基于卷積神經網絡的候鳥潛在分布預測①
2018-10-24 11:06:56蘇錦河樸英超閻保平
計算機系統應用 2018年10期
蘇錦河, 樸英超, 羅 澤, 閻保平
1(中國科學院 計算機網絡信息中心, 北京 100190)
2(中國科學院大學, 北京 100049)
人口規模的增長和全球氣候的不斷變化對野生動物的生存環境產生極大的負面影響[1].了解動物的潛在棲息地是生態學、自然資源管理和保護的中心主題之一[2].物種分布模型利用動物出現的數據并結合出現點所在位置的多種生態位因子, 例如溫度、降雨、土壤、斜坡、植被指數等因子, 對物種分布進行建模, 進而預測物種在其它特定地區或者在相同區域不同時間出現的概率值, 概率值的大小反應了物種對該地區環境的偏好程度.因此物種分布模型可以用來分析物種與環境變量之間的關系, 尤其是氣候變化條件下對物種潛在棲息地分布的影響[3], 還有助于研究入侵物種潛在的棲息地擴張范圍[4,5]或者瀕危物種潛在棲息地的萎縮[6].在動物出現數據獲取方式上, 傳統的方式是通過野外調查、各標本館的標本數據、各類公開的文獻記載等方式獲取有用的數據, 這種方式獲取的單個物種尤其是稀有物種的有效樣本非常少且容易存在誤差,尤其是地理位置精度不高, 例如有些較早記錄沒有經緯度信息, 只存儲所在位置的縣名, 甚至是所在的省市.近年來隨著各種先進數據采集設備的廣泛應用, 例如Argos, GPS和無線追蹤器等, 使得我們可以對單一物種獲得大量的有效的動物出現數據, 有利于我們提取更多的有效訓練樣本從而使用更加復雜的模型對其進行建模和預測.
最大熵模型(MaxEnt)[7]自從提出來以來就被廣泛應用來預測各種動植物的潛在分布或者分析入侵物種的適合生長區.Gibson[8]等人利用MaxEnt模型來預測稀有物種鸚鵡在澳大利亞西南部的潛在分布, 通過模型得到鸚鵡喜歡海拔相對較高, 遠離河流, 有植被覆蓋的地形相對平緩的棲息地.吳慶明[9]等人利用丹頂鶴2012-2013年營巢分布點和環境特征變量, 通過MaxEnt分析丹頂鶴在扎龍保護區的潛在棲息地分布情況.Hu[3]等人利用 MaxEnt對地形, 氣候, 生境 (土地覆蓋)和人為影響這些變量進行建模, 預測瀕危候鳥在五個不同地區的潛在越冬棲息地以及在不考慮物種傳播的基礎上分析將來氣候變化對越冬棲息地的影響.MaxEnt模型的最大好處是只需要物種在研究區域明確出現的數據以及出現位置的環境信息就可以有效的進行建模分析, 尤其在小樣本集的情況下比其它物種模型取得更好的效果.近年來隨著機器學習應用面的日益擴展, 越來越多的方法利用有/無物種出現數據建立機器學習模型來預測物種分布[6,10–14], 包括人工智能網絡(ANN)[12], 分類回歸(CART)[13], 隨機森林算法[14]等.Yoo[12]等人通過ANN對50個地點收集的13個生態位變量數據進行建模, 預測潮汐灘地的物種多樣性.基于生態位的方法來分析物種的潛在分布主要存在以下三個問題:1)將原始遙感數據聚合成離散的土地覆蓋類型或者植被覆蓋指數會導致新的分類誤差, 而且在轉換過程中大量其它可用的信息可能會丟失以及導致時間粒度和空間分辨率變大.2)對原始遙感影像進行分類從而獲得相應的生態位因子, 這個過程本身就需要花費大量的計算和人力成本.盡管中尺度的遙感影像是免費公開的, 但是對影像進行分類需要有一定的相關領域知識以及相關的計算過程.3)傳統方法在樣本選擇上往往局限于少數一些觀察點, 在時間跨度和空間范圍上都有一定的限制, 適合于棲息地范圍分布地比較集中的物種.斑頭雁夏季繁殖在高原湖泊, 越冬則在低地湖泊、河流和沼澤地等, 主要以禾本科和莎草科植物的葉、莖、青草和豆科植物種子等植物性食物為食.因此影響斑頭雁潛在分布的主要因素有植被情況, 湖泊河流分布和溫度等.我們可以從遙感影像中提取植被情況和湖泊河流分布情況, 以及從氣象站中獲取溫度數據, 因此本文直接以遙感圖像作為卷積神經網絡模型的輸入, 避免了傳統生態位模型中提取特征的過程, 然后結合溫度對斑頭雁的出現數據進行建模.
本文首先利用斑頭雁的軌跡數據, 結合Landsat遙感影像來獲得空間和時間都跨度大的有效訓練樣本,從而解決傳統數據樣本少的問題.由于斑頭雁每年都會在越冬區和繁殖區之間進行來回遷徙, 我們通過DBSCAN聚類算法對軌跡數據進行聚類來發現其在整個年度活動過程中的停留區, 從停留區提取的數據來標記遙感影像數據的正(出現)樣本, 避免遷徙飛行過程中的數據產生的干擾, 能更加符合斑頭雁的實際棲息地環境;其次, 設計一種多維卷積神經網絡(MCNN)結構, 利用1-D卷積和2-D卷積操作來分別從溫度序列數據和遙感影像圖片提取特征從而進行訓練并預測斑頭雁在青海湖地區的潛在棲息地.
1 基于 M-CNN 的棲息地預測
本文的系統主要分為兩步(如圖1所示):1)正/負樣本提取, 斑頭雁是遷徙物種, 每年都會進行春季和秋季遷徙, 越冬區和夏季活動區距離很遠, 相差一兩千公里, 導致采集到的原始GPS數據覆蓋范圍很廣(如圖2),直接將所有GPS點所在的位置都劃為正樣本顯然不符合斑頭雁實際情況.2)模型訓練和預測.
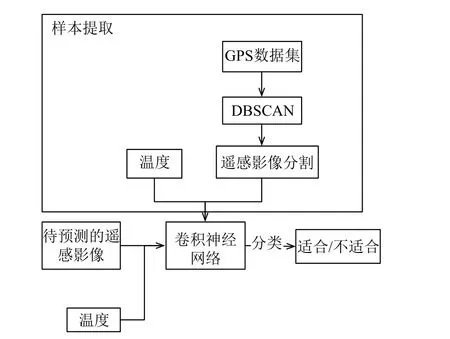
圖1 基于 CNN 的棲息地預測算法
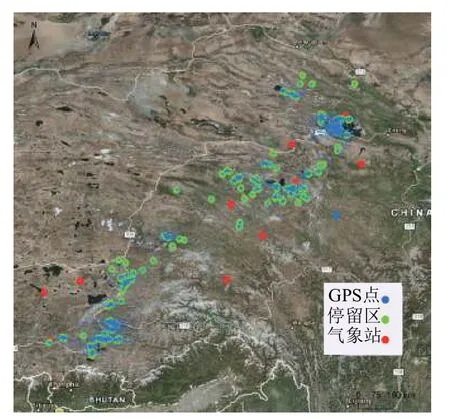
圖2 藍色點為采集的斑頭雁GPS數據點;綠色點為基于DBSCAN的斑頭雁軌跡數據聚類結果, 表示斑頭雁的棲息地;紅色為NOOA上離這些棲息地最近的10個氣象站.
1.1 正/負樣本提取
DBSCAN[15]是一種典型的基于密度的聚類算法,它將在給定半徑的鄰域中包含的點大于給定的最小值的點作為核心點, 通過迭代查找的方法找到各個類簇所包含的所有密度可達的點.斑頭雁的運動軌跡無法連續記錄下來, 而是由一系列離散的采樣點組成,traj=(p1,p2,···,pn).每個采樣點用一個三元組表示,即:pi= (xi,yi,ti), 其中xi,yi分別表示采集點所處的經度和維度,ti表示該采樣點的采集時間(如表1).我們首先利用DBSCAN對斑頭雁的軌跡數據點進行聚類, 將每一個類簇作為斑頭雁的一個棲息地(如圖2綠色點);然后我們下載斑頭雁在每個棲息地內的停留時間對應的 Landsat 5 TM 遙感影像, 并將每張遙感影像按照16×16像素的大小分成二維的圖片, 將和停留區有重疊的圖片作為正樣本, 否則為負樣本.
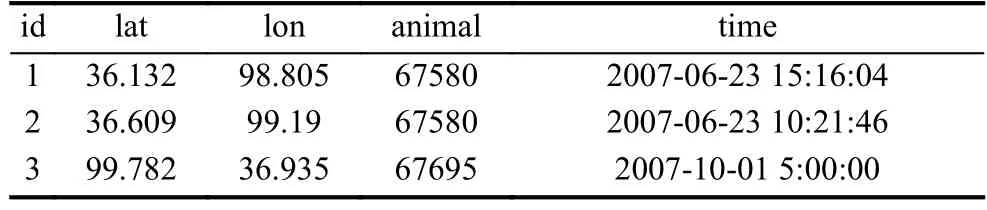
表1 lon 和 lat表示經緯度, animal表示采集的動物的編號, time采集時間
1.2 M-CNN網絡結構
CNN是一種主要由卷積層、池化層、全連接層和激活函數組成的多層深度神經網絡模型, 采用卷積核共享參數, 減少了訓練的參數.圖3為本文的M-CNN網絡結構.2-D卷積的輸入數據為6通道的16×16像素塊大小的Landsat 5 TM影像和1-D的卷積輸入為15×3大小的溫度序列數據, 隨后圖片數據通過三層卷積, 兩層最大池化層, 溫度數據經過兩層卷積層, 然后將兩個卷積過程獲得的特征拼接起來輸出到兩層全連接層和兩層Dropout層, 最后輸出到softmax分類器.卷積神經網絡的第一層卷積層的濾波器主要用來檢測低階特征, 比如邊、角、曲線等, 越往后的卷積層檢測更高階的特征.我們在第一層分別使用多個不同尺寸的卷積核, 以獲得不同尺度的特征, 再把這些特征結合起來作為第一層卷積層的輸出來以獲得更好的低階特征.為了減少訓練過程中的內部協變量偏移(internal covariate shift), 我們在執行激活函數前加入了批量規范化 (batch normalization)操作[16], 使得輸出的各個維度的均值為0, 方差為1, 這也有助于提高模型的收斂速度和減少對Dropout的要求.
卷積層可以看成是輸入圖像/前一層特征圖與一個可訓練的卷積核進行卷積運算得到的結果, 例如第一個1×1的卷積成可以用如下表示:
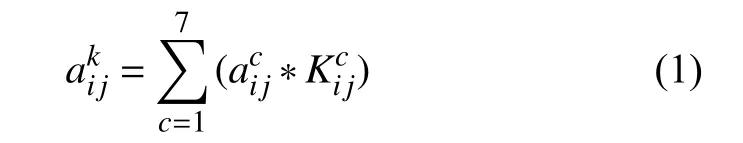
批量規范化操作如果將前一層的數據做規范化后直接進入下一層會改變前一層網絡所學到的特征, 因此作者引入了一對可學習參數γ和β, 使得整個批量規范操作如下[16]:
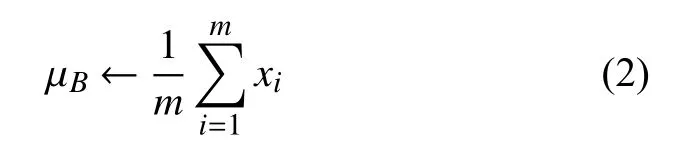
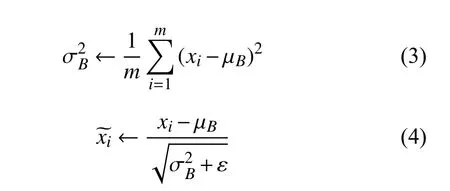
其中,m為批量訓練樣本的大小,ε是加入的噪聲.
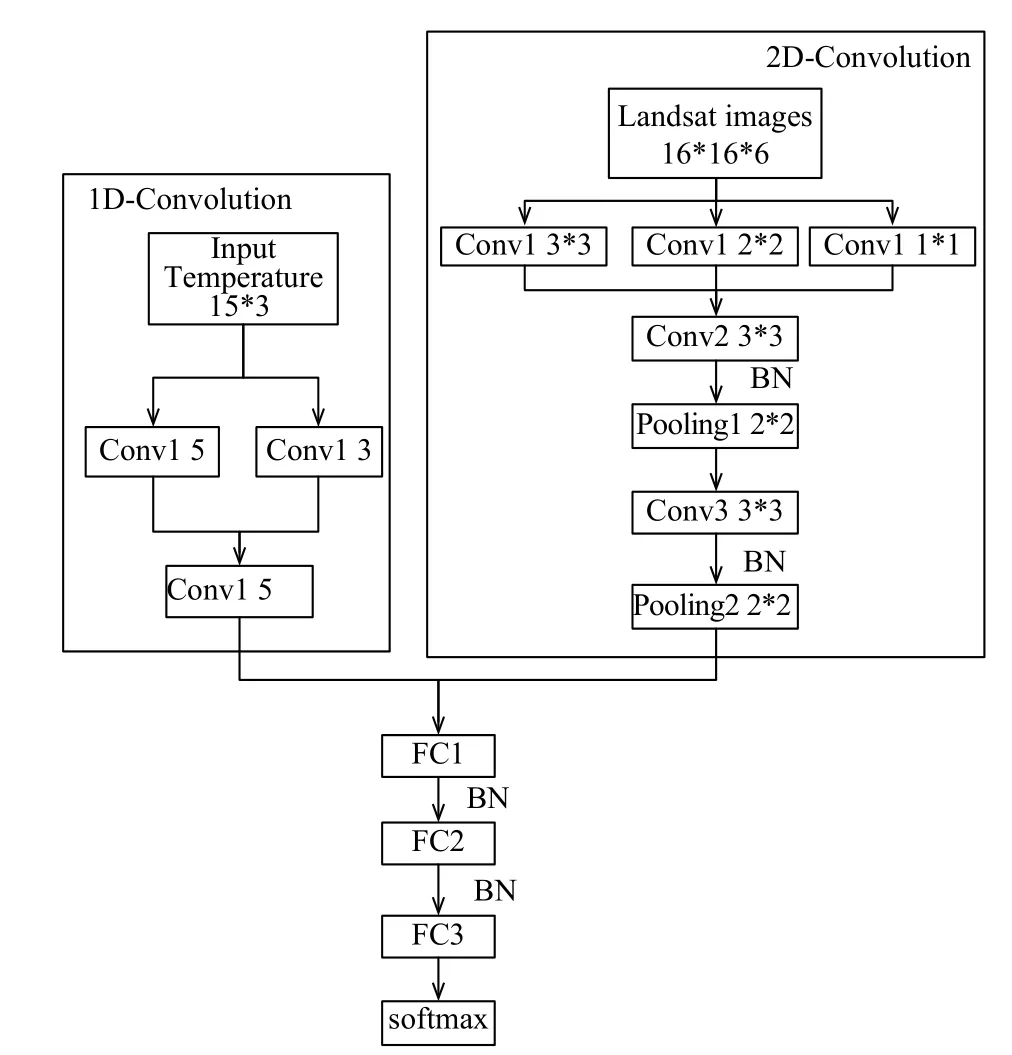
圖3 棲息地預測系統的 M-CNN 網絡結構, 其中 Conv 為卷積層, BN 表示 Batch Normalization, FC 為全連接層
池化層經常在卷積層后面, 能夠對卷積所輸出的圖像特征進行聚合統計.將上一層輸出的卷積特征劃分到若干個不重疊的大小為m×n的區域上, 最大池化就是用這m×n個位置上的最大值作為池化后的卷積特征而舍棄其它位置的值.這樣CNN不關注池化窗口內到底是在哪一個位置匹配上了, 只關心是不是有匹配上.池化層在一定程度上還能降低網絡的復雜度, 減少計算量和降低過擬合.
Dropout指在每次批量訓練模型時以一定的概率隨機讓網絡中某些隱含層節點的權重暫時不工作, 在下一輪訓練時這些神經元又會恢復, 然后再次以一定的概率隨機選擇部分神經元暫時不工作.由于每次輸入的批量樣本進行權值更新時, 隱含節點都是以一定概率隨機出現, 從而使得權值的更新不再依賴于有固定關系隱含節點的共同作用, 相當于網絡結構在每次訓練過程中都發生變化, 避免了對某一局部特征的過擬合.
2 實驗和分析
2.1 實驗數據
本文實驗數據來主要來自青海湖地區的29只斑頭雁, 它們從2007年到2010年的在青海湖區域和錯愕湖區域之間來回遷徙, 每只斑頭雁攜帶有一個便攜式遙感設備, 能夠通過Argos衛星和GPS接收器進行定位和發送數據, 采集間隔時間設為2小時, 采集數據的存儲格式如表1所示, 總共采集到60 161個GPS點(如圖2藍色的點).斑頭雁的棲息地主要分布在從青海湖地區到斑頭雁越冬區沿途經過的地方, 通過DBSCAN聚類結果(如圖2)我們可以看到主要包括哈拉湖, 青海湖, 冬給措納湖, 扎陵湖, 鄂陵湖, 曲麻萊縣, 隆寶灘自然保護區, 扎木措濕地, 納木錯湖, 羊卓雍錯, 拉薩河, 雅魯藏布江等區域, 其中青海湖和扎鄂陵陵湖是主要的繁殖區和換羽區, 羊卓雍錯, 拉薩河,雅魯藏布江是主要的越冬區.
本文使用的Landsat 5 TM的遙感影像從USGS(https://earthexplorer.usgs.gov/)官網下載.我們下載所有研究區域內從2007年到2009年的遙感影像, 通過分析其自帶的元數據文件, 移除云層覆蓋率大于20%或者影像時間前后十天內沒有出現過斑頭雁的遙感影像, 剩下的影像用來提取訓練數據, 然后下載2010年8月和2011年2月青海湖及其周圍區域的4幅云層覆蓋率小于20%的遙感影像.每幅遙感影像有 7個波段, 我們使用其中的 B1, B2, B3, B4, B5和B7六個波段的值, 每個像素點的分辨率為30 m, 我們樣本的大小為 16×16×6, 對應的分辨率為 480 m, 基本上和GPS設備定位的最大誤差相接近.本文使用了從青海湖到西藏越冬區沿途的10個包含有2007年到2010年溫度數據的氣象站(如圖2所示), 所有溫度數據從NOOA(http://gis.ncdc.noaa.gov)網站上下載, 每個氣象站每天都保存最高溫度、最低溫度和平均溫度.針對每幅遙感影像, 我們將離它最近的氣象站的當前遙感影像時間的前后7天(包括遙感影像當天, 共15天)的平均溫度、最低溫度和最高溫度作為遙感影像的溫度特征.
經過2.1部分的正/負樣本提取后, 我們總共得到26 023張 16×16×6大小的圖片, 其中正樣本 8696張,負樣本 17 327張.為了使正負樣本的數量更加平衡, 我們對每張正樣本分別進行左旋轉90度和又旋轉90度的數據, 并隨機抽取2000張加入樣本集中, 并按9:1比例分成訓練樣本和測試樣本.因此, 最后我們共得到28 023張圖片, 正樣本 10 696張, 負樣本 17 327張, 對應的訓練樣本和測試樣本分別是25 221張和2802張.
2.2 模型訓練
卷積神經網絡的訓練主要采用梯度下降法, 包括批量梯度下降(BGD)、隨機梯度下降(SGD)和小批量梯度下降(MGD).其中, 批量梯度下降法每次迭代需要所有樣本參與運算, 能夠尋找到全局最優解, 但是收斂速度比較慢.隨機梯度下降法則每次迭代利用一個樣本來更新參數, 計算成本低, 收斂速度快, 缺點是單個樣本可能會帶來很多噪聲, 使得每次更新不一定朝著全局最優的方向, 容易造成收斂到局部最優解.
本文采用的小批量梯度下降法可以看成是前兩種方法的一種折中, 每次迭代計算一小批樣本的梯度來更新參數的權值, 這樣能夠在盡可能尋找到全局最優解的同時加快模型的收斂速度.為了防止過擬合, 利用L2正則化對網絡參數進行約束, 并在全連接層的訓練過程中引入了Dropout策略, 即每次迭代中隨機放棄一部分訓練好的參數[17].在模型訓練初期, 可以使用較大的學習率來加速收斂, 當訓練集的損失下降到一定程度后就不再下降, 容易在一個局部范圍內震蕩.為了解決這個問題, 我們采用學習率衰減的方法, 學習率隨著訓練的進行逐漸衰減.整個模型的訓練參數如表2所示.
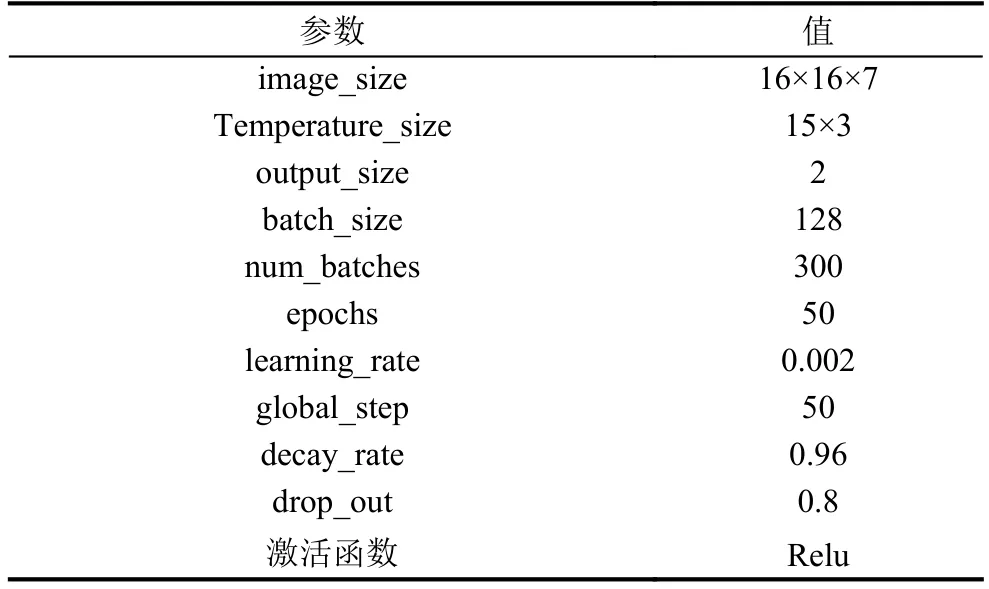
表2 CNN 模型訓練參數
2.3 實驗設置
我們設置了兩組實驗, 每組實驗都和傳統的兩個方法進行對比:基于灰度共生矩陣的特征提取的SVM分類(GLCM+SVM)和本文采用的網絡結構中去掉1-D卷積部分的CNN網絡(CNN).
對于GLCM+SVM模型, 我們將圖片的灰度級別設為64, 每個點選取8組不同的偏移量來計算灰度共生矩陣.由于灰度共生矩陣的數據量較大, 一般不直接作為區分紋理的特征, 本文選取常見的基于灰度共生矩陣計算出來的統計量來作為SVM模型的輸入特征,包括均值、相關性、對比度、能量、均勻性和最大相關系數等.
第一組實驗, 我們分別訓練各個模型, 然后利用二分類常見的三個指標:總體準確率、F1值和曲線下面積 (Area Under the Curve of ROC, AUC)[3]來評價各個模型的性能.在第二個實驗中, 我們利用訓練好的模型來預測青海湖周圍斑頭雁潛在的棲息地情況.青海湖夏天是斑頭雁重要的繁殖地, 而冬天都往南遷徙, 很少有斑頭雁停留[13], 因此我們分別選取夏季(8月)和冬季(2月)兩個不同時期的遙感影像來分析各個模型的預測結果.
2.3 實驗結果
本文實驗環境為 12核 Intel(R) Xeon(R) CPU E5-2620, 無 GPU, 內存 64 GB, 編程語言 python2.7, 采用Tensorflow-0.9.0深度學習框架[18]進行CNN神經網絡訓練學習.表3顯示了各個模型在訓練數據集上的結果, 可以看出我們設計的網絡結構在各個指標上都取得比較好的成績.和卷積神經網絡相比, 傳統的GLCM+SVM在提取特征上沒有優勢.
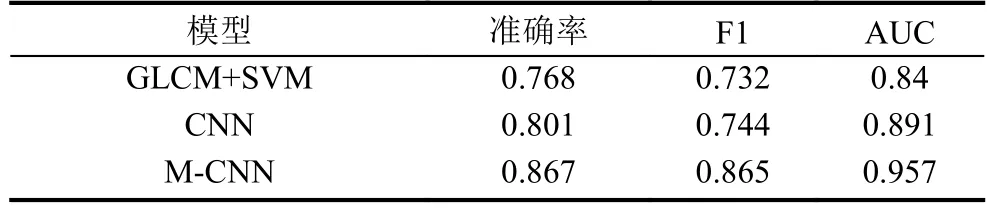
表3 3個模型在訓練數據集上的分類結果
我們選取2010年8月份和2011年2月份的青海湖及其周圍的遙感影像進行預測, 預測的斑頭雁潛在棲息地分布如圖4所示.對于8月份(圖4第一列)的預測結果, GLCM+SVM模型在沿湖區域基本上沒有概率特別高的區域, 預測的潛在分布都是在湖面上;CNN和M-CNN模型都會將沿著湖邊的部分或者大部分區域標記為概率非常高的區域, 標記面積MCNN模型會略大于CNN模型;各個模型在湖面的處理表現差異比較大, 基本上都將湖面標記為潛在分布區, 其中CNN模型會將部分標記為低概率(顏色更深),其它兩個模型基本都是標記為高概率.8月份, 在青海湖地區對于繁殖成功的斑頭雁主要活動是帶領幼鳥覓食, 其它斑頭雁則進行換羽或者在儲備食物做秋季遷徙前的準備.這些任務都要求斑頭雁在食物更豐富、外界因素干擾更小的河口和支流濕地去活動, 這些地方都在離湖面一段距離的地方.因此M-CNN模型將青海湖離湖較近及其離湖面一段距離內的地方都標記為高概率區域, 更加符合實際情況.
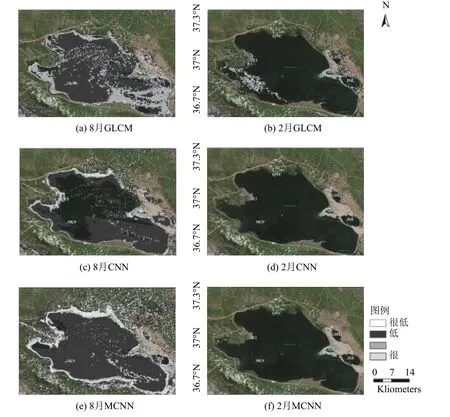
圖4 從上到下三行分別是GLCM+SVM、CNN和M-CNN模型;第一列是2010年8月份的預測結果, 第二列是2011年2月的預測結果.很低、低、高、很高表示斑頭雁出現的概率, 其中很低用透明色表示, 即顯示背景.
2月份斑頭雁基本上還在西藏或者其它越冬區, 或者在往青海湖遷徙的前期, 青海湖上還基本上沒有適合斑頭雁的地方.從圖4第2列中可以看出來三個模型都錯誤的將少部分區域標記為潛在分布區, 錯誤標記的面積大小GLCM+SVM>CNN>M-CNN, 也可以看出我們模型準確度更高.
3 結論與展望
本文利用斑頭雁的軌跡數據, 結合Landsat遙感影像, 提出一種基于M-CNN模型的候鳥棲息地預測方法, 利用1-D卷積和2-D卷積分別從溫度序列和遙感影像中提取特征.有別于傳統的方法從遙感影像中計算生態位值作為分類器的特征, 卷積神經網絡能夠自動從圖片中進行學習, 直接處理原始遙感影像來實現對斑頭雁潛在棲息地的預測.基于生態位因子模型一般都是研究大范圍區域內適合某個物種的區域分布,基于遙感影像建模能夠比它提供更高空間分辨率和更細時間粒度的潛在分布結果, 有助于更好的了解物種的分布和更好的進行保護.由于遙感影像數據容易受到云層的影響, 當研究區域被云覆蓋住時, 就無法提取有效數據, 而遙感影像周期又比較長, 因此如何減少云覆蓋的影響是今后研究的重點.
猜你喜歡
課堂內外·初中版(科學少年)(2025年1期)2025-02-28 00:00:00
課堂內外·初中版(科學少年)(2025年2期)2025-02-28 00:00:00
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
英語世界(2023年10期)2023-11-17 09:18:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科學大眾(中學)(2019年3期)2019-05-17 10:04:30
汽車觀察(2018年10期)2018-11-06 07:05:26
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
