基于特征融合網絡的自然場景文本檢測①
2018-10-24 11:05:38王晴晴
計算機系統應用 2018年10期
余 崢, 王晴晴, 呂 岳
(華東師范大學 計算機科學與軟件工程學院, 上海 200062)
1 概述
隨著互聯網和多媒體技術的發展, 越來越多的信息載體以圖像的形式存在. 自然場景圖像中的文字作為一種極其重要的信息來源, 捕獲和識別這些文字有助于理解和分析圖像, 因此, 自然場景圖像中的文本檢測成為當下熱門的研究話題之一. 目前文本檢測技術在現實生活中有著廣泛的應用, 例如, 手機設備上的拍照翻譯軟件, 可以拍攝異國街道或路牌上的文字, 將一種語言實時翻譯為另一種語言, 提供導游幫助;公安機關的高速監控設備, 可以抓拍識別高速公路上行駛汽車的車牌號碼, 智能化收集違章車輛信息[1]. 除此之外,文本檢測技術在圖像檢索[2]、視頻字幕提取[3]等領域也存在廣泛的應用. 因此, 對自然場景圖像中的文本檢測進行研究具有重要的理論意義和實用價值.
由于自然場景圖像中背景錯綜復雜, 以及文字所處的位置可能存在逆光、遮擋和模糊等現象, 準確檢測出場景中的文字成為一項具有挑戰性的工作. 同時,自然場景中的文字具有字體多樣、顏色多變、分布不一的特點, 文本檢測技術需要具有較強的魯棒性.
傳統的自然場景文本檢測方法主要依賴于手動創建圖像的特征, 利用機器學習的方法判別出文字的位置, 此類方法存在計算量大、檢測過程復雜等缺點. 近年來, 隨著深度學習的發展, 基于深度學習的方法在文本檢測中取得顯著的效果, 這些方法簡單高效, 利用單個神經網絡便能檢測到不同尺度的文本. 但是, 大多數的神經網絡在檢測小尺度的文本上不能取得很好的效果. 因此, 本文基于傳統深度神經網絡, 在保證網絡層次結構不變的前提下, 提出將網絡中的高層特征與低層特征進行融合, 構建一種高級語義的神經網絡用于自然場景文本檢測.
為了驗證高層特征與低層特征不同融合方式對網絡性能的影響, 本文提出三種特征融合網絡, 分別為相鄰兩層特征融合網絡、相鄰三層特征融合網絡和最高層特征融合網絡. 特征融合網絡在層次結構上是金字塔結構, 通過自底向上和自頂向下的連接方式將不同層的特征進行融合. 特征融合后的網絡具有多個輸出層, 每個輸出層都具有較強的語義信息并能檢測不同尺度的文字. 本文在ICDAR2011和ICDAR2013兩個標準數據集上進行了實驗, 實驗表明本文提出的特征融合網絡可以有效地檢測出小尺度的文本, 并具有較高的定位準確性和魯棒性.
2 相關研究
自然場景文本檢測是從具有復雜背景的圖像中檢測出文字的位置. 目前自然場景文本檢測方法主要分為三類:基于滑動窗口的文本檢測方法、基于連通域的文本檢測方法和基于深度學習的文本檢測方法.
2.1 基于滑動窗口的文本檢測方法
基于滑動窗口的文本檢測方法使用多尺度的滑動窗口去掃描圖像, 搜索圖像中文字出現的位置. 基于文字的特征, 運用一個預訓練的文字分類器, 判別窗口內是否存在文字. 其中文獻[4]使用滑動窗口結合方向直方圖(Histogram Of Gradient, HOG)特征建立文本置信圖, 然后使用隨機蕨(random ferns)過濾掉圖中的非文本區域. 文獻[5]結合多尺度滑動窗口利用AdaBoost算法, 將多個弱文本分類器組合成強文本分類器, 過濾掉圖中的非文字區域. 這類方法的主要缺陷是需要對整張圖像進行窮盡式的掃描, 計算量大、消耗時間.
2.2 基于連通域的文本檢測方法
基于連通域的文本檢測方法是利用文字區域具有相同的顏色和結構等特征來生成文本連通域, 然后根據連通域的大小, 寬高比等先驗知識來獲得文字區域.文獻[6]提出使用筆畫寬度變換(Stroke Width Transform, SWT)算子提取出字符筆畫的邊緣圖, 再結合幾何推理恢復出字符的形態, 該算子可以有效地提取復雜背景圖像中不同尺度的文本. 文獻[7]率先提出最大穩定極值區域(Maximally Stable Extremal Regions, MSER)算法檢測文字, 該算法能有效地提取候選文本連通域, 然后通過形態學操作和連通域的形狀來確定文本區域. 為解決MSER算法檢測結果存在較多嵌套區域的問題, 文獻[8]采用MSCR (Maximally Stable Color Regions)算法與MSER算法相結合提取候選字符區域, 依據字符區域的顏色一致性和幾何鄰接關系對字符進行合并, 最終得到文本區域. 基于連通域的方法降低了掃描圖像的計算復雜度, 但這類方法應用了大量的自定義規則和參數, 并且很容易生成大量的非文字候選字符和重復的文字候選字符. 為了消除無效的候選字符, 該類方法還需要設計一個字符級別的分類器過濾掉無效的候選文字, 使得檢測復雜度增大.
2.3 基于深度學習的文本檢測方法
近年來, 隨著深度學習的發展, 越來越多的研究傾向于使用深度神經網絡來解決文本檢測問題. 文獻[9]率先提出使用卷積神經網絡(Convolutional Neural Network, CNN)訓練一個文本分類器. 卷積神經網絡通過提取圖像的深層特征來區分文本和非文本, 訓練過程簡單高效. 基于卷積神經網絡的強分類性能, 文獻[10]首先使用MSER算子提取圖像中的候選文字連通域,然后使用CNN分類器過濾掉MSER產生的無效連通域, 該方法大幅度地提高了傳統檢測文本的性能.
隨著深度神經網絡在目標檢測中的發展, 先后涌現出一系列的目標檢測方法, 例如, R-CNN (Regions with CNN)[11], Fast R-CNN[12], Faster R-CNN[13], SSD(Single Shot multibox Detector)[14]. 其中, SSD通過單個卷積神經網絡直接預測目標的邊界框并且得到相應類別的概率.
受SSD直接預測目標的邊界框的啟發, 文獻[15]將SSD應用于文本檢測, 并提出一個用于文本檢測的神經網絡TextBoxes, TextBoxes利用網絡層中的特征圖(feature map)直接輸出文本的邊界框和置信度. 其網絡結構, 如圖1所示. 該網絡是一個全卷積神經網絡,網絡結構里有多個輸出層(conv4_3, conv6_2, conv7_2,conv8_2, conv9_2, conv10_2, conv11_2). 這些輸出層是網絡中的卷積層, 也是網絡結構中的關鍵組成部分, 可以在其特征圖上預測文本出現的概率和文本邊界框.網絡最后使用非極大值抑制算法聚集所有的Textbox層輸出的文本框, 得到最終的文本位置.
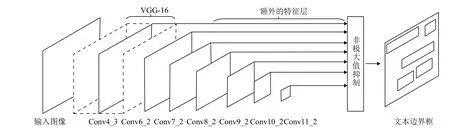
圖1 TextBoxes的網絡結構圖
TextBoxes的網絡模型可以端到端進行訓練, 不僅訓練過程簡單, 而且檢測速度快. TextBoxes可以在不同分辨率的特征圖上預測文字的位置, 與以往的文本檢測方法相比, 它的處理過程簡單, 不需要設計啟發式的規則, 使得文本檢測更加高效. 但是它不能較好地預測小尺度文本. 因此, 本文將提出新的方法來提高網絡對小尺度文字的定位準確率, 進一步提高網絡的性能.
3 基于特征融合網絡的自然場景文本檢測
TextBoxes的網絡模型具有金字塔特征層次結構,網絡高層的語義信息比較強, 低層語義信息比較弱. 由于網絡低層特征圖表達能力不足, 所以不能較好地預測小尺度的文本. 為了解決該問題, 提高低層特征圖的表達能力, 使網絡能在不同分辨率的特征圖上都能檢測到對應尺度的文本, 本文提出將網絡高層的特征與低層的特征進行融合得到新的特征圖, 在新的特征圖上預測文字的位置.
3.1 特征融合
特征融合是指提取和綜合目標的兩種或多種特征,提高同一類別的目標識別率. 一般是將不同的特征向量組合起來, 組成一個新的特征向量, 然后采用分類器進行判別分類. 在神經網絡中, 將網絡高層特征和低層特征進行融合, 可以使用融合特征圖的方式. 將特征圖進行融合一般有兩種方式, 分別是元素求和方式和元素點積方式.
神經網絡中的特征圖相當于二維矩陣, 使用元素求和方式和元素點積方式必須要求兩個矩陣的大小一致. 由于高層和低層輸出層對應的特征圖大小不一致,不能直接進行融合. 為了融合高層特征和低層特征, 本文對網絡高層輸出的特征圖使用一個反卷積操作, 將網絡高層特征圖的尺度大小處理成與低層特征圖一致.反卷積操作類似于雙線性差值, 可以有選擇地對特征圖進行放大. 在神經網絡中, 使用反卷積層實現反卷積操作, 反卷積層輸出的特征圖大小的計算公式為:
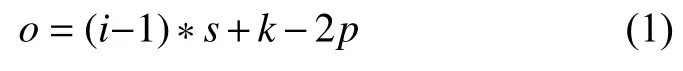
其中,i表示反卷積層輸入特征圖的大小,k表示卷積核的尺寸,s表示步長大小,p表示填充邊距. 網絡高層的特征圖通過反卷積層設置相應的參數, 便可得到與低層一樣大小的特征圖.
假設網絡高層特征圖為A (n×n矩陣), 低層特征圖為B (m×m矩陣), 高層特征圖A (n×n矩陣)通過反卷積操作得到新的特征圖A’(m×m矩陣). 將兩個相同尺度的特征圖A’和B進行融合, 使用元素求和方式, 即兩個矩陣對應元素求和, 融合后的特征圖為T1:
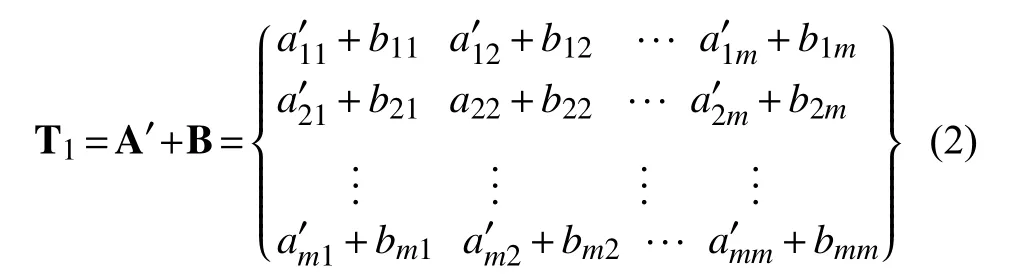
使用元素點積方式融合兩個特征圖, 即兩個矩陣對應元素相乘, 融合后的特征圖為T2:
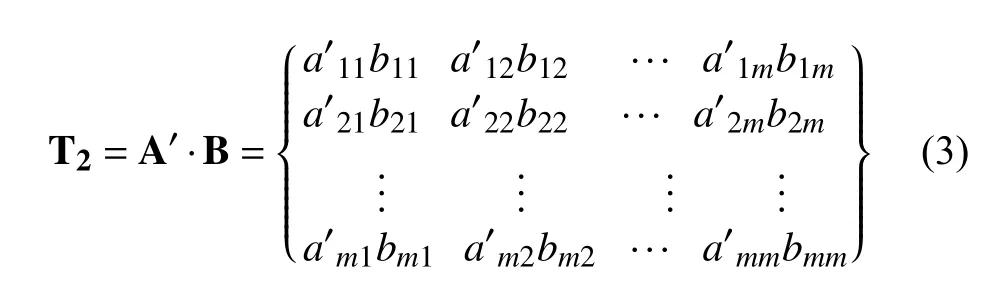
研究表明[16], 點積計算能得到更好的精度, 獲得更好的融合效果, 因此, 本文采用元素點積方式實現特征圖的融合.
3.2 特征融合網絡的結構
原始網絡的輸出層是網絡中獨立的卷積層, 網絡中特征圖經過卷積核計算越來越小, 特征圖語義信息越來越強, 如圖2(a)所示. 雖然, 網絡的每個輸出層都可以通過特征圖預測文字的位置, 但是, 網絡中低層輸出層語義信息表達能力弱, 無法準確檢測到小尺度的文本. 為了增強網絡低層輸出層的語義信息, 本文運用特征融合方式, 將網絡高層的特征圖與低層的特征圖進行融合, 并提出三種特征融合網絡, 分別為相鄰兩層特征融合網絡、相鄰三層特征融合網絡以及最高層特征融合網絡.
特征融合網絡在結構上有兩種連接方式, 一種是自底向上的連接方式, 一種是自頂向下的連接方式. 自底向上是網絡的前向傳播過程, 特征圖的大小經過卷積層后會逐漸變小, 整個網絡在層次結構上是金字塔結構. 自頂向下的連接采用反卷積, 將反卷積的結果與自底向上生成的相同大小的特征圖進行融合. 特征融合后的網絡利用高層特征的強語義信息, 提高網絡低層的語義信息. 網絡通過融合不同層的特征達到預測效果, 并在每個融合后的特征層上預測文字.
以TextBoxes中Conv4_3和Conv6_2兩層特征進行融合為例, 在Caffe深度學習框架下, 網絡的連接方式, 如圖3所示. 低層的Conv4_3層, 先連接一個1×1的卷積層, 目的是減少特征圖的通道數, 進而降低計算復雜度, 該操作并不會對特征圖的大小產生影響.高層的Conv6_2層經過反卷積操作后, 特征圖大小與Conv4_3層一致. 接著對兩層特征使用BatchNorm層對數據進行標準化, 消除數據間的量綱關系, 避免梯度更新導致數值問題, 同時可以加快收斂速度尋找最優解. 最后使用Eltwise層的product操作, 對特征圖采用元素點積方式進行融合, 融合后的結果作為新的輸出層, 預測文字的位置和置信度.
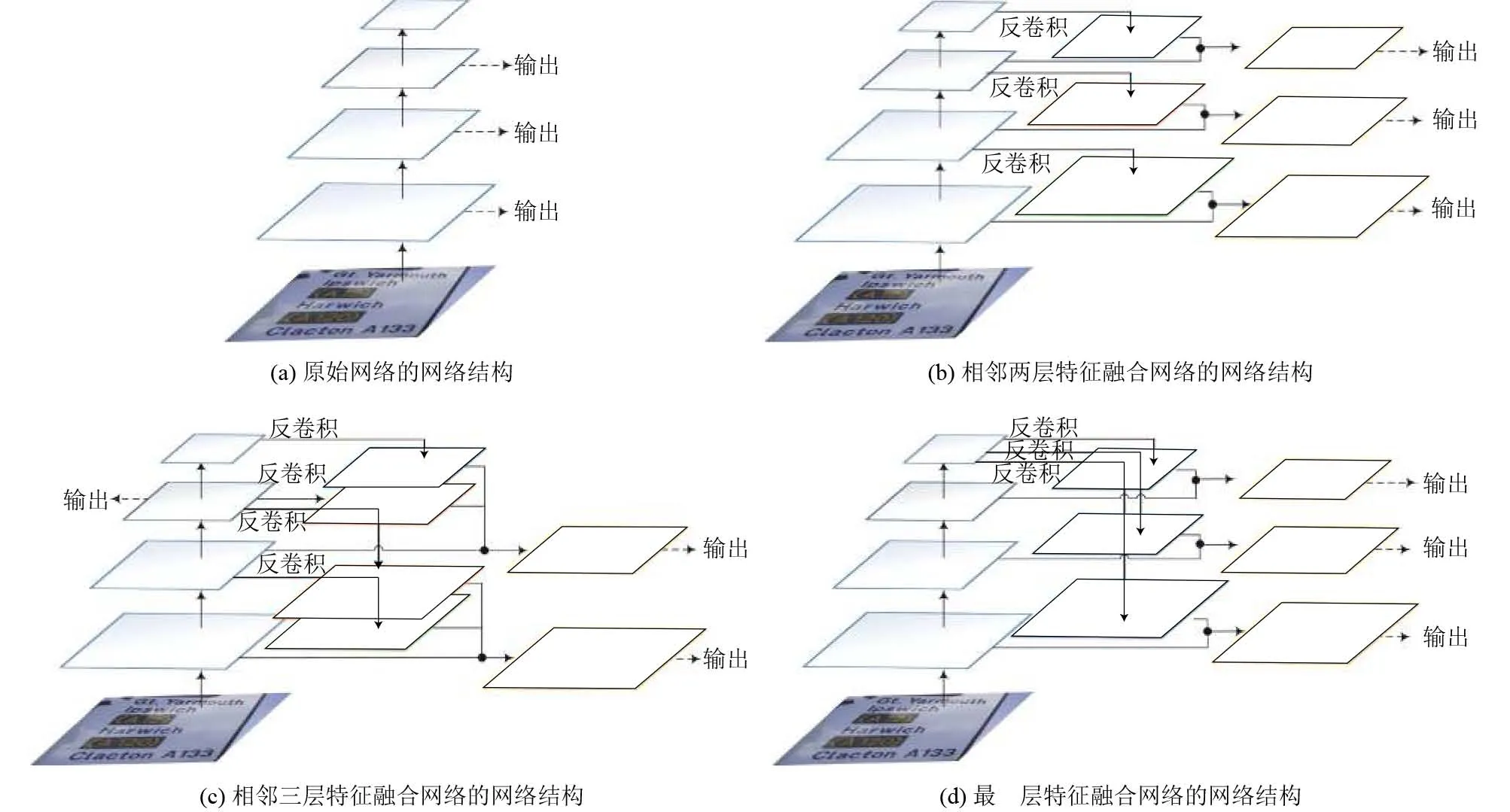
圖2 原始網絡的網絡結構與特征融合網絡的網絡結構對比圖
本文提出三種特征融合網絡, 選擇不同的組合方式將高層特征與低層特征進行融合. 相鄰兩層特征融合網絡是指原始網絡低層的特征圖與最近鄰的高層特征圖進行融合的網絡, 如圖2(b)所示, 原始網絡高層的特征圖經過反卷積操作, 得到與低層尺度一樣的特征圖, 然后兩個相同尺度的特征圖進行融合得到新的特征圖, 網絡在新的特征圖上輸出文字的位置.
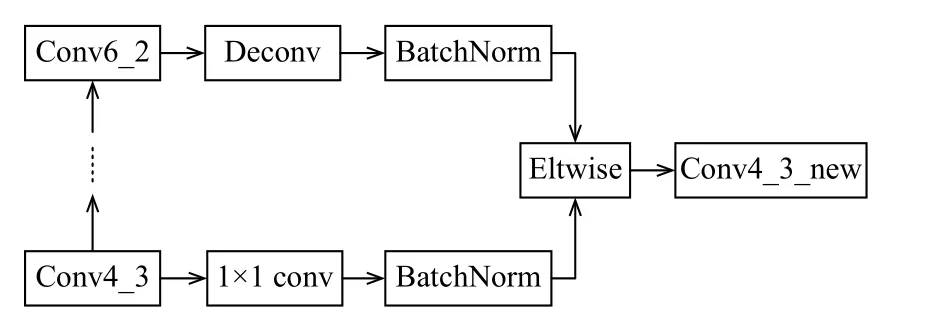
圖3 Caffe框架下網絡層的連接方式
相鄰三層特征融合網絡是指原始網絡低層的特征圖與近鄰的兩層特征圖進行融合的網絡, 如圖2(c)所示. 其中, 近鄰的兩層特征圖都來自于網絡的高層特征圖, 融合后的特征圖來自于原始網絡的三層特征圖. 如果較高層的輸出層沒有兩個近鄰的特征層可以融合,則輸出層保持不變.
最高層特征融合網絡表示原始網絡中語義信息最強的特征圖分別與其他輸出層的特征圖進行融合的網絡, 如圖2(d)所示, 新的輸出層來自于低層特征與最高層特征的融合.
3.3 特征融合網絡的采樣策略
特征融合網絡在訓練時僅僅需要輸入圖像和圖像中文本的真實標簽框(ground truth). 由于網絡的輸出是預測文本框與默認框(default box)的偏移坐標以及文本的置信度, 因此, 網絡在訓練過程中, 需要建立真實標簽框和默認框之間的關系, 并對默認框進行標注.
特征融合網絡在每個輸出層上采用滑動窗口的模式生成默認框,N×N的特征圖有N×N個特征點, 每個特征點可以對應多個不同橫縱比的默認框. 本文使用jaccard重疊率作為匹配指標對默認框進行標注, jaccard重疊率越高表明樣本相似度越高, 兩個樣本越匹配. 給定默認框A和真實標簽框B, 默認框與真實標簽框的jaccard重疊率表示A與B的交集面積與并集面積的比值:
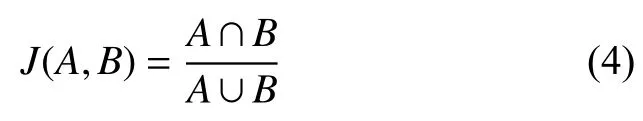
本文將jaccard重疊率大于或等于0.5的默認框作為匹配的默認框, jaccard重疊率小于0.5的默認框作為不匹配的默認框. 其中, 匹配的默認框作為正樣本,不匹配的默認框作為負樣本. 如圖4(a)所示, 文本“Marlboro”的真實標簽框為圖中的上方的實線框, 文本“LIGHTS”的真實標簽框為圖中的下方的實線框. 在圖4(b)和4(c)中可以看到一些虛線框, 虛線框表示特征圖上的默認框. 其中, 有兩個加粗的虛線框匹配文本“LIGHTS”, 有一個加粗的虛線框與文本“Marlboro”相匹配, 因此, 標注匹配的默認框作為正樣本, 不匹配的默認框作為負樣本.
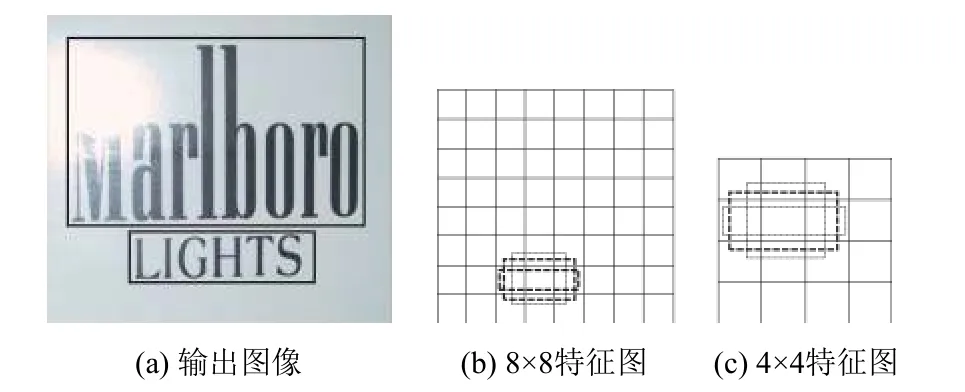
圖4 特征融合網絡的特征圖
通過樣本標注階段后, 默認框中會產生大量的負樣本, 這會導致正負樣本的數量不均衡, 進而導致模型不穩定, 預測效果差. 為了解決該問題, 本文將默認框中的負樣本通過置信度損失進行排序, 選擇置信度損失值較高的默認框作為網絡訓練的負樣本, 使訓練的正負樣本的比例保持在1:3, 這樣可以穩定網絡的訓練.
3.4 特征融合網絡目標函數
特征融合網絡的目標函數源自于TextBoxes的目標函數, 特征融合網絡能處理默認框與文本的真實標簽框是否匹配. 假設一張圖像中存在第i個默認框和第j個真實標簽框,xij=1表示第i個默認框與第j個真實標簽框相匹配, 如果不匹配, 則xij=0.
特征融合網絡的目標損失函數是定位損失與置信度損失的加權和:
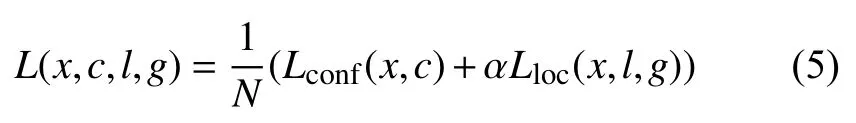
其中,x表示匹配結果矩陣,c表示置信度,l表示預測位置,g表示文本的真實位置,N表示默認框匹配真實標簽框的個數;其中, 權重系數α設置為1;定位損失Lloc是預測位置和真實位置的L2損失:
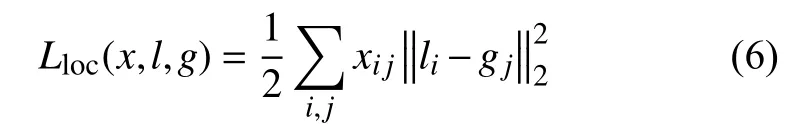
置信度損失Lconf是二分類的softmax損失:
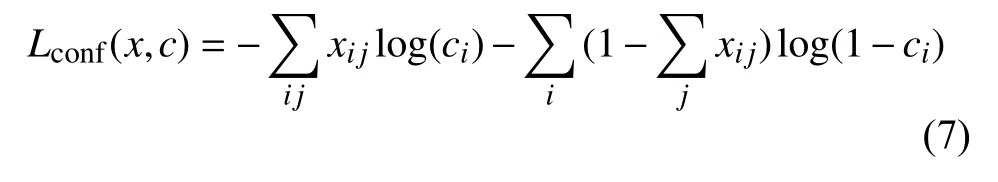
3.5 多尺度文本檢測
特征融合網絡在層次結構上仍然是金字塔結構,網絡在新的輸出層上預測文本框的位置和置信度. 在每個輸出層的特征圖上定義一系列固定大小的默認框,輸出層輸出文本的置信度和相對于默認框的偏移坐標.假設圖像和特征圖的大小分別是(wim,him)和(wmap,hmap), 在特征圖中(i,j)位置對應一個默認框b0=(x0,y0,w0,h0), 輸出層的輸出為 (Δx, Δy, Δw, Δh,c), 其中 (Δx,Δy, Δw, Δh)表示預測文字邊界框相對于默認框的偏移坐標,c表示文字的置信度. 預測的文字邊界框為b=(x,y,w,h), 其中:
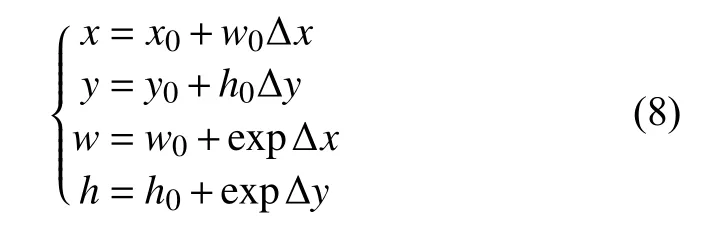
x,y表示預測的文本框的左上角的橫縱坐標,w,h為文本框的寬和高. 為了預測不同橫縱比的文本邊界框, 特征圖上每一個特征點可以關聯多個橫縱比的默認框. 本文使用6種橫縱比的默認框去預測文本邊界框:
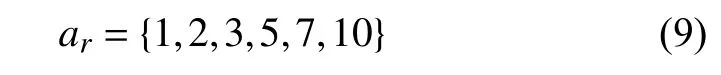
此外, 由于網絡中不同的輸出層對應的特征圖尺度不一樣, 輸出層可以預測不同尺度的文字. 假設網絡中有m個輸出層, 每個輸出層對應一個特征圖, 每個特征圖中默認框的尺度為:
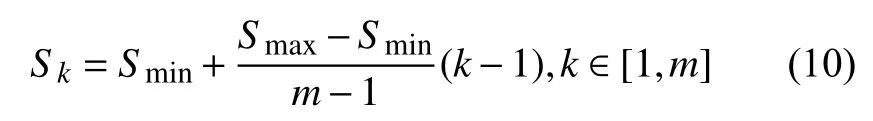
每個默認框的寬度和高度分別為:
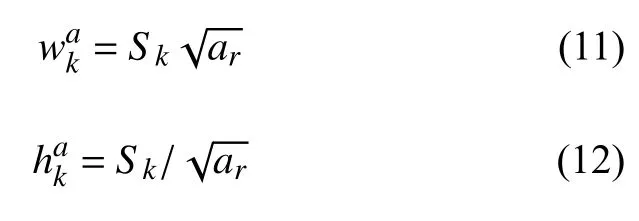
其中,Smin,Smax分別表示最低層和最高層的默認框的尺度. 從公式(10)可以看出, 低層輸出層預測小尺度的文字, 高層輸出層預測大尺度的文字.
輸出層的默認框在不同的特征圖上有著不同的尺度, 在同一個特征圖又有著不同的橫縱比, 相應的, 整個網絡可以通過多個輸出層預測不同尺度和不同形狀的文本. 最后, 網絡使用非極大值抑制算法聚集輸出層輸出的所有文本框, 選擇置信度較高的文本框作為文本檢測結果.
3.6 非極大值抑制算法
非極大值抑制算法(Non-Maximum Suppression,NMS)的本質是搜索局部極值點, 抑制非極大值元素,該算法被廣泛應用在目標檢測的后處理中, 主要目的是排除多余的檢測結果, 得到目標的最佳位置.
文本檢測中普遍使用非極大值抑制算法去除冗余文本框, 因為它簡單高效, 主要步驟如下:
(1) 將文本檢測結果(預測文本框)按照置信度的值從高到低排序;
(2) 將第一個文本框作為當前抑制的文本框;
(3) 非極大值抑制. 將其他文本框作為被抑制文本框, 計算當前抑制文本框與被抑制文本框的面積交疊率(IOU). 如果交疊率高于閾值α, 剔除該文本框.
(4) 如果只剩最后一個文本框, 則算法結束;否則,按照之前排列好的順序, 取下一個未被抑制的文本框作為抑制文本框, 執行步驟(3).
(5) 算法結束后, 選擇置信度高于閾值β的文本框作為最終文本檢測結果.
其中, 兩個文本框的面積交疊率的計算方法如公式(13)所示,area(A)和area(B)分別為文本框A和文本框B的面積:
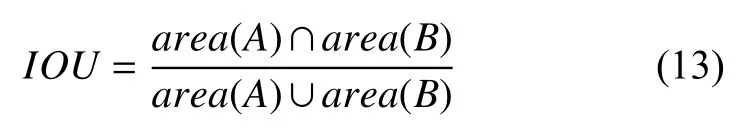
使用非極大值抑制算法后, 文本檢測的結果, 如圖5所示. 圖5(a)表示輸入圖像, 圖5(b)表示通過網絡檢測后預測的文本框的位置及置信度, 圖5(c)表示使用非極大值抑制算法后文本檢測的最終結果.

圖5 使用非極大值抑制算法后文本檢測結果
4 實驗結果和分析
4.1 數據集
為驗證網絡的有效性, 本文在兩個公開的場景文本檢測數據集上評估網絡的性能:ICDAR2011和ICDAR2013. 其中ICDAR2011數據集包含229張訓練圖像和255張測試圖像, ICDAR2013數據集包含229張訓練圖像和233張測試圖像.
4.2 網絡參數設置
本文的網絡使用隨機梯度下降(Stochastic Gradient, SGD)的方法訓練, 其中動量(momentum)和權值衰減系數(weight decay)分別設置為0.9和5×10–4.最大迭代次數為12萬次, 學習率(learning rate)初始設置為 10–3, 迭代 6 萬次后, 學習率調整為 10–4. 整個實驗在深度學習框架Caffe平臺上進行, 訓練和測試圖像的尺寸都為700×700, 每個訓練模型使用一個Titan X GPU大約訓練50小時.
4.3 性能指標
在自然場景文本檢測算法里, 涉及三個評價指標,分別為準確率(P)、召回率(R)和F值(F).
準確率表示檢測正確的文本框數量與算法檢測出的文本框數量的比值, 召回率表示檢測正確的文本框數量與數據集中真實文本框數量的比值. 準確率和召回率是一對矛盾的度量. 一般來說, 準確率高時, 召回率往往偏低;而召回率高時, 準確率往往偏低. 所以, 準確率和召回率都不能唯一的評價算法的性能. 為了綜合評價算法的性能, 一般使用準確率和召回率的調和平均數(F值)來衡量算法的優劣. 準確率、召回率和F值, 三個評價指標的計算公式分別如公式(14)、公式(15)、公式(16)所示:

其中,Match(G,D)表示檢測正確的文本框數量,D表示算法檢測出的文本框數量,G表示數據集中真實文本框數量.
4.4 實驗分析
為了確定文本檢測中后處理算法(非極大值抑制算法)中交疊率和置信度選取的最佳閾值, 本文首先在ICDAR2013數據集上, 對原始網絡的文本檢測結果進行實驗分析.
如圖6所示, 為非極大值抑制算法中交疊率α和置信度β采用不同值進行組合下的文本檢測性能. 從圖中可以看出, 當交疊率α和置信度β分別取值為0.5和0.6時, 文本檢測性能達到最高并趨于穩定. 因此, 本文的實驗中, 非極大值抑制算法中的交疊率α和置信度β分別取值0.5和0.6. 在后續的網絡性能對比中, 本文均使用該閾值進行實驗對比.
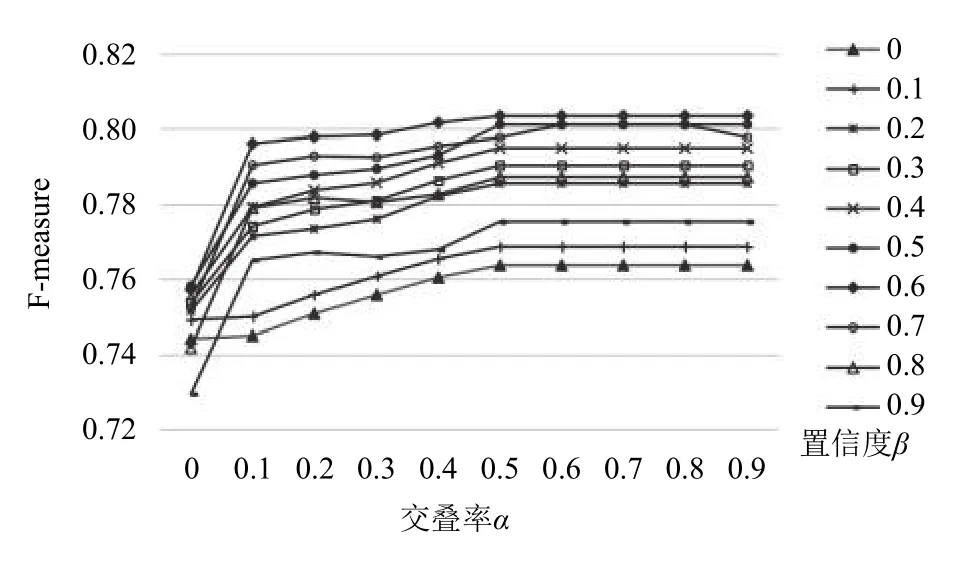
圖6 不同交疊率α和置信度β下的文本檢測性能
本文提出了三個特征融合網絡, 分別為相鄰兩層特征融合網絡、相鄰三層特征融合網絡以及最高層特征融合網絡. 本文在ICDAR2013數據集上驗證提出的特征融合網絡的性能, 在輸入圖像為單尺度的條件下,與原始網絡(Fast TextBoxes)[15]進行實驗對比.
如表1所示, 本文提出的三個特征融合網絡中, 相鄰兩層特征融合網絡和最高層特征融合網絡在F值上分別得到2%和3%的提升, 而相鄰三層特征融合網絡的F值與Fast TextBoxes相比下降1%.
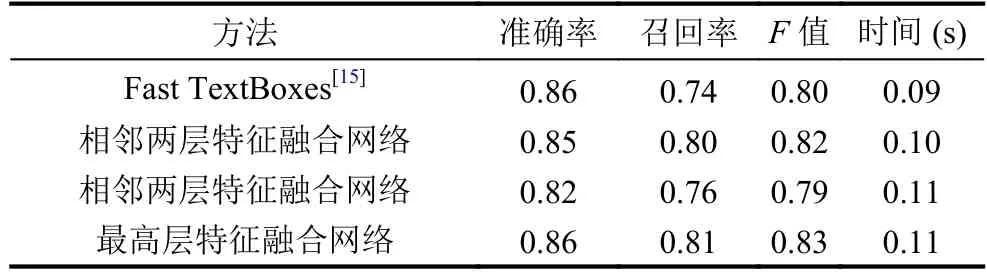
表1 原始網絡與特征融合網絡實驗對比結果
此外, 本文的方法與Fast TextBoxes相比, 在召回率上提升較高, 三個特征融合網絡在召回率上分別提升了6%、2%和7%. 這是因為特征融合后, 網絡低層輸出層的特征圖的語義信息得到增強, 能準確預測出小尺度的文字, 總體的召回率得到提升. 如圖7所示,原始網絡(Fast TextBoxes)對于檢測小尺度文字并不理想, 不能準確檢測出小尺度文字, 而本文采用不同層特征圖進行融合的方式, 能有效地檢測出小尺度文字.
從時間性能上比較, 本文提出的特征融合網絡在時間性能上與原始網絡相比存在微小的差異, 微小的差異來源于特征融合中反卷積的計算, 但并不影響現實應用.

圖7 原始網絡和特征融合網絡實驗結果對比
相鄰三層特征融合網絡與相鄰兩層特征融合網絡相比較, 在準確率和召回率上均有所下降. 此外, 在訓練過程中, 多層特征進行融合存在計算量大、消耗內存的情況, 因此本文沒有采用三層以三層以上的特征融合網絡.
本文所提出的三種特征融合網絡中, 最高層特征融合網絡的性能最好. 由于最高層的語義信息比較強,高層的語義特征融合至其他層后, 使網絡在各個層級上都具有豐富的語義, 性能上取得顯著的提升, 并且不犧牲速度和內存. 因此, 之后的實驗中, 本文使用最高層特征融合網絡作為最佳的特征融合網絡, 與常用的自然場景文本檢測方法進行比較.
表2和表3分別展示了最高層特征融合網絡與其他方法在ICDAR2011和ICDAR2013數據集上的實驗結果. 從表中可以看出, 本文的方法在ICDAR2011和ICDAR2013數據集上,F值都達到0.83, 比原始網絡(Fast TextBoxes)的F值的提高了3%, 比之前最好的方法提高了2%. 本文方法最大的優勢在于召回率得到顯著的提升, 在ICDAR2011數據集上, 本文方法比之前最好的方法Text Flow在召回率上提升了4%;在ICDAR2013數據集上, 本文方法比之前最好的方法FCN在召回率上提高了5%, 這主要因為小尺度文本檢測的召回率得到提升. 綜上所述, 本文的方法相比于之前的方法, 能有效地檢測出小尺度文本, 文本檢測的整體性能有顯著的改善.
由上述實驗結果可知, 本文方法在自然場景文本檢測上能夠有效地檢測出文字的位置. 圖8展示了使用本文的最高層特征融合網絡檢測文本成功和失敗的圖例. 檢測成功的圖例(圖8(a))顯示出本文方法具有較高的定位準確性和魯棒性, 能有效地從復雜背景中檢測出不同大小和不同形狀的文字. 對于檢測失敗的圖例(圖8(b)), 圖像中的文字極其模糊或者文字與背景具有較低的對比度, 即使人眼也很難識別出圖像中的文字區域.
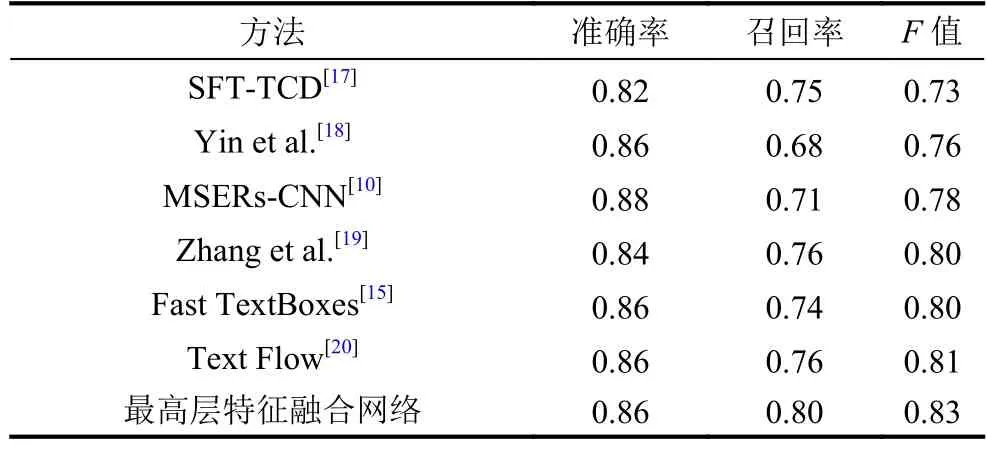
表2 在ICDAR2011數據集上的實驗結果
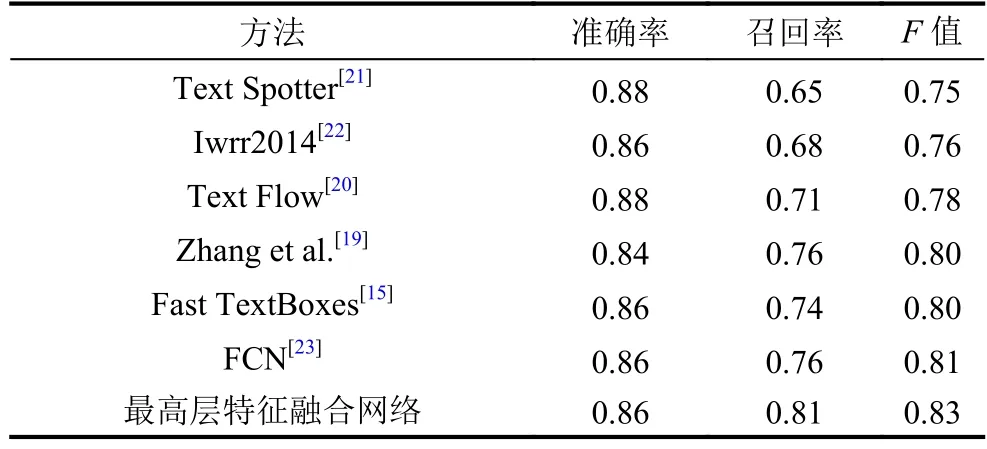
表3 在ICDAR2013數據集上的實驗結果

圖8 本文方法檢測文本示例圖
5 結論與展望
本文提出了一種基于特征融合的深度神經網絡,該網絡將高層特征與低層特征相融合, 利用網絡高層的強語義特征增強低層輸出層的語義信息, 使整個網絡的輸出層都具有較強的表達能力. 特征融合后的網絡能在不同的輸出層上預測不同尺度以及不同形狀的文字. 本文在兩個公開的數據集上驗證了特征融合網絡的性能, 實驗結果表明本文提出的特征融合網絡對小尺度的文字, 定位效果顯著. 其中, 本文提出的最高層特征融合網絡能取得最佳的檢測效果, 具有較高的定位準確性和魯棒性, 并優于常用的自然場景文本檢測方法,F值在ICDAR2011和ICDAR2013兩個數據集上均達到了0.83. 本文的特征融合網絡只支持單尺度的圖像輸入, 在一定程度上限制算法性能的提升. 因此, 下一步的工作, 我們將嘗試把改進后的網絡改為多尺度輸入的網絡. 網絡將會從以下兩方面進行修改, 一方面是改變網絡中卷積層的卷積核大小, 建立輸出層中不同大小的特征圖之間的整體關聯性, 使網絡能支持多尺度圖像輸入. 另一方面, 使用其他方式放大高層的特征圖, 例如, 反池化操作, 即記錄池化過程中最大激活值所在的坐標位置, 然后上采樣得到放大的特征圖, 使網絡中融合的特征圖能自適應進行變化而不依賴于固定計算. 接下來的工作, 我們將嘗試用這兩種方法, 進一步提高網絡的性能.
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
