基于支持向量的最近鄰文本分類方法
2018-09-18 09:48:58古麗娜孜艾力木江乎西旦居馬洪孫鐵利梁義
智能系統學報 2018年5期
古麗娜孜·艾力木江,乎西旦·居馬洪,孫鐵利,梁義
文本分類(text classification,TC)是對一個文檔自動分配一組預定義的類別或應用主題的過程[1]。隨著數字圖書館的快速增長,TC已成為文本數據組織與處理的關鍵技術。數字化數據有不同的形式,它可以是文字、圖像、空間形式等,其中最常見和應用最多的是文本數據,閱讀的新聞、社交媒體上的帖子和信息主要以文本形式出現。文本自動分類在網站分類[2-3]、自動索引[4-5]、電子郵件過濾[6]、垃圾郵件過濾[7-9]、本體匹配[10]、超文本分類[11-12]和情感分析[13-14]等許多信息檢索應用中起到了重要的作用。數字化時代,在線文本文檔及其類別的數量越來越巨大,而TC是從數據海洋當中挖掘出具有參考價值數據的應用程序[15-16]。文本挖掘工作是政府工作、科學研究、辦公業務等許多應用領域里書面文本的分析過程。樸素貝葉斯、k近鄰、支持向量機、決策樹、最大熵和神經網絡等基于統計與監督的模式分類算法在文本分類研究中已被廣泛應用。提高文本分類效率的算法研究對web數據的開發應用具有重要意義。
合理的詞干有助于提高文本分類的性能和效率[17-18],特別是對于哈薩克語這樣的構詞和詞性變化較復雜語言的文本分類而言,詞干的準確提取極其重要。從同一個詞干可以派生出許多單詞,因此通過詞干提取還可以對語料庫規模進行降維。文本文檔數量的巨大化和包含特征的多樣化,給文本挖掘工作帶來一定的困難。目前,眾多文本分類研究都是基于英文或中文,基于少數民族語言的文本分類研究相對較少[19];但是國外對于阿拉伯語的文本分類工作比中國少數民族語言文本分類工作成熟[20–21],投入研究的人員也較多。
哈薩克語言屬于阿爾泰語系突厥語族的克普恰克語支,中國境內通用的哈薩克文借用了阿拉伯語和部分波斯文字母,而哈薩克斯坦等國家用的哈薩克文是斯拉夫文字。哈薩克文本跟中文不同的一點是哈薩克文文本單詞以空格分開的,這點類似于英文,都需要文本詞干提取過程。由于哈薩克語與英語語法體系不一樣,英文詞干提取規則還不能直接用到哈薩克語文本分類問題上,要研究適合哈薩克語語法體系的詞干提取規則之后才能實現哈薩克語文本的分類工作。哈薩克語具有豐富的形態和復雜的拼字法,因此哈薩克語文本分類系統的實現是有難度的。為了實現文本分類任務需要一定規模的語料庫,語料庫里語料的質量直接影響文本分類的精度。到目前為止在哈薩克語中還沒有一個公認的哈薩克文語料庫,當然,也有不少人認為新疆人民日報(哈文版)上的文本可以當作文本分類語料庫。本文為了保證文本分類語料庫的規范化和文本分類工作的標準化,經過認真挑選中文標準語料庫里的部分語料文檔并對其進行翻譯和新疆人民日報上的部分文檔來自行搭建了本研究的語料庫。本文在對前期研究里詞干提取程序詞干解析規則[22-24]進行優化改善的基礎上實現本研究的文本預處理,提出新的樣本測度指標與距離公式,并結合SVM與KNN分類算法實現了哈薩克語文本分類。
1 文本特征提取
1.1 文本預處理
文本預處理在整個文本分類工作中扮演著最重要的角色,其處理程度直接影響到文本分類精度。因為它是從文檔中抽取關鍵詞集合的過程,而關鍵詞的單獨抽取因語言語法規則的不同而不同,所以這層工作屬于技術含量較高的基礎性工作,需要設計人員熟練掌握語言語法規則和計算機編程能力。目前存在一個現實問題,即包括作者在內的很多編程人員因研究工作的需要一般從事于中英文文字資料上的研究,所以對母語(哈薩克語)語法規則的細節不精通,對從小開始在漢語授課學校上學的編程人員情況則更嚴重,所以要實現詞干解析需要向語言學專家或相關人員全面請教,這也是影響哈薩克語文本分類工作進展的一個客觀問題。
哈薩克語文字由24個輔音字母和9個元音字母的共有33個字母組成。因為哈薩克語語法形式是在單詞原形前后附加一定附加成分來完成的,所以哈薩克語言屬于黏著語,即跟英文類似一個哈薩克語單詞對應多種鏈接形式,因此對其一定要進行詞干提取。
本文前期系列研究工作基本完成了哈薩克語文本詞干提取以及詞性標注工作,已完成哈薩克語文本詞干表的構建。該詞干表收錄了如圖1所示的由新疆人民出版社出版的《哈薩克語詳解詞典》中的60 000多個哈薩克語文本詞干和如圖2所示的438個哈薩克語文本詞干附加成分。
圖1 哈薩克語詞干Fig. 1 Kazakh text stem

圖2 哈薩克語附加成分Fig. 2 Additional components in Kazakh text
本文在前期準備研究工作的基礎上,給出3種詞性的有限狀態自動機,并采用詞法分析和雙向全切分相結合的改進方法實現哈薩克語文本詞干的提取與單詞構形附加成分的細切分。以改進的逐字母二分詞典查詢機制對詞干表進行搜索,提高詞干提取的效率。以概率統計的方法對歧義詞和未記載詞進行切分。在此研究基礎上,設計實現了哈薩克語文本的詞法自動分析程序,完成哈薩克語文本的讀取預處理。處理結果如圖3所示,上半窗體上顯示的是待切分的文檔原文,下半窗體上顯示是詞干切分后的結果。

圖3 哈薩克語文本詞干切分結果示例Fig. 3 Example segmentation results of the Kazakh text stem
1.2 特征處理
特征是文本分類時判別類別的尺度。模式識別的不同分類問題有不同的特征選擇方法,而在文本分類問題中常用到的方法有互信息(MI)、X2統計量(CHI)、信息增益(IG)、文檔頻率(DF)、卡方統計等[25]。這些方法各具優點和不足之處。MI、IG和CHI傾向于低頻詞的處理,而DF則傾向于高頻詞的處理。目前,也有許多優化改進方法[26-28],其中文本頻率比值法(document frequency ratio,DFR)以簡單、快捷等優點克服了以上幾種方法存在的問題,綜合考慮了類內外文本頻率,其計算公式為
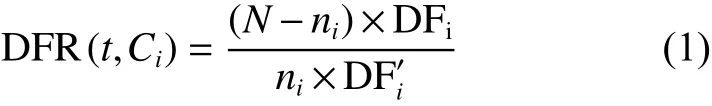
式中,對于詞t,N是訓練文本數,ni是Ci類別中的文本數,DFi是Ci類別中包含詞t的文本數,而顯然是除了Ci類以外的別的類別中包含詞t的文本數。
通過詞頻統計、詞權重計算和文檔向量化表示等一系列的預處理工作之后才能運用分類算法,所以對文本分類工作而言這些都是非常重要的階段性基礎工作。圖4所示的是每類文檔里(如體育類文檔中)每一個單詞(如“排球”)的總出現次數。圖5所示的是詞的權重計算結果,即統計某詞在判別文檔類別所屬關系中的隸屬度,當然隸屬度越高說明該詞在文檔分類時的貢獻越大。最后把文檔由如圖6所示的形式向量化表示,生成分類問題的文檔向量,即“X號特征詞:該特征詞的特征向量”形式向量化表示。
圖4 詞頻統計結果Fig. 4 Term frequency statistical result

圖5 詞權重計算結果Fig. 5 Term weight computed result
圖6 文本向量文件Fig. 6 Text vector files
2 SVM與KNN方法
2.1 SVM方法
支持向量機(support vector machine,SVM)是在1995年由Cortes和Vapnik首次提出來的一種模式識別分類技術[29]。SVM是在統計學習理論(statistical learning theory,SLT)原理的基礎上發展起來的機器學習算法。SVM方法的重點在于在高維特征空間中能構造函數集VC維盡可能小的最優分類面,使得不同類別樣本在這分類面上分類上界最小化,從而保證分類算法的最優推廣能力。圖7所示的是SVM方法的分類原理示意圖。SVM在有限訓練樣本情況下,在學習機復雜度和學習機泛化能力之間找到一個平衡點,從而保證學習機的推廣能力[30]。
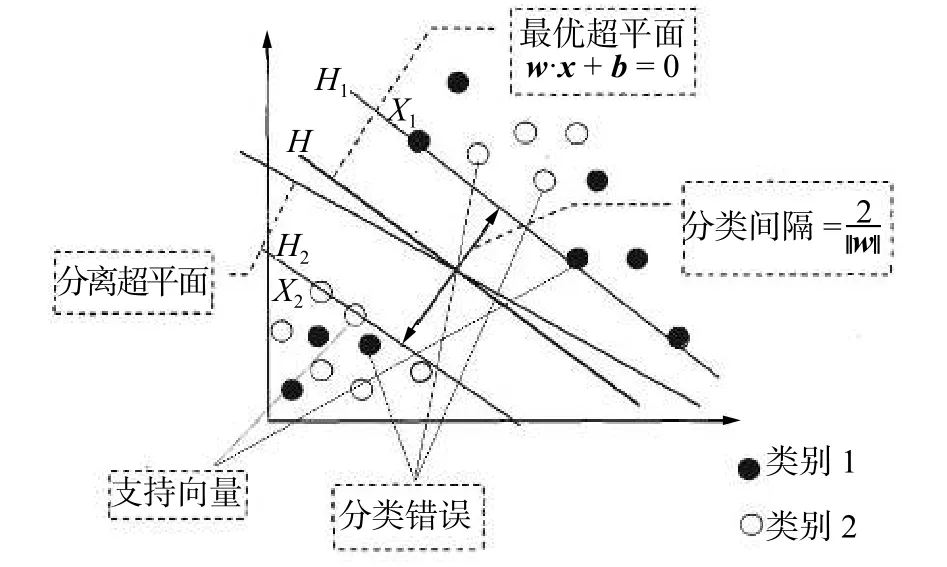
圖7 SVM 分類原理示意圖Fig. 7 SVM classification schematic diagram
根據樣本分布情況與樣本集維數,SVM算法的判別函數原理大致可分為線性可分與非線性可分兩種形式。
1)線性可分
帶有以式(2)所示訓練樣本集的SVM線性可分分類問題的數學模型可通過式(3)來表示:


式中對應ai≠0時的樣本點就是支持向量。因為最優化問題解ai的每一個分量都與一個訓練點相對應,顯然所求得的劃分超平面僅僅與對應ai≠0 時的那些訓練點 (xi·x)相關,而跟 ai=0 時的那些訓練點沒有任何關系。相應于ai≠0時的訓練點(xi·x)里的輸入點xi就是支持向量,通常它們是全體樣本中的很少一部分。得出結論,最終分類分界面的法向量ω只受支持向量的影響,不受非支持向量訓練點的影響。
2)非線性可分
為此,需要在式(3)中增加一個松弛變量ξi和懲罰因子C,從而式(3)變為

式中:ξi≥ 0;i = 1, 2, ···, n;C 為控制樣本對錯分的調整因子,通常稱為懲罰因子。C越大,懲罰越重。
雖然原理看起來簡單,然而在分類問題的訓練樣本不充足或不能保證訓練樣本質量的情形下確定非線性映射是很困難的,那么如何確定非線性映射呢?SVM通過運用核函數概念解決這個問題,核函數是SVM的其他分類算法無法替代的獨特功能。
SVM通過引入一個核函數K(xi·x),將原低維的分類問題空間映射到高維的新問題空間中,使核函數代替內積運算,這個高維空間就稱為Hilbert空間。引入核函數以后的最優分類函數為
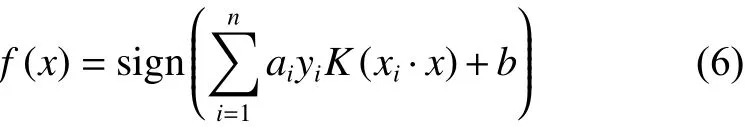
2.2 KNN方法
KNN(K nearest neighbor)分類法是基于實例的學習算法,它需要所有的訓練樣本都參與分類[31]。在分類階段,利用歐氏距離公式,將每個測試樣本與和它鄰近的k個訓練樣本進行比較,然后將測試樣本歸屬到票數最多的那一類里[32]。KNN算法是根據測試樣本最近的k個樣本點的類別信息來對該測試樣本類型進行判別,所以k值的選取非常重要。k值若太小,測試樣本特征不能充分體現;k值若太大,與測試樣本并不相似的個別樣本也可能被包含進來,這樣反而對分類不利。KNN算法在分類決策上只憑k個最鄰近樣本類別確定待分樣本的所屬類。目前,對于k值的選取還沒有一個全局最優的篩選方法,這也是KNN方法的弊端,具體操作時,根據先驗知識先給出一個初始值,然后需要根據仿真分類實驗結果重新調整,調整k值的操作有時一直到分類結果滿足用戶需求為止。該方法原理可由式(7)表示:
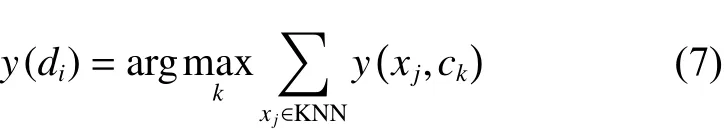
式(7)表明將測試樣本di劃入到k個鄰近類別中成員最多的那個類別里。
在使用KNN算法時,還可由其他策略生成測試樣本的歸屬類,如式(8)也是被廣泛使用的公式:
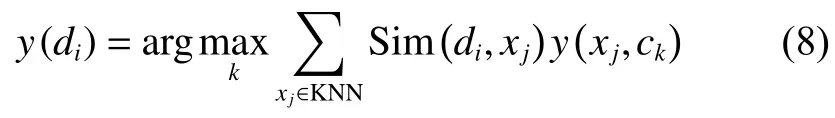
當x(j∈ci時,;當xjci時,;是測試樣本di和它最近鄰xj之間的余弦相似度。余弦相似度測量是由一個向量空間中兩個向量之間角余弦值來定義的。式(8)說明測試樣本di被歸到k個最近鄰類里相似性最大那個類別里。
一般情況下,不同類別訓練樣本的分布是不均勻的,同樣不同類別的樣本數量也可能不一樣。所以,在分類任務中,KNN中k參數的一個固定值可能會導致不同類別之間的偏差。例如,對于式(7),一個較大的k值使得方法運行結果過擬合,反過來一個較小的k值使得方法模型性能不穩定。實際上,k的值通常由交叉驗證技術來獲取。然而,像在線分類等情況,就不能用交叉驗證技術,只能給出經驗值,因此k值的選定很重要。
KNN雖是簡單有效的分類方法,但不能忽略以下兩方面的問題:1)由于KNN需要保留分類過程中的所有相似性計算實例,從而隨著訓練集規模的增多,其計算量也會增加,在處理較大規模數據集分類時方法的時間復雜度會達到不可接受的程度[33],這是KNN方法的主要缺點;2) KNN方法分類的準確性可能受到訓練數據集中特性的無關性和噪聲數據的影響,若考慮這些因素其分類效果也許更好。
3 基于SV-NN的哈薩克語文本分類算法
本文提出一種組合分類方法,把SVM算法當作KNN算法的訓練階段,這樣可以避免k參數的選擇。組合分類方法結合了SVM算法的訓練和KNN算法的學習階段。首先運用SVM算法對所有訓練樣本進行一次訓練獲得每一類別的少量的支持向量(support vectors,SVs),在測試階段使用最近鄰分類器進行測試并分類測試樣本,即計算出新測試樣本與每個類別SVs平均距離值后對其進行對比分析,該測試樣本與哪一類別SVs平均距離值點離得最近就把它歸為該類別中。分類決策依據是各類別SVs平均距離值后對其與測試點之間距離的數值分析,所以簡稱該算法為支持向量與最近鄰方法(the support vector of nearest neighbor,SV-NN)。
3.1 SV-NN算法描述及流程圖
假設共有n個類別,每個類別含有m個支持向量。
SVM: T1→svij;//通過使用 SVM 定義每個類別的支持向量。
while(k<l)
{ 輸入 xk;
利用式(9)計算xk與svij之間的距離(Dk);
利用式(10)計算xk與svij之間的平均距離(averDk);
SV-NN 分類算法:
Start:
{ integer i, j,k,l;
利用式(11)計算xk與svij之間最小平均距離
將xk劃入到基于的最近類別;
k=k+1;
}
}
End
SV-NN分類方法的工作流程如圖8所示。
3.2 SV-NN 算法實現
1)將所有訓練點映射到向量空間,并通過傳統SVM確定每一個類別的支持向量。

式中:支持向量svij是從輸入文檔中提取的(共有n個類,每個類別含有m個支持向量)。確定每一類的支持向量之后,其余的訓練點可以消除。
2)使用歐氏距離公式(9)計算測試樣本xk與由1)生成的每一類支持向量svij之間的距離。
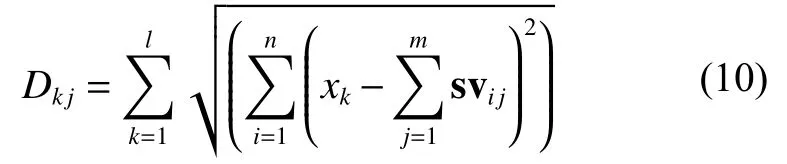

圖8 SV-NN分類方法工作原理Fig. 8 SV-NN classification approach working principle diagram
3)使用式(10)計算測試樣本xk與每一類支持向量svij之間的平均距離:

4)計算最短平均距離minD,并將測試樣本xk劃入到最短平均距離對應的那一類中。

即輸入點被確認為與svij之間最短平均距離值對應的正確類。
重復步驟2)~4),直到所有的測試樣本分類完為止。
4 實驗結果與評價
通常,語料庫里語料的質量與數量直接影響文本分類算法的分類性能。中、英文等其他語言文本分類研究都有標準的語料庫,而哈薩克語文本分類工作卻還沒有一個公認的標準語料庫。本文考慮到文本分類工作的規范性和語料的標準性,由中文標準語料部分文檔的翻譯和挑選新疆日報(哈文版)上的部分文檔來搭建了本研究的語料庫。在前期研究里,同樣是通過翻譯收集語料集的,只是其規模小了點,本文的語料工作算是對前期研究語料集的補充和優化完善。前期研究語料集語料文檔只有5類文檔,本文擴充到8類文檔。通過跟語言學專家們的多次溝通,選擇具有代表性的文檔,同時對詞干提取程序解析規則也作了適當的調整。雖然本文所構建的語料庫還不能稱得上“標準”詞語,但對現階段哈薩克語文本分類任務的完成具有實際應用價值。
本文把語料集規模擴大到由計算機、經濟、教育、法律、醫學、政治、交通、體育等8類共1 400個哈薩克語文檔組成的小型語料集,如表1所示。數據集被分為兩個部分。880個文檔(63%)用于訓練,520個文檔用于測試(37%)。

表1 數據集Table 1 Data set
本文文本分類實驗評價指標采用了召回率、精度和F1這3種評價方法。精度評價是指比較實際文本數據與分類結果,以確定文本分類過程的準確程度,是文本分類結果是否可信的一種度量。高精度意味著一個算法返回更相關的結果,高召回率代表著一個算法返回最相關的結果,所以文本分類工作期望獲得較高的精度和召回率。
本文在前期研究中搭建的哈薩克文語料集的補充完善以及對其詞干提取程序提取規則細節的優化改善基礎上實現了本研究哈薩克語文本的預處理。分類任務的實現運用了SVM、KNN與本文提出的SV-NN算法,并對3種算法分類精度進行了較全面的對比分析。通過對表2和圖9上的仿真實驗數字的對比分析,發現SVM算法優于KNN算法,而SV-NN算法優于SVM 算法。SV-NN方法F1指標除了教育類和法律類以外在其他類上的F1指標都高于都SVM、KNN對應指標。SVM、KNN和SV-NN平均分類精度分別為0.754、0.731和0.778,這說明本文提出算法對所有類別文檔詞的召回率和區分度較穩定。本研究提出的算法模型繼承了SVM算法在有限樣本情況下也能獲得較好分類精度的優點,另外,本算法沒有去定義KNN算法的k參數,也沒有跟所有類所有訓練樣本進行距離運算。所以,本研究提出的算法無論從算法復雜度的分析還是算法收斂速度的分析都是有效的。當然,總體精度還是沒有像中、英文等其他語言文本分類精度那么理想,因為涉及很多方面的因素,如研究語料庫語料文檔數量、每一類文檔本身的質量、詞干表里已錄用的詞干數量和質量、詞干提取程序解析規則的細節等,但目前所獲得的分類精度比前期系列研究成果理想,本算法的文本分類性能有了很大的提升也較好地提高了召回率。

表2 SVM、KNN、SV-NN的分類精度對比Table 2 SVM KNN and SV–NN comparison of classification accuracy
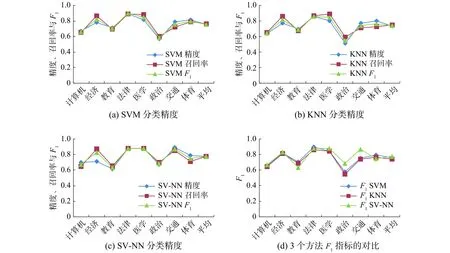
圖9 分類精度的對比分析(每一類別均含175篇文檔)Fig. 9 Comparative analysis of classification accuracy (each category contains 175 documents)
5 結束語
本文在前期系列研究中所搭建的哈薩克文語料集和詞干提取程序的優化完善基礎上實現了哈薩克語文本的預處理。分類任務的實現上運用了模式識別的3種分類算法,并對3種分類算法分類精度進行了較全面的對比分析。通過仿真實驗客觀數字的對比分析,說明本文提出算法的優越性。本文算法對所有類別文檔詞的召回率和區分度較穩定。本文算法在繼承SVM算法的分類優越性基礎上,還有效避免了KNN算法設置k參數的麻煩和跟所有訓練樣本進行距離計算而帶來的巨大時間復雜度,進而保證了分類算法的收斂速度。
本研究仍有許多待優化完善的問題,本文接下來的研究工作中將系統地研究并解決影響文本分類精度的階段性問題,獲得滿意的分類精度。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
