2018機(jī)器閱讀理解技術(shù)競賽總體報(bào)告
2018-11-16 08:00:22呂雅娟佘俏俏時(shí)迎超
中文信息學(xué)報(bào) 2018年10期
劉 凱,劉 璐,劉 璟,呂雅娟,佘俏俏,張 倩,時(shí)迎超
(百度 自然語言處理部,北京 100190)
0 引言
機(jī)器閱讀理解(Machine Reading Comprehension)是指讓機(jī)器閱讀文本,然后回答和閱讀內(nèi)容相關(guān)的問題。這項(xiàng)技術(shù)可以使計(jì)算機(jī)具備從文本數(shù)據(jù)中獲取知識(shí)并回答問題的能力,是構(gòu)建通用人工智能的關(guān)鍵技術(shù)之一。作為自然語言處理和人工智能領(lǐng)域的前沿課題,機(jī)器閱讀理解研究近年來受到廣泛關(guān)注。
“2018機(jī)器閱讀理解技術(shù)競賽”由中國中文信息學(xué)會(huì)、中國計(jì)算機(jī)學(xué)會(huì)主辦,百度公司承辦,旨在為研究者提供開放的學(xué)術(shù)交流平臺(tái),提升機(jī)器閱讀理解的水平,推動(dòng)語言理解和人工智能領(lǐng)域技術(shù)研究和應(yīng)用的發(fā)展。
競賽數(shù)據(jù)集采用了百度公司發(fā)布的當(dāng)前最大規(guī)模的中文閱讀理解數(shù)據(jù)集DuReader[1]。該數(shù)據(jù)集中的問題和文檔均來自搜索引擎的真實(shí)場景,符合用戶實(shí)際需求。在傳統(tǒng)閱讀理解自動(dòng)評價(jià)指標(biāo)基礎(chǔ)上,此次競賽針對特定類型問題的評價(jià)進(jìn)行了適當(dāng)?shù)恼{(diào)整,使其與人工評價(jià)標(biāo)準(zhǔn)更為一致。除此之外,競賽還提供了先進(jìn)的閱讀理解基線系統(tǒng)*① https://github.com/baidu/DuReader,為參賽者快速實(shí)驗(yàn)和提升閱讀理解技術(shù)提供了便利。競賽吸引了來自國內(nèi)外的千余支隊(duì)伍報(bào)名參與,參賽閱讀理解系統(tǒng)的整體水平得到了顯著提升。
本報(bào)告詳細(xì)介紹了此次閱讀理解競賽的整體情況、評測方法、評測結(jié)果以及相應(yīng)的結(jié)果分析等。希望能夠?yàn)閲鴥?nèi)外學(xué)者和單位提供有益的信息,對閱讀理解技術(shù)發(fā)展起到積極的推動(dòng)作用。
1 競賽設(shè)置
1.1 競賽任務(wù)
本次競賽任務(wù)設(shè)置為: 對于給定問題q及其候選文檔集合D=d1,d2, …,dn,要求閱讀理解系統(tǒng)輸出能夠回答問題的文本答案a。目標(biāo)是a能夠正確、完整、簡潔地回答問題q。其中對于是非類型問題q,我們期望參賽者能夠進(jìn)一步給出相應(yīng)答案的是非判斷信息(Yes/No/Depends)。
1.2 數(shù)據(jù)簡介
競賽采用的DuReader[1]閱讀理解數(shù)據(jù)集是當(dāng)前規(guī)模最大的中文閱讀理解數(shù)據(jù)集。數(shù)據(jù)集的構(gòu)建基于真實(shí)的應(yīng)用需求,所有問題都是百度搜索中用戶提出的真實(shí)問題。文檔來自全網(wǎng)采集的網(wǎng)頁(Search)和百度知道(Zhidao)文檔,答案是基于問題與文檔人工撰寫生成的。數(shù)據(jù)集中標(biāo)注了問題類型、實(shí)體答案和觀點(diǎn)答案等豐富信息。其中問題分為描述類、實(shí)體類和是非類三種類型,而實(shí)體類問題和是非類問題中分別包含了進(jìn)一步的實(shí)體答案和觀點(diǎn)答案。關(guān)于DuReader數(shù)據(jù)集的構(gòu)建和詳細(xì)的數(shù)據(jù)分布信息請參見參考文獻(xiàn)[1]。本次競賽的數(shù)據(jù)集的分布如表1所示,劃分為Search和Zhidao兩個(gè)不同數(shù)據(jù)來源的集合,并在測試集中隨機(jī)添加了10萬的混淆數(shù)據(jù),以避免參賽系統(tǒng)針對性調(diào)節(jié)參數(shù),保證競賽的公平公正。
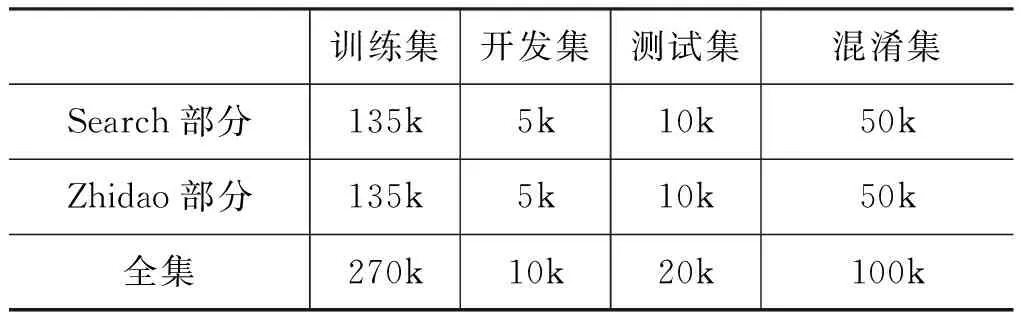
表1 DuReader數(shù)據(jù)分布
1.3 基線系統(tǒng)
本次競賽為參賽者提供了數(shù)據(jù)集相應(yīng)的基線系統(tǒng)源代碼。參賽隊(duì)伍可以有針對性地對基線系統(tǒng)進(jìn)行改進(jìn)升級,構(gòu)造自己的參賽系統(tǒng)。基線系統(tǒng)實(shí)現(xiàn)了BiDAF[2]和MatchLSTM[3]兩個(gè)閱讀理解神經(jīng)網(wǎng)絡(luò)模型,二者均為當(dāng)前主流的閱讀理解模型,很多閱讀理解模型是以這兩個(gè)模型為基礎(chǔ)進(jìn)行創(chuàng)新的。本文中將采用基于BiDAF模型的系統(tǒng)作為基線系統(tǒng)。
1.4 評價(jià)方法
競賽結(jié)果采用自動(dòng)和人工兩種評價(jià)方法進(jìn)行評價(jià)。其中自動(dòng)評價(jià)指標(biāo)將作為直接的評價(jià)指標(biāo)對提交的全部系統(tǒng)結(jié)果進(jìn)行效果評價(jià),用于系統(tǒng)排名和最終成績認(rèn)定。而人工評價(jià)指標(biāo)將作為對前10名(TOP10)系統(tǒng)進(jìn)行效果評價(jià)和問題分析的主要依據(jù)。
1.4.1 自動(dòng)評價(jià)
在自動(dòng)評測中采用ROUGE-L[4]和BLEU-4[5]兩個(gè)指標(biāo),其中ROUGE-L將作為主要參考指標(biāo)用于排名。對于數(shù)據(jù)集中的是非類型問題和實(shí)體類型問題,答案中包含觀點(diǎn)判斷或?qū)嶓w答案枚舉的片段對于答案應(yīng)當(dāng)有著更大的影響。因此本次競賽采用了改進(jìn)的ROUGE-L和BLEU-4指標(biāo)[6]進(jìn)行效果評價(jià),對于是非類型問題,希望參賽者能夠?qū)ψ约赫业降拇鸢缸鲞M(jìn)一步的觀點(diǎn)判斷,如果判斷正確,評估時(shí)將會(huì)得到一定的獎(jiǎng)勵(lì);而對于實(shí)體類型問題,將直接在評價(jià)時(shí)對答案中包含的正確實(shí)體在評價(jià)中進(jìn)行一定的獎(jiǎng)勵(lì)。關(guān)于改進(jìn)的評價(jià)指標(biāo)及改進(jìn)效果詳見參考文獻(xiàn)[6]。在本次競賽的自動(dòng)評價(jià)計(jì)算中,取γ=1.2,而是非問題和實(shí)體問題類型的激勵(lì)權(quán)重則分別設(shè)置為α=1.0,β=1.0。
1.4.2 人工評價(jià)
為了更好地評價(jià)系統(tǒng)結(jié)果并進(jìn)行系統(tǒng)問題分析,本次競賽對自動(dòng)評價(jià)排名靠前的系統(tǒng)進(jìn)行了人工采樣打分評價(jià)。評分的主要依據(jù)為該答案是否正確、完整并簡潔地回答了對應(yīng)問題。人工評分原則上依據(jù)表2中的標(biāo)準(zhǔn),為每個(gè)系統(tǒng)的答案給出0-3分的打分。對于每一條待評分答案安排五個(gè)標(biāo)注者進(jìn)行評分標(biāo)注,最終評分結(jié)果采用五人的均值。
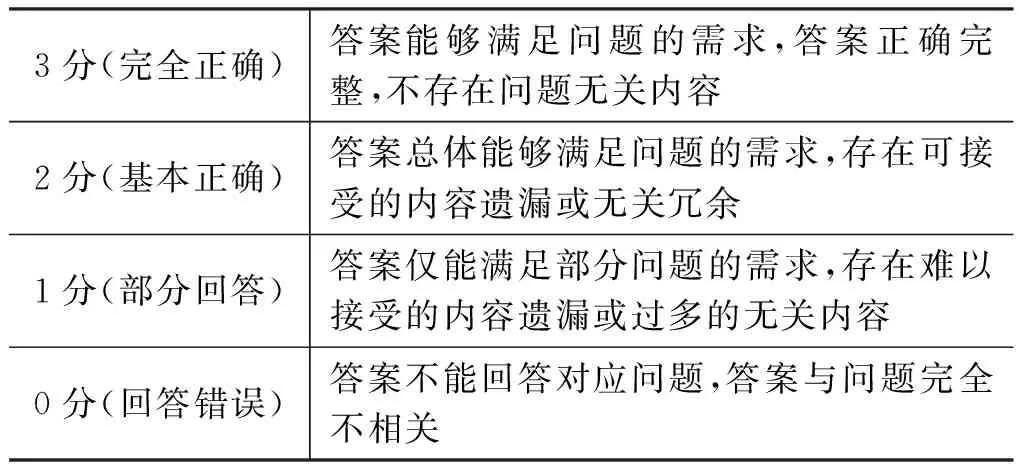
表2 人工評分標(biāo)準(zhǔn)
對于不同的待評估系統(tǒng),評測組織方隨機(jī)采樣相同的1 000條問題進(jìn)行評分,且對不同類型的問題(描述類/是非類/實(shí)體類)均依據(jù)總體一致的原則進(jìn)行打分評估,不同類型問題的具體打分標(biāo)準(zhǔn)略有不同,人工評分樣例詳見附表1。對于有瑕疵或者錯(cuò)誤的答案,我們進(jìn)一步地考察了候選答案存在的具體問題,以便進(jìn)行問題分析。
2 組織流程
本次閱讀理解技術(shù)競賽為期兩個(gè)月,具體競賽組織流程如表3所示。競賽測試集分兩次發(fā)放,首次發(fā)放一部分測試集供參賽者在線自助評估并查看排名。在線自動(dòng)評估階段每個(gè)參賽系統(tǒng)每天最多可以提交兩次結(jié)果。完整的測試集于競賽結(jié)束前一周發(fā)放,作為最終排名依據(jù)。

表3 競賽組織流程
此次競賽總注冊報(bào)名的隊(duì)伍達(dá)1062支,覆蓋眾多高校、科研機(jī)構(gòu)及企業(yè),其中包含了128支來自美、英、日等14個(gè)國家的國際隊(duì)伍。最終共有153支隊(duì)伍累計(jì)提交了1 489份系統(tǒng)結(jié)果。競賽期間,參賽系統(tǒng)整體水平提升顯著,ROUGE-L評價(jià)指標(biāo)上由最初的35.96提升至終賽的63.62,超過半數(shù)系統(tǒng)的效果都優(yōu)于官方提供的基線系統(tǒng)。
3 評價(jià)結(jié)果
在本報(bào)告中對參賽系統(tǒng)依據(jù)自動(dòng)評價(jià)的ROUGE-L評分排序進(jìn)行順序編號,將系統(tǒng)編號替代系統(tǒng)名稱指代各個(gè)系統(tǒng)。本報(bào)告中將重點(diǎn)就TOP10系統(tǒng)進(jìn)行評價(jià)和分析,完整系統(tǒng)結(jié)果詳見競賽官網(wǎng)[注]http://mrc2018.cipsc.org.cn/。
3.1 自動(dòng)評價(jià)結(jié)果
排名前10系統(tǒng)整體的自動(dòng)評價(jià)效果如表4所示,排名前10系統(tǒng)在不同問題類型下的自動(dòng)評價(jià)效果如表5所示。各系統(tǒng)在不同數(shù)據(jù)來源及問題類型下的對比如圖1所示。

表4 TOP10系統(tǒng)自動(dòng)評價(jià)結(jié)果
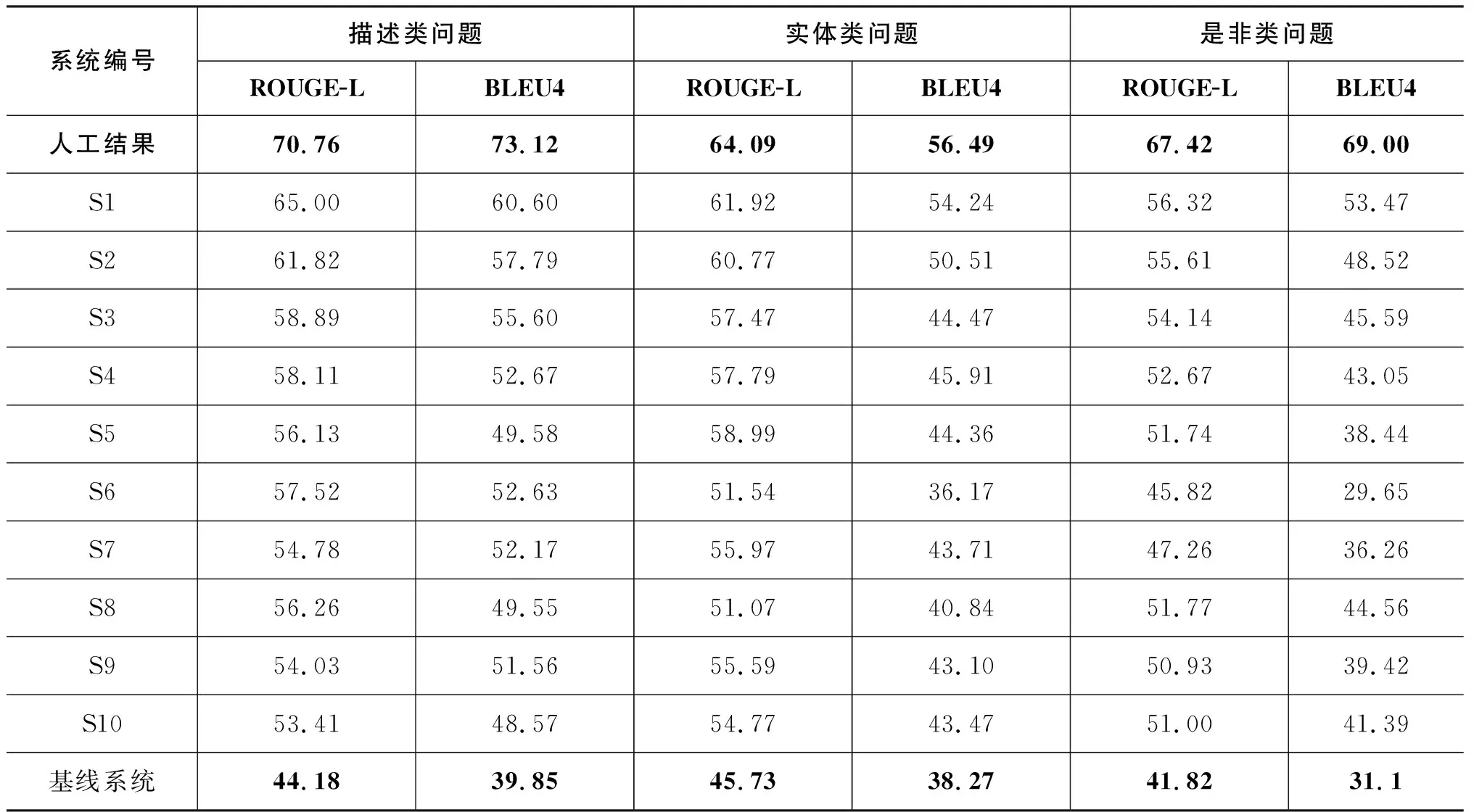
表5 TOP10系統(tǒng)在不同問題類型下的自動(dòng)評價(jià)結(jié)果
從數(shù)據(jù)集來源上看,如圖1所示,Zhidao來源的結(jié)果普遍優(yōu)于同系統(tǒng)的Search部分結(jié)果。相比之下,如表4所示,人類閱讀理解的效果在不同來源的數(shù)據(jù)上未顯示出明顯效果差距。在不同問題類型方面,如圖1所示,各系統(tǒng)在描述類型和實(shí)體類型問題上的答案的自動(dòng)評價(jià)效果相對較好,而在是非類問題上效果相對較差。而如表5所示,人工的效果則在實(shí)體類型的問題上表現(xiàn)相對一般,在其他兩類問題上效果相對較好。
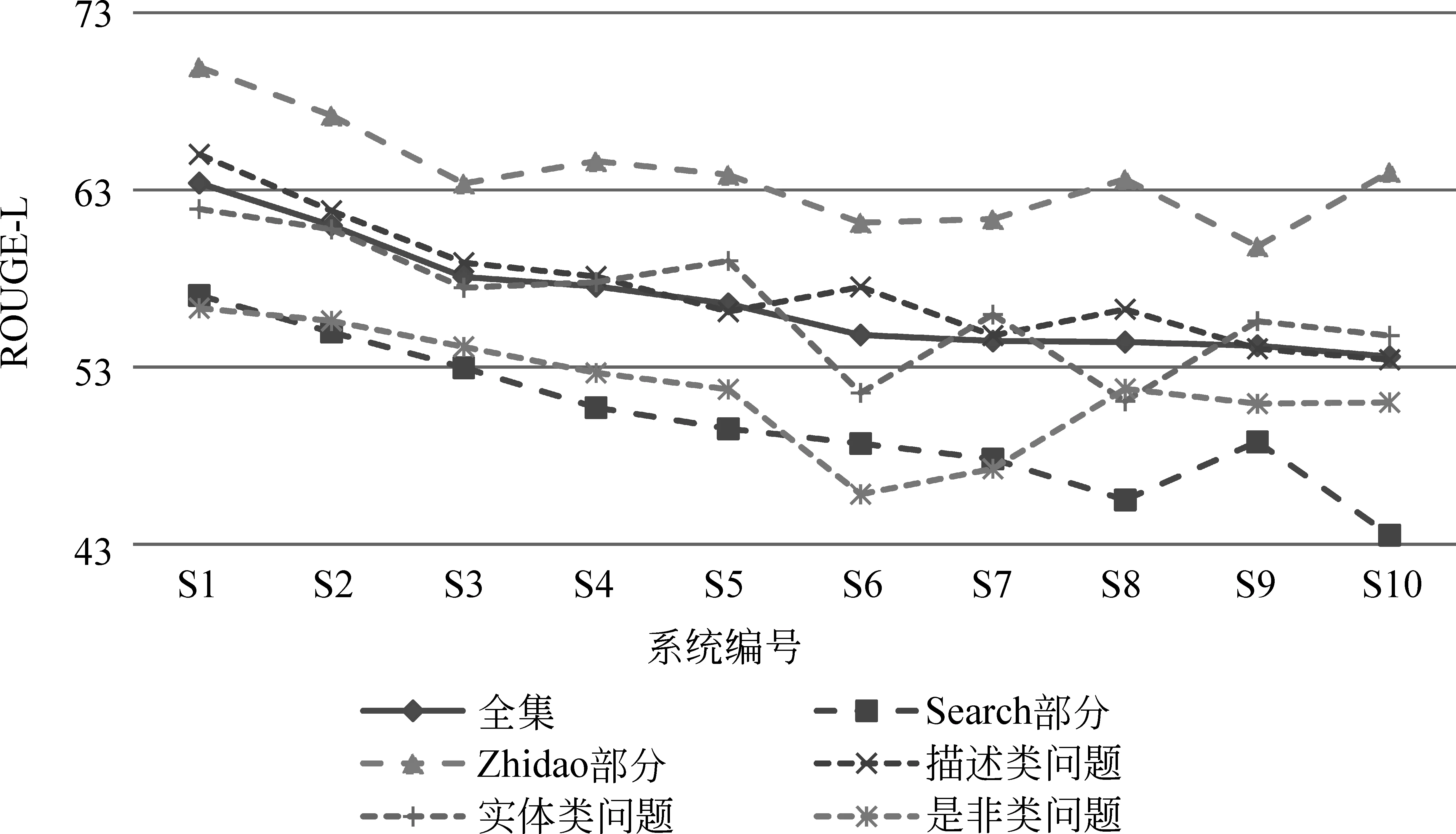
圖1 各系統(tǒng)在不同數(shù)據(jù)來源及問題類型下的效果對比
3.2 人工評價(jià)結(jié)果
自動(dòng)排名前10系統(tǒng)的人工評價(jià)評分均值效果如表6所示。對于所有系統(tǒng)和問題,五人評分的多數(shù)一致率達(dá)94.7%,評分質(zhì)量相對可靠。系統(tǒng)間的人工評價(jià)結(jié)果顯著性檢驗(yàn)見附表2。
如表6所示,參賽系統(tǒng)整體最高分為2.20,距人工評價(jià)的3分滿分評價(jià)仍有一定差距。在不同類型問題方面,描述類/實(shí)體類/是非類問題的最高人工評分分別為2.25/2.07/2.33,其中是非類型答案在人工評價(jià)標(biāo)準(zhǔn)下為效果最好部分,與自動(dòng)評價(jià)中是非類型答案效果最差的結(jié)論不一致。在不同數(shù)據(jù)來源方面,各系統(tǒng)的Zhidao部分結(jié)果的人工評價(jià)均高于Search部分的結(jié)果,該結(jié)論與自動(dòng)評價(jià)結(jié)論一致。
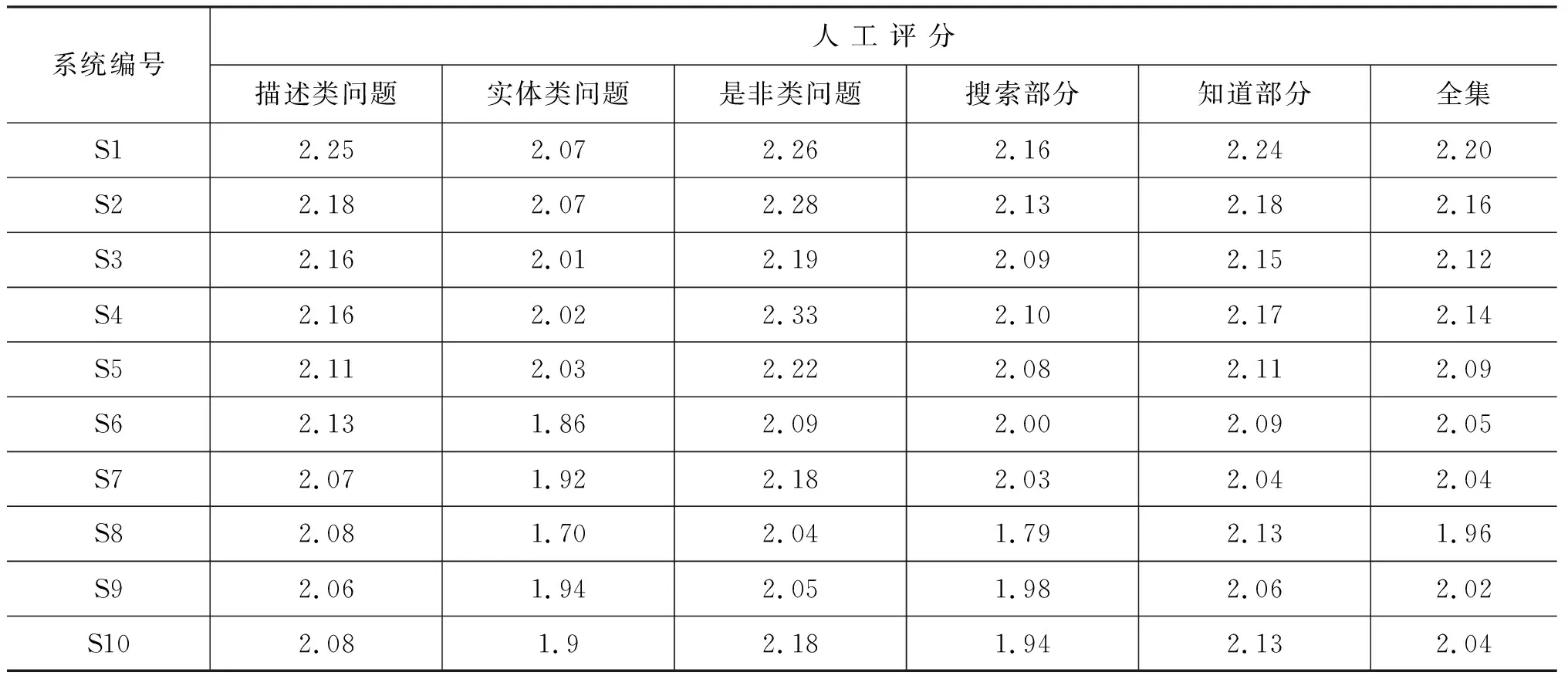
表6 TOP10系統(tǒng)人工評價(jià)結(jié)果
人工評估結(jié)果與自動(dòng)評估結(jié)果在不同情況下的排序相關(guān)性如表7所示,其中在測試集全集上的自動(dòng)/人工排序相關(guān)性達(dá)0.92,整體排序基本一致。在不同類型問題方面,描述類和實(shí)體類問題排序基本與自動(dòng)排序結(jié)論一致,其中實(shí)體類型自動(dòng)/人工排序相關(guān)性最高,而是非類型問題上當(dāng)前自動(dòng)/人工評價(jià)相關(guān)度較低。在不同數(shù)據(jù)來源方面,自動(dòng)/人工評價(jià)相關(guān)度均較高,相對而言Search部分來源排序相關(guān)性較Zhidao部分略高。因此自動(dòng)評價(jià)指標(biāo)在效果在整體上效果良好,但對于是非類型的評估有待進(jìn)一步改進(jìn)。

表7 人工評估與自動(dòng)評估的系統(tǒng)排序相關(guān)性
TOP10系統(tǒng)總體和TOP1參賽系統(tǒng)人工評分分值分布如表8所示。其中可以看出TOP10系統(tǒng)平均可以基本解決(答案評分達(dá)2~3分)75%以上的閱讀理解問題,而TOP1系統(tǒng)可以基本解決82%的問題。完全回答錯(cuò)誤的部分占比均小于10%。
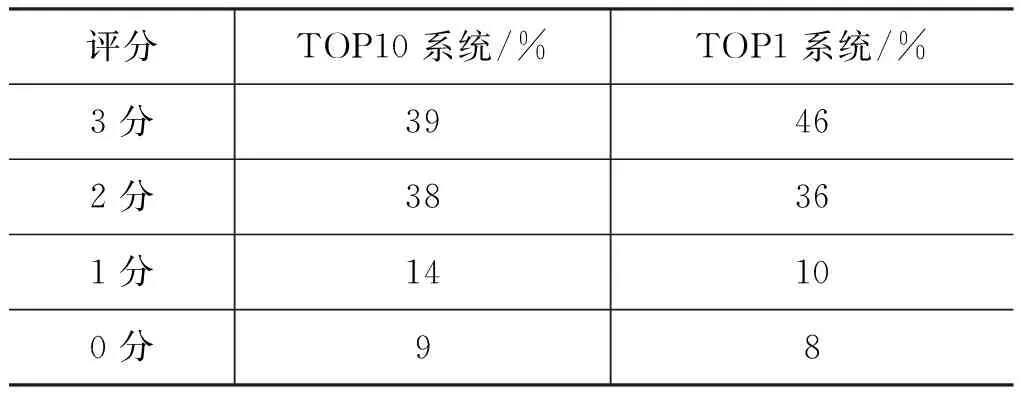
表8 TOP10總體/TOP1參賽系統(tǒng)人工評分分布
4 結(jié)果分析
4.1 主要錯(cuò)誤分析
為了更好地進(jìn)行錯(cuò)誤分析,人工評價(jià)時(shí)對主要錯(cuò)誤類型進(jìn)行了標(biāo)注。主要錯(cuò)誤類型如表9所示。不同的錯(cuò)誤類型可能同時(shí)出現(xiàn)在一個(gè)答案中,在標(biāo)注時(shí)僅標(biāo)注該答案的一個(gè)最主要錯(cuò)誤類型。
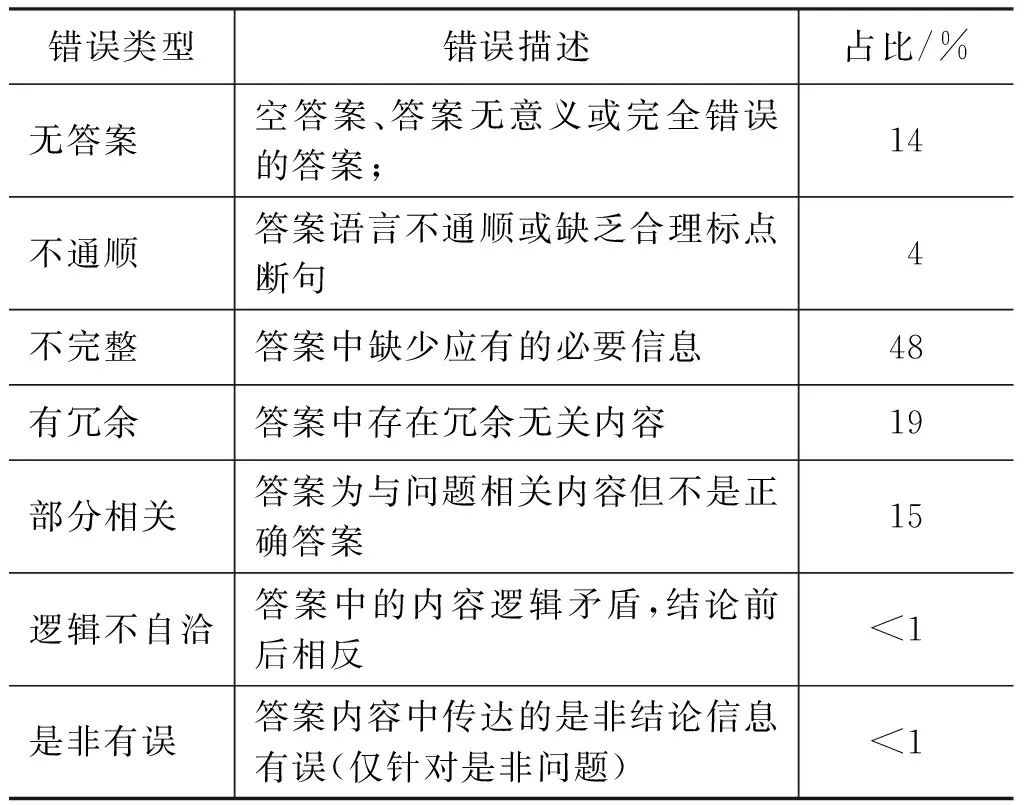
表9 答案主要錯(cuò)誤類型
表9中給出了所有參賽系統(tǒng)的錯(cuò)誤類型分布。其中所有錯(cuò)誤中的“不完整”和“有冗余”類型錯(cuò)誤的占比最大,占錯(cuò)誤總量的67%。這兩類錯(cuò)誤的直接原因可以歸結(jié)為,參賽閱讀理解系統(tǒng)有能力找到相關(guān)答案,但答案邊界定位不夠準(zhǔn)確。因此,當(dāng)前閱讀理解系統(tǒng)主流的答案邊界預(yù)測框架的改進(jìn)空間仍然很大,這類問題也是當(dāng)前閱讀理解技術(shù)所需重點(diǎn)解決的問題之一。相比之下,由于相關(guān)性問題導(dǎo)致的“無答案”的錯(cuò)誤占錯(cuò)誤總量14%,說明當(dāng)前系統(tǒng)在答案相關(guān)性匹配上獲得的效果較好,但仍然有改進(jìn)空間。而錯(cuò)誤中涉及到邏輯類型的“部分相關(guān)”和“邏輯不自洽”錯(cuò)誤也占有相當(dāng)部分,該類型錯(cuò)誤的主要原因可能為系統(tǒng)未能深入理解答案內(nèi)容邏輯,給出了相關(guān)但錯(cuò)誤的答案。因此當(dāng)前閱讀理解技術(shù)在答案內(nèi)容上如何進(jìn)行進(jìn)一步的邏輯建模仍然有待深入研究。
4.2 不同數(shù)據(jù)來源錯(cuò)誤分析
所有參賽系統(tǒng)在不同數(shù)據(jù)來源下的錯(cuò)誤類型分布如圖2所示。其中Zhidao來源上的錯(cuò)誤相對集中,有超過56%來自于“不完整”錯(cuò)誤,而其他問題相對Search來源數(shù)據(jù)錯(cuò)誤較少。其可能的主要原因?yàn)閆hidao來源數(shù)據(jù)為已經(jīng)人工處理的問題相關(guān)數(shù)據(jù),因此文檔數(shù)據(jù)中天然存在的內(nèi)容冗余和不相關(guān)問題較少,所以答案邊界定位的問題易集中體現(xiàn)在“不完整”的錯(cuò)誤上。
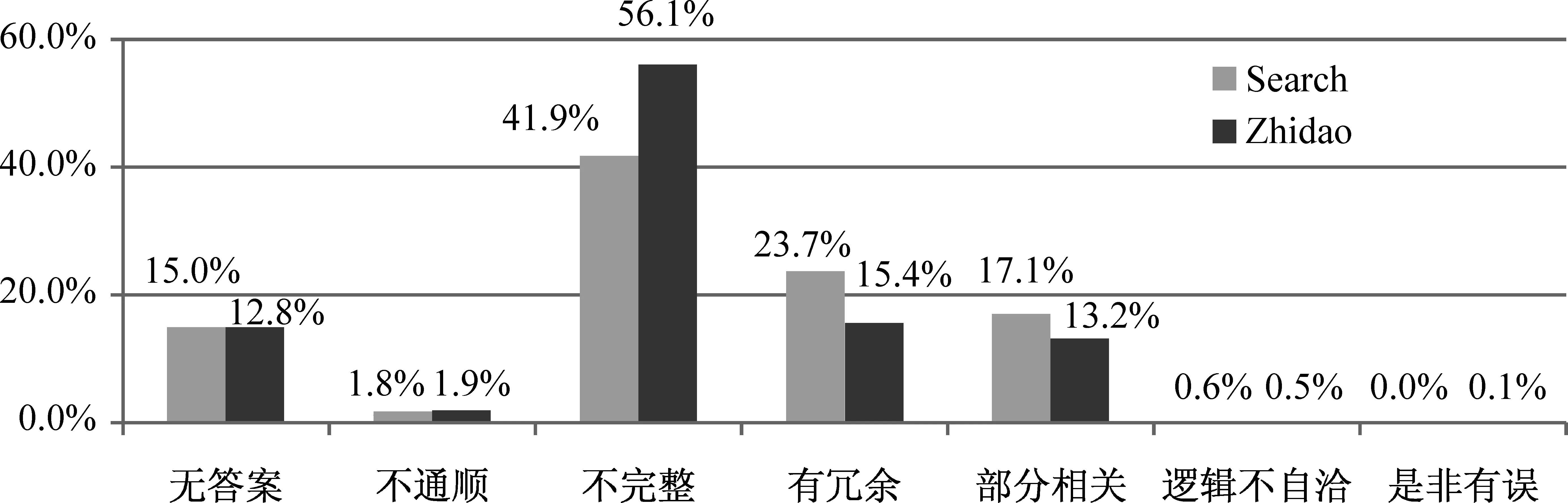
圖2 不同數(shù)據(jù)來源條件下的錯(cuò)誤類型分布
4.3 不同問題類型錯(cuò)誤分析
不同問題類型下參賽系統(tǒng)的錯(cuò)誤類型分布如圖3所示。在描述類問題中最突出的錯(cuò)誤為“不完整”,實(shí)體類問題中分布突出的錯(cuò)誤為“無答案”及“有冗余”錯(cuò)誤,是非類問題相對突出的錯(cuò)誤為涉及答案邏輯的“部分相關(guān)”、“邏輯不自洽”以及特有的“是非有誤”錯(cuò)誤。由此我們可以看出,不同問題類型上的錯(cuò)誤分布不同、特點(diǎn)明顯,所需解決的難點(diǎn)均不相同,因此針對不同問題類型進(jìn)行差異性建模對于提升已有閱讀理解系統(tǒng)效果具有積極意義。
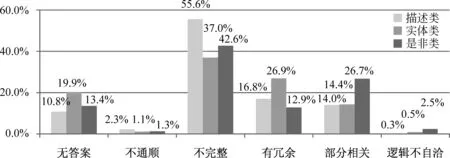
圖3 不同問題類型條件下答案的錯(cuò)誤類型分布
4.4 系統(tǒng)技術(shù)應(yīng)用統(tǒng)計(jì)
我們采用調(diào)查問卷的方式對參賽系統(tǒng)所采用的技術(shù)進(jìn)行統(tǒng)計(jì)分析,梳理當(dāng)前閱讀理解技術(shù)方面流行或有效的技術(shù)模塊。其中發(fā)放110份問卷,返回有效數(shù)據(jù)39份,其中TOP10系統(tǒng)均提交了有效問卷,具體TOP10應(yīng)用技術(shù)統(tǒng)計(jì)點(diǎn)如表10所示。大部分參賽系統(tǒng)均采用了基線系統(tǒng)進(jìn)行改進(jìn),少量參賽系統(tǒng)采用了自研或其他開源系統(tǒng)。在建模方法方面,多數(shù)參賽系統(tǒng)選擇的是流行的多層次注意力建模方法,并采用了是非判斷和文檔排序的算法模塊,僅有少量的系統(tǒng)采用了語言生成改寫及強(qiáng)化學(xué)習(xí)方法。TOP10各系統(tǒng)的詳細(xì)系統(tǒng)描述參見附表3。
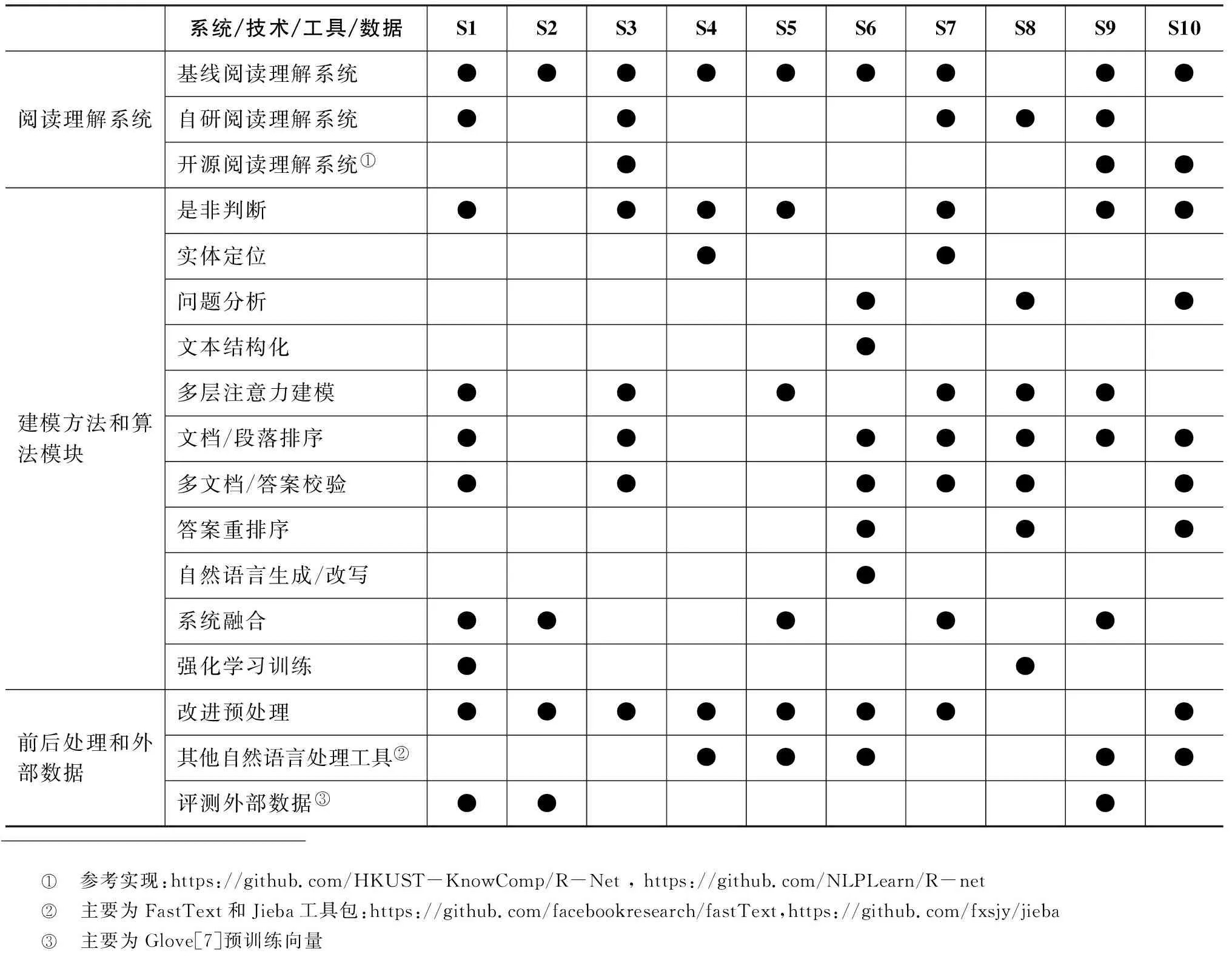
表10 參賽閱讀理解系統(tǒng)采用的技術(shù)統(tǒng)計(jì)
實(shí)心圓點(diǎn)代表該系統(tǒng)采用了相關(guān)技術(shù)。
5 總結(jié)
2018機(jī)器閱讀理解技術(shù)競賽得到學(xué)術(shù)界和工業(yè)界學(xué)者的廣泛關(guān)注和參與。參賽系統(tǒng)效果提升顯著,對推動(dòng)閱讀理解技術(shù)發(fā)展起到了積極的作用。在人工評價(jià)標(biāo)準(zhǔn)下對參賽系統(tǒng)的分析發(fā)現(xiàn),當(dāng)前優(yōu)秀的參賽系統(tǒng)已能基本正確回答75%以上的問題,但與人類閱讀理解能力相比仍然存在一定差距。其中,閱讀理解系統(tǒng)的錯(cuò)誤主要集中在答案邊界定位、答案冗余等方面,現(xiàn)有專注答案邊界定位的閱讀理解技術(shù)和模型仍然有很大的改進(jìn)空間。對于不同的問題類型,參賽系統(tǒng)所表現(xiàn)出來的錯(cuò)誤分布有顯著不同,針對不同問題類型進(jìn)行差異性建模是可行的改進(jìn)方向。在評價(jià)標(biāo)準(zhǔn)方面,當(dāng)前的閱讀理解自動(dòng)評價(jià)指標(biāo)整體上與人工評價(jià)具有較好的相關(guān)性,但對于是非類型問題答案的自動(dòng)評價(jià)仍然需要進(jìn)一步的研究和探索。
猜你喜歡
工業(yè)設(shè)計(jì)(2022年8期)2022-09-09 07:43:20
石油瀝青(2021年4期)2021-10-14 08:50:44
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2021年10期)2021-03-02 05:52:06
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(shù)(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(yè)(2019年4期)2019-05-11 09:27:34
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
中國教育技術(shù)裝備(2015年19期)2015-03-01 02:43:07
中國工程咨詢(2015年2期)2015-02-14 02:59:26
