面向“邊緣”應用的卷積神經網絡量化與壓縮方法
2018-10-16 08:23:48蔡瑞初鐘椿榮陳炳豐
計算機應用 2018年9期
蔡瑞初,鐘椿榮,余 洋,陳炳豐,盧 冶,陳 瑤,3
(1.廣東工業大學 計算機學院,廣州 510006; 2.南開大學 計算機與控制工程學院,天津 300353;3.新加坡高等數字科學中心,新加坡 138602)
0 引言
近年,卷積神經網絡(Convolution Neural Network, CNN)憑借其強大的特征提取能力而被廣泛應用于自動控制、模式識別、計算機視覺、傳感器信號處理等方面,但由于智能識別任務數據交互量大,云計算中心存在負擔重和網絡傳輸延遲時間較長等問題,使得卷積神經網絡在嵌入式終端的部署受到限制。例如,無人駕駛汽車領域[1],其車載傳感器和攝像頭持續捕捉實時路況信息,如果所有的無人駕駛汽車的數據直接發送到云計算中心處理,響應延遲時間將會更長,以至于無法滿足自動駕駛對實時性數據處理的需求。為了實現實時路況的及時響應,需在車載嵌入式等“邊緣”設備上進行卷積神經網絡的部署。
隨著卷積神經網絡模型堆疊的層數越來越多,網絡模型的權重參數數量也隨之增長。例如,LeCun等[2]提出的LeNet-5卷積神經網絡模型需要訓練600 000個參數;Krizhevsky等[3]設計的AlexNet權重參數數量是LeNet-5的近100倍。而之后的VGG-19[4]網絡模型的權重參數數量達到了1×108;Coates等[5]甚至將卷積神經網絡權重參數擴展到1×109。卷積神經網絡的復雜度主要體現在兩個部分:一是卷積層包含了網絡90%以上的運算操作;二是全連接層產生了超過90%的網絡參數。這導致卷積神經網絡的“邊緣”部署受到嵌入式設備的內存空間、計算量和計算速度等方面的影響。
通常情況下,如車載嵌入式設備計算資源非常有限且對功耗有嚴格的要求,其處理器處理能力較弱、存儲及內存空間較小,使得嵌入式設備的計算能力與存儲訪問能力受到了極大的限制,卷積神經網絡較高的運算及存儲訪問需求使其在嵌入式終端設備的實現成為難點。針對以上情況,神經網絡應用在嵌入式設備的實現需在保障其網絡模型不變的前提下解決其運算量大及存儲需求高的問題。
本文的主要工作如下:
1) 針對原始網絡的計算及存儲訪問需求過高的問題,采用動態網絡權重裁剪方法去除網絡中的冗余連接,在保障網絡模型精度在可控變化范圍內的前提下有效減少模型的非零權重數量;
2) 針對嵌入式硬件平臺的硬件特性對模型數據進行以比特位為單位的動態數據量化,充分利用嵌入式平臺所具有的位操作特性,進一步提升網絡模型的執行性能;
3) 提出針對嵌入式平臺的卷積神經網絡處理框架,結合以上處理過程,并將處理結果進行實現。
1 相關工作
邊緣計算應用主要針對當前有許多在“邊緣”設備上使用神經網絡模型的研究工作,并得到了不錯的成果。由于神經網絡模型含有大量的參數,而大量冗余的參數占用了很多計算資源和存儲空間[6],因此,首要任務是減少網絡參數從而降低計算與存儲消耗,如LeCun等[7]和Hassibi等[8]率先提出OBD(Optimal Brain Damage)和OBS(Optimal Brain Surgeon)的參數裁剪方法。該方法利用二階泰勒展開選擇裁剪參數,使網絡輕量化的同時促進了網絡的泛化,但是需要額外的內存和計算資源來計算黑塞矩陣(Hessian Matrix)。Molchanov等[9]則用一階泰勒展開方法對卷積神經網絡中冗余的特征圖進行裁剪,但該方法僅適用于在小型數據集上作遷移學習的網絡模型。Han等[10]則在裁剪的基礎上,對大型網絡模型用k均值(k-means)和哈夫曼樹的方法對網絡權重進行量化壓縮,有效地降低了網絡中的冗余度。
嵌入式處理器,因處理器位寬及性能的限制,常規的計算需求在該環境下難以得到滿足。面對這種情況,在保證網絡模型精度的同時對網絡中的權重數據進行量化已成為一種趨勢。Vanhoucke等[11]采用8位整數定點表示的方法表示激活函數;Hwang等[12]則提出用三元權重結合3位激活函數的定點的網絡優化方法消除冗余;Gong等[13]提出一種損失精度的方法,使用向量量化來壓縮Convnet并且只降低了1%精確度;Chen等[14]的HashedNet是通過散列函數將連接權重隨機分組到哈希桶中,同一個哈希桶中的所有連接共享一個參數值來減小模型大小的技術;Courbariaux等[15]使用了實值和二進制的兩組權重,通過前向和后向傳播計算的梯度來更新權重的實值,并將實數權重量化為+1和-1的二進制權重,有效減小網絡模型所需的位寬。
本文基于上述研究,提出的基于閾值的權重數據裁剪和面向硬件平臺的動態定點量化方法,實現卷積神經網絡模型輕量化的效果,在減少網絡權重的位寬表示和數量的同時,保證了精度的穩定,在三者之間權衡,尋求最優的平衡點。
2 理論分析
2.1 神經連接的冗余性分析
在網絡結構確定的前提下,在未知最優網絡規模時,大量的參數使網絡模型具有強大的分類能力,同時也容易導致網絡的過擬合;反之,網絡參數過少會限制網絡的學習能力。由于更多的參數意味著更多的存儲需求和計算操作,增加了在移動平臺上應用CNN的難度。
已有研究工作證實,在網絡模型權重參數中,并不是每一個參數都具有同等的重要性[16],不同網絡層權值的概率分布也有很大差異。以CaffeNet[17]最后一層全連接層(Fc8)的權重分布為例,如圖1所示,其分布具有類似正態分布的特征;當分別對權重絕對值較小和權重絕對值較大的連接進行裁剪時,得到網絡精度結果如圖2所示。可見:不斷增大對絕對值較小的連接的裁剪比率時,網絡精確率基本保持穩定,當裁剪率高于80%時精確率才出現緩慢下降;與之相反,裁剪權重較大的連接對網絡的精確率影響十分明顯。已有研究工作也證明,網絡模型中絕對值大的權重參數比絕對值小的權重對輸出的影響更大[16]。
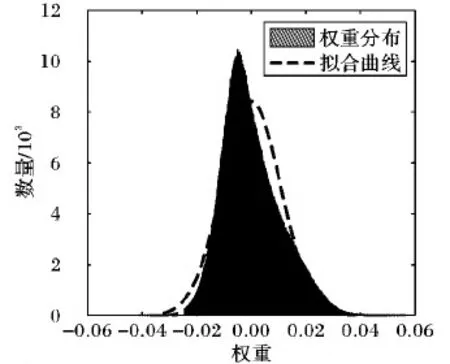
圖1 CaffeNet中Fc8的權重分布
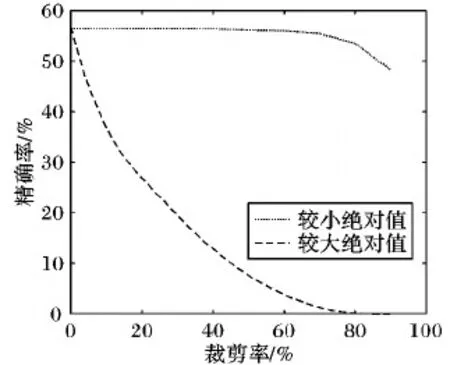
圖2 Fc8層不同權重裁剪結果
同樣,以CaffeNet為例,在保證精確率不變化的前提下,動態調整每一層的裁剪閾值并進行權重數據的裁剪,每次最大限度地實現單層的裁剪并逐層遞進,最終通過fine-tune保持網絡執行的精確率下降不超過1%,其結果如圖3所示。網絡模型中每一層都有相當數量的權重參數被裁剪而不影響網絡輸出結果的精確率。

圖3 單層最大被裁剪率
2.2 權重及激活函數的離散性分析
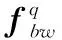
(1)
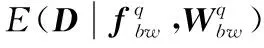
以CaffeNet的Fc8層的權重為例。將32位的權重用9位定點表示,量化為一個離散的權重區間,可在滿足網絡輸出精度不變的情況下采用定點表示其數據,如圖4所示。

圖4 定點量化后的權重分布
定點數據量化相比浮點數據獲得了更高的網絡精確率,明顯地降低了網絡計算的開銷,提高了性能并且降低了功耗。
3 方法描述
在本章中,詳細描述本文所采用的算法。
3.1 基于閾值的權重數據裁剪
通過對網絡中各層權重的數據分布和數值特點進行分析,權重的絕對值越小對該連接所產生的全局影響越小。在保證精度的前提下,對重要性較低的網絡連接進行權重數據裁剪,減少網絡的非零參數數量,使網絡數據量降低。
網絡訓練過程通過優化權重W,以最小化損失函數E(D|f,W|),其中D為訓練集。在裁剪網絡時,選擇并優化參數子集Wp,其中Wp為相對重要的權重連接并且Wp?W,同時保證網絡精確度E(D|f,Wp|)。因此,最小化裁剪導致的精確度的損失可表示為:
(2)
基于閾值的權重數據裁剪操作主要包括三個步驟:
1)為保證網絡的重要連接得到充分的學習,采用浮點型數據將網絡模型訓練至收斂。統計該網絡模型各層l的權重分布Fl(wl),取一個較小且無精確度損失的裁剪率p0,使得Fl(tl0)=P{0<|tl0|}=p0,即網絡模型各層i的初始裁剪率為p0時,其初始閾值分別設為tl0。同時,將所有小于此閾值的權重連接重置為0。

2)再次訓練網絡,對重要的權重連接進行微調,恢復網絡的精確率。其中,已重置為0的權重不被更新,采用以下方法:
(3)
(4)
(5)
(6)
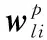
3.2 動態定點量化
卷積神經網絡中,網絡各層數值動態范圍存在差異。例如在普遍采用ReLu[21]為激活函數的網絡模型中,當該神經元輸出大于0時,該值等于上層的輸出與權重的點積,其輸出數據范圍遠大于當前層權重。定點表示的數值范圍有限,因此采用動態定點(Dynamic fixed point)[20,22]來表示網絡的權重和激活函數,即每個數值表示如下:
(7)
其中:bw表示位寬,s是符號位,fl為小數的長度,m表示尾數位。網絡中的各個值都可以在較小影響下,根據bw動態分配相應的fl。
對權重與激活函數的動態定點量化按以下4個步驟進行:
1)將經過預訓練的網絡模型的精確率作為網絡模型量化的基線Ab,同時設置正閾值σ。在動態定點量化過程中,允許其量化后的精確率Aq相對于基線的降低范圍在閾值σ之內,Ab-Aq<σ。
2)分析權重和激活函數各自的動態范圍,尋找與其相對應整數部il所需的位寬,計算小數部分的位寬長度fl=bw-il-1。采用最鄰近舍入法從浮點轉化為定點數據。
測試量化后網絡精確率Aq,當精確率的損失在σ范圍內,采用折半查找法,多次迭代量化分別尋找激活函數、卷積層與全連接層權重的最優位寬。否則,將bw和fl部分設為上一次循環所得位寬長度。因為網絡模型三個部分的位寬相對獨立,因此每次只將卷積層或全連接層的權重或各層激活函數三部分的其中之一作動態定點量化,其余保持浮點型數據。
3)找到當前層動態定點量化的位數與精確率之間的最優平衡點,對量化后的網絡進行微調。為了使動態定點量化不降低網絡的精確率,采取全精度的影子權重(full precision shadow weight)[15],對計算過程中的梯度進行反向傳播。權重的梯度為Δw由全精度權重w計算得到,而離散的權重wq由w動態定點量化而得,對權重進行隨機舍入(stochastic rounding)[23]獲得,即:
(8)
(9)
(10)
(11)
其中:fl為神經網絡的激活函數,Q為動態量化函數。為了得到更精準的權重梯度,在微調階段將不對激活函數fl的量化結果進行調整。
4 驗證與分析
為了驗證與分析上述方法,本文在Caffe 1.0版本[17]深度學習開發框架中,加入以上權重裁剪及量化功能,采用CaffeNet、VGG-19、SqueezeNet[24]、ResNet[25]等廣泛使用的典型卷積神經網絡模型作為實驗對象,將2012年ImageNet大規模視覺識別挑戰賽(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)的驗證集作為實驗的測試數據集。
4.1 網絡模型的權重數據裁剪
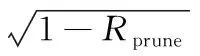
CaffeNet網絡模型各層權重數量、裁剪閾值及其裁剪率結果如表1所示。整體來看,經閾值法裁剪后,CaffeNet網絡權重數目從61×106減少為10.1×106,裁剪率為83.4%,并且,網絡模型精確率保持在55.2%。另外,網絡中不同的層所設置閾值的大小及裁剪率并不相同。相比權重共享的卷積層,全連接層的裁剪率都在63.72%以上,最高的裁剪率可到達88.1%;因此,全連接層比卷積層權重的冗余性更高。在卷積神經網絡中,閾值的大小與層的類型及當前層在網絡中所處位置相關[16]。同時,在網絡模型中,上下層之間相互影響,單層閾值設置過大,會影響后面層的特征提取。表2中所示為上述四個卷積神經網絡的裁剪結果。由表2可以看出,基于閾值的裁剪方法對CaffeNet、VGG-19等大型網絡均可達到80%以上的裁剪率。此外,不含全連接層的參數密集的網絡模型ResNet和SqueezeNet也能通過閾值法裁剪減少30%的參數數量。因此,基于閾值的裁剪方法能有效降低卷積神經網絡中的非零權重數量。
相比當前的Dropout方法,閾值法裁剪則將權重連接永久刪除,而Dropout在訓練時使每個神經元都有一定的概率不參與訓練但在網絡推理時參與回歸,因此Dropout并不降低非零權重數量。隨著網絡連接的刪除,網絡模型將選擇最重要的連接進行表達,因此可以極大地降低神經網絡本身所存在的冗余性[16]。
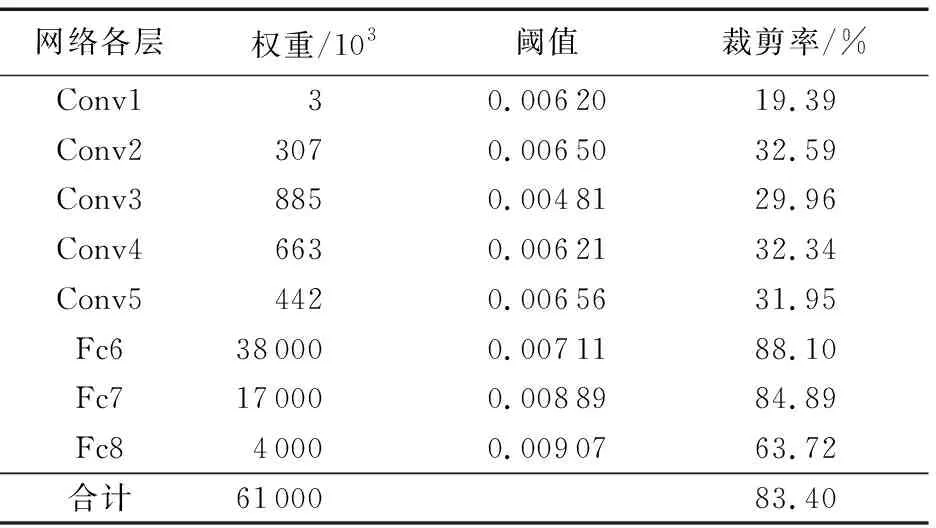
表1 基于閾值裁剪后CaffeNet各層權重變化
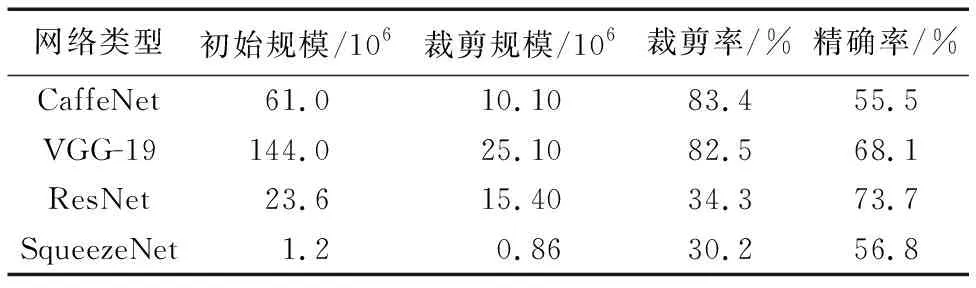
表2 不同網絡模型裁剪后結果對比
4.2 網絡模型的動態定點量化
在本節中,使用動態定點量化方法對上述4個網絡模型的權重與激活函數進行處理,本節實驗將各個網絡的原始精確率作為基線,并使得量化后的精確率不低于基線的3%。
表3所示為CaffeNet、VGG-19、ResNet和SqueezeNet動態定點量化后網絡各個部分的位寬、初始基線和量化后的精確率及變化。表4為各個卷積神經網絡模型量化前后大小對比。表4中,最后一列數據所示為便于在嵌入式微處理器平臺進行硬件加速,采用8(1 B)的倍數位定點量化網絡所得結果。實驗結果顯示,將CaffeNet的卷積層和全連接層的權重及激活函數32位的位寬分別最大量化為8位、7位和12位時,可不產生分類精確率損失;同時,其網絡大小從232.6 MB縮減為51.2 MB,網絡模型大小減少了78%。此外,對于前處理器平臺,CaffeNet也能被量化為58.1 MB。與CaffeNet類似,網絡層數更多的卷積神經網絡ResNet經過動態定點量化后,各層數據均可采用較低位寬數據表示,網絡存儲所占空間可縮減到25.2 MB和45.0 MB。對于參數密集型網絡SqueezeNet,雖然網絡本身具有較高的權重共享能力,其模型大小也由4.7 MB縮減至1.2 MB。由此可知,網絡權重的量化,對于大規模神經網絡在“邊緣”及低性能終端設備的部署具有顯著意義。
同時,相比裁剪與量化方法,網絡精確率嚴格處于閾值所限定范圍內。

表3 動態定點量化對不同網絡處理的效果
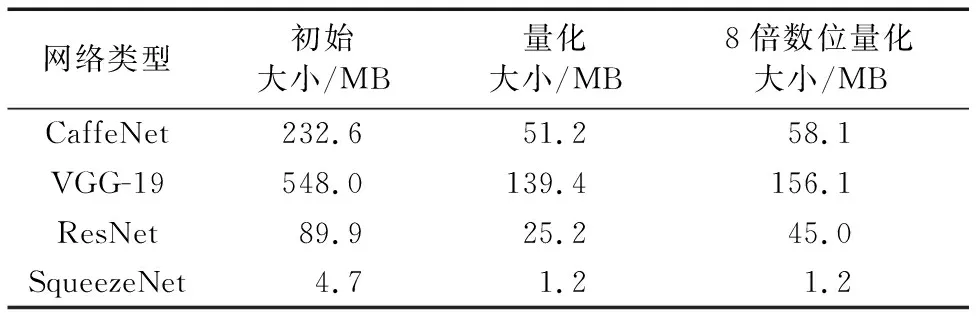
表4 定點量化后各個網絡的大小
4.3 裁剪與量化的結合
實際應用中,網絡裁剪和網絡權重的量化均可單獨作為網絡模型壓縮的方法,為了對網絡模型進行進一步壓縮,本節實驗將在4.1節及4.2節實驗結果的基礎上,提出將網絡裁剪及網絡權重量化相結合的方法,并對其進行嵌套迭代實現。其中,精確率閾值與基線的設置與以上章節相同。
表5中給出了網絡裁剪、量化及將其結合后對CaffeNet模型各層大小的影響。相比原始CaffeNet網絡的大小,將裁剪與量化結合后網絡規模有了明顯的降低,從232.6 MB壓縮為僅9.02 MB的大小,CaffeNet網絡模型減小了96.12%,極大地減少了網絡存儲空間。單獨的裁剪和量化則分別減少為41.13 MB和44.2 MB,只減少了81.5%。而網絡的精確率稍有降低,但仍處于前文所述閾值范圍內。網絡裁剪與量化相結合后,對CaffeNet網絡的卷積層和全連接層的大小都能有效地進行壓縮,說明方法結合后能更進一步地對卷積神經網絡進行壓縮。
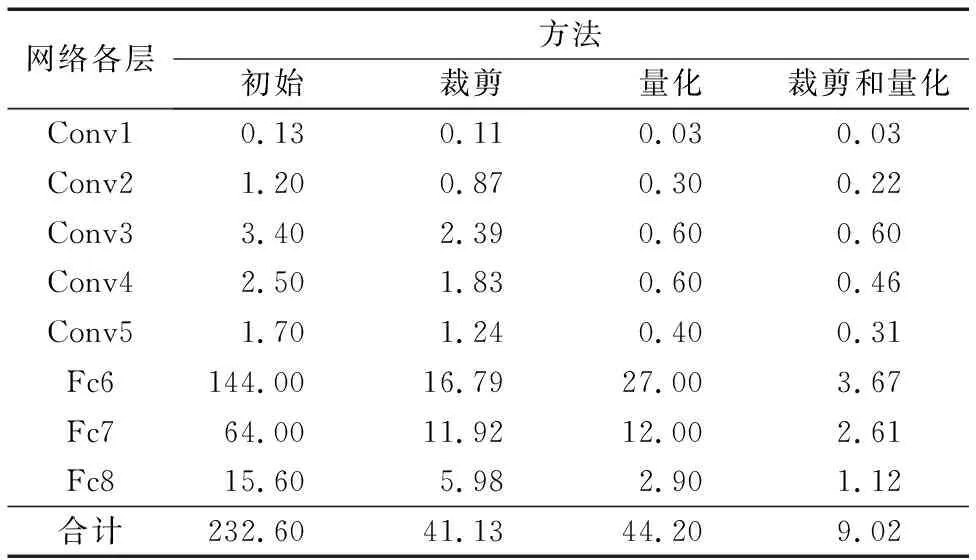
表5 CaffeNet網絡裁剪及量化后各層大小 MB
與此同時,網絡精確率嚴格處于閾值所在范圍內。如表6所示,本實驗所采用的網絡模型都可以通過網絡裁剪和量化或其結合的方法,對網絡模型數據大小進行壓縮。VGG-19從初始大小548 MB壓縮為25.2 MB而精確率僅降低0.3個百分點,壓縮了95.4%;同時,層數更多的卷積神經網絡的ResNet和SqueezeNet也能壓縮為原始大小的18.7%以下。在精確率變化方面,在多個模型上的測試結果幾何平均后精度下降為1.46個百分點,可見裁剪和量化對實現模型在嵌入式設備上的“邊緣”部署有非常大的優勢。

表6 不同網絡裁剪及量化后結果對比
5 結語
本文針對卷積神經網絡對存儲空間及計算資源需求過大從而限制了其在嵌入式“邊緣”設備上部署的問題,提出了結合網絡權重裁剪及面向嵌入式硬件平臺數據類型的數據量化的卷積神經網絡壓縮方法,降低網絡模型的冗余度和數據位寬需求。實驗結果表明,該方法在保證網絡精確率的前提下能有效地對卷積神經網絡進行壓縮。未來工作中,還將對上述方法進一步優化,更深入研究網絡模型中權重連接之間的聯系;在定點量化方面,將用更少的位寬量化網絡的不同部分,從而在更大程度上降低網絡大小及其計算消耗。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
鐵道通信信號(2018年2期)2018-04-18 12:18:23
電鍍與環保(2016年3期)2017-01-20 08:15:32
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
單片機與嵌入式系統應用(2014年9期)2014-03-11 15:35:13
