基于空間金字塔的BoW模型圖像分類方法
2018-09-10 12:30:22林椹尠惠小強
西安郵電大學學報 2018年3期
林椹尠, 李 妮, 惠小強
(1.西安郵電大學 理學院, 陜西 西安 710121;2.西安郵電大學 通信與信息工程學院, 陜西 西安 710121;3.西安郵電大學 物聯網與兩化融合研究院, 陜西 西安 710061)
圖像分類是對不同圖像信息進行歸納整理的分類技術,可以識別及管理大量復雜的圖像場景,如建筑物、人物、自然風景等。圖像分類主要是通過提取圖像自身特征數據,并綜合像素、光照、尺度、旋轉等多種影響因素進行分類的技術,該技術已經被廣泛應用于多媒體圖像、醫療圖像、衛星圖像以及人工智能等應用場合[1],并成為了計算機視覺的研究熱點之一。
尺度不變特征變換(scale-invariant feature transform, SIFT)算法[2]、支持向量機(support vector machine,SVM)算法[3]、詞袋(bag of words, BoW)模型[4]是常用的圖像分類方法。SIFT算法主要用于識別不同圖像場景中出現的同一目標分類,對于圖像的平移、縮放、旋轉等情況具有穩定的判別能力,其計算維數較高,對光照變化較敏感。SVM算法通過選取核函數以及優化參數進行圖像分類,但在圖像特征多而雜的情況下計算量較大。BoW模型是通過收集相似圖像特征進行圖像分類,該方法不必考慮光照、尺度、旋轉等因素。上述3種分類方法都能很好的識別出多個圖像中出現的少量目標,但是,在不同場景圖像目標較多的情況下,SIFT算法容易受圖像光照的影響較大,識別率降低;SVM算法時間復雜度較高,識別時間較長;BoW模型未考慮圖像空間位置信息,導致了無序組合的數據,使分類準確率降低。
考慮到BoW模型圖像分類方法在多場景圖像下,因圖像內容的復雜化導致分類準確率低的問題,本文擬構建一種基于空間金字塔的BoW模型圖像分類方法。利用SIFT算法提取圖像特征數據,對其聚類后形成圖像視覺詞袋,建立空間金字塔BoW模型,再通過支持向量機算法進行圖像分類,并對算法進行了驗證。
1 提取SIFT特征
為了建立空間金字塔BoW模型,首先對樣本進行圖像特征提取。圖像特征提取采用SIFT算法[5],通常需要創建圖像尺度空間[6]。假設I(x.y)為圖像數據,其中x,y為圖像像素點的二維坐標值,σ∈(0,1)為尺度空間因子,G(x,y,σ)為高斯核函數,則圖像的尺度空間表示L(x,y,σ)為
(1)
式中“*”為卷積符號。在式(1)構建的尺度空間表示中,利用尺度空間中的差分高斯(difference of gaussian, DoG)算子[7]作為判別依據,搜尋圖像特征極值點。DoG定義為
D(x,y,σ)=L(x,y,kσ)-L(x,y,σ),
(2)
式中k∈(0,1)表示兩個尺度間的比例因子。利用DoG尋找極值點,若x表示D(x,y,σ)函數的極值點,X表示x方向的偏移量,對式(2)進行關于x的泰勒級數展開,則有
(3)
對式(3)求x的偏導后,得到其偏移量X為
(4)
由式(4)偏移量得到圖像中所有的極值點。考慮到極值點中存在邊緣點,可能影響到圖像識別的準確性,因此,必須通過式(3)判斷式(4)偏移量所在的極值點是否需被保留使用。根據先驗經驗[5-6],當某個圖像極值點的|D(x)|值小于0.03時,該點應該被舍棄。
對上述所有極值點篩選后進行保存,生成了SIFT關鍵點。為了得到圖像SIFT特征向量,需為每個關鍵點都分配一個梯度方向[8]。計算所有關鍵點周圍像素點的梯度方向,使用一個直方圖來統計關鍵點及其周圍像素點梯度方向的個數,則得到梯度方向直方圖。梯度方向的角度取值范圍為0~2π,以π/4為一個分割單位,得到8個梯度值。最終選擇該直方圖中頻率最高(即峰值最高)的柱所代表的方向為該關鍵點的方向。如圖1是樣本圖像像素點對應梯度方向直方圖。

圖1 梯度方向直方圖
確定像素關鍵點的方向后,利用式(4)得到關鍵點的精確位置,即得到了SIFT特征向量。樣本圖像所有像素關鍵點的SIFT特征向量如圖2(a)所示,圖中向量表示所對應像素點SIFT特征向量。

圖2 SIFT特征向量
對SIFT特征向量進行整理后進行特征提取。首先,將圖像分成16×16個bin,得到576個bin,如圖2(a)所示。然后,按照從上到下,從左到右的次序,把4×4個bin組成一個塊,共組合成16個塊,如圖2(b)所示。在每塊上分別進行SIFT特征提取,得到128維SIFT特征向量,即為樣本圖像特征數據。實驗中的圖像包括訓練樣本和測試樣本,提取特征向量數據量較大。
2 建立空間金字塔BoW模型
2.1 構建BoW模型
考慮到采用SIFT特征提取所得到的特征數據量較大,則采用構建BoW模型,對圖像的SIFT特征向量進行優化。利用K-Means聚類算法[9],對相似SIFT特征向量進行聚類。假設Ha和Hb為兩個SIFT特征向量樣本,利用歐幾里得距離[10]

(5)
計算兩個向量之間的相似度。式(5)的值越小,向量相似度越高,反之相似度越低。相似度高的向量聚類形成聚類中心,聚類中心內具有較高相似度,不同聚類中心之間具有較低相似度。把每一個聚類中心作為BoW模型的視覺關鍵詞,每個關鍵詞對應一個索引號,再將關鍵詞對應的索引號組合在一起作為視覺關鍵詞詞袋。統計詞袋中不同索引號出現的頻率形成詞頻直方圖,即生成了BoW模型。構建BoW模型流程圖如圖3所示。
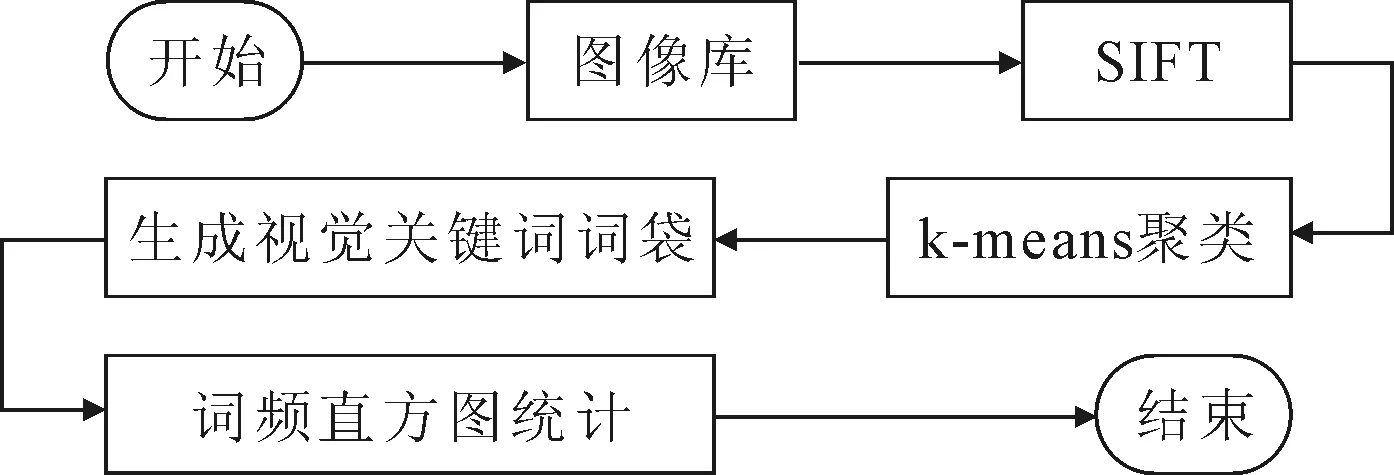
圖3 構建BoW模型流程圖
2.2 空間金字塔的BoW模型
BoW模型生成的視覺關鍵詞互相獨立,未記錄視覺關鍵詞在原始圖像中的位置信息,個別不同場景圖像間的視覺詞相似度可能較高,導致誤判為同一場景下的圖像,為此,引入其空間位置信息加以區別。本文采用空間金字塔匹配(spatial pyramid matching, SPM)[11]方法,將BoW模型得到的不同層視覺詞袋進行層次劃分,以建立空間金字塔BoW模型。
下面將說明構建空間金字塔BoW模型的方法:將金字塔第l層作為劃分標記。
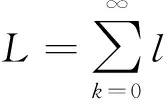

(6)
由式(6)得到金字塔匹配核KL(X,Y)為
(7)
其中1/2L-1為第l層的權重[11]。利用式(7)對圖像相似的特征進行匹配,分別得到該層圖像特征直方圖,即構建了該層的視覺詞典直方圖。各層視覺詞典直方圖組合,即建立了空間金字塔的BoW模型。
樣本圖像劃分的層數越多,區域越密,權重越大,同時帶來了計算量的急劇增加;但是,劃分層數較少,將會影響圖像的分類的準確率。所以,選擇合適的劃分層,需要考慮圖像的分類準確率和計算量綜合效果。如表1是空間金字塔總層數為3層的BoW模型。
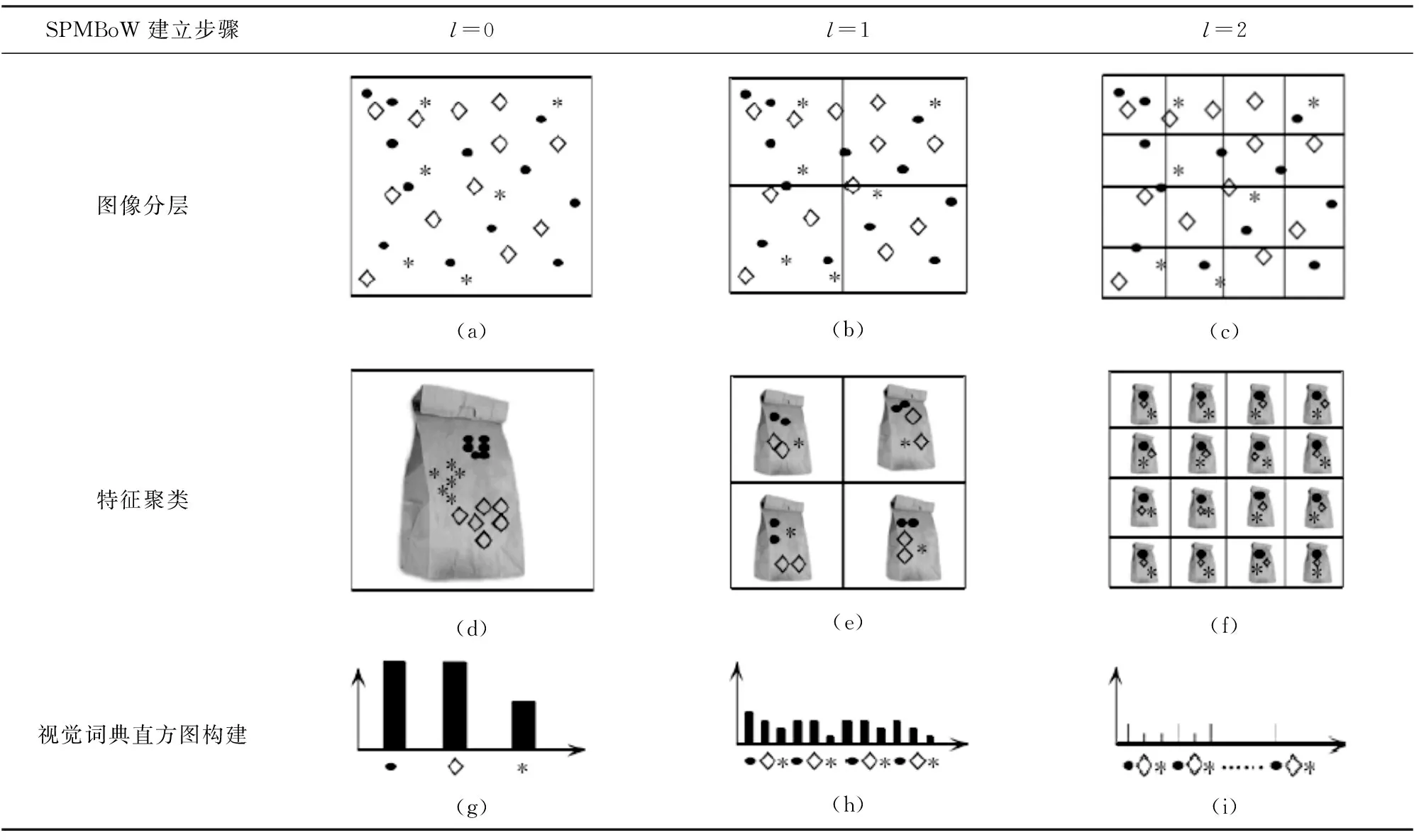
表1 空間金字塔的BoW模型
在表1中,圖(a)、(b)、(c)分別表示l=0,1,2時圖像被分成1×1,2×2,4×4個小塊;圖(d)、(e)、(f)分別表示空間金字塔的BoW模型對應層的視覺詞袋特征集合,圖(g)、(h)、(i)分別表示對應層的視覺詞典直方圖,組合成空間金字塔的BoW模型。
3 構建SVM圖像分類器
建立了空間金字塔BoW模型,就可以構建圖像分類器進行圖像分類訓練和預測,選擇SVM作為分類模型,并創建圖像分類器。
3.1 SVM核函數的選取
為了匹配空間金字塔的BoW模型中圖像特征直方圖的統計結果,采用直方圖交叉核(histogram intersection kernel, HIK)作為SVM分類器的核函數[12],即
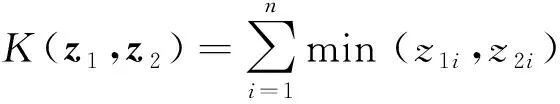
(8)
其中z1=[z11,z12,…,z1n]和z2=[z21,z22,…,z2n]分別表示兩個不同圖像直方圖特征向量。對式(8)進行線性插值[13],可以將SVM分類器的時間復雜度由o(mn)降為o(nlogm)[12-13]。
3.2 創建圖像分類器
選擇核函數后,尋找最大間隔超平面,對樣本圖像對應的空間金字塔BoW模型進行特征分類[14]。假設zi為已知圖像特征向量訓練樣本數據,ξ為未知圖像特征向量預測樣本數據,Yi為分類標記,不同圖像類別的Yi∈Z值取不同的整數進行標記,b∈R作為分類閾值[15]來進行分類判別,sign為符號函數,αi為拉格朗日乘子向量,通過Lagrange函數將圖像分類問題轉為對偶問題,K(z1,ξ)表示為分類器核函數,并得到直方圖交叉核下的超平面公式f(ξ)為
(9)
利用式(9),可以把樣本圖像對應的空間金字塔BoW模型特征數據進行分類。
5 實驗與結果分析
5.1 實驗環境
實驗運行環境采用Matlab2012a,libsvm-3.1-[FarutoUltimate3.1Mcode]作為庫函數[16],其他參數使用libsvm庫函數默認值。對于本文所選用的樣本圖像,經多次測試實驗及結果對比,設置最優空間金字塔總層數L=3,相對應的空間金字塔各層的權重分別為1/8,1/4,1/2。
5.2 實驗樣本
圖像數據采用網絡數據庫進行實驗,從中選出打電話、彈吉他、騎車、騎馬、跑步、射擊等6類不同場景作為訓練樣本以及測試樣本。其中每類抽取40張訓練樣本圖像,20張測試樣本圖像,數據庫部分圖像如表2所示。

表2 數據庫部分圖像
5.3 圖像分類實驗過程
為驗證本文采用空間金字塔BoW模型以及HIKSVM分類器進行圖像分類的效果。選取上述6類圖像,其中240張圖像作為訓練樣本,對空間金字塔的BoW模型中的視覺詞袋進行訓練,得到訓練樣本數據。再選取120張測試樣本,在訓練階段產生的訓練數據下進行分類測試,得到6類圖像對用的分類準確率。分類效果采用混淆矩陣方式表示,其結果如圖4所示。從中可見,跑步類和射擊類因空間金字塔中特征種類較少而分類準確率最高,其余4類中分別有個別圖像錯分到其他類中,但整體分類效果仍然較高。
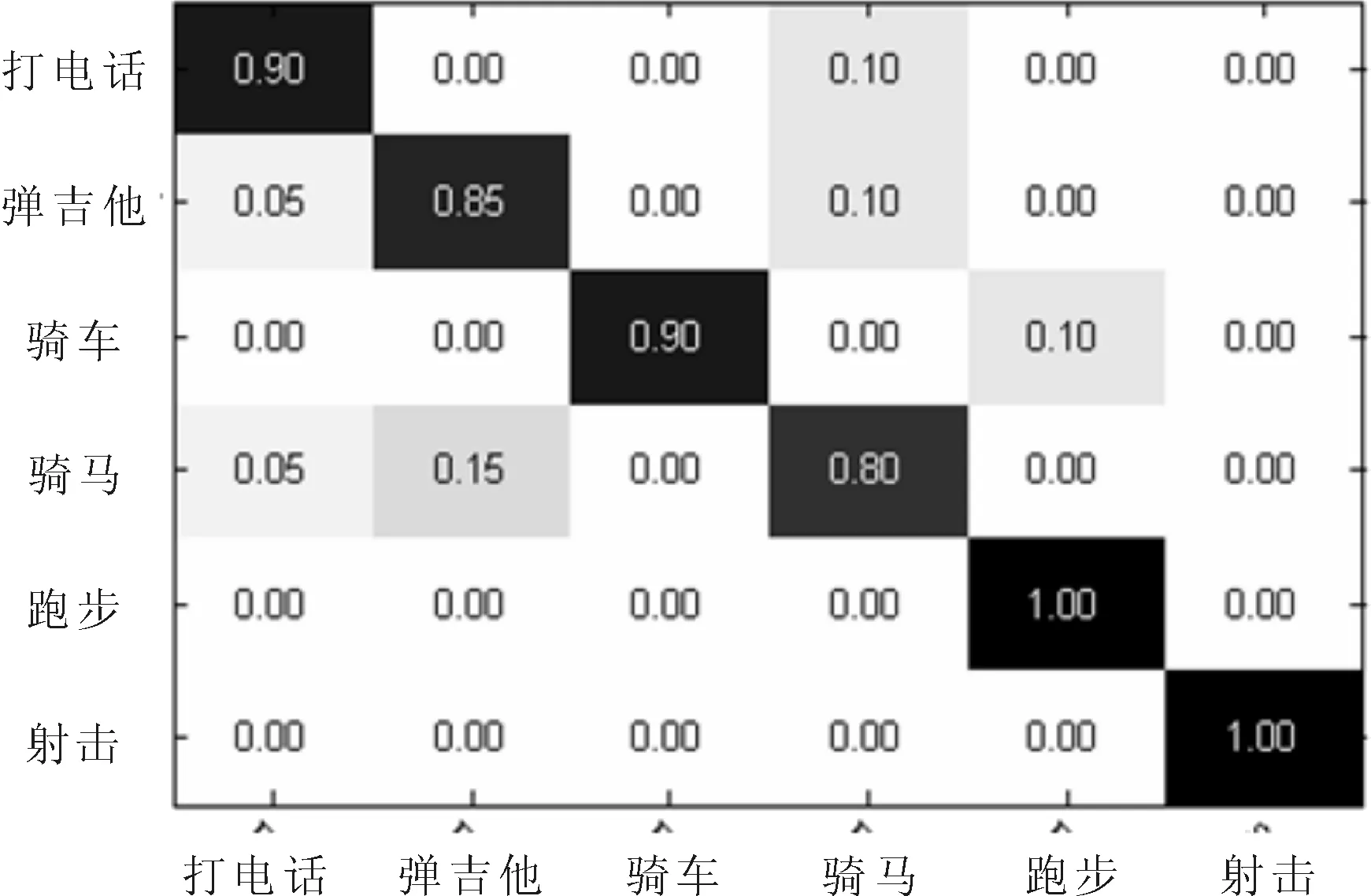
圖4 6類圖像分類情況的混淆矩陣
分別將本文方法與基于BoW模型RBF核的分類方法(BoW+RBF)、基于空間金字塔BoW模型RBF核的分類(SPMBoW+RBF)方法、基于BoW模型HIK核的分類方法(BoW+HIK)等3種分類方法進行比較,各分類方法在不同場景圖像下的分類準確率如表3所示。
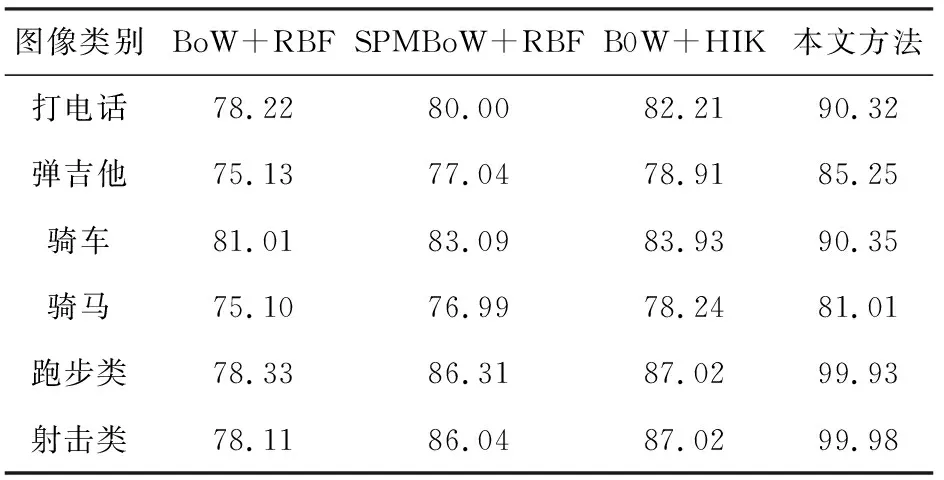
表3 4種方法分類準確率/(%)
由表3可見,本文方法對打電話類、騎車類、跑步類、射擊類等圖像分類準確率最高,而彈吉他類和騎馬類分類準確率較低,但是也達到80%以上。其主要原因是彈吉他類和騎馬類圖像的構圖復雜,導致圖像特征較多,在特征匹配階段具有一定的誤差。并且,在相同實驗樣本和實驗條件下,BoW+RBF圖像分類方法準確率最低,SPMBoW+RBF圖像分類方法的分類準確率高于基于BoW模型的分類準確率;而在基于BoW模型采用HIK核函數進行圖像分類的方法,分類準確率有一定的提高;本文方法是基于空間金字塔BoW模型,采用HIK核函數的分類方法,分類準確率明顯高于其他3種方法。
6 結語
針對不同場景圖像下的圖像分類問題,給出了一種基于空間金字塔BoW模型的圖像分類方法。該方法利用尺度不變特征變換法提取原始圖像像素特征,進行聚類形成視覺詞袋,進而構建空間金字塔的BoW模型,再利用支持向量機分類器對視覺詞袋進行圖像分類。實驗測試了在不同場景下的6類圖像分類,并分別與基于BoW模型RBF核的分類方法、基于空間金字塔BoW模型RBF核的分類方法、基于BoW模型HIK核的分類方法等進行了比較,結果表明,本文方法所測圖像分類的準確率相比其他3種方法均有較大幅度地提高。空間金字塔BoW模型相對于BoW模型增加了圖像特征的空間信息,使不同場景下圖像分類識別率得以提高,但是,對多層圖像的特征處理,同時也增加了BoW模型分類圖像的時間復雜度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
