基于GRU網絡和矩陣分解的混合推薦算法
2018-10-18 10:33:46徐彬源高茂庭
現代計算機 2018年26期
徐彬源,高茂庭
(上海海事大學信息工程學院,上海 201306)
推薦算法;門控循環單元;數據降維;長期狀態;短期狀態
0 引言
隨著互聯網技術的快速發展以及智能移動終端產品的普及,人人皆是網民的時代即將來臨,手機網民指數不斷攀升,互聯網中的數據爆發式增長,而信息處理能力遠遠跟不上信息增長的速度,導致出現了信息過載問題。為有效解決該問題,推薦系統[1]誕生了,而推薦系統中最關鍵的部分是推薦算法,推薦算法的好壞直接決定了推薦系統的優劣。目前主流的推薦算法[2]包括基于內容的推薦、基于協同過濾的推薦以及混合推薦。
其中,最成功的算法是協同過濾推薦算法[3],被廣泛應用在各大推薦系統中。其基本原理非常簡單,就是根據用戶的行為歷史數據分析用戶對項目的興趣偏好,發現用戶或項目之間的相似度,然后基于這些相似度對用戶進行推薦。協同過濾推薦又分為基于用戶的推薦、基于項目的推薦以及基于模型的推薦[4]。但隨著用戶數和項目數的劇增,前兩個算法的計算復雜度太大,并且受到數據稀疏性的影響較大。基于模型的推薦能有效緩解上述問題,并做出更好的推薦。因此,基于模型的推薦算法逐漸成為推薦領域中的研究熱點。基于模型的推薦算法中最關鍵的一步就是用戶模型的建立,因此很多流行的建模技術都可以應用在推薦算法上,如聚類[5]、分類、關聯規則、矩陣分解[6]等。后續學者利用這些建模技術提出了很多基于模型的改進推薦算法。
文獻[5]針對傳統協同過濾中沒有考慮用戶偏好的問題,利用聯合聚類技術結合用戶屬性相似性和用戶評分相似性來分析用戶偏好,采用了用戶屬性信息有效緩解了數據稀疏性,提高了評分預測準確度。文獻[6]在基于矩陣分解的推薦算法中引入標簽構建向量,作為對用戶興趣建模和項目特征表示的補充,提升了推薦精度。文獻[7]在矩陣分解模型中引入用戶屬性構建用戶屬性特征向量,計算新用戶與舊用戶之間的相似度,以解決新用戶冷啟動問題。雖然上述算法在一定程度上提高了算法預測準確度,考慮了用戶屬性和標簽等數據源,但是缺乏對用戶和電影的長短期狀態的考慮。
本文針對電影領域傳統推薦算法中的上述問題,提出基于GRU網絡和矩陣分解的混合推薦算法。首先,嚴格按照評分時間順序劃分數據集,得到用戶序列和電影序列,針對序列中高維稀疏的向量,使用自編碼器對其進行降維處理,然后使用兩個GRU(Gated Re?current Unit)[8]網絡處理時間序列數據以得到用戶和電影短期內隨時間變化的狀態特征,使用矩陣分解算法捕獲用戶和電影長期內固定狀態特征,最后用線性回歸模型結合長期狀態的內積和短期狀態的內積的線性加權結果作為該混合算法的最終預測評分,并在多個公開數據集上通過與傳統推薦算法的對比實驗,驗證本文提出的算法在預測評分的有效性和準確度。
1 GRU網絡
選擇GRU網絡來處理時間序列數據,是因為GRU網絡是一種改進的循環神經網絡[9],并且解決了循環神經網絡中的梯度消失問題,實現了更長距離的傳播。因此,GRU網絡能夠從時間序列數據中記憶歷史時刻的信息,并基于歷史信息和當前時刻的輸入來預測下一時刻即將發生的行為。
GRU控制信息流動原理是,利用門控機制控制當前輸入、歷史記憶等狀態信息在當前時間步做出預測。圖1給出了GRU模型的結構。從圖中可以看出,GRU的結構比較見到那,只有兩個門:重置門(reset gate)和更新門(update gate),即rt和zt。從信息流動的角度來說,重置門控制如何將新的輸入信息與前一時刻的狀態信息相結合;更新門控制前一時刻的狀態信息保存到當前狀態中的量。
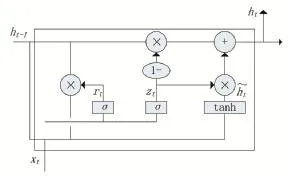
圖1 GRU結構圖
上圖1中,xt表示時刻t處GRU單元的輸入,ht表示t時刻的狀態信息,表示當前記憶內容。
(1)更新門
在時間步長t處,更新門的計算公式如下所示,其中Wz表示更新門的權重:

對輸入向量xt和前一時刻t-1隱藏狀態ht-1分別做線性變換,通過Sigmoid激活函數將兩部分的信息相加的結果壓縮到0到1之間。更新門決定前一時刻的狀態信息和當前時刻的狀態信息繼續傳遞到未來的量。
(2)重置門
在時間步長t處,重置門的計算公式如下所示,其中Wr表示重置門的權重:

與更新門類似,先對xt與ht-1分別做線性變換,然后通過Sigmoid激活函數輸出0到1之間的激活值。重置門決定了前一時刻的狀態信息要被遺忘的量。
(3)當前記憶內容
在當前記憶內容的計算中,將重置門直接應用于前一時刻的狀態信息上,以存儲前一時刻隱藏層的信息,計算公式如下,其中Wh?表示當前時刻輸入數據生成當前狀態信息的權重:

將前一時刻的狀態信息ht-1與重置門rt做對應元素的乘積,這一步驟確定了前一時刻所要保留的信息,然后對該乘積結果rt?ht-1和當前時刻的輸入xt做線性變換,通過tanh激活函數將兩部分相加的結果映射到-1到1之間,以得到當前記憶內容h?t。
(4)當前時間步的最終記憶
當前時間步的最終記憶ht將保留當前隱藏層的狀態信息并繼續傳遞到下一時刻。在這一步,使用更新門來決定當前記憶內容和前一時刻的狀態信息ht-1要保留的量,計算公式如下所示:

(1-zt)?ht-1表示前一時刻的信息保留到當前時刻最終記憶的量,zt?表示當前記憶內容保留到當前時刻最終記憶的量,兩個部分的相加結果作為GRU最終的輸出內容。本文使用ht=GRU(ht-1,zt)來表示GRU的前向計算過程

GRU網絡的參數更新方式采用BPTT算法[10]進行更新。
2 基于GRU網絡和矩陣分解的推薦算法
2.1 基于GGRRUU網絡的推薦算法
本文使用兩個GRU網絡模型分別解決用戶和電影狀態的時間演變,獲取短期內用戶和電影的時間狀態,并將用戶和電影時間狀態的內積作為最終預測評分。其中用戶的狀態變化取決于用戶先前對哪些電影進行評分,同樣的,電影的狀態變化依賴于前一段時間內對其進行評分的用戶。
首先,將評分數據嚴格按照時間戳進行劃分,以得到用戶序列和電影序列。但序列中的向量都是高維稀疏的,不利于模型的訓練。然后,利用自編碼器的編碼過程對數據進行降維,將降維后的低維稠密向量作為GRU網絡的直接輸入,并將預訓練期間自編碼器[11]隱藏層節點數和權重作為輸入嵌入層(即Embedding層)的節點數和權重。最后,通過GRU網絡能夠記憶歷史信息,并基于最新輸入對下一步的評分行為做出預測。
圖2給出了基于GRU網絡的推薦模型完整結構。
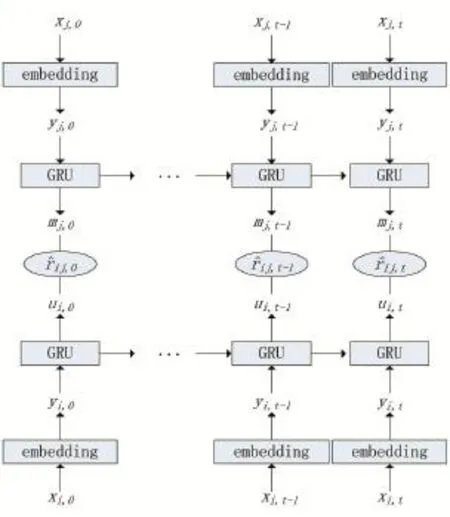
圖2 基于GRU網絡的推薦模型
其中,{xi,0,...,xi,t-1,xi,t}和{xj,0,...,xj,t-1,xj,t}分別表示原始用戶序列和電影序列,包含了0到t時刻的原始用戶i的向量和電影j的向量,Embedding層表示由自編碼器預訓練得到的模型的隱藏層,以實現數據降維,{yi,0,...,yi,t-1,yi,t}和{yj,0,...,yj,t-1,yj,t}分別表示由Embedding
層降維后直接用于GRU網絡輸入的用戶序列和電影序列,{ui,0,...,ui,t-1,ui,t}和{uj,0,...,uj,t-1,uj,t}分別表示由GRU網絡對輸入序列的處理得到的用戶和電影的時間狀態,{ri,0,...,ri,t-1,ri,t}表示0到t時刻對下一時刻用戶i對電影j的評分。
給定M個電影,N個用戶的數據集,則xi,t∈RM(xj,t∈RN)表示給定用戶i(或電影j)在時間t的評分向量,=k表示給定用戶i在時間步長t對電影j的評分為k,=k表示給定電影j在時間步長t處被用戶i的評分為k,否則對應元素值為0。由上述內容可知,用戶和電影時間狀態的計算公式如下所示:
將三種單礦物用瑪瑙研缽研至-5 μm,采用D8Advance/Bruker型X射線衍射儀進行定量分析,分析結果及XRD衍射圖分別見表1和圖1。

將用戶狀態和電影狀態的內積作為評分的估計值,計算公式如下:

<·>表示兩個向量之間的內積。對GRU網絡的輸出層做了適當改進,我們不使用激活函數[12],只做簡單的線性加權,其中,和分別是ui,t和mj,t的線性函數。即有:

其中,Wuser、Wmovie和buser、bmovie分別表示 GRU 的輸出到輸出層用戶和電影的權重和偏置。用θ表示模型中所有需要學習的參數,即Wrx、Wrh、Wzx、Wzh、Wh?x、Wh?h、Wuser、buser、Wmovie、bmovie。因此,基于 GRU 網絡的推薦模型的目標函數如下所示:

其中,Itrain表示訓練集中觀察到的(用戶、電影、時間戳)的元組的集合,R是關于參數的L2正則化項。訓練過程中,使用Adam優化器來優化訓練模型,以便模型的目標函數以最快速度達到最小,得到最優參數。
2.2 矩陣分解算法
使用矩陣分解算法對用戶和電影的長期狀態進行建模。基于矩陣分解的推薦算法的原理很簡單,就是將用戶-項目評分矩陣分解為用戶因子矩陣和項目因子矩陣,通過兩個矩陣相乘,得到原始評分矩陣中的缺失值,進而對用戶進行推薦。對于給定M個電影,N個用戶的評分矩陣RN×M,對R做矩陣分解的結果如下所示:

其中,K表示潛在因子的個數,P和Q分別表示用戶和電影與潛在因子之間的關系,R?N×M表示由兩個矩陣P和Q生成的預測評分矩陣。矩陣分解的目標是使預測評分矩陣和原始評分矩陣中的觀察值之間的誤差最小,即如下公式:
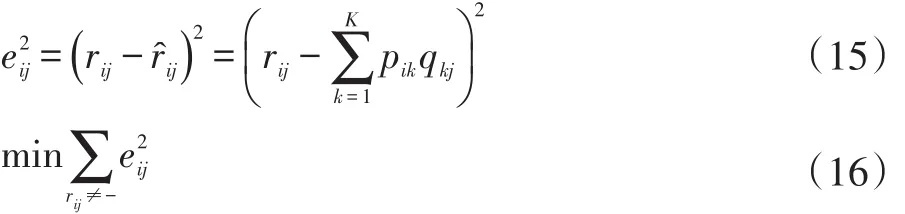
使用梯度下降法求得上述損失函數的參數變量的最優值。
2.3 基于GGRRUU網絡和矩陣分解的混合推薦算法
綜合前兩節的內容,綜合考慮長期和短期狀態對評分行為的影響,并針對數據維度高的問題,提出一種基于GRU網絡和矩陣分解的混合推薦算法。圖3給出了混合模型的結構。
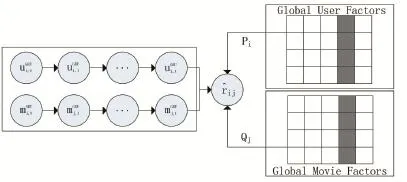
圖3 GRU網絡和矩陣分解的混合推薦模型
由上述內容,使用混合加權的方式將兩個訓練好的模型的預測評分結合起來以作為混合模型的預測評分,兩個基礎預測評分的權重通過線性回歸模型求解得出。最終預測評分的計算公式如式(17),其中表示基于矩陣分解的預測評分,表示基于GRU的預測評分,WMF和WGRU分別表示和在最終預測評分中所占的權重。

用L上述線性回歸模型的損失函數,則L的計算公式如下所示:

使用梯度下降法[13]確定式(17)中的權重WMF和WGRU,進而生成最終的預測評分。混合加權推薦算法綜合循環神經網絡和矩陣分解各自的優勢,綜合考慮長期和短期狀態,提高評分預測準確度。
3 實驗結果與分析
3.1 實驗數據集
為了研究時間動態的有效性建模,在Netflix比賽和IMDB數據集上評估本文模型。IMDB數據集包含1998年7月至2013年9月期間收集的1429600個評分,完整Netflix數據集包含1988年11月至2005年12月期間收集的100400000個評分,其中6個月Netf?lix數據包含2005年6月至2005年12月期間收集的15800000個評分。每個數據點是一個時間戳粒度為1天的(用戶id,項目id,時間戳,評分)元組。根據時間分割數據以模擬需要預測未來評分的實際情況。整個數據集都被分割成訓練集和測試集。詳細數據如表1所示。
3.2 實驗設置
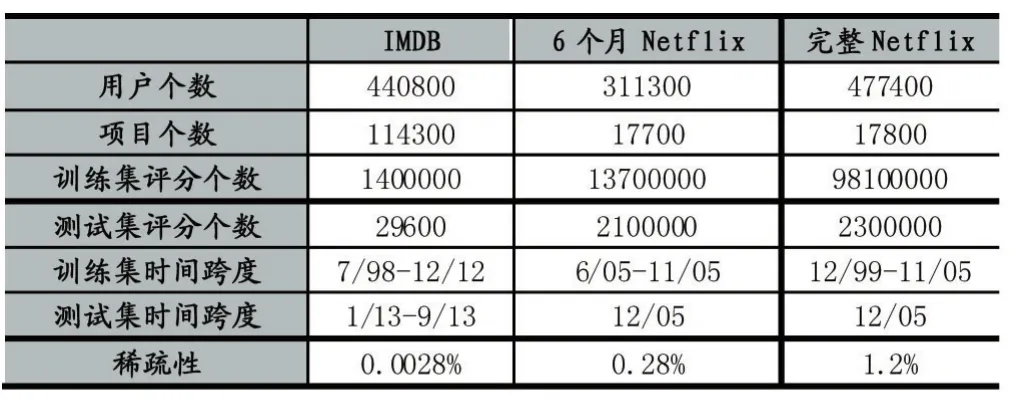
表1 實驗數據集的詳細數據
實驗中使用具有20個隱藏神經元,40維輸入嵌入和20維動態狀態的單層GRU。本文模型在Tensor?Flow[14]上實現,這是一個開源的深度學習框架。
均方根誤差(RMSE)和平均絕對誤差(MAE)均是度量預測誤差的指標,其中,RMSE對大誤差比較敏感,MAE對小誤差的積累比較敏感。由于RMSE加大了對預測不準的用戶物品評分的懲罰,對系統的測評更加苛刻,實驗中選擇RMSE評估算法精度。對于完整的Netflix和IMDB數據集,采用2個月的時間步長粒度,對于六個月的Netflix數據集,采用7天的時間步長粒度。每個時期之后,計算RMSE。在驗證集上給出最佳結果的模型上,計算在測試集上的RMSE。
3.3 實驗結果及分析
為了評估本文提出模型(R-GRUMF)的性能,將其與PMF、TimeSVD、AutoRec進行對比實驗。實驗結果如表2所示。

表2 各模型在數據集上的RMSE
從表2可以看出,R-GRUMF模型的RMSE比所有對比模型的RMSE都要低,表示該模型能有效降低預測誤差,并且在越稀疏的數據集上,其RMSE的差距越大,說明該模型可以在一定程度上緩解數據稀疏性對模型預測評分的影響。雖然對比方法在不同數據集之間排名忽前忽后,但是本文提出的模型在所有數據集中的預測誤差都是最低的,說明該模型有很好的健壯性,適應不同的數據集。
4 結語
本文針對電影領域中傳統推薦算法中數據維度高,缺乏考慮用戶和電影長短期狀態的問題,利用GRU網絡在處理時間序列數據上的優勢,捕獲短期狀態,利用矩陣分解對長期用戶和電影之間的交互評分行為的建模分析,得到長期狀態,綜合考慮兩種狀態對預測評分的影響,提出一種基于GRU網絡和矩陣分解的混合推薦算法,緩解了數據稀疏性問題,提高了評分預測準確度。
本文嘗試將GRU網絡用于推薦,并取得不錯的效果。但是整個推薦過程中,也僅僅使用了評分及時間戳信息,目前推薦系統中還有很多更加復雜的數據源可供研究,如用戶評論、電影的音頻及圖像等信息都可以被深度學習等技術利用起來,以建立更完善的用戶個人畫像,提高推薦精度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
核科學與工程(2015年4期)2015-09-26 11:59:03
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
