新浪微博數(shù)據(jù)分析及社區(qū)發(fā)現(xiàn)方法研究
2018-10-18 10:33:44茍良
現(xiàn)代計(jì)算機(jī) 2018年26期
關(guān)鍵詞:用戶
茍良
(新疆大學(xué)信息科學(xué)與工程學(xué)院,烏魯木齊 830046)
新浪微博;社區(qū)發(fā)現(xiàn);TF-IDF;K-means
0 引言
目前隨著社交媒體的普及以及移動(dòng)設(shè)備的飛速發(fā)展,新浪微博成了人們生活中必備的社交工具。在每天都產(chǎn)生億級別的數(shù)據(jù)量中,蘊(yùn)含著巨大的價(jià)值。新浪微博是一款為大眾提供娛樂休閑生活服務(wù)的信息分享和交流平臺(tái),是一種開放的,可以快速發(fā)布信息的社交平臺(tái)。每一條信息(稱為微博)被限制在140個(gè)字符之內(nèi),用戶與用戶之間存在關(guān)注與被關(guān)注的關(guān)系,用戶之間可以評論、點(diǎn)贊、轉(zhuǎn)發(fā)別人的微博,稱之為互動(dòng)。
目前對新浪微博中整體用戶的數(shù)據(jù)研究[1-3]有很多。在社交網(wǎng)絡(luò)發(fā)現(xiàn)算法[4]中,值得一提的一類算法是凝聚類算法(Agglomeration Algorithms),這類算法是通過構(gòu)建一個(gè)將小的類簇合并為大的類簇的層次樹得到的多層聚類算法。其中比較著名的是Clauset A[5]等人提出的CNM[6]算法。隨后,Yi Fan Hu[7]等人提出的Yi Fan Hu算法在用戶關(guān)系上將點(diǎn)與線引入力學(xué)公式,進(jìn)行了社交網(wǎng)絡(luò)構(gòu)圖的完善。
本文從新浪微博中選擇了若干用戶作為種子用戶,從這些種子的粉絲開始,繼續(xù)爬取數(shù)據(jù)集中用戶的粉絲的數(shù)據(jù),通過此方法不斷的遍歷用戶的粉絲,抓取了7萬多用戶,收集了200多萬條微博。然后使用熵力模型確定節(jié)點(diǎn)關(guān)系,借助Gephi[8]工具進(jìn)行繪圖操作,繪制出了社交網(wǎng)絡(luò)圖,分析了數(shù)據(jù)集的特點(diǎn),發(fā)現(xiàn)了用戶在信息傳遞中的位置與作用。最后對數(shù)據(jù)集用戶進(jìn)行了群體劃分,找出了每個(gè)群體的關(guān)鍵詞。
1 數(shù)據(jù)收集與篩選
本文使用Python語言編寫微博爬蟲的程序,使用模擬登錄的方法進(jìn)行數(shù)據(jù)爬取,具體思路如下:
首先在新浪微博的高級搜索中找出了若干用戶作為種子用戶,從這些種子用戶的粉絲開始,每位用戶爬取前200名粉絲的數(shù)據(jù),繼續(xù)爬取數(shù)據(jù)集中用戶的粉絲的數(shù)據(jù),重復(fù)此方法,如圖1所示。
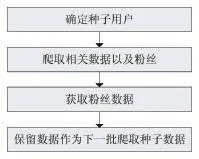
圖1 獲取數(shù)據(jù)流程圖
通過此方法不斷地遍歷用戶的粉絲,抓取了7萬多用戶,收集了200多萬條微博。
2 數(shù)據(jù)集特征分析
本文分析用戶之間的關(guān)系并沒有從關(guān)注與被關(guān)注的用戶關(guān)系中尋找答案,因?yàn)樾吕宋⒉┲写嬖诓簧佟敖┦邸保盃I銷號”等“spam user”存在,若只從單純的關(guān)注關(guān)系來分析,這類“spam user”會(huì)很大程度上干擾真實(shí)的互動(dòng)結(jié)果,所以本文主要從互動(dòng)的用戶(在微博下有點(diǎn)贊、評論、轉(zhuǎn)發(fā)行為)入手,收集每個(gè)用戶與其互動(dòng)的用戶,稱這類用戶為該用戶的互動(dòng)圈。在數(shù)據(jù)集中,若用戶i對用戶j的微博進(jìn)行了評論(轉(zhuǎn)發(fā),點(diǎn)贊)行為,標(biāo)記為 i→j。
2.1 熵力模型
本文使用熵力模型[9]確定節(jié)點(diǎn)之間的位置,該模型將節(jié)點(diǎn)位置問題(用戶分布問題)轉(zhuǎn)換為節(jié)點(diǎn)間連線長度問題,引入熵H(x)模型的目的是尋找兩節(jié)點(diǎn)之間的距離關(guān)系,如公式(1)所示:

其中,E代表節(jié)點(diǎn)間連線,xi,xj代表節(jié)點(diǎn)i,j的度。在式(1)中,兩節(jié)點(diǎn)之間的距離由兩節(jié)點(diǎn)的度的差值決定,度反映節(jié)點(diǎn)上連線的數(shù)值,所以該公式的思想是確定互連的兩節(jié)點(diǎn)之間的熵值,通過次公式遍歷所有互連節(jié)點(diǎn),如公式(2):公式(2)代表節(jié)點(diǎn)間的熵值由該節(jié)點(diǎn)與所有與其互連的節(jié)點(diǎn)共同決定。由此確定出所有節(jié)點(diǎn)的距離(熵值)。

2.2 社交網(wǎng)絡(luò)圖
通過該模型借助Gephi繪圖工具繪制社交網(wǎng)絡(luò)圖,以用戶ID為節(jié)點(diǎn),互動(dòng)關(guān)系用有向線表示,繪制出社交網(wǎng)絡(luò)圖,如圖2所示:

圖2 社交網(wǎng)絡(luò)圖
節(jié)點(diǎn)大小反映節(jié)點(diǎn)的度,即用戶的互動(dòng)圈大小,通常情況下節(jié)點(diǎn)大的用戶群體互動(dòng)程度較高、粉絲數(shù)量較多、發(fā)布的微博數(shù)量較多。
3 用戶社區(qū)發(fā)現(xiàn)研究方法
3.1 方法概述
傳統(tǒng)的社群發(fā)現(xiàn)算法都是從社交媒體上用戶間的社交網(wǎng)絡(luò)中延伸而來,從個(gè)人節(jié)點(diǎn)出發(fā),計(jì)算與其有關(guān)聯(lián)的節(jié)點(diǎn),從而確定一個(gè)群體,這樣做的好處是能較快地將互相關(guān)注的人聚成一個(gè)群體。但是卻忽略了一些較為重要的問題,一個(gè)群體的人發(fā)布微博內(nèi)容是否相似,興趣是否一致,對事件的態(tài)度是否有差異。
針對這類問題,本文從用戶的微博內(nèi)容出發(fā),以關(guān)鍵詞為單位,對用戶進(jìn)行聚類計(jì)算。通過聚類算法,找到包含關(guān)鍵詞相似的用戶并歸為一類。這樣做的目的是,可以針對不同的關(guān)鍵詞,定位到不同群體,了解不同群體所表述的內(nèi)容,區(qū)分興趣點(diǎn),縮小檢索范圍。
之所以從關(guān)鍵詞的角度出發(fā),是因?yàn)槲谋镜幕締挝皇窃~,文本的中心思想由詞來表示,對關(guān)鍵詞的提取能很大程度地反映文本內(nèi)容的表達(dá)。所以定位到詞,找到使用相同詞的不同用戶,將這類用戶聚為一個(gè)群體。
用戶社群發(fā)現(xiàn)具有很大的利用價(jià)值,目前較頻繁使用的好友推薦系統(tǒng),廣告定位系統(tǒng),產(chǎn)品推薦系統(tǒng)都可以在此基礎(chǔ)上繼續(xù)延伸。
我們所采用的數(shù)據(jù)集包括兩部分,一是從抓取的7萬多用戶中隨機(jī)選擇了5萬多用戶及其相關(guān)微博,二是為增加群體多樣性,又從其他微博數(shù)據(jù)集中加入了3萬多用戶及其相關(guān)微博。然后對每條微博進(jìn)行歸屬分類,單獨(dú)統(tǒng)計(jì)出每位用戶發(fā)布的微博,使用Jieba分詞對中文部分進(jìn)行分詞,Jieba是包裝于Python中的第三方類庫,其中主要使用到的原理有:
(1)為了達(dá)到高效的目的,底層使用Trie樹結(jié)構(gòu)進(jìn)行詞圖掃描,在一句話中,對于所有可能構(gòu)成詞的情況,全部建立有向無環(huán)圖(DAG)。
(2)為了查找最大概率路徑,采用了動(dòng)態(tài)規(guī)劃的方法。根據(jù)詞頻,找到最大概率切分組合。
(3)當(dāng)出現(xiàn)未記錄詞時(shí),使用了基于HMM模型進(jìn)行新詞訓(xùn)練,使用了其中的Viterbi算法。
之后是用TF-IDF算法計(jì)算所有詞的詞權(quán)值,將所得結(jié)果進(jìn)行歸一化處理后使用K-means算法進(jìn)行聚類統(tǒng)計(jì),選取質(zhì)心找出群體關(guān)鍵詞,根據(jù)關(guān)鍵詞進(jìn)行集中分析。
3.2 TFF--IIDDFF算法
將微博文本使用分詞算法進(jìn)行詞切割之后,最小單位從文本轉(zhuǎn)變?yōu)樵~,并統(tǒng)計(jì)出每位用戶所使用的詞,使用TF-IDF算法計(jì)算每個(gè)詞的詞權(quán)值。
TF-IDF算法是一種用來評估一個(gè)詞對于一個(gè)文件的重要程度的算法。一個(gè)詞的重要程度分別由兩部分決定。
(1)TF(Term Frequency):
一個(gè)詞在一個(gè)用戶的微博中出現(xiàn)的次數(shù)與其對該用戶的價(jià)值的大小成正比,如公式(3):

其中,tfi,j代表詞i在微博j中的權(quán)值,ni,j是詞i在文件dj中出現(xiàn)的次數(shù),而分母則是文件中所有詞匯出現(xiàn)的次數(shù)總和。
(2)IDF(Inverse Document Frequency):
逆文檔頻率,反映一個(gè)詞的常見程度,若一個(gè)詞很常見,說明該詞并沒有很好的分類效果,從而權(quán)值較小。換句話說,一個(gè)詞的權(quán)值與該詞的常見程度成分反比,如公式(4):

其中,|D|是個(gè)人微博總數(shù),分母表示包含詞語ti的微博總數(shù)。
最后,可以計(jì)算出每個(gè)詞(t)的 TF-IDF(t)=TF(t)*IDF(t)。
觀察計(jì)算出的每個(gè)詞的詞頻,由于文本數(shù)量龐大,而詞數(shù)遠(yuǎn)小于文本數(shù)量,導(dǎo)致計(jì)算出來的詞權(quán)值趨近于零。為了解決數(shù)值較小影響計(jì)算的問題,本文選取[0-20]之間的區(qū)間隨機(jī)數(shù)代替詞權(quán),這里詞權(quán)的大小與隨機(jī)數(shù)的大小一一對應(yīng),以便接下來的聚類計(jì)算。
3.3 K-mmeeaannss算法
通過TF-IDF算法計(jì)算出了每個(gè)用戶使用詞的權(quán)值之后,本文針對每個(gè)用戶,選取權(quán)值最大的10個(gè)詞作為該用戶的關(guān)鍵詞,若有用戶關(guān)鍵詞數(shù)量不夠10個(gè),則補(bǔ)零至10位,這樣處理后,數(shù)據(jù)集轉(zhuǎn)換為向量集,每位用戶轉(zhuǎn)為十維的向量,如下:
useri=[w ordi1,wordi2,wordi3,…,wordi10]
其中,useri代表用戶i,wordij代表用戶i的第j個(gè)關(guān)鍵詞權(quán)值,使用K-means算法進(jìn)行聚類計(jì)算。
K-means算法是一種基于距離的無監(jiān)督聚類算法,相似性以距離為指標(biāo)進(jìn)行聚類,若兩個(gè)對象的歐氏距離越近,則兩個(gè)對象為一類的可能性就越大。K-means算法的關(guān)鍵之處在于K值的選取,K代表初始質(zhì)心的數(shù)量,也就是最終分類的數(shù)量。
K-means算法說明如下:
選定K個(gè)簇中心Uk的初值。由于K-means算法不能保證全局最優(yōu),而結(jié)果最優(yōu)通常與初始K值有較大關(guān)系,所以多次選取初值進(jìn)行結(jié)果比較是較常用的方法;
遍歷所有點(diǎn),將每個(gè)點(diǎn)歸類到與其最近的中心點(diǎn)簇中;
計(jì)算新的中心點(diǎn),如公式(5):

重復(fù)第二步,直到最大的步數(shù)。

圖3 用戶聚類圖
針對本文數(shù)據(jù)集,聚類結(jié)果如圖3所示:可以看到,圖3中有較明顯的聚類現(xiàn)象,本文聚類結(jié)果分析如下節(jié)。
3.4 聚類結(jié)果統(tǒng)計(jì)
選取各類群體的質(zhì)心,共找出七類群體,如表1所示:

表1 七類群體
不同類的用戶所使用的關(guān)鍵詞具有一定的差異性,說明不同群體內(nèi)發(fā)布的微博內(nèi)容有一定的區(qū)別。
1.第一類群體,“方便”、“別致”、“人氣”、“補(bǔ)水”、“在家”、“拼命”、“攀比”、“趕快”、“團(tuán)隊(duì)”等詞突出微博內(nèi)容的日常生活及工作性。
2.第二類群體,該類群體的關(guān)鍵詞中評論性的副詞較多,如“實(shí)在”、“由”、“即”、“曾經(jīng)”、“信任”、“精彩”也體現(xiàn)出微博內(nèi)容具有一定的評論性質(zhì)。
3.第三類群體,“想念”、“互粉”、“身體”、“多么”、“操心”、“可怕”、“悲傷”、“精神”、“無論”、“追求”等關(guān)鍵詞表示微博內(nèi)容多在表達(dá)心理狀態(tài)。
4.第四類群體,“多云”、“春暖花開”、“陽光”、“整齊”等關(guān)鍵詞說明該類群體關(guān)注天氣環(huán)境。
5.第五類群體,微博內(nèi)容里多出現(xiàn)“攝影”、“畫”、“天籟”、“閱讀”等詞,突出該類群體對藝術(shù)類的側(cè)重。
6.第六類群體,這類群體微博內(nèi)容中的“人氣”、“套裝”、“這款”、“炒股”、“新人”等詞說明該類用戶在微博內(nèi)容上以商業(yè)為主,通過社交媒體進(jìn)行產(chǎn)品銷售也是目前很常見的一種現(xiàn)象。
7.第七類群體,“城市”、“鄉(xiāng)村”、“旅游”、“道路”、“我家”等展現(xiàn)出該類群體傾向于旅游。
如上結(jié)果表明,本文所提出的方法能夠挖掘出數(shù)據(jù)集中的不同群體,并找出該類群體的特點(diǎn)。
4 結(jié)語
本文主要提出了一種新的數(shù)據(jù)爬取策略,引入熵力模型繪制社交網(wǎng)絡(luò)圖,發(fā)現(xiàn)了互動(dòng)人群的特點(diǎn)。在社群發(fā)現(xiàn)方面,從關(guān)鍵詞的角度出發(fā),找出每位用戶發(fā)布微博時(shí)使用的代表詞,并通過聚類算法對用戶進(jìn)行了群體聚類,找出每個(gè)群體最具代表性的關(guān)鍵詞,分析群體特點(diǎn)。
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業(yè)黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛(wèi)星與網(wǎng)絡(luò)(2016年12期)2016-02-05 09:23:23
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:55:08
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:54:39
