基于模型堆疊的上網行為日志用戶畫像方法
2018-09-19 08:20:18,,,
山東科技大學學報(自然科學版) 2018年5期
,,,
(1.山東科技大學 計算機科學與工程學院, 山東 青島 266590;2.山東科技大學 電子通信與物理學院, 山東 青島 266590)
隨著互聯網技術的不斷發展和普及,網民的數量迅速上升,根據中國互聯網絡信息中心(CNNIC)發布的《第40次中國互聯網發展狀況統計報告》,截止2017年6月,我國網民規模達7.51億。網民在遨游網絡的同時,在網絡中留下了海量的上網行為日志數據。分析上網行為日志數據,挖掘出用戶興趣、喜好、基本屬性(性別、年齡等),可以為個性化推薦、精準營銷、商業決斷分析、風險控制等提供數據支持。
用戶畫像作為大數據技術的重要應用之一,為分析和挖掘上網行為日志數據提供了可靠的方法。用戶畫像是由交互設計之父Alan Cooper提出的[1],定義用戶畫像為真實用戶的虛擬代表,根據一系列用戶的真實數據來挖掘出目標用戶。用戶畫像根據用戶的基本屬性、生活習慣和上網行為等信息,篩選出一類用戶標簽,給用戶信息進行結構化處理。其目的是在多維度上構建用戶的標簽屬性,利用這些標簽屬性構造用戶真實的特征,可用于描述用戶的興趣、偏好、特征等。Fawcett T等[2]利用規則發現的方法在大量電話記錄中發現欺詐行為標簽,利用這些標簽構建用戶畫像模型,該方法可以產生高可信度的報警。Adomavicius等[3]展示了針對個性化的用戶畫像模型,利用分類規則、關聯規則等數據挖掘方法來發現潛藏在用戶商品交易記錄中的行為檔案信息。Nasraoui等[4]根據動態網站的網絡日志數據構建了動態可演化的用戶行為畫像模型,提出的網絡使用日志挖掘框架可以挖掘、追蹤和驗證動態的多方面用戶畫像信息。陳志明等[5]基于“知乎”網站的數據,構建了基于用戶基本屬性、社交屬性、興趣屬性和能力屬性四個維度的動態用戶畫像模型,并通過對“知乎”網站PM2.5話題下1303位用戶進行實證分析,得出的動態用戶畫像模型可以很好的區分用戶的能力。Burger等[6]通過提取Twitter的個人簡介中隱藏的特征標簽構建用戶畫像方法,利用SVM[7]、樸素Bayes[8]和Balanced Winnow2[9]等分類器針對性別標簽進行實驗,得到了較好的實驗效果。Iglesias等[10]根據用戶在Unix Shell上的命令日志數據研究用戶畫像,獲得了計算機用戶的行為畫像。郭光明[11]基于微博行為數據進行了用戶信用畫像的研究,利用帶有L2正則的邏輯斯蒂回歸分類器對用戶進行分類,實驗結果表明學習出的用戶行為模式可以很好地解釋用戶的信用標簽。但由于上網行為日志數據的復雜性,傳統的用戶畫像方法不能很好的應用于上網行為日志數據中。本文通過分析校園網日志的特點,提出了一種多維度標簽用戶畫像方法。結合五種特征選擇算法構建多指標融合的特征選擇方法,融合二元特征和關聯規則特征提取方法構建標簽庫,在兩層疊加式框架中組合支持向量機、隨機森林、決策樹、樸素貝葉斯和邏輯斯蒂回歸五種單一分類器模型構建基于Stacking的用戶畫像。實驗結果證實了本文用戶畫像方法比單一分類模型在識別用戶性別、年級、年齡屬性的準確性上有較大提高。
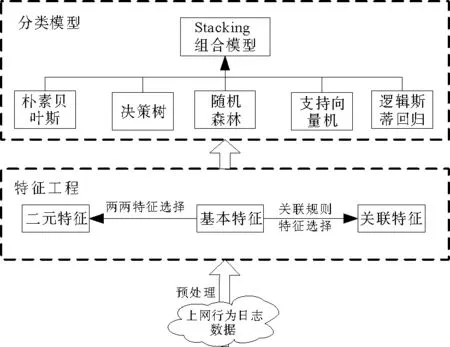
圖1 用戶畫像框架Fig.1 The framework of user portrait
1 基于上網行為日志的用戶畫像框架
參考數據挖掘的一般研究流程框架,本研究基于上網行為日志的用戶畫像框架如圖1所示,主要包括特征工程和分類模型兩個關鍵環節。其中,特征工程是通過特征選擇和特征提取(基本單特征、二元特征、關聯規則特征)來構建標簽庫;而分類模型是利用支持向量機、邏輯斯蒂回歸、決策樹、隨機森林和樸素貝葉斯五種單一分類器模型構建Stacking組合模型。
2 用戶特征選擇與提取
2.1 構建標簽庫
標簽是用戶特征的符號標識。標簽具有兩個重要特征,一是具有一定的種群性,可以在一定程度上抽樣出概括事務的特征;二是可以使用符號來表示用戶的某一類特征,這個符號可以是中文、英文,也可以是數字。標簽庫則是對標簽進行集中管理,最終用于對用戶行為、屬性的標記。
本研究基于上網行為日志數據的特性構建了三級標簽。一級標簽分為學生基本屬性和行為標簽兩部分,二級標簽則是對一級標簽的細分,三級標簽是標簽庫中最詳細的標簽描述。標簽庫的分級層結構如圖2所示。
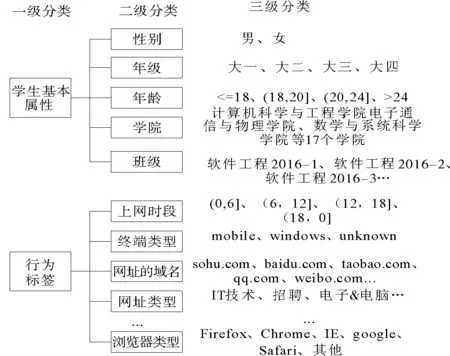
圖2 標簽庫分級結構圖Fig.2 Hierarchical structure map based on label Library
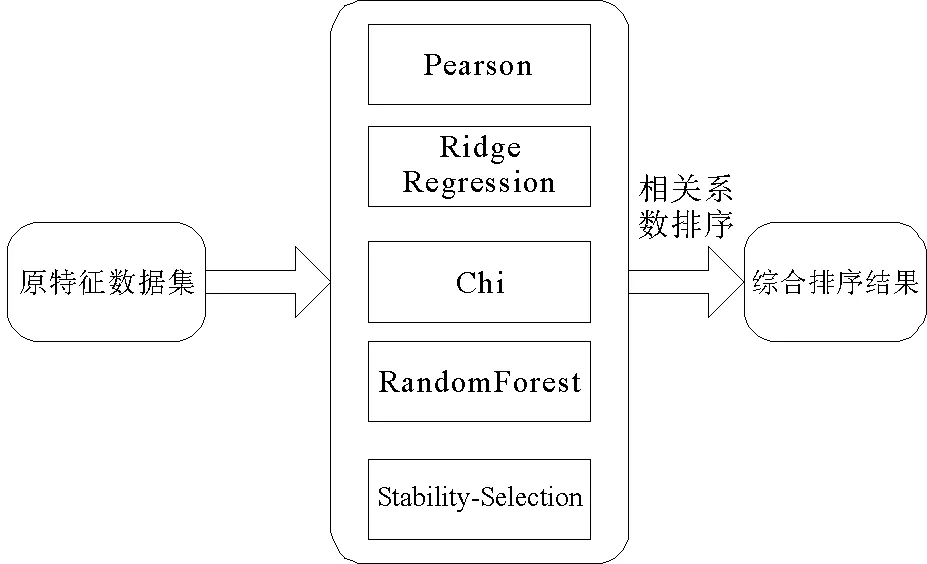
圖3 特征選擇方法架構圖Fig.3 Architecture diagram of feature selection method
2.2 特征選擇
特征選擇[12]是模型識別的關鍵因素之一,特征選擇結果的好壞直接影響分類結果的精度,因此需要有效的方法進行特征選擇,提取對標簽區分能力較高的特征,同時刪除無用的噪聲特征。
目前,特征選擇的方法有很多,但是針對實際問題的研究仍存在各自不足。本文融合Pearson相關系數(皮爾森相關系數)[12]、Ridge Regression(嶺回歸)[13]、Chi(卡方檢驗)、RandomForest[14](隨機森林)和Stability-Selection(基于隨機lasso的穩定性選擇)[15]五種不同類型的特征選擇算法構建多指標融合的特征選擇方法,有效地避免了一種特征選擇方法的不穩定性。本文特征選擇方法的架構如圖3所示。
假設X=(X1,X2,…,Xk)為n維k列滿秩矩陣,代表由k列不同屬性特征組成的n維樣本訓練集合,其中Xi=(xi1,xi2,…,xin)T代表第i(i≤k)列訓練樣本。Y=(Y1,…,Yl)代表n維l列目標類向量(類標簽),其中Yj= (y1,y2,…,yn)T代表第j(j≤l)列類標簽。{F1,F2,F3,F4,F5}代表Pearson、Ridge Regression、Chi、RandomForest、Stability-Selection五種特征選擇方法。coefj(j∈[1,5])代表由第j類特征選擇方法得到的X與Y的相關系數集合。
由圖3可以看出,本研究多指標融合的特征選擇方法,首先利用五種特征選擇算法得到X與Y的相關系數coefj,然后通過k種不同特征對相關系數進行排序,最后綜合五種特征選擇排序結果選擇出排名前t的特征子集F_select。
本研究的特征選擇算法如圖1所示。
2.3 特征提取
本研究提取了三類特征用于訓練用戶畫像模型: 基本特征、二元特征和關聯特征。
1) 基本特征
首先對數據庫數據屬性進行篩選、離散化處理得到離散化特征;然后根據特征選擇方法選擇特征。假設離散化屬性直接分為K個特征,例如性別直接劃分為男、女兩個特征。非離散化屬性則采用等距離劃分算法與等頻率劃分算法。
算法1: 多指標融合的特征選擇算法
輸入:屬性特征X,標簽特征Y,特征選擇方法Methods={F1,F,2F3,F4,F5}。
輸出:特征子集F_Select。
步驟:
1.F_Select←φ
2.Merge←φ//相同特征的相關系數排序集合
3.foreachFi∈Methodsdo
4.coefi←Fi(X,Y)
5.Sort(coefi)
6.Merge=Merge∪coefi(X,Y)
7.endfor
8.Sort(Merge)//綜合5種特征選擇結果排序
9.foreachi∈[1,t]//do選擇排名前t的特征子集
10.F_Select=F_Select∪Merge[i]
11.endfor
12.returnF_Select//輸出特征子集
等距離劃分算法:在每個屬性上,根據給定的參數把屬性值劃分為距離相等的斷點段,假設某個屬性的最大屬性值為χmax,最小屬性值為χmin,用戶給定的參數為K,則斷點間隔為δ
為此得到此屬性上的斷點為χmin+iδ(i=0,1,…,K)。
等頻率劃分算法:根據給定的參數K把m個對象分段,每段中有m/K個對象。首先將此屬性在所有實例上的取值排序,然后每隔m/K取一個值作為斷點。
2) 二元特征
提取二元特征是指對不同類型的特征進行兩兩組合后利用選定的特征選擇算法進行特征選擇。
假設離散化之前的特征集合為F={f1,f2,…,fm-1,fm},離散化之后的特征集合為F1={f1_1,f1_2,…,fk_1,fk_2,…,fk_e,…,fm-1_r,fm_t},其中,fm表示一共有m個特征,fk_e表示特征fk離散化后的第e個離散特征。則組合后的二元特征集合為F2={f1_1Xf2_1,…,f1_1Xfk_e,…,fm-1_rXfm_t}。
3) 關聯特征
利用關聯規則挖掘算法計算特征組合與目標屬性Y的關聯強度,然后為每個特征組合計算在該目標屬性中不同取值上的關聯強度熵,據此得到該特征組合的權重weight,根據所有特征權重集合results_weight排序得到排名前p的特征組合,用于后續的模型訓練。本文提取關聯特征的算法如算法2所示。
算法2中,LK代表頻繁K項集,all_frequents代表頻繁項集集合,apriori-gen(LK-1)函數根據Lk-1中的頻繁項集連接、剪枝產生候選K項集CK;D是由基本特征X組成的數據集,函數Sort(results_weight)對所有關聯特征根據權重進行排序。
得到上述三種特征后,按照如下方式構建模型的特征庫,其中top_n表示選取排名前n的特征。
基本特征×top_n二元特征×top_m關聯特征
(6)
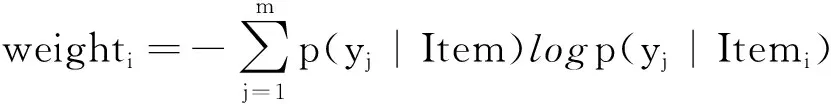

圖4 基于Stacking的組合模型架構Fig.4 Architecture diagram of stacking model
3 Stacking組合模型
Stacking組合模型是指將多種分類器組合在一起來取得更好表現的一種集成學習模型。本文采用邏輯斯蒂回歸(logistic regression,LR)、支持向量機(support vector machine,SVM),決策樹(decision tree,DT),隨機森林(random forest,RF)和Bayes(樸素貝葉斯)五種單一分類器模型構建Stacking組合模型,采用兩層疊加式框架,第一層對數據集data進行K折交叉驗證訓練多個單一分類器模型,然后將第一層訓練模型的輸出加入原訓練樣本集作為輸入,在元分類器下訓練第二層模型,得到一個最終輸出。其中單一分類器模型中預測效果最好的模型作為第二層模型訓練的元分類器。基于Stacking的組合模型架構如圖4所示。
Sacking算法如算法3所示。
算法3:Stacking模型組合算法
輸入:數據集data,特征選擇方法Models,交叉驗證次數K。
輸出:分類結果output
步驟:
1.output=φ
2.foreachclf∈Modelsdo
3.predicted=φ//得到候選K項集
4.foreath(train,test)∈cross_validation(K,data)do
5.clf.fit(train)//訓練分類模型
6.predicted=predicted∪clf.predict(test)//得到預測結果
7.endfor
8.data=data∪predicted//將預測結果加入預測樣本特征
9.endfor
10.output=bestmodel.fit(data)//對關聯特征進行排序
11.returnoutput//輸出分類結果
其中,函數cross_validation(K,data)是對數據集進行K折交叉驗證,bestmodel表示第一層模型中分類效果最好的單一分類器模型,在第二層模型中做元分類器。
本文的Stoceking模型組合算法時間復雜度分析:假設每個單一分類模型的訓練時間復雜度為O(M),由于在stacking模型組合過程中需使用K折交叉驗證的方式訓練每個單一分類模型,故Stacking模型組合算法的訓練時間復雜度為O(Models·K·M)。
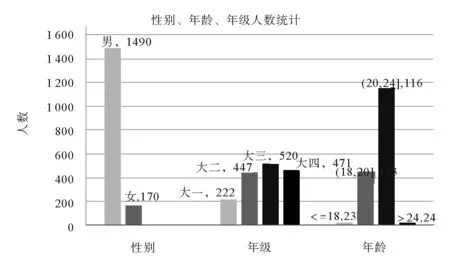
圖5 性別、年級、年齡的人數分布圖Fig.5 Population distribution of sex, grade and age
4 實驗結果與分析
4.1 數據集描述
選取校園網訪問行為日志作為實驗數據,共有9 963個學生55個屬性,約1 155.6萬條日志數據。通過日志數據的篩選、離散化得到1 660個學生樣本及91個標簽。其中性別、年級和年齡的人數分布如圖5所示。
通過圖5可以看出性別標簽中男女比例約為9:1,說明了男生上網人數比較多。四個年級中大一上網學生人數比較少,其余三個年級上網比例較為均勻。年齡標簽屬性中在(20,24]年齡范圍中的學生上網人數比較多。由此發現日志行為數據的屬性分布不均衡,故進行二元特征提取和關聯特征提取是有意義的,不僅可以擴展原始數據,而且可以避免過擬合現象。
3.2 實驗結果與分析
基于用戶畫像模型,為了顯示不同特征集合的有效性,本文采用的評價指標主要有精確率(Precision)、召回率(Recall)和F-Measure值(F-Measure為Precision和Recall的加權調和均值)。
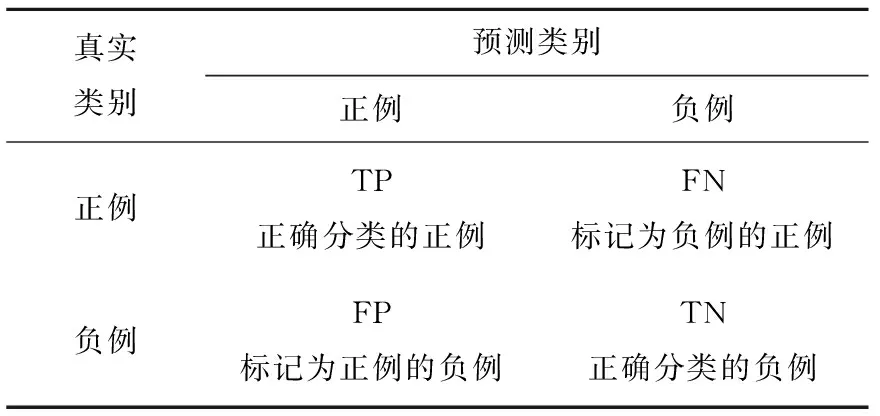
表1 混淆矩陣Tab.1 Confusion matrix
由表1混淆矩陣,得到精確率、召回率和F-Measure值的定義如下:
,
(7)
,
(8)
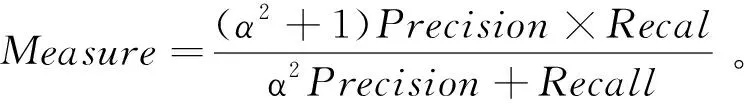
(9)
當參數α=1時,是常見的F1,即:
(10)
由于F1集成了Precision和Recall的值,故當F1較高時能更好地說明實驗方法的有效性。
為驗證本文提出方法的有效性,在性別、年級和年齡三個維度上進行實驗。
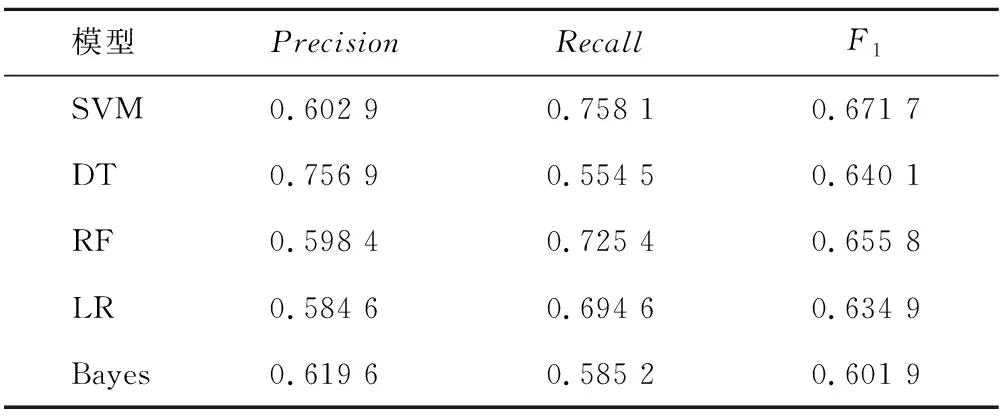
表2 基本特征下單一分類器對性別的分類實驗最優結果Tab.2 The optimal results of a single classifier for gender classification under basicfeatures
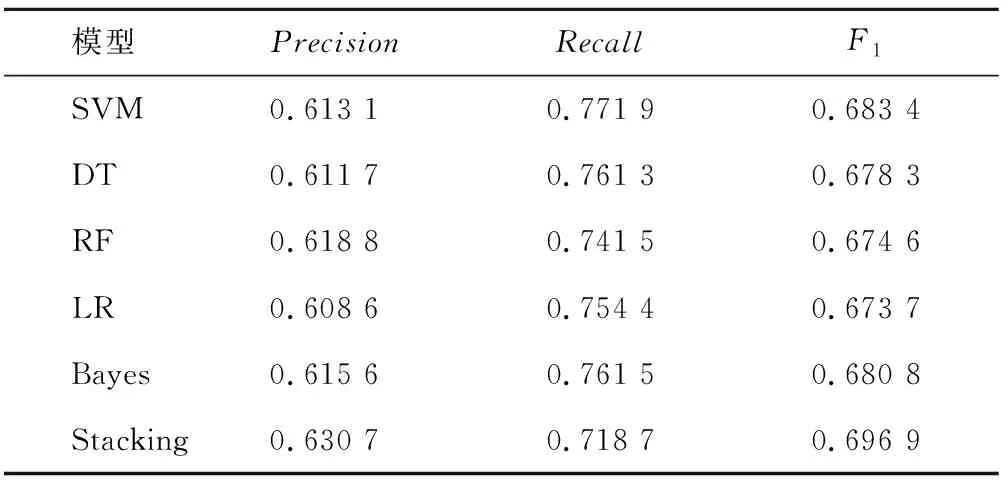
表3 特征組合下各分類器模型對性別分類的最優結果Tab.3 The optimal results of the classifier model for gender classification under the feature combination
1) 性別標簽自動識別結果與分析
本組實驗基于校園網行為日志數據,對性別標簽進行用戶畫像研究。表2列出了基本特征下各單一分類器模型的最優實驗結果。其中,RF和SVM對性別分類的實驗結果較好,調和平均值F1均達到0.65。在組合標簽下單一分類器模型和Stacking組合模型最優實驗結果如表3所示。通過表2與表3對比發現每一個單一分類器模型在組合標簽上的F1值均比基本標簽上有較大提高,證明了特征標簽可以提高對性別的分類結果。由于RF的結果最優,所以采用RF為Stacking組合模型第二層架構的元模型,表3中組合模型的F1值達到了實驗的最優值0.696 9,可見,本文的用戶畫像方法可以提高性別預測的結果。
2) 年級標簽自動識別結果與分析
本組實驗基于校園網行為日志數據對年級標簽進行用戶畫像研究。表4和表5分別給出了基本方法和用戶畫像方法下,對學生年級分類的模型最優結果。由表4可以看出,在基本特征下RF對年級的分類效果最好,其次是DT、LR、SVM,最差的是Bayes。由表5看出,在組合標簽下,DT對年級的分類效果較好F1達到0.396 4,LR的分類效果最差。綜合表4和表5可以得出:LR對年級的分類研究結果一般;相比基本標簽,組合標簽下模型的訓練結果的F1值均有所提高,證明了組合標簽有助于提高對年級的分類結果;由于單一分類器模型中DT的訓練結果最好,故將DT用于組合模型中的第二層模型訓練中,得到組合模型下對年級分類的F1值為0.412 1,相比單一分類器模型實驗下的最好調和均值F1提升了12.28%,證明了Stacking組合模型對提高年級的準確性有顯著的效果,在實際應用場景中可以更準確地捕獲用戶屬性,更好地為校園網管理工作提供精準服務。故組合多種單一分類器的Stacking模型是有價值的。
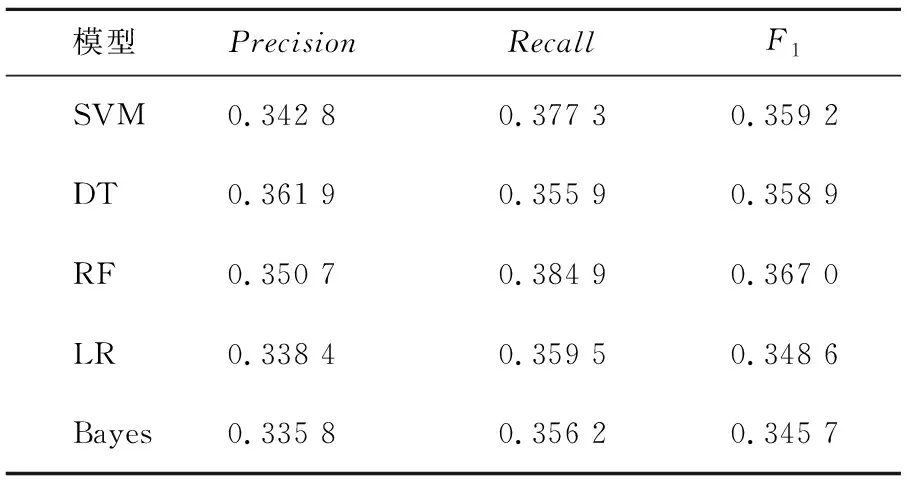
表4 基本特征下單一分類器對年級的分類實驗最優結果Tab.4 The optimal results of a single classifier for grade classification under basic features
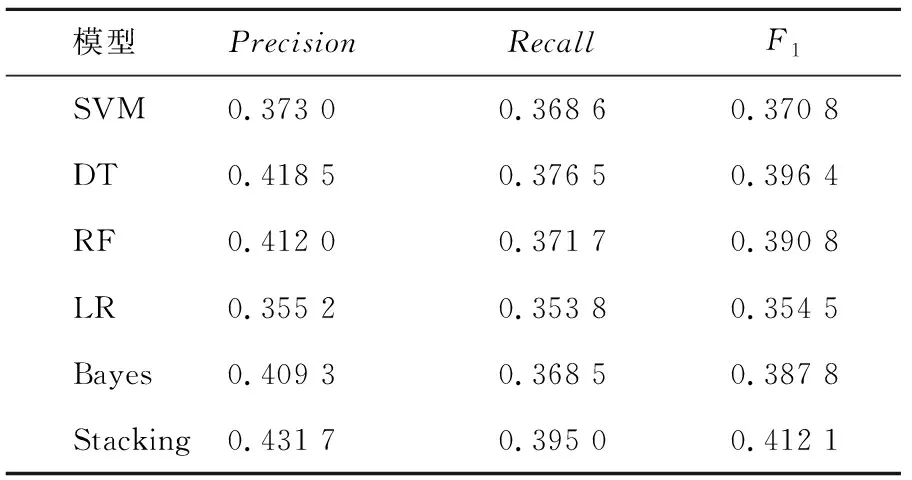
表5 特征組合下各分類器模型對年級分類的最優結果Tab.5 The optimal results of classifier model for grade classification under feature combination
通過對網絡日志樣本數據集中的學生用戶性別和年級的分類實驗結果分析可以得出,本文提出的方法比傳統分類方法可以獲得更好的屬性預測結果。
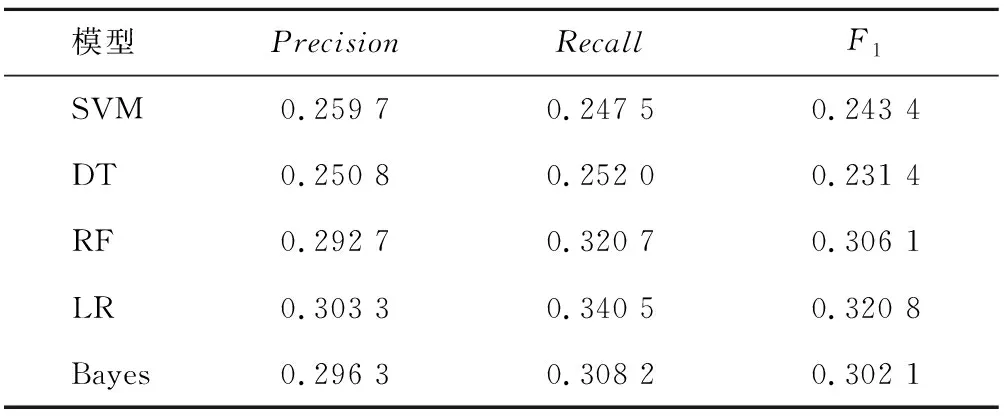
表6 基本特征下單一分類器對年齡的分類實驗最優結果Tab.6 The Optimal results of a single classifier for age classification under basic features
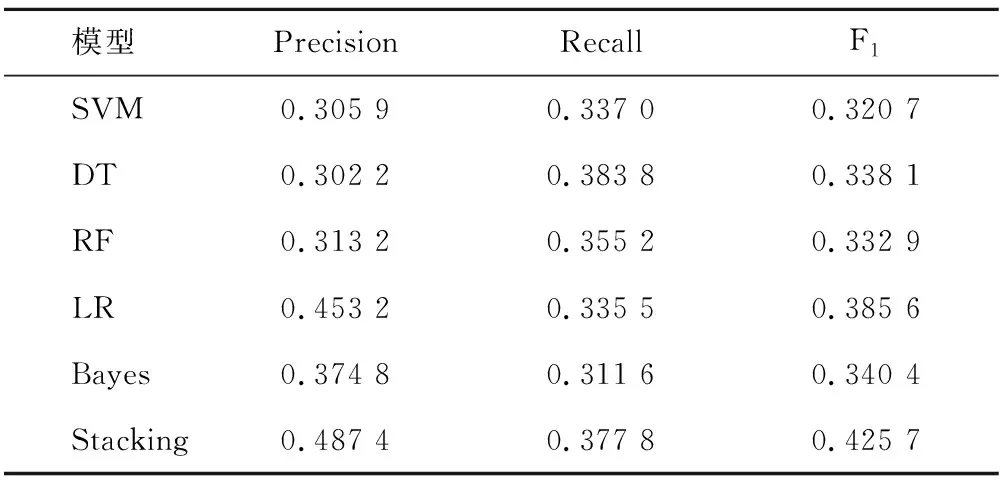
表7 特征組合下各分類器模型對年齡分類的最優結果Tab.7 The optimal results of the classifier model for age classification under the feature combination
3) 年齡標簽自動識別結果與分析
該組實驗基于校園網行為日志數據對年齡標簽進行用戶畫像研究。表6和表7分類給出了傳統的單一分類器模型和本文基于Stacking組合模型的用戶畫像方法下的實驗最優結果。通過對比可以發現基于組合標簽下的Stacking組合模型,對年齡的識別結果得到了提高,證明了組合標簽以及Stacking組合模型對提高年齡分類結果是有效的。
4 結論
相對于傳統的用戶畫像方法,本文提出的基于上網行為日志的用戶畫像方法,側重于對用戶標簽進行組合,并利用Stacking組合模型來避免單一分類器模型的不足。通過在校園網行為日志數據上的實驗分析,證明了本文所提出的基于上網行為日志的用戶畫像方法顯著提升了對性別、年級、年齡屬性的預測效果。下一步的工作中,將嘗試在更大規模的數據集上,組合更多的單一分類器模型進行實驗。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
