彭圳生,鞏青歌,高志強,段妍羽,曾子賢
(1. 武警工程大學 信息工程學院,陜西 西安 710086;2. 軍隊大數據與云計算重點實驗室,陜西 西安 710086)
0 引言
[1][2]。
相對于有著成熟研究的Web正文信息抽取技術[3-5],新聞標題抽取技術的研究相對較少,其主要難點在于: 對于大量的復雜非規范網頁來說,無法根據某種統一的網頁結構或規則進行統一抽取,且新聞標題的特征不像正文一樣明顯[6],在抽取的過程中,很容易被埋沒在正文中或者被遺漏,無法很好地與正文分開抽取。然而,只有從網頁中準確抽取出新聞標題,才能為后期信息檢索和文本挖掘提供準確依據。
1 相關工作
雖然新聞標題抽取是Web信息抽取中的一個重要課題,但這方面的研究目前還比較少[7],尤其對于復雜不規范的網頁結構,尚未提出一種通用的新聞標題抽取方法。目前對新聞標題的抽取技術主要集中在: ①基于網頁規則[5,8-12]方法;②基于機器學習[1,7,13-17]方法;③基于相似度[18-21]方法。
針對基于網頁規則的新聞標題抽取技術研究,Zhang[9]等通過XPath規則自動抽取Web論壇內容,并通過統計和預測的方法自動生成抽取規則。Wang[10]等提出一種基于DOM樹的提取方法,將DOM樹轉化為STU-DOM樹,通過信息提取算法自動準確地從HTML文檔中提取有用的相關內容。
針對基于機器學習方法的新聞標題抽取技術研究,朱青[13]等將HTML格式及DOM樹結構等信息引入機器學習抽取過程中,實現對新聞標題的抽取。羅永蓮[7]等提出一種基于新聞特點與網頁標記信息的方法,將網頁標記和文本相似度作為機器學習的特征來提取新聞標題。
針對基于相似度的新聞標題抽取技術研究,李國華[18]等利用網頁標題和正文信息之間的關系,通過計算句子之間的相似度和對應權值確定新聞標題。Mohammadzadeh[21]等人將每個文本片段的內容與HTML文件中的標題進行比較,并實現了四種類型的相似性比較方法。
隨著網頁結構日趨復雜,網頁元素日趨多樣,網頁噪聲內容逐步增多,按照網頁結構和HTML標簽編寫規則并維護模板的統一抽取網頁信息的方法愈來愈不可行。一方面,隨著HTML和CSS的分離,樣式特征很難具有區分性質,重新標注網頁訓練集,而后再重新訓練機器學習,模型代價巨大,基于樣式特征的機器學習方法已經不再適用;另一方面,由于網頁編寫規則不統一,不同網站編寫的隨意性很大,基于網頁DOM結構和XPath的信息抽取方法很難保證抽取效果。因此基于網頁規則及基于機器學習的抽取方法的實用性和適用性極大降低。
本文將基于密度的正文抽取方法引入新聞標題的抽取方法中,過濾網頁中非文本信息(例如,鏈接、圖片、視頻等非文本網頁噪聲)的干擾,提出一種基于密度和文本特征的語料判定模型,通過判定模型將網頁劃分為語料區和標題候選區,利用Text Rank算法[22]從語料中計算key-value權重集合,結合改進的相似度計算方法從標題候選區域抽取出新聞標題。最后通過多源數據適應性實驗和傳統算法的對比實驗,驗證了算法的適用性和有效性。
2 抽取算法實現
基于密度及文本特征的新聞標題抽取算法(title extraction with density and text-features, TEDT)實現主要由三部分構成: 語料判定模型(corpus decision model, CDM)進行區域劃分;通過TextRank算法構建key-value權重集合,獲得詞(key)和詞對應的權重(value);利用改進的相似度計算方法,從標題候選隊列中抽取新聞標題。
2.1 語料判定模型
對語料區和標題候選區進行劃分前,需要過濾Script、Style、Comment標簽,去除網頁特殊標記(包括空格)并只保留換行符“
”,最后再過濾掉不包含中文文本信息的行,處理后的HTML網頁源代碼中由含有中文的文本行和換行符“
”構成。新聞的正文區域和標題區域有如下特征。
(1) 正文一般在標題下方,兩者中間一般含有發布時間、新聞來源、編輯或者外部鏈接等信息。
(2) 新聞標題的文本特征表現為標題是對正文的概括,所以標題中關鍵詞多。此外,由于新聞標題的簡潔性,新聞標題含有的特殊符號少且一般沒有分句符。
(3) 正文具有連續性,即從正文開始到正文結束之間的內容一定為正文。正文部分(即使包含圖片、視頻和鏈接)文本行之間的間隔一般不超過10個換行符[5];文本行之間如果沒有間隔,則必定屬于正文。
(4) 正文的文本行一般較長且含有分句符。
(5) 正文的頭部和尾部的文本特征表現為阿拉伯數字比較多,例如發布日期、發布時間和瀏覽次數等其它特殊標記。由于已經不屬于正文部分,所以分句符較少,且一些特殊的詞出現的頻率較高,如,“來源”、“編輯”、“收藏”、“分享”、“評論”、“閱讀”等。
根據以上關于網頁中新聞內容密度分布特性和新聞文本特征的分析,總結出以下特征變量:
(1) 純文本數(Pure Text Number, PTN): 一個文本行中包含中文字符的個數。
(2) 句數(Sentence Number, SN): 一個文本行中句子的個數,按照“,。;!?”的標點符號劃分。
(3) 數字數(Numerals Number, NN): 一個文本行中所包含的阿拉伯數字的個數。
(4) 特殊字符數(Special Characters Number, SCN): 一個文本行中“: - |《》”符號和其他不同于分隔句子的符號個數。
(5) 特殊中文字符(Special Chinese Characters, SCC): 在正文開始前與正文結束后出現頻率較高的詞語,如“來源、編輯、收藏、分享、評論、閱讀”等。
(6) 中心間隔(Center Distance,CD): 當前文本行與上一個加入語料區文本行之間的換行符個數。
(7) 字符數(Characters Number, CN): 每個文本行中字符的個數,不管是漢字、英文還是符號都算作一個字符。
區域劃分的關鍵在于判別語料區和標題候選區,為保證所選取的語料都屬于正文,并在進入標題候選區之前語料選取判停,我們引入了風險因子,如式(1) 所示。
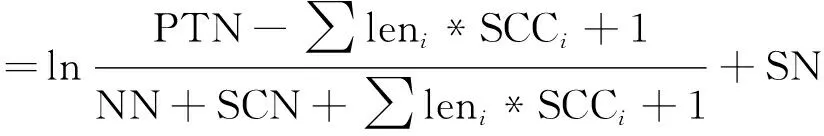
(1)
其中,α表示準備加入到語料區的文本行的權值,PTN表示該文本行的純文本數,∑leni*SCCi表示該文本行中所出現的第i個特殊中文字符數與該字符長度乘積的和,NN表示當前文本行中出現阿拉伯數字的個數,SCN表示當前文本行中出現的特殊字符的個數,SN表示當前文本行中分句符的個數。以上所有變量均有可能為0,因此ln中的分子、分母同時加上調節常量1。
風險因子ln部分的分母NN+SCN+∑leni*SCCi+1體現為: 加入語料庫中的文本行中,如果當前文本行中出現的阿拉伯數字、特殊字符數和特殊中文字符所占比重越大,則越有可能不屬于正文,ln部分的分子PTN-∑leni*SCCi+1體現為,加入語料庫中的文本行中,如果純文本數越多,特殊中文字符所占比重越小,則該行越有可能屬于正文。此外,當前文本行中分句符的個數SN體現為,如果加入語料區中的該行中含有的分句符越多,其越有可能屬于正文。
根據風險因子的計算公式,當α大于0時,將對應文本行加入語料區,當α小于0時可以認為選取的語料不屬于正文。結合正文連續性的特征,進一步得到語料判定模型(Corpus Decision Model, CDM),如式(2)所示。
(2)
其中,CDMi是對加入語料庫的第i個文本行的判斷值,CDi表示當前加入語料區的文本行的中心間隔,即第i行與前一個加入語料區的文本行之間換行符“
”的個數,CNi表示第i個文本行中字符的個數;當CDi為0且CNi不為0時,CDMi的判定值為1,表明在文本行與文本行之間沒有間隔且加入語料區的文本行不為空行的情況下,該文本行一定屬于語料區;當CDi≥10或CNi為0時,CDMi的判定值為0,表明當前文本行與其加于語料區中的上一文本行間隔距離大于10或者加入語料區的當前文本行為空行的情況下,該行一定不屬于語料區;當0算法1CDM區域劃分算法偽代碼
程序輸入: HC(Html Code)
程序輸出: corpus, titleCandidateQueue
初始化變量
1: Corpus = []
2: titleCandidateQueue = []
3: HC←removeScript/Style/Label(HC)
初始語料選擇
4:Forall textLine in HC
5: PTN←chineseNumber(textLine)
6:EndFor
反向判定
8:FortextLine in HCstart
9: PTN←ChineseNumber (textLine)
10: SN←sentenceNumber (textLine)
11: NN←numeralsNumber (textLine)
12: SCN←specialCharactersNumber(textLine)
13: SCC←specialChineseCharacters (textLine)
14: CN←lenght(textLine)
15: CD←distance (textLine)
16:IfCD=0 and CN≠0
17: Corpus.append(textLine)
18:EndIf
19:IfCD≥10 or CN=0
20:Break(set textLine index as end)
21:EndIf
22:Ifα<0(αrefer to PTN,SN,NN,SCN,SCC)
23:Break(set textLine index as end)
24:Elsedo step 17
25:EndIf
26:EndFor
27: titleCandidateQueue.append(HC0~end)
正向判定
28:FortextLine in HCstart
29: do step 9~25
30:EndFor
為了展示網頁文本行區劃分的效果,以鳳凰資訊2017年12月26日新聞《技術創新領導未來: 小間距LED 2018年行業10大猜想》為例,經過算法1處理后,其網頁文本行被劃分成三個部分,其中第一個部分為新聞標題候選區(0~287行),第二個部分為語料區(288~391行),第三個部分(392~1 000行)直接舍棄,具體效果如圖1所示。
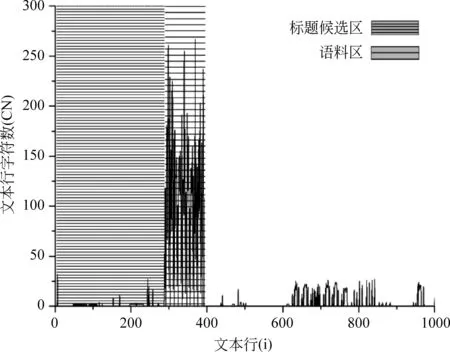
圖1 網頁文本行區域劃分效果圖
2.2 構建單詞權重集合
TextRank[22]是PageRank算法[23]的改進版,其算法核心如式(3)所示。
(3)
式(3)中,TextRank利用權重項ωji,表示兩個節點之間的邊連接的重要程度,其中d為阻尼系數,一般取值為0.85。對于一個給定的點Vi,ln(Vi)為指向Vi的點集合,Out(Vj)為Vj指向其他點的集合。利用TextRank構建單詞權重集合的具體算法如算法2所示。
算法2TextRank構建key-value權重集合算法偽代碼

2.3 計算標題候選隊列權重
在算法2輸出單詞權重集合的基礎上,根據改進的相似度公式計算標題候選隊列的相似度。在數據挖掘領域,通常采用Jaccard相似系數計算兩個含有布爾值度量對象之間的距離(相似度),如式(5)所示。
(5)
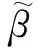
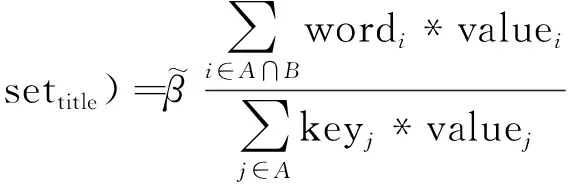
(6)
(7)
在對β進行歸一化處理時,式(7)中的βi為標題候選隊列中選取的當前文本行的β值,βj(1≤j≤n)是標題候選隊列每個文本行的β值,n為標題候選隊列的長度值。
從新聞標題候選隊列中抽取新聞標題的算法偽代碼如算法3所示。
算法3改進Jaccard標題抽取算法偽代碼

在算法3中,首先利用改良的風險因子β過濾標題候選區中不具備新聞標題文本特性的候選項,而后通過改進Jaccard標題抽取算法抽取新聞標題。通過計算β
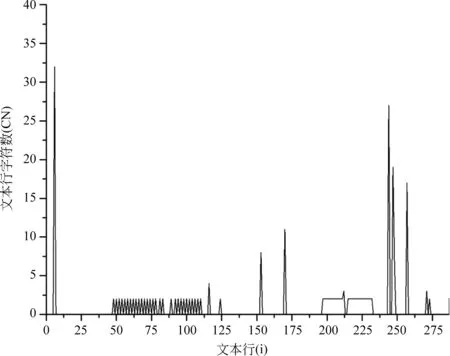
圖2 網頁文本行標題候選區密度分布
3 實驗與結果分析
為了驗證本文基于密度及文本特征新聞標題抽取算法(算法源代碼https://github.com/pzs741/TEDT)的有效性,設計兩組實驗:
(1) 針對主流新聞網站和復雜不規范新聞網站,測試算法的適用性。
(2) 與傳統的基于相似度和基于規則的新聞標題抽取算法進行對比,驗證算法的有效性。
3.1 測試樣本集
測試樣本主要來源于各大主流門戶網站和院校內部信息網,通過網絡爬蟲爬取了3 100個新聞網站并手工摘取并標注了新聞標題,其中主流門戶網2 050個,院校內部信息網1 050個,分為主流網站新聞標題和復雜不規則網站新聞標題兩個互不重疊數據集。
3.2 評價標準
抽取單一網頁新聞標題的準確率P,召回率R和F1值定義如式(8)所示。
(8)
其中,a是自動抽取的網頁新聞標題的字符序列,b是手工標注網頁新聞標題的字符序列,LCS(a,b)為a、b的最大公共子序列,.len是序列對應的長度。
為綜合評價TEDT算法對大量復雜不規范網頁的性能,采用平均準確率、平均召回率和平均F1的值作為評價指標,如式(9)所示。
(9)
其中,Pi,Ri,F1i分別是單個網頁的準確率、召回率和F1值,N為網頁集合的數量。抽取新聞標題的最終結果有四種情況,其主要受到TEDT算法中CDM區域劃分的影響。第一種抽取結果為準確的新聞標題,出現這種情況表示算法劃區是準確的;第二種抽取結果是含有雜質的新聞標題(一般為
標簽內的文本),出現這種情況表明算法劃區靠前,標題候選隊列中不包含真實新聞標題;第三種抽取結果是非標題文本信息(可能與標題存在公共子序列),出現這種情況表明算法劃區靠后,標題候選隊列中含有正文段落;第四種抽取結果是空文本或者錯誤信息,出現這種情況主要是由于網頁錯誤或中英文混雜引起的;抽取結果種類如表1所示。</p><p><img src="https://cimg.fx361.com/images/2023/0204/56a1892c6bbe4f5aec97d82d6ce49bc665a06613.webp"/></p><p>表1 抽取結果種類表</p><h2>3.3 實驗結果分析</h2><p>測試樣本源一共10個,5個主流新聞網頁,5個復雜非規范網頁,各類網站抽取指標實驗結果如表2所示,抽取種類結果比例如表3所示。</p><p><img src="https://cimg.fx361.com/images/2023/0204/7078e218999914b8cea171ae17a5939bf13919a9.webp"/></p><p>表2 新聞標題抽取指標結果</p><p><img src="https://cimg.fx361.com/images/2023/0204/ccf42e9568a0361a2be1fe59046f78465a36293e.webp"/></p><p>表3 新聞標題抽取結果種類比例/%</p><p>表2抽取指標的結果表明,不管是主流網頁還是復雜非規范網頁,平均F1值都在90%以上,證明TEDT算法對于主流網頁和復雜非規范網頁具有通用性,這主要是因為TEDT算法是基于密度和文本特征的,與網頁的標簽(包括鏈接、視頻、圖片等)和樣式特征沒有任何關系,因此TEDT具有廣泛的適用性。</p><p>對表3的進一步分析發現,部分平均F1</p><p>為了驗證TEDT算法抽取新聞標題的有效性,與基于DOM樹標簽規則[10](title extraction based on DOM-Tree)的TEBD和基于文本相似度[18](title extraction based on similarity)的TEBS算法進行對比實驗,三種算法在各類網站新聞標題抽取的平均準確率、平均召回率和平均F1值實驗結果分別如圖3~圖5所示。其中數據來源的類別順序分別為參考消息、鳳凰資訊、環球網、中華網、澎湃新聞、深圳大學新聞網、鄭州大學新聞網、人民大學新聞網、中國海洋大學新聞網和上海交通大學新聞網。</p><p><img src="https://cimg.fx361.com/images/2023/0204/e66ef67075817ef73abf81efba71838dfa87fca8.webp"/></p><p>圖3 三種算法各類網站新聞標題抽取準確率</p><p><img src="https://cimg.fx361.com/images/2023/0204/db363591030dbba6031519aecd6de5120afd2ec1.webp"/></p><p>圖4 三種算法各類網站新聞標題抽取召回率</p><p><img src="https://cimg.fx361.com/images/2023/0204/970635acfa8db4fa1efa0bddc31beb0cc761d185.webp"/></p><p>圖5 三種算法各類網站新聞標題抽取F1值</p><p>由圖3~圖5的實驗結果可知,TEBS算法對主流新聞網站和復雜不規范新聞網站的抽取效果區別不大,但其抽取準確率普遍低于TEDT算法,這主要是由于TEBS算法無法很好地把含雜標題和真實新聞標題區別開來,且網頁中經常存在和原新聞標題相似的推薦新聞信息,導致算法抽取結果的準確率降低;同時由于新聞網站網頁噪聲信息較多(這種趨勢還在不斷增大),這些廣告信息對相似度計算起到了干擾作用,抽取結果中出現網頁噪聲的情況增多,導致了算法召回率降低。</p><p>TEBD算法對主流新聞網站和復雜不規范新聞網站的抽取效果區別較大,這主要是由于主流新聞網站的新聞標題使用規范的<h1>標簽,而復雜不規范新聞網站的新聞標題的標簽是不確定的(且經常不為<h1>或<h1>的類標簽),因此TEBD對主流新聞網站新聞標題的抽取準確率比復雜不規范新聞網站要高得多。但對于復雜不規范新聞網站,例如鄭州大學新聞網,其真實新聞標題的標簽為最常見的<div>塊標簽,同時具有不常見的樣式,無法很好地與其他文本行區分開來,且網頁<title>標簽中不含標題信息,這種在內部網常見的“個性化”編碼方式使得TEBD的算法規則失去效用,從而獲得較低的準確率和召回率。</p><p>由表4各項指標綜合分析可知,TEBD算法過于依賴于常規的網頁結構和標簽,因此對復雜不規范網站的抽取效果很差,而TEBS算法根據整個網頁正文相似度抽取新聞標題,遇到文章主題突出且噪聲較少的網站尚可,一旦網頁噪聲過多將會嚴重影響抽取效果。綜上所述,TEDT算法要優于TEBD和TEBS的方法,TEDT的CDM模型劃分語料區和標題候選區對新聞標題的抽取具有借鑒意義。</p><p><img src="https://cimg.fx361.com/images/2023/0204/0ef4e6fee9b6649cade9273231f00f74c0a5a77b.webp"/></p><p>表4 標題抽取算法比較/%</p><h2>4 結束語</h2><p>為了應對大量復雜非規范網頁自動抽取新聞標題的問題,本文提出了一種基于密度和文本特征的新聞標題抽取方法,該方法融合密度和文本特征構建語料判定模型,通過模型將網頁劃分為語料區和標題候選區,使用TextRank算法計算語料單詞權重集合,而后采用改進的相似度計算方法從標題候選區域抽取新聞標題,避免網頁噪聲干擾,最終抽取出真實新聞標題。</p><p>該方法無需人工設置規則或者維護模板,相對于機器學習反復訓練樣本的方法具有更廣泛的適用性,不僅對主流新聞網站有效,而且面對大量復雜不規范網頁依舊能保證較高的新聞標題抽取準確率和召回率。本文算法性能仍有待進一步提高,例如,當新聞的標題并不能很好的概括正文或者正文過于分散時,將會導致語料選取錯誤,算法可能無法正確抽取新聞標題。下一步的工作重點是加強對初始語料和語料區選擇的判定,并進一步減少標題候選區噪聲干擾。</p></p>
<!-- <div id="g0gggggg" class="article_pdf"><a >查看pdf文檔請下載app</a></div>--><div id="g0gggggg" class="article_love">
<div id="g0gggggg" class="title">猜你喜歡</div>
<div id="g0gggggg" class="article_love_keyword"><span><a href="/tags/9/d/380da93d257f9fbf/1.html" target="_blank">文本</a></span></div>
<div id="g0gggggg" class="article_love_news"><dd><a class="txt_title" href="/page/2022/0517/10316447.shtml" target="_blank" title="文本聯讀學概括 細致觀察促寫作">文本聯讀學概括 細致觀察促寫作</a><div id="g0gggggg" class="rsorc"><a href="/bk/ynjyxxjs/20224.html" class="ly" title="云南教育·小學教師(2022年4期)">云南教育·小學教師(2022年4期)</a><span id="g0gggggg" class="txt">2022-05-17 14:46:24</span></div></dd><dd><a class="txt_title" href="/page/2020/0725/13688655.shtml" target="_blank" title="重點:論述類文本閱讀">重點:論述類文本閱讀</a><div id="g0gggggg" class="rsorc"><a href="/bk/xsjznywbk/20204.html" class="ly" title="新世紀智能(語文備考)(2020年4期)">新世紀智能(語文備考)(2020年4期)</a><span id="g0gggggg" class="txt">2020-07-25 02:28:52</span></div></dd><dd><a class="txt_title" href="/page/2020/0725/13688690.shtml" target="_blank" title="重點:實用類文本閱讀">重點:實用類文本閱讀</a><div id="g0gggggg" class="rsorc"><a href="/bk/xsjznywbk/20204.html" class="ly" title="新世紀智能(語文備考)(2020年4期)">新世紀智能(語文備考)(2020年4期)</a><span id="g0gggggg" class="txt">2020-07-25 02:28:52</span></div></dd><dd><a class="txt_title" href="/page/2020/0611/11549024.shtml" target="_blank" title="初中群文閱讀的文本選擇及組織">初中群文閱讀的文本選擇及組織</a><div id="g0gggggg" class="rsorc"><a href="/bk/gsjy/20208.html" class="ly" title="甘肅教育(2020年8期)">甘肅教育(2020年8期)</a><span id="g0gggggg" class="txt">2020-06-11 06:10:02</span></div></dd><dd><a class="txt_title" href="/page/2020/0206/11091718.shtml" target="_blank" title="作為“文本鏈”的元電影">作為“文本鏈”的元電影</a><div id="g0gggggg" class="rsorc"><a href="/bk/yspl/20203.html" class="ly" title="藝術評論(2020年3期)">藝術評論(2020年3期)</a><span id="g0gggggg" class="txt">2020-02-06 06:29:22</span></div></dd><dd><a class="txt_title" href="/page/2019/1026/15409156.shtml" target="_blank" title="在808DA上文本顯示的改善">在808DA上文本顯示的改善</a><div id="g0gggggg" class="rsorc"><a href="/bk/zzjsyjc/201910.html" class="ly" title="制造技術與機床(2019年10期)">制造技術與機床(2019年10期)</a><span id="g0gggggg" class="txt">2019-10-26 02:48:08</span></div></dd><dd><a class="txt_title" href="/page/2018/1229/15680225.shtml" target="_blank" title="“文化傳承與理解”離不開對具體文本的解讀與把握">“文化傳承與理解”離不開對具體文本的解讀與把握</a><div id="g0gggggg" class="rsorc"><a href="/bk/xsjznywbk/201811.html" class="ly" title="新世紀智能(語文備考)(2018年11期)">新世紀智能(語文備考)(2018年11期)</a><span id="g0gggggg" class="txt">2018-12-29 12:30:58</span></div></dd><dd><a class="txt_title" href="/page/2018/1114/13848581.shtml" target="_blank" title="基于doc2vec和TF-IDF的相似文本識別">基于doc2vec和TF-IDF的相似文本識別</a><div id="g0gggggg" class="rsorc"><a href="/bk/dzzz/201818.html" class="ly" title="電子制作(2018年18期)">電子制作(2018年18期)</a><span id="g0gggggg" class="txt">2018-11-14 01:48:06</span></div></dd><dd><a class="txt_title" href="/page/2016/0115/18138612.shtml" target="_blank" title="文本之中·文本之外·文本之上——童話故事《坐井觀天》的教學隱喻">文本之中·文本之外·文本之上——童話故事《坐井觀天》的教學隱喻</a><div id="g0gggggg" class="rsorc"><a href="/bk/xxjyck/201520.html" class="ly" title="小學教學參考(2015年20期)">小學教學參考(2015年20期)</a><span id="g0gggggg" class="txt">2016-01-15 08:44:38</span></div></dd><dd><a class="txt_title" href="/page/2015/0228/17152994.shtml" target="_blank" title="從背景出發還是從文本出發">從背景出發還是從文本出發</a><div id="g0gggggg" class="rsorc"><a href="/bk/ywzs/201511.html" class="ly" title="語文知識(2015年11期)">語文知識(2015年11期)</a><span id="g0gggggg" class="txt">2015-02-28 22:01:59</span></div></dd></div>
</div><div id="g0gggggg" class="other_pel mt80">
<p class="fl"><a href="/bk/zwxxxb/201810.html" target="_blank"><img src="https://cimg.fx361.com/images/2023/0204/5193aa8b42cf7bd24e9751cb749592fdcf081680.webp" alt=""></a><span id="g0gggggg" class="p1"><a href="/bk/zwxxxb/" target="_blank">中文信息學報</a></span><span id="g0gggggg" class="p2"><a href="/bk/zwxxxb/201810.html" target="_blank">2018年10期</a></span></p>
<dl class="fl"><dt>中文信息學報的其它文章</dt><dd><a href="/page/2018/1116/16508881.shtml" title="N-Reader: 基于雙層Self-attention的機器閱讀理解模型">N-Reader: 基于雙層Self-attention的機器閱讀理解模型</a></dd><dd><a href="/page/2018/1116/16508850.shtml" title="2018機器閱讀理解技術競賽總體報告">2018機器閱讀理解技術競賽總體報告</a></dd><dd><a href="/page/2018/1116/16508621.shtml" title="基于網絡小說熱度預測的CDN內容分發策略研究">基于網絡小說熱度預測的CDN內容分發策略研究</a></dd><dd><a href="/page/2018/1116/16508596.shtml" title="基于多模型的新聞標題分類">基于多模型的新聞標題分類</a></dd><dd><a href="/page/2018/1116/16508211.shtml" title="地理社會網絡數據可視化分析研究綜述">地理社會網絡數據可視化分析研究綜述</a></dd><dd><a href="/page/2018/1116/16508228.shtml" title="基于分形幾何的甲骨文字形識別方法">基于分形幾何的甲骨文字形識別方法</a></dd></dl>
</div></div>
</div>
</div>
<div id="g0gggggg" class="sidebarR">
<!-- tab選項卡 -->
<div id="g0gggggg" class="tab01 mb20"><div id="g0gggggg" class="tabArrow"></div><div id="g0gggggg" class="tabItem"><div id="g0gggggg" class="tabTit"><a href="#">雜志排行</a></div>
<div id="g0gggggg" class="tabCont"><ol><li><p class="row01"><span id="g0gggggg" class="topNum">1</span><a href="/bk/sdjy/202410.html" class="row01a">《師道·教研》</a><span id="g0gggggg" class="row01_fr"><a href="/bk/sdjy/202410.html">2024年10期</a></span></p></li><li><p class="row01"><span id="g0gggggg" class="topNum">2</span><a href="/bk/swyzhsby/202411.html" class="row01a">《思維與智慧·上半月》</a><span id="g0gggggg" class="row01_fr"><a href="/bk/swyzhsby/202411.html">2024年11期</a></span></p></li><li><p class="row01"><span id="g0gggggg" class="topNum">3</span><a href="/bk/xdgyjjhxxh/20242.html" class="row01a">《現代工業經濟和信息化》</a><span id="g0gggggg" class="row01_fr"><a href="/bk/xdgyjjhxxh/20242.html">2024年2期</a></span></p></li><li><p class="row01"><span id="g0gggggg" class="topNum">4</span><a href="/bk/wxxsyb/202410.html" class="row01a">《微型小說月報》</a><span id="g0gggggg" class="row01_fr"><a href="/bk/wxxsyb/202410.html">2024年10期</a></span></p></li><li><p class="row01"><span id="g0gggggg" class="topNum">5</span><a href="/bk/gywsw/20241.html" class="row01a">《工業微生物》</a><span id="g0gggggg" class="row01_fr"><a href="/bk/gywsw/20241.html">2024年1期</a></span></p></li><li><p class="row01"><span id="g0gggggg" class="topNum">6</span><a href="/bk/xl/20249.html" class="row01a">《雪蓮》</a><span id="g0gggggg" class="row01_fr"><a href="/bk/xl/20249.html">2024年9期</a></span></p></li><li><p class="row01"><span id="g0gggggg" class="topNum">7</span><a href="/bk/sjbl/202421.html" class="row01a">《世界博覽》</a><span id="g0gggggg" class="row01_fr"><a href="/bk/sjbl/202421.html">2024年21期</a></span></p></li><li><p class="row01"><span id="g0gggggg" class="topNum">8</span><a href="/bk/zxqyglykj/20246.html" class="row01a">《中小企業管理與科技》</a><span id="g0gggggg" class="row01_fr"><a href="/bk/zxqyglykj/20246.html">2024年6期</a></span></p></li><li><p class="row01"><span id="g0gggggg" class="topNum">9</span><a href="/bk/xdsp/20244.html" class="row01a">《現代食品》</a><span id="g0gggggg" class="row01_fr"><a href="/bk/xdsp/20244.html">2024年4期</a></span></p></li><li><p class="row01"><span id="g0gggggg" class="topNum">10</span><a href="/bk/wszyjy/202410.html" class="row01a">《衛生職業教育》</a><span id="g0gggggg" class="row01_fr"><a href="/bk/wszyjy/202410.html">2024年10期</a></span></p></li></ol> </div></div>
</div>
</div>
<div id="g0gggggg" class="clr"></div>
</div>
</div>
<!--div class="advertisement">
</div-->
<div id="g0gggggg" class="footer">
<p><a href="/aboutus/index.html">關于參考網</a></p>
</div>
<!--
<script>
if ('serviceWorker' in navigator) {
window.onload = function () {
navigator.serviceWorker.register('/sw.js');
};
}
</script>
-->
<script type="text/javascript" src="https://s1.pstatp.com/cdn/expire-1-M/jquery/3.4.0/jquery.min.js"></script>
<script type="text/javascript" src="https://s1.pstatp.com/cdn/expire-1-M/sticky-kit/1.1.3/sticky-kit.min.js"></script>
<script type="text/javascript">
document.write('<script src="https://cimg.fx361.com/cdn/w/index.js"><\/script>');
</script>
<footer>
<div class="friendship-link">
<p>感谢您访问我们的网站,您可能还对以下资源感兴趣:自贡牌麓投资有限公司</p>
<a href="http://www.handmsg.com"title=999精品在线视频,手机成人午夜在线视频,久久不卡国产精品无码,中日无码在线观看,成人av手机在线观看,日韩精品亚洲一区中文字幕,亚洲av无码人妻,四虎国产在线观看">999精品在线视频,手机成人午夜在线视频,久久不卡国产精品无码,中日无码在线观看,成人av手机在线观看,日韩精品亚洲一区中文字幕,亚洲av无码人妻,四虎国产在线观看</a>
<a href="/sitemap.xml">网站地图</a>
<div style="position:fixed;left:-9000px;top:-9000px;"></div>
<div class="friend-links">
</div>
</div>
</footer>
主站蜘蛛池模板:
<a href="http://www.suzhoushuman.com" target="_blank">久久精品中文字幕少妇</a>|
<a href="http://www.keerjianchem.com" target="_blank">国产亚洲精品97在线观看</a>|
<a href="http://www.caohuiji.com" target="_blank">国产在线精品网址你懂的</a>|
<a href="http://www.djaudi.com" target="_blank">亚洲天堂免费在线视频</a>|
<a href="http://www.eticaretdanismanligi.net" target="_blank">国产一区二区在线视频观看</a>|
<a href="http://www.blackannealedwire.net" target="_blank">69av在线</a>|
<a href="http://www.xydlcn.com" target="_blank">亚洲精品人成网线在线</a>|
<a href="http://www.hlch.net" target="_blank">国产成人综合亚洲网址</a>|
<a href="http://www.989753.com" target="_blank">亚洲天堂伊人</a>|
<a href="http://www.atrduoduo.com" target="_blank">久久99热这里只有精品免费看</a>|
<a href="http://www.bdccz.com" target="_blank">激情六月丁香婷婷四房播</a>|
<a href="http://www.yimlong.com" target="_blank">亚洲欧美成人综合</a>|
<a href="http://www.bc4999.com" target="_blank">日韩区欧美国产区在线观看</a>|
<a href="http://www.90du-dqzz.com" target="_blank">欧美三级日韩三级</a>|
<a href="http://www.taijian.net" target="_blank">免费啪啪网址</a>|
<a href="http://www.jmgjg.com" target="_blank">日韩欧美国产精品</a>|
<a href="http://www.mgpsdata-2.com" target="_blank">少妇极品熟妇人妻专区视频</a>|
<a href="http://www.nokia4issu.net" target="_blank">亚洲日韩欧美在线观看</a>|
<a href="http://www.xfbcece.cn" target="_blank">久久伊人操</a>|
<a href="http://www.ykqynh.com" target="_blank">久久亚洲高清国产</a>|
<a href="http://www.ht-sc.com" target="_blank">亚洲激情区</a>|
<a href="http://www.wffxjd888.com" target="_blank">波多野结衣一区二区三区AV</a>|
<a href="http://www.zeyu-zhang.com" target="_blank">日韩成人高清无码</a>|
<a href="http://www.astsgs.com" target="_blank">在线观看视频一区二区</a>|
<a href="http://www.thgcjs.com" target="_blank">亚洲欧美精品一中文字幕</a>|
<a href="http://www.989753.com" target="_blank">欧美专区在线观看</a>|
<a href="http://www.smjxxj.com" target="_blank">国产精品99一区不卡</a>|
<a href="http://www.wind-blog.com" target="_blank">国产免费黄</a>|
<a href="http://www.dyofs.com" target="_blank">欧美一级高清视频在线播放</a>|
<a href="http://www.cjmss.com" target="_blank">久久久精品无码一二三区</a>|
<a href="http://www.hsdonghong.com" target="_blank">欧美黄色a</a>|
<a href="http://www.1chache.com" target="_blank">六月婷婷精品视频在线观看</a>|
<a href="http://www.043498.com" target="_blank">日韩精品一区二区三区中文无码
</a>|
<a href="http://www.rrtg.net" target="_blank">亚洲国产综合精品一区</a>|
<a href="http://www.2facedbook.net" target="_blank">香蕉蕉亚亚洲aav综合</a>|
<a href="http://www.weitebiaoshi.com" target="_blank">欧美精品xx</a>|
<a href="http://www.hiwiner.com" target="_blank">亚洲一区二区三区国产精品
</a>|
<a href="http://www.montrealluxurycars.com" target="_blank">av大片在线无码免费</a>|
<a href="http://www.sdfatong.net" target="_blank">国产真实自在自线免费精品</a>|
<a href="http://www.langanjiaotong.com" target="_blank">伊人精品成人久久综合</a>|
<a href="http://www.674cq.com" target="_blank">亚洲人成网站观看在线观看</a>|
<a href="http://www.hrhst.com" target="_blank">99在线视频免费</a>|
<a href="http://www.xianhuasen.com" target="_blank">亚洲另类第一页</a>|
<a href="http://www.bhne.cn" target="_blank">无码中文字幕乱码免费2</a>|
<a href="http://www.chuanlbx.com" target="_blank">国产18在线播放</a>|
<a href="http://www.suyahuishou.com" target="_blank">а∨天堂一区中文字幕</a>|
<a href="http://www.blackhatguide.net" target="_blank">欧美日韩成人在线观看</a>|
<a href="http://www.0517s.com" target="_blank">99er这里只有精品</a>|
<a href="http://www.6dragons.net" target="_blank">欧美亚洲欧美</a>|
<a href="http://www.laminatedtube.net" target="_blank">国产在线视频欧美亚综合</a>|
<a href="http://www.kanzhihu.com" target="_blank">亚洲天堂视频网站</a>|
<a href="http://www.qdljsl.com" target="_blank">国产精品入口麻豆</a>|
<a href="http://www.0915eye.com" target="_blank">91区国产福利在线观看午夜</a>|
<a href="http://www.yxccn.cn" target="_blank">日韩AV无码免费一二三区</a>|
<a href="http://www.fanaiqi.com" target="_blank">国产在线观看91精品</a>|
<a href="http://www.iraqws.com" target="_blank">亚洲天天更新</a>|
<a href="http://www.xianhuasen.com" target="_blank">国产精品区视频中文字幕</a>|
<a href="http://www.hongdawantong.com" target="_blank">91精品小视频</a>|
<a href="http://www.jm-dd.com" target="_blank">国产视频欧美</a>|
<a href="http://www.zhongjuntools.com" target="_blank">欧美精品二区</a>|
<a href="http://www.echeya.com" target="_blank">97视频免费在线观看</a>|
<a href="http://www.420party.net" target="_blank">亚洲AV无码一区二区三区牲色</a>|
<a href="http://www.youmogou.com" target="_blank">伊人成人在线视频</a>|
<a href="http://www.jkmyu.com" target="_blank">就去吻亚洲精品国产欧美</a>|
<a href="http://www.taijian.net" target="_blank">a毛片基地免费大全</a>|
<a href="http://www.66fvip.com" target="_blank">久久中文字幕2021精品</a>|
<a href="http://www.sds678.com" target="_blank">亚洲αv毛片</a>|
<a href="http://www.indihomesolution.com" target="_blank">亚洲人成网站色7799在线播放</a>|
<a href="http://www.zgzjfc.net" target="_blank">成人午夜免费观看</a>|
<a href="http://www.linruoxi.com" target="_blank">A级全黄试看30分钟小视频</a>|
<a href="http://www.mrjl.net" target="_blank">欧美日本在线播放</a>|
<a href="http://www.gsymbljc.com" target="_blank">婷婷久久综合九色综合88</a>|
<a href="http://www.5211114.com" target="_blank">国产日韩精品欧美一区灰</a>|
<a href="http://www.mmhapra.cn" target="_blank">国产乱子伦无码精品小说</a>|
<a href="http://www.guodongdong.net" target="_blank">亚洲性网站</a>|
<a href="http://www.shenhang.net" target="_blank">日韩中文无码av超清</a>|
<a href="http://www.bijiecj.com" target="_blank">亚洲永久视频</a>|
<a href="http://www.968012.com" target="_blank">99久久性生片</a>|
<a href="http://www.miramar-digital.com" target="_blank">激情综合五月网</a>|
<a href="http://www.justchoosehappiness.net" target="_blank">激情综合图区</a>|
<a href="http://www.mapdude.net" target="_blank">午夜a级毛片</a>|
<a href="http://www.whybxx.com" target="_blank">亚洲三级影院</a>|
<script>
(function(){
var bp = document.createElement('script');
var curProtocol = window.location.protocol.split(':')[0];
if (curProtocol === 'https') {
bp.src = 'https://zz.bdstatic.com/linksubmit/push.js';
}
else {
bp.src = 'http://push.zhanzhang.baidu.com/push.js';
}
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(bp, s);
})();
</script>
</body><div id="yyyyy" class="pl_css_ganrao" style="display: none;"><pre id="yyyyy"></pre><strong id="yyyyy"><del id="yyyyy"><button id="yyyyy"></button></del></strong><input id="yyyyy"></input><li id="yyyyy"></li><menu id="yyyyy"></menu><delect id="yyyyy"></delect><table id="yyyyy"><pre id="yyyyy"><delect id="yyyyy"></delect></pre></table><blockquote id="yyyyy"><menu id="yyyyy"><center id="yyyyy"></center></menu></blockquote><small id="yyyyy"><blockquote id="yyyyy"><menu id="yyyyy"></menu></blockquote></small><s id="yyyyy"></s><abbr id="yyyyy"></abbr><acronym id="yyyyy"></acronym><td id="yyyyy"><abbr id="yyyyy"><tbody id="yyyyy"></tbody></abbr></td><tfoot id="yyyyy"><noscript id="yyyyy"><dd id="yyyyy"></dd></noscript></tfoot><dl id="yyyyy"><tr id="yyyyy"><wbr id="yyyyy"></wbr></tr></dl><input id="yyyyy"></input><noscript id="yyyyy"></noscript><object id="yyyyy"></object><wbr id="yyyyy"></wbr><td id="yyyyy"></td><table id="yyyyy"></table><wbr id="yyyyy"></wbr><sup id="yyyyy"></sup><cite id="yyyyy"></cite><tr id="yyyyy"></tr><tr id="yyyyy"></tr><tbody id="yyyyy"></tbody><delect id="yyyyy"></delect><wbr id="yyyyy"></wbr><code id="yyyyy"></code><em id="yyyyy"></em><bdo id="yyyyy"><samp id="yyyyy"><input id="yyyyy"></input></samp></bdo><dfn id="yyyyy"></dfn><tbody id="yyyyy"></tbody><s id="yyyyy"></s><s id="yyyyy"></s><sup id="yyyyy"></sup><strike id="yyyyy"></strike><strike id="yyyyy"><li id="yyyyy"><center id="yyyyy"></center></li></strike><s id="yyyyy"></s><tr id="yyyyy"></tr><dl id="yyyyy"></dl><code id="yyyyy"></code><del id="yyyyy"></del><cite id="yyyyy"><ul id="yyyyy"><rt id="yyyyy"></rt></ul></cite><input id="yyyyy"></input><samp id="yyyyy"></samp><code id="yyyyy"><delect id="yyyyy"><object id="yyyyy"></object></delect></code><nav id="yyyyy"></nav><button id="yyyyy"></button><wbr id="yyyyy"><noframes id="yyyyy"><tr id="yyyyy"></tr></noframes></wbr><dfn id="yyyyy"><bdo id="yyyyy"><samp id="yyyyy"></samp></bdo></dfn><ul id="yyyyy"><rt id="yyyyy"><option id="yyyyy"></option></rt></ul><wbr id="yyyyy"><tfoot id="yyyyy"><noscript id="yyyyy"></noscript></tfoot></wbr><em id="yyyyy"></em><noscript id="yyyyy"></noscript><tbody id="yyyyy"><xmp id="yyyyy"><nav id="yyyyy"></nav></xmp></tbody><pre id="yyyyy"></pre><noscript id="yyyyy"></noscript><tbody id="yyyyy"></tbody><object id="yyyyy"><pre id="yyyyy"><th id="yyyyy"></th></pre></object><em id="yyyyy"></em><tfoot id="yyyyy"></tfoot><pre id="yyyyy"></pre><noframes id="yyyyy"><tfoot id="yyyyy"><noscript id="yyyyy"></noscript></tfoot></noframes><optgroup id="yyyyy"></optgroup><ul id="yyyyy"><rt id="yyyyy"><option id="yyyyy"></option></rt></ul><cite id="yyyyy"><ul id="yyyyy"><rt id="yyyyy"></rt></ul></cite><abbr id="yyyyy"></abbr><del id="yyyyy"><s id="yyyyy"><strike id="yyyyy"></strike></s></del><code id="yyyyy"><delect id="yyyyy"><pre id="yyyyy"></pre></delect></code><fieldset id="yyyyy"></fieldset><s id="yyyyy"></s><optgroup id="yyyyy"><pre id="yyyyy"><strong id="yyyyy"></strong></pre></optgroup><kbd id="yyyyy"><source id="yyyyy"><strike id="yyyyy"></strike></source></kbd><sup id="yyyyy"></sup><pre id="yyyyy"></pre><noscript id="yyyyy"></noscript><abbr id="yyyyy"></abbr><kbd id="yyyyy"></kbd><dl id="yyyyy"><tr id="yyyyy"><wbr id="yyyyy"></wbr></tr></dl><acronym id="yyyyy"></acronym><xmp id="yyyyy"></xmp><table id="yyyyy"></table><tr id="yyyyy"><noframes id="yyyyy"><tr id="yyyyy"></tr></noframes></tr><s id="yyyyy"></s><samp id="yyyyy"></samp><pre id="yyyyy"><th id="yyyyy"><abbr id="yyyyy"></abbr></th></pre><tbody id="yyyyy"><xmp id="yyyyy"><nav id="yyyyy"></nav></xmp></tbody><dl id="yyyyy"></dl><sup id="yyyyy"><cite id="yyyyy"><ul id="yyyyy"></ul></cite></sup><sup id="yyyyy"><cite id="yyyyy"><ul id="yyyyy"></ul></cite></sup><td id="yyyyy"><abbr id="yyyyy"><tbody id="yyyyy"></tbody></abbr></td><abbr id="yyyyy"><td id="yyyyy"><tbody id="yyyyy"></tbody></td></abbr><rt id="yyyyy"></rt><delect id="yyyyy"><object id="yyyyy"><fieldset id="yyyyy"></fieldset></object></delect><xmp id="yyyyy"></xmp><menu id="yyyyy"></menu><li id="yyyyy"></li><menu id="yyyyy"></menu><samp id="yyyyy"><input id="yyyyy"><dl id="yyyyy"></dl></input></samp><th id="yyyyy"></th><del id="yyyyy"></del><nav id="yyyyy"></nav><del id="yyyyy"></del><code id="yyyyy"><delect id="yyyyy"><object id="yyyyy"></object></delect></code><input id="yyyyy"><acronym id="yyyyy"><cite id="yyyyy"></cite></acronym></input><noscript id="yyyyy"></noscript><dd id="yyyyy"><pre id="yyyyy"><strong id="yyyyy"></strong></pre></dd><dl id="yyyyy"></dl><xmp id="yyyyy"></xmp><del id="yyyyy"><button id="yyyyy"><dl id="yyyyy"></dl></button></del><tr id="yyyyy"><small id="yyyyy"><menu id="yyyyy"></menu></small></tr><strike id="yyyyy"></strike><menu id="yyyyy"></menu><delect id="yyyyy"><object id="yyyyy"><th id="yyyyy"></th></object></delect><code id="yyyyy"><object id="yyyyy"><pre id="yyyyy"></pre></object></code><pre id="yyyyy"></pre><del id="yyyyy"></del><noscript id="yyyyy"><pre id="yyyyy"><del id="yyyyy"></del></pre></noscript><rt id="yyyyy"></rt><cite id="yyyyy"></cite><optgroup id="yyyyy"><bdo id="yyyyy"><samp id="yyyyy"></samp></bdo></optgroup><delect id="yyyyy"></delect><center id="yyyyy"><strong id="yyyyy"><s id="yyyyy"></s></strong></center><pre id="yyyyy"></pre><s id="yyyyy"><strike id="yyyyy"><li id="yyyyy"></li></strike></s><dfn id="yyyyy"><bdo id="yyyyy"><input id="yyyyy"></input></bdo></dfn><rt id="yyyyy"></rt><abbr id="yyyyy"><abbr id="yyyyy"><tbody id="yyyyy"></tbody></abbr></abbr><small id="yyyyy"></small><pre id="yyyyy"></pre><table id="yyyyy"><pre id="yyyyy"><code id="yyyyy"></code></pre></table><strong id="yyyyy"></strong><tr id="yyyyy"><wbr id="yyyyy"><tfoot id="yyyyy"></tfoot></wbr></tr><xmp id="yyyyy"></xmp><td id="yyyyy"></td><code id="yyyyy"><object id="yyyyy"><pre id="yyyyy"></pre></object></code><dl id="yyyyy"></dl><pre id="yyyyy"></pre><optgroup id="yyyyy"><bdo id="yyyyy"><input id="yyyyy"></input></bdo></optgroup><delect id="yyyyy"></delect><pre id="yyyyy"></pre><center id="yyyyy"></center><pre id="yyyyy"></pre><xmp id="yyyyy"></xmp><delect id="yyyyy"><pre id="yyyyy"><kbd id="yyyyy"></kbd></pre></delect><ul id="yyyyy"></ul><ul id="yyyyy"></ul><pre id="yyyyy"></pre></div>
</html>