主動容錯云存儲系統的可靠性評價模型
2018-10-16 08:23:50劉冬實
計算機應用 2018年9期
李 靜,劉冬實
(1.中國民航大學 計算機科學與技術學院,天津 300300; 2.南開大學 計算機與控制工程學院,天津 300500)
0 引言
近年來,大規模云存儲系統已成為主流IT企業的主要存儲架構,因為價格等方面的優勢,硬盤仍然是它們的主要存儲介質。由于制作工藝及技術的進步,單體硬盤的可靠性不斷提高,但是,在包含成千上萬塊硬盤的大規模云存儲系統中,硬盤故障甚至是并發故障時有發生[1]。硬盤故障不僅會引起服務中斷、降低用戶服務體驗,甚至會導致數據的永久丟失,給企業和用戶帶來無法挽回的損失。因此,當前大規模云存儲系統面臨著高可靠性的挑戰。
傳統存儲系統普遍采用副本或糾刪碼等冗余機制提高系統的可靠性,如果有硬盤發生故障,系統可以利用其他存活盤上的數據重構故障數據,這是一種典型的“故障-重構”模式的被動容錯方式。然而,面對硬盤故障頻發的大規模云存儲系統,被動容錯技術只能通過不斷增加冗余來保證系統的可靠性,導致系統承受高昂的構建、維護成本以及沉重的讀寫開銷。硬盤故障預測[2-3]可以在硬盤真正故障之前發出預警,提醒用戶對危險數據采取措施(遷移或備份),從而減少或避免硬盤故障帶來的損失,這是一種“預警-處理”模式的主動容錯機制。如果具有良好的預測性能和有效的預警處理機制,主動容錯機制可以大幅度提高云存儲系統的可靠性。
正如Eckart等[4]所說,主動容錯方式并不能完全避免硬盤故障的發生(沒有達到100%的預測準確率),還需要結合一定的冗余機制共同保證系統的可靠性,因此主動容錯云存儲系統的可靠性分析非常復雜。目前針對該領域的研究非常匱乏,僅有少量研究[2,4-5]基于硬盤故障及重構過程符合指數分布的假設,采用馬爾可夫(Markov)模型評價主動容錯存儲系統的可靠性。
而且,現有研究存在以下缺陷:1)故障分布假設不合理。基于指數分布的假設,硬盤故障率和修復率恒定不變,文獻[6]通過領域數據的分析推翻了該假設。2)故障類型考慮不全面。只關注硬盤完全崩潰故障,而忽略了潛在扇區錯誤等塊故障對系統可靠性的影響,隨著系統規模和單體硬盤容量的增大,塊故障已不容忽視[7]。3)度量指標不準確。采用平均數據丟失時間(Mean Time To Data Loss, MTTDL)作為可靠性評價指標,而MTTDL相對于系統的實際運行時間過長,并不能準確評價云存儲系統的可靠性水平[8]。
本文針對主動容錯磁盤冗余陣列(Redundant Arrays of Independent Disks, RAID)RAID-5和RAID-6云存儲系統提出兩個可靠性狀態轉移模型,描述系統在各種可靠性狀態之間的轉換,并根據模型設計了蒙特卡洛仿真算法,模擬主動容錯RAID系統的運行,統計系統在一定運行周期內發生數據丟失事件的期望個數。本文方法克服了現有研究的缺陷,采用更接近實際的韋布分布(而不是指數分布)函數描述隨時間變化(下降、恒定不變、或上升)的硬盤故障和修復率,除硬盤整體故障外,增加考慮塊故障和磁盤清洗過程對云存儲系統可靠性的影響,并采用更合理的指標(某一運行周期內發生數據丟失的個數)評價系統可靠性。利用本文方法可以準確、定量地評價主動容錯技術和系統參數對存儲系統可靠性的影響,幫助系統設計師(或管理員)設計出滿足可靠性要求的容錯方案,更好地理解系統性能和可靠性之間的權衡。
1 背景知識
1.1 相關工作
硬盤期望壽命的研究是可靠性評價的基礎。Gibson[9]認為硬盤故障時間(Mean Time To Failure, MTTF)服從指數分布是一個合理假設,這為后來很多研究[2,4-5,10-11]利用馬爾可夫模型分析存儲系統可靠性提供了理論指導;但Schroeder等[6]以高置信度推翻了硬盤故障時間服從指數分布的假設,他們建議研究者使用真實的故障替換數據(或是雙參分布,如韋布分布),模擬硬盤的故障時間,已有一些研究[12-15]基于硬盤故障非指數分布的前提,使用仿真或組合分析等方法分析存儲系統的可靠性。
基于硬盤故障分布數據,研究者提出了一些存儲系統可靠性評價方法,有三類被廣泛采用:1)連續時間馬爾可夫鏈模型[2,4-5,10-11]能直觀表示系統的故障、修復等事件,基于硬盤故障指數分布假設前提,可方便地計算系統平均數據丟失時間(MTTDL);2)蒙特卡洛仿真方法[13,16]適用于不同的硬盤故障分布,且容易表達一些復雜策略,如延遲校驗計算、延遲修復等;3)組合分析方法[13-15]直接計算各種數據丟失情況的概率,計算速度遠優于前兩種方法,且能與它們結合,適用于不同硬盤故障分布。
伴隨著硬盤故障預測問題的研究,學術界也相應地出現了一些評價主動容錯存儲系統可靠性的研究[2,4-5],但是這些方法存在一些缺陷,并不能真實有效地評價主動容錯存儲系統的可靠性水平。因此,本文擬彌補現有方法的缺陷、研究能準確評價主動容錯存儲系統可靠性的方法。
1.2 硬盤故障
潛在塊故障(Latent block defects)一般由潛在扇區錯誤或數據損壞引發:1)潛在扇區錯誤是部分二進制位永久損壞,無論嘗試多少次都不能正確讀取一個扇區,一般由磁頭劃傷或介質損壞等物理原因造成;2)數據損壞是數據塊上存放著錯誤的數據,只能通過校驗信息驗證才能發現,通常由軟件或固件缺陷造成。隨著系統和硬盤個體容量的增大,這些塊級別的硬盤故障已不能再被忽視。為檢測和修復塊故障,存儲系統通常在后臺運行著一個“磁盤清洗”進程,主動讀取并檢測系統中所有的數據塊,如果發現損壞數據塊,系統會利用冗余信息重構損壞數據。
運行故障(operational failure)是硬盤最為嚴重的故障形式,表現為整個硬盤永久不可訪問,只能通過替換硬盤進行修復。如果系統中發生了運行故障,系統會立即啟動故障重構過程,利用其他存活盤上的數據和冗余信息恢復出故障數據。
1.3 主動容錯技術
當前大部分硬盤內部都具有SMART(Self-Monitoring, Analysis and Reporting Technology)[17]配置,SMART 是硬盤的“自我監測、分析和報告”技術,可以實時監測硬盤重要屬性值并與預先設定的閾值進行比較,如果有屬性值超過閾值,則認為硬盤即將發生運行故障,于是發出預警信息,提醒用戶對危險數據進行備份或遷移。為了提高預測性能,有研究者嘗試基于硬盤 SMART 信息、采用統計學或機器學習方法構建硬盤故障預測模型[2-3],其中有一些模型(比如,基于決策樹[2]的預測模型)取得了比較理想的預測效果。
在主動容錯系統中,硬盤故障預測模型運行在系統后臺,實時監測工作硬盤的屬性狀態并周期性地(比如,每隔一小時)輸出它們的“健康度”情況,如果發現預警(危險)硬盤,系統會立刻啟動預警修復進程,把預警硬盤上的數據遷移備份到其他健康硬盤上。
1.4 冗余機制
在云存儲系統中,多個運行故障和(或者)多個塊故障同時發生會導致數據丟失事件的發生,如果(消除運行故障的)重構過程或者(消除塊故障的)磁盤清洗過程能夠及時完成,可以避免數據丟失事件的發生。
RAID-5和 RAID-6是兩種廣泛應用在云存儲系統的冗余機制,存儲硬盤在系統中被劃分為不同的校驗組,數據在校驗組中按條紋存儲,從而實現數據的并行訪問以提高系統訪問性能[18]。每個RAID-5校驗條紋能夠容忍任意一個故障——一個運行故障或一個塊故障;每個RAID-6校驗條紋能夠容忍任意兩個并發故障——兩個并發的運行故障、一個運行故障和一個塊故障、或兩個塊故障。
1.5 韋布分布
在實際系統中,硬盤故障的發生率不是恒定不變的,而是遵循典型的“浴盆曲線”規律[ 19]:經歷過初期比較高的“嬰兒死亡率”之后,硬盤故障率進入平穩期,直到硬盤生命周期的末尾,由于磨損老化,故障率再次升高。另外,Schroeder和Gibson[6]發現,相對指數分布,韋布分布可以更好地擬合硬盤故障數據的累積分布函數。而且,Elerath和Schindler[13]通過領域數據的分析,發現韋布分布可以很好地匹配硬盤故障、修復以及磁盤清洗事件的時間分布。
因此,使用兩個參數的韋布分布函數模擬硬盤故障(運行故障和塊故障)、故障重構以及磁盤清洗過程在云存儲系統中的發生。韋布分布的概率密度函數f,累積密度函數F,風險率函數h,以及累積風險率函數H的公式[20]如下:
(1)
F(t)=1-e(-(t/α)β)
(2)
(3)
H(t)=tβ/αβ
(4)
其中:α是表示特征生命的尺度參數(scale parameter),β是控制分布形狀的形狀參數(shape parameter)。
根據上述公式可以看到:1)β>1時,風險率h隨著時間t的增長而變大,即硬盤發生運行故障的風險隨時間逐漸升高,能夠模擬運行時間較長出現老化現象的云存儲系統;2)β=1時,韋布分布退化為指數分布,即硬盤發生運行故障的概率是恒定不變的(不隨時間變化而變化),能夠模擬處于穩定運行時期的云存儲系統;3)0<β<1時,風險率h隨時間的推移而降低,能夠模擬處于“早期失效”時期的云存儲系統。
2 可靠性狀態轉移模型
2.1 主動容錯RAID-5系統
對于一個RAID-5校驗組,理論上有三種導致數據丟失的情況:
1)同時發生兩個運行故障;
2)同時發生一個運行故障和一個塊故障;
3)同時發生兩個塊故障。
通常每個硬盤存儲著上萬個數據塊,相同校驗條紋上的數據塊同時發生故障的概率非常小(從而可以忽略),即,校驗組內兩個或更多并發的塊故障一般不會導致數據丟失,因此,只考慮上述前兩種導致數據丟失的故障情況。
針對主動容錯RAID-5校驗組,創建了如圖1所示的可靠性狀態轉移模型,大致存在8種不同的可靠性狀態,隨著故障、修復、預警等事件的發生,校驗組在不同可靠性狀態之間轉移。

圖1 主動容錯RAID-5可靠性狀態轉移
圖1中,RAID-5校驗組總共有N+1塊硬盤,包含N塊數據硬盤和一塊冗余硬盤,符號“W”表示預警事件,“OP”表示運行故障事件,“LD”表示塊故障事件。使用單、雙箭頭兩種狀態轉移線,其中,單箭頭表示某一狀態到另一狀態的轉換,雙箭頭表示兩種狀態之間的相互轉換。狀態轉移線上的符號“g[·]”表示狀態之間轉移的通用函數,轉移線上面的“g[·]”是左邊狀態轉移到右邊狀態的函數,下面的表示右邊轉移到左邊的函數。“fdr”表示硬盤故障預測模型的故障檢測率(Failure Detection Rate),“d”表示某事件的時間分布,其中:“dLD”表示塊故障事件的時間分布, “dOP”表示運行故障的時間分布,“dW-OP”表示預警硬盤(沒有被及時處理)發生運行故障的時間分布,“dScrub”表示磁盤清洗事件的時間分布,“dRestore”表示運行故障修復的時間分布,“dHandle”表示預警處理事件的時間分布。“dW-OP”由提前預測模型的提前預測時間TIA(Time In Advance)和預警處理分布“dHandle”確定。
狀態1 校驗組中所有硬盤都在正常運行且沒有塊故障。從狀態1出發校驗組有三種轉移可能:1)有硬盤發生了塊故障(LD),轉移到狀態2;2)有硬盤被預警即將發生運行故障(出現預警硬盤),轉移到狀態3;3)有硬盤(被預測模型漏報)發生了運行故障,轉移到狀態5。狀態轉移依賴于可用硬盤的數量,預測模型的故障檢測率,(運行或塊損壞)故障以及修復(或預警備份)事件的時間分布。比如,從狀態1到2的轉移是N+1塊硬盤根據故障分布dLD發生塊故障的函數,狀態1到5的轉移是N+1塊硬盤根據分布dOP存在故障風險,并以(1-fdr)的概率(被漏報)發生運行故障的函數。
狀態2 校驗組內發生了塊故障。校驗組從狀態2出發有三種轉移可能:1)磁盤清洗過程及時修復了塊故障,返回狀態1;2)其他(無損壞塊的)硬盤被預警即將發生運行故障,轉移到狀態4;3)其他硬盤(被預測模型漏報)發生了運行故障,轉移到狀態7。
狀態3 有硬盤被預警將要發生運行故障。從狀態3出發有4種轉移可能:1)預警硬盤得到及時有效的處理(危險數據被安全遷移到新的健康硬盤,并替換預警盤),返回狀態1;2)其他(非預警)硬盤發生塊故障,轉移到狀態4;3)預警硬盤沒有得到及時處理,發生了運行故障,轉移到狀態5;4)其他硬盤發生運行故障,轉移到狀態6。
狀態4 校驗組內發生了塊故障,同時又有其他硬盤被預警。從狀態4出發有三種轉移可能:1)預警硬盤得到及時處理,返回狀態2;2)磁盤清洗過程消除了塊故障,返回狀態3;3)預警硬盤沒有被及時修復而發生了運行故障,或者其他硬盤發生了運行故障,轉移到狀態7。
狀態5 校驗組內發生了運行故障。從狀態5出發有四種轉移可能:1)故障修復完成(增加新硬盤替換故障硬盤,并重構損壞數據),返回狀態1;2)其他硬盤被預警,轉移到狀態6;3)其他硬盤又發生了運行故障,轉移到狀態8;4)其他硬盤發生塊故障,轉移到狀態7。
狀態6 校驗組內發生了運行故障,同時又有其他硬盤被預警。從狀態6出發有三種轉移可能:1)運行故障被成功修復,返回狀態3;2)預警硬盤得到及時處理,返回狀態5;3)預警硬盤發生了運行故障,或者,其他(非預警)硬盤發生運行故障,轉移到狀態8。
狀態7 校驗組內同時發生一個運行故障和其他硬盤的塊故障。
狀態8 校驗組內存在兩個并發的運行故障。處于這兩種狀態時,校驗組發生數據丟失事件,不能再提供正常服務。
2.2 主動容錯RAID-6系統
對于一個RAID-6校驗組,理論上有4種導致數據丟失的情況:
1)3個運行故障同時發生;
2)2個運行故障和1個塊故障同時發生;
3)1個運行故障和2個位于同一條紋的塊故障同時發生;
4)3個位于同一條紋的塊故障同時發生。
與RAID-5類似,多個并發的塊故障處于同一校驗條紋的概率很小,可以忽略。通常來說,當RAID-6校驗組內3個硬盤同時發生損壞時(3個運行故障,或者,2個運行故障和1個塊故障),會導致數據丟失事件的發生。
針對主動容錯RAID-6校驗組,創建了如圖2所示的可靠性狀態轉移模型。

圖2 主動容錯RAID-6可靠性狀態轉移
RAID-6校驗組內有N+2塊硬盤,包括N塊數據盤和2塊校驗盤,大致存在12種可靠性狀態,其中,狀態1~8與圖1的情況類似,此處僅介紹與圖1不同的內容。因為RAID-6可以容忍任意的兩個并發故障,所以轉移到狀態7和8時,不會發生數據丟失,系統還可以自我修復。
處于狀態4時,如果其他(非預警或塊損壞)硬盤發生運行故障,轉移到狀態9。
處于狀態6時,如果:1)其他(非預警)硬盤發生塊故障,轉移到狀態9;2)其他硬盤發生運行故障,轉移到狀態10。
處于狀態7時,如果:1)其他硬盤被預警,轉移到狀態9;2)其他硬盤發生運行故障,轉移到狀態11。
處于狀態8時,如果:1)其他硬盤被預警,轉移到狀態10;2)其他硬盤發生運行故障,轉移到狀態12;3)其他硬盤發生塊故障,轉移到狀態11。
狀態9,校驗組內發生了運行故障和塊故障,同時又出現預警硬盤。此時,校驗組有四種轉移可能:1)運行故障得到及時修復,返回狀態4;2)預警硬盤得到及時有效的處理,返回狀態7;3)塊故障被磁盤清洗消除,返回狀態6;4)預警硬盤沒有得到及時修復,發生了運行故障,或者其他硬盤發生運行故障,轉移到狀態11。
狀態10,校驗組內有兩個并發的運行故障,同時又有硬盤被預警。此時,校驗組有3種轉移可能:1)某個運行故障被成功修復,返回狀態6;2)預警硬盤得到及時處理,轉移到狀態8;3)預警硬盤發生了運行故障,或者其他硬盤發生運行故障,轉移到狀態12。
狀態11,校驗組內發生了2個運行故障和一個(些)塊故障,數據丟失事件發生。
狀態12,校驗組內同時發生了3個運行故障,數據丟失事件發生。
3 仿真
根據第2章提出的可靠性狀態轉移模型,設計了事件驅動的蒙特卡洛仿真算法,模擬主動容錯RAID云存儲系統的運行,并統計系統在一定運行周期內(比如10年)發生數據丟失事件的期望個數。算法通過6種仿真事件向前推進模擬時間:
a)運行故障事件,潛在存在于每一個硬盤上;
b)塊故障事件,潛在存在于每一個硬盤上;
c)故障重構完成事件,在運行故障修復完成時觸發;
d)磁盤清洗完成事件,在磁盤清洗過程完成時觸發;
e)故障預警事件,在預測模型檢測到潛在運行故障時觸發(故障發生前TIA小時發生),受到預測模型性能的限制;
f)預警處理完成事件,在預警數據備份完成時觸發。
事件e)和f)模擬了主動容錯技術在存儲系統中的應用,事件c)和f)觸發系統增加新硬盤。如果發生的故障滿足一定條件,系統發生數據丟失事件,為了保持系統規模,增加新數據到系統中。
程序開始時為系統中的每塊硬盤生成一個潛在的運行故障和塊故障,并基于硬盤故障預測模型的性能生成一些預警事件,然后根據事件發生的先后順序插入一個最小堆。在程序運行期間(達到指定仿真時間之前),不斷地從最小堆的頂部彈出最先出現的事件以模擬它的發生,并根據事件類型采取相應操作。事件的發生時間是累積的,直到達到或超過指定的仿真時間。重復執行仿真程序,直到系統發生10次以上的數據丟失事件,最后統計數據丟失事件的期望數量作為仿真程序的結果。
4 評價
本章首先評價了可靠性狀態轉移模型的準確性,然后利用模型對主動容錯RAID云存儲系統作了參數敏感性分析。
4.1 實驗準備
對仿真算法中的事件a)~d),使用Elerath等[13]通過領域數據分析得出的分布參數,詳細信息見表1,其中,硬盤A和B是1 TB容量的近線SATA類型硬盤,硬盤C是288 GB容量的企業級FC型號硬盤。
Li等[2]提出的分類決策樹模型可以提前大約360 h預測出95%的潛在運行故障,所以設置提前預警時間TIA=300 h,即運行故障發生前300 h觸發預警事件。預警發出后,系統會啟動預警處理進程,把危險硬盤上的數據遷移備份到其他健康硬盤上。為了簡化程序,假設預警處理需要的時間與故障重構時間相同,使用故障重構的參數設置預警完成事件。

表1 韋布分布參數[13]
設置每個RAID-5校驗組內包含的硬盤總量為15,每個RIAD-6校驗組內為16,這樣,每個 RAID 校驗組內都包含14塊數據硬盤。為每個主動云存儲系統部署1 000個校驗組,即,RAID-5系統總共包含15 000塊硬盤,RAID-6系統總共包含16 000塊硬盤,這樣,兩個存儲系統都存儲相同容量的用戶數據。
4.2 模型驗證
4.2.1 被動容錯系統
如果設置預測模型的故障檢測率(fdr)為0,本文模型退化為被動容錯云存儲系統的可靠性狀態轉移模型。為了驗證模型在被動容錯系統上的有效性,使用論文[14]和[13]中的可靠性公式(被動容錯RAID-5公式[14]、被動容錯RAID-6公式[13])與本文提出的模型作了實驗對比。實驗分別使用公式和仿真統計了不同運行周期內被動容錯RAID-5和RAID-6云存儲系統發生數據丟失事件的期望個數,結果顯示在圖3中。

圖3 系統在不同運行周期內發生數據丟失事件的期望數
對于所有型號的硬盤,每個云存儲系統的仿真結果和公式計算結果都非常接近,只有不到10%的偏差,這些結果證實了本文模型在被動容錯云存儲系統上的有效性。
4.2.2 主動容錯系統
為了驗證模型在主動容錯云存儲系統上的有效性,使用馬爾可夫可靠性評價模型(主動容錯RAID-5模型[4]、主動容錯RAID-6模型[2])與本文的模型進行實驗對比。因為馬爾可夫模型的限制,此實驗設置βf=1,βr=1,并且忽略塊故障和磁盤清洗事件。分別使用仿真算法和馬爾可夫模型評價了硬盤A系統在10年內的可靠性水平,結果顯示在圖4中。
結果顯示,在不同的預測性能下兩種模型得出的結果都非常接近,平均只有10%的誤差,證實了本文模型在主動容錯云存儲系統上的有效性。

圖4 不同預測性能下發生數據丟失事件的期望數
4.3 敏感性分析
使用本文提出的模型,系統設計者在系統部署前或者潛在數據丟失事件發生前就能了解系統參數對系統整體可靠性的影響,有助于系統構建和維護。本節將演示如何使用狀態轉移模型分析系統參數對系統可靠性的影響。除非特殊說明,下述實驗使用硬盤A的分布參數,運行周期設置為10年。
4.3.1 重構時間
故障修復時間越長,系統(降級模式期間)發生并發故障的概率越大,所以故障重構時間對系統可靠性的影響很大。本實驗分析了故障重構時間對主動/被動容錯云存儲系統可靠性的影響。對于主動容錯云存儲,設置預測模型的預測準確率fdr為0.8;當fdr=0時,系統退化為被動容錯系統。
通過調節參數αr改變重構時間,結果顯示在圖5中。

圖5 不同重構時間下發生數據丟失的期望數
正如上述分析所示,隨著重構時間的增加,系統可靠性逐漸降低。而且,1)相比RAID-5系統,RAID-6系統的可靠性受重構時間的影響更明顯,這主要是因為RAID-6系統發生數據丟失需要更多的運行故障;2)與被動容錯系統相比,主動容錯系統的可靠性對重構時間的敏感性低,由于主動容錯技術的引入,系統由“正常-故障恢復”兩狀態變化為“正常-預警處理-故障恢復”三狀態,系統處于故障恢復狀態的時間變短,使得重構時間對系統可靠性的影響減弱。
4.3.2 塊故障率
塊故障的發生頻率受到硬盤型號和硬盤使用情況的影響。本實驗想研究系統可靠性對塊故障率的敏感性。通過改變參數α1調整塊故障的發生頻率,結果顯示在圖6中。結果顯示,塊故障率越高,系統可靠性越低。而且,相比被動容錯系統,主動容錯系統受塊故障率的影響較大,這主要是因為引入主動容錯技術之后,系統中發生運行故障的概率降低,從而導致塊故障對數據丟失事件的貢獻增大。
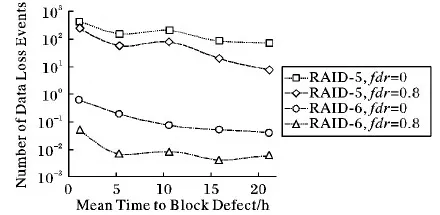
圖6 不同塊故障率下發生數據丟失的期望數
4.3.3 磁盤清洗周期
本實驗研究磁盤清洗周期對系統可靠性的影響,通過改變參數αs調整磁盤清洗時間,結果顯示在圖7中。結果顯示,隨著清洗周期的變長,系統可靠性不斷降低;而且,與塊故障率實驗結論類似,相比被動容錯系統,主動容錯系統對磁盤清洗周期的敏感性更強。

圖7 不同清洗周期下發生數據丟失的期望數
5 結語
本文分別針對主動容錯RAID-5和RAID-6云存儲系統提出可靠性狀態轉移模型,分析了運行故障和塊故障下系統的全局可靠性。基于狀態轉移模型,設計了蒙特卡洛仿真算法,模擬主動容錯云存儲系統的運行,評價主動容錯技術、硬盤運行故障、重構過程、塊故障以及磁盤清洗過程對系統全局可靠性的影響。利用本文提出的模型,系統設計者可以方便準確地評價主動容錯技術以及其他系統參數對云存儲系統可靠性的影響,有助于存儲系統的構建和維護。
[15] EPSTEIN A, KOLODNER E K, SOTNIKOV D. Network aware reliability analysis for distributed storage systems [C]// Proceedings of the 2016 IEEE 35th Symposium on Reliable Distributed Systems. Washington, DC: IEEE Computer Society, 2016: 249-258.
[16] HALL R J. Tools for predicting the reliability of large-scale storage systems [J]. ACM Transactions on Storage, 2016, 12(4): Article No. 24.
[17] ALLEN B. Monitoring hard disks with smart [J]. Linux Journal, 2004, 2004(117):9.
[18] 羅象宏,舒繼武.存儲系統中的糾刪碼研究綜述[J].計算機研究與發展,2012,49(1):1-11.(LUO X H, SHU J W. Summary of research for erasure code in storage system [J]. Journal of Computer Research and Development, 2012, 49(1): 1-11.)
[19] ELERATH J G. Specifying reliability in the disk drive industry: No more MTBF’s [C]// Proceedings of the 2000 International Symposium on Product Quality and Integrity, Reliability and Maintainability Symposium. Piscataway, IEEE, 2000: 194-199.
[20] McCOOL J I. Using the weibull distribution: reliability, modeling and inference [J]. Journal of Applied Statistics, 2012, 41(4): 913-914.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
汽車維修與保養(2019年7期)2020-01-06 03:30:42
家庭影院技術(2017年9期)2017-09-26 03:41:45
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車維護與修理(2016年10期)2016-07-10 08:17:41
