基于屬性關聯相似度的中文簡稱匹配算法研究?
2018-09-28 02:30:06暉董源周
計算機與數字工程 2018年9期
關鍵詞:關聯
郭 暉董 源周 鋼
(1.海軍工程大學電子工程學院計算機工程系 武漢 430033)(2.海軍水文氣象中心 北京 100000)
1 引言
大數據應用中由于數據來源各異、結構不一,為了提高數據分析性能,需要對不一致、不準確的等臟數據進行數據清洗,或對不同數據源的同一數據進行數據集成[1~2]。字符匹配是指尋找表示實體世界中同一實體的字符串,相互匹配的字符串應對具有同義性,可互換[3]。
在中文語言環境中,對于中文固定名詞,如組織機構名等常用簡稱,如“華中科技大學”簡稱為“華科大”或“華科”,研究同一名詞的“簡稱”和“全稱”兩個字符串的匹配算法,其核心在于字符串相似度的度量方法。
本文針對大數據應用特點,以中文固定名詞所在數據源為基礎,采用基于統計方法,運用數據挖掘技術,提出了基于屬性相關度的中文簡稱匹配算法,該算法通過對匹配名詞所處屬性的強相關屬性的數據范圍對比相似度,按照中文簡稱和全稱比量設置置信度,兩者乘積得到匹配度。該算法對大數據中保障數據質量,提高數據分析性能具有重要意義。
2 問題背景
中文語言環境中,對于很多固定名詞,通常會約定俗成的簡短稱謂,即為簡稱。在大數據具體應用中,由于數據采集規范要求不同,數據來源不一,容易出現同一對象有簡稱和全稱兩種不同表述,在對數據進行數據清洗或對不同數據源進行數據集成時,需要對中文固定名詞的“簡稱”和“全稱”字符串進行有效匹配,是提高數據質量的重要途徑。
對中文固定名詞簡稱,通過對中國部分高校簡稱與全稱對比表分析,中文簡稱具有以下特點規律:一是其長度相對全稱要簡短很多;二是簡稱字符串中所有字符在全稱中均有出現;三是簡稱中基本單個字符,有意義詞極少出現。
對中文固定名詞的“簡稱”和“全稱”進行匹配,本質就是字符串的相似度計算。目前,較具代表性的算法有基于相同字詞[4]、基于編輯距離[5]、基于向量空間[6]、基于語義詞典[7]、基于統計關聯[8]和基于語義依存[9]等方法。前三種方法是基于字符串本身分析,且在英文字符串匹配中有較好應用,但在中文匹配中由于涉及到分詞問題,將大幅降低算法準確性,增加執行時間;基于語義詞典、基于統計關聯依托詞典實現,對于中文專屬名詞中生澀詞匯多,簡稱字符串簡短且無意義,基于語義依存對于短中文應用效果較差,所以針對中文固定名詞的簡稱和全稱字符匹配問題,由于其分詞不明,語義不清,文幅較短特點,已有算法在其上應用存在局限性。
因此,在大數據應用背景下,已擁有大量相關數據基礎上,可以考慮使用以統計學為基礎,使用數據挖掘技術,提出一種基于屬性關聯度的中文“簡稱”和“全稱”的匹配算法。
3 基于屬性關聯度的匹配算法
根據對我國高校部分簡稱[10]分析中文簡稱特點,先采用單個字符進行初步匹配,逐步抽取“簡稱”字符串中的單個字符與“全稱”字符串中的所有字符進行逐一比較,并將匹配成功的字符個數與“簡稱”字符串長度相同,從而判斷兩者基本匹配。若中文“全稱”字符串長度n一般不大,算法的時間復雜度O(nlogn)是非常有限。
但由于存在中文簡稱指代不明情況,需要做進一步更加準確的匹配,如“南京大學”“南昌大學”均可簡稱為“南大”。
3.1 算法基本思想
基于屬性關聯度的匹配算法主要基于某一個屬性數據的區分可以由與該屬性密切相關屬性的區分來發現,即可以通過密切相關屬性來辨別某一屬性的數據。假設中文“簡稱”和“全稱”匹配的屬性為A,算法包括四個步驟:選取A的強關聯屬性;分別分析“簡稱”和“全稱”在強關聯屬性的分布相似情況;“簡稱”和“全稱”屬相的元組數量確定置信度;以關聯相似度同置信度的乘積為匹配度。算法整體框架示意如圖1所示。
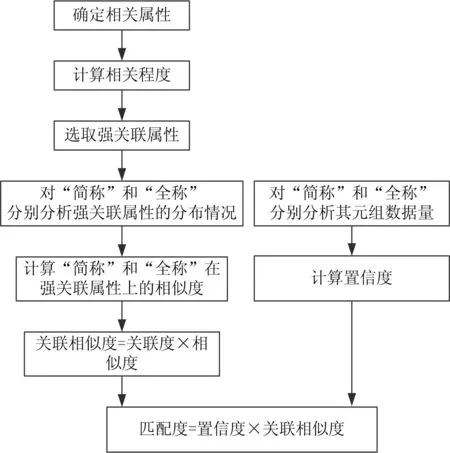
圖1 算法整體框架示意圖
3.2 屬性關聯相似度計算
3.2.1 屬性關聯度
屬性關聯度就是數據源中S中屬性集合A中任意兩個屬性間的關聯程度,這里主要研究屬性集合中各屬性同 D 的關聯程度。屬性關聯度計算有基于線性相關性計算或基于貝葉斯分類器進行實現等方法,由于數據源中各屬性數據數值型數據較少使用線性相關性不能計算完全,對于貝葉斯分類器方法通過針對決策屬性的條件屬性調整判斷關聯度,只能得到條件數據的關聯強度定性數據。因此,這里使用基于信息熵理論的互信息度來評價屬性關聯度。
在數據源中,兩個屬性間如果相互關聯,那么其中一個屬性數據變化時,另一個關聯屬性也會發生相應變化,兩屬性關聯程度越強,那么聯動變化越緊密。從信息熵的角度來看,屬性間的關聯度轉化為一個屬性的變化引起另一屬性變化的互信息度。
苗奪謙在文獻[11]中的基本方法,給出了一種計算互信息度的基本方法。該方法以屬性D為目標屬性,以A’屬性集為條件屬性,研究A’中各屬性和屬性D的互信息度。由于D∩A’=?,D∪A’=A,那么U在D和A’上的概率分布為
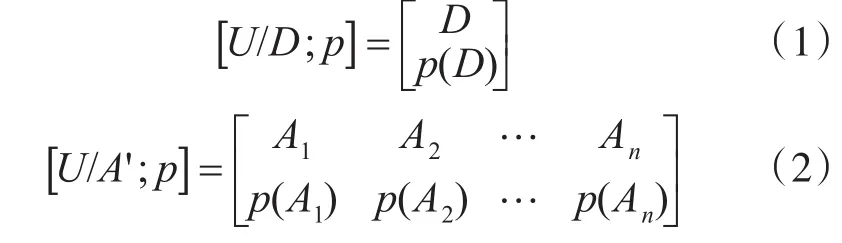
其中,p(Ai)=|Ai|/|U|,根據信息熵的定義,屬性集 A’的信息熵可以定義為
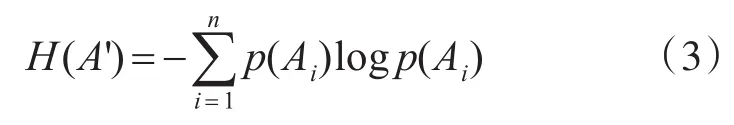
那么目標屬性D相對于條件屬性集A’的條件信息熵為

根據粗糙集理論[12~13],計算A’中所有支持D的屬性集合,即為A’的D核CoreD(A’),記A0=CoreD(A’)。
按照互信息計算方法,依次計算I(D|A0),由于討論不含D核的互信息沒有衡量意義。因此,對于不含D核的集合A’-A0的任意屬性Ak的相對D的關聯度為
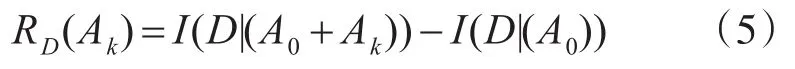
對于D核集合A0中的屬性則不作單獨討論,認為RD(A0)=I(D|A0)。因此得到了A’相對于D的所有屬性關聯度。
3.2.2 屬性相似度
屬性相似度主要研究的是屬性D上d1,d2對應的關聯屬性集合A’D中各屬性上數據分布的相似程度。在大數據應用中,代表中文固定名詞的“簡稱”和“全稱”的數據如果指代相同,由于參與統計數據量大,那么其相關屬性上的數據分布應當近似。
對于大數據應用中的具體業務數據源,除基本的數值類型數據外,其余文本型、非結構化數據等可以通過聚集、分類等技術轉化為離散型數值,重點對離散型數據進行分析研究,對于連續型數據可以按照隸屬函數的方法轉化為離散型數值。
分析關聯屬性中離散型數據進而分析其分布近似情況。對于關聯屬性Ak中離散型數據在U上的集合{a1,a2,…an},主要統計各數據點分布數據個數集合Ck={c1,c2,…cn},分別計算 d1,d2對應的統計分布集合為 C1k={c11,c12,…c1n},C2k={c21,c22,…c2n},那么屬性D中d1,d2相對關聯屬性A的差異體現在Ak同一數據ai的統計數占總比值的差值,則兩者在離散數據類型屬性Ak相似度表示是100%減去差異度,即為
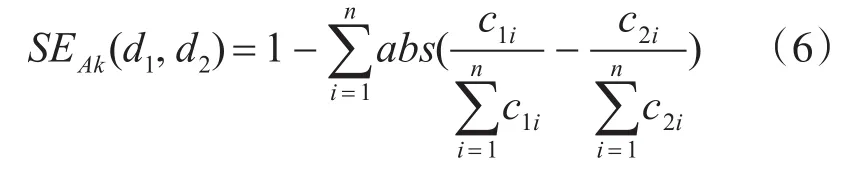
當屬性D取d1,d2對應在關聯屬性Ak上的數據集在各離散點分布情況完全相同,即認為d1,d2本質上完全相同的,那么式(6)的后半部分為0,此時相似度為1,即100%。
3.2.3 屬性關聯相似度
屬性關聯相似度作為判斷中文固定名詞所在屬性D中兩個數值“簡稱”和“全稱”的d1,d2的相似程度,對與屬性D相關聯屬性A’進行相似分析得到無當量相似度SEAi(d1,d2)。在判斷d1,d2的匹配程度時,考慮所有關聯屬性A’,那么以關聯屬性集合A’中各屬性權重可以用與屬性D的關聯度表示。
因此,首先對 A’中的所有屬性 A0+{A1,A2,…Am},其中A0為屬性D的核其中包括n-m個屬性,并對A’-A0的非核屬性進行重新編號,通過歸一化方法得到各屬性或屬性集的權重矩陣為
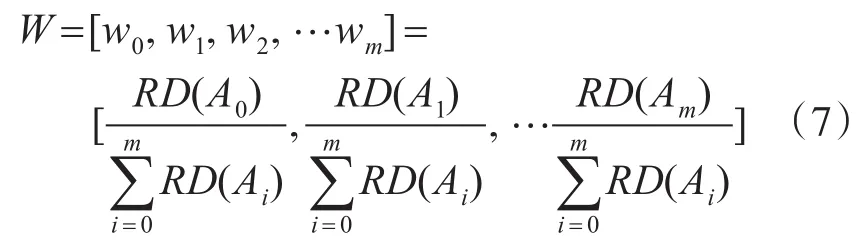
那么,可以得到屬性D上d1,d2的關聯相似度RS(d1,d2)為W和 A’中各屬性相似度的對應乘積和,是一個小于100%的無量綱數值,即
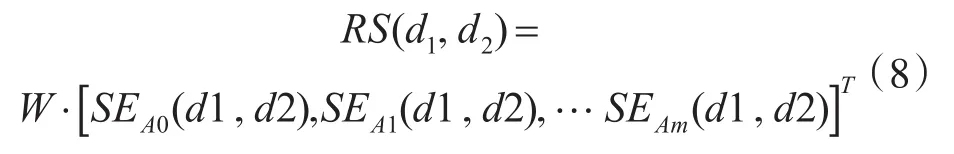
3.3 置信度的引入及匹配度計算
由于關聯相似度的計算主要基于統計學的,需要大量基礎數據作為支撐。但同時要注意,作為數據源S上屬性D=d1,D=d2所對應的數據集元組數量足夠多且相當,否則,當D=d1,D=d2數據量有限且不相當時,即便關聯相似度較高,可以認為是偶然因素導致,不具備普遍意義。樣本量數據與結果置信度密切相關[14],因此,需要在關聯相似度基礎上引入置信度。
根據置信度與樣本量的密切關系,使用頻繁共現熵方法[15]分析置信度,假設D=d1,D=d2對應數據量為C1,C2,當 C1,C2不是足夠大時,那么 d1在屬性D對應的全樣本空間分布概率為p(d1)=C1/(C1+C2),同理可得 p(d2)的值。
那么頻繁共現熵 f(D)值為
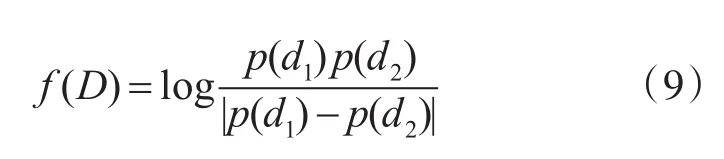
由式(9)得到置信度c(D)為
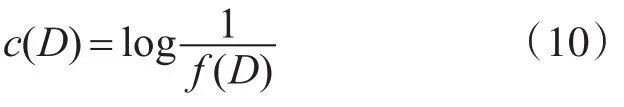
由式(8)和(10)得到 d1,d2的匹配度為
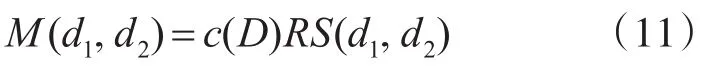
4 實驗分析及效果評價
根據數據堂提供的我國15萬在售小區信息數據集,數據集包含數據項:小區id、城市、小區名稱、均價、小區地址、所在區域、周邊學校、郵編、竣工時間、總戶數、停車位、綠化率、容積率、物業費,以及停車位信息包含停車場方式、價格車位數等方面信息。由于數據源來自網絡,數據規范性較差,在周邊學校數據項中出現比較多的高校名稱簡稱,主要研究該屬性中高校簡稱匹配問題。
大數據應用中,對數據集進行數據預處理,主要先完成“周邊學校”其他屬性,如將均價按千元,物業費按1元劃分區間等級,“周邊學校”屬性按標點劃分開來。按照基于屬性關聯度方法對高校名稱進行匹配,以數據項“周邊學校”為目標屬性D,得到屬性D的核CoreD為A0={均價,所在區域,郵編},按照式(5)得到其余屬性的關聯度(忽略值<0.01的屬性),那么通過式(7)歸一化處理得到屬性集合{均價,所在區域,郵編,物業費,城市}的相對“周邊學校”屬性D關聯度權重為
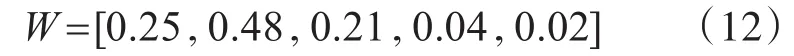
這里對屬性D中的d1=“華中科技大學”進行分析,通過單字匹配方法進行初步匹配得到d2=“華科大”,d3=“華科”,d4=“科大”,d5=“中科大”,以 d1為基準,計算關聯屬性集{均價,所在區域,郵編,物業費,城市}的相似度為
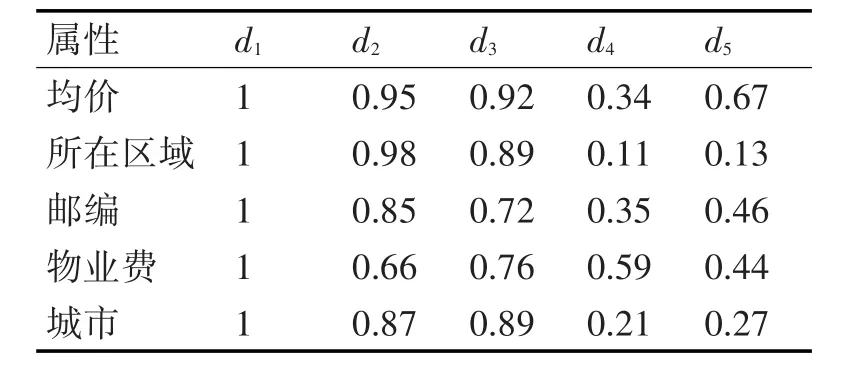
表1 關聯屬性集的相似度
根據式(8)得到 d2,d3,d4,d5相對屬性D的值 d1的匹配關聯度為
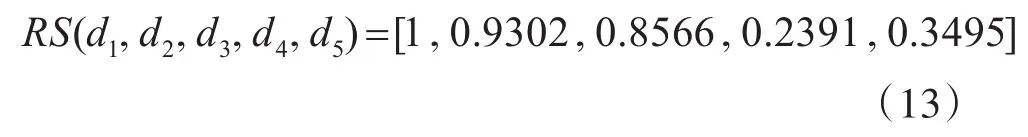

認為d2,d3同全稱d1的匹配度高,且匹配度均超過75%,判斷與d1為同一指向,d4,d5與d1的匹配度均沒有達到35%,不認為匹配。根據現實簡稱情況,該匹配算法結果符合實際情況。
5 結語
該匹配算法主要運用于大數據具體分析及應用之前,對于匹配算法結果匹配度不高時候,采用關聯屬性方法會導致后續的關聯分析存在效能增強的情況,因此對于涉及各屬性關聯情況的主因分析等大數據應用時,應謹慎使用本算法。
在大數據應用中,為解決數據清洗或數據集成中中文固定名詞的簡稱和全稱匹配問題,提出一種基于屬性關聯度的匹配算法。該算法在單詞匹配基礎上,通過其他屬性同匹配目標屬性間的關聯度,及“簡稱”和“全稱”對應關聯屬性上的數據分布相似度得到各屬性的關聯相似度,并結合“簡稱”和“全稱”的數據量得到置信度,并結合關聯相似度得到匹配度。該算法應用于小區數據集,發現該算法匹配度高,結果符合實際情況,算法匹配效果好。
猜你喜歡
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:30
當代陜西(2021年17期)2021-11-06 03:21:36
原道(2020年2期)2020-12-21 05:47:06
當代陜西(2019年15期)2019-09-02 01:52:00
中國非營利評論(2018年2期)2018-06-18 10:48:50
學苑創造·A版(2018年11期)2018-02-01 06:29:20
自動化學報(2017年1期)2017-03-11 17:31:17
讀者(2017年5期)2017-02-15 18:04:18
西藏科技(2016年5期)2016-09-26 12:16:39
振動工程學報(2015年1期)2015-03-01 01:15:42
