基于無服務器架構的邊緣AI計算平臺
2018-11-16 06:34:28劉暢毋濤徐雷
信息通信技術 2018年5期
劉 暢 毋 濤 徐 雷
中國聯通研究院 北京 100176
1 AI計算平臺
1.1 AI的定義
AI(Artificial Intelligence)即人工智能,是計算機科學的一個分支領域[1]。1956年夏季,以麥卡賽、明斯基、羅切斯特和申農等為首的一批有遠見卓識的年輕科學家在一起聚會,共同研究和探討用機器模擬人類智能的一系列相關問題,并首次提出了“人工智能”這一術語,它標志著“人工智能”這門新興學科的正式誕生。
尼爾遜教授對人工智能下了這樣一個定義:“人工智能是關于知識的學科,一個關于怎樣表示知識以及怎樣獲得知識并使用知識的科學。”而另一個美國麻省理工學院的溫斯頓教授認為:“人工智能就是研究如何使計算機去做過去只有人才能做的智能工作。”這些說法都很好地反映了人工智能學科的基本思想和基本內容,即人工智能是研究人類智能活動的規律、構造具有一定智能的人工系統,研究如何讓計算機去完成以往需要人的智力才能勝任的工作,也就是研究如何應用計算機的軟硬件來模擬人類某些智能行為的理論、方法和技術。
1.2 AI計算平臺
AI計算平臺的目標是通過大量的歷史數據訓練得到一個盡量貼合應用需求的模型,然后通過不斷的迭代優化完善模型,最終使該模型在應用推理過程中的結果最貼近期望值[2]。在訓練過程中,AI計算平臺需要大量的計算,才能保證模型的時效性和準確性,所以需要將系統部署在一個大型的計算集群中,云計算服務剛好滿足這種需求,部署在云中是目前主流的部署模式。如圖1所示,AI計算平臺主要分為三個部分。

圖1 傳統AI計算平臺
1)數據預處理。AI建模所使用的數據源通常是海量的大數據,這些數據的維度眾多,數據質量參差不齊,甚至還有很多垃圾數據以及不完整的數據,如果不進行處理,會給建模的過程帶來很大的困難,也會影響模型的準確程度,所以,在AI的建模過程中,數據預處理是非常重要的工作。數據預處理主要包括數據清理、數據集成、數據變換以及數據歸約,最終把它歸類到AI的計算模型中。
2)模型訓練。目前,針對不同的應用有不同的訓練算法,模型的訓練首先要選擇與應用相匹配的算法。在選擇了合適的算法之后利用計算集群強大的計算資源結合歷史數據對模型不斷的迭代優化來形成最終的AI模型、算法公式以及一些相關的參數。隨著應用過程中數據的不斷累積,模型還可以不斷地進行優化,以使計算結果更加接近期望值。
3)應用推理。在實際的應用中,將實際數據帶入上面第二步訓練得到的模型進行推理計算,可以得到期望的推理結果。
2 無服務器架構
無服務器(Serverless)架構可以分成兩種類型[3]。一種是BaaS(Backend as a Service,后端即服務),例如消息隊列、CDN、云對象存儲、云數據庫等,這些服務主要是承載數據的存儲。另一種是FaaS(Function as a Service,函數即服務),這種方式主要是承載用戶的計算功能,更多是對用戶的計算進行托管。第二種方式是無服務器架構的核心技術點。
本文主要介紹采用FaaS方式的架構。采用此種架構,用戶首先要將代碼和配置提交到云平臺上,代碼即用戶為實現某一個函數功能編寫的一份代碼或者代碼包;配置則是指本身對于函數運行環境的配置,使用的是哪種環境、所需的內存、超時時間等,以及觸發函數運行的觸發器的配置。因為整個FaaS的運行方式是觸發式運行,觸發就需要有一個事件來源,而事件來源可以有很多種。例如當用戶上傳一張圖片或者刪除一張圖片時,就會產生一個事件,這個事件會觸發云函數的運行;例如和API網關的對接,也可以作為事件來源,在用戶的HTTP請求到達網關之后,API網關會把該請求作為事件轉發給云函數,觸發云函數的運行,云函數拿到請求之后進行處理,生成響應給到用戶。
如圖2所示,Serverless的運行方式是按需運行,僅在設定的觸發器上有事件產生時才會運行。圖中左側,是用戶將代碼和配置提交到Serverless平臺進行保存,當設定好的事件產生后,針對每一個事件都會拉起一個函數實例,實現觸發式運行。
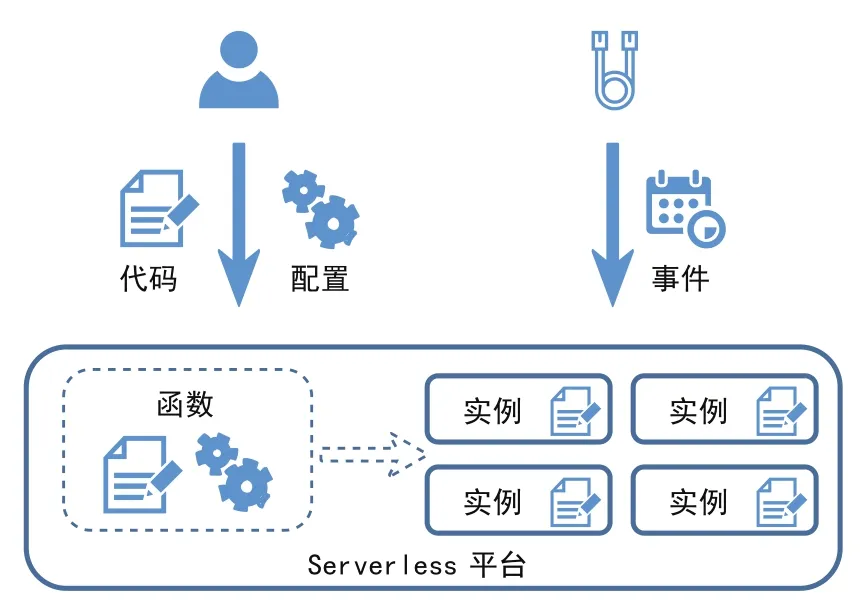
圖2 Serverless平臺工作流程
因為函數本身是托管型的,用戶本身無法感知到實例在哪里運行。Serverless平臺背后有個大的計算資源池,用戶實例觸發之后,平臺會從資源池中隨機選取可運行的位置,把用戶的函數實例在對應位置上跑起來。因此,整個調度過程或者事件來臨之后的函數運行環境的擴縮容過程,都是由平臺進行的。對用戶來說,調度的粒度更細了,而且調度也都托管給平臺了,用戶自身只需考慮功能的實現,而一切和運維相關的問題都可以由平臺的提供商來解決。
3 MEC技術
MEC(Multi-Access Edge Computing)即多接入邊緣計算[4]。ETSI對MEC的標準定義是:在網絡邊緣提供IT服務環境和云計算能力。就是將應用、內容和核心網的部分業務處理和資源調度的功能一同部署到靠近接入側的網絡邊緣,通過將業務靠近用戶處理,以及應用、內容與網絡的協同,來提供可靠、高效的業務體驗。
近年來,隨著AR/VR、車聯網、高清視頻以及物聯網等應用的興起,傳統的網絡結構已經逐漸不堪重負,因此催生了MEC的出現,將網絡業務“下沉”[5]到更接近用戶的無線接入網側,從而帶來三個好處[6]。
1)用戶感受到的傳輸時延減小;2)網絡擁塞被顯著控制;3)更多的網絡信息和網絡擁塞控制功能可以開放給開發者。
4 基于無服務器架構的邊緣AI計算平臺
本文在傳統的AI計算平臺基礎上進行創新,提出了一個新的基于無服務器架構的邊緣AI計算平臺方案。本節首先分別介紹引入無服務器架構以及引入MEC技術對AI計算平臺的改進情況,之后對整體方案進行介紹說明。
4.1 無服務器架構加速AI計算平臺
如第二節所述,從整個的計算過程來說,對于傳統的數據存儲過程,數據產生后,會先把數據進行緩存或者存儲,比如以對象存儲文件的形式進行保存,或者在數據庫中以結構化形式存儲下來,之后再進行分析及應用。
利用無服務器架構后,計算過程可以有很大的加速。如圖3所示,可以在事件產生的時候就立刻拉起運行實例對數據進行處理,因此整個處理過程就變成了先計算,再對結果進行保存,從而加速了數據的存儲以及后續調取的過程,也大大節省了存儲需要的空間。因為AI計算平臺在模型訓練的過程中需要頻繁地對數據進行計算和存儲,所以引入無服務器架構可以顯著提高計算平臺的性能。

圖3 利用無服務器架構加速AI計算平臺
4.2 MEC技術加速AI計算平臺
在利用無服務器架構對存儲過程進行了加速之后,我們仍需要想辦法對計算過程進行進一步加速。對于傳統應用來說,數據在終端側產生,上傳到云端進行處理并保存結果。在AI的推理階段,需要頻繁地利用數據模型進行推理運算,但是計算量并不是很大。如果每次計算都要將數據上傳到云端進行處理,不但增加了數據處理的時延,也給整個網絡帶來了不小的壓力。
如圖4所示,利用MEC技術可以使處理過程更加靠近用戶,把一部分計算資源下放到靠近用戶的網絡邊緣。傳統的云計算方式,無論是使用容器,或是使用云主機,運算能力都是集中部署在云端的,而邊緣計算技術可以把運算能力下放到中心云端之外,使計算能力更接近真正的用戶,更加靠近設備端,免去了數據從終端到云端的傳輸過程,從而使計算過程可以盡快地在較近的計算節點中進行處理。因此,利用MEC可以將AI計算平臺推理計算過程的時延進一步降低,也增加了系統的可靠性。
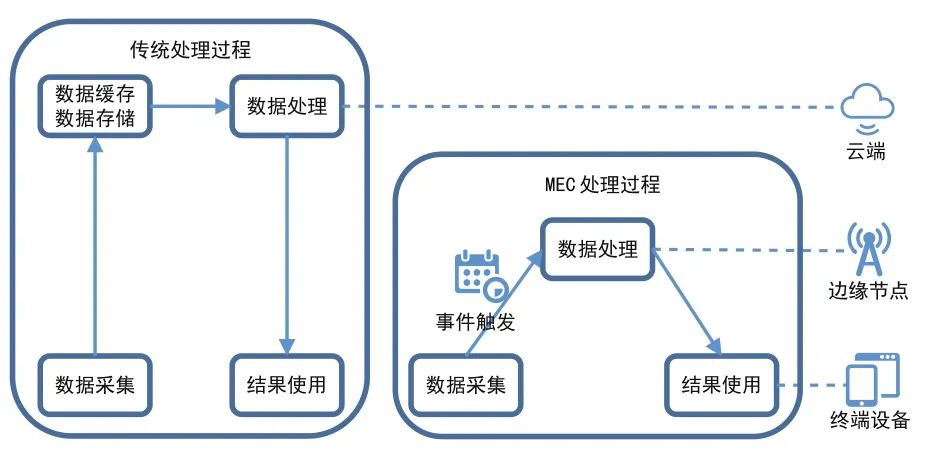
圖4 利用MEC技術加速AI計算平臺
4.3 基于無服務器架構的邊緣AI計算平臺
構建一個AI計算平臺通常包括三個步驟。第一步是對預處理后的數據進行訓練。第二步是驗證測試數據的準確率情況。這兩個步驟需要多次的迭代重復,直到使該算法實現了預期的精度。通過每次的迭代過程,算法可以學習到更多的數據并發現新的模式,這可以使模型的效率和準確率都得到提升。這兩個步驟最終得出的是一個機器學習模型,它的參數被不斷調整以處理后續產生的未知數據。第三個步驟也是最后一步,就是使用數據調用模型來計算預期的結果,這可能是基于新數據的預測、分類或分組。
前兩個階段因為涉及到機器學習所以需要大量計算工作,這需要由部署在云端的大量計算資源來滿足。但是,第三個階段的應用推理過程卻不需要很多資源,所以非常適合將這部分功能部署在邊緣設備上。它是一段代碼,其中包含了計算的模型以及基于前兩個階段訓練和驗證的一系列參數。基于這些預定義的參數,它將在有新數據到來的時候對其進行分析。
如圖5所示,本文提出了一種新的系統模型,在構建AI平臺的前兩個階段,利用Serverless框架,使訓練和測試模塊可以按需觸發式執行,節省了這個階段的計算過程和存儲過程,也簡化了云端的運維工作。在第三階段,利用MEC技術將AI平臺的推理模塊下放到網絡邊緣設備上,從而加速了計算過程。在終端側有AI計算需求時,部署在網絡邊緣的Serverless框架可以按需建立AI推理計算實例,可以在請求量抖動時按需進行資源的擴縮容,使整個平臺的資源利用率更高,穩定性更強。

圖5 基于無服務器架構的邊緣AI計算平臺
綜上,盡管AI計算平臺的訓練和驗證階段需要在擁有大量計算資源的云端進行,但推理階段可以通過邊緣計算技術在網絡的邊緣設備上進行計算,再加上與Serverless架構的結合,對整個平臺的計算過程和存儲過程都有顯著的提速,而且也簡化了系統的運維工作。
5 挑戰和未來研究方向
利用Serverless框架和MEC技術,很好地解決了AI計算平臺目前面臨的問題。但是,在為我們帶來便利和效益的同時,它還存在一些問題和挑戰[7]。
1)計費問題。由于在部署邊緣計算平臺時將服務下沉到了網絡的邊緣,流量在邊緣節點上進行了本地化卸載,而沒有通過一個核心的節點,因此計費的功能很難實現。對于該問題,目前各公司已經有了自己傾向的解決方案,但是仍然沒有統一的方案,移動邊緣計算平臺的標準化工作也尚未涵蓋該部分。該問題需要設備供應商、OTT、運營商等多方的共同努力并積極探索。
2)安全問題。由于服務的下沉也帶來一些安全問題,例如可能存在一些不受信任的終端或移動邊緣應用開發者的非法接入問題,因此需要在接入側和邊緣計算節點之間建立鑒權流程以及安全的通信隧道,以保證數據的機密性和完整性,并保證網絡的安全。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
核科學與工程(2015年4期)2015-09-26 11:59:03
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
