基于深度殘差生成對抗網絡的醫學影像超分辨率算法
2018-10-16 08:23:50秦品樂王麗芳
計算機應用 2018年9期
高 媛,劉 志,秦品樂,王麗芳
(中北大學 大數據學院,太原 030051)
0 引言
圖像超分辨率技術是指從一幅或多幅低分辨率圖像運用技術手段獲得對應的高分辨率圖像,在醫學影像[1-2]、面部識別[3]、衛星圖像[4]等場景擁有廣泛應用。
目前超分辨率技術主要有3類[5],即基于插值[6]、重建[7-8]和學習[9]的方法。基于插值的方法如雙線性內插(Bilinear interpolation, Bilinear),最近鄰插值(Nearest-Neighbor interpolation, NN)[5]和雙三次插值法(Bicubic)[10],該類方法計算時以假設圖像像素的灰度值連續變化為前提,使用鄰近區域像素點的灰度值來計算要插入的像素灰度值,卻沒有考慮到圖像的復雜性。該類算法比較簡單、復雜度低、適應性不強,使得生成的圖像邊緣輪廓比較模糊,視覺上過于平滑,容易產生方塊現象。基于重建的超分辨率技術如迭代反向投影法[11-12]、最大后驗概率方法[13]、凸集投影法[14]。此類方法利用低分辨率圖像作為約束前提,并結合圖像的先驗知識來重建出高分辨率圖像, 在一定程度上緩解了基于插值方法產生的方塊現象,效果上有較好的改善,但當放大倍數較大或輸入圖像尺寸較小時,能有效利用的先驗知識較少,不足以滿足高分辨率的需求,重建出的效果也較差。基于學習的方法,該類方法通過學習高、低分辨率圖像間的關聯,利用樣本圖像的先驗知識來重建高分辨率圖像,相比其他方法有較大優勢。近年來,由于深度學習在諸多領域取得的成功,使得基于深度學習的超分辨率重建方法成為研究的熱點。2014年,Dong等[15]率先將卷積神經網絡應用于圖像超分辨率領域中,提出使用卷積神經網絡的超分辨率(Super-Resolution using Convolutional Neural Network, SRCNN)算法,該算法通過3層的卷積神經網絡結構學習低分辨率到高分辨率的關聯關系,重建出的高分辨率圖像效果相比傳統方法有很大改善,但3層的網絡層次結構太淺,難以獲得圖像深層次的特征。之后,Dong等[16]又提出了快速的超分辨率卷積神經網絡算法,該算法對SRCNN算法進行了改進,將3層的卷積神經網絡結構加深到了8層,同時對低分辨率圖像的上采樣用反卷積取代了雙三次插值,取得了比SRCNN更好的效果,但8層網絡結構依然較淺,重建出的效果有限。Kim等[17]提出基于深度遞歸神經網絡 (Deeply-Recursive Convolutional Network for image super-resolution, DRCN)的超分辨率算法,相比SRCNN較小的局部感受野,DRCN算法通過增加局部感受野大小來進一步利用更多的鄰域像素,同時該算法使用遞歸神經網絡減少過多的網絡參數,取得了較好的效果。Ledig等[18]將深度學習中熱門的生成對抗網絡(Generative Adversarial Network, GAN)應用于圖像的超分辨率重建中,提出了基于生成對抗網絡的超分辨率 (Super-Resolution using a Generative Adversarial Network, SRGAN)算法,該算法將低分辨率圖片樣本輸入到生成器網絡訓練學習,來生成高分辨率圖片,再用判別器網絡辨別其輸入的高分辨率圖片是來自原始真實的圖片還是生成的高分辨率圖片,當判別器無法辨別出圖片的真偽時,說明生成器網絡生成出了高質量的高分辨率圖片。實驗結果表明相比其他深度學習方法,SRGAN算法生成的圖片效果在視覺上更逼真。
將低分辨率的醫學影像進行超分辨率重建,可有效提升影像清晰度,重建后的高清醫學圖像能使醫生更清楚看到組織結構和病變早期發現病情,為醫生對疾病作正確的判斷作輔助診斷,為醫學影像的研究、教學、手術等提供支持。目前超分辨率重建在自然圖像上研究眾多,在醫學影像上的研究還不夠豐富,不同于自然圖像,大多數醫學圖像紋理更復雜,細節更豐富,黑白的顏色沒有彩色那般更好的視覺辨識度,所以保留紋理細節不丟失成為醫學超分辨率重建的關鍵。
鑒于基于深度學習的超分辨率重建方法生成的圖像質量高、視覺效果好,本文在最新的SRGAN基礎上,通過使用縮放卷積、去掉批量規范化層(Batch-Normalization, BN)、增加特征圖數量、加深網絡等對SRGAN作出改進,提出了基于深度殘差生成對抗網絡(Deep Residual Generative Adversarial Network, DR-GAN)的醫學影像超分辨率算法,來達到對醫學影像放大2倍后仍然保留較多的紋理和細節特征的目標。
1 相關理論
1.1 生成對抗網絡
生成對抗網絡(GAN)由Goodfellow等[19]提出,它啟發自博弈論中的二人零和博弈。GAN強大的圖片生成能力,使其在圖片合成[20]、圖像修補[21]、超分辨率[18]、草稿圖復原[22]等方面有直接的應用。
GAN的基本框架包含一個生成器模型(Generative model, G)和一個判別器模型(Discriminative model, D),GAN的過程如圖1所示。
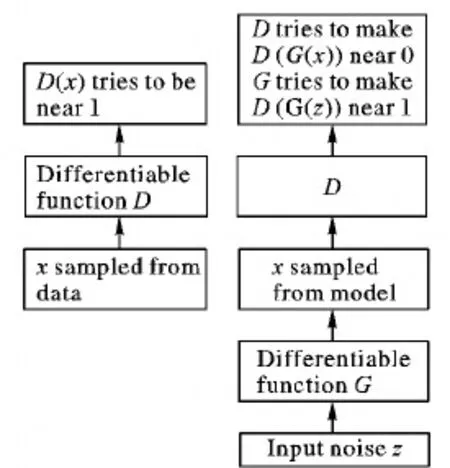
圖1 GAN的基本框架
如圖1所示的GAN的基本框架中, 生成器模型用可微函數G(x)表示,判別器模型用可微函數D(x)表示,每個函數都有可調參數。GAN過程中有兩個場景:第一個場景中,從真實訓練數據中采樣x,作為判別器模型D(x) 的輸入,D(x)通過自身的訓練學習,盡可能地輸出接近1的概率值;第二個場景中,從先驗分布中采樣z,經生成器模型生成偽造樣本G(z),將其作為判別器模型的輸入,判別器模型的目的盡量使D(G(z))接近0,而生成器模型的目的盡量使它接近1,最終在二者的互相博弈中達到平衡。
原始的生成對抗網絡理論中,并不要求生成器和判別器都是神經網絡,只需能夠擬合出相應的生成和判別的函數就可以,但是,由于神經網絡在圖像處理方面的較好效果,所以,本文設計生成器和判別器均為神經網絡結構。
1.2 殘差和快捷連接
殘差網絡(Residual Network, ResNet)和快捷連接(Skip Connection)由He等[23]提出,該網絡結構使得更深的網絡更容易訓練,因而可以通過增加網絡層數提高識別準確率。
殘差塊的基本結構如圖2所示。

圖2 殘差學習:基本殘差塊
如圖2所示,殘差網絡在原始的卷積層上增加跳層快捷連接支路Skip Connection構成基本殘差塊,使原始要學習的H(x)被表示成H(x)=F(x)+x。殘差網絡的殘差結構使得對H(x)的學習轉為對F(x)的學習,而對F(x)的學習較H(x)容易。殘差網絡通過層層累加的殘差塊結構,有效緩解了深層網絡的退化問題,提高了網絡性能。
由于殘差網絡的殘差塊(Residual Block)和快捷連接的結構,改善了網絡深度增加帶來的梯度消失和網絡退化問題,提升了深度網絡的性能。鑒于殘差網絡結構近年來在圖像生成任務上的優異成績,本文將改進算法的生成器部分設計成基于殘差網絡的神經網絡結構。
2 基于DR-GAN的醫學影像超分辨率算法
2.1 改進思想
神經網絡的結構、寬度和深度等是影響網絡性能的重要因素。在網絡結構方面,本文借鑒文獻[24]提出的縮放卷積思想采用縮放圖片再卷積的上采樣層來盡量削弱棋盤效應的出現,借鑒文獻[25-26]作超分辨率對原始的ResNet去掉BN層節約顯存獲得性能提升的做法,本文將SRGAN的標準殘差塊去掉BN層,來建立一種新的殘差塊結構,以此簡化殘差塊結構達到優化網絡的目的。在網絡寬度方面,本文借鑒文獻[25]在有限內存時增加特征圖通道數比加深網絡更有效的做法,將原始SRGAN的判別器進一步增加特征圖數量,由于過多的特征圖數量易使網絡不穩定,所以本文算法通過增加快捷連接使網絡更穩定、更易訓練來提升網絡性能。在網絡深度方面,受到文獻[27-29]顯示更深網絡能夠建立高復雜度映射,極大提高網絡精確性的啟發,本文算法通過增加網絡的深度來提高網絡的性能。由于過深的網絡難以訓練,所以改進方法將生成器部分的殘差塊數量由原有的16個增加到32個,網絡深度增加了16層。
綜上所述,本文提出的DR-GAN改進原有SRGAN主要是通過用縮放卷積的上采樣層(ResizeLayer)替換原始SRGAN的亞像素層,將SRGAN的標準殘差塊去掉BN層,增加原始SRGAN判別器的特征通道數并添加快捷連接改進原始判別器參數,增加生成器部分的殘差塊數量來加深網絡層次。
2.2 DR-GAN算法的網絡結構
由2.1節所述的改進思想,將改進的措施應用到本文的研究,設計的整個網絡結構如圖3所示,其中生成器網絡結構如圖3(a)所示,判別器網絡結構如圖3(b)所示。

圖3 DR-GAN網絡結構
2.2.1 生成器
如圖3(a)所示的生成器網絡參數,改進生成器網絡的參數設置與原始SRGAN略有不同。具體來說,輸入的低分辨率圖片,先進入卷積層進行卷積操作,卷積層參數設置為3×3×3×64,即64個3×3 過濾器,3個通道,步長為1,再填補適宜的0用以保持圖片尺寸;借鑒文獻[25]使用整流線性單元(Rectified Linear Unit, ReLU)提升性能的思想,本文使用ReLU替換原始SRGAN的參數化整流線性單元激活,達到評價指標的提升,然后依次進入到32個相同殘差塊網絡中訓練學習;特別地改進的每個殘差塊都去掉了BN層并使用Skip Connection的方式易于網絡的訓練,從32個殘差塊輸出后接著進入卷積層然后使用Skip Connection,接著上采樣將圖片放大2倍,上采樣操作采用縮放卷積的做法,先用最近鄰插值將圖片放大2倍后再進入卷積層,最后通過卷積操作后輸出高分辨率圖片。
2.2.2 判別器
如圖3(b)所示,改進的判別器的網絡結構和參數設置與原始SRGAN的不同。具體來說,輸入待判別的高分辨率圖片,先經過5層的卷積層抽取圖片特征,不同于原始的SRGAN,為了增大局部感受野,采用4×4尺寸的卷積核,并進一步增加特征圖數量,即像VGGNet[27]那樣,卷積層通道的數量從第一層的64個開始,每層的通道數以2倍遞增,直到第5層的1 024個;接著經1×1卷積核的卷積層進行降維,然后經層層的卷積操作并使用Skip Connection使網絡順暢訓練,再將圖片數據的維度壓平(Flatten)再經全連接層(Fully Connected layer, FC)后經Sigmoid輸出判別的結果。
2.3 代價函數
代價函數的選擇是深度學習算法設計中的一個重要部分,由于交叉熵[30]可以用來衡量兩個分布之間的相似程度,均方差的高效性,交叉熵和均方差損失函數在深度學習代價函數設計中的廣泛應用,所以本文算法選取均方差以及訓練數據和模型預測間的交叉熵作為代價函數。如式(1)~(8):
LDR-GAN={min(LD),min(LG)}
(1)
其中,LDR-GAN表示DR-GAN算法的損失函數,LD為判別損失函數,LG為生成損失函數,網絡訓練的目的為最小化LD和LG。
LD=Ld1+Ld2
(2)
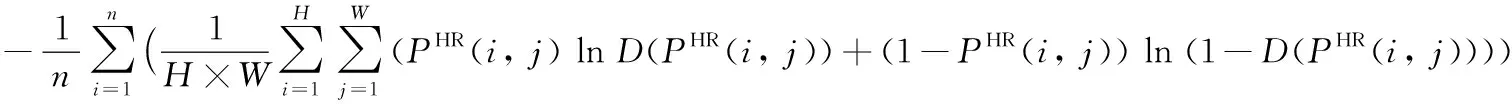
(3)

(4)
其中:PLR為網絡輸入的圖片,PHR為供參照的原始高清圖片,n為小批量樣本(mini-batch)大小,本文n=16。H、W分別為圖片的高度和寬度,D(PHR(i,j))表示真實高分辨率圖片訓練數據輸入判別器的結果,G(PLR(i,j))為圖片經生成器后的生成結果,Ld1表示真實高分辨率圖片訓練數據輸入判別器判斷后的輸出結果與其真實值(為1)的交叉熵。Ld2表示低分辨率圖片輸入生成器生成的高分辨率圖片再輸入到判別器的判別結果與其真實值(為0)的交叉熵。
LG=LMSE+10-3Lg+2×10-6LVGG
(5)
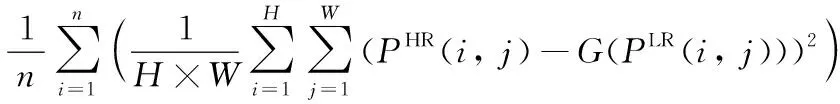
(6)
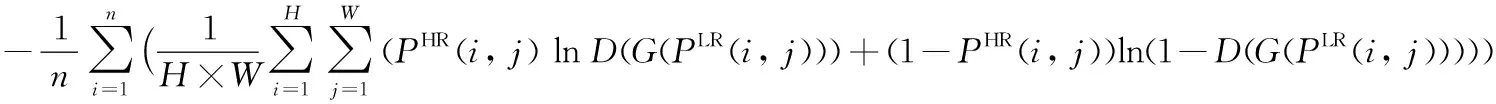
(7)
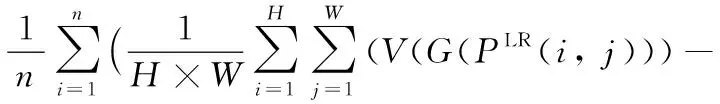
V(PHR(i,j)))2)
(8)
其中:V(PHR(i,j))為真實高分辨率圖片輸入到預先訓練好的VGG19[27]網絡模型的輸出結果,V(G(PLR(i,j)))為低分辨率圖片用生成器生成的結果輸入到預先訓練好的VGG19網絡模型的輸出結果,LMSE表示PHR與G(PLR(i,j))像素之間的損失,Lg表示低分辨率圖片輸入生成器后的生成結果再輸入到判別器的判別結果與真實值(為1)的交叉熵。LVGG表示V(G(PLR(i,j)))與V(PHR(i,j))像素之間的損失。
2.4 訓練過程:
采用mini-batch的訓練方式,因為實驗硬件GPU顯存的限制,mini-batch設置為16張圖片。訓練時,對每個mini-batch的每個真實高分辨率圖片隨機裁剪96×96的子圖片,接著對此高分辨率96×96的子圖片用目前主流做法使用Bicubic下采樣2倍得到降質的低分辨率48×48圖像,然后把這個mini-batch的真實高分辨率子圖和對應的低分辨率降質圖片輸入到判別器和生成器網絡中進行訓練,同時使用Adam優化算法在訓練過程中促使判別損失和生成損失函數達到最小來不斷更新網絡的參數。初始學習率設置為1×10-4,實驗迭代12 000次,每隔6 000次將學習率減小,變為原來的0.1倍,以達到訓練最優的目的。
算法偽碼實現如下:
for number of training iterations do
Sample minibatch of HR train set to randomly cropPHR:512×512 toPHR_sub:96×96
use Bicubic downsamplePHR_subtoPLR_sub:48×48
PLR_subinput the Generative Model to generatePfake
PHR_sub,Pfakeinput the Discriminative Model to discriminate thePfake,Adam Optimizer minimize theLDto update the Discriminative network
Adam Optimizer minimize theLMSE,Lg,LVGGto update the Generative network
end for
3 實驗仿真與結果分析
本文實驗使用的是美國國家肺癌中心的數據集[31],并從中挑選了清晰度高、紋理豐富、細節復雜的304張512×512高質量的圖片來訓練。
本實驗環境包括硬件環境和軟件環境。實驗測試所用的硬件設備是一臺Intel Xeon服務器,搭載2塊NVIDIA Tesla M40的GPU,每塊顯存12 GB,共24 GB。實驗軟件,平臺是64位Ubuntu 14.04.5 LTS操作系統,Tensorflow V1.2,CUDA Toolkit 8.0,Python3.5。
3.1 實驗與結果
為了驗證說明本文算法超分辨率重建圖片的效果,特別選取了常見的具有典型性的3種傳統超分辨率方法和2種具有代表性效果較好的基于深度學習的超分辨率方法。3種傳統超分辨率方法是Bilinear、NN和Bicubic,2種基于深度學習的超分辨率方法是DRCN和SRGAN。為了公正地對比各算法,各個算法均統一在搭載GPU 為NVIDIA Tesla M40,Tensorflow V1.2的Intel Xeon服務器實驗環境下使用Python3.5實現仿真。Bilinear、NN和Bicubic的結果與迭代的次數無關,DRCN、SRGAN和DR-GAN均迭代12 000次,初始學習率設置為1×10-4,每隔6 000次將學習率減小,變為原來的0.1倍。
為了驗證各超分辨率算法的處理效果,顯示實驗結果的客觀合理,選取4幅有代表性,肺部氣管、肺泡、胸廓等細節復雜,紋理豐富的肺部影像進行對比測試。實驗結果如圖4所示。
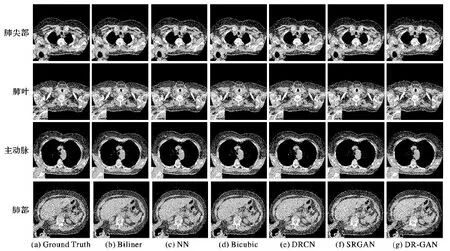
圖4 各方法超分辨率效果對比
3.2 評價指標
由于峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)[32]和結構相似性(Structural SIMilarity, SSIM)[33]被廣泛地作為圖像壓縮、修復后評價圖像質量優劣的檢測手段,本文也選用PSNR和SSIM作為超分辨率重建算法重建圖像質量的參考評價指標,并將整個數據集的PSNR和SSIM數據平均化,將整個數據集上的平均峰值信噪比(Mean Peak Signal-to-Noise Ratio, MPSNR)和平均結構相似性(Mean Structural Similarity, MSSIM)也納入重建圖像質量的參考評價指標。
同時,算法超分辨率重建出高分辨率圖片所耗費的時間也是衡量算法優劣的重要因素。為了評價本文算法與其他算法的優劣,本文將算法的耗時也作為評價算法的參考指標。
3.2.1 客觀效果
為了客觀顯示本文算法與其對比的各個算法的效果,對圖4各算法超分辨率重建后的圖片分別與最左側的原始高清標準圖像(Ground Truth)計算PSNR、SSIM,用同樣的方法計算得到整個數據集上的PSNR、SSIM數據,然后得出整個數據集的MPSNR、MSSIM數據,并記錄各算法的耗時,以實際數據值作為評價各算法優劣的參考。圖4的PSNR、SSIM和各算法的耗時如表1所示。
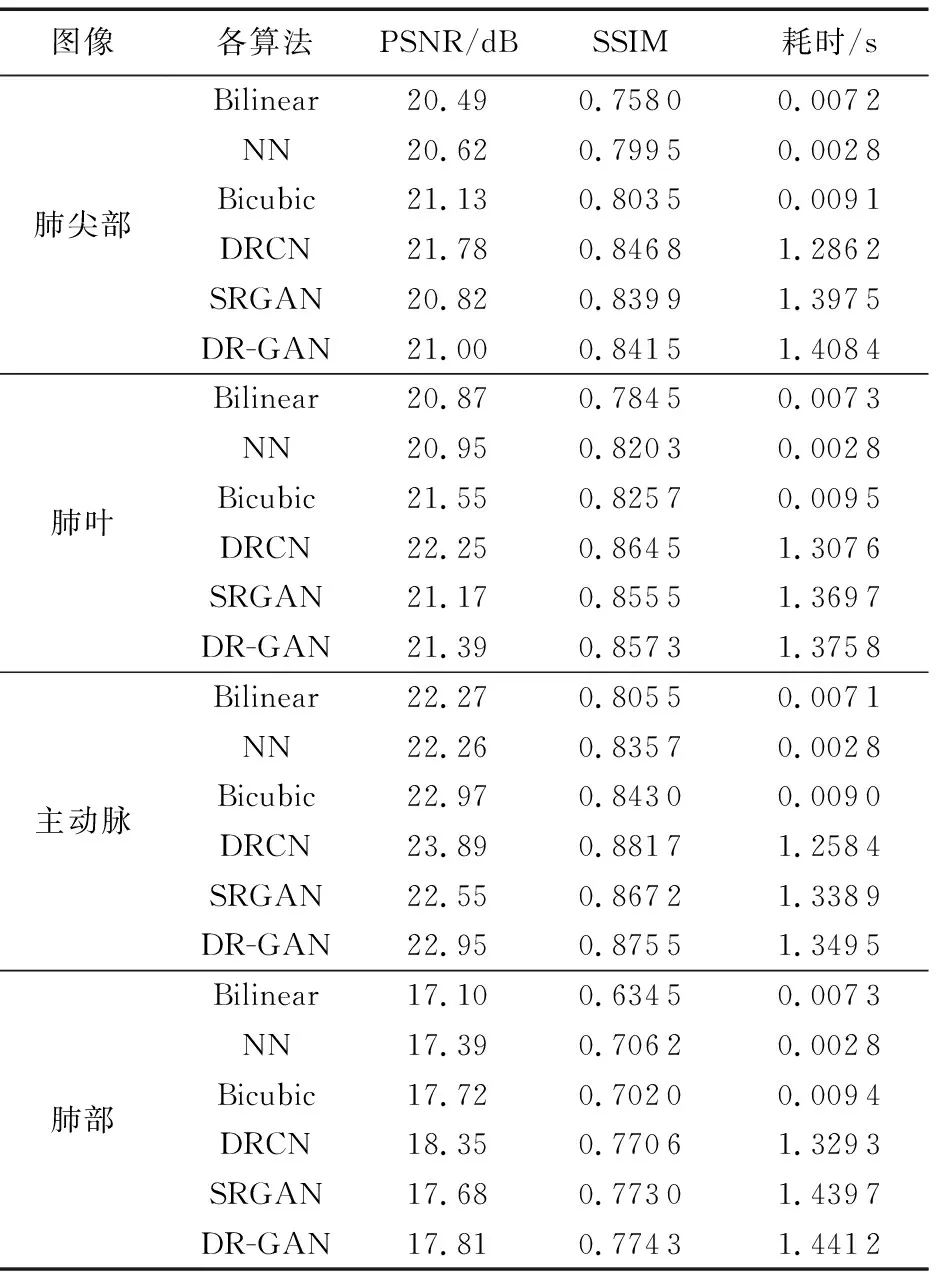
表1 各超分辨率算法評價指標值對比
同時,將整個數據集上計算的PSNR、SSIM數據平均化,得到各算法在整個數據集上的MPSNR、MSSIM和平均耗時如表2所示。
由表1中圖4第1行的各超分辨率算法實驗數據可以看出,Bilinear、NN、Bicubic、DRCN算法重建出圖片的PSNR、SSIM分數越來越高,DR-GAN和SRGAN的PSNR、SSIM分數低于DRCN, 但DR-GAN的PSNR、SSIM均略高于原始SRGAN算法。
同樣,從表1中圖4第2行~第4行的各超分辨率算法實驗數據可以看到,Bilinear、DRCN重建出圖片的PSNR、SSIM分數分別為最低和最高,Bilinear、NN、Bicubic、DRCN的PSNR、SSIM分數也越來越高,同時DR-GAN的PSNR、SSIM均高于SRGAN。
從表2中可以看到,Bilinear、NN、Bicubic、DRCN的MPSNR、MSSIM分數同樣是越來越高的,DR-GAN的MPSNR、MSSIM均高于SRGAN。

表2 各超分辨率算法MPSNR,MSSIM,耗時結果對比
各算法的耗時方面,從表1可看出,基于深度學習的DRCN、SRGAN,DR-GAN的耗時高于傳統的Bilinear、NN、Bicubic算法,但是DRCN、SRGAN、DR-GAN的耗時都在1.5 s以內。
同時,由DR-GAN算法訓練過程中的生成損失和判別損失的實驗數據繪制圖表如圖5所示。

圖5 DR-GAN算法的損失
從圖5可以看到,隨著迭代次數的增加,生成損失整體呈現下降趨勢,曲線后段趨于平緩,另一方面,隨著迭代次數的增加,判別損失整體呈現緩慢上升趨勢,因此,綜合權衡生成損失和判別損失,確定本文算法最終迭代次數為12 000次。
3.2.2 主觀效果
從圖4顯示的結果可以看出,在處理醫學影像的超分辨率任務時,整體來看,基于深度學習的DRCN算法、SRGAN算法和DR-GAN算法處理的效果都明顯優于傳統的Bilinear、NN、Bicubic算法。主觀來看,DRCN算法、SRGAN算法和DR-GAN算法都得到了較好的超分辨率圖像,但對于上面的某些圖片和某些部位,DR-GAN算法顯示出了更逼真的細節紋理和圖像銳度。
具體來說,圖4第1行(肺尖部)中:Bilinear算法得到的圖片整體看起來很模糊;NN算法得到的圖片出現了比較明顯的方塊狀;Bicubic得到的圖片也比較模糊,且在視覺上顯得過于平滑;DRCN在圖像銳度方面有了很大的提升,但相比SRGAN和DR-GAN在復雜細節方面的處理仍顯不足;SRGAN在圖像銳度和視覺效果方面都較好,但圖中方框區域的下半部分出現了棋盤狀效應;而DR-GAN算法沒有顯現棋盤狀效應,DR-GAN算法的效果最接近于標準圖像。
同樣,在圖4第2行~第4行中,也可以看到:Bilinear很模糊,NN有明顯的方塊狀,Bicubic也比較模糊且視覺過于平滑,DRCN提升了圖像銳度但復雜細節處理不足,SRGAN相比DR-GAN算法對豐富紋理處理仍顯不夠細膩,DR-GAN算法在視覺上顯示出了更逼真的紋理細節。
3.2.3 綜合評價
雖然PSNR是廣泛使用的評價圖像質量的客觀檢測手段,尤其在超分辨率領域,眾多的算法和大型挑戰賽[34]往往以PSNR數值的高低來評判算法的優劣,但PSNR本身有很大的局限性,最近幾年很多的實驗結果[18,35]和研究[36]都顯示了,PSNR數據無法和人類視覺感官看到的完全符合,有些情況,PSNR較低的反而比PSNR較高的視覺上更逼真[18]。
所以本文采用客觀PSNR,SSIM等評價指標和主觀視覺效果的綜合評價方式。
從表1和表2的實驗數據結果可以看出,DR-GAN算法的PSNR、SSIM、MPSNR、MSSIM均高于原始SRGAN算法。
雖然DR-GAN算法超分辨率重建圖像的PSNR、SSIM等客觀指標低于DRCN,但是從主觀視覺效果上來看,DR-GAN算法重建的圖像紋理要更細膩、更逼真,視覺體驗更好,更接近真實標準圖像。
在耗時方面,因為傳統插值等方法計算簡單,復雜度低,耗時短,DR-GAN算法在提高精度的同時犧牲了時間,時間上雖然缺乏明顯優勢,但也在可接受的范圍內。
因此,綜合評價來說,本文提出的DR-GAN算法要優于SRGAN、DRCN、Bilinear、NN、Bicubic算法。
4 結語
針對2倍醫學影像超分辨率,本文提出了基于深度殘差的生成對抗網絡的醫學影像超分辨率算法。該算法由生成器網絡和判別器網絡構成,其中生成器網絡由基于改進的32層殘差網絡和快捷連接組成,判別器由層層卷積層和快捷連接組成。對于肺部醫學影像的2倍超分辨率圖像,提出的算法綜合PSNR等客觀指標和主觀視覺效果因素要優于SRGAN、DRCN、Bilinear、NN、Bicubic算法,充分說明了本文算法的適用性。下一步的研究工作將探尋高效的算法,以便重建出高質量的更大放大倍數的高分辨率圖像。
