基于生成少數類技術的深度自動睡眠分期模型
2018-10-16 08:23:50金歡歡尹海波何玲娜
計算機應用 2018年9期
金歡歡,尹海波,何玲娜
(1.浙江工業大學 計算機科學與技術學院,杭州 310023; 2.哈爾濱工業大學 航天學院,哈爾濱 150001)
0 引言
睡眠分期對研究睡眠相關疾病[1]具有重要意義。睡眠分期通常由有經驗的睡眠分期專家,依據睡眠分期規則手動完成睡眠各階段的劃分和統計。人工睡眠分期需要大量的專業人才和時間,可普及性較差,因此自動睡眠分期一直是睡眠分期研究的重要方向。
自動睡眠分期的研究多基于睡眠腦電信號[2]。對原始數據的預處理、針對數據集特點設計所要提取的特征、將提取的特征輸入分類器進行類別劃分是近年自動睡眠分期研究的三個關鍵點。其中針對特定數據集的人工特征設計,是制約分類效果的關鍵因素[3]。人工設計的特征雖然針對特定數據集效果較好,但是由于需針對性嘗試設計特征,具有很強的主觀性,無法實現對原始睡眠腦電數據的端到端學習[4]。
近年來深度學習在圖像識別、自然語言處理以及語音識別領域已有大量成熟的應用。在經大量注釋的數據集訓練后,基于深層神經網絡的機器學習模型,能夠接近并超過人類專家水平[5-6]。尤其在醫學成像識別中,得益于可直接應用現存大型圖像數據集對模型進行預訓練,這種優越性更為突出[7-8]。在時序信號處理方面,卷積神經網絡和遞歸神經網共同構建的網絡模型已成功應用于語音識別和自然語言處理中[9-10]。雖然受限于目前包括自動睡眠分期在內的絕大多數領域都無法提供足量的數據,仍有少量團隊將深度學習模型應用于自動睡眠分期[11-12],實現了端到端睡眠自動分期,但是由于類不平衡小數據集在深度學習中的局限性,以及未應用最新的深度學習優化技術,分類精度仍有很大的提升空間。
本文在這些技術的基礎上,分別從對類不平衡小數據集中少數類的擴增,以及應用深度學習模型優化技術對模型訓練進行優化兩方面入手,來完成高分類精度端到端自動睡眠分期模型的構建。在類不平衡小數據集的處理方面,對修改的生成少數類過采樣技術(Modified Synthetic Minority Oversampling Technique, MSMOTE)[13]進行改進,并將其應用于高維度、多分類腦電數據集中少數類的過采樣。在訓練方法的優化方面,仿照遷移學習中的兩步訓練法,將擴增后的類平衡數據集用于預訓練,原始數據集用于微調。此外還應用如殘差連接(Residual Connections)[14]、批歸一化(Batch Normalization, BN)[15]、Swish激活函數[16]等技術,進一步對模型進行優化。最終實現可用于類不平衡小數據集的端到端自動睡眠分期模型。
1 模型結構及技術介紹
1.1 自動特征提取部分
本文提出的自動睡眠分期模型由三部分組成,如圖1所示,在圖1中依次標示為Part1、Part2、Part3。

圖1 模型結構圖及重要參數
該模型的第一部分(Part1)主要作用為自動特征提取。Part1采用三個獨立的卷積神經網絡對序列進行并行特征提取。為了從數據集中捕獲全局信息,按照一定步幅對這三個卷積神經網絡的第一層卷積核尺寸進行設定。在每個卷積層的卷積運算之后,依次進行批歸一化、應用Swish自門控激活。最后對并行卷積神經網絡提取的時不變特征進行連接(Concat)操作。采用與殘差網絡結構中類似的方式來構建殘差網絡,進一步對卷積神經網絡部分進行優化;通過這種結構,信息可以在較深的神經網絡中更有效地傳播,進而達到優化訓練的目的。
作為深度學習模型核心結構之一,深度神經網絡中激活函數的選擇極其重要;即使所使用激活函數性能只有微小的提升,也會由于它的大量使用而獲得巨大的性能提升。本文模型使用Swish函數作為激活函數。Swish激活函數的設計,主要受到高速網絡(Highway Network)和長短期記憶網絡(Long Short Term Memory, LSTM)中使用 Sigmoid 函數作為門控所啟發。谷歌大腦團隊通過使用相同值進行門控,完成門控機制簡化,并將其稱為自門控(Self-Gating)。相較于傳統門控,自門控最大的優勢是僅需要輸入單個簡單標量。這種優勢令使用自門控的Swish激活函數,可輕易在程序中取代用單個標量進行輸入的激活函數,如現在廣泛使用的修正線性單元(Rectified Linear Unit, ReLU)激活函數,并且不需對參數的隱藏數量或容量進行改變。Swish函數和ReLU函數的數學表達式如下:
(1)
ReLU(x)=max(x,0)
(2)
圖2為兩種激活函數曲線對比。
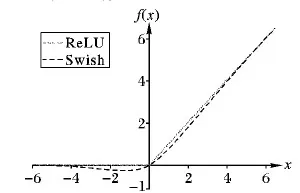
圖2 Swish和ReLU函數曲線對比
Swish激活函數形式極其簡單,且具有非單調、平滑等特性;這些優勢理論上使Swish成為優于ReLU的激活函數,并且谷歌大腦團隊通過大量相關實驗得出:在不改變針對ReLU設計的超參的情況下,用Swish 直接替換ReLU,可以在總體上提升深度神經網絡的分類精度和收斂速度[16]。本文會在4.3節對兩種激活函數應用于本文模型中的效果進行對比。
1.2 時間信息解碼部分
第二部分是由兩層雙向門限循環單元構建的遞歸神經網絡,和含有池化層的捷徑連接,共同構成的序列殘差學習框架。該框架可從時不變特征中學習時間信息特征,并完成時不變特征與時間信息特征的融合。具體結構及部分參數如圖1中Part2所示。
門限循環單元(Gated Recurrent Unit, GRU)是LSTM的一個變化極大的變體。GRU除擁有 LSTM的優點外,相較于LSTM具有更少的參數,出現過擬合問題的概率更小,處理同樣的問題收斂所用時間更少。
本文模型使用雙向GRU構建的遞歸神經網絡,學習時間序列中的時間信息特征。雙向GRU結構相對于單向GRU,可以通過兩個GRU獨立處理前向和后向輸入序列來擴展GRU;前向和后向GRU的輸出彼此之間沒有連接,因此該模型能夠利用時間點前后兩側的信息。
此外本文模型中的七個捷徑連接都使用了最大池化層。這樣一方面可對輸入的時不變特征進行維度變換;另一方面可大幅減少參數數量,進而減少訓練過程中的過擬合。
1.3 分類器
第三部分(圖1中Part3)是完全連接的Softmax層。本層位于模型的最后階段,具體的來說就是:第二部分產生的復合特征形成模型的倒數第二層,經過Dropout[17]隨機丟棄部分神經元,然后被饋送到完全連接的Softmax層以產生分類。圖1中兩個全連接的Softmax層(Softmax-1、Softmax-2)分別用于預訓練和微調(3.1節的模型訓練方法部分會詳細介紹)。
2 實驗數據及數據生成技術
2.1 實驗數據及分析
采用PhysioBank的公開基準睡眠數據(Sleep-EDF數據集)作為實驗數據,Sleep-EDF數據集包含20名25~34歲的健康志愿者(男女各一半)的多導睡眠圖(Polysomnography, PSG)記錄,實驗過程沒有使用任何藥物,實驗周期為兩個晝夜(約40 h),采樣頻率為100 Hz。由于原數據集中的一個文件(SC4132E0.npz)已經損壞,實驗數據集共包含39個文件。人工標記時,將PSG劃分為30 s(即3 000個采樣點)一段,然后由睡眠專家根據睡眠分期標準進行人工標記。本文使用Fpz-Cz通道的原始腦電數據對模型進行評估。使用最新的美國睡眠醫學學會(American Academy of Sleep Medicine, AASM)標準。依據AASM標準整個睡眠監測過程由3個階段組成,分別是清醒(Wake, W)期、非快速動眼(Non-Rapid Eye Movement, NREM)期和快速動眼(Rapid Eye Movement, REM)期。其中NREM期又細分為淺睡一(NREM1, N1)期、淺睡二(NREM2, N2)期和慢波睡眠(NREM3, N3)期。表1為睡眠專家人工分類結果。
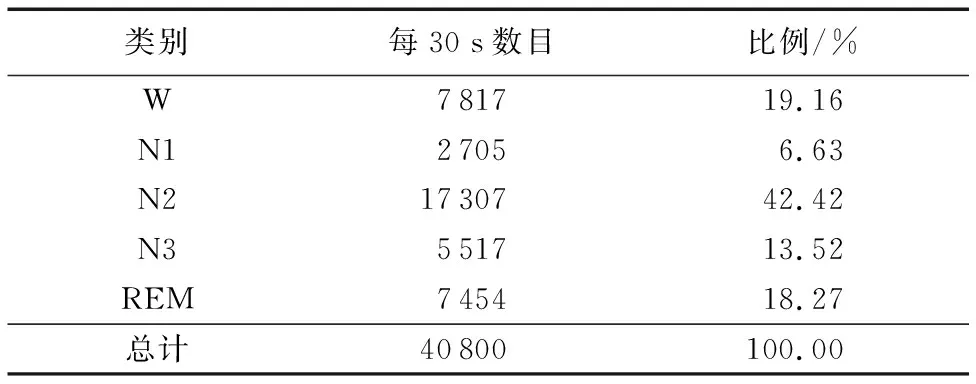
表1 睡眠專家對數據的分類及各期比例
通過表1中各分類占總數據的比例可知,該睡眠數據集為類不均衡數據集,且占比最小的類為N1期(僅為6.63%)。原始數據中出現類不均衡是分類任務中的典型問題,通常以少數類占總數的10%到20%為類不平衡研究對象。事實上若實驗所用數據集較大,無論是少數類還是多數類都有足夠的數據用于訓練,類不平衡的影響可忽略,但是本文采用數據集較小,類不均衡會造成模型對于少數類的分類精度較差。通常是通過復制來完成少數類的過采樣,進而完成類平衡數據集的構建,以減少對類不均衡小數據集中的少數類的影響,但復制重構后的數據集用于訓練極易出現過擬合問題。
2.2 構建類平衡數據集
本文對MSMOTE進行改進,并將其應用于高維度多分類數據集的擴增,進而完成多分類數據集中少數類的過采樣,最終生成類平衡數據集。MSMOTE將少數類分為安全類、邊界類、噪聲類,并對安全類和邊界類進行擴增,MSMOTE對于低維數據的生成效果較好。考慮到本文所使用的睡眠數據為高維數據(3 000維),強化各類邊界所起到的作用不明顯,還會產生部分不屬于任何分類的新數據,干擾最終的訓練效果。對MSMOTE進行改進,只對少數類中的安全類進行擴增;并從控制擴增后少數類樣本區域范圍(決策域)的角度出發,對安全類中新樣本的生成算法進行修改。具體修改如下:
1)以N1期的一個新樣本newS的生成為例,通過k鄰近算法確定屬于N1的安全類樣本。
2)隨機選取一個安全類樣本S[i],從S[i]的3 000個維度中隨機選取500個進行修改,修改后的維度與未修改的剩余2 500維重新組合,生成屬于N1的新樣本newS。
3)若待修改的數據S[i][d](位于S[i]的第d維),判斷S[i]為安全類的k個鄰近點的第d維的數據分別用N1d、N2d…、Nkd表示,從S[i][d]、N1d、N2d…、Nkd中任意選取一個數來作為新生成的newS的第d維數值。
修改后的新的少數類生成過采樣技術稱為維度修改生成少數類過采樣技術(Dimension Modified Synthetic Minority Oversampling Technique, DMSMOTE),DMSMOTE偽代碼如下:
輸入:T個少數類樣本;DMSMOTE生成的樣本數N;鄰近數k。
輸出:生成的N個少數類樣本。
k=鄰近樣本數;numdimens= 樣本維度數;S[][]:原始少數類樣本;newindex:生成樣本的索引號,初值為0;newS[][]:生成樣本數組。
*(計算每個少數類的k個鄰居,對安全類進行擴充)*
fori← 1 toTdo
計算第i個少數類樣本的k個鄰近樣本的同類鄰近數,將同類鄰近樣本的索引值保存在nnarray中。
if(type==2)
//type=0,1,2;其中2代表安全類
Populate(N,i,nnarray)
end if
end for
RandomSelect(chooseList)
*(從該安全類和其所有鄰居的第d維數據中隨機選取一個數據)*
從1到k+1中隨機生成一個隨機數,叫作i
returnchooseList[i-1]
Populate(N,i,nnarray)
*(從該安全類S[i]和其所有鄰居中產生少數類樣本)*
whileN≠0 do
cdimens=需要改變的維度數
flag[numdimens]:flag== 1 表示該維度不需要改變,初值為0
forattr← 1to(numdimens-cdimens) do
//保留原安全類中numdimens-cdimens個不同維度的數據
//不變
newS[newidex][d] =S[i][d] //隨機選取一個在1和
//numdimens之間的數d,且flag[d]≠1
flag[d] = 1
end for
ford← 1 tonumdimensdo
ifflag[d]≠1
//從該安全類和其所有鄰居的第d維的數據組成的列表中
//隨機選取一個數據作為新生成樣本newS的第d維數據值
chooseList= [S[i][d],S[nnarray[0][d] ,
S[nnarray[1][d],…,S[nnarray[k][d]]
newS[newindex][d]= RandomSelect(chooseList)
end if
end for
newindex++
N=N-1
end while
returnnewS
3 模型訓練及參數設定
3.1 模型訓練方法
理論上,深度學習模型性能會隨著網絡深度的加深而增強,但是更深的網絡也意味著需要更大的數據集來支撐訓練。目前絕大多數領域都無法提供足量的數據,遷移學習的引入,為數據相似度較高的領域提供了數據共享[18-19]的可能性。本文仿照遷移學習方法對模型進行訓練,首先將經DMSMOTE擴增后的類平衡數據集用于對模型進行預訓練,然后使用未經任何處理的原始順序數據集對預訓練后的模型進行微調。本文模型進行預訓練的主要目的為學習類平衡數據集的結構,使卷積層權值靠近較優的(保持在有高梯度區間內)局部最優解,以便能夠有效地對權值進一步微調。訓練過程中使用基于小批量梯度下降的自適應動量估計(Adaptive moment estimation, Adam) 優化器對網絡權值進行更新。
圖3為具體訓練流程。
1)使用經DMSMOTE擴增后的類平衡數據集,對整個模型進行預訓練。保留預訓練最后一個歷元中part1和part2的神經網絡權值,并將其作為微調初值。
2)將用于預訓練的Softmax-1(圖1)及其全連接層(dense-1),置換為用于微調的Softmax-2及dense-2。
3)使用原始順序數據集,對置換了全連接及Softmax層的模型進行微調。

圖3 模型訓練方法解析
3.2 參數設定
參數設定是影響實驗效果的關鍵因素。為了對不同層次時不變特征進行提取,按照一定步幅,對圖1中三個獨立的卷積神經網絡中第一層卷積運算的卷積核尺寸進行設定。圖1中標示了各卷積運算的卷積核大小、卷積核個數、步長(如 “conv 50,64,6”表示卷積核尺寸為50,個數為64,卷積運算步長為6 )。對于卷積運算中的補零(pading)規則,參數將全部設置為“SAME”。除此之外,圖1中還標示了池化層中的池化尺寸和步長,全連接層和遞歸神經網絡層的單元(cell)個數。
預訓練的學習率設置為0.001,Adam優化器中參數beta1、beta2分別為0.9和0.999。預訓練的歷元(epoch)數為90,一個迭代(iteration)選取序列個數(batchsize)為10,每個序列長度30,梯度削波的閾值設為10。 DMSMOTE中的k值設置為3,模型中Dropout參數設置為0.5。Swish技術對應開啟的縮放參數gamma(mean=1.0,variance=0.002)。對于微調訓練,除歷元數設為160,學習率設置為0.000 1,其他所有參數與預訓練完全相同。
4 模型評估及實驗分析
4.1 模型評估設計
為全面評估模型性能,會從宏觀(總體)和微觀(每類)兩方面對模型進行評估。總體評估指標包括總體分類精度(Overall Accuracy, OA)以及宏平均F1值(Macro-averaged F1-score, MF1);對于每類評估,使用每類召回率(REcall, RE)、每類精度(PRecision, PR)、每類F1值(F1-score, F1)來評估模型性能。由于本文有五個分類,每類評估通過將其他各類當作負例(Negative),待評估類作為正例(Positive)進行評估。
各指標計算表達式如下:
PRi=TPi/(TPi+FPi)
(3)
REi=TPi/(TPi+FNi)
(4)
F1i=2PRi×REi/(PRi+REi)
(5)
(6)
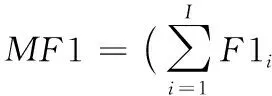
(7)
式(3)~(7)中:TPi為i類真陽數,F1i為i類F1值,I為睡眠階段總數,N為所有類的總樣本數。公式中參數含義如表2所示。
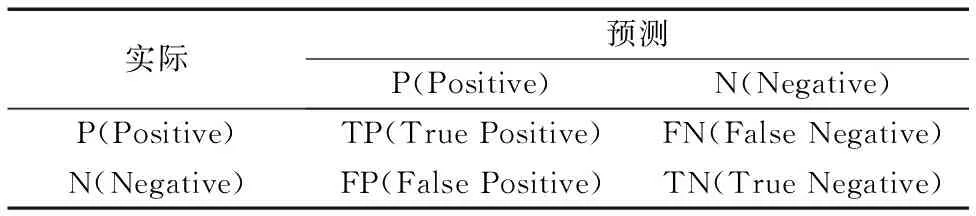
表2 公式中各參數含義
為了在數據樣本量較少時,最大化利用現有數據樣本對模型進行合理評估,本文使用K折交叉驗證(K-fold Cross Validation)來評估本文模型。
4.2 實驗方案設計
為確定K折交叉驗證實驗最佳K值,對本文提出的模型分別進行5、10、15、20、25折交叉驗證實驗,得出15折交叉驗證實驗分類性能為最優。
為驗證本文所提出的DMSMOTE及各種優化結構的合理性,所進行的主要實驗如表3所示。其中“捷徑連接”為模型中的7個捷徑連接。
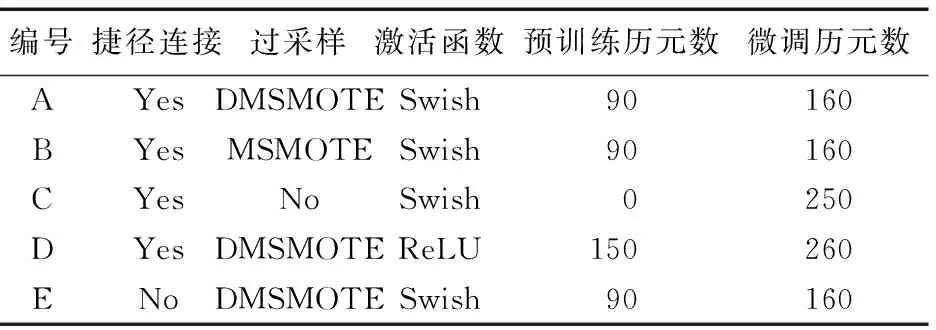
表3 實驗設計
A、B、C、D、E這5組實驗中,A實驗所用的模型為理論最優模型。A組實驗得出的結果一方面代表本文模型最優實驗結果,一方面用于與其他四組作對比。五組實驗皆采用15折交叉驗證。為控制DMSMOTE生成類平衡數據的隨機性,需要用到DMSMOTE構建的類平衡數據的實驗(C、D),直接調用實驗A中的類平衡數據。其他四組實驗目的如下:
1)B組。B組采用MSMOTE對預訓練中的少數類進行過采樣。與實驗A對比用以驗證采用DMSMOTE進行過采樣,相對于MSMOTE能否取得更好的效果。
2)C組。可驗證結合DMSMOTE生成的類平衡數據對模型作預激活處理,對模型的分類效果是否具有提升作用,尤其是對少數類分類效果的影響。
3)D組。得出ReLU作為激活函數時模型的分類效果,并與A組模型的收斂速度以及分類效果作對比。
4)E組。得出移除7個捷徑連接模塊后模型的分類效果,與A組結果對比驗證這種結構的合理性。
4.3 實驗結果及分析
圖4為5組實驗得出的總混淆矩陣圖,總混淆矩陣是由15折交叉驗證中的每折驗證集混淆矩陣相加得出的。第6列表示每類召回率(REi),第6行代表每類精度(PRi),6行與6列交匯處(各組混淆矩陣右下角)為總體精度(OA)。圖4中A組實驗結果的右側為各組實驗所得的MF1值。

圖4 五組實驗總混淆矩陣結果
從圖4中各實驗分類數據指標可直觀看出:A組的分類效果明顯優于E組;由此可知,模型中7個捷徑連接模塊的嵌入可優化訓練,進而提升模型分類性能。
圖4中A組與C組結果對比可知,采用DMSMOTE生成的類平衡數據對模型作預訓練,然后再用原始數據對模型微調,獲得的總體分類效果優于采用原始類不均衡數據直接對模型進行訓練。為進一步驗證采用DMSMOTE生成的類平衡數據作預激活處理,對數據集中少數類的影響;使用A、C兩組實驗結果中的每類指標進行分析。以W期F1值提升百分比為例,aF1W代表A組W期的F1值,cF1W代表C組W期的F1值,P代表A組W期F1值相對于C組提升百分比值,正值代表有所提升,負值代表下降。計算公式為:
(8)
表4為A實驗相對C實驗的每類指標(每類精度、每類召回率、每類F1值)提升百分比。
由表4可直觀看出,使用DMSMOTE生成的類平衡數據對模型作預激活處理,相較于直接使用原始數據進行訓練,對各類的分類效果都有所提升。其中占數據集總數最少的類(N1期)各指標提升幅度最大;REM期的召回率雖然有略微下降,但分類效果是提升的。由圖4中A、C兩組實驗所得的總混淆矩陣也能看出,與C組實驗結果相比,A組實驗結果中各分類的真陽數都在增加;N1期被誤分到其他期的數值,除N2期與C組保持持平,其他各期數目都有所下降。實驗表明:使用DMSMOTE生成的類平衡腦電數據集用于預訓練,在提升總體分類效果的同時,對各類別的分類效果都有所提升,且可大幅提升極少數類(N1期)的分類效果。
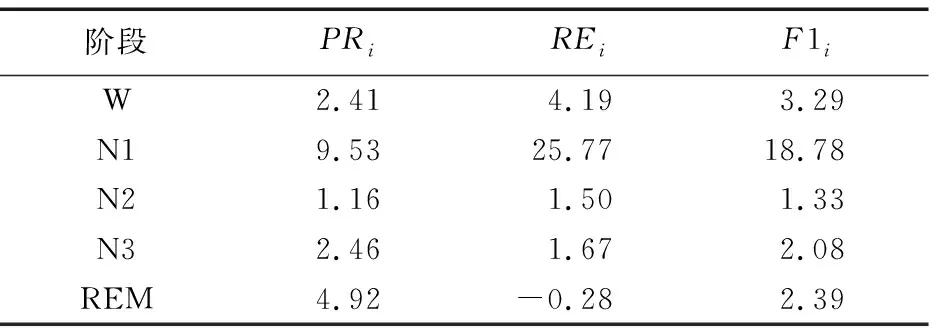
表4 用DMSMOTE生成的類平衡數據作預訓練對各類分類效果提升 %
由圖4中A、B兩組實驗結果對比可知,采用DMSMOTE生成的類平衡數據對模型作預訓練,獲得的總體分類效果優于MSMOTE。為進一步分析使用DMSMOTE生成的類平衡數據對模型作預激活處理對各類的提升效果(相對于MSMOTE),使用A、B兩組的實驗結果中的每類指標進行分析。表5為A實驗相對B實驗的每類指標(每類精度、每類召回率、每類F1值)提升百分比,計算公式與式(8)類似,正值代表有所提升,負值代表下降。
由表5結果可知,DMSMOTE用于對本文實驗數據作過采樣處理,相對于MSMOTE,對各分類的分類效果都有所提升,尤其對極少數類(N1)的提升較明顯。綜合總體和每類兩方面的指標來看,DMSMOTE用于處理高維多分類腦電數據獲得的性能較優。
由圖4中A、D兩組實驗結果的對比可知:將兩種激活函數分別應用于本文模型,Swish在本模型中所取得的分類效果略優。為進一步比較兩激活函數對本文模型收斂速度的影響,對兩組實驗模型微調時的收斂效果進行對比。對比所采用的指標:
指標1 每個模型訓練集平均損失函數曲線。該曲線由AverageLi組成。
Lij表示第i個歷元第j折的損失函數值,第i個歷元的平均損失值AverageLi的計算公式為:
(9)
指標2 每個模型訓練集平均總體精度函數曲線。該曲線是由AverageOAi組成。
OAij表示第i個歷元第j折的總體精度值,第i個歷元的總體精度AverageOAi的計算公式為:
(10)

表5 DMSMOTE用于過采樣相對于MSMOTE對各類指標的提升 %
圖5為采用這兩種指標的兩模型微調收斂效果對比圖,其中A、D兩模型微調訓練歷元數分別為160、260。
圖5(a)為依據指標1所繪制的曲線,圖5(b)為依據指標2所繪制的曲線。由圖5可直觀看出,采用Swish函數作為本模型的激活函數,收斂速度明顯高于使用ReLU函數。圖5(a)底端的水平線(以ReLU作為激活函數所得第160個歷元的訓練損失平均值為縱坐標所作的水平線)也可看出,采用ReLU函數作為激活函數時,第160個歷元的收斂效果與Swish函數作為激活函數的第110個歷元的收斂效果相當。綜合圖4中的模型A、D分類效果以及圖5中的收斂速度對比可知:作為本文模型所要使用的激活函數,Swish函數略優于ReLU函數。
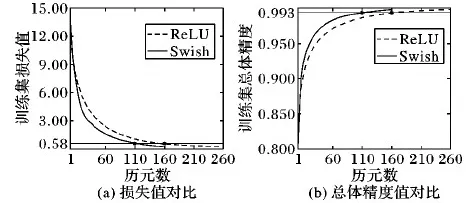
圖5 Swish和ReLU函數平均收斂速度對比
4.4 模型評估
為驗證本文所提出的模型的有效性,將本文模型實驗(實驗A)結果,與近年采用Sleep-EDF數據集(Fpz-Cz通道)作為實驗數據的研究成果進行比較。為客觀評價各文獻模型,只選取進行交叉驗證實驗的文獻進行對比。多評價指標對比結果如表6所示。
表6的四組模型中,文獻[3]使用的是人工設計特征的方法,文獻[11]、[12]以及本文采用的是卷積神經網絡自動提取特征的方式。本文方法相對于其他三種方法獲得了更好的分類效果;除本文外,文獻[12]所提出的模型分類效果最佳。相比文獻[12]所提出模型的分類效果,本文模型OA和MF1兩指標提升比例分別為5.74%、6.28%,同時也明顯提升了數據集中極少數類N1期的分類效果(F1值提升幅度為15.21%)。
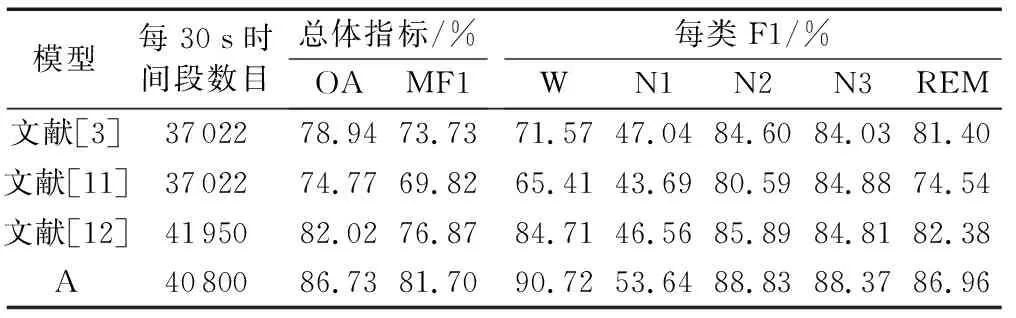
表6 近兩年先進研究與本文結果對比
5 結語
本文設計一種基于深度學習和少數類生成技術的自動睡眠分期模型。實驗表明,該模型能完成少量類不均衡原始睡眠腦電數據的高精度端到端分期。鑒于其端到端特性,該模型更適用于配備遠程服務器的分體式便攜睡眠監測設備。
本文提出DMSMOTE算法,并將其用于類不平衡腦電數據集中少數類的過采樣。 DMSMOTE結合預訓練的方法只能一定程度上減少類不均衡造成的影響,并不能避免這種分布造成的缺陷。以后的研究可通過采用集成學習算法技術對微調部分的分類器進行修改,以增強其對原始類不均衡微調數據集的適應性,最終達到提升模型分類效果的目的。
[10] WANG J, YU L C, LAI K R, et al. Dimensional sentiment analysis using a regional CNN-LSTM model [EB/OL]. [2017- 12- 11]. http://www.aclweb.org/anthology/P/P16/P16-2037.pdf.
[11] TSINALIS O, MATTHEWS P M, GUO Y, et al. Automatic sleep stage scoring with single-channel EEG using convolutional neural networks [EB/OL]. [2016- 10- 05]. http://xueshu.baidu.com/s?wd=paperuri%3A%284f2f11d92bb57d7a8b02a0ad792a9478%29&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http%3A%2F%2Farxiv.org%2Fpdf%2F1610.01683&ie=utf-8&sc_us=3154002015441067732.
[12] SUPRATAK A, DONG H, WU C, et al. DeepSleepNet: a model for automatic sleep stage scoring based on raw single-channel EEG [J]. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 2017, 25(11): 1998-2008.
[13] HU S, LIANG Y, MA L, et al. MSMOTE: improving classification performance when training data is imbalanced [C]// IWCSE ’09: Proceedings of the 2009 2nd International Workshop on Computer Science and Engineering. Washington, DC: IEEE Computer Society, 2009, 2: 13-17.
[14] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 770-778.
[15] IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift [EB/OL]. [2017- 12- 20]. http://proceedings.mlr.press/v37/ioffe15.pdf.
[16] RAMACHANDRAN P, ZOPH B, LE Q V. Swish: a self-gated activation function [EB/OL]. [2017- 10- 27]. http://xueshu.baidu.com/s?wd=paperuri%3A%2829e84daf3ac69561b1408e4fa0638c79%29&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http%3A%2F%2Farxiv.org%2Fpdf%2F1710.05941v1&ie=utf-8&sc_us=7597521573451541055.
[17] HINTON G E, SRIVASTAVA N, KRIZHEVSKY A, et al. Improving neural networks by preventing co-adaptation of feature detectors [J]. Computer Science, 2012, 3(4): 212-223.
[18] 王文朋,毛文濤,何建樑,等.基于深度遷移學習的煙霧識別方法[J].計算機應用,2017,37(11):3176-3181.(WANG W P, MAO W T, HE J L, et al. Smoke recognition based on deep transfer learning [J]. Journal of Computer Applications, 2017, 37(11): 3176-3181.)
[19] 李彥冬,郝宗波,雷航.卷積神經網絡研究綜述[J].計算機應用,2016,36(9):2508-2515.(LI Y D, HAO Z B, LEI H. Survey of convolutional neural network [J]. Journal of Computer Applications, 2016, 36(9): 2508-2515.)
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中老年保健(2021年12期)2021-11-30 02:58:01
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
中華詩詞(2018年11期)2018-03-26 06:41:34
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年8期)2016-10-09 02:11:50
