基于自動編碼器和SVM的軸承故障診斷方法
2018-09-13 09:02:34雷文平吳小龍陳超宇林輝翼
鄭州大學學報(工學版) 2018年5期
雷文平, 吳小龍, 陳超宇, 林輝翼
(鄭州大學 機械工程學院 振動工程研究所,河南 鄭州 450001)
0 引言
基于SVM的軸承故障診斷本質上是一種模式識別.SVM作為一種經典的分類器,不斷地被優化并應用于各種生物信息學、模式識別等問題中[1].Mohammed等提出了基于自適應群體智能(self-adaptive cohort intelligence, SACI)算法的特征選擇和SVM模型選擇的混合方法,以減小特征冗余從而降低分類計算復雜度,提高SVM的準確性.姚亞夫等[2]將軸承振動信號EMD后得到的瞬時能量熵用于SVM的分類診斷,經過實驗驗證,該方法能夠有效地識別軸承正常狀態、內圈故障、外圈故障以及滾珠故障.
從文獻[1,2]可以看出,為了提高識別、診斷能力,提取到合理、明顯的故障特征是運用SVM進行分類的重要環節.最近,文獻[3]提出了一種基于多目標優化(multi-objective optimization, MO)的EMD方法,任子暉等[4]將局部均值分解(local mean decomposition, LMD)加以改進,都取得了更好的特征提取效果.HUANG等[5]運用各階本征模函數(intrinsic mode function, IMF)的時頻熵(time-frequency entropy)實現了對原信號能量分布的準確描述.此外特征提取也可以通過神經網絡實現,神經網絡能夠靈活地處理數據,在模式識別、分類、預測等方面被廣泛地應用,在處理工業大數據方面有廣闊的應用前景[6],使機械的故障診斷更加智能化.其中自動編碼器(auto-encoder,AE)作為一種無監督的自學習網絡,實現了信號的重構與特征提取,三層網絡結構使得輸出層的編碼矢量成為輸入層數據的特征表示[7].Hinton等[8-9]提出由深度學習(deep learning, DL)理論構建的DNN,就是先將多個無監督學習的AE串聯,構成DNN的多層網絡框架進行數據特征提取;然后通過誤差反向傳播(back propagation, BP)算法的有監督學習,對上述各層AE進行參數調整,使整個DNN具備識別、診斷能力[10].
AE的應用是DL中的重要組成部分.神經網絡中的AE隱含層是一個編碼器加上一個解碼器,輸入數據經過隱含層的編碼和解碼,到達輸出層時,確保輸出的結果盡量與輸入數據保持一致.這樣做使得維度較低的隱含層能夠抓住輸入數據的特點,使其特征保持不變.筆者根據AE本身的特點將DAE與SVM相結合,以提高SVM在軸承故障診斷中的識別能力,并與運用軸承振動信號各階IMF能量熵來進行SVM的故障診斷效果對比,體現本方法的優越性.
1 相關技術原理
1.1 AE原理
AE的結構如圖1所示,分為編碼網絡(coding network)與解碼網絡(decoding network).
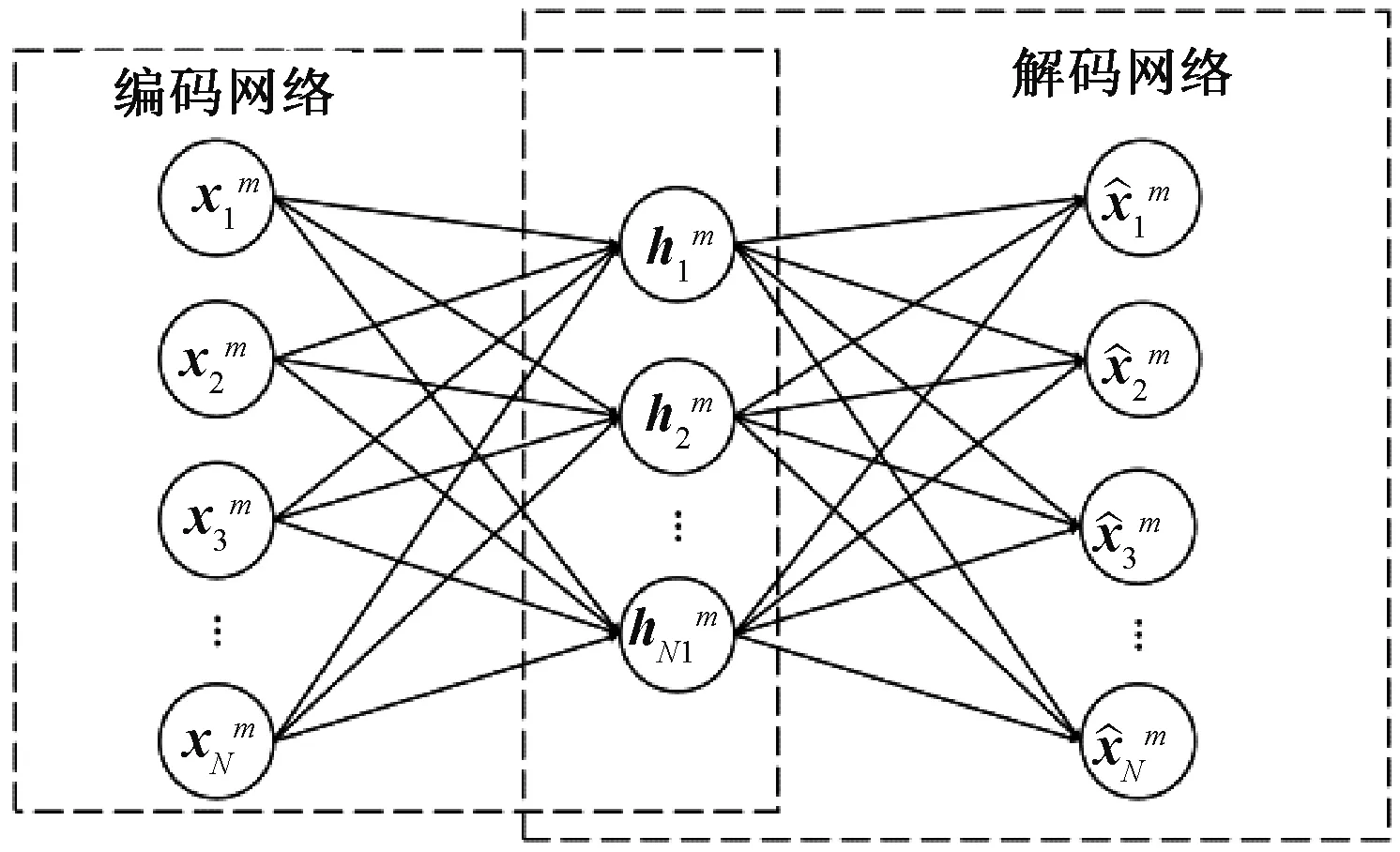
圖1 AE結構圖Fig.1 Structure of AE
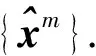
hm=f(Wxm+b),
(1)
對特征提取結果hm進行反編碼可得:
(2)
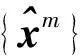
(3)
式中:f、g分別是編碼網絡和解碼網絡的激活函數;{W,b}、{W′,d}是網絡對應的連接權值和偏置.上述訓練過程的目的是得到{W,b},用以實現對任意高維向量X,提取到其特征表示H,
H=f(WX+b).
(4)
1.2 多層DAE結構
考慮到實際應用中的復雜情況,為了進一步增加AE學習的魯棒性,將用于重構學習的一部分數據隨機添加符合一定統計特征的噪聲,然后使得AE能夠根據噪聲的特點估計出沒有添加噪聲的原始數據,進而提高AE的抗干擾能力,這便是去噪自編碼器的核心思想[11].
向xm中加噪聲,可以是將其中的一部分數據隨機置零,或者是按照二項隨機分布向xm中添加噪聲[12],含有噪聲的數據表示為x0m.則DAE的訓練目標調整為:
(5)
一個多層DAE的特征提取過程如圖2所示.
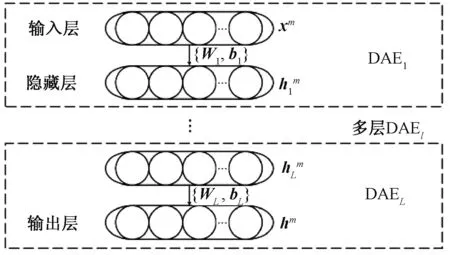
圖2 多層DAE的特征提取過程Fig.2 Feature extraction process of multi-layer DAE
在經過m組數據的迭代訓練后,獲得隱層權值W以及偏置b,便可用于多層DAE特征提取模型的參數初始化.多層DAE結構即是DNN最基本的結構框架(如圖2所示),它是由一系列訓練好的DAE編碼網絡實現的特征深度提取.其中第l層DAE特征提取過程為:
Hl=fl(WlHl-1+bl).
(6)
2 具體實施方式
2.1 特征提取的具體實施方式
運用多層結構的DAE網絡,通過無監督學習,實現了軸承運轉狀態的特征提取.即多層DAE特征提取是將該時刻軸承振動頻譜作為圖2中多層DAE網絡框架的輸入,依次對各層DAE依據圖1所述的方式進行參數回歸,最終得到該時刻的特征向量hm.
為了使提取到的特征具備很好的稀疏性,DAE的訓練目標可進一步演變為:
(7)
式中:k稀疏懲罰系數;hi表示DAE隱藏層第i個節點的輸出;ξ為一較小的常數,且稀疏控制條件為:
(8)
通過以上的改進,DAE提取特征的稀疏性得以保證,且不增加額外的訓練時間.多層DAE的建立及特征提取實現流程如圖3所示.
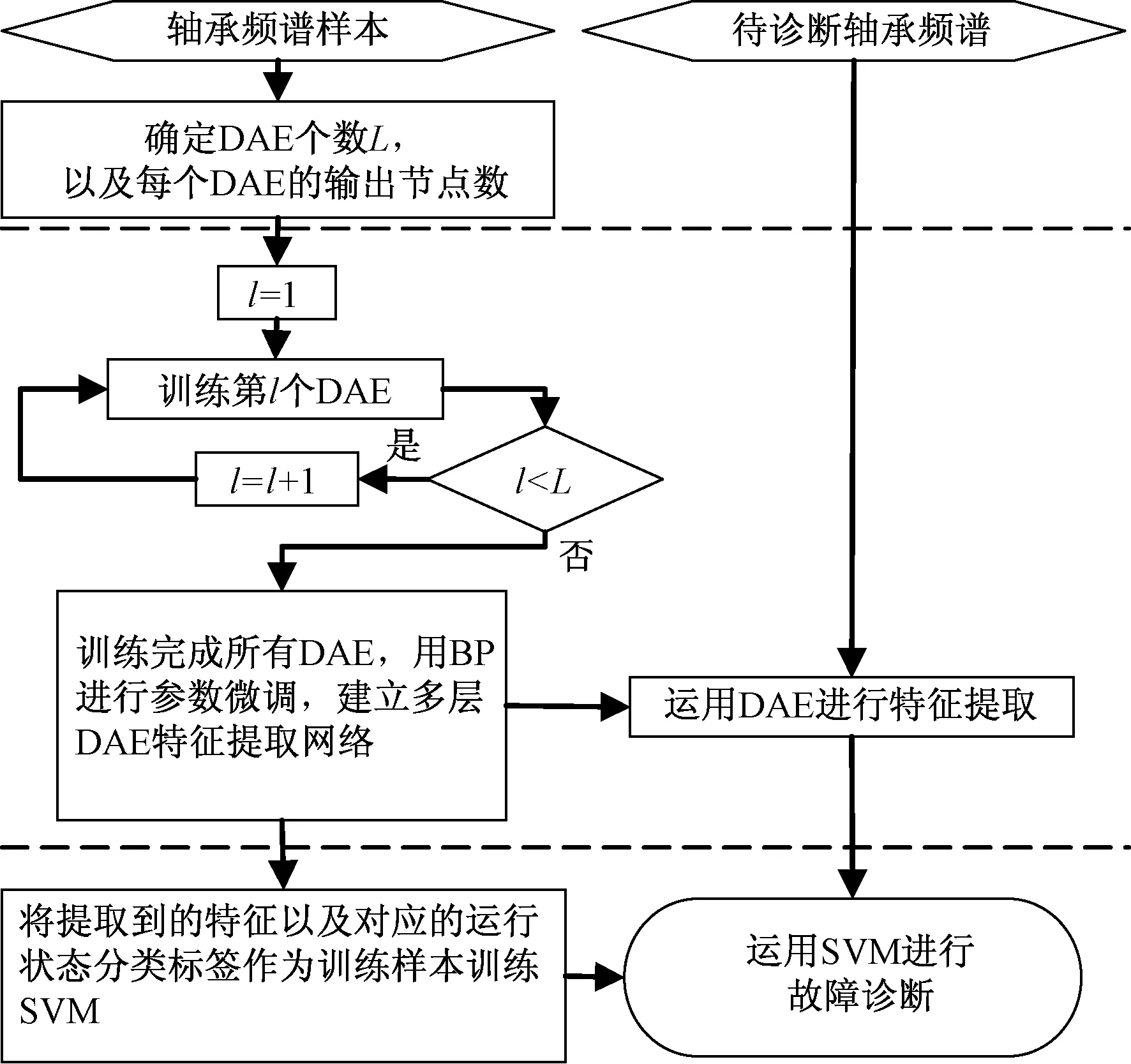
圖3 基于DAE的SVM軸承故障診斷流程圖Fig.3 SVM bearing fault diagnosis flowchart based on DAE
2.2 訓練SVM的具體實施方式
如圖3所示,軸承的狀態特征通過DAE提取出來后,接著被用于SVM的訓練和診斷.將這些特征作為訓練樣本,并將軸承的6種工作狀態按表1中的編號作為SVM的分類標簽,進行SVM的訓練,使之具有故障診斷的能力.

表1 SVM故障分類標簽
3 效果對比試驗
本試驗數據來自美國西儲大學軸承數據中心,以12 000 Hz為采樣頻率,采集電機驅動端軸承不同類型故障的信號.軸承故障程度不一,且電機轉速為1 730~1 797 rad/min.
隨機選取每種故障類型不同故障程度的振動信號.分別用EMD能量熵和DAE進行特征提取.其中EMD能量熵是指先將信號分解成為若干個IMF分量,設第i階IMF分量的能量為Ei,且令[13]:
(9)
則其能量熵為:
(10)
將各階IMF的能量熵作為軸承運轉狀態的表征,達到特征提取的目的,還可以通過剔除某些階的IMF分量以實現降噪和減少特征冗余.
選取相關性較強的前12階IMF分量的能量熵作為提取到的EMD能量熵特征向量;同樣地,運用上文提出的DAE將原信號頻譜進行特征自提取,為使兩種方法更具可比性,設定最后一層DAE的輸出節點(即上文中hm的長度)也為12.因此,得到每個故障信號的EMD能量熵特征、DAE提取特征均是維度為12的向量.
3.1 提取特征的直觀對比
為了直觀地觀察兩種方法提取到的各類故障特征聚集情況,對提取到的特征分別做主成分分析(principal component analysis, PCA),將緯度為12的特征向量轉換到三維坐標系中.分別如圖4、圖5所示.
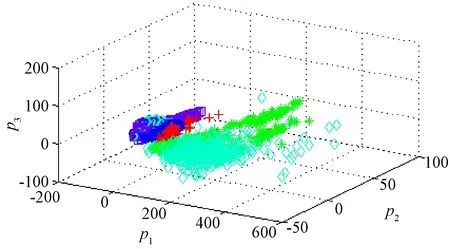
圖4 EMD能量熵特征提取分布Fig.4 Distribution of EMD energy entropy feature extraction
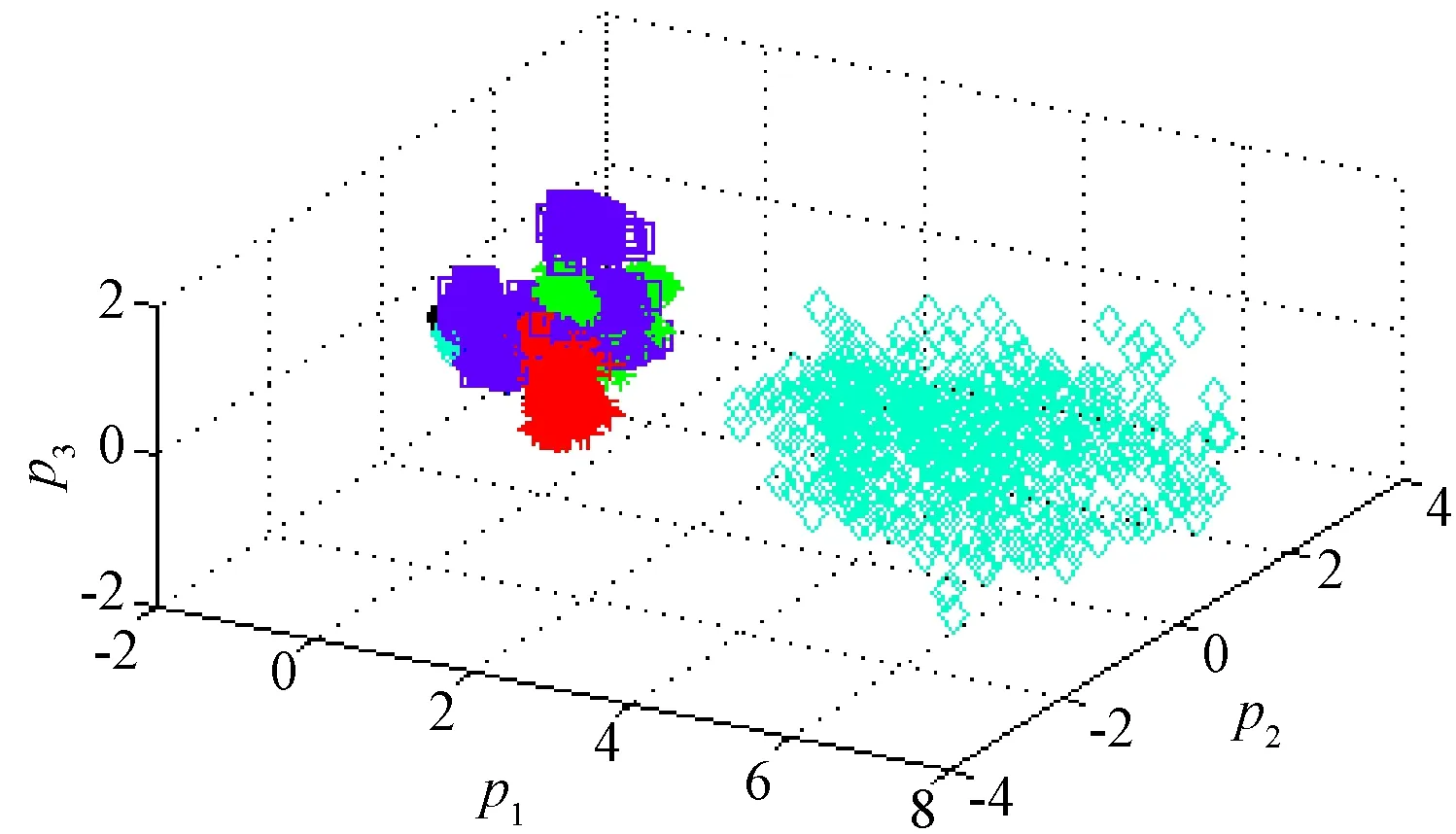
圖5 DAE特征提取分布Fig.5 Distribution of DAE feature extraction
由圖4、圖5可以看出,基于DAE特征提取的不同故障特征分布聚散情況較為分明(其中▽數據聚集在被其他數據遮擋著的另一側).在這兩種特征提取方法的基礎上,最終運用SVM分別實現等維空間內故障特征的分類.
3.2 故障診斷效果對比
先分別用兩種特征提取方式提取到的、包含了不同故障類型的600組12維(12×600)特征向量及其對應的故障類型標簽訓練SVM.再用兩種建立好的特征提取模型,實現6 100組代表軸承不同故障類型的測試數據特征提取,并根據提取到的6 100組故障特征(12×6 100)診斷其故障類型,對比結果見表2.

表2 不同特征提取方法的故障診斷效果對比Tab.2 Comparison of fault diagnosis effect based on defferent feature extraction methods
圖6為6 100組測試數據,其中縱坐標表示故障對應的分類標簽編號(參照表1),橫坐標表示測試數據組數.基于兩種不同的特征提取方法的SVM故障診斷結果如圖7所示.
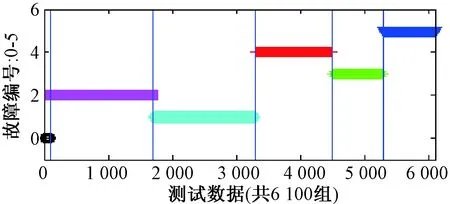
圖6 各測試數據的故障類型Fig.6 The types of fault of test data
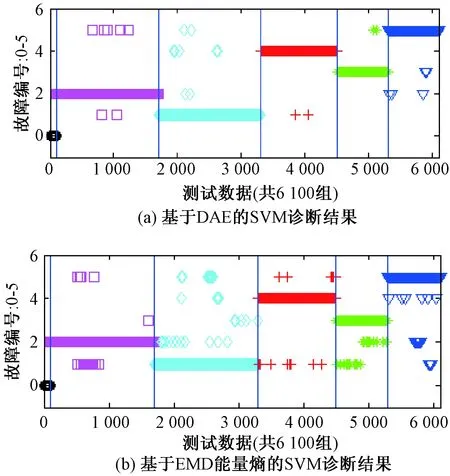
圖7 軸承故障診斷結果Fig.7 The bearing fault diagnosis results
由圖7可以看出,基于DAE特征提取的SVM故障診斷明顯比基于EMD能量熵特征提取的SVM診斷準確率高.在6 100組測試數據中,前者出現不到50例診斷錯誤,且經觀察分析,誤診故障與實際發生的故障極為相近.由此可以判斷DAE是一種更具優勢的特征提取方法.
4 結論
本方法主要是針對故障診斷領域,運用基于無監督學習、數據驅動的故障特征提取,來提高診斷精度.試驗證明DAE這一完全自適應的提取方法能夠明顯起到特征提取的作用,由于DAE在特征提取中良好的魯棒性,避免了由于數據變化而需要建立復雜的特征提取模型;另外,在此基礎上建立的故障診斷方法,其診斷精度得到顯著的提高.這一方法是直接以軸承的頻譜作為輸入的,能夠通過AE自動地提取故障特征來實現軸承數據的預處理,因此與其他故障診斷方法中需要人為地設計數據預處理方式的情況相比,更顯智能化.
本方法并未具體闡述卻有研究價值的方面:可以討論通過一定的方法改善、規范化DAE訓練過程中加噪參數、DAE層數、各層輸出節點數等,有望達到更高的識別精度.
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
河南科技(2014年23期)2014-02-27 14:19:15
