(jié)果來看,五種IRT方法的主效應(yīng)是顯著的。從進一步的事后檢驗的可以看出,HA法與SL法的等值效果最優(yōu);其次是MM法;最后是RMS法與MS法。其中,HA法與RMS法、MS法之間存在著顯著性差異;SL法與RMS法和MS法之間也存在著顯著性差異;而其他方法間并未發(fā)現(xiàn)顯著的差異。
從表6的結(jié)果可以看出,以標(biāo)準(zhǔn)加權(quán)均方差為比較標(biāo)準(zhǔn)時,根據(jù)總標(biāo)準(zhǔn)加權(quán)均方差或總誤差平方根值越小測驗等值誤差越小的原則,可以發(fā)現(xiàn)HA法最佳(排名第一),其次是RMS法(排名第二),再次是MS法和MM法(分別排名第三和第四),最差是SL法(排名第五)。
評價指標(biāo)的選取也是一個問題,選取不同的評價指標(biāo)可能會得出不一樣的結(jié)果。為增加結(jié)果的可信度,本研究同時采用了兩種等值比較的評價指標(biāo)。綜合各研究結(jié)果來看,因為等值結(jié)果的比較在標(biāo)準(zhǔn)加權(quán)均方差和誤差平均差兩種比較標(biāo)準(zhǔn)中并不太一致,即SL法在選用誤差平均差作為評價指標(biāo)時表現(xiàn)較好,而選用標(biāo)準(zhǔn)加權(quán)均方差作為評價指標(biāo)時表現(xiàn)是最差的。這很可能就說明了兩種比較標(biāo)準(zhǔn)結(jié)果可能是并不一致的。但是,HA法在兩種評價指標(biāo)中都是誤差最小的。因此,可以認為五種IRT等值方法中,HA法是最優(yōu)的,有著很大的等值優(yōu)勢。
評價比較不同等值方法精確性的參照標(biāo)準(zhǔn)問題正是等值研究中一直沒有得以有效解決的一個重要問題。本研究選用Tucker等值方法作為檢驗標(biāo)準(zhǔn)是因為國內(nèi)外許多等值方法的比較研究(Lord,1977;Marco, Petersen, & Stewart,1979; 焦麗亞, 辛濤,2006;謝小慶,2000)均顯示出Tucker方法相對于其他很多方法準(zhǔn)確性是比較高的,另外也有很多研究以Tucker方法作為檢驗標(biāo)準(zhǔn)。但是,選用Tucker方法作為標(biāo)準(zhǔn)只能用等值分計算等值誤差作為評價的指標(biāo),這樣便會忽略了IRT理論采用各項目參數(shù)的優(yōu)勢。有關(guān)等值研究的已有文獻(丁樹良,熊建華,戴海琦,2005;焦麗亞,辛濤,2009)表明,許多關(guān)于等值方法的比較研究并沒有達成一致的結(jié)果,最主要的一個原因為實踐中缺少一個評價等值方法精確性和有效的絕對標(biāo)準(zhǔn)。
在今后的研究中,為有效解決評價標(biāo)準(zhǔn)等方面的問題,可以開展進一步的模擬研究。原因在于,當(dāng)使用真實數(shù)據(jù)時,沒有很好的評價構(gòu)建共同尺度的方法。因為不存在評價結(jié)果精確性的標(biāo)準(zhǔn),只有在兩套項目參數(shù)的關(guān)系已知時,才可以完成評價,這樣的標(biāo)準(zhǔn)只有在模擬數(shù)據(jù)的情況下存在。
5 結(jié)論
IRT五種等值方法中,Haebara特征曲線法(HA)最優(yōu)。即便評價指標(biāo)不一致,但無論是選取誤差平均差,還是選取標(biāo)準(zhǔn)加權(quán)均方差作為評價指標(biāo)時,HA法都是誤差最小的方法。
客觀題等值結(jié)果最為精確,主觀題等值誤差最大,包括客觀題與主觀題的混合題的等值誤差介于兩者之間。
等值方法與題型具有交互作用,客觀題等值方法間差異不顯著,而主觀題或混合題等值方法間出現(xiàn)顯著差異。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
