分布式環境下話題發現算法性能分析
2018-09-12 05:43:48鄧璐賈焰方濱興周斌張濤劉心
通信學報 2018年8期
關鍵詞:模型
鄧璐,賈焰,方濱興,周斌,張濤,劉心
?
分布式環境下話題發現算法性能分析
鄧璐1,賈焰1,方濱興2,周斌1,張濤1,劉心1
(1. 國防科技大學計算機學院,湖南 長沙 410073;2. 北京郵電大學計算機學院,北京 100876)
社交網絡成為現在人們生活的一種重要方式,越來越多的人選擇通過社交網絡表達觀點、抒發心情。在海量的數據下,快速發現討論的內容得到越來越多的研究者的關注,隨即出現了大量的話題發現算法。在大規模新浪微博數據環境下,針對3種經典分布式話題發現算法,結合社交網絡平臺的特點提出了分析性能的測試方案,并根據測試方案比較與分析了3種算法的性能,指出了各算法的優缺點,為后續應用提供參考。
話題發現;分布式環境;社交網絡;性能分析
1 引言
互聯網正在逐步發展為無處不在的計算平臺和信息傳播平臺,這為基于互聯網的社交網絡服務應用的快速發展提供了契機。中國互聯網絡信息中心發布的統計信息顯示:截至2017年12月,中國的網民規模達到了7.72億[1]。這些用戶每天瀏覽、關注、發布數以千萬計的信息,因此,如何在如此巨大的數據規模下快速發現人們討論的內容是一個基礎和流行的研究問題。
很多研究都是基于這個問題展開的,且大多數已有工作都來源于話題發現和追蹤(TDT, topic detection and tracking)這個任務。話題發現自1996年以來就是TDT的子任務之一,它是將新聞、廣播、TV和其他媒體的信息流看作處理對象,將信息流中涉及的事件放入相關話題的過程。發展初期的信息通常由官方媒體發布,因此數據規模通常較小,單個機器節點就可以快速地完成處理。由于互聯網的快速發展以及移動終端使用的普及,各類社交媒體得到越來越多人的青睞,因此相關學者將研究重點放到郵件、論壇、微博等新型媒體。這類媒體的一個重要特征就是任意用戶都可以發布信息內容,不再局限于官方媒體,而是由用戶共同營造話題,用戶的參與感更強。這就導致了話題發現任務需要處理的數據規模大幅度增加,大多數情況下單個機器節點已經很難滿足快速完成任務的要求,分布式話題發現方法或將話題發現方法并行化是現在話題發現任務的必然趨勢。
本文首先回顧了主流的話題發現算法,在此基礎上,選擇了3種代表性的分布式話題發現算法:MrLDA算法,Mahout LDA算法和Spark LDA算法,簡單介紹了3種算法的工作原理。然后以運行時間和加速比為衡量指標,測試3種算法在不同數據規模、不同集群規模、不同迭代次數下的執行情況。最后對3種算法的性能進行對比分析,指出各自的優缺點,為后續應用提供參考。此項研究在實際的工程應用中有很大意義。
2 主流話題發現算法介紹
話題發現對于提供有效網絡輿情信息、輿情監控和競爭情報等方面具有重大意義。各類話題發現方法都基于特定話題模型,而話題模型是研究話題發現的基礎,目前主要有以下2類話題發現方法。
第一類是基于向量空間模型的方法。它是相對傳統的模型化文檔方法,將文檔看作詞袋,每個文檔看作詞匯空間中的向量。TFIDF方法是用來衡量詞項權重比較常見的方法,它的基本思想是,如果某個詞匯或短語在一篇文檔中出現的頻率較高,并且在其他文檔中很少出現,則認為該詞匯或短語具有很好的類別區分能力,適合表示文檔。2個文檔的相似性可以通過多種方法計算,一般采用余弦相似性方法,通過2個文檔向量夾角的余弦值衡量。很多基于距離的方法可以被應用到話題發現中,比如Spherical k-Means algorithm (Sk-Mean)[2]、Fuzzy Spherical k-Means (FSk-Means)[3-4]等。Makkonen等[5]將單一的事件向量分解為4個子向量,用4種不同類型的詞匯表征,分別是人物機構指示詞、地點位置指示詞、時間日期指示詞和事件指示詞。將時間表達式進行形式化,并利用本體知識對地點信息進行擴展,進而應用在話題發現中。Wu等[6]提出一個重建文本向量的高效方法檢測新話題,該方法通過Jaccard相似系數和逆向頻率計算文本向量每一維的重要程度,基于重要程度重建文本向量,提高了文本聚類和關鍵話題抽取的準確性。
第二類是基于概率模型的方法。概率話題模型[7-10]是發現隱藏話題的有效統計模型,得到越來越多研究者的青睞。其中,最具有代表性的是LDA模型[8]。它是在pLSI模型的基礎上改進的,認為文檔是在話題上的多項式分布,話題是在詞匯上的多項式分布,從而構造了文檔的產生式模型:依據概率分布依次抽取話題和詞匯,迭代地產生出文檔中的每一個詞匯,需要參數估計的方法得到最終模型,比如variational inference[8, 11]、collapsed Gibbs sampling[12]等。該模型也成功地應用于Twitter數據,Ramage等[13]提出一種基于標簽LDA(labeled LDA)的半監督學習模型,可將Twitter消息按主旨、風格、狀態和社會角色這4個維度進行分類,以便用戶瀏覽感興趣的信息。Chen等[14]采用lifelong learing方法,在訓練模型時融入must-link集合和cannot-link集合:1) 對于多個文檔集合利用經典的話題模型得到每個文檔對應的話題集合,基于該集合獲取詞匯間的must-link集合;2) 在測試數據上將must-link集合融入基于知識的話題模型(KBTM, knowledge-based topic model),根據求得的話題集合抽取其中的cannot-link集合;3) 將must-link集合和cannot-link集合重新應用到測試數據中,得到最終的話題集合。Lin等[15]提出一個雙稀疏話題模型,該模型同時考慮了文檔—主題分布的稀疏性和主題—詞匯的稀疏性,是建立在一篇文檔一般只包含幾個主題、一個主題所使用的詞匯也相對有限而不是分布在整個詞匯表的基礎上,將文檔的生成過程依托于固定主題集合和固定詞匯集合。
相對于基于向量空間模型的方法,基于概率模型的方法的應用更為廣泛,特別是基于LDA模型的方法,在話題發現、情感分析等多個領域都得到了認可。本文針對LDA模型,選擇了3種典型的分布式算法:MrLDA算法[16],Mahout LDA算法[17]和Spark LDA[18],通過分析3種算法在不同條件下的性能情況,評估不同算法的優勢。
3 3種算法的原理
LDA模型[8]是一個三層結構的貝葉斯模型,是處理語料庫中文檔的產生式概率模型。文檔由隨機潛在的話題表示,話題則是詞匯上的分布。LDA模型的具體描述如下:一篇文檔=1,…,w是由數量為的詞匯組成,話題分布θ是基于參數的Dirichlet分布,文檔中詞匯對應的話題序列=1,…,z是基于話題分布θ產生的,任意詞匯w是根據分布(w|z)產生的。參數和是先驗參數,整個語料庫采樣一次。參數是文檔級別的變量,每個文檔采樣一次。變量和是詞匯級別的變量,每個文檔下的每個詞匯采樣一次。在完成LDA模型的訓練后,可以通過推導方法求取文檔的話題分布。
3.1 MrLDA算法原理
MrLDA[16]是基于Hadoop MapReduce框架實現的大規模分布式LDA話題發現模型。其主要思想是通過對變分法的分布式化計算變分參數,迭代計算全局LDA模型的參數,從而提高LDA模型在分布式環境下的運行效率。
MrLDA算法的迭代過程如圖1所示,分為3個部分:在并行的Mapper中計算特定文檔的變分參數;在并行的Reducer中計算特定話題參數;在Driver中更新全局參數,同時監控算法是否收斂,判斷是否結束迭代。
3.2 Mahout LDA算法原理
Mahout是一個強大的數據挖掘工具,也是一個分布式機器學習方法的集合。Mahout LDA[17]基于Hadoop MapReduce框架,將變分法和Gibbs 采樣相結合來計算參數,提高了算法可處理的數據量級和算法本身的性能。
Mahout LDA算法的本質是貝葉斯公式和EM算法的結合。Mahout程序利用CVBo 算法來計算LDA模型,在Map過程中對向量和矩陣反復迭代求解,算出每個文檔的并且在更新writeModel階段將矩陣進行向量的相加。執行完所有的Map過程后將整個數據集的聚合,最終在cleanup過程中將話題的索引作為key值,矩陣作為value值寫入Reduce過程。
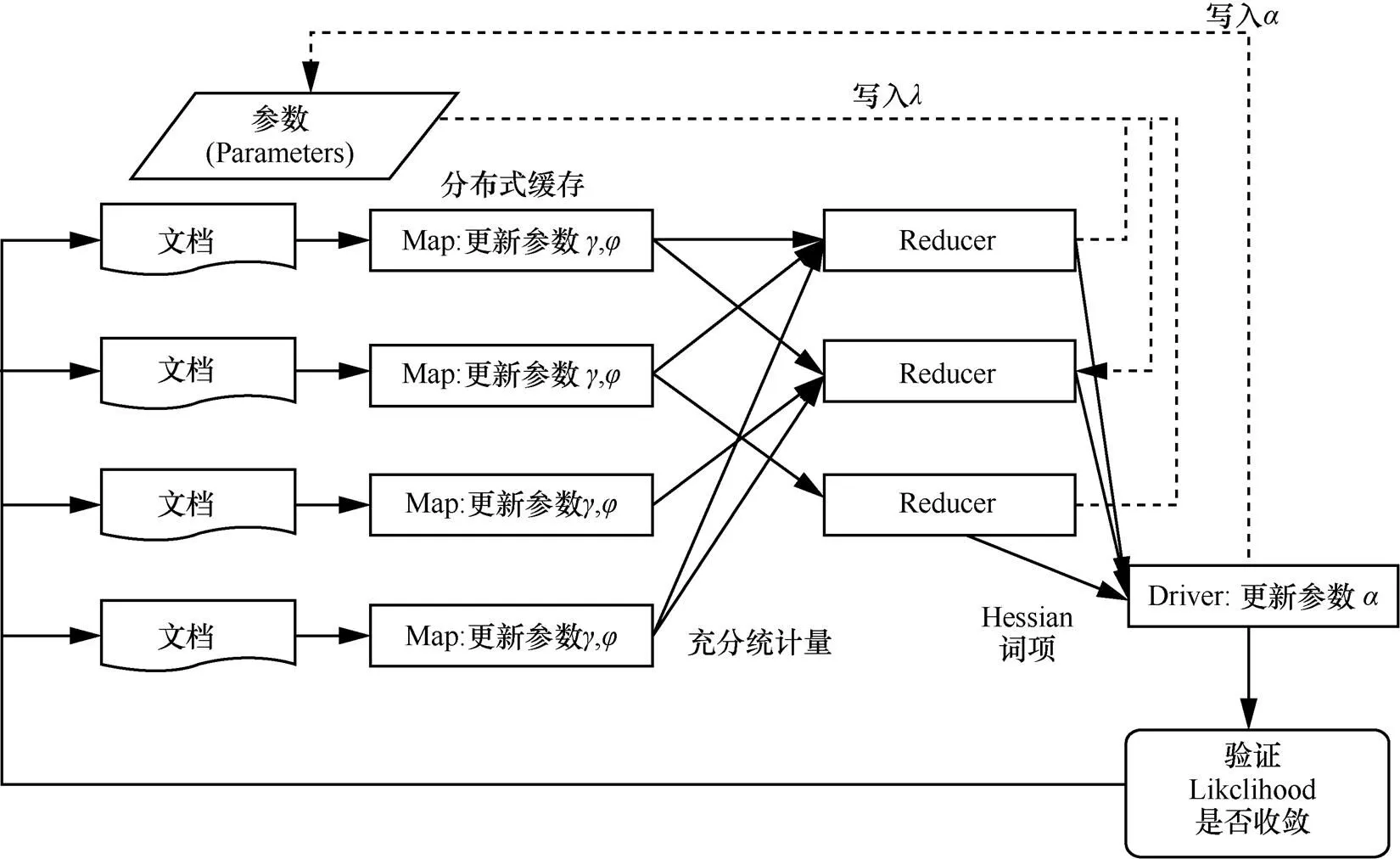
圖1 MrLDA算法原理
3.3 Spark LDA算法原理
Spark LDA[18]在Spark機器學習庫MLlib上實現了2個版本的LDA,分別為Spark EM LDA和Spark Online LDA。Spark EM LDA建立在Spark框架下,通過GraphX實現的LDA模型的算法,利用對圖的邊和頂點數據的操作訓練模型,并使用Gibbs采樣原理估計模型參數,將訓練的話題—詞匯模型存儲在GraphX圖頂點上,屬于分布式存儲方式。Spark Online LDA建立在抽樣模式的基礎上,每次訓練模型是通過抽取一些文檔實現的,最終模型是多次訓練后的結果,參數估計采用貝葉斯變分的方法,利用矩陣存儲話題—詞匯模型,屬于本地模型。Spark EM LDA在訓練時,shuffle量非常大,極大地影響速度,同時,每輪迭代完畢后更新模型,導致收斂速度較慢。Spark Online LDA使用矩陣存儲模型,矩陣規模直接限制訓練文檔集的主題數和詞的數目,且在每次訓練完抽樣文本后更新模型。因而Spark Online LDA模型更新更及時,收斂速度更快。Online LDA Optimizer 通過在小批量數據上迭代采樣實現Online變分推斷,比較節省內存。而EMLDAOptimizer得到的結果是建立在整個數據集基礎上的,更為全面,所以這里選擇Spark EM LDA進行實驗。
Spark EM LDA實現的核心是GraphX以文檔到詞匯作為邊,以詞頻作為邊數據,把語料庫構造成圖,把對語料庫中每篇文檔的每個詞匯的操作轉化為對圖中每條邊上的操作。GraphX把文檔—話題矩陣和話題—詞匯矩陣存儲在文檔頂點和詞匯頂點上,把詞頻信息存儲在邊上。它把整個文檔的聚類結果矩陣、模型矩陣和語料庫詞頻矩陣都表示在圖結構中,將LDA算法處理過程轉化為對邊的遍歷處理過程。
4 測試計劃
4.1 測試環境
本文實驗是在騰訊云上實現的,租用128臺服務器節點,如圖2所示。每個節點的軟件環境如下:CentOS6.5, Ubuntu14.04, Jdk1.8, Hadoop2.6,0, Spark1.6.2。其中,有一個主節點的配置是8核處理器,64 GB內存,500 GB硬盤,1 Mbit/s帶寬;其余節點的配置是8核處理器,32 GB內存,100 GB硬盤,1 Mbit/s帶寬。
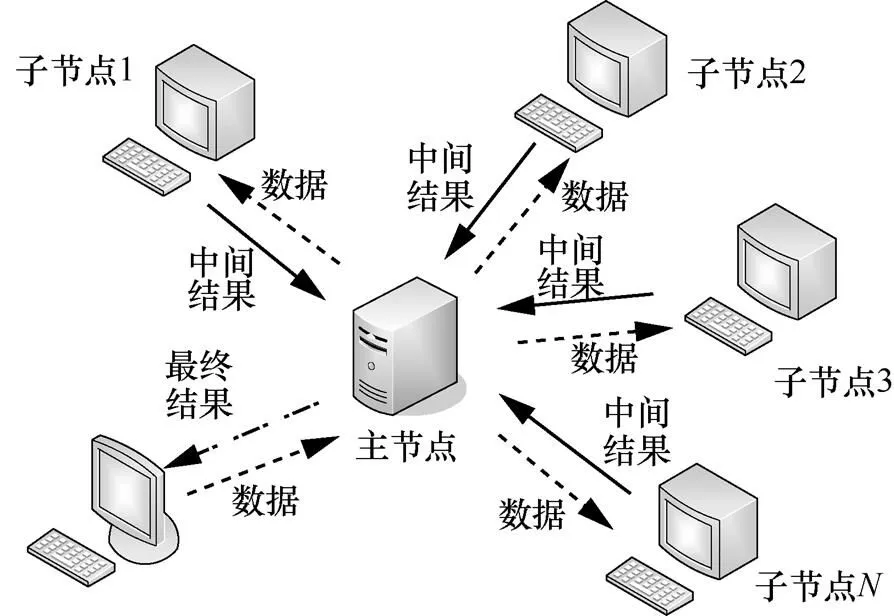
圖2 測試分布式環境示意
4.2 數據集
測試數據來自新浪微博的真實數據,爬取了2015年8月的微博內容,經過預處理,去除字數較少的博文,最終得到約1 900萬條左右的博文數據,數據規模約為12 GB。3種算法都是基于LDA模型的,所以涉及話題數目的設定,這里統一將話題數目設置為20。
4.3 測試指標
本文主要從加速比和運行時間這2個指標對3種不同的分布式話題發現算法進行測試。
加速比:測試3種算法在不同集群規模上的加速比。
運行時間:測試3種算法在不同數據規模、不同迭代次數、不同集群規模上從開始運行到結束運行的時間之差。
4.4 測試方案
1) 集群規模:隨著集群規模的增加,算法的運行時間會呈現一定程度的減小,但是否會隨著集群規模的不斷增加,呈現不斷減小的趨勢是一個值得探索的問題。根據算法的實際情況,有選擇地對3種算法節點數設定為1、4、8、16、32、64、128的集群規模,研究在同一數據規模和迭代次數條件下算法的運行時間和加速比。
2) 數據規模:計算3種算法執行不同規模測試數據的運行時間。由于3種算法的執行原理不同,對數據規模的適用情況也會有所差異,數據規模的選取可能會對算法的性能產生影響。分別對3種算法選取100萬、1 000萬和1億條博文的數據規模,研究在同一迭代次數和集群規模條件下算法的運行時間。
3) 迭代次數:3種算法都需要反復迭代處理,迭代次數太少會影響產生話題的質量,迭代次數過多會影響算法效率,不同的迭代次數對算法的性能有一定的影響。分別對3種算法設定10、30、50的迭代次數,研究在同一數據規模和集群規模條件下的運行時間。
5 3種算法的性能
5.1 MrLDA算法性能
由于在單個節點上運行MrLDA算法的時間過長,因此集群規模最小設定為4個服務器節點。這里展示了MrLDA算法在百萬數據級別,不同迭代次數和不同集群規模下的運行時間和加速比,如圖3所示。
1) 集群規模:從運行時間這個指標來看,對于100萬條博文規模的數據,MrLDA算法在16個節點時出現量級上的降低,之后時間降落沒有很明顯。從加速比指標來看,加速比在32個節點時,都達到最高值或變化不大。
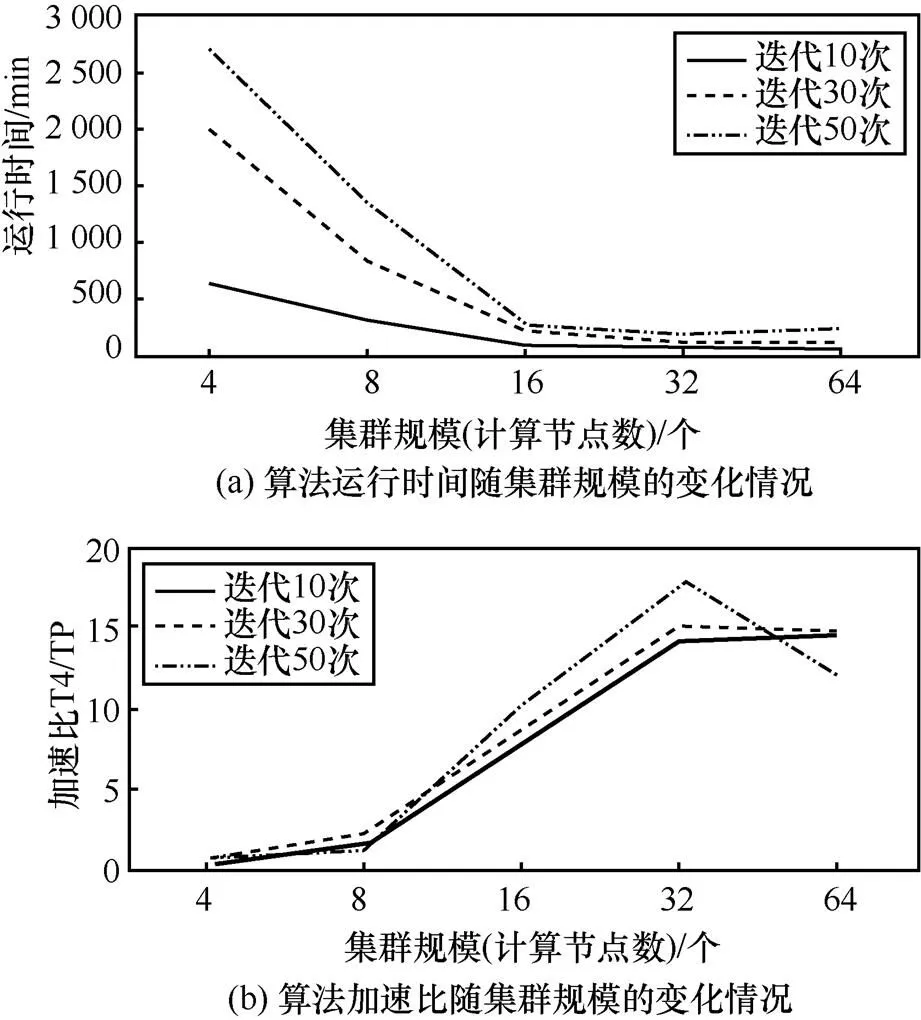
圖3 MrLDA算法百萬級別下的測試
2) 數據規模:MrLDA算法由于自身算法的局限性,沒有基于內存消耗做優化處理,因此實際能夠處理的數據量有限,在執行千萬級別以上的數據規模時會出現錯誤警告,不適合處理超過百萬級別的數據規模。
3) 迭代次數:隨著迭代次數的增加,運行時間呈現變大趨勢。迭代次數越大時,隨著集群規模的增加,其相應運行時間的下降幅度越大,加速比的上升趨勢越明顯。MrLDA算法在30次迭代時未出現收斂,在50次迭代時出現收斂。
5.2 Mahout LDA算法性能
與MrLDA算法類似,Mahout LDA在單個服務器節點時間同樣過長,因此集群規模最小設定為4個服務器節點。這里分別展示了Mahout LDA算法在百萬、千萬、億級別的數據規模,不同迭代次數和不同集群規模下的運行時間和加速比,如圖4~圖6所示。
1) 集群規模:Mahout LDA在百萬條博文規模上8個節點的運行時間最短,加速比最大。對于數據量為百萬級別的博文,最優集群規模是8個節點左右。而以千萬條規模和億條規模條件為前提時,算法在64個節點處出現了拐點,由于數據規模為百萬級別時,過早出現了性能的“瓶頸”,因此只測試到64臺服務器節點規模。而數據規模為千萬和億級別時,測試到64臺服務器節點時,運行時間仍呈現下降趨勢,加速比仍出現上升趨勢,所以對于這2個數據規模級別,測試了128臺服務器節點下的執行情況。
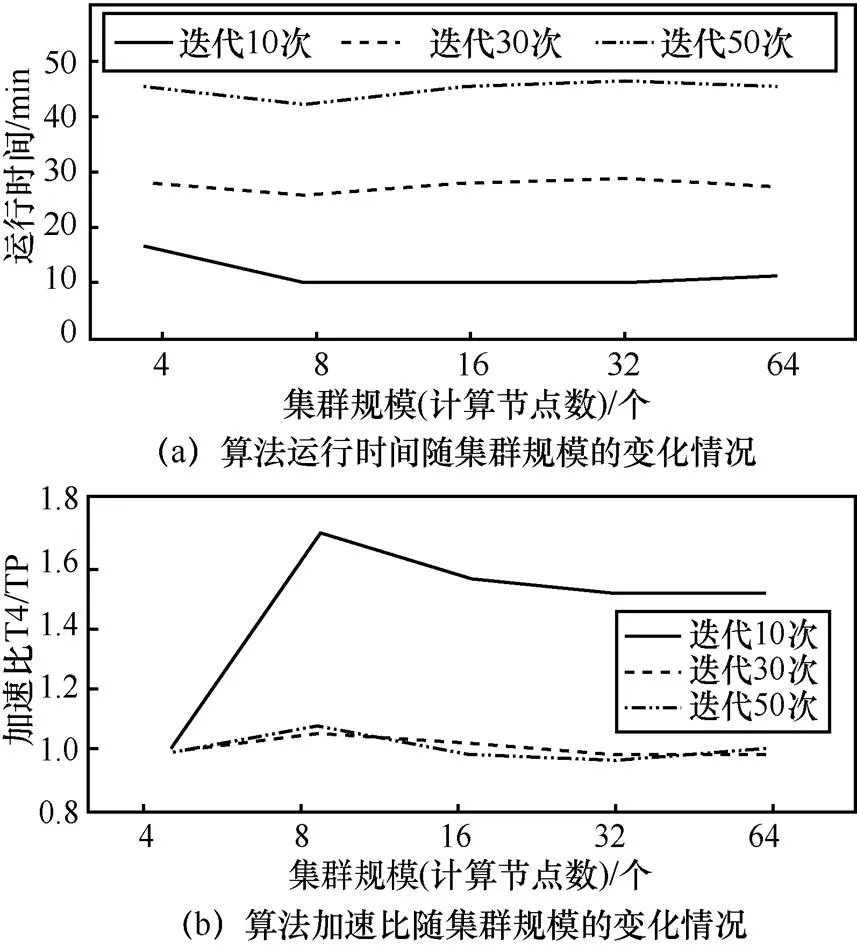
圖4 Mahout LDA算法百萬級別下的測試
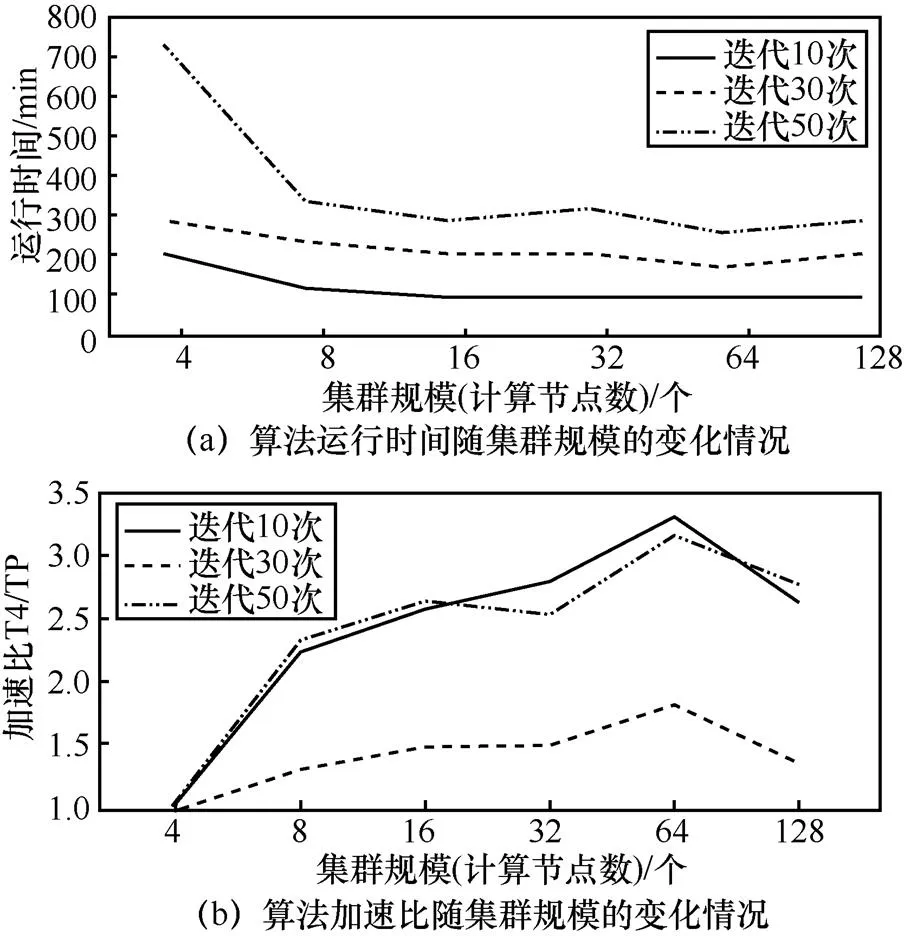
圖5 Mahout LDA算法千萬級別下的測試
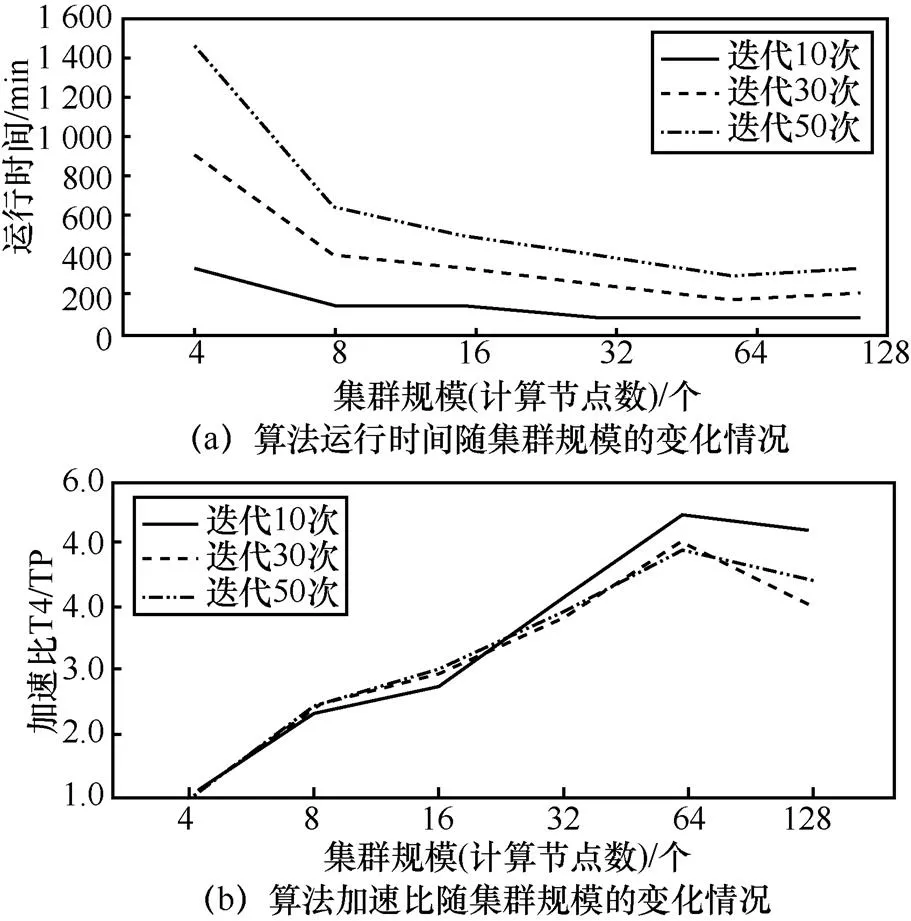
圖6 Mahout LDA算法億級別下的測試
2) 數據規模:在相同條件下,數據規模越大,算法的運行時間越長,加速比越大。即隨著數據規模的增加,雖然運行時間相應變長,但分布式實現帶來的優勢也越顯著。
3) 迭代次數:與MrLDA算法類似,隨著迭代次數的增加,運行時間呈現大幅度增長。而在不同數據規模、不同集群規模、不同迭代次數下,Mahout LDA算法均未達到收斂。
5.3 Spark LDA算法性能
由于Spark LDA算法的普遍執行時間較短,因此對于該算法的實驗是從服務器節點數量為1時開始測試的。這里分別展示了Spark LDA算法在百萬、千萬、億級別的數據規模,不同迭代次數和不同集群規模下的運行時間和加速比,如圖7~圖9所示。
1) 集群規模:Spark LDA在百萬、千萬、億級別數據規模上,均在4臺服務器節點處運行時間最短,加速比最大。由于在3種數據規模級別下,該算法均過早出現了性能的“瓶頸”,因此只測試到32臺服務器節點規模。
2) 數據規模:隨著數據規模的增加,執行時間呈量級增加趨勢。千萬級數據以下時間可以控制在30 min內,億級別數據的時間消耗明顯與百萬級別數據和千萬級別數據不在一個量級上。這應該是與算法的并行框架——Spark有關,該框架將中間結果寫入內存,隨著數據規模的增大,中間結果也大幅度增加,內存無法負荷,所以時間呈現大規模增加趨勢。在3種數據規模下,Spark LDA的加速比均在0.7~1.3這個較小區間變動,即并不是數據規模越大,分布式實現的優勢越明顯,而是整體上保持穩定。

圖7 Spark LDA算法百萬級別下的測試
3) 迭代次數:與Mahout LDA算法類似,隨著迭代次數的增加,算法的運行時間呈現大幅度增長趨勢。而在不同數據規模、不同集群規模、不同迭代次數下,Spark LDA算法均未達到收斂,這也論證了該算法在每輪迭代完畢后更新模型,導致收斂速度較慢的這個原理。
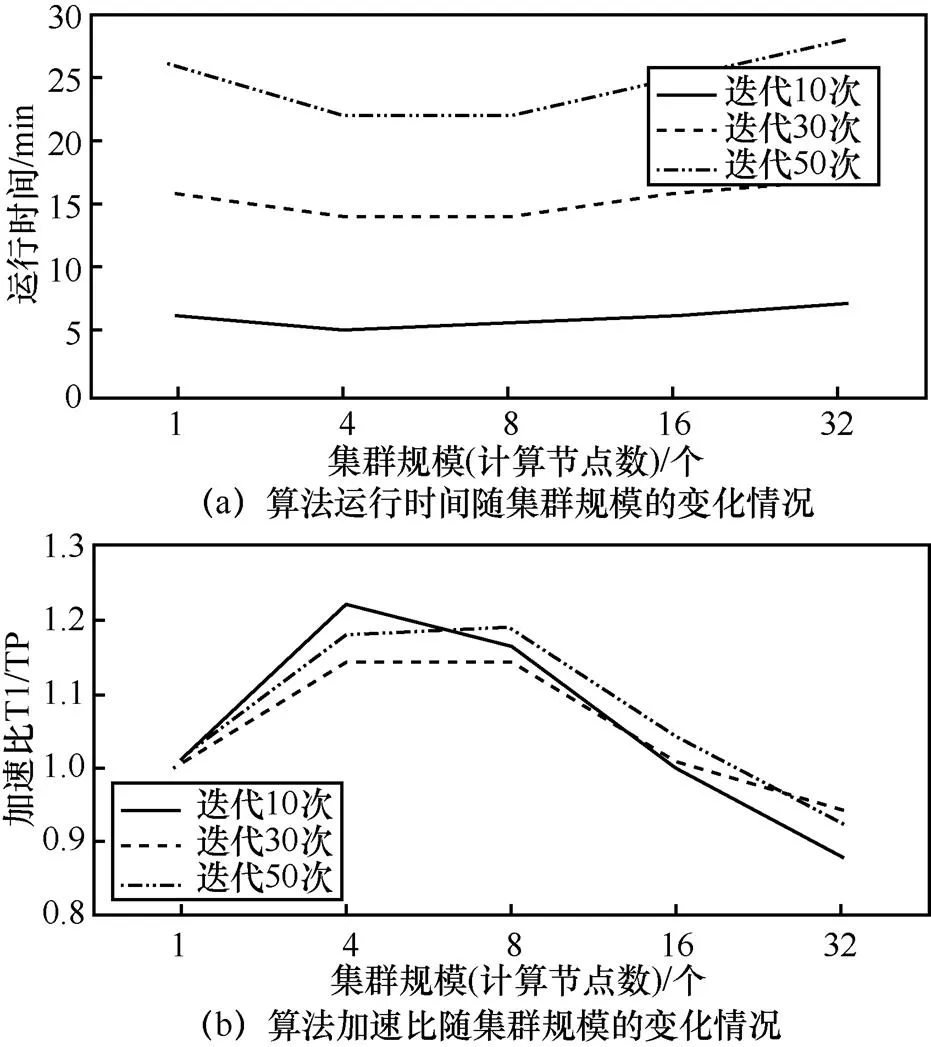
圖8 Spark LDA算法千萬級別下的測試

圖9 Spark LDA算法億級別下的測試
5.4 3種算法的分析對比
表1~表3分別展示在不同數據規模下,MrLDA、Mahout LDA和Spark LDA算法的運行時間,其中,加粗數值表示在當前條件下,算法可以達到收斂狀態。
3種算法基于的并行框架不同,在一定程度上可以很好地解釋實驗結果。MapReduce框架在復雜的挖掘算法中往往需要多個MapReduce作業才能完成,多個作業之間存在著冗余的磁盤讀寫開銷和多次資源申請過程,使基于MapReduce的算法實現存在嚴重的性能問題,MrLDA算法和Mahout算法都基于MapReduce框架,這就使在相同條件下,2種算法的運行時間均處于較大數量級,如當數據規模為百萬級別,集群規模為16個節點,迭代次數為30時,MrLDA算法的運行時間達到220.90 min,Mahout LDA算法的運行時間達到27.20 min,如表1所示。
Spark框架得益于其在迭代計算和內存計算上的優勢,可以自動調度復雜的計算任務,避免中間結果的磁盤讀寫和資源申請過程,在一定程度上提高了算法的性能。Spark LDA基于Spark框架,由于它將中間結果寫入內存,因此運行時間處于較小數量級,同樣是在數據規模為百萬級別,集群規模為16個節點,迭代次數為30的條件下,Spark LDA的運行時間僅為3.40 min,如表1所示。但是隨著數據規模的增加,內存沒有辦法負荷,所以它的時間呈大幅度上升趨勢,例如,在迭代次數為50的條件下,Mahout LDA算法在億級別和千萬級別下的運行時間比值較小,而Spark LDA算法在億級別和千萬級別下的運行時間比值呈現大規模增長趨勢,如表2和表3所示,這充分說明Spark LDA算法在巨大規模數據處理上的劣勢。

表1 MrLDA、Mahout LDA和Spark LDA在不同集群規模和迭代次數下的運行時間
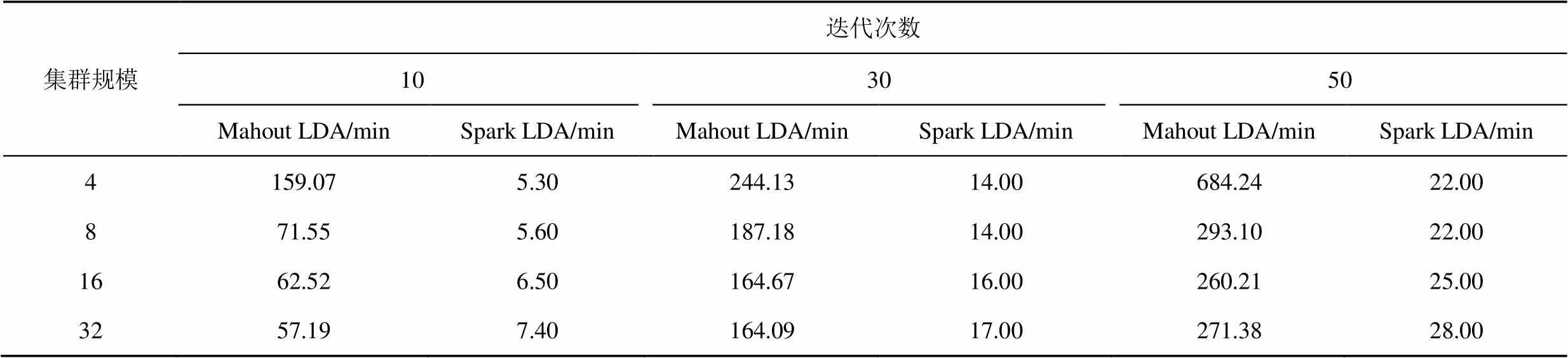
表2 千萬級別下Mahout LDA和Spark LDA在不同集群規模和迭代次數下的運行時間
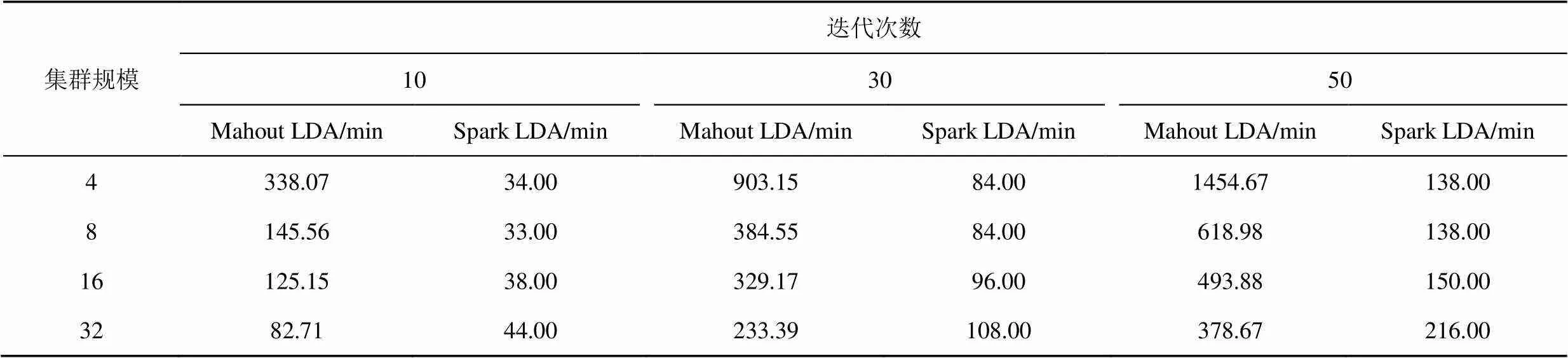
表3 億級別下Mahout LDA和Spark LDA在不同集群規模和迭代次數下的運行時間
在參數推導方面,MrLDA、Mahout LDA和Spark LDA分別基于變分方法、變分方法和Gibbs采樣方法。變分方法既能推斷隱變量,也能推斷未知參數,其難點在于公式演算比較復雜,和Gibbs采樣方法相比,其具有不易計算但運行效率高的特點。而Gibbs采樣方法的特點是容易計算但速度慢。MrLDA基于變分方法,所以其運行效率應該最高,但是由于每一輪迭代后都會更新超參數并計算相應的Likelihood,在一定程度上影響了算法的執行時間。Spark LDA基于Gibbs采樣方法,本來計算時間應該相對較長,但是其主要在內存中完成,節省了大量中間結果的磁盤讀寫時間,所以時間反而相對較快。
在數據規模方面,隨著數據規模的增大,增加計算節點數量,算法的運行時間會相應減少,且數據規模越大,效果越明顯。然而不同算法自身原理并不相同,對應數據規模的適用情況也會有所區別:MrLDA由于自身算法的局限,沒有基于內存消耗做優化處理,因此實際能夠處理的數據量有限,在處理超過百萬級別規模數據時存在問題。Mahout LDA隨著數據規模增大,時間增長幅度較小,比較適合處理大規模數據。例如,在集群規模為32,迭代次數為30的條件下,Mahout LDA算法在千萬級別下的運行時間為164.09 min,億級別下的運行時間為233.39 min,增長幅度較小,如表2和表3所示。Spark LDA隨著數據規模增大,時間增長幅度較大,在億級數據規模上相較前2種算法仍存在較小的運行時間優勢,但是不適合處理超過億級別的數據,而在百萬規模和千萬規模上優勢明顯,更適合處理千萬級規模以下數據。例如,在集群規模為32,迭代次數為50的條件下,SparkLDA在百萬數據規模和千萬數據規模的運行時間遠小于Mahout LDA,而在億數據規模下的運行時間優勢顯著減小,時間量級明顯增加,如表1~表3所示。
在迭代次數方面,迭代次數與算法的運行時間呈線性相關。迭代次數太少會導致模型尚未收斂,影響話題的質量,而迭代次數越大,其計算的資源消耗越高,運行時間也會越長。MrLDA算法在百萬數據規模,50次迭代設置下出現收斂,對應的話題發現質量較好,而其他情況均未出現收斂,在一定程度上影響了算法話題發現的質量,如表1所示。
在集群規模方面,在相同迭代次數和數據規模下,隨著集群規模的增加,不同算法的運行時間出現先大幅降低后減少速率逐漸變緩,直至基本無變化或呈上升趨勢,而加速比呈現先增加后基本無變化或呈下降趨勢,且不同算法對應的拐點出現有所不同。這是因為在處理大規模數據時,當前現有的主流算法存在著瓶頸,當集群規模達到一定數量時,再增加計算節點也無法提高算法的性能。這在MrLDA、Mahout LDA和Spark LDA算法中均有體現,例如,MrLDA算法的加速比在百萬級別的32節點出現拐點;Mahout LDA算法的加速比在百萬級別的8節點出現拐點,在千萬級別和億級別的64節點出現拐點;Spark LDA算法的加速比均在百萬、千萬、億級別的4節點出現最優值。
分布式話題模型的訓練在最近幾年得到越來越多研究者的關注,涌現了一大批相關模型。AliasLDA針對Gibbs采樣過程進行優化,基于Alias Table使個話題的采樣時間復雜度由原來的()降低到(1)。LightLDA則針對采用的分布進行修改,將原來建立在話題上的詞匯、文檔聯合分布變為2個獨立的采樣過程且交替進行,分別只與詞匯和文檔相關。WarpLDA做了更多的工程級別的優化,讓LightLDA更快。LDA* 則解決了頑健的采樣性能以及詞分布傾斜這2個難題,取得了更好的性能。LDA* 構建于騰訊開源的系統Angel之上,得益于Angel開放的參數服務器架構、良好的擴展性以及優秀的編程接口設計,它可以輕松處理TB級別的數據和十億維度的話題模型。這些都是近幾年比較有代表性的分布式話題模型,也是以后分布式話題模型測試的努力方向。
6 結束語
本文針對社交網絡中的話題發現問題,在簡單介紹了MrLDA、Mahout LDA和Spark LDA算法基本原理的基礎上,測試了這3種典型分布式算法在面向不同數據規模、不同迭代次數、不同集群規模條件下的運行時間和加速比,并給出了不同情況下3種算法的數據規模適用性、迭代次數的設置以及集群規模的建議,由此可以為實際應用場景下,不同的現實需求選取較優算法提供參考。下一步,將面向評價指標——困惑度,從話題質量的角度分析各個算法的優劣。
[1] 中國互聯網絡信息中心. 第41次《中國互聯網絡發展狀況統計報告》[R]. 2018. China Internet Network Information Center. The 41th statistical report on Internet development in China[R]. 2018.
[2] DHILLON I S, MODHA D S. Concept decompositions for large sparse text data using clustering[C]//Machine Learning. 2001:143-175.
[3] KUMMAMURU K, DHAWALE A, KRISHNAPURAM R. Fuzzy co-clustering of documents and keywords[C]//The IEEE International Conference on Fuzzy Systems. 2003:772-777.
[4] ZHAO Y, KARYPIS G. Soft clustering criterion functions for partitional document clustering:a summary of results[C]//Thirteenth ACM International Conference on Information & Knowledge Management. 2004: 246-247.
[5] MAKKONEN J, AHONENMYKA H, SALMENKIVI M. Topic detection and tracking with spatio-temporal evidence[C]// European Conference on Ir Research. 2003: 251-265.
[6] WU C, WANG B. Extracting topics based on Word2Vec and improved jaccard similarity coefficient[C]//IEEE Second International Conference on Data Science in Cyberspace. 2017: 389-397.
[7] HOFMANN T. Probabilistic latent semantic indexing[C]//International ACM SIGIR Conference on Research and Development in Information Retrieval. 1999: 50-57.
[8] BLEI D M, NG A Y, JORDAN M I. Latent dirichlet allocation[J]. J Machine Learning Research Archive, 2003, 3:993-1022.
[9] STEYVERS M , GRIFFITHS T. Probabilistic topic models[J]. Handbook of Latent Semantic Analysis, 2007, 427(7): 424-440.
[10] BLEI D, CARIN L, DUNSON D. Probabilistic topic models[C]//ACM SIGKDD International Conference Tutorials. 2011: 1.
[11] BERNHARD S, JOHN P, THOMAS H. A collapsed variational bayesian inference algorithm for latent dirichlet allocation[C]//The Twentieth Conference on Neural Information Processing Systems. 2006:1353-1360.
[12] GRIFFITHS T L, STEYVERS M. Finding scientific topics[J]. National Academy of Sciences of the United States of America, 2004: 5228-5235.
[13] RAMAGE D. Characterizing microblogs with topic models[C]// International AAAI Conference on Weblogs and Social Media. 2010:130-137.
[14] CHEN Z, LIU B. Mining topics in documents:standing on the shoulders of big data[C]//ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2014: 1116-1125.
[15] LIN T, TIAN W, MEI Q, et al. The dual-sparse topic model:mining focused topics and focused terms in short text[C]//International Conference on World Wide Web. 2014:539-550.
[16] ZHAI K, BOYD G J, ASADI N, et al. MrLDA:a flexible large scale topic modeling package using variational inference in MapReduce[C]// International Conference on World Wide Web. 2012:879-888.
[17] ARONSSON F. Large scale cluster analysis with Hadoop and Mahout[J]. Technology & Engineering. 2015.
[18] MENG X R, BRADLEY J, BURAK Y, et al. MLlib: machine learning in apache spark[J]. Journal of Machine Learning Research, 2015, 17(1):1235-1241.
Performance analysis of topic detection algorithms in distributed environment
DENG Lu1, JIA Yan1, FANG Binxing2, ZHOU Bin1, ZHANG Tao1, LIU Xin1
1. College of Computer, National University of Defense Technology, Changsha 410073, China 2. College of Computer, Beijing University of Posts and Telecommunications, Beijing 100876, China
Social network has become a way of life, therefore more and more people choose social network to express their views and feelings. Quickly find what people are talking about in big data gets more and more attention. And a lot of related methods of topic detection spring up in this situation. The performance analysis project was proposed based on the characteristics of social network. According to the project, the performances of some typical topic detection algorithms were tested and compared in large-scale data of Sina Weibo. What’s more, the advantages and disadvantages of these algorithms were pointed out so as to provide references for later applications.?
topic detection, distributed environment, social network, performance analysis
TP391
A
10.11959/j.issn.1000?436x.2018136
鄧璐(1989?),女,湖北松滋人,國防科技大學博士生,主要研究方向為社交網絡分析、數據挖掘、復雜網絡等。

賈焰(1960?),女,四川成都人,國防科技大學教授、博士生導師,主要研究方向為社交網絡分析、信息安全等。
方濱興(1960?),男,江西萬年人,中國工程院院士,北京郵電大學教授、博士生導師,主要研究方向為計算機體系結構、計算機網絡與信息安全。
周斌(1971?),男,江西南昌人,國防科技大學教授、博士生導師,主要研究方向為社交網絡分析、信息安全等。
張濤(1993?),女,湖南常德人,國防科技大學碩士生,主要研究方向為社交網絡分析。
劉心(1993?),女,湖南長沙人,國防科技大學碩士生,主要研究方向為社交網絡分析。
2017?11?08;
2018?07?03
國家自然科學基金資助項目(No.61502517, No.61472433, No.61732004, No.61732022);國家重點研發計劃課題基金資助項目(No.0708068118002, No.2017YFB0803303)
The National Natural Science Foundation of China (No.61502517, No.61472433, No.61732004, No.61732022), The National Key Research and Development Program of China (No.0708068118002, No.2017YFB0803303)
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
