基于Hadoop的區域土壤侵蝕強度計算GIS設計與實驗
2018-09-17 06:52:56岳德鵬YANGDi羅志東許永利
農業機械學報 2018年9期
雷 章 岳德鵬 YANG Di 羅志東 許永利 于 強
(1.北京林業大學林學院, 北京 100083; 2.佛羅里達大學地理系, 蓋恩斯維爾 32611; 3.水利部水土保持監測中心, 北京 100053; 4北京地拓科技發展有限公司, 北京 100083)
0 引言
土壤侵蝕直接或間接導致土壤肥力下降,造成土質惡化、生態破壞,不利于農業可持續發展[1]。我國是世界上土壤侵蝕最嚴重的國家之一,區域土壤侵蝕預測預報一直是水土保持科研領域的研究熱點[2]。區域土壤侵蝕預測預報研究的一項重要內容是根據土壤侵蝕模型快速計算土壤侵蝕強度,及時定量評價目標區域的土壤侵蝕狀況[3-6]。近年來隨著空間信息技術的發展和生產實際的需要,區域土壤侵蝕預測預報研究使用的空間數據精度越來越高,米級、亞米級高分辨率遙感影像已經得到廣泛應用,土壤侵蝕強度計算涉及的數據量也越來越大,第一次全國水利普查水土保持普查各類侵蝕因子柵格數據約14TB[7-9]。對于這種大數據量柵格計算應用,傳統的地理信息系統(Geographic information system,GIS)開發技術已難以滿足實際需求[10-12]。一是大量數據的網絡傳輸耗時太長,整個程序難以快速出結果;二是內存有限,無法寫入整個數據,即使采用多線程進行數據分塊讀取分析的方式,仍無法解決這個內存限制,并且程序復雜度大大增加。目前已有文獻研究使用Hadoop解決大數據量柵格數據計算應用方面的相關問題,在數據存儲管理和查詢應用方面取得了一些成果[13-22],但對柵格數據坐標關聯性問題和多柵格因子之間的計算應用考慮較少,不適合處理區域土壤侵蝕計算這種涉及多個柵格數據層處理的情況。
本文探討可適應多柵格數據層處理的土壤侵蝕因子柵格數據分割分塊算法、Hadoop數據節點選擇策略和土壤侵蝕模型MapReduce編程等技術問題,構建區域土壤侵蝕計算GIS,并通過實驗驗證系統功能和性能。
1 設計與實現
該系統主要功能是實現在任意空間范圍內土壤侵蝕強度快速分析計算并將結果數據發布為地圖服務供查詢應用,涉及土壤侵蝕因子柵格數據存儲管理、土壤侵蝕強度分析計算和土壤侵蝕強度數據發布3個模塊。其中土壤侵蝕因子柵格數據存儲管理模塊需解決大數據量柵格數據在Hadoop的分布式文件系統( Hadoop distributed file system,HDFS)集群環境下的高效存取問題;土壤侵蝕強度計算模塊需設計以MapReduce編程模式開發土壤侵蝕模型程序的方法并實現;土壤侵蝕強度數據發布模塊是將計算結果實時發布為Web地圖瓦片服務(Web map tile service,WMTS),以便于查詢應用。由于Hadoop是JAVA語言開發的,且僅支持在Linux平臺上運行,故本研究同樣采用JAVA和Linux系統,以避免采用不同開發語言和操作系統平臺可能引起的額外工作。
1.1 土壤侵蝕因子柵格數據存儲管理
根據Hadoop的計算任務本地化思想,數據存儲非常關鍵,需盡可能使計算關聯緊密的土壤侵蝕因子柵格數據存儲于同一個數據節點,使計算關聯不緊密的數據分散存儲在不同的數據節點。這樣設計可降低土壤侵蝕強度計算程序通過網絡從不同數據節點抓取數據的數據量及頻率,減少網絡傳輸對系統性能的影響,因為網絡傳輸速度遠小于本地硬盤讀速度,同時使土壤侵蝕強度計算程序運行時始終有最多的計算節點并行執行,提高計算性能。
由于土壤侵蝕強度計算是分地理區域進行的計算,所以土壤侵蝕因子柵格數據存儲管理的基本思路是:劃分地理網格,分割柵格數據,改進Hadoop存儲數據時數據節點選擇策略使同一地理網格的柵格數據可存儲于同一個數據節點,即一個計算單元中,以實現大區域內多個地理網格柵格數據并行處理。分割柵格數據也可以根據柵格文件大小直接分成數據量在HDFS默認的文件大小64MB之內文件塊,分塊存儲,但這樣僅適用于柵格圖層連續完整的情況,生產實際中柵格圖層很可能只是某個特定區域的,不能夠保證每個柵格圖層都是連續完整的情況,所以本文采用地理網格分割數據,這樣即使柵格數據不連續,也可使其放到既定數據節點。具體算法如下:
(1)依2000國家大地坐標系(China geodetic coordinate system 2000,CGCS2000)劃分地理網格。
地理網格劃分非常重要,它決定了柵格數據分塊的數據量大小。在并行計算中,如果數據分塊太大,各計算單元處理的數據量就大,不能充分發揮并行計算的優勢,同時會造成很多數據分塊空間未占滿,磁盤空間利用率不高;分割太碎,會使一個文件需要存放在大量的文件塊上,而這些位置信息需要被管理節點記錄,浪費管理單元的存儲空間,檢索文件開銷會比較高,同時會使磁盤頻繁尋址,降低數據讀取效率,也不利于并行計算,所以地理網格劃分是柵格數據存儲的關鍵。
HDFS研發之初的目標是解決大數據分布式存儲,以支持并行計算的問題,它假定數據都是以大文件的形式存在的,不是只有幾KB的小文件,以此為單位讀取數據文件,這是以空間換時間的策略,降低文件讀取時磁盤訪問次數,使文件系統具備較高的性能。目前一般計算機磁盤數據傳輸速度在100 MB/s以上,平均尋址時間約10 ms,為了使數據塊讀寫時,尋址時間小于整個時間的10%,需設置數據塊在100 MB以上,這里設定數據分塊大小為128 MB。
CGCS2000是國家2008年規定使用的大地坐標系統,要求測繪結果逐步統一到該坐標系統下。土壤侵蝕柵格因子是單波段數據,每個像素記錄的數據最短類型為byte(字節型),占空間是1個字節,最長是float(單精度)4個字節,所以一個像素數據量在1 byte到4 byte之間。分析某區域土壤侵蝕狀況,比如一個生產建設項目所在區域,需要遙感分辨率一般不大于2 m,所以本研究中考慮柵格數據分塊大小,也以2 m分辨率柵格數據量估計為基準。128 MB柵格文件2 m分辨率所占面積在134.217~536.871 km2,選取范圍較小的作為劃分地理網格的基礎,這樣每個柵格塊數據量都會在128 MB以內,所以縱橫軸都選取11.585 km為跨度劃分地理網格。為了便于實際應用,將跨度提升為12 km,將數據分塊大小響應調整為138 MB。
假定(x0,y0)是CGCS2000坐標系下我國國土的左下角坐標,以12 km×12 km為一個網格,編號為(i,j),那每一個網格坐標范圍計算公式為
(1)
式中 (xi,yj)——網格左下角坐標
(x′i,y′j)——網格右上角坐標
(2)根據網格坐標范圍從柵格文件左下角開始逐列分割柵格數據,并建立元數據。
假定柵格文件左下角坐標為(x,y),根據此坐標計算第1個柵格分塊的位置編號,計算公式為
(2)
式中 (ri,ci)——柵格分塊位置編號
用位置編號(ri,ci)根據式(1)計算出(xmin,ymin)和(xmax,ymax),即第一個柵格塊四角坐標。
假定柵格文件右上角坐標為(x′max,y′max),先計算柵格文件可分割的行數和列數,計算公式為
(3)
式中f——可分割總列數
f′——可分割總行數
將(xmin,ymin)代入式(1),計算各柵格分塊的四角坐標,計算方法為
(4)
為便于土壤侵蝕因子柵格數據塊的快速查找,設計元數據信息由柵格數據分塊編號C、分辨率R、因子名N和數據時相T組成,并且在數據分塊存儲時直接將CRNT 4類信息記錄為柵格數據文件名。這樣將不用侵入Hadoop內部修改Namenode的元數據管理程序,直接根據文件名稱判別目標文件是否屬于當次計算任務涉及的柵格數據塊,降低開發難度。
(3)柵格數據塊上傳存儲于Hadoop的數據節點datanode集群中。
需遵循兩個原則:①不同土壤侵蝕因子柵格數據所在網格編號相同的柵格數據塊存儲于同一個數據節點。②任何相鄰網格的柵格數據塊不能存儲于同一個節點,這樣可使多個柵格圖層進行數學計算時能盡可能多的利用多個計算單元并行處理。由于每一行的格子最多與上一行的3個格子相鄰,所以最少需要4個存儲單元,才能讓該行每個格子與上一行相鄰的格子錯開存儲,每個格子對應的存儲單元編號計算方法如下:
假定有4個存儲單元,編號分別為0、1、2、3;每個柵格分塊的編號為(x,y)。計算每個柵格分塊對應的存儲單元編號f(x,y)為

(5)
Hadoop數據存儲是由管理節點選取3臺數據節點冗余存儲每個數據塊,其中第1個數據節點隨機選擇,第2個與第1個在同一個機架,第3個在其他機架,這樣是為了保障數據存儲穩定。按照上述原理,可以配置至少4個數據節點,改進數據存儲時管理節點選擇數據節點的策略,使其按照式(5)策略選擇存儲單元,計算過程如圖1所示。
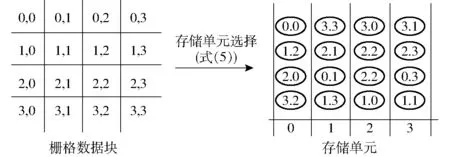
圖1 存儲單元選擇算法Fig.1 Storage unit selection algorithm
1.2 土壤侵蝕強度分析
土壤侵蝕強度分析是根據土壤侵蝕模型,計算單位面積單位時間內土壤侵蝕數量。土壤侵蝕模型實質為同一地理坐標系統下同一個地理坐標點上柵格像素計算,只要設計一種侵蝕模型對應的MapReduce程序,其他侵蝕模型可以此類推。研究中通用水土流失方程為
A=RKLSCP
(6)
式中A——年平均土壤流失量,t/(hm2·a)
R——降雨侵蝕力因子,MJ·mm/(hm2·h·a)
K——土壤可侵蝕性因子,t·h/(MJ·mm)
LS——地形因子
C——植被覆蓋因子
P——水土保持措施因子
根據式(6),設計土壤侵蝕強度并行計算程序。根據MapReduce并行編程框架的思想,設計土壤侵蝕強度并行計算程序的Mapper和Reducer接口的輸入輸出如表1所示,程序邏輯如圖2所示,具體算法如下:
(1)根據計算區域查找其覆蓋的柵格文件集合
假定輸入的計算區域對應的外包矩形,其對角坐標分別為(xmin,ymin)和(xmax,ymax),根據式(2)可分別計算出對角對應的柵格塊編號分別為(rmin,cmin)和(rmax,cmax),形成了一個編號區間。該編號區間涵蓋的全部文件即為該區域覆蓋的柵格文件集合。根據上述元數據定義,即可推知全部柵格文件的名稱。
(2)通過Mapper程序讀取柵格值
按照柵格數據分塊存儲時建立的元數據,以文件名和文件數據內容組成的形式如表1中的〈“C|R|N|T”,“V”〉,輸入到Mapper程序,讀取每個像素位的柵格值,并形成新的key-value形式作為Reducer程序的輸入。
(3)通過Reducer程序進行柵格計算
Reducer程序通過對像素坐標相同的值進行解析,獲取同一個像素坐標下,不同柵格因子對應的柵格值,并按照式(6)計算形成侵蝕強度數據,并輸出成柵格文件。
MapReduce執行邏輯如圖2所示。

表1 Mapper程序和Reducer程序的輸入輸出說明Tab.1 Input and output instructions for Mapper and Reducer program
注:C|R|N|T表示柵格文件名稱,具體為分塊位置編號|分辨率|侵蝕因子名|時間;V表示柵格文件數據內容;P表示像素坐標。

圖2 土壤侵蝕模型MapReduce程序邏輯圖Fig.2 MapReduce program algorithm overview
1.3 土壤侵蝕數據發布
本研究中使用GIS中間件Geoserver對生成的土壤侵蝕強度柵格數據進行發布,形成土壤侵蝕WMS(WEB地圖服務)。由于土壤侵蝕強度柵格數據存儲于HDFS集群中,一般的GIS中間件如ArcGIS Server、SuperGIS等不支持HDFS數據讀取,所以無法直接應用。而Geoserver是開源項目,可以直接獲取源代碼,在源碼基礎上擴展開發Geoserver柵格數據源識別功能,使Geoserver可以支持直接讀取HDFS文件系統中的柵格數據,實現土壤侵蝕強度柵格數據的動態實時發布。
Geoserver數據源管理功能程序設計比較簡潔,是采用JAVA SPI(Service provider interface,服務提供接口)機制實現的,添加HDFS柵格數據源讀操作時需先創建HDFS數據讀操作類,實現org.geotools.coverage.grid.io.GridFormatFactorySpi接口規定的createFormat方法;然后根據JAVA SPI的規則要求在目錄META-INF/services/下增加文件org.geotools.data.GridFormatFactorySpi,內容為HDFS數據讀操作類的完整類名。完成后重啟Geoserver服務,即可讀取HDFS柵格數據源。
2 實驗與分析
2.1 實驗環境和數據
實驗中使用了5臺計算機組成集群部署運行該系統。每個節點機器軟硬件配置相同,具體為:CPU4核4線程、3.4 GHz頻率,內存4 GB,硬盤500 GB,操作系統ubuntu linux 14.04,Java虛擬機JRE1.7,網絡帶寬為各節點獨享100 Mb/s。其中一臺部署為HDFS管理節點namenode,并運行該系統程序,另外4臺作為HDFS的數據節點datanode使用。
在上述測試環境下,采用大凌河流域的R、K、LS、C和P共5個土壤侵蝕因子柵格數據做實驗,數據見圖3。大凌河位于遼寧省西部低山丘陵區,長約435 km,流域面積約23 549 km2,各因子數據分辨率為2 m、像素值類型為IEEE單精度浮點數(4字節)、數據量為5.632 GB,總數據量為28.16 GB。

圖3 土壤侵蝕因子分布Fig.3 Distribution of soil erosion factors
2.2 功能分析
輸入5個因子數據,系統生成大凌河流域水力土壤侵蝕強度柵格如圖4和表2所示,柵格圖上顏色越深的區域土壤侵蝕強度越大,表2是根據土壤侵蝕分類分級標準[23]統計生成的。

圖4 土壤侵蝕強度圖Fig.4 Map of soil erosion
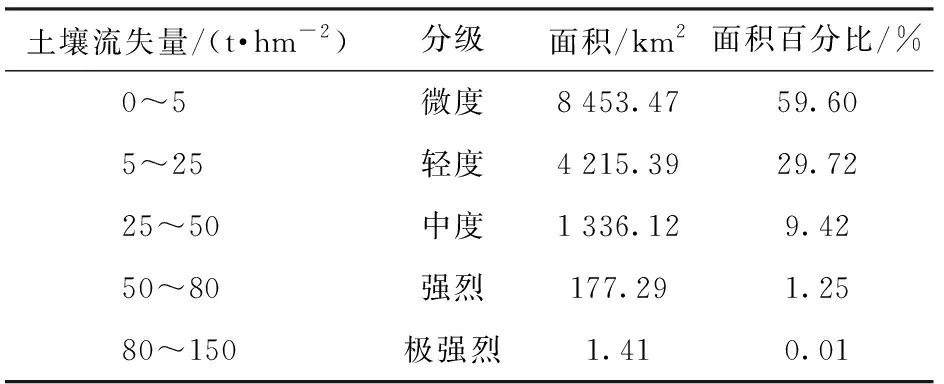
土壤流失量/(t·hm-2)分級面積/km2面積百分比/%0~5微度8453.47 59.605~25輕度4215.3929.72 25~50中度1336.12 9.42 50~80強烈177.29 1.25 80~150極強烈1.41 0.01
由圖4和表2可知:①柵格圖上顏色比較淺區域,其數量、位置和形狀與水土保持措施分布的數量、位置和形狀完全吻合,說明存在水土保持措施區域,土壤侵蝕強度都比較小,符合RUSLE模型中水土保持措施與土壤侵蝕強度的負相關特征。②表2中微度和輕度流失區域占總面積89.32%。微度主要位于城區,強烈和極強烈流失區的面積之和為178.7 km2,占總面積1.26%,這些區域為需優先治理的區域,它們主要分散在山溝地區。
2.3 性能分析
系統輸出的大凌河流域水力土壤數學侵蝕強度柵格數據,分辨率為2 m、像素值類型為無符號整數(1字節),數據量為1.412 GB。執行過程中執行時間和網絡使用率如圖5所示。
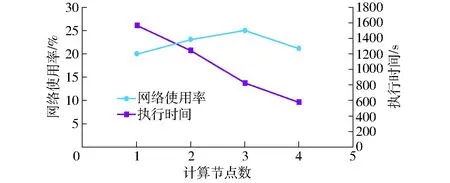
圖5 不同計算節點數量下的網絡使用率和執行時間Fig.5 Network utilization and execution time of different numbers of compute node
由圖5可知:①隨著計算節點從1臺增加至4臺,該區域土壤侵蝕強度柵格圖生成過程耗時明顯降低,說明本研究提出的系統構建方法可以實現區域土壤侵蝕快速計算與實時發布,并通過增加計算節點可顯著提升系統性能。②計算過程中集群環境網絡負載較低,使用率保持在22%左右。說明研究中設計的數據存儲策略使數據本地化較好,在區域土壤侵蝕強度計算過程中,按數據分塊啟動的多個并行執行的計算任務都較好地分布在各數據分塊對應的數據節點上,沒有出現通過網絡異地大量讀取數據的現象。
3 結論
(1)該系統可快速計算出大凌河流域不同強度的水力土壤侵蝕分布區域及占比,可以為大凌河流域水力土壤侵蝕監測和治理提供參考依據。
(2)該系統可明顯提升基于大數據量高分辨率土壤侵蝕因子柵格數據的區域土壤侵蝕強度從分析計算到發布應用的效率,可較好滿足區域土壤侵蝕預測預報的時效性要求。
(3)所設計的土壤侵蝕模型MapReduce編程模式,可以為同類模型的MapReduce并行計算程序研究提供參考。
(4)對于大數據量柵格數據并行計算時,該系統計算任務本地化效果明顯,顯著降低了計算過程中的網絡傳輸壓力,系統性能較好,通過增加計算節點,系統性能還可進一步提升。
