位置數據稀疏約束下的疑犯時空位置預測
2018-09-13 09:02:34黨蘭學朱欣焰
鄭州大學學報(工學版) 2018年5期
段 煉, 黨蘭學, 李 銘, 高 超, 朱欣焰
(1.廣西師范學院 地理科學與規劃學院,廣西 南寧 530001; 2.廣西師范學院 北部灣環境演變與資源利用教育部重點實驗室,廣西 南寧 530001; 3.河南大學 計算機與信息工程學院,河南 開封 475001; 4.南昌大學 空間科學與技術研究院,江西 南昌 330031; 5.警用地理信息技術公安部重點實驗室,江蘇 常州 213000; 6.武漢大學 測繪遙感信息工程國家重點實驗室,湖北 武漢 430079)
0 引言
疑犯位置預測對探明疑犯作案時空規律、評估案發位置與疑犯關聯性等警務需求有重要的應用價值[1].但由于位置探測源(如旅店登記系統、進出港登記系統、ATM機等)數量和類型有限,警方僅能獲取到他們稀疏的位置數據[2],嚴重影響了疑犯位置預測的準確性.在犯罪地理學中,已有研究基于犯罪個體的系列犯罪位置序列,基于平均作案距離[3]、路網結構[4],利用距離衰減函數[4]、貝葉斯公式[5]和動力學模型[6]等,估算錨點(住址或未來犯罪地點等)[7]在空間上的出現概率.然而,這些研究既沒有考慮數據稀疏性的影響[8],也極少考慮時間因素.近年來,基于車輛定位數據[9]、Wi-Fi信號[10]、公共交通數據[11]、人員軌跡數據[12]和地理社交網絡check-in數據[13]等的位置預測成為研究熱點.然而,疑犯位置數據較這些數據更加稀疏,也不存在好友關系等數據以提高預測精度.為應對以上挑戰,筆者融合疑犯群體的統計先驗知識和社會環境信息,基于張量聯合分解方法來估算疑犯在所有時空節點上的駐留概率.
1 問題描述
疑犯位置數據集包括了W市2012年1月至2012年6月間241名疑犯的18 754個軌跡點.將研究區域網格化,獲得g×g格網,G={p1,p2,…,pi,…,pg×g}.本文中g=100,每個網格覆蓋的范圍約為256 m×224 m[9].如圖1所示.
利用各時段(筆者將一天劃分為12個時段,每個時段為2小時)不同疑犯在各網格上的駐留次數,構建三維張量Q∈U×G×T,表達“疑犯-位置-時段”的相互關系,如圖2所示.其中,U為疑犯數量;G為網格數量;T為時段數量.由于疑犯位置數據的稀疏性,Q中僅有1%的項才具有數值.因此,需解決的問題是:估算Q內所有缺失項.

圖1 網格化后的疑犯空間分布強度Fig.1 Spatial distribution of suspects visiting density
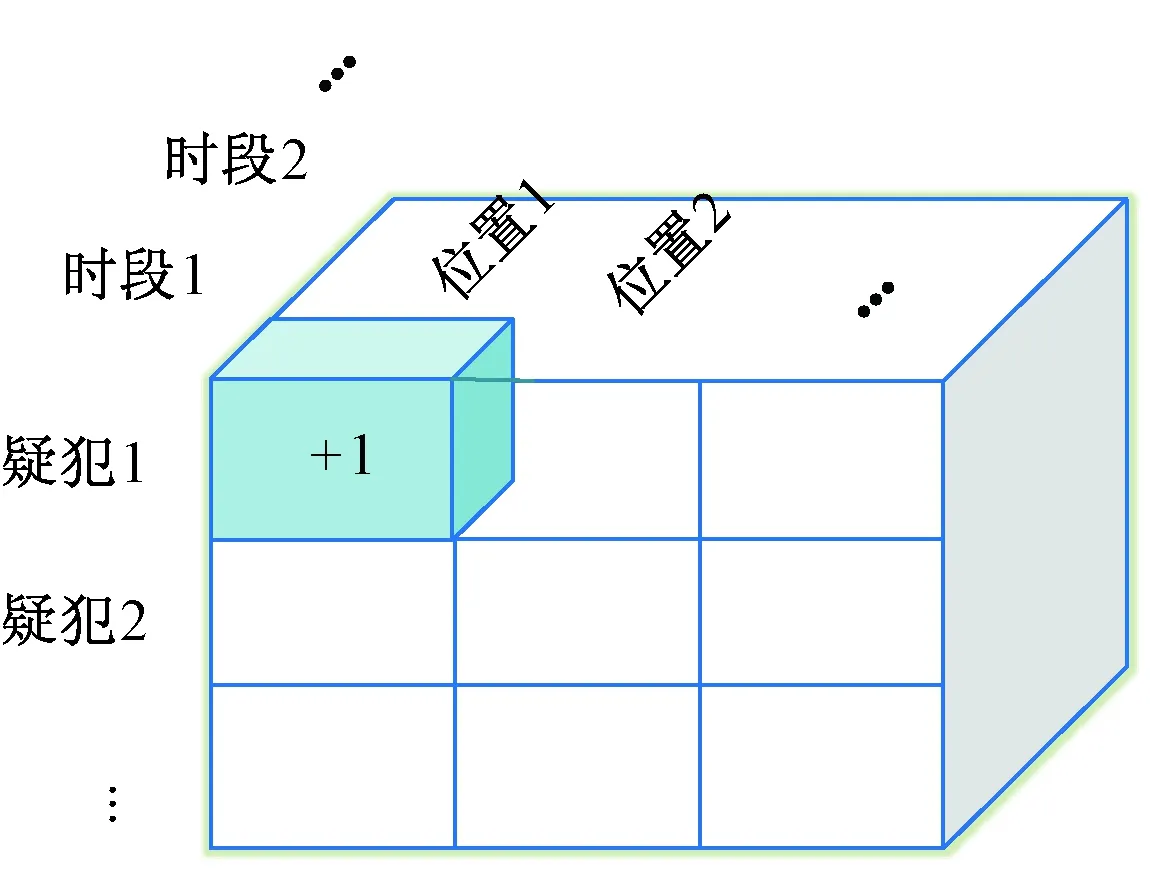
圖2 “疑犯-位置-時段”張量Fig.2 “Suspect-location-time” tensor
2 系統流程
本方法具體流程如圖 3所示.首先,構建“疑犯-位置-時間”張量Q.其次,抽取所有疑犯在不同時空節點駐留的統計信息,構建“疑犯-位置”矩陣與“位置-時間”矩陣,表達疑犯對各時空節點的訪問模式.再將人口、路網和POI等信息按照網格尺度匯集,形成“位置-特征”矩陣,并利用出租車軌跡數據構建“位置-位置”矩陣,通過這兩個矩陣描述位置間的關聯性.最終,對以上張量和矩陣進行協同分解,計算出“張量Q中的缺失值”,實現疑犯個體的時空預測.
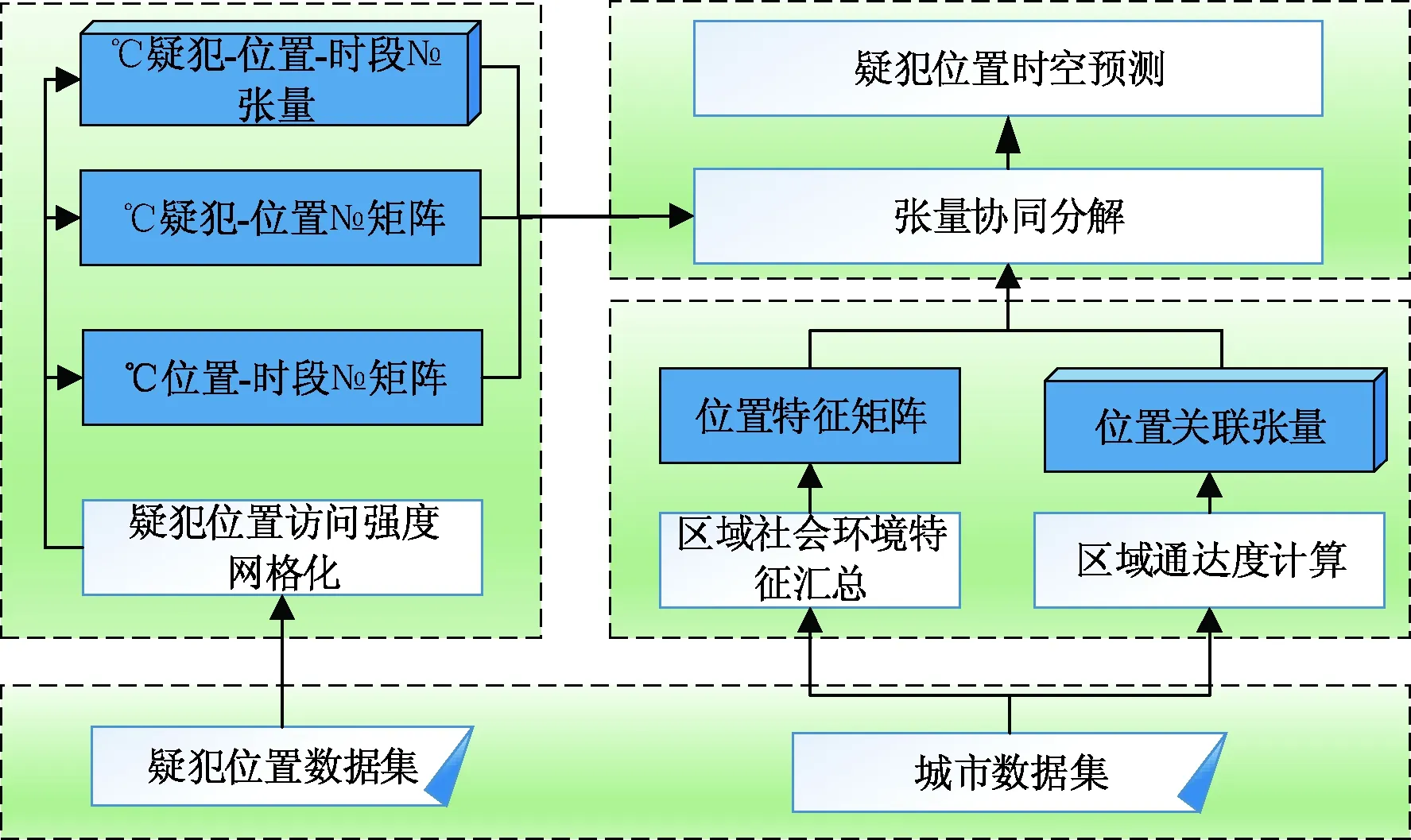
圖3 系統架構圖Fig.3 System architecture
2.1 疑犯群體的位移特征抽取
基于疑犯位置數據,構建“疑犯-位置”矩陣E∈U×G,其中,U為疑犯總數;G為網格總數.該矩陣刻畫各疑犯的全局空間分布模式.
為獲得所有疑犯的全局時空分布模式,構建“位置-時間”矩陣D∈G×T,其中,G表示位置數量;T表示一天內的所有時段數量.D中第i行和第j列的項D(i,j)表示所有疑犯在j時段訪問i位置的次數.
2.2 位置特征抽取
2.2.1 位置-特征矩陣
具有類似社會經濟環境的區域往往對疑犯具有類似的吸引力.筆者涉及的社會經濟環境信息包括4個部分:POI特征集Fp、路網特征集Fr、房屋特征集Fb和人口統計特征集Fc.據此,構建“位置-特征”矩陣C∈G×(p+r+b+c),其中,G表示位置總數;p、r、b和c分別表示Fp、Fr、Fb和Fc集的特征個數.特別的,對于category 類型的屬性,將其轉變為1和0表示的one-hot向量結構.
①POI特征.POI特征Fp包括:該位置內POI的空間密度以及12個類型的POI數量共13個特征.為體現區域獨有的社會經濟環境特性.借鑒TF-IDF方法,將位置i中類型為j的POI數量qij轉換為POI類型重要度Yij,
(1)
其中,o為POI類型數量;|G|表示位置總數;|{qi:qij> 0}|表示具有POI類型j的位置個數.
②路網特征.路網特征Fr包括:該位置內的路口數量和5個等級(高速公路、一級公路、二級公路、三級公路及四級公路)的道路長度,共6個指標.
③建筑物特征.筆者抽取的房屋特征Fb包括:樓房密度、5類房屋(住宅型、商業性、行政型、工業型、其他)的數量分布、3類高度(低層、多層、高層)房屋的數量分布,共9個指標.
④人口統計特征.人口統計特征Fc涉及10個指標,分別是人口密度、4個年齡段(18歲以下、18~40歲、40~60歲、60歲以上)的人口數量分布、5類教育程度(文盲、初中、高中、大學、研究生)的人口分布.
2.2.2 位置可達性張量
位置間的空間鄰近性和通勤強度體現了位置之間的疑犯轉移傾向或流動的便捷程度.下面利用出租車數據表達位置間的時態通勤強度,再結合空間鄰近性,計算位置間的時空可達度.

(2)
基于上式,構建張量P∈T×G×G,將ptij作為P中的項,得以刻畫位置和位置之間的空間可達度.
3 多源數據融合下的張量分解
結合矩陣因子分解和張量因子分解方法計算出Q中的所有缺失項,以獲取疑犯個體在任意時空節點的駐留概率.張量Q可因此分解為:
Q≈S×U×J×T.
(3)
其中,核張量(core tensor)S∈du×dg×dt,疑犯低階潛在因子矩陣(low rank latent factors matrix)U∈U×du、位置低階潛在因子矩陣J∈G×dl和時間低階潛在因子矩陣T∈T×dt,du≤u,dl≤g,dt≤t(本文du=dl=dt).
“疑犯-位置”矩陣E可因此分解為U和JT的乘積,即:
E≈U×JT.
(4)
同理,“位置-時間”矩陣D≈J×TT, “位置-特征”矩陣C≈I×P(P∈dl×(p+r+c));位置可達性張量P≈W×J×JT, 其中W∈dl×dl×dt,dl≤G,dt≤T(本文中dl=dt).
可見,Q與E、D、C及P共享了潛在因子矩陣U、J和T;P也與E、D以及C共享了潛在因子矩陣J和T.依據這些信息交互關系,得到融合疑犯位移、社會經濟環境和位置可達性數據的張量因子分解目標函數:
L(Q,S,W,U,J,T,P)=
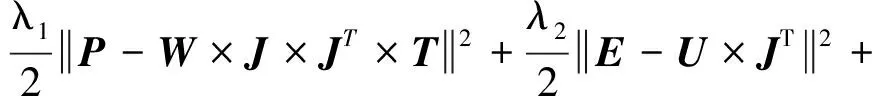
(5)
4 試驗與分析
試驗硬件配置為 Intel (R) Core (TM) i777003.6 GHz (4 核),16 GB內存的計算機,操作系統為Windows 7,軟件采用MATLAB2 016 a和TensorToolbox包[17].采用均方根誤差和top-k最近距離作為模型性能的評價指標,其中:均方根誤差(RMSE)為預測值與真實值之間的誤差累加均方根,
(6)
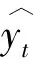
Top-k最近距離(SED@k):目標位置與前top-k個預測結果的最小距離.
(7)
該指標越小越好,本文中k=10.兩網格間的距離為它們的中心間距.
4.1 比較方法
筆者所提方法稱為TCDLP.Baseline方法.
①時態約束下的Kriging克呂格插值法(TK):基于每個時間槽內空間鄰近位置的訪問次數作為目標位置的訪問次數.
②層次Pitman-Yorprocess語言統計模型(HPHD):描述用戶在各位置上的語義時間訪問強度.該方法無法對未知位置建模.
③HOSVD[15]:僅對“疑犯-位置-時間”張量進行因子分解來獲取其缺失值.
試驗采用交叉驗證,隨機從疑犯位置數據集抽取70%為訓練數據,20%位驗證數據,10%作為測試數據.
4.2 模型性能比較
TCDLP的參數λ1=λ2=λ3=λ4=λ5=0.05,各潛在因子數量k=10.表1為各模型在RMSE和SED@10上的性能.筆者提出的模型在這3個指標上都優于其他3種方法,說明融合多源城市社會經濟環境數據對疑犯時空節點估算是有效的.TK的各項指標性能值均為最差,說明在數據稀疏情況下,空間鄰近性還無法充分刻畫疑犯位置分布的時空模式.基于矩陣/張量分解的方法(如TCDM和HOSVD)的各項性能指標均超過了TK,這表明,位置間的環境相似性能為疑犯時空分布模式的挖掘提供有效信息.由于HPHD給出的結果為概率形式,因此無法對其進行RMSE指標測試.

表 1 各模型的預測性能
4.3 TCDLP參數影響分析
讓λ1~λ5在0~10變化,觀察TCDLP方法在RMSE和SED@10兩個指標的變化,如圖4所示.驗證各外部環境信息E、D、C和P對疑犯位置預測性能的影響.由圖4可知,集成了外部環境信息后,模型預測性能有了較大提升,RMSE和SED@10的變化較大;但隨著各參數的增加,相對于RMSE、SED@10的變化幅度不大,這再次驗證了疑犯的社會活動趨向于集聚性.隨著λ3的增加, 模型的RMSE和SED@10都有明顯提升,說明位置間的社會環境相似性對疑犯社會移動具有顯著的影響.然而,一旦λ4和λ5增加到一定數值,模型的RMSE急速下降,SED@10也有一定的上升,這可能是疑犯位置關聯性數據中存在噪聲,λ4和λ5的增加放大了這樣的噪聲,造成模型性能降低.

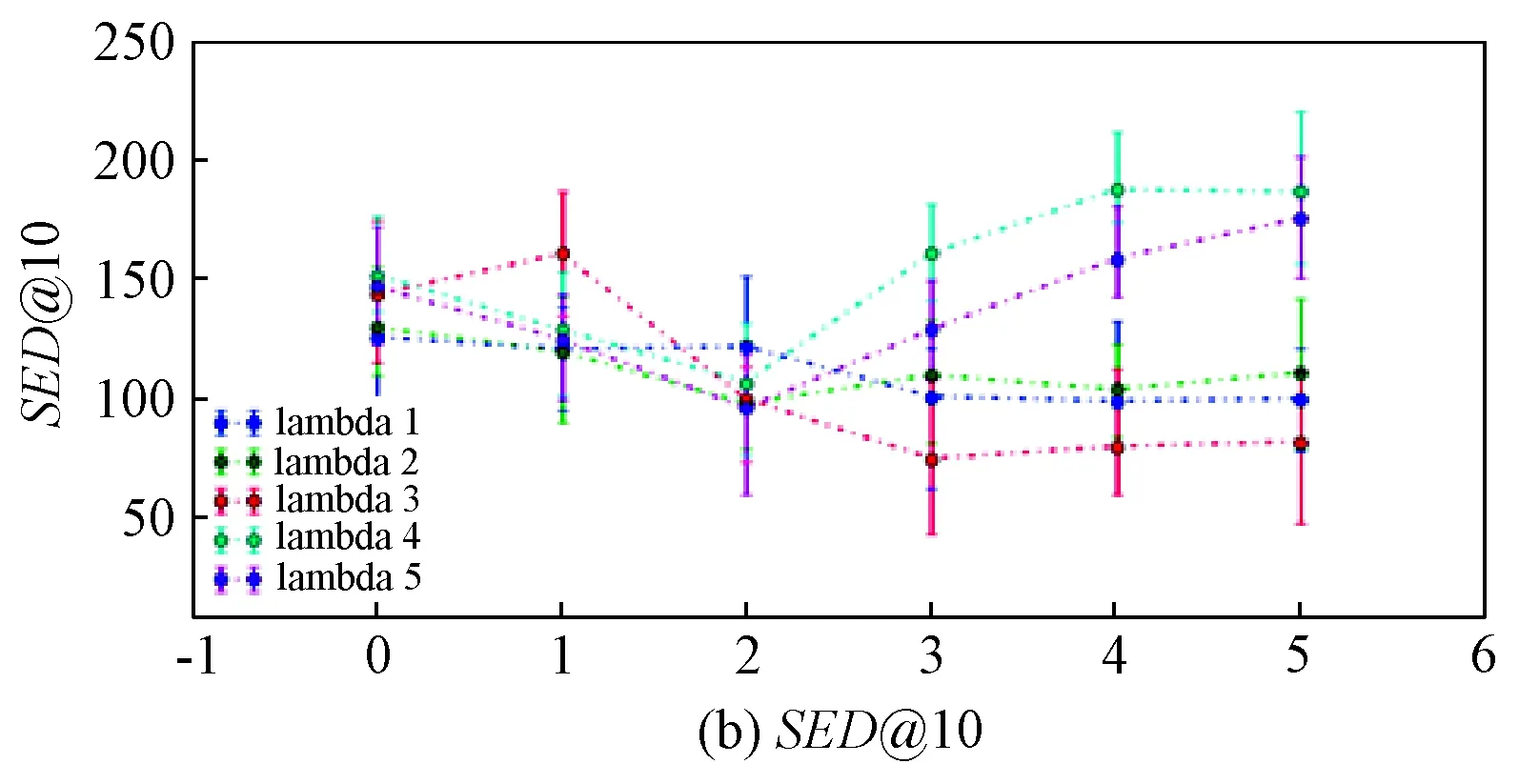
圖4 λ1~λ5對RMSE和SED@10的影響Fig.4 Impact of λ1~λ5 on RMSE and SED@10
5 結論
提出基于張量協同分解模型估算疑犯的潛在時空分布概率算法.該算法引入社會環境信息,通過張量和矩陣的聯合分解估算疑犯位置時空分布,緩解了疑犯位置數據的稀疏性.基于真實疑犯位置跟蹤數據的實驗結果表明,筆者所提算法在RMSE和SED@10兩個指標上分別平均高于其他baseline方法50%和18%.今后的工作將對疑犯進行分類,如盜竊類、搶劫類等,針對不同犯罪類型特點設計算法,進一步提高算法的精度.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
