基于深度卷積神經網絡的非法攤位檢測
2018-10-15 08:04:00宋樂陶劉正熙熊運余
現代計算機 2018年24期
宋樂陶,劉正熙,熊運余
(四川大學計算機學院,成都 610065)
0 引言
隨著城市現代化發展,越來越多的非法擺攤現象涌現出來,對城市環境秩序、居民的日常生活造成嚴重干擾,因此有必要有一種智能非法攤位檢測算法,來對各類非法水果攤、小吃攤等進行智能識別檢測,減少城市管理人員負擔。非法攤位各式各樣,是不同運輸工具,不同貨物的組合,因此采用傳統機器學習目標檢測的方法,很難刻畫非法攤位的特征,效果很不理想。
相比于一些形態單一、剛性的物體,攤位則復雜許多:不同的攤位是不同載體,不同物體的組合體,更為復雜。傳統的機器學習目標檢測算法使用滑動窗口策略,一般包含三個步驟:設定不同大小的窗口,將窗口作為候選區,并不斷在圖片上滑動;利用手工設置的特征如行人識別的HOG(Histogram Orientation of Gradi?ent)特征[1]、人臉識別的 Haar特征[2],對候選區進行特征提取操作;利用特定的分類器如SVM(Support Vector Machine)[3]對特征進行分類,判斷候選區是否包含目標及目標類別;最后將同一類別相交候選區合并,計算出每個類別的候選框,完成目標檢測。
傳統目標檢測方法使用的特征是人為設計的特征,這種特征是非常低維度的特征,表達能力差,分類效果差,而且往往具有單一性,對特定物體的效果或許尚可,如使用HOG特征進行行人檢測,對于復雜多樣的物體檢測效果則極差。
傳統目標檢測方法中,多尺度形變部件模型DPM(Deformable PartModel)最為出色[4],連續獲得 VOC(Vi?sualObjectClass)2007到2009的檢測冠軍,DPM把一個物體看作不同部件所組成的,并通過部件之間的關系來描述一個物體,是HOG+SVM的升級,但是檢測速度極慢,一度成為目標檢測的瓶頸。為了自動提取高維度、高魯棒性的特征,Hinton提出深度學習來自動提取高維度特征[5],相比傳統手工設計的特征,這種特征有著更高的維度,更強的特征表達能力。隨著發展,卷積神經網絡通過多層卷積提取特征,在圖像分類方面取得卓越成果。之后基于深度學習的目標檢測框架R-CNN(Region-based ConvolutionalNeuralNetworks)不管在速度還是精度上都超越了傳統方法[6],R-CNN是基于區域的卷積神經網絡,首先在一張圖片上提取約2000個建議框(Region Proposal),然后將這些建議框放入到卷積神經網絡中進行訓練得到特征,將得到的特征放入SVM分類器分類,最后將得到目標檢測結果,達到 58%的 mAP(mean Average Precision),47 秒/張的速度。
這種基于建議框的目標檢測方法引領了深度學習目標檢測的潮流,為了解決需要對2000個建議框進行2000次卷積神經網絡特征提取耗時的問題,進而出現SPP-NET[7]和 Fast R-CNN[8],相較于 R-CNN,Fast RCNN只對整張特征圖進行一次卷積操作,然后對得到的特征圖通過空間金字塔池化層映射為特征向量,最后通過全連接層進行分類、預測邊框,以及邊框修正。但是這種方法同樣不能避免一開始先提取2000個建議框耗時的問題,Faster R-CNN[9]由FastR-CNN網絡和 RPN(Region Proposal Network)兩部分構成,使用RPN網絡來提取高質量建議框,從而大大縮短了時間;提取的建議框再交由FastR-CNN進行目標分類,對候選建議框的修正,實現端到端(end-to-end)的訓練,使用VGG16網絡達到73%的mAP,5fps的檢測速度。
本文實驗使用基于Caffe框架的Faster R-CNN算法,對非法攤位進行智能檢測。
1 卷積神經網絡
1.1 卷積神經網絡概述
1962年,生物學家Hubel和Wiesel過對貓腦視覺皮層進行研究,發現視覺皮層中一系列復雜的細胞,而不同的細胞對視覺輸入的不同局部敏感,所以被稱作感受野。并且這些視覺細胞有層次結構,由低級到高級,逐步理解。CNN也由此受啟發,由不同的卷積核作為感受野,提取局部信息,由池化核來適應位移和形變,CNN在圖像識別任務中取得良好分類效果。
卷積神經網絡(CNN)是對普通 BP(Back Propaga?tion)神經網絡的改進,與BP神經網絡相同的是:都使用前向傳播計算輸出值,再通過反向傳播調整模型中的權重和偏置;不同在于:卷積神經網絡包含了由卷積層、池化層構成的特征提取器,卷積層通過卷積核來提取特征圖,池化層則對提取到的特征圖進行壓縮,降低模型參數,提高訓練速度以及模型的泛化能力,在圖像識別方面有良好效果[10-13]。
卷積神經網絡是一個層次結構,包含輸入層、卷積層、池化層、全連接層、輸出層,輸入圖像經多個卷積、池化層進行特征提取,逐漸提取出高維特征,最后提取到的高維特征經全連接層、輸出層,輸出一個一維向量,向量中每個元素是一個得分值/概率值,也即是該圖像屬于各個類別的概率。
在工業界中常用的網絡有 LeNet-5、AlexNet、VGG16、ZFNET、ResNet等,本文所使用的網絡結構基于小型網絡ZFNET[14]、大型網絡VGG16[15]。
1.2 卷積神經網絡結構
卷積層是卷積神經網絡最核心的部分,作用是通過卷積操作提取特征,卷積核通過對輸入圖片或上層特征圖進行滑動窗口操作,逐一進行卷積。
如圖1所示,卷積神經網絡是一個層次結構,包含輸入層、卷積層、池化層、全連接層和輸出層,卷積神經網絡輸入是原始圖像,卷積層利用卷積操作提取特征,假設i代表第i層卷積層,Li-1是前一層的特征圖,Li是第i層卷積之后所得到的特征圖,該層過程為:

其中Wi為第i層的權重向量,?代表卷積操作,第i層的權重與i-1層的特征圖進行卷積操作,然后與第i層的偏移向量相加,最后通過非線性激勵函數 f(x)得到第i層的特征圖。通常第1層卷積層提取的是邊緣、線條等低級特征,越高層的卷積核逐步提取更高級的特征。
激勵函數的作用,是增加模型的非線性,目前CNN中常使用ReLU函數作為激勵函數,相較于sigmoid、tanh函數,能夠解決梯度爆炸、梯度消失等問題,同時能夠加快收斂速度。ReLU函數如下:

圖1 卷積神經網絡典型結構

池化層在卷積層和激活函數之后,主要作用是對特征圖降維,以使得訓練加快,同時保證特征的尺度不變形,一定程度上避免過擬合,池化過程為:

常見的池化操作有最大池化、均值池化等,經多個卷積層、池化層交替,卷積神經網絡逐步提取高維度特征。
經過多層卷積、池化處理后,會接一層或多層全連接層,全連接層中神經元與前一層所有神經元相連,旨在整合類別的局部信息,全連接層會根據輸出層任務,有針對性的對高層特征進行映射。最后一層全連接層的輸出值輸入到輸出層,輸出層面向具體任務,例如用CNN來進行分類,那么輸出層可以采用如Softmax層來進行分類,輸出一個n維向量y=(y1,y2...yn)T,其中n為類別數,每個值代表相應類別的置信度。
2 Faster R-CNN攤位檢測架構
2.1 網絡參數初始化
在訓練網絡前,有一個重要的任務是如何對網絡中權重參數進行初始化,神經網絡的訓練其實質就是不斷調節權重參數和偏移參數的過程,有了這些參數就知道了每一層所代表的特征,如果一層中所有參數都相同,那么他們表征的特征就是相同的,即使在這層中有很多節點,其實和只有一個節點沒有任何區別。如果每一層參數都是相同的,那么這個神經網絡模型就退化為線性模型了。
最早有個貌似很合理的思想,是一開始把所有權重參數初始化為0,但是權重參數的更新規則為:

其中i表示是第i層,α表示學習率。
將參數初始化為0,導致前向傳播時每一層的輸出是相同的,反向傳播時dW是相同的,進而每一層都是一樣的,此時網絡是完全對稱的。
既然權重不能全部初始化為0,那么一種自然而然的思想就是把權重隨機初始化為一些小的數,來打破對稱性,這個思想是神經元一開始是獨一無二的、隨機的,它們會計算出不同的更新來調整整個網絡,例如高斯初始化,它的權重矩陣如同:
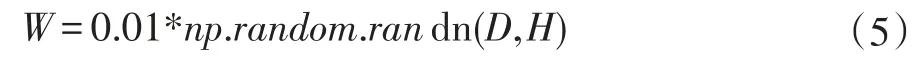
其中randn是從均值為0的單位標準高斯分布進行取樣,通過這個函數,使得權重參數初始化為一個從多維高斯分布取樣的隨機向量。
還有一些其他的參數初始化方法如均勻分布初始化、Xavier初始化、MSRA初始化。
2.2 遷移學習
神經網絡需要通過訓練數據來訓練,從中獲得相應信息并轉化為權重。在實際應用中,通常沒有太多的數據集用于訓練,因此從頭進行初始化訓練網絡并不好。在人類的文明中,上一代會將知識傳授給下一代,下一代只需要在此基礎上進行學習即可,而不需要從頭開始,神經網絡也借鑒這一思想,可以對已有的模型進行微調(fine-turn),來完成我們的自己任務,可以從別的模型中提取權重,并遷移到自己的任務上。
ImageNet數據集是一個大型數據集,包含1400萬張圖片,超過200萬個類別,是目前深度學習領域應用的非常多的公開數據集。由于ImageNet數據集過大,所以有公開的已經在ImageNet數據集上訓練得到的模型參數,本文以此作為預訓練模型(pre-trainedmodel)用來對網絡進行初始化。接下來fine-turn整個神經網絡,替換掉輸入層(圖片數據),使用自己的實驗數據集進行訓練,可以對部分層進行微調,也可以對全部層進行微調,通常前面的層提取到的是圖像的通用特征(如邊緣特征、色彩特征),這些特征對許多任務都有用,因此只對后面的層進行調整。
與重新訓練整個網絡相比,使用遷移學習需要使用更小的學習率(本文實驗使用的學習率learning rate為0.001,而訓練ImageNet數據集使用的學習率為0.01),因為預訓練模型的參數已經很平滑,我們不希望太快去扭曲它們。
2.3 Faster R-CNN檢測流程
FastR-CNN解決了需要重復對建議區域進行特征提取,耗費大量時間的問題,此時目標檢測速度的瓶頸在于依然要預先通過Selective Search等方法提取建議區域。Faster R-CNN提出區域生成網絡RPN(Re?gion ProposalNetwork),把建議區域的生成糅合到卷積神經網絡中,進一步提高了速度。
Faster R-CNN框架由兩個模塊組成:
(1)RPN模塊用于生成建議區域
(2)FastR-CNN模塊用于對RPN提取的建議區域識別目標
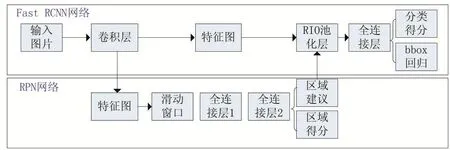
圖2 Faster R-CNN檢測架構
從R-CNN到Faster R-CNN,目標檢測的四個步驟:候選區域生成、特征提取、分類、位置精修被融入到一個網絡中,實現了端到端(end-to-end)訓練。
2.4 訓練過程
通過反向傳播(BP,Back Propagation)和隨機梯度下降(SGD,Stochastic Gradient Descent)進行端到端的訓練。
(1)RPN網絡預訓練:
以ImageNet訓練好的網絡ZF/VGG-16來進行參數初始化,以標準差0.01均值0的高斯分布對新層進行隨機初始化。
(2)FastR-CNN網絡預訓練:
以ImageNet訓練好的網絡ZF/VGG-16來進行參數初始化。
(3)RPN網絡微調訓練:
以與Ground Truth相交IoU最大的anchor以及IoU>=0.7的anchor作為正樣本;以IoU<0.3的作為負樣本,同FastR-CNN網絡,采取“image-centric”方式采樣,即層次采樣,先對圖像取樣,再對anchors取樣,同一圖像的anchors共享計算和內存。每個mini-batch包含從一張圖中隨機提取的256個anchors,正負樣本比例為1:1,來計算一個mini-batch的損失函數,如果一張圖中不夠128個正樣本,拿負樣本補湊齊。訓練超參數選擇:在數據集上前60k次迭代學習率為0.001,后20k次迭代學習率為0.0001;動量設置為0.9,權重衰減設置為0.0005。
一張圖片多任務損失函數(分類損失+回歸損失)如下:

其中,i表示一個mini-batch中某個anchor的下標,pi表示anchor i預測為物體的概率;當anchor為正樣本時,,當anchor為負樣本時,由此可以看出回歸損失項僅在anchor為正樣本情況下才被激活;ti表示正樣本anchor到預測區域的4個平移縮放參數(以anchor為基準的變換);t*i表示正樣本anchor到Ground Truth的4個平移縮放參數(以anchor為基準的變換);
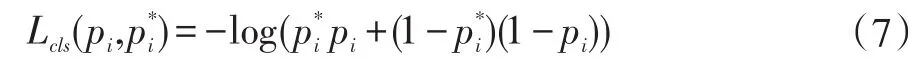
回歸損失函數Lcls表達式:

R函數定義:
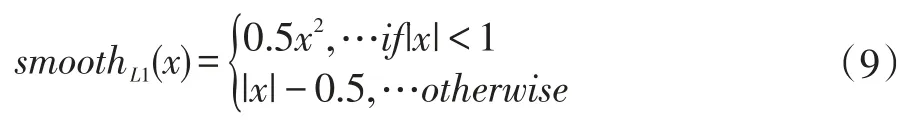
RPN和FastR-CNN都是獨立訓練的,要用不同方式修改它們的卷積層。因此需要開發一種允許兩個網絡間共享卷積層的技術,而不是分別學習兩個網絡。RPN在提取得到proposals后,使用Fast R-CNN實現最終目標的檢測和識別。RPN和FastR-CNN共用了13個VGG的卷積層,將這兩個網絡完全孤立訓練不是明智的選擇,所以采用交替訓練(Alternating Training)階段卷積層特征共享:
(1)用ImageNet預訓練的模型初始化,得到初試參數W0,并端到端微調用于區域建議任務;
(2)從W0開始訓練RPN,得到訓練集上的候選區域;
(3)從W0開始,用候選區域訓練Fast R-CNN,得到參數W1;
(4)從W1開始訓練RPN。
3 實驗結果
實驗環境為:CPU:Intel i7 6700K,顯卡:GeForce GTX 1070,顯存 8GB。
實驗所使用訓練數據集,大多來自于真實攝像頭下截取的圖片,以及一些網絡上找的圖片以提高泛化能力,圖片的長寬比(width/height)在 0.463-6.828之間,在最初的數據集基礎上,訓練出模型進行測試,并將漏檢、誤檢的圖片重新加入到訓練集中進行再次訓練,不斷得到魯棒性更高、泛化性更強的模型,如表所示:
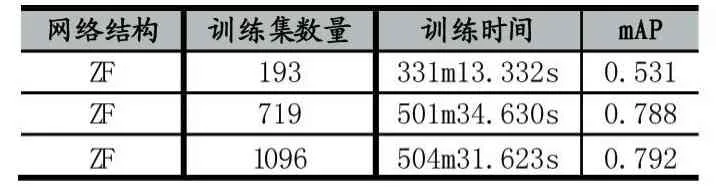
表2 訓練集數量對訓練結果的影響
目標檢測中衡量識別精度的指標是mAP,在多類別目標檢測中,每個類別都根據recall和precision繪制一條曲線,AP就是該曲線下的面積。
由表2可知,不斷增加樣本,平均準確度也不斷上升,尤其是初期樣本比較少時,將難例增加到訓練集中對整體效果提升非常明顯,提升了46.7個百分點;當然由于訓練的數量加大,訓練時間也隨之增加。最終訓練集有1096張圖片,已經能達到0.792的mAP。
雖然ZF網絡已經能達到不錯的效果,但是ZF網絡只有5層的卷積來提取特征,因而對復雜場景如陰影、光照、部分遮擋等效果并不好,很容易出現漏檢,如圖3。

圖3 ZF網絡下部分漏檢圖
針對ZF網絡深度較淺,提取出的特征維度不高,因而容易出現漏檢的問題,在網絡結構上加以改進,使用深度更高的VGG16網絡,VGG16網絡共16層,有13層卷積、池化層來提取更高維度的特征,3個全連接層,如3表:

表3 ZF、VGG-16訓練結果對比
使用更深的網絡,會提取出更好的特征,提高模型的魯棒性;同時更深的網絡擁有更多的參數,會計算更多的卷積操作,所以訓練時間也會明顯提升。
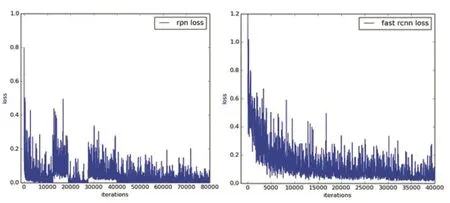
圖4 損失函數變化圖
從圖4可以看到在訓練RPN和FastR-CNN階段的損失函數變化,RPN階段損失函數在30000次迭代前變化起伏比較大,30000次之后逐漸收斂,40000次迭代已經區域穩定;FastR-CNN階段一開始損失函數比較大,接下來逐漸收斂,到20000次迭代時趨于穩定。由于使用了遷移學習策略,最終訓練獲得了比較好的收斂效果。
在得到兩種網絡訓練出的模型后,使用282張不同類別(如手推車攤位、三輪車攤位、小貨車攤位)的測試圖片對兩種模型分別進行測試,使用的測試集區別于訓練集中圖片,并且都來自真實場景。

表4 ZF、VGG-16模型測試結果
可見,VGG16訓練出的模型,相比于ZF模型,在漏檢問題上有明顯提升,以下是兩種模型的實際檢測效果:

圖5 ZF(左)與VGG(右)效果對比
從實驗結果不難發現,ZF模型由于提取特征層次較淺,在復雜環境(如光照、陰影、部分遮擋)下,很難有效對目標進行檢測;VGG16訓練的模型有強大的魯棒性,即便在復雜環境下同樣具有強大的目標捕捉能力。
4 結語
本文所使用的Faster R-CNN+VGG16網絡結構,在遷移學習和交替優化策略下對非法攤位進行檢測,實驗表明能達到80%的平均準確度,5fps,可應用到實際場景中,對不同類別非法攤位進行智能檢測。但是對于小物體(目標在整張圖片中占比過小)以及強光下檢測效果不理想;并且對一些車輛、人群有時會出現誤檢;同時能否進一步提升fps以適應實時要求,也是接下來要研究的工作。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
