中醫脈診信號的無監督聚類分析研究
2018-09-19 01:05:10馮冰李紹滋
智能系統學報 2018年4期
馮冰,李紹滋
(廈門大學 信息科學與技術學院,福建 廈門 361000)
在傳統中醫學中,作為中醫四診之一的脈診扮演了相當重要的角色,傳統中醫師通過手指感知病人的脈動來獲取脈搏信息,從而對人體器官的健康狀況進行判斷。中醫師之所以能夠做到這點,是因為脈診是對人的整體健康狀況進行考察的一種信息獲取方式,在臨床診斷中,脈診扮演了非常重要的角色,兼具研究和現實意義。脈搏信號是一種人體生物信號,其中包含了大量人體生物信息。從中醫的觀點來看,個體脈搏信息中的內容,很多都能直接被解讀為單個個體的生理或者病理的信息[1]。因此,通過脈搏信號,我們可以了解個體身體的狀況和變化。脈搏信息也能夠為我們進行疾病的診斷提供一些基礎的信息。
然而長期以來,脈診都依賴于醫生在病患身上采集信息之后,進行主觀地判斷。當然,在中醫的研究上為了便于記憶,醫師們將這些判斷形象化為一些“脈象”。但是在臨床診斷和教學中,醫生與醫生之間對于脈象的體會不同,會導致他們對病人脈象的區分標注不同,也就是說,因為醫生的個體差異,比如個人經驗的多寡,個人主觀的因素,都會導致脈象判斷的不同[2-3]。因此,這對于脈診的客觀化,以及中醫的客觀化,都是一個大的制約。
隨著中醫客觀化工作的推進,脈診技術也越來越走向客觀化和儀器化。然而,如何對儀器所檢測和收集到的信息進行解讀,卻又回到了原來脈診診斷主觀化的問題上來。因為傳統的機器學習方法,依賴于對大量的脈診數據進行標注,然后再利用標注的數據,從中學習到特征,從而構建起一個脈診診斷的智能算法。假若標注的過程不夠客觀,就難免影響到最后的分類效果。
本文提出的方法,是先對脈搏信號數據進行預處理(去基線漂移和歸一化),然后提取特征,最后用FCM聚類算法進行聚類,將結果與粗分類的結果進行對比。本文旨在提出一個無監督的客觀化方法。在中醫專家對數據進行標注之前,先根據信號的特征,進行粗線條的分類,為客觀化提供依據。如果在更大規模的數據支持下,對特征進行進一步地優化,有理由預期無監督聚類分析可以得到更好的效果。
1 相關研究工作
脈診信號的模式分類研究,在脈診客觀化的過程中,扮演了核心的位置。脈診信號的自動識別以及準確分類,是完成相關模式分類工作的預備條件。現階段,在提取脈象信號特征的方法上,較常采用的是時域分析法[4],但脈象信號的時域特征存在一些自身的問題,如差異性小,區分脈象較為困難。所以,大多數研究人員都通過在時域特征之上結合頻域特征的方法來獲取脈象的特征頻譜,從而將可顯著區分的特征從信號的頻域中找出,其中較為常用的方法為功率譜分析與倒譜分析[5]。
此外,為了更好地梳理脈象特征和生理病理兩者間的關聯,以做到令脈診技術進一步客觀化、智能化,很多學者也做了大量的研究工作。李娜等[6]對支氣管哮喘與慢性胃炎患者脈圖的比較研究,提取時域分析特征,通過實驗證明了支氣管哮喘與慢性胃炎在“寸”部存在脈圖時域特征差異之間的相關性。張冬雨等[7]提出了兩類基于ERP彈性測量距離的脈搏信號形態分類方法,用于脈搏信號的分類。實驗證明,同現有的脈搏信號分類方法相比,他所提出的彈性核函數——高斯彈性測度距離核函數。對脈搏信號的分類和復雜時間序列的分類,都展現出較好的效果。
在神經網絡被廣泛應用到中醫客觀化的大背景下,用計算機進行脈診特征分析,帶來了進一步的效率和準確性的提升。人工神經網絡是一種自適應的非線性動力系統,目前有不少學者利用人工神經網絡對脈搏信號進行分類和識別,也取得了不錯的效果。如郭紅霞等[8]提出的基于小波包分析和BP神經網絡的中醫脈象識別方法,利用小波變換具有揭示信號時頻兩域細節和局部特征的能力,提出了將脈象信號的小波包分析和BP神經網絡相結合以達到識別中醫脈象的目的。小波包分解中的第3層從低頻到高頻的8個頻帶的信號能量,被用作脈沖識別的輸入層,脈沖信號通過小波包分析,然后輸入神經網絡。通過該算法,步長函數和迭代的改進不僅縮短了網絡訓練時間,而且還利用小波包分解系數進行重建信號,并在此基礎上獲得更好的結果。此外,Zhang等[9]也通過小波變換提取時域和頻域信息,進行了相似的實驗,通過更細致地調校,網絡的正確識別率有了進一步的提升。
然而,在上述方法中,無一不嚴重依賴于大量中醫專家對脈搏數據的分類和標記,然而正如前文所提及,醫生之間因為個體差異或者主觀因素,會對脈象的判斷有所不同,當數據量大,且分別來自不同醫生的標注時,難免出現標注不準確的情況。這樣的狀況,對目前的中醫客觀化,特別是脈診的客觀化,起到了阻礙的作用。如果我們可以提出一種方法,減少人的主觀判斷信號的成分,直接從脈搏信息中進行特征提取,然后通過聚類的方法進行粗分類,這樣的方法具備一定的理論價值。在當下醫療資源不均衡發展的現狀中,醫學儀器價格逐漸走低,而醫學專家數量卻十分有限,在解決醫療資源不匹配的問題上,粗分類可以扮演一個先期分診的作用,使得它同時還具有一定實用價值。
2 中醫脈診的無監督分類方法
文中提出的特征提取和分類的方法,是由3個主要步驟構成的:數據的預處理、特征提取過程和聚類過程。在這里,首先選擇一個較好的特征來代言脈搏信號的相關數據,然后從訓練數據中以一種無監督的形式,來進行聚類。
2.1 基于雙樹復小波變換的去除基線漂移方法
脈象信號是一種相當復雜的生物醫學信號,它的特點包括背景噪聲大以及隨機性強。脈象,體現了人身中的各類復雜的生理狀態周期,它反映了人們在外部環境以及內部生理特征綜合作用下的整體生理變化。因此,脈象信號具有非線性、整體性和可調性等特點。由于脈象信號受整體環境影響較大,不可避免的結果就是采集到的脈搏信號會因呼吸和儀器本身而引起基線漂移。目前,基線漂移的去除方法有很多種,如小波變換法、自適應濾波、插值擬合法、滑動平均濾波等[10-12]。其中被最廣泛應用的是離散小波變換法,不過離散小波變換法因為具有對平移的高度敏感性以及容易出現頻率混疊等缺點,為實驗增加了一些不確定性因素。為了克服以上缺點,本論文則選取了雙樹復小波變換法來進行基線漂移的去除工作。
雙樹復小波(dual-tree complex wavelet transform)的概念最早由金斯伯里(Kingsbury)率先提出,該算法在雙樹濾波基礎之上,又進行了一層優化,使其不單具備了一般復小波算法的優點,還可以完全重構原始信號,它屬于對一維雙樹復小波的一種推廣。
一維雙樹復小波:


由一維雙樹復小波推廣,其中雙樹實小波為
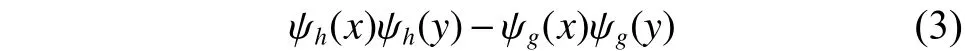
雙樹復小波方法采用了二叉樹結構的兩路變換,一樹生成變換的實部,一樹生成虛部(如圖1所示)。該方法的思路主要是:首先對于第1層進行分解,如果兩樹濾波器間的延遲恰好等于一個采樣間隔,那么就可通過區別b樹種第1層的二抽取令其正好采樣到a樹種因二抽取所丟掉的采樣值。
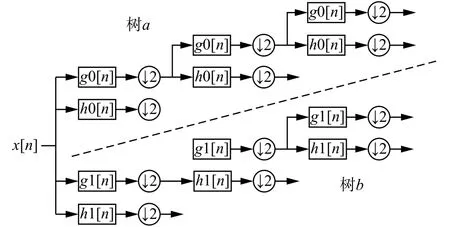
圖 1 雙樹復小波二叉樹結構Fig. 1 Double tree complex wavelet binary tree structure
好的數據預處理,對脈搏信號的要求比較高,要求獲取的脈搏信號穩定性比較好,并且具有比較好的可重復性。在單個個體的同一體質條件下,脈搏信號能夠保持一定的持續性和穩定性。在這樣的條件下,我們實施以去除基線漂移的處理,使得后續的信號分析工作成為可能。
2.2 基于小波變換的脈象信號的去噪與歸一化
原始的脈搏信號是不適合作為分類器的直接輸入信息的,首先因為原始信號在未經處理前,維度過高,且有噪聲干擾;其次沒有進行歸一化,相似性不易被捕捉到。為了改善后續的分析和識別,我們先將原始脈搏信號進行去噪處理,然后進行歸一化過程,再利用一些通用的波形信號特征學習的手段,將波形信號轉換成時空序列的表示,是數據預處理過程中很重要的一個步驟。在本文的實驗中,首先基于小波變換,用非線性閾值法,從而對脈象信號進行一個去噪處理,然后再進行一個歸一化的過程:我們將抽樣頻率統一調整為128 Hz每個心動周期,即將信號進行預處理之后,再進一步做一個歸一化處理,其中包括對數據進行補零,然后將一個心動周期中的脈搏波信號長度進行調整,最后統一為128點。圖2為補零操作完成后的一個心動周期,其中縱軸代表信號強度,橫軸則示意了每個周期內采樣點的數目(在圖中第68個采樣點后補零至第128個采樣點)。

圖 2 脈搏信號歸一化單心動周期Fig. 2 Pulse signal normalized single cardiac cycle
2.3 基于梅爾倒譜系數的特征提取
多種時域分析和頻域分析的手段,比如經驗模態分解方法、傅里葉變換和小波分析都被廣泛地應用于脈搏信號的基本分析過程中[13]。尤其是傅里葉分析、小波分析這樣的頻域分析方法,對周期性的信號進行數值分析,將脈搏信號中復雜的周期性變化進行分解,得到不同頻率的頻譜變化,這樣的做法,利用了脈象信號自身的周期性,很好地抓住了脈搏信號中的特點,從而使得后續的工作可以把從其間得到的頻譜數據與人體的生理和病理相關狀態關聯起來[14-15]。
本文將采用梅爾倒譜系數這樣更成熟而且高層的特征。在語音處理領域,梅爾倒譜系數(MFCC)是一個非常常用而且成熟的特征[16]。該特征根據人耳聽覺的特征要點,用Mel標度頻率域提取出來的倒譜參數,進行非線性轉換,從而做到使得“處理之后的特征”,與“人類的真實聽覺特征”相符。其優點在于:當用于信噪比較低的狀況時,仍可做到較好的識別性能。MFCC這種特征的優良性質,在于它對于信號的性質并沒有過高的要求,對于輸入的信號也沒有太多的預設和限定。所以MFCC特征與其他特征相比,具有更好的魯棒性。因此本文選用它來對脈診的輸入信號進行特征提取的處理。
倒譜分析可以分為3步過程,首先,將原波形信號經過傅里葉變換得到頻譜:

在兩邊取自然對數:
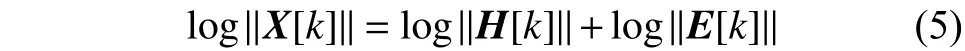
最后在兩邊取逆傅里葉變換得到
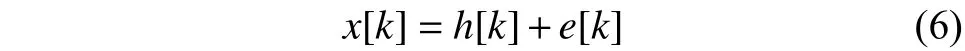
式中:x[k]就是倒譜,e[k]與h[k]分別是倒譜的高頻和低頻部分,其中的低頻部分h[k]也就是本文真正關心的描述性特征。只需將頻譜通過一組Mel濾波器就得到Mel頻譜,在Mel頻譜上面獲得的倒譜系數h[k]就稱為Mel頻率倒譜系數。
MFCC特征的特點,是在頻率坐標軸上非均勻的濾波。具體來說:在低頻區有很多濾波器,分布較為密集,而在高頻區域,濾波器的數目就變得較少,分布也變得稀疏(如圖3)。這樣的特點,可以把特征的關注點放在某些特定的頻率,比較符合脈診信號在中醫診斷中的特點,因此可以較好地抓住相關信號的本質特征。
因為脈象識別本質上是一個模式識別問題,而在模式識別問題中,特征的提取是其中的關鍵一環。因此,在對原始的脈搏信號特征化過程中,選擇時域信號當中最能夠反映脈象的形態特點的參數,是一個關鍵點。在這里選取MFCC提取的特征作為輸入向量,是為了更好地進行下一步,即脈診信號的聚類工作。

圖 3 MFCC非線性頻譜(橫軸與縱軸分別代表頻率與濾波)Fig. 3 MFCC non-linear spectrum (horizontal for frequency, vertical for filter)
2.4 基于 Fuzzy C-means (FCM)的聚類
在前述過程中,通過對數據進行一些基本處理,提取出了信號的高層特征。整個流程(如圖4)的最后一步是聚類過程。在聚類過程中,使用了Fuzzy C-means (FCM)聚類算法,它允許同一數據屬于多個不同的類。FCM算法與K-means算法的不同,在于同一個數據并不單獨屬于一個分類,而是可能屬于幾個分類。

圖 4 脈象信號處理流程Fig. 4 Structure model of group organizations
傳統的聚類算法通常需要預先確定聚類中心的數量,其缺點是容易降低聚類結果的客觀性,不僅如此,傳統算法得到的結果也容易陷入局部最優解。而本文采用的模糊C均值(fuzzy c-means,FCM)算法,與傳統的算法相比,在客觀性上進行了提升。它首先執行優化的模糊目標函數計算,以獲得單個采樣點相對于每個類別中心的隸屬度,并以此來進一步確定這個采樣點的歸屬。FCM在不少應用領域均被采用,比如醫學診斷和目標識別等[17-18]。
FCM算法的做法,是首先將n個向量xi(i=1,2, · ··,n)分為c個模糊群,并找出每個群的聚類中心,接下來非相似性指標的計算價值函數,令這些聚類中心能使價值函數達到最小。傳統聚類算法(含K-means算法等),可以被稱作是硬聚類算法HCM(hard clustering method),而FCM算法與HCM這樣的硬聚類算法之間的重要區別,是在FCM采用了模糊的劃分,從而使得單個給定采樣點均使用[0,1]的隸屬度數值,來明確其歸屬單個群的狀況。與前面介紹的模糊劃分相同,整體分類中的隸屬度矩陣U也是由取值在[0,1]的元素構成的。同時,歸一化的規則明確了單個數據集的所相加得到的隸屬度總和必須等于1。
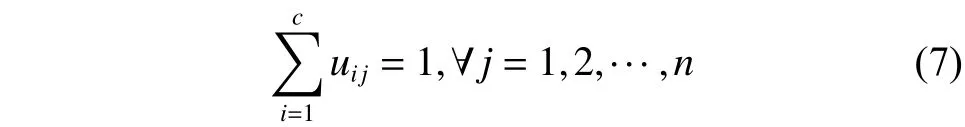
式中:uij表示了第j個元素屬于第i個類群的隸屬度值。因此,FCM的目標函數就是:
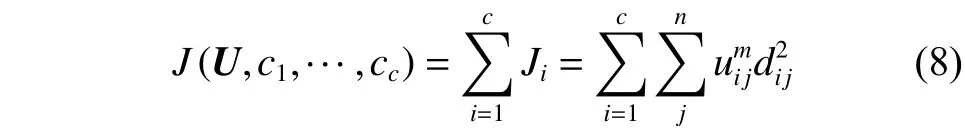
式中:uij的取值在[0,1];ci則表示模糊群第I類的聚類中心,dij=||ci-xj||則計算了第I類聚類中心與第j個采樣點之間的歐式L2距離;此外m∈[1,∞)則是一個指數加權。
為了求出FCM目標函數的最小值,可以將其轉換成下列函數,以進行最小化的求解:

式中:λj,j=,它們是拉格朗日乘子的n個約束條件。接下來,需要對所有的輸入參量進行求導,從而令式(9)取得最小值,可以得到:

由上述求得的解不難看出,模糊c均值聚類算法可以被歸結為一個簡單的迭代過程。
3 實驗結果
本文所選用的實驗環境是MATLAB運行在2.8 GHz Intel i5 CPU,8 GB內存平臺下。本實驗中采用的樣本是69名健康大學生的脈搏數據,其中脈搏數據的頻率為60~80次/min,而頻率則主要分布在0~40 Hz的區間范圍內,原始數據的采樣頻率為 512 Hz。通過降頻處理,將原512 Hz頻率的數據降低到了128 Hz。在預處理的過程中,進行了歸一化和去均值,然后將一個心動周期中的脈搏波信號長度進行調整,最后通過補零統一調整為128點。為了將無監督聚類的效果進行評估,將歸一化之后的信號進行粗分類為標記的4種基本類型(如圖5),再通過聚類的方法進行試驗。
在實驗中,通過對比不同的特征源,分別使用基于線性距離度量特征(LD)、功率譜分析(PSA)、線性預測編碼(LPC)、線性預測倒譜系數(LPCC)獲取的特征,與MFCC倒譜分析獲取的特征進行對比;同時使用傳統的硬聚類的方法(k-MEANS、KNN)與模糊C均值的效果進行對比。
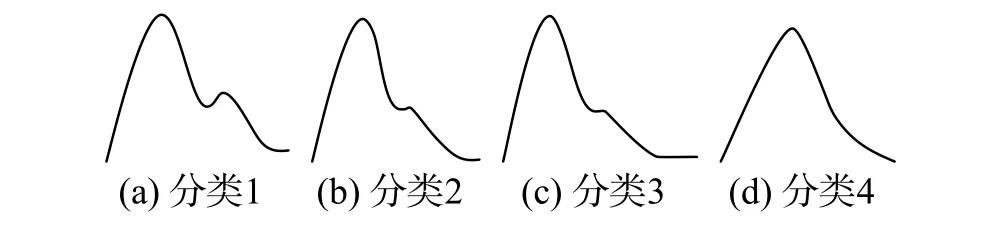
圖 5 單脈搏信號粗分類基本類型Fig. 5 Structure model of group organizations
另一方面,還比較了隸屬度值對聚類結果的影響。隸屬度函數A(x)越接近于1,表示x屬于A的程度越高,A(x)越接近于0,則表示x屬于A的程度越低。使用取值于區間[0,1]的隸屬函數A(x)是FCM中最常用的,但是如果我們放寬FCM隸屬度以及其歸一化的條件,令所有的樣本針對各個類的隸屬度的總和值可以大于1,這樣的改變,是否可以獲得較好的結果呢?
在實驗中,對比了當模糊C均值的隸屬度等于1時,和當我們放寬條件,允許模糊C均值的隸屬度值大于1時的結果。實驗的結果顯示,使用倒譜分析獲取的特征源以及模糊C均值的方法進行聚類,對于脈象的識別準確率相對較高(如表1)。同時我們觀察到,當放寬隸屬度的條件,允許模糊C 均值的隸屬度值大于1時,實驗效果會更好一些。

表 1 多聚類方案與特征源實驗效果對比Table 1 Comparison experiment of multi-clustering scheme and feature source %
此外,單獨考察了效果較好的3類特征提取方案(MFCC、FFT和LPC),觀察它們在相同的聚類方案(FCM,隸屬度>1)情況下,對每個單脈搏信號的準確分類數量(圖6)。可以觀察到,選用MFCC倒譜分析獲取的特征,配合以模糊C均值的聚類方案,在所有的單個脈搏信號粗分類上,都獲得了較佳的效果。

圖 6 3種特征方案對單脈搏信號的準確分類數量Fig. 6 Accurate classification of single pulse signals by three feature schemes
4 結束語
在中醫研究中,脈象是對人體機能的狀況進行分析的重要指標之一。一個有經驗的中醫,可以通過脈象的模式變換,判斷出病癥的緊迫性、位置和相應的性征。脈診的客觀化也是中醫客觀化研究中的一個重點。本文提出的一種客觀化的方法,首先是通過脈象信號取漂移預處理,然后進行歸一化,再通過頻域信息特征的提取和分析,然后用其作為脈象信號識別過程中的輸入向量,再采用模糊C均值的聚類方法,對脈象的信號進行識別。作為一種無監督的分析方法,它可以在沒有中醫專家的參與下,進行脈象信號的粗分類的識別。也可以作為有監督時特征提取的依據,進行進一步優化研究。
本文旨在提出了一個無監督的脈診客觀化方法。在中醫專家對數據進行標注之前,先根據信號的特征,進行粗線條分類,為客觀化提供依據。同時,在解決醫療資源不匹配的問題上,粗分類可以扮演一個先期分診的作用,可以用于人群分類的脈診預判斷(比如孕婦與非孕婦,心臟病人與心臟健康人群)。在大數據的時代背景下,在醫院擁有更大規模的數據情況后,可以將無監督的算法進一步細化,從而為節省醫療資源,提高分診效率,做出進一步的貢獻。
猜你喜歡
世界科學技術-中醫藥現代化(2021年9期)2021-12-31 03:30:28
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中國臨床醫學影像雜志(2019年2期)2019-04-25 06:15:42
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
湖南中醫藥大學學報(2015年1期)2016-01-06 01:06:43
