卷積神經網絡雙目視覺路面障礙物檢測
2018-10-24 02:29:58馬國軍王亞軍
計算機工程與設計 2018年10期
關鍵詞:檢測
胡 穎,馬國軍,何 康,王亞軍
(江蘇科技大學 電子信息學院, 江蘇 鎮江 212003)
0 引 言
傳統立體匹配算法[1]有SAD/SSD[2]、Adapt weight[3]等基于像素灰度值相似度的算法以及歸一化互相關(normalized cross correlation,NCC)[4]、Gradient[2]和Census[5]變換等基于像素灰度提取特征相似度的算法,這些算法對紋理不明顯的路面場景匹配精度差。卷積神經網絡(convolution neural network,CNN)[6]是一種數據驅動型算法,能從大量的樣本數據中自動提取圖像中多種隱性特征,因此得到廣泛應用。在立體匹配方面,文獻[7]設計一種孿生結構MC-CNN,應用于圖像塊的相似度度量,全連接層的采用極大地增加了網絡參數,有效提取圖像對的深度信息,但由于卷積層數較少,無法提取深層特征;文獻[8]改進MC-CNN孿生結構,增加卷積層數并使用支持向量機(support vector machine,SVM)作為網絡輸出層,應用于雙目視差評估,取得較好的精度。
在障礙物檢測方法中,文獻[9]采用數字高程圖(di-gital elevation model,DEM)的方法實現障礙物檢測,具有較好的魯棒性,但需要對環境進行三維重建,計算復雜,不適合車載計算機實時演算;文獻[10]采用光流法檢測路面運動障礙物,但無法檢測靜止的障礙物;文獻[11]采用V視差法實現障礙物檢測,該方法計算簡單,但在道路信息較少的場景中,道路直線提取會受到干擾,降低了障礙物檢測效果。
本文提出一種利用卷積神經網絡的路面障礙物檢測方法,以解決傳統方法在匹配精度差,檢測算法穩定性與魯棒性差等問題。首先,設計一種孿生卷積神經網絡用于生成立體圖像對的視差圖;其次,提出道路直線自適應閾值提取算法,以精確提取V視差圖中道路直線;最后,逐個判斷各個像素點是否為障礙物點。
1 視差計算
在局部匹配方法中,NCC、Gradient和Census變換等只提取圖像中的人工特征,進行匹配代價的計算,CNN能夠自動提取圖像中多個隱性特征并計算匹配代價,從而獲得更高精度的視差圖。
1.1 網絡結構設計
本文設計如圖1所示的孿生網絡結構,其左右分支參數共享。該孿生網絡結構由特征提取子網絡(L1-L8)和特征分類子網絡(L9-L10)兩部分組成。特征提取子網絡左右分支能夠分別從輸入的圖像方塊和圖像長條中提取對應的特征描述;特征分類子網絡將提取的左右分支特征描述作點積運算,得到視差搜索范圍內待匹配像素點的相似性得分,然后作為softmax層的輸入得到視差概率分布。
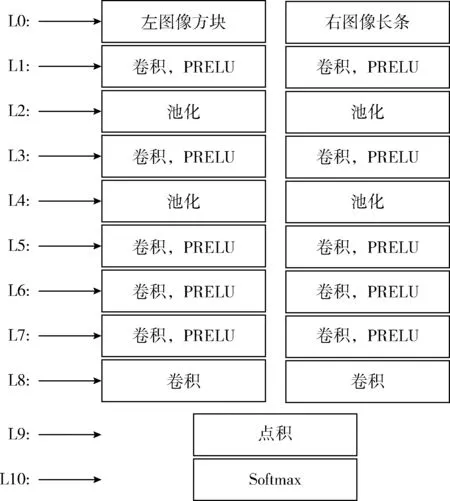
圖1 孿生卷積神經網絡結構
特征提取子網絡左右分支分均包含一個輸入層(L0),6個卷積層(L1,L3,L5,L6,L7,L8)和2個池化層(L2,L4)。卷積層采用大小為5×5,數量為32或64個卷積核提取各層信息;同時,使用Batch Normalization技術以弱化網絡對初始化的依賴,使得卷積神經網絡更容易訓練;最后在卷積層上使用PRELU激活函數,輸出卷積層結果。在L8卷積層中不使用激活函數是為了保留輸出的特征描述負值信息。在池化層中,采用最大池化方式,其中L2層采用9×9池化核,L4采用5×5池化核。最終,特征提取子網絡左分支輸出1×64維特征描述,右分支輸出201×64維特征描述。特征分類子網絡包含1個點積層(L9),1個softmax層(L10)。L9層將L8層提取的兩個特征描述對應各個視差作點積運算,得到視差搜索范圍內待匹配像素點的相似性得分,輸入softmax層得到視差范圍內視差概率分布。表1給出了卷積神經網絡結構的具體參數。
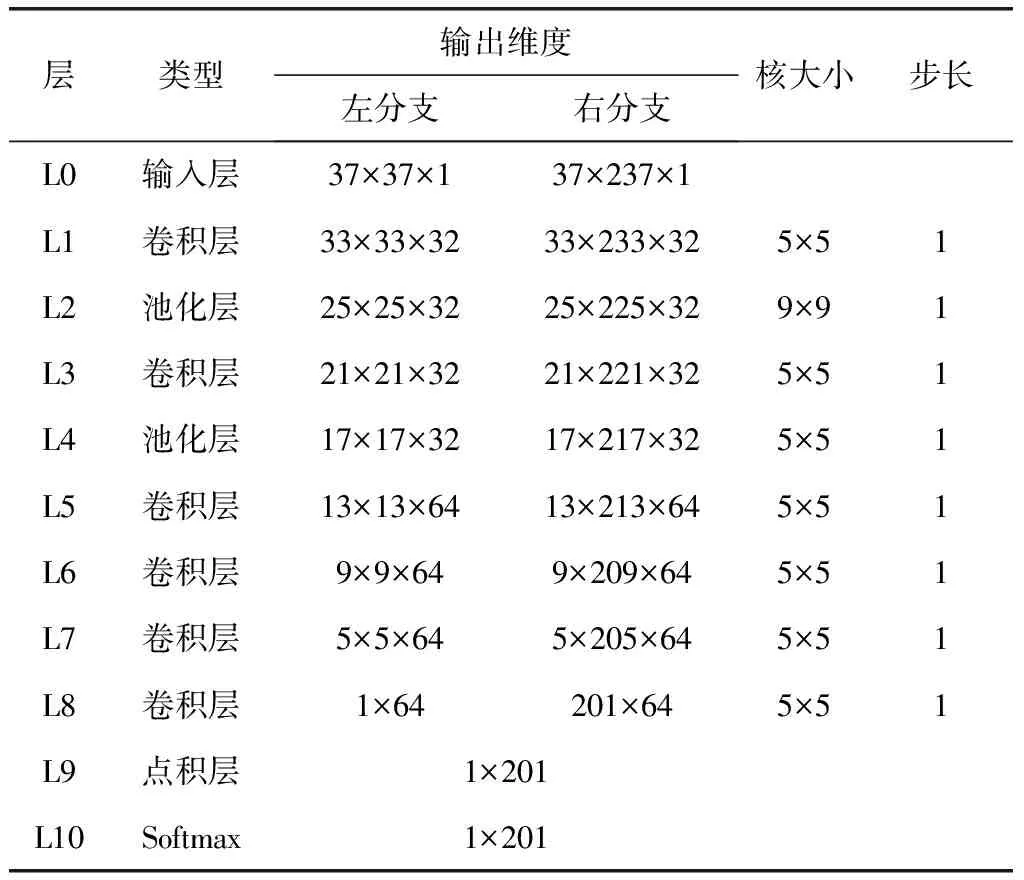
表1 孿生卷積神經網絡參數
局部匹配時,通常選擇像素點的局部支持窗口作為匹配單元,根據文獻[12]的對比實驗,選取37×37像素大小的窗口可以得到最優的匹配效果。針對KITTI數據集[13]的真實最大視差,設定視差搜索范圍為201像素,故輸入網絡右分支的圖像長條的大小為37×(201+37-1),即37×237像素。
1.2 卷積神經網絡的訓練
1.2.1 訓練集構建
(1)樣本裁剪
基于CNN的視差計算方法屬于局部匹配方法,要求輸入給CNN的數據為圖像局部方塊。本文使用KITTI雙目數據集中的圖像的分辨率為375×1242,不能直接輸入本文的CNN結構,需要將其進行相應的裁剪,步驟如下:
1)根據KITTI數據集中的真實視差數據,在左圖像中選取具有真實視差的像素點p,并記錄該點圖像坐標(xi,yi);然后提取以該像素點為中心的37×37的圖像方塊,如圖2(a)所示;
2)在右圖像中選取像素點q,其坐標為(xi,yi),并以q為中心選擇37×37的圖像方塊。根據視差搜索范圍,在右圖像中選擇以q為中心,圖像方塊右邊界左側大小為37×237的圖像長條,如圖2(b)所示。從而該圖像長條包含了視差搜索范圍內所有待匹配圖像方塊。
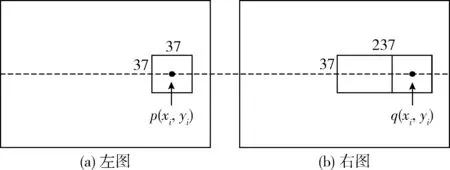
圖2 樣本裁剪
以此步驟,提取KITTI數據集中所有的圖像構建訓練集。選用KITTI數據集中200對圖像中160對圖像用于網絡訓練,由此方法提取的圖像塊共有14 248 394對。
(2)標準化處理
樣本裁剪后得到的訓練集中,原始數據范圍為[0,255],不能直接作為網絡的輸入,需要對數據進行標準化處理。利用式(1)將原始數據變換到[-1,1]范圍內,并以此作為網絡的輸入
(1)
其中
(2)
(3)
1.2.2 網絡訓練
網絡的輸出為softmax分類層,在訓練過程中需要對網絡權重w最小化互熵損失函數。針對本文的應用場景,對原始互熵損失函數進行了相應的修改,如式(4)
j(ω)=∑i,dipgt(di)lgpi(di,w)
(4)
其中
(5)
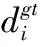
本文采用自適應矩估計的隨機梯度下降算法(Adam)[14]來優化式(4)的損失函數,并調整網絡參數,根據損失函數對每個參數的梯度的一階矩估計和二階矩估計,動態調整每個權值的學習速率,使得網絡權值平穩、迅速達到最優解。
1.3 視差計算
訓練良好的卷積神經網絡能夠有效提取左右圖像中各像素點的64維特征描述,分別記作SL(p)和SR(q),其中p和q表示為左右圖像中的點;將SL(p)與SR(q)作點積運算得到圖像對相似性得分,然后將該相似性得分取相反數作為圖像對之間的匹配代價CCNN(p,d)
CCNN(p,d)=-s(
(6)
式中:s(
最后,采用勝者為王(winner-take-all)策略[15],在視差搜索范圍內,選擇匹配代價最小的點作為匹配點進行視差選擇,進而生成視差圖D
(7)
2 障礙物檢測
V視差法通過累計視差圖的同一行中視差值相同點的個數,將原圖像中的平面投影成一條直線。在障礙物檢測問題中,路平面被投影成V視差圖中的一條斜線,即路面檢測由平面檢測轉化成直線檢測。通過引入直線檢測算法,提取V視差圖中的路面直線,即可準確獲取路面在圖像中的區域,進而判斷非路面區域為障礙物區域。
2.1 道路直線提取
針對傳統的V視差法在道路信息較少,且存在較多較大障礙物干擾時,不能準確提取道路直線的問題,本文提出了道路直線自適應閾值提取算法。
(1)在視差圖的列方向上,路面像素值均勻變化,而障礙物區域,像素值基本不變,本文采用Prewitt算子計算視差圖列方向的梯度,并保留梯度為負值位置的視差,以濾除障礙物像素點,如式(8)
D(G≥0)=0
(8)
其中
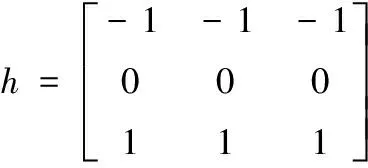
(9)
G=D?h
(10)
其中,h為Prewitt算子,D為原視差圖,G為視差圖列方向梯度,符號?表示卷積。
圖3(a)為原始視差圖,濾波后如圖3(b)所示,可以看出圖像中大部分的障礙區域被濾除并保留了大部分的路面信息。

圖3 道路直線提取自適應閾值算法過程
(2)對濾波后的視差圖計算其V視差圖I1,如圖3(c)所示。由于路面為平面,在視差圖中每一行的視差值相等,而在V視差圖中表現為每一行的最大值,搜索I1中的每一行最大值并保留,其余像素點灰度值置0,從而獲得V視差圖I2,如圖3(d)所示。
(3)為去除攝像機遠端非路面像素點的干擾,設定閾值T,將I2中大于T的像素灰度值置1,其余置0,生成僅包含道路信息的V視差二值圖I3,如圖3(e)所示,閾值T的計算公式為
(11)
式中:xi為I2中各像素值;N為I2中像素總個數;1{xi≠0}表示xi不等于0時取1,否則取0。
(4)運用hough變換提取I3中路面直線,如圖3(f)中紅線所示。
2.2 障礙物區域判定
在V視差圖中,道路直線是路面投影,道路直線上方的點是障礙物投影。將視差圖中每個像素點投影到V視差圖中,通過判斷其是否在道路直線上,從而檢測視差圖中像素點是否為障礙點,步驟如下:
(1)計算道路直線在V視差圖中圖像坐標的斜率k和截距b;
(2)按照光柵掃描法,從下往上從左往右逐點掃描視差圖D(x,y,d),對每個像素點計算f=kd+b;
(3)若(f-y)>T1,則視差圖中像素點投影在V視差圖中高于道路直線,即高于路面,則該像素點為障礙點,其中,T1為去除路面不平現象而設定的閾值;
(4)重復步驟(2)、步驟(3),直至完全掃描視差圖,得到圖像中障礙物區域。
3 實驗結果與分析
為驗證本文方法,使用Torch深度學習框架和MATLAB2015a軟件進行仿真實驗。硬件平臺為Intel core i5-6500 CPU、12 GB內存和NVIDIA GTX 1070,使用KITTI雙目數據集中的200對圖像,包含鄉村、城市、高速公路等多種道路場景。實驗時,選取其中160對圖像作訓練集,40對圖像作測試集。
3.1 視差圖生成實驗
為了驗證本文孿生卷積神經網絡計算視差圖的有效性,在測試集選取21組不同場景的圖像,其中鄉村、城市、高速公路場景各7張,進行測試。圖4列舉部分場景的測試結果,圖4(a)、(c)、(e)為原始圖像;圖4(b)、(d)、(f)為計算的視差圖。

圖4 部分場景視差計算結果
采用誤匹配像素百分比(percentage of bad matching,PBM)的評價,估算出的視差圖與標準視差圖的誤匹配率,并與NCC、Gradient、Census視差計算方法進行對比。表2為21組場景的平均誤匹配像素百分比,本文方法的平均PBM為4.29%,遠低于NCC的16.78%、Gradient的37.31%、Census的12.16%;圖5為21組場景誤匹配像素百分比分布,本文方法PBM的標準差為0.0207低于NCC的0.0832、Gradient的0.1005以及Census的0.0569。表明本文視差計算方法的穩定性與魯棒性更好。

表2 不同方法平均誤匹配百分比
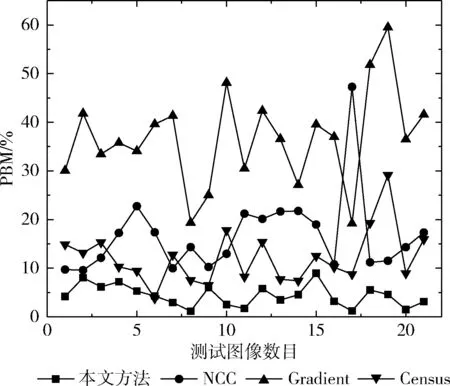
圖5 不同方法誤匹配百分比
3.2 障礙物檢測實驗
圖6列舉了鄉村、城市、高速公路場景使用本文V視差法的障礙物檢測結果,其中,閾值T1=5。圖6(a)、(c)、(e)為原圖像,圖6(b)、(d)、(f)為障礙物檢測圖,圖中亮色區域為障礙物區域。
為進一步的評價本文V視差法,與傳統V視差法在召回率和精確率兩個指標上進行比較。召回率表示障礙像素點被預測正確的比率;精確率表示預測為障礙像素點是真障礙點的比率,計算公式如下
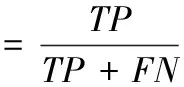
(12)
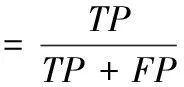
(13)
其中,TP表示正確的正檢測結果,FP表示錯誤的正檢測結果,FN表示錯誤的負檢測結果。本文V視差法與傳統V視差法在召回率和精確率的對比如圖7所示。
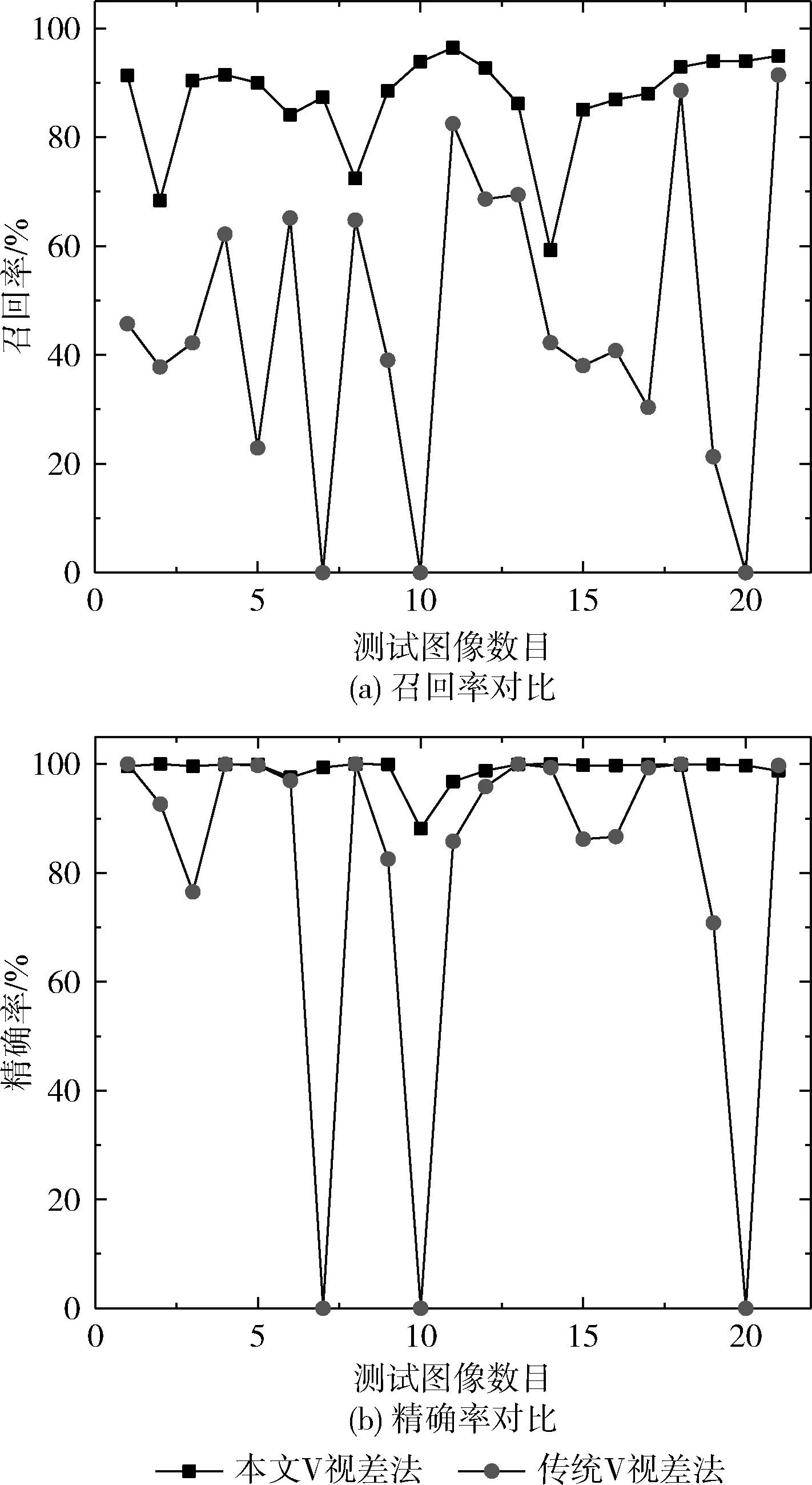
圖7 召回率與精確率對比
本文的V視差法在所有的場景中均能夠有效地識別出障礙區域,且召回率和精確率要優于傳統V視差法,其標準差分別為0.0901和0.024,小于傳統V視差法的召回率與精確率標準差0.2667和0.0884,表明本文V視差法檢測障礙物的可靠性。
3.3 閾值T1對障礙物檢測結果影響
在障礙物檢測過程中,閾值T1是為了去除真實路面不平的現象,閾值T1的選取對檢測效果有較大影響。本文對T1在[0,30]范圍內進行取值實驗,計算其召回率和精確率,由表3可知,召回率隨著閾值T1的增大逐漸的減小,精確率在閾值T1=5時為99.05%,并隨著閾值的增大緩慢增大。綜合考慮,當閾值T1=5時障礙物檢測效果最好。
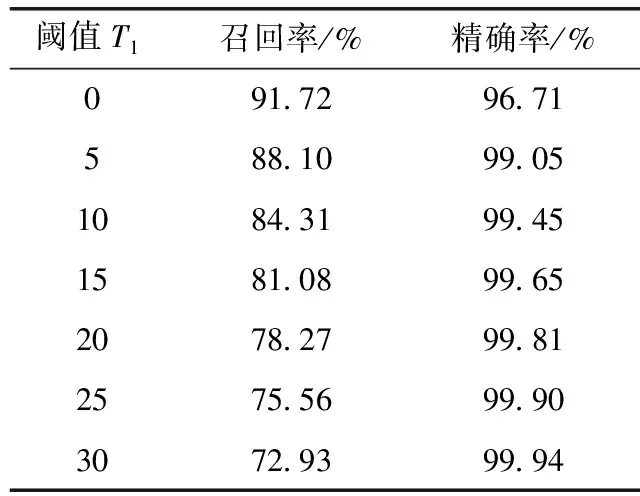
表3 不同閾值T1召回率與精確率
4 結束語
本文設計一種孿生結構的卷積神經網絡生成視差圖,在傳統V視差法基礎上提出道路直線自適應閾值提取算法,利用KITTI數據集對該方法進行測試。實驗結果表明,該方法具有如下優勢:
(1)孿生卷積神經網絡在處理立體圖像對時,可提取單個像素點的64維特征,用于匹配代價計算,避免了人工特征的局限性。相比于傳統的視差生成方法,具有更高的精度。
(2)本文V視差法通過道路直線自適應閾值提取算法有效提取道路直線,從而完成路面障礙物檢測,相較于傳統V視差法具有較高的召回率、精確率和可靠性。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
