分布式環境下遙感影像數據存儲方法
2018-11-16 09:11:30王卓琳高心丹
實驗室研究與探索 2018年10期
王卓琳, 高心丹
(東北林業大學 信息與計算機工程學院, 哈爾濱 150000)
0 引 言
隨著遙感技術的發展,遙感數據逐步呈現多源,多尺度,多時相,全球覆蓋和高分辨率特征,數據量爆炸性增長[1]。遙感以其能夠表達大容量數據的特點廣泛應用在對地、軍事、勘探、水污染防治、林火防治以及莊稼病蟲害監測等有空間大范圍數據量需求的領域。如何能高效地存儲和查詢遙感影像數據,在海量的信息中有效提取所需信息,已成為地理信息科學領域日益關注的熱點問題[2-3]。
傳統的數據管理方式為文件系統方式,存在讀寫速率低,傳輸速率慢等缺點。隨著數據庫技術的發展,逐漸提高了數據的共享性,減小了數據的冗余,提高了數據的一致性和完整性。在此基礎上,文獻[4]中提出了一種線性四叉樹技術的影像金字塔模型快速索引機制,該機制可以根據用戶需要以不同分辨率進行存儲與顯示,但是海量影像數據的存儲性能低下。文獻[5]中提出了一種基于影像塊組織的遙感數據分布Key-Value存儲模型,結合開源分布式文件系統HDFS[6],實現了影像數據的分布式高效存儲與空間區域檢索,有效地解決了傳統的關系型數據庫技術不能滿足存儲和管理海量數據的性能需求和海量數據在單節點存儲的效率和可擴展性不足等缺點。但是這種方法無法實現快速隨機訪問數據,因此文獻[7]中研究基于HBase的分布式存儲,釆用網格法對地理空間進行劃分,構建索引表,計算出每個網格單元對應的ID,設計行鍵和列族方案,提高了存儲和查詢效率。在金字塔構建部分,文獻[4,8]中都采用降采樣方法來構建金字塔,但在金字塔構建中卻耗費了很長時間,因此文獻[9] 在文獻[4,8]的基礎上采用分布式網格金字塔生成算法(Distributed Grid Pyramid Generation Algorithm,DGPG)并行構建金字塔,節約了金字塔構建時間,提高了效率,但同樣存在金字塔構建中上層分辨率降低,導致金字塔上層影像重要內容的清晰度和存儲性能降低的問題。
為在構建影像金字塔過程中降低分辨率的損失,作者采用尋優算法替代降采樣。在經典尋優算法中,遺傳算法[10]搜索速度較為緩慢,不能很好進行局部搜索;粒子群算法[11]在算法后期不能很好的跳出局部最優;蟻群算法[12]引入了信息素,加大了算法的時間復雜度,降低了算法效率(尤其是在樣品較多的情況下)。為解決上述問題,本文實驗中引入了一種新型的用于解決圖像問題的群體智能算法—貓群算法[13-14],并結合MapReduce[15]并行框架構建金字塔;然后使用HBase[16]存儲影像數據,設計了一種結合地物標識碼和四叉樹索引ID兩種信息的行鍵方案進行索引查詢,大幅提高查詢的處理速度。
貓群算法是建立在貓的行為模式和群體智能基礎上的一種非數值優化計算方法。該算法將貓群分為兩種工作模式,在搜尋模式下,通過對自身位置的復制,之后再對復制副本應用變異算子,加深了對自身位置周圍的搜索,有效地提高了問題的求解性能; 在跟蹤模式下,利用最優解的位置來不斷的更新貓的當前位置,使得解不斷地向著最優解的方向逼近,最終達到全局最優解。影像金字塔結合了分塊和細節層次模型LOD兩者的特點,以原始圖像作為底層,通過對原始圖像采用重采樣的方法,建立一系列地理覆蓋范圍相同但詳盡程度和分辨率不同的多個影像。為了提高影像金字塔各層的分辨率,本文采用貓群算法對金字塔下層尋優來獲得上一層,進而構建金字塔。
1 高分辨率影像金字塔的并行構建
影像金字塔最初用于機器視覺和圖像壓縮。一幅影像的金字塔是一系列以金字塔形狀排列的分辨率逐步降低,且來源于同一張原始影像的影像集合[17-18]。其通過貓群算法尋優獲得,直到達到某個終止條件停止。金字塔的底部是待處理影像的高分辨率表示,而頂部是低分辨率的近似。將一層一層的影像比喻成金字塔,層級越高,則影像越小,分辨率越低。
在瀏覽影像數據時,需要根據當前顯示的影像數據的分辨率來抽取金字塔相應層的數據。設原始影像數據的分辨率為R0,倍率為2,則第I層柵格數據的分辨率為:
RI=R0×2-I
(1)
設影像分塊為X×Y個像素,影像數據的像素為寬×高,則金字塔等級層數I的計算式為:
I=[log2max(Width/X,Height/Y)+1]
(2)
I級金字塔水平方向總塊數H和垂直方向總塊數V的計算式分別為:
(3)
(4)
式中:[]表示取整;| |表示向下取整。
本文釆用線性四叉樹對地理空間進行劃分,將劃分好的每個網格單元進行編碼,然后利用MapReduce并行計算框架結合貓群算法構建金字塔。
1.1 線性四叉樹編碼
影像金字塔的線性四叉樹編碼實質就是用線性四叉樹的數據結構來表示多分辨率遙感影像的索引[19],影像金字塔與線性四叉樹的映射關系如圖1所示。

圖1 影像金字塔與線性四叉樹的映射關系
由圖1可以看出,I-2層第1行第2列的編碼可以表示為:000001;I-2層第1行第3列的編碼可以表示為:000100;I-2層第2行第2列的編碼可以表示為:000011;I-2層第2行第3列的編碼可以表示為:000110,以此類推。
1.2 貓群算法尋優構建金字塔
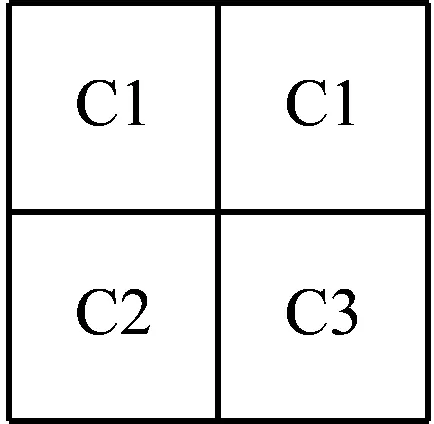
因以2倍率構建金字塔,所以金字塔上層的每一塊影像只需在其下一層中找到該層每4個相鄰的影像塊及其附近的一塊能代替該4個影像塊即可。假設原始影像可以分成4類,分別用C1、C2、C3、C4來表示。構建中可能出現4種情況,現將它們分為2組來討論,4種情況的示意簡圖如圖2所示。




(a)(b)(c)(d)
圖2 金字塔下層每4個相鄰的影像塊情況
若每相鄰的4個影像塊中有3塊或4塊的影像屬于同一類,上一層的影像就用該類中的一個影像塊代替,該影像塊根據特征相似度在4個影像塊同類中最大,不同類中最小的原則選取。如圖2中的(a)和(b)所示,則用C1類代替,具體用C1類中的哪個塊代替,則根據計算的相似度決定。如果是圖2中(c)和(d)的情況,則運用貓群算法進行搜索尋優,找到能代替該4個相鄰影像塊數據的那個影像塊,用其構建金字塔上一層。設f為找出搜索范圍內影像塊特征相似度在該類中較大的,在不同類中較小的影像塊且影像塊數最多的目標影像塊,x為目標影像塊。搜索范圍以C1影像塊為例如圖3所示,其余3個影像塊的搜索范圍同C1。

圖3 貓群算法搜索范圍
圖3中C1影像塊的搜索范圍為以C1為中心的八個方位上搜索。圖中紅色+藍色區域為搜尋一次的搜索范圍,若該區域不能找出最優解,則搜尋范圍擴充為紅色+藍色+黃色區域,以此類推。
貓群算法中各術語代表如下:
貓算法中的一個解,對應金字塔構建問題中的一個影像塊解。
貓群金字塔構建問題中的所有影像塊解。
適應度貓所處位置的適應度,在算法中表現為貓所處位置的優劣,在金字塔構建問題中代表影像塊解的特征相似度和影像塊數。
記憶池(smp) 在搜尋模式下,記憶池的大小代表貓能夠搜索的地點數量,通過變異算子,改變原值,使記憶池儲存了貓自身的鄰域內能夠搜索的新地點。貓將依據適應度的大小從記憶池中選擇一個最好的位置點。
個體上每個基因的改變范圍(srd):在算法開始之前設定,在本文算法中代表影像塊解每一特征的變異概率。
每個個體上需要改變的基因的個數(cdc):在算法開始之前設定,在本算法中代表影像塊解可變異的特征數。
分組率(mr):分組率將貓群隨機分為跟蹤模式和搜尋模式2組,指的是跟蹤模式的貓在貓群中所占的比例,通常為較小的數。
跟蹤模式是來模擬貓處于跟蹤狀態下建立的模型。在該模式下,通過改變貓的每一個特征的速度來改變貓的位置。跟蹤模式可以通過以下2步來描述。
(1) 速度更新。.每只貓都有自己的一個當前速度,記為Vi={Vi1,Vi2,…,Vil},每只貓根據式(5)來更新自己的速度。記Xbest(t) 為當前貓群里經歷的最優位置,即適應度最好的貓。

d=1,2,…,l
(5)
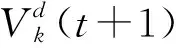
(2) 位置更新。每只貓根據下式更新自己的位置:
(6)
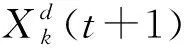
搜尋模式是模擬貓在四處搜索并尋找下一個地點所建立的模型。貓復制自身副本,在自身鄰域內加一個隨機擾動到達新的位置,再根據適應度函數求取適應度最高的點作為貓所要移動到的位置點。其副本的位置更新函數為:

(7)
式中:srd=0.2,即每個貓個體上的特征值變化范圍控制在0.2之內,相當于是在自身鄰域內搜索。
設貓群為X={Xi,i=1,2,…,n},Xi為D維模式向量,代表第i個貓(影像塊)總特征,內部可擁有表示光譜信息的DN值,反射率值、波段相關系數、表示空間信息的像素位置、大小等。如擴展開,還可加入顏色特征信息,紋理信息、煽、能量等。該小節問題就是要找出搜索范圍內該影像塊特征相似度在同類中相似度較大的,在不同類中較小的那個影像塊且所占影像塊數最多的。設任意 2個貓的同一基因(特征)分別為:X1=(x11,x12,…,x1d),X2=(x21,x22,…,x2d),其中d為基因中分量的個數。C[X1,X2]為X1與X2的基因屬性值的集合,那么X1與X2之間的距離為:
(8)
假如定義其光譜特征距離為D1,采用特征空間網格劃分方法得到的紋理和形狀特征距離分別為D2和D3,則光譜特征為:
(9)
由式(9)進一步可得,圖像空間的2個貓(網格)N1和N2,設它們的相似性為S,則相似性為:
(10)
式中:ωi為經驗權值;ω1,ω2,ω3為3個影像塊特征的權重;ω1+ω2+ω3=1。
由式(8)~(10)可得貓群算法的適應度函數為:
Cat(i).fitness=max[sum(class(N))]∪max(S(i,k))∪min(S(i,N-k))
(11)
式中:i為目標影像塊;k為某類影像塊的集合;N為搜索范圍內所有影像塊的集合。max[sum(class)(N)]是指搜索范圍內所有影像塊中某類影像塊數量占總影像塊數量(1/4以上)最多的,max(S(i,k))是指該尋找的目標影像塊與某類影像塊集合相似度(大于50%)最大的,min(S(i,N-k))是指該尋找的目標影像塊與其他類影像塊集合相似度最小(小于10%)的。以上各參數值是根據實際數據類別數量和具體情況經過反復實驗得到的。
算法實現偽代碼如下:
貓群算法尋優構建金字塔偽代碼
%初始化貓的數目N,記憶池大小smp,個體上每個基因的改變范圍srd,每個個體上需要改變的基因的個數cdc,分組率mr,貓的初始位置X、初始速度V和初始適應度Cat(1).fitness=0
%if跟蹤模式
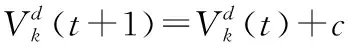
%適應度計算
Cat.(i)fitness=max[sum(class(N))]∪max(S(i,k))∪min(S(i,N-k));
%最優解,直接退出
%else搜尋模式
%將自身位置復制smp份,同自身一起存入記憶池
forn=2:smp
current_Cat(N)=Cat(i);
end
%對記憶池復制的位置進行改變
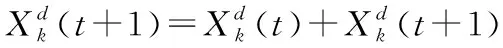
%適應度計算
current_Cat.fitness=max[sum(class(N))]∪max(S(i,k))∪min(S(i,N-k));
%最優解,直接退出
%記錄搜尋的最好位置
max_Cat=current_Cat(1);
for n=2:smp
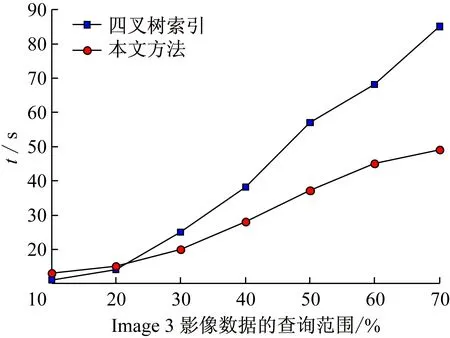
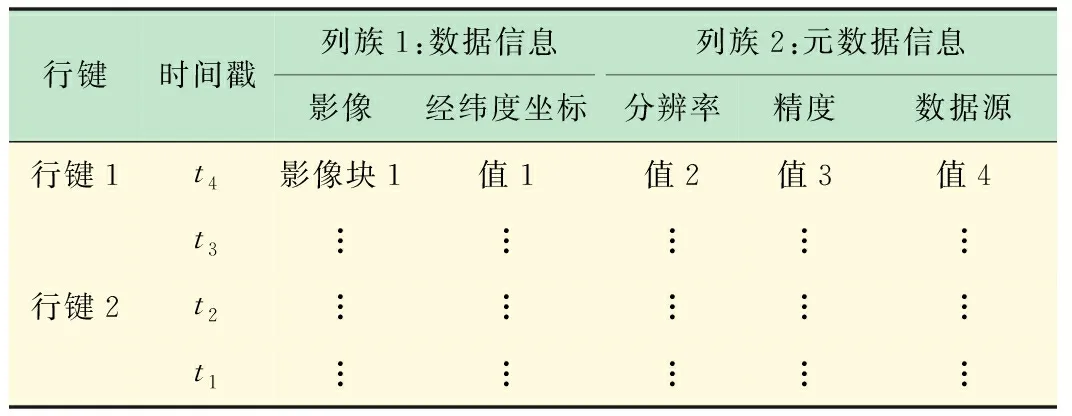
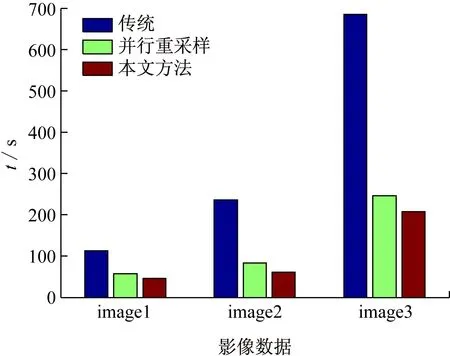
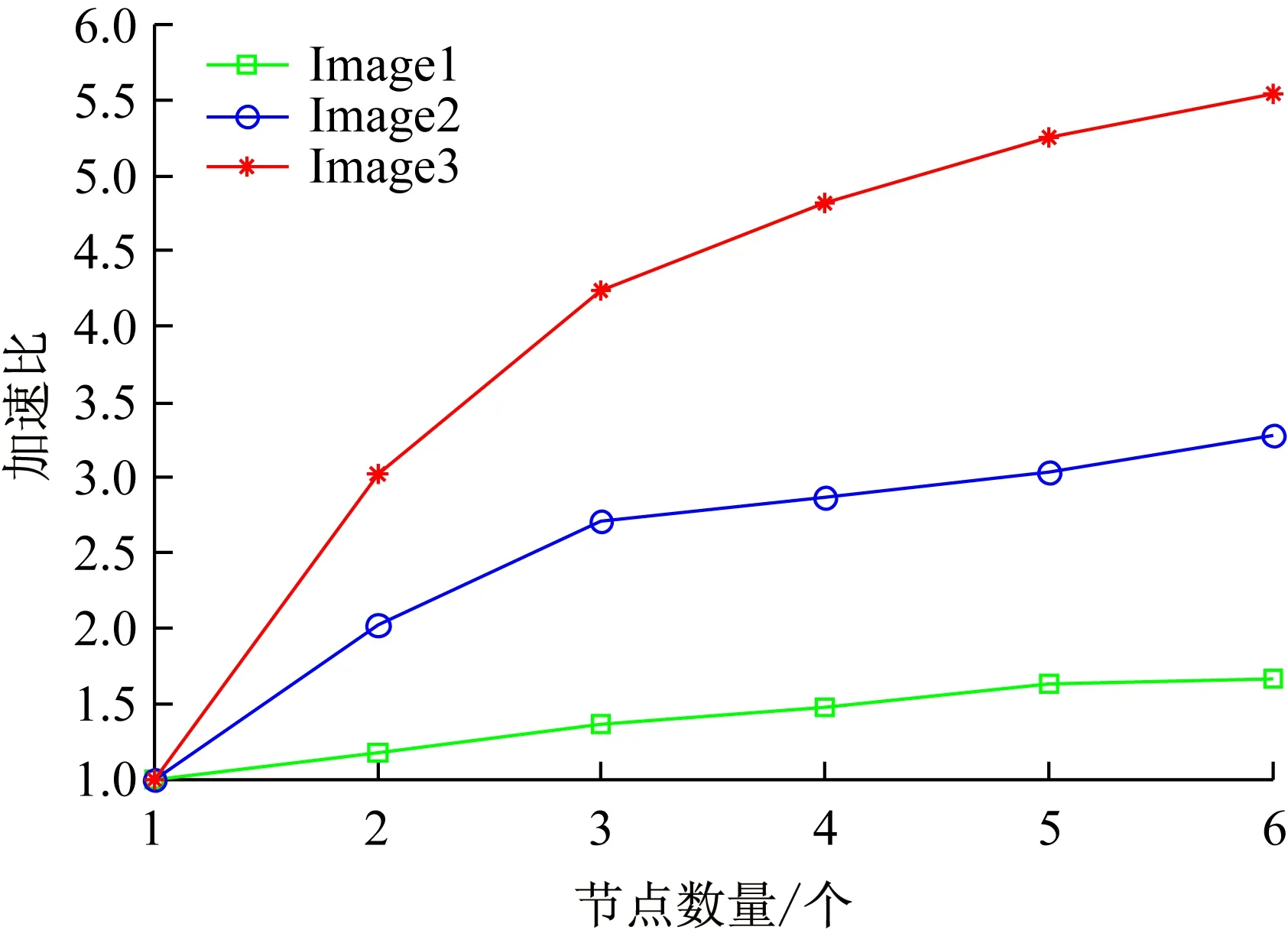
if max_Cat.fitness max_Cat =current_Cat(N); end end Cat(i) =max_Cat; end 為了提高金字塔的構建速率,本文使用MapReduce并行計算框架,通過對金字塔的每一層分別使用MapReduce來解決傳統的串行方法構建金字塔效率低下的問題。在原始圖像已經分好類的前提下,以原始圖像作為金字塔的最底層即第0層,然后依次從最底層出發通過2I×2I→1(I為金字塔的層數)影像塊的映射關系運用MapReduce得到金字塔第1層、第2層...第I層。但是這只是在滿足圖2中(a)、(b)兩種情況下的映射關系,如若不是這兩種情況則需要結合貓群算法尋優,第0層均采用如圖1~3 所示的紅色+藍色+黃色區域,即(21+4)2個影像塊作為尋優范圍來找出金字塔第1層所對應的一個影像塊,金字塔的第1層均采用如圖4 所示的藍色+黃色+綠色區域,即(22+4)2個影像塊作為尋優范圍來找出金字塔第2層所對應的一個影像塊......以此類推,金字塔的第I-1層均采用(2I+4)2個影像塊作為尋優范圍來找出金字塔第I層所對應的一個影像塊。 圖4 并行構建中金字塔第1層到第2層映射范圍 如圖4所示,C1-C16→1為金字塔第0層到第2層的塊數映射關系,但是結合貓群算法后實質的映射關系為藍色+黃色+綠色影像塊區域→1,即貓群算法在此區域內尋優找到所對應的一個影像塊。 Map 函數讀取影像分塊并計算它們對應的上層金字塔對應的編碼號,鍵為影像分塊的編碼號,值為影像分塊文件;Reduce函數結合貓群算法對構成該層金字塔的影像分塊進行抽樣處理生成新的影像塊。總的來說就是通過(2I+4)2→1影像塊的新映射關系運用MapReduce得到金字塔第1層、第2層...第I層。其中總體的并行構建流程如下圖5所示。 圖5 影像金字塔并行構建的MapReduce算法 圖5所示的是金字塔并行構建的核心流程,從圖中可以看出所有尋優范圍的金字塔第0層的相鄰影像塊都經Map函數寫入并計算它們對應的上層金字塔對應的編碼號(這里僅列出金字塔第1層4個影像塊的構建過程),然后通過Reduce函數合并,再結合貓群算法最終得到金字塔第1層影像。 HBase的基本存儲單元cell是由行鍵RowKey、時間戳TimeStamp、列族ColumnFamily組成。其中行鍵是確定行的標識符,時間戳是保證cell的時間版本特性,列族是預先定義的,并可以根據自己的實際需求定義[20]。由于HBase是按列存儲的,即按Key-Value的形式存儲,而且對影像數據進行查詢時,按照行鍵、列族和時間戳的順序進行定位,因此想要快速查詢所需要的影像信息,行鍵RowKey的設計是至關重要的。本文將表的行鍵設計為,地物標識碼+四叉樹索引ID,其中地物標識碼即不同地物用不同的二進制編碼來表示,如樹木:00,河流:01,建筑物:10。具體地物標識碼用幾位二進制表示,可以根據實際需要將影像分為了幾種類別來確定。下面是行鍵這樣設計的原因: (1) 設計地物標識碼+四叉樹索引ID的行鍵方案,是針對實際中需要快速定位特定影像數據的需求,比如在林火防治領域就需要找到可燃物、水源、道路等,來提前設計好林火撲救方案,以免森林火災一旦發生,造成撲救不及時而帶來的不必要的損失。 (2) 行鍵和空間對象一一對應,設計地物標識碼+四叉樹索引ID可以讓行鍵和地物最大限度的對應。 (3) 根據行鍵長度設計的原則,結合遙感影像數據的特性,將行鍵的長度定義為32 B(8 B的整數倍),其中ID占16 B。例如某一個空間對象的ID為0001100010010101,地物為建筑物,假如其地物標識碼為011(共分為5類,針葉林000、闊葉林001、河流010、建筑物011、其他100)則它的行鍵設計為:0001100010010101011。 HBase的表結構設計見表1。 表1 HBase的表結構設計 表1中列族1為遙感影像數據信息,包括影像塊和經緯度坐標;列族2為存儲遙感影像數據的元數據信息,其中包括分辨率、精度和數據源。 HBase數據庫是按列存儲的,而按列存儲的本質含義就是按照Key-Value的形式進行存儲。所以本文通過HBase與MapReduce相結合來實現影像數據的并行入庫,從而提高入庫效率。本文HBase鍵值對中不同字段的排列如圖6所示。 圖6 HBase鍵值對中不同字段的排列 由圖6可以看出本文的鍵Key依次由行鍵、列族和時間戳組成,值Value就是cell所對應的值。 本實驗采用虛擬軟件XenServer6.2將3臺曙光 I450-G10塔式服務器(InterXeon E5-2407四核2.2 GHz處理器,8GB內存)虛擬成6臺主機,一臺HP Compaq dx2308(Intel Pentium E2160 1.8 GHz處理器,1GB內存)作為Master。具體的軟件配置見表2。 本文實驗數據來源有兩個:其中1幅高分辨率影像數據來自于國產衛星高分二號GF-2,研究區位于大興安嶺,大興安嶺全長1 200 km,寬200~300 km。此遙感影像包括0.8 m的全色單波段和3.2 m分辨率的多光譜波段,具有4個標準波譜段( 紅、綠、藍、近紅外) 。其地理位置是:東經123°76′31.81″~124°16′10.30″,北緯 50°02′10.21″~50°27′02.73″。該一景圖像成像時間為2015年7月14日02∶57。它的全色中心波長為0.814 0 μm,多光譜:藍光波段(Band1)中心波長0.502 0 μm,綠光波段(Band2)中心波長0.576 0 μm,紅光波段(Band3)中心波長0.680 0 μm,近紅外波段(Band4)中心波長0.810 0 μm;另一幅影像來源于Landsat 8衛星,研究區位于河南信陽。地理位置是:東經113°32′12.10″~114°25′12.33″,北緯 31°43′20.33″~32°38′36.94″。成像時間為2016年4月27日08:52。此遙感影像包括9個波段,空間分辨率為30 m,其中包括一個15 m的全色波段,成像寬幅為185 km×185 km,其中光譜信息為:Band5波段為(0.845~0.885 μm),全色波段Band8波段范圍較窄,藍色波段Band 1波段為(0.433~0.453 μm) ,短波紅外波段Band 9波段為(1.360~1.390 μm) 。 表2 軟件配置表 在數據的完整性實驗中,本文選取大興安嶺和信陽影像的1/64大小(706×706像素)的且已經標記好地物的遙感影像圖。為了驗證研究方法的完整性,本文分別對2幅影像進行128×128、256×256、512×512、1 024×1 024分塊,然后利用貓群算法分別得到368×353像素大小的影像,其原始影像和貓群尋優后的影像分別如圖7所示。最后在各影像中隨機選取100個點和原始圖像對應的100個點進行相似度比較,重復3次,取平均值。發現影像分塊越精細,數據的完整性就越好,實驗結果圖如8所示。 (a)(b)(c)(d) 圖7 貓群算法尋優后影像圖 圖7(a)為大興安嶺地區的1/64大小的且已經標記好地物的遙感影像圖,圖7(b)為(a)經過貓群算法以1∶4的比例構建出來的影像,圖7(c)為河南信陽地區的1/64大小的且已經標記好地物的遙感影像圖,圖7(d)在(c)基礎上經過貓群算法以1∶4的比例構建出來的影像。 由圖8(a)、(b)可以看出,運用貓群算法對金字塔進行構建不會損失大量的數據,數據的完整性可以得到保證;并且隨著影像分塊數目的增多,貓群算法尋優構建金字塔的完整性也越來越好。運用貓群算法后信陽地區的數據完整性明顯高于大興安嶺地區的原因經分析是類別比較集中且每個類別范圍相對較大。 在數據的存儲實驗中,本文選取3幅高分二號衛星的遙感影像圖,經處理影像數據的大小分別為623 MB、1.49 GB和3.21 GB。分別對上述3幅影像進行并行金字塔的構建和數據的并行寫入實驗。 為了驗證本文提出算法的有效性,分別對不同大小的遙感影像進行并行的構建金字塔。由圖9可知,本文提出的并行構建金字塔的方法所需時間要遠遠小于傳統方法。當數據量逐漸增加時,傳統構建金字塔的方法所需時間增加幅度較大而本文的并行構建方法時間雖然有所增加但是幅度較小,由此可看出本文提出的方法有效地減少了金字塔構建所需的時間。 在金字塔創建完成后,為了驗證本文提出方法的可擴展性分別對上述3幅圖像進行數據的導入。研究在隨著處理節點的增加,本文采用的并行處理方法加速比的差異,其中加速比為: speedup=T1/Tp (12) 式中:T1為單處理器下的運行時間,Tp為p個處理器的并行運行時間。變化趨勢如圖10所示。 圖9 影像金字塔并行構建 圖10 加速比對比圖 由圖10的實驗結果可知,當實驗數據較少時并行算法的加速比效果并不是很理想,數據導入時間幾乎不變,但是隨著數據的增大加速比逐漸增大,數據寫入的時間減少,本文提出的并行方法效率提高。這主要是因為,數據量較少時在HBase上存儲時需要劃分的region數量較少,數據只存在固定的幾個節點中,從而導致數據導入時間變化不大。但是,隨著數據量的增大HBase需要的region數量增多,這時不同的節點均可寫入到HBase中,并行算法加速效果比較明顯。 在進行數據的查詢實驗時,本文選擇image3影像中分辨率最高的一層中地物標識為針葉林的影像塊作為查詢對象,分別將整幅影像占比為10%~70%作為輸入的查詢范圍,測試數據包含的文件數量從6 554張到45 875張。實驗結果如圖11所示。由圖可見,在查詢范圍較少時本文改進行鍵的設計方法和行鍵中不加地物標識碼的方法查詢時間相差不大,并且后者的查詢性能要優于本文方法。但是隨著查詢范圍的增加本文方法的查詢時間增長較慢,且查詢時間要低于后者的方法。 以HBase分布式數據庫為工具,采用線性四叉樹構建影像金字塔來解決遙感影像大數據的存儲效率低及查找速度慢等問題。實驗中為減小金字塔構建中分辨率的損失,利用貓群算法和MapReduce并行處理架構相結合來構建金字塔,不僅相對提高了金字塔上層影像的清晰度,同時還提高了數據的存儲性能。實驗通過對RowKey的設計,有效地提高了數據的讀取性能。本研究將為遙感影像的存儲及特征識別等應用提供借鑒和參考。 圖11 索引改進前后實驗對比圖1.3 MapReduce并行構建金字塔


2 影像數據的分布式存儲

3 實驗分析與評估
3.1 實驗環境及數據

3.2 數據完整性比較



3.3 影像數據的并行存儲
3.4 影像數據的并行查詢
4 結 語