
基于遺傳算法的聚類分析及其應用
2018-10-17 08:58:02
福建質量管理 2018年18期
(成都理工大學 四川 成都 610059)
一、前言
(一)研究目的和意義。數據挖掘技術的目的就是為了從錯綜復雜的大數據中挖掘出有用的知識和數據,進而應用到科學決策中(趙艷麗,2009)。聚類分析(Clustering Method)是一類無監督分類方法,是數據挖掘中極其關鍵的一個數據處理方式,使同一類內里對象之間的相似程度最小,不同類內對象之間的相似程度最大的目標(李薈嬈,2014)。在地球化學數據的分析研究中,首要的是要研究地球化學元素的分布特征,再依據數據分類的方法找尋元素空間分布規律。
(二)國內外研究現狀。k-means算法最早是由J.B.MacQueen于1967年提出來的,由于該算法不僅聚類時間快,而且聚類過程簡單,效率高,隨后該算法廣泛的開始傳播。但k-means算法也存在以下缺點:(1)聚類數據的要求很高;(2)初始聚類中心的選取不合適會導致聚類結果的不穩定;(3)需要人為的去確定分類數k;許多專家對上述問題進行了深入研究,已找出一些新的方法可以彌補k-means算法的缺陷。重點是通過以下兩個方面來改進k-means算法。(1)傳統k-means算法的k值被替換為人為確定的k值;(2)初始聚類中心選擇的優化排除了聚類初始點對聚類結果的影響。
遺傳算法最早由美國J.Holland教授在1975年提出的(劉建莊,1995)。其最顯著的特點是能夠直接對結構對象進行操作,并且沒有函數連續性的定義,它具有隱式并行性和全局尋優能力。它應用在許多問題上表現出簡單,通用,強大,適合并行處理等優點,是當前智能計算的核心技術之一。
近年來,k-means聚類分析和遺傳算法的發展十分迅猛,并且基于k-means聚類算法和遺傳算法已經擴展成一系列不同的算法,已被廣泛的應用于生活。
(三)本文的主要研究內容。k-means算法的最主要的兩個缺點是需要我們自己來確定分類數k以及初始聚類中心,因此在隨機選取聚類中心點上會很大程度上讓聚類結果接近于局部最優值。遺傳算法最主要的特點是隱式并行性和有效利用全局信息,因此基于遺傳算法的聚類分析具有很強的魯棒性,很大程度上不會陷入局部最優,進而顯著的提升算法的聚類效果。本文實驗使用標準數據集來驗證算法的有限性,通過與傳統算法的結果進行比較分析,證實算法是可行的。我們從發現問題,提出問題,分析問題和解決問題四個角度出發,通過對其自身改進算法的研究,深入研究了該算法的優劣性,提出了一種基于遺傳算法的k-means聚類算法。
二、實驗結果與分析
(一)數據分析。地球化學數據處理指的是通過某些方法或軟件對地球化學中的部分元素數據進行分析研究,繪制成圖,得出結論的過程(管世明,2012)。本文就以地球化學元素作為聚類分析的數據對象,對地球化學采樣數據進行了分析,這里選擇了一組銅的數據,首先先對這組數據進行分析,如表1所示,發現個體差異值很大,最大值和最小值差異明顯,如圖1所示,最大值跟均值差異也很明顯,所以很有可能對聚類產生影響,有可能產生異常值點。將數據代入遺傳k-means聚類算法程序中進行分析,發現k值為4的時候聚類效果最好。

表1 元素特征
(二)結果分析。
利用surfer專業成圖軟件對聚類結果進行分析產生聚類圖。把數據聚類結果做成分類圖,不同的類別點用不同的顏色表示,從聚類結果圖上可以明顯的看出存在分布特征特別明顯的幾個區域,特征表現在:(1)圖中區域內同一顏色的點屬于同一個類;(2)圖中種群擁有相當大的規模,有很大一部分的采樣點,而其他位置上也有其他類的分布。利用聚類分析的優勢,依據地球化學元素作為聚類分析問題的研究對象,能夠直觀的展示元素的空間分布規律,指示找礦有利地段。
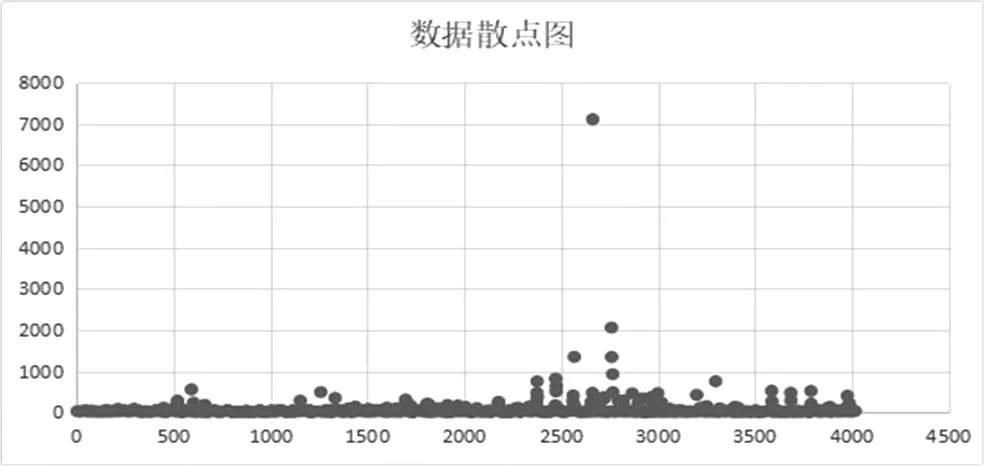
圖1 原始數據散點圖

圖2 聚類分析圖
結論
k-means聚類算法簡單易行,聚類速度快,但是隨機的初始化容易陷入局部最優解。遺傳算法簡單通用,魯棒性高,適合并行處理,但是計算效率過低,同時對局部尋優的過程不佳。本文結合兩種算法的優缺點,改進了遺傳k-means算法。通過仿真實驗和實際數據的處理驗證了算法的有效性。
聚類分析的研究由來已久,本文只是截取龐大體系中的很小一部分開展研究,雖有成果,但仍有需要改進之處,如算法的效率方面仍可提高,結合神經網絡或模糊聚類可能取得更好的效果,這些都是值得進一步研究的方向。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:24
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
