基于大數據平臺的線網中心運營指揮系統的運營指標分析技術*
2018-11-16 06:55:28陳莉莉周映江
城市軌道交通研究 2018年11期
胡 波 李 冰 陳莉莉 周映江
(1.南瑞集團(國網電力科學研究院)有限公司,210003,南京;2.國電南瑞科技股份有限公司,210061,南京;3.南京郵電大學自動化學院,210023,南京//第一作者,高級工程師)
隨著各個城市軌道交通線路由單一化逐漸向網絡化發展,軌道交通運營中產生并積累了大量的數據。如何有效地處理和分析這些結構化和非結構化數據,挖掘其中有價值的信息,通過海量數據的采集、整理和分析,提高軌道交通的運營水平,提升科學決策能力,日益成為業界關注的重點及研究方向。
目前,地鐵線網中心運營指揮系統(TCC)通常采用數據倉儲MPP(massively parallel processing)進行數據分析及管理,對于地鐵運營海量的數據,其在客流分析、能效管理、運營指標分析等方面尚異常薄弱,沒有達到提升運營水平的目的[1-3]。本文提出一種基于大數據平臺的運營指標分析的方法,通過研究數據挖掘技術,完成對TCC海量數據的分析。通過合理的數據模型設計搭建大數據平臺,進行數據統計和建模,挖掘數據的深層價值,從而提升軌道交通信息服務能力及運營水平,提升效益,降低成本。
1 軌道交通TCC數據
1.1 TCC數據分類
軌道交通運營中每時每刻都產生并積累大量的數據,特別是非結構化數據,更是呈指數級增長。TCC的數據來源包括:各線路的綜合監控系統(ISCS,含電力監控與數據采集(PSCADA)、環境與設備監控系統(BAS)、火災報警系統(FAS)、站臺屏蔽門(PSD)、自動售檢票(AFC)等專業),以及信號(SIG)、閉路電視(CCTV)數據;自動售檢票清分中心(ACC)的客流數據;主變電所的PSCADA數據;來自能源管理系統的能效數據;視頻文檔等文件。根據數據的類型,分為結構化數據、非結構化數據和半結構化數據,具體說明如下:
結構化數據:主要包括ISCS(PSCADA、BAS、FAS、PSD、AFC等)、列車自動監控(ATS)、ACC、能源管理系統等。ACC系統提供客流數據和清分清算類數據,各線路ISCS和主變電所提供設備狀態類數據,ATS提供行車數據,能源管理系統提供能耗數據。
非結構化數據:主要包括CCTV視頻資料、圖紙、檔案文件、文檔,以及系統運行過程中生成的日志、視頻、音頻、圖片文件等,如應急指揮系統執行過程中的歸檔記錄、歷史報表等。
半結構化數據:主要指系統中的XML、HTML文檔。
1.2 TCC數據特點
對TCC數據進行分析可知,TCC數據結構的復雜性主要表現為:
大規模:數據容量巨大,每年增量在幾十TB;
異構性:數據來源于各個系統,數據結構及類型千差萬別;
分布性:數據源的多樣性及跨地域性造就了數據的分布性;
動態性:每時每刻的實時數據。
2 大數據平臺
2.1 大數據介紹
大數據,指無法在一定時間范圍內用常規軟件工具進行捕捉、管理和處理的數據集合,是需要新處理模式才能具有更強的決策力、洞察發現力和流程優化能力的海量、高增長率和多樣化的信息資產。其不用隨機分析法(抽樣調查)這樣的捷徑,而采用所有數據進行分析處理[4]。
借助大數據平臺,整合SCADA、FAS、BAS、ATC、AFC、ACC等專業數據,實現客流、 行車、設備數據的集中統一,形成企業級數據統一視圖,實現企業數據標準化,再通過平臺強大的數據分析和數據挖掘能力,可幫助地鐵企業充分發掘潛在的數據價值,全面提升運營管理能力、科學規劃能力、應急輔助決策能力及公眾信息服務能力。
2.2 大數據平臺建設方案
進行數據分析首先需要選擇一種合適的數據平臺。本文采用處理效率及性能更佳的基于Hadoop的大數據平臺代替數據倉庫的MPP進行數據分析及存儲。大數據平臺的數據處理包括元數據處理、ETL(數據抽取、轉換及裝載)數據處理、數據挖掘等部分,本文主要涉及的是數據挖掘部分。大數據平臺的架構見圖1。
3 基于大數據的數據統計和預測
3.1 數據統計和預處理
TCC中的數據除了結構化數據,還包括照片、視頻、音頻、文檔、日志等非結構化數據,并且需要支持數十TB到PB級的數據存儲需求。采用分布式架構的大數據平臺,將數據倉庫部署在不同的服務器上,并將來自各個源的數據規整,以統一格式存儲在大數據平臺中。
首先要對數據源中的數據進行格式規整處理,再用清理、集成、變換、規約等預處理技術改善數據質量,從而提高數據分析的效率與質量。
3.2 數據挖掘和數據分析
所謂數據挖掘和數據分析,就是以業務為驅動,利用數據分析算法,從海量數據中發掘出其中隱含的模式。
數據分析方法一般包括估計、預測、關聯、聚類、分類等。分析的過程就是模型構建的過程。模型構建通常包括模型建立、模型訓練、模型驗證和模型預測四個步驟。模型的建立是一個反復的過程,需要仔細考察不同的模型以判斷優選。常見的數據分析方法見圖2。
3.3 客流數據分析
在TCC數據中挑選出客流信息,通過對客流數據進行建模分析,預測短期日常客流、實時客流及預估大客流。從ACC得來的客流數據和起點/終點(OD)數據信息,可通過客流和換乘的統計分析,進行路徑規劃和能效控制;可以監視客流數據進行客流預測;可分析實時斷面客流量和三色圖展示,協助進行客流引導。常用的分析方法為時間序列法和回歸分析法。
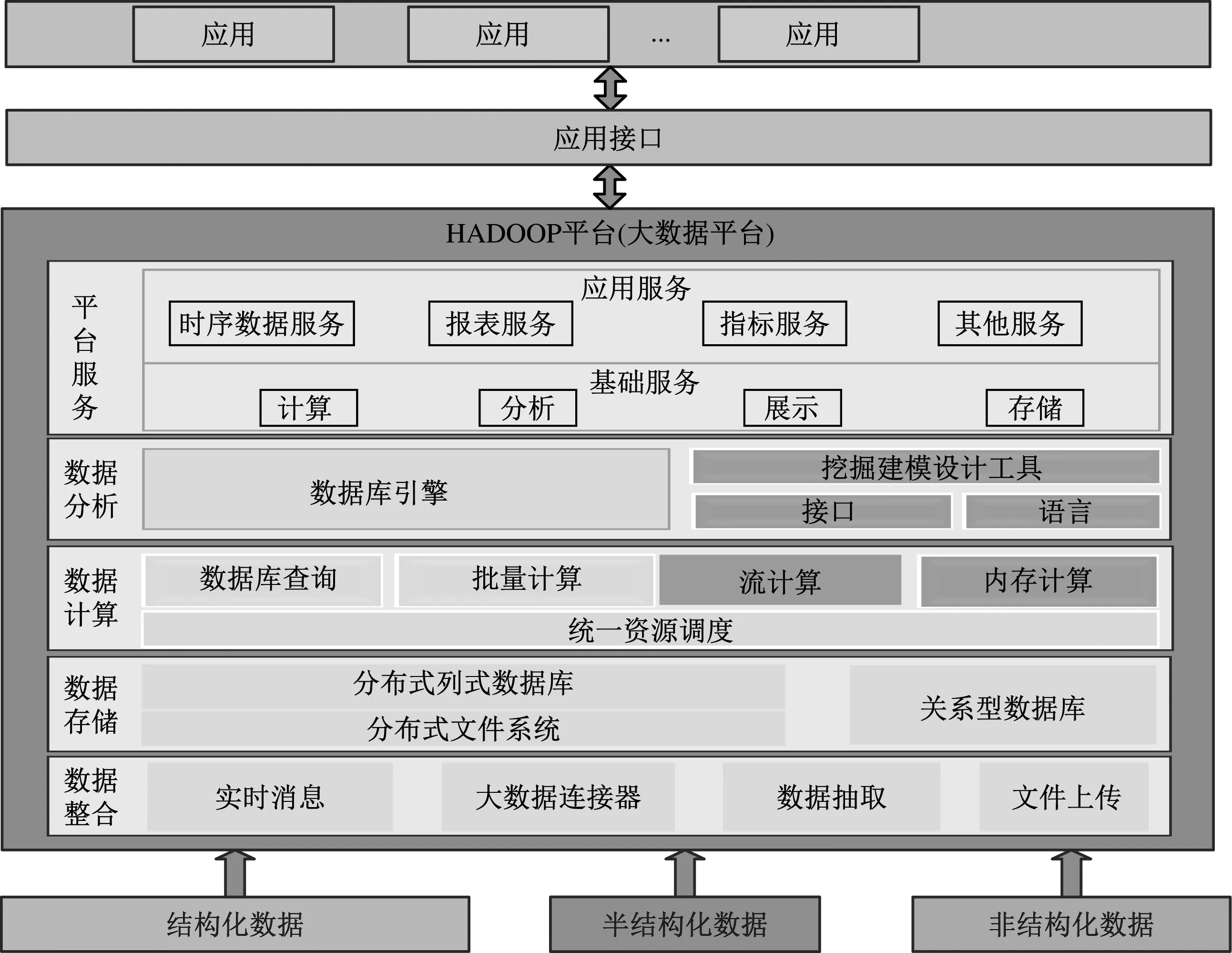
圖1 大數據平臺架構
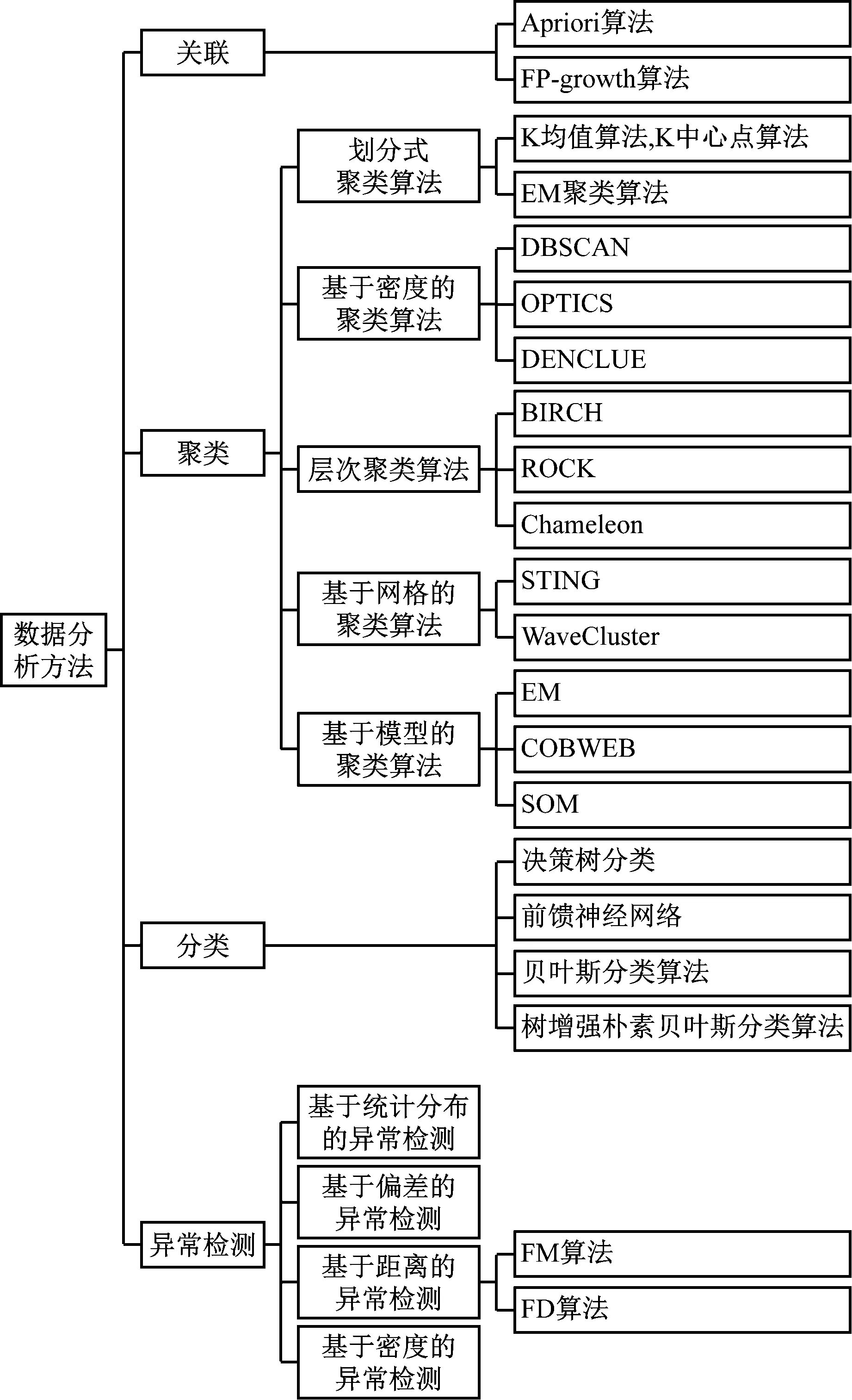
圖2 常見的數據分析方法
3.3.1 短期日常客流預測輸入
客流預測條件導入模塊通過指定日期條件(某天或者一段時間范圍內),從統計分析平臺加載AFC歷史客流數據作為預測參考數據,實現短期客流預測輸入功能。其數據流如圖3所示。
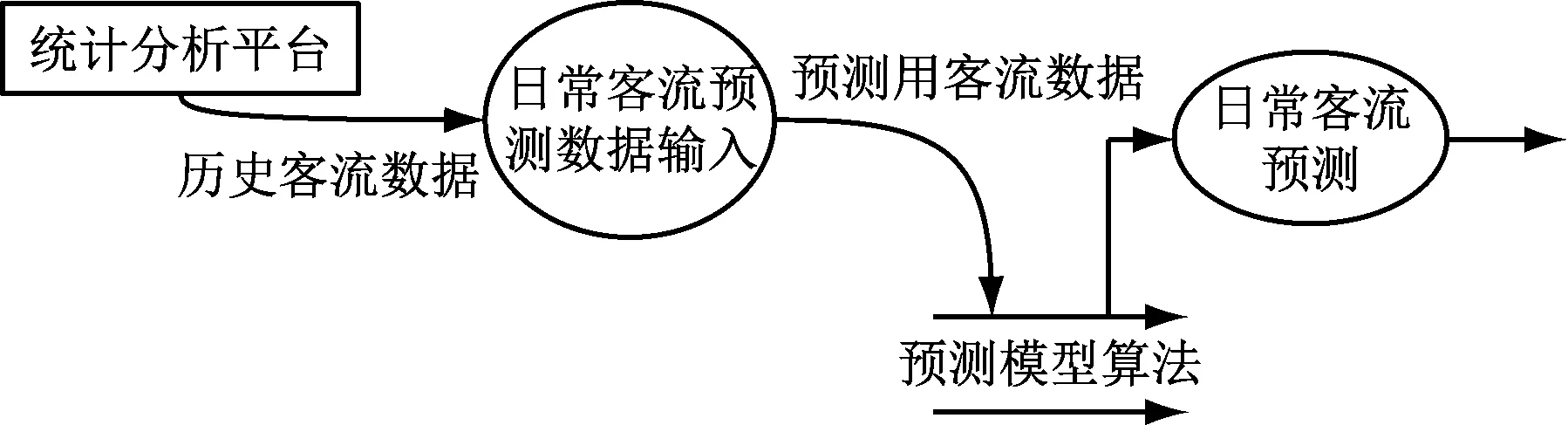
圖3 短期日常客流預測數據流圖
客流預測條件導入模塊從統計分析平臺加載歷史客流數據,界面可設置客流影響因素,包括大型活動車站等。
3.3.2 實時客流預測輸入
客流預測條件導入模塊通過指定日期條件(某天或者一段時間范圍內),從統計分析平臺加載AFC實時客流數據作為預測參考數據,實現實時客流預測輸入功能。其數據流如圖4所示。

圖4 實時客流預測數據流圖
客流預測條件導入模塊從統計分析平臺加載AFC實時客流數據,經過實時客流預測數據輸入功能對數據清洗/變換,保存為預測用的客流數據;客流預測模型管理模塊在正常情況下實時客流預測、中斷行車情況下客流預測、大客流情況下客流預測中讀取此數據,執行客流預測。
3.3.3 預知大客流預測輸入
客流預測條件導入模塊通過指定大客流事件的時間、車站,從統計分析平臺加載同類型的歷史客流數據作為預測參考數據,實現預知大客流預測輸入功能。其數據流如圖5所示。
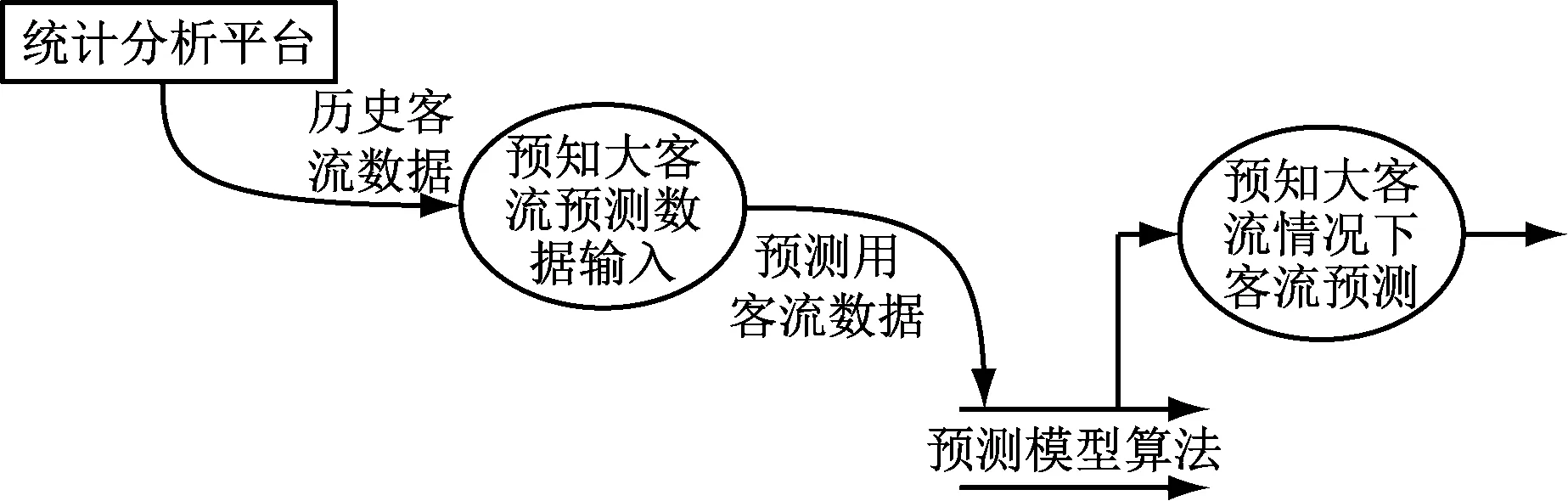
圖5 預知大客流預測數據流圖
客流預測條件導入模塊從統計分析平臺加載歷史客流數據,經過預知大客流預測數據輸入功能對數據清洗/變換,保存為預測用的客流數據;客流預測模型管理模塊在預知大客流情況下客流預測中讀取此數據,執行客流預測。
4 運營指標分析
4.1 運營指標體系
目前軌道交通行業常用的指標體系是國際地鐵聯盟CoMET指標體系和中國城市軌道交通MOPES指標體系。
CoMET的核心是建立衡量地鐵運營效率的關鍵績效指數系統,并建立有針對性的基準化分析方法。CoMET指標數據僅在聯盟內使用,對外有保密公約,所以不具有公開使用價值。
MOPES是為了加強軌道交通行業內部的密切聯系,統一運營績效評估指標和統計方式,樹立績效參照標桿,建立經驗交流平臺和組織開展專題攻關等。整個評價體系含基礎指標2類8個,績效指標6類75個。基礎指標包括線網指標和車站指標,是基礎設施的評價數據。績效指標包括客流指標、運行指標、服務指標、安全指標、能耗指標和成本指標,是在一定基礎設施條件下反映運營效率的主要指標[5]。
4.2 TCC常用運營指標分析
目前,通過大數據平臺可采集到以下數據:
(1) 從線路實時采集的數據,包括列車運行信息、電扶梯運營狀況、AFC閘機/售票機運營狀況、車站站廳站臺溫/濕度、火災報警等。
(2) 從線路定時采集的歷史數據,包括AFC閘機/售票機歷史運營狀況等。
目前TCC中的運營指標分析模塊,僅能對上述數據進行簡單的加工,做一些簡單的運營指標統計分析。這些分析主要集中在單一指標,并沒有深度挖掘不同數據之間的關系。
表1是TCC中核心統計的運營指標,可以看出,此三種指標目前互相孤立,之間沒有聯系。其實從能效管理的角度,通過閘機的通過率、電扶梯的使用率等判斷出人流量的大小,提前預測站內合適的溫濕度,可力保乘客乘車候車的舒適度,也能在一定程度上進行節能。

表1 現系統常用運營統計指標
4.3 進站量分析自適應預測溫濕度
溫濕度預測將所有的溫濕度預測業務按照預測方案組織起來,首先需創建溫濕度預測方案。在預測方案中設置預測的目標和具體的時間維度、空間維度條件,選擇預測的類型及應用的預測模型,并錄入與溫濕度預測方案相關的描述性信息,根據不同預測類型和預測模型的需要設置溫濕度預測的相關參數,完成預測方案的創建。客流預測流程各步驟如圖6所示。
通過大數據平臺,選擇相關的關聯算法,對車站進站量數據及站內溫濕度數據進行統計、訓練,通過計算機擬合出車站進站量與溫濕度之間的曲線,找出他們之間的內在關系。
5 結語
目前的地鐵TCC在運營指標分析及應急指揮方面功能薄弱,不能滿足實際運營的需求。本文研究了基于大數據平臺的城市軌道交通網絡化運營指揮中心的關鍵技術,利用大數據平臺對數據進行統計、挖掘,通過算法尋找相關聯的運營指標。通過對運營指標的綜合分析,可提升地鐵運營管理能力和應對突發應急事件的能力。
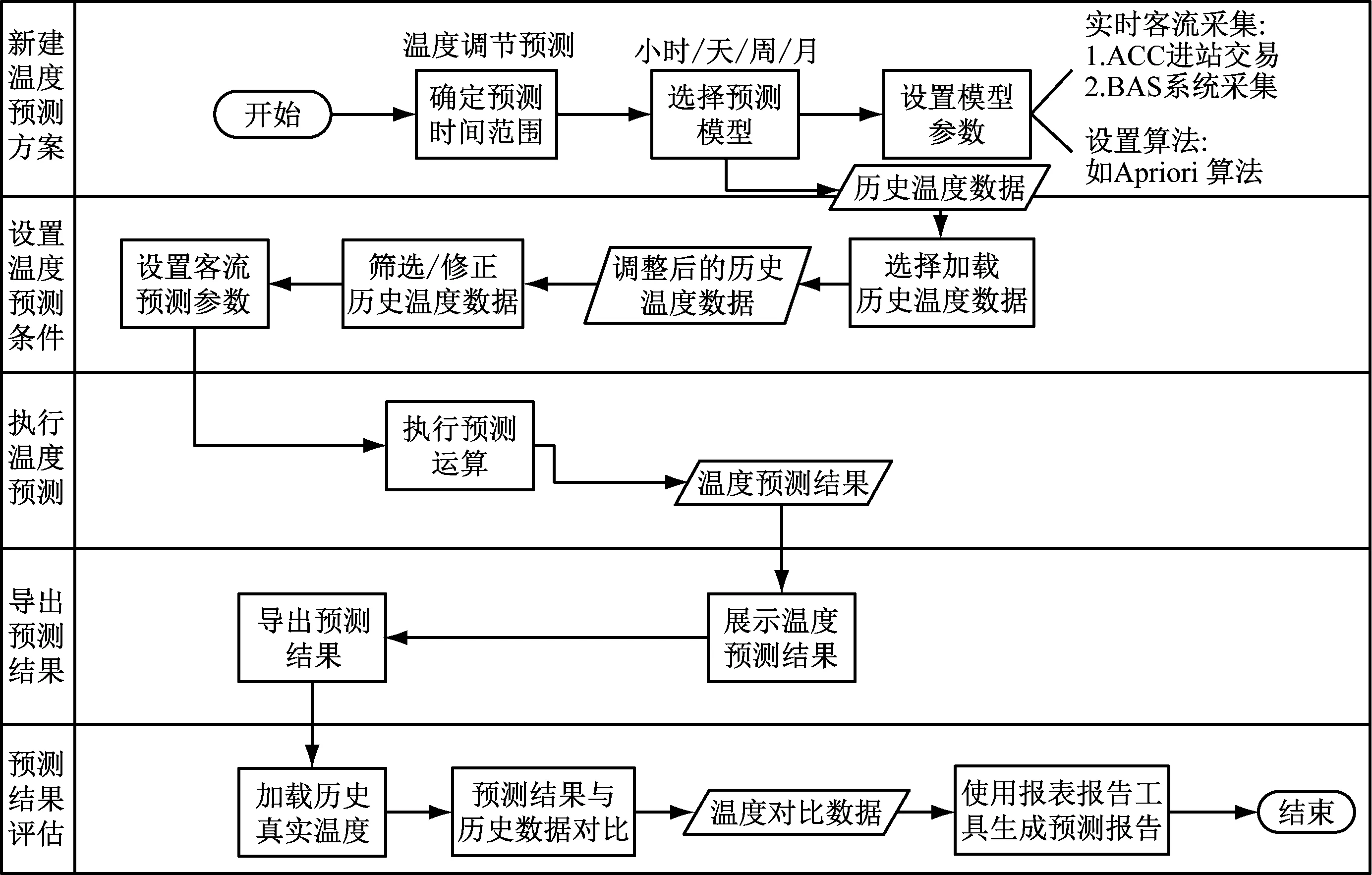
圖6 溫度預測系統流程
