大樣本數據標準化率的SAS宏實現*
2018-09-20 06:48:12夏雷震HeziFu劉紅波
中國衛生統計 2018年4期
關鍵詞:標準化
夏雷震 Hezi Fu 金 城 缐 偉 劉紅波△
流行病學研究過程中,經常會遇到率的比較問題,當各組觀測的內部構成,諸如年齡、性別等存在較大差異時,直接比較各組的粗率(合計率)是不合理的,通常應該對其進行標準化來消除內部構成不同的影響。對于小樣本數據,一般只涉及幾組率的比較而不是多組率的比較或者是內部構成簡單(比如只有年齡這一混雜因素),通常結合統計相關教材借助Excel就能較容易、簡單的計算出標準化率;但在這個信息化時代,我們經常會遇到復雜嵌套關系下的多層次組群結構的海量數據,如各省市疾病預防控制中心的傳染病報告數據、疾病死亡數據,某疾病各年份患病情況等,對這種含有多個混雜因素、多分組的數據,利用教材里公式和Excel的統計匯總功能來計算標準化率常常會遇到很大的困難,且計算過程繁瑣容易出錯[1-2],這時我們最好借助統計軟件來完成[3]。SAS是最常用的數據處理和統計分析的軟件之一,本研究通過編寫SAS宏程序實現大樣本數據率的標準化,希望能夠幫助科研工作者更加方便快捷的解決標準化率的計算問題。
基本原理
率的標準化法就是在指定的標準構成條件下計算標準化率,以便于對多組率進行對比。對于標準人群的選擇有三種方法,分別是任選一個對比組的人群、各組人群之和以及有代表性的、穩定的、數量大的人群,如全國、全省的數據[4],選擇前兩種人群的標準化法稱為直接法,選擇后一種人群稱為間接法。無論是直接法還是間接法,它們標準化的基本思想是先計算出標準人群的內部構成比例(比如年齡構成比)當作權重qi,再計算出各組別(比如各地區)各年齡段的率Pij,最后對各地區計算各年齡段的加權算術平均數∑qiPij[5]。一般情況下,對標準人群的選擇會選擇后兩種,即以各組人群的總和為標準人群計算直接法標準化率和以具有代表性的全國人口為標準人群計算間接法的標準化率,所以本研究以這兩種人群作為標準人群對率分別進行直接標準化法和間接標準化法。
實例分析和SAS宏實現
實例:結節病是一種免疫系統疾病,其發病機制和病因不明確。文獻報道結節病的發生和死亡與年齡、性別有關,也表現出地域性差別。某研究者欲了解結節病的發病特征,調查了2014年的5個地區的47780名在職及退休職工,記錄結節病患病情況,原始數據std.sar形式如表1。
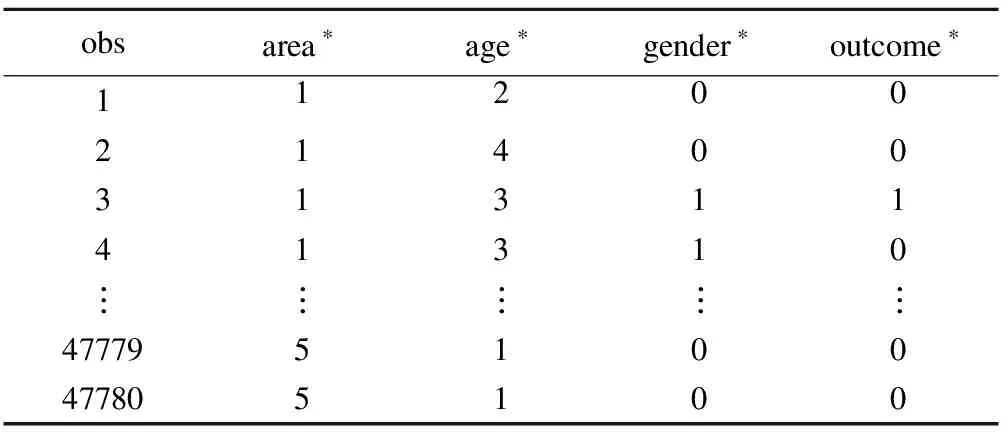
表1 實例中原始數據的形式
*area:1~5代表5個區;age:1~6代表6個年齡段;gender:1=男,0=女;outcome:1=患病,0=不患病
1.選擇所有地區的人口作為標準人群做直接法的標準化率
SAS宏命令如下:
%macro direct_std(data=,outcome=,group=,confounder=,confounder_=);
data standardization;
set &data.;
keep &outcome.&group.&confounder.;
run;/*提取數據中有用的信息*/
proc summary data=standardization nway;
class &group.;
var &outcome.;
output out=crude(drop=_:) n=N sum=cases;
run; /*匯總原始數據五個地區的總人數N,發病人數cases*/
data crude;
set crude;
crude=cases/n;lower_CI=crude-1.96*sqrt(crude*(1-crude)/n);upper_CI=crude+1.96*sqrt(crude*(1-crude)/n);
run;/*計算粗率crude及應用二項分布的正態近似法計算置信區間[5-7]*/
proc summary data=standardization nway;
class &group.&confounder.;
var &outcome.;
output out=summary(drop=_:) n=N sum=cases;
run; /*匯總原始數據各地區各性別年齡別的人數N,發病人數cases*/
data summary;
set summary;
p=cases/n;
run;/*計算各地區各性別年齡別的發病率p */
proc sort data=summary out=summary;
by &confounder.;
run;
proc sql;
create table summary as select *,sum(n) as totall from summary group by &confounder_.;
quit;/*此命令group by后面的變量間需要逗號隔開,故而重復設置了confounder_宏參數*/
proc sql;
create table summary as select *,sum(n) as total2 from summary ;
quit;
data summary;
set summary;
ratio=total1/total2;
run;/*計算以各組人群的總和為標準人群的內部構成(性別年齡別)的構成比ratio */
data summary;
set summary;
rate=p*ratio;
run;
proc summary data=summary nway; class &group.; var rate; output out=adj_rate(drop=_:) sum=adj_rate;
run; /*對各地區按照構成比ratio為權重計算各年齡性別組發病率p的加權算術平均數adj_rate,即為標準化率*/
data adjust;
merge crude adj_rate;
drop cases crude lower_ci upper_ci;
run;
data adjust;
set adjust;adj_cases=n*adj_rate;adj_lower_CI=adj_rate-1.96*sqrt(adj_rate*(1-adj_rate)/n);adj_upper_CI=adj_rate+1.96*sqrt(adj_rate*(1-adj_rate)/n);run;/*計算標準化率adj_rate的置信區間*/
data adjust;
retain area N adj_cases adj_rate adj_lower_CI adj_upper_CI;set adjust;
run;
title “粗率及其置信區間”;
proc print data=crude;run;
title “標準化率及其置信區間”;
proc print data=adjust;run;
%mend;
消除年齡和性別的影響計算各地區結節病標準化患病率的宏參數設置如下:
%direct_std(data=std.sar,outcome=outcome,group=%str(area),confounder=%str(age gender),confounder_=%str(age,gender));
結果輸出為:
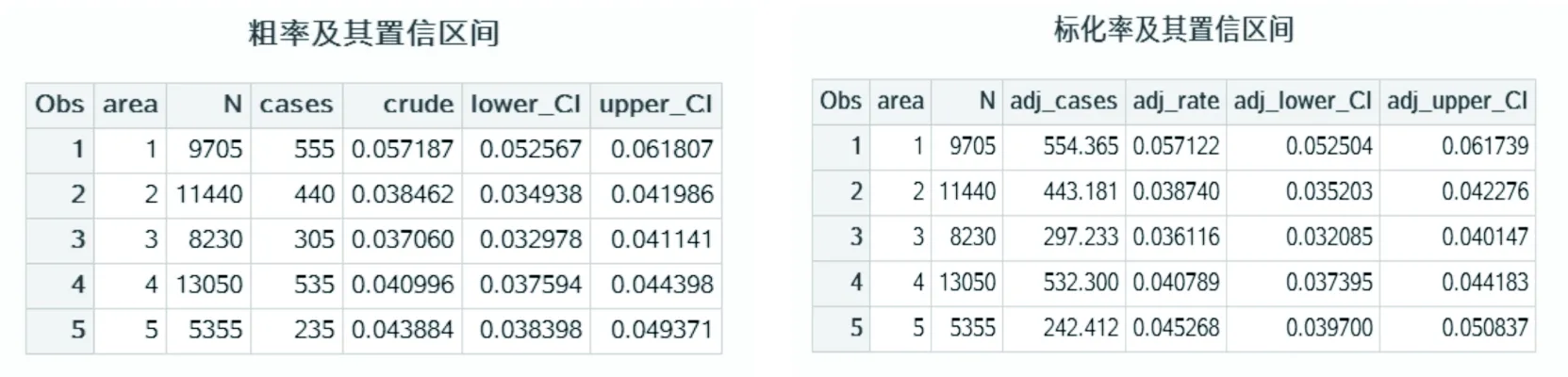
所有結果也可在文件work.crude和work.adjust中查看和導出。如果想消除年齡的的影響計算各地區分性別的結節病標準化患病率的宏參數設置如下:
%direct_std(data=std.sar,outcome=outcome,group=%str(area gender),confounder=%str(age),confounder_=%str(age));
以此類推。
在實際工作中,有時收集不到原始數據std.sar,
只有匯總數據std.sar2,同樣可以計算標準化率,數據形式為:
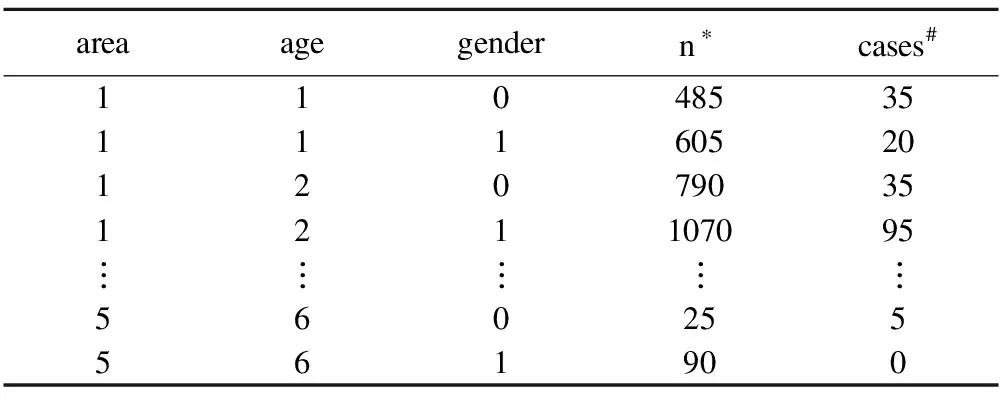
表2 匯總數據的形式
*:不同地區各年齡性別的總人數; #不同地區各年齡性別的患病人數
SAS宏及宏參數設置如下(其中省略部分與上文SAS宏對應位置一致):
%macro direct_std(data=,group=,confounder=,confounder_=,n=,cases=);
data standardization;
set &data.;
keep &group.&confounder.&n.&cases.;
run;
proc summary data=standardization nway;
class &group.;
var &n.;
output out=crude1(drop=_:) sum=n;
run;
proc summary data=standardization nway;
class &group.;
var &cases.;
output out=crude2(drop=_:) sum=cases;
run;
data crude;
merge crude1 crude2;
run;
data crude;set crude;crude=cases/n;lower_CI=crude-1.96*sqrt(crude*(1-crude)/n);upper_CI=crude+1.96*sqrt(crude*(1-crude)/n);run;
data summary;
set standardization;
p=cases/n;
run;
proc sort data=summary out=summary;
by &confounder.;
run;
…
%mend;
%direct_std(data=std.sar2,group=%str(area),confounder=%str(age gender),confounder_=%str(age,gender),n=n,cases=cases);
2.以全省人口作為標準人群做間接法的標準化率
SAS宏命令及宏參數設置如下:
%macro indirect_std(data=,group=,confounder=,n=,cases=,ratio_data=,ratio=);
data standardization;
set &data.;
keep &group.&confounder.&n.&cases.;
run;
proc summary data=standardization nway;
class &group.;
var &n.;
output out=crude1(drop=_:) sum=n;
run;
proc summary data=standardization nway;
class &group.;
var &cases.;
output out=crude2(drop=_:) sum=cases;
run;
data crude;
merge crude1 crude2;
run;
data crude;
set crude;
crude=cases/n;lower_CI=crude-1.96*sqrt(crude*(1-crude)/n);upper_CI=crude+1.96*sqrt(crude*(1-crude)/n);
run;/*以上為計算粗率及其置信區間的代碼,與前文一致,不贅述*/
proc sort data=&data.out=standardization; by &confounder.; run;
proc sort data=&ratio_data.out=std; by &confounder.; run;
data summary; merge standardization std; by &confounder.;run;/*合并匯總數據與標準人群構成比數據,注意兩個數據相同的變量名設置要一樣,比如都為age、gender*/
data summary; set summary; rate=&ratio.*&cases./&n.; run;
proc summary data=summary nway;
class &group.;var rate;
output out=adj_rate(drop=_:) sum=adj_rate;
run; /*對各地區按照構成比ratio為權重計算各年齡性別組的加權算術平均數adj_rate,即為標準化率*/
data adjust;
merge crude adj_rate;
drop cases crude lower_ci upper_ci;
run;
data adjust;
set adjust;
adj_cases=n*adj_rate;adj_lower_CI=adj_rate-1.96*sqrt(adj_rate*(1-adj_rate)/n);adj_upper_CI=adj_rate+1.96*sqrt(adj_rate*(1-adj_rate)/n);
run;
data adjust;
retain area N adj_cases adj_rate adj_lower_CI adj_upper_CI;set adjust;
run;
title “粗率及其置信區間”;
proc print data=crude;run;
title “標準化率及其置信區間”;
proc print data=adjust;run;
%mend;
%indirect_std(data=std.sar2,group=%str(area),confounder=%str(age gender),n=n,cases=cases,ratio_data=std.ratio,ratio=ratio);
其中,數據集std.sar2為匯總數據的形式,如果要對原始數據std.sar運行此宏,只需對原始數據運行如下命令:
proc summary data=std.sar nway;
class area age gender;
var outcome;
output out=std.sar2(drop=_:) n=N sum=cases;
run;
數據集std.ratio為全省人群年齡性別構成比,數據形式如下:
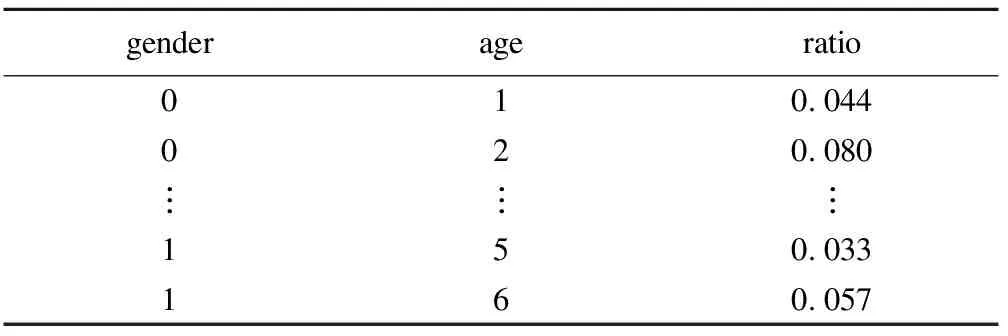
表3 某省人群年齡性別構成比
結果輸出為:
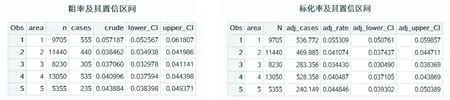
結 語
率的標準化是在疾病的流行病學研究中經常會遇到的問題,而大部分教材只介紹了按照公式計算的方法[5],但在實際工作中,經常會遇到多層次組群結構的大樣本復雜數據,公式的計算常常會有較大的困難,常用的數據處理軟件也沒有專門的模塊來解決這個問題。因此,我們通過上述實例系統的解決了對率進行直接標準化和間接標準化問題,讀者可以根據實際情況選擇相應的SAS宏,通過宏參數設置相應的需要比較的組別和需要消除的混雜因素,并且調整好數據形式就可以簡單、快捷的計算出標準化率。
猜你喜歡
電器工業(2023年1期)2023-02-13 06:31:42
口腔護理用品工業(2021年4期)2021-11-02 08:22:56
機械工業標準化與質量(2018年5期)2018-05-30 09:48:17
中國公路(2017年9期)2017-07-25 13:26:38
水利技術監督(2017年2期)2017-05-17 05:19:25
福建輕紡(2017年12期)2017-04-10 12:56:27
知識經濟·中國直銷(2016年4期)2016-11-07 09:34:05
質量與標準化(2015年7期)2015-07-12 12:21:02
汽車維修與保養(2015年8期)2015-04-17 03:32:51
石家莊理工職業學院學術研究(2014年4期)2014-04-27 14:14:40
