基于層次化聚類的稀疏謂詞語義角色標注方法
2018-11-17 01:25:56楊海彤
計算機工程與設計 2018年11期
楊海彤
(華中師范大學 計算機學院, 湖北 武漢 430079)
0 引 言
語義角色標注是一種自然語言處理領域的淺層語義分析技術。它以句子為單位,分析句子中的謂詞與其相關成分之間的語義關系,進而獲取句子所表達語義的淺層表示。下面是一個語義角色標注的例子:
[警方]Agent [正在]Time [調查]Pred [事故原因]Patient
其中“調查”是謂詞,代表了一個事件,“警方”是施事者,“事故原因”是受事者,“正在”是事件發生的時間。由此可見,語義角色標注能夠抽取出一個句子表達的事件的全部重要信息。由于語義角色標注可以提供較為簡潔、準確、有益的分析結果,因此近年來受到了學術界的普遍重視,并已經成功地應用到信息抽取[1]、自動問答[2]、機器翻譯[3]等任務中。
由于語義角色標注的簡潔、有效的語義分析能力,吸引大量的研究人員投入到語義角色標注的研究中。文獻[4]細致地分析了哪些特征對中文語義角色標注是有效的,并進行了大量的實驗驗證。文獻[5]提出了一種中文句法分析和語義角色標注聯合學習模型。文獻[6]融合了4個基本的語義角色標注系統,取得了較好的結果。文獻[7]研究了位于同一個句子中的多個謂詞的語義角色標注之間是否有聯系。
目前,語義角色標注系統大多采用有監督的方法來完成語義標注。然而,在有監督的方法體系下,模型的最終效果和性能受到標注數據的規模和質量的影響。目前中文語義角色標注最大的公開語料是中文命題庫(Chinese PropBank,CPB)。它是在中文樹庫的基礎上增加了語義角色標注相應的人工標注。盡管中文命題庫的標注過程耗費了大量的人力、物力,促進了語義角色標注理論方法的進步[8-11],然而語料的標注過程忽視了一個重要的隱含問題即謂詞標注不均勻。謂詞標注統計分布整體上表現出明顯的長尾現象,一些謂詞在中文命題庫中被標注了許多次,而大多數謂詞僅僅被標注了一次或兩次,比如謂詞“是”被標注了超過1000次,而80%的謂詞僅僅被標注了一次或兩次。因此,這些標注次數較少的稀疏謂詞由于缺乏足夠的訓練實例,導致模型很難學習到有效的模型參數,進而語義分析效果要遠遠地低于其它謂詞。而一個實用的語義角色標注系統經常需要處理各種稀疏謂詞,因此,研究稀疏謂詞的語義分析方法具有理論和現實的意義。
為解決稀疏謂詞的語義分析問題,本文提出了一種基于聚合層次化聚類的方法。該方法通過聚合層次化聚類建立起稀疏謂詞與常見謂詞的聯系,把稀疏謂詞可以泛化為與之語義相近的常用謂詞,進而緩和語義角色標注系統中的謂詞稀疏問題。實驗結果表明,該方法可以顯著地提升稀疏謂詞的語義分析性能。
本文的創新點在于:
(1)語義角色標注中稀疏謂詞的問題一直以來都被忽視,本文是第一個提出該問題,并進行細致地分析研究的工作。
(2)對于稀疏謂詞問題,本文提出了一種基于聚合層次化聚類的方法,可以顯著地提升稀疏謂詞的語義分析性能,提升了語義角色標注在實際語義分析系統的可用性。
1 中文語義角色標注系統
1.1 數據資源
本文采用中文命題庫作為實驗的語料。中文命題庫(Chinese PropBank,CPB)是賓州大學建設的中文語義角色標注語料庫。它是在中文樹庫(Chinese TreeBank,CTB)的基礎上添加了一個語義角色標注層。具體地,該語料通過在句法樹中找到與待分析的謂詞語義密切相關的成分,并給不同的語義成分賦予不同的語義角色,來實現對句子語義的形式化表示。下面以一個具體例子進行說明。在圖1,待分析的句子是“警方已到現場,正在詳細調查事故原因”。從圖中可以看到在文字部分的上方是該句的句法分析結果,在文字部分的下方是該句的語義角色標注結果。從結果可以看出,“調查”是謂詞,被標注為“Pred”,代表了發生的一個事件;“警方”被標注為“ARG0”,是事件的施事者;“事故原因”被標注為“ARG1”,是事件的受事者;而“正在”和“詳細”分別被標注為“AM-TMP”和“AM-MNR”代表了事件發生的時間和方式。
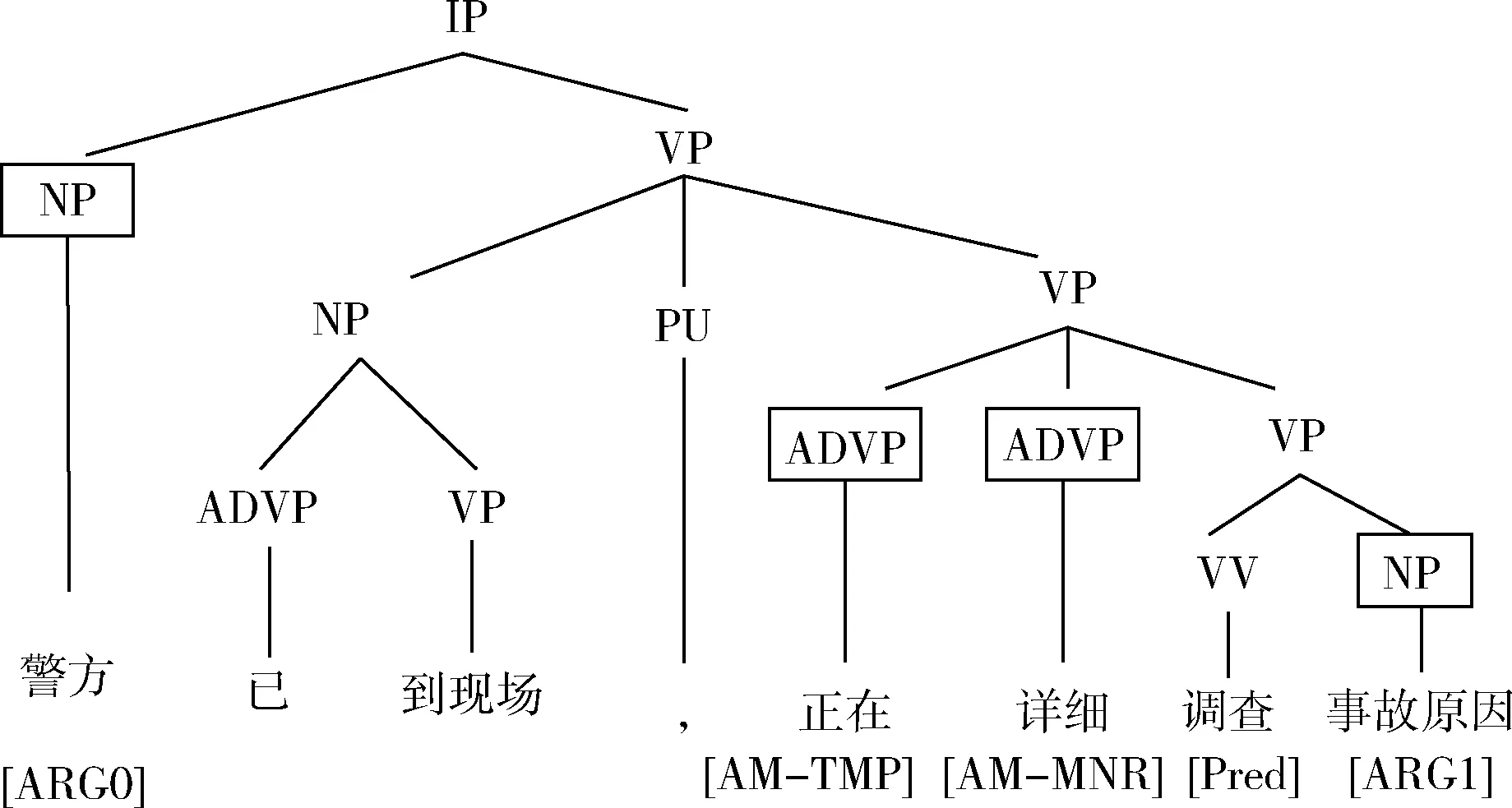
圖1 中文命題庫中的一個具體實例
1.2 系統框架
本文所采用的標注系統的基本框架如圖2所示。句子經過句法分析后,需要先后經過如下的4個模塊。

圖2 標注系統的系統框架
(1)候選論元剪枝。該模塊的作用是從大量候選論元中剪掉不可能是論元的那些候選,從而減少候選論元數目。本文采用文獻[4]提出的啟發式方法進行論元剪枝。
(2)論元識別。該階段的目標是從候選論元集合中識別出哪些是真正的論元。一般地,論元識別被當作一個二元分類問題來解決。
本文采用最大熵模型(maximum entropy,ME)完成此二元分類。模型如下式所示
其中,x是輸入樣例,y是輸出結果,即1(是候選論元)或0(非候選論元),fi(x,y)是人工定義的特征函數,θi是特征fi(x,y)相應的參數,Z(x)是一個歸一化項,計算方式如下式所示
(3)論元分類。該階段就要為論元識別階段識別出的論元賦予一個語義角色。一般地,論元分類會被作為一個多元分類問題來解決。本文依然采用最大熵模型完成此多元分類。
(4)后處理。該階段的作用是對前面得到的語義角色標注結果進行后處理。
1.3 特征選擇
特征選擇的好壞直接影響了標注系統的性能。在特征選擇方面已有許多相關工作。其中,文獻[4]通過實驗從大量特征中仔細挑選了一組性能較好的特征。因此,本文系統采用他們使用的特征,詳細的特征列表如下:
(1)謂詞
(2)候選論元到謂詞的句法路徑
(3)候選論元的頭節點
(4)候選論元頭節點的詞性
(5)謂詞類別
(6)謂詞和候選論元頭節點的組合
(7)謂詞和候選論元句法標簽的組合
(8)謂詞類別和候選論元頭節點的組合
(9)謂詞類別和候選論元句法標簽的組合
(10)候選論元與謂詞的相對位置
(11)謂詞父節點的句法生成規則
(12)候選論元的首詞和尾詞
(13)候選論元的句法標簽
(14)句子中名詞性短語生成框架
2 謂詞的層次化聚類方法
在有監督的方法體系下,如果固定下分類器,那么論元的類別標簽是由論元的特征決定的。對于語義角色標注來講,從1.3節所選的特征可以看出,謂詞相關的特征占據了重要的地位,直接影響了標注系統的性能,對系統標注性能起了關鍵的作用。然而,稀疏謂詞由于在訓練集中僅僅擁有極少的標注訓練樣例,因此導致分類器很難學習到一組較優的模型。其中,一種極端情況是從未在訓練集中出現過的謂詞,這種情況會更加嚴重,因為重要的謂詞特征均成為了詞典外特征(out-of-dictionary,OOV),對角色判別不能發揮任何作用。
對于稀疏謂詞問題,本文提出了一種基于層次化聚類方法。本文的動機是通過層次化聚類方法為稀疏謂詞找到與之語義相近的常用謂詞,然后再在特征提取過程中的用找到的常用謂詞替代該稀疏謂詞。下面舉例說明,在中文命題庫中,‘操控’僅僅出現了一次,而與之語義相近的謂詞‘控制’出現了28次。顯然,對于統計分類器而言,較容易學習到‘控制’的概率分布情況。但由于‘操控’和‘控制’具有相近的語義,因此它們應具有相近的概率分布。這啟發本文當需要處理稀疏謂詞‘操控’時,可以使用常用謂詞‘控制’進行替換。具體地,本文使用層次化聚類的方法實現該目標。
2.1 層次化聚類
層次化聚類算法是機器學習和自然語言處理領域被廣泛采用的聚類算法。在理論上,層次化聚類算法的目標是通過構建一棵層次化的樹結構,從而找出數據集內部各個元素的聚類關聯。在具體的實現中,一般有兩種層次化聚類策略:
(1)聚合策略
聚合是一種從底向上的方法策略。該策略每次迭代時首先計算各個類別核心的距離,之后將最近鄰距離的兩個類別合并,形成一個新的聚類,直至所有數據形成一個聚類結束。
(2)分裂策略
分裂是一種從頂向下的方法策略。該策略在算法運行伊始,將所有數據看作一個聚類,之后每次迭代將一個聚類分類為兩個聚類,直至每個原始數據都成為一個獨立聚類為止。
綜合考慮,本文采用了聚合層次化聚類算法對所有的謂詞進行聚類。一般地,聚合層次化聚類算法在算法伊始時,把所有的數據點均看作一個獨立結點,之后每次迭代過程中,計算出距離最近的兩個結點,直至形成一個最終的結點。相比分類策略,聚合策略在運行效率上具有較大優勢。
2.2 聚合層次化聚類算法描述
本節對算法實現細節進行詳細闡述。本文采用了分布式詞向量技術表示每個謂詞。分布式詞向量技術是近年來自然語言處理領域對詞進行表示的主流方法,它的每一維可以看作包含了原始詞的句法或語義信息。所有的謂詞集合記為P,謂詞數目為n,集合P又被劃分為兩個集合:常用謂詞集合Pr和稀疏謂詞集合Pc。在聚類過程中,所有聚類結點的集合記為S,結點數目記為Sl,S內部各結點之間的聚類矩陣記為M,其中Mij表示結點Pi和Pj之間的距離。
算法1給出了聚合層次化聚類算法的詳細描述。在算法初始化階段,該算法將每個謂詞都作為一個獨立的結點看待。在每次迭代時,計算各個結點之間的距離,從而得到距離矩陣M。根據距離矩陣M,找出距離最近的兩個結點,并將其合并,形成一個新的結點,該結點的向量表示為上述最近鄰結點對的平均。經過n-1次迭代后,所有的結點最終合并為一個統一的結點。在算法1第4行,需要計算兩個結點的距離,本文采用了如下的余弦距離公式
算法1:聚合層次化聚類算法
輸入:所有的謂詞集合P
輸出:關于所有謂詞的一棵層次化聚類樹
初始化所有的謂詞為聚類結點集合S中的元素
(1) fork= 1 ton- 1 do
(2) fori= 1 toSldo
(3) forj= 1 toido

(5) end for
(6) end for
(7)i′,j′←argmini,jMij//從當前聚類結點集合S中找出最近鄰的兩個結點i′,j′
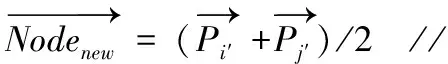
(9) end
2.3 嵌入中文語義角色標注系統
經過算法1,可以得到關于所有謂詞聚類關系的一棵層次化樹結構。該層次化的樹結構反映了所有謂詞間的關聯信息,語義相近的謂詞對將會在樹的底層某結點合并,而語義差異較大的謂詞對只能在樹的高層某結點合并。當一個謂詞進入到標注系統時,系統首先判斷該謂詞是否是稀疏謂詞,如果該謂詞是常用謂詞,則不進行任何處理,直接進行語義分析;如果該謂詞是稀疏謂詞,則系統首先在上述層次化的樹結構中定位到該謂詞,之后從底向上搜索,如果遇到的聚類結點中包含常用謂詞,則標注系統在抽取特征時自動地用找到的常用謂詞替換稀疏謂詞。
3 實 驗
3.1 實驗設置
本文使用中文命題庫1.0作為實驗數據集。與文獻[4-6]相同,所有的數據被劃分為3部分:648個文件(chtb_081.fid到chtb_899.fid)作為訓練集、40個文件(chtb_041.fid到chtb_080.fid)作為開發集、72文件(chtb_001.fid到chtb_040.fid和chtb_900.fid到chtb_931.fid)作為測試集。本章采用Berkeley parser自動地生成短語結構樹,同時句法模型也是在訓練語料上重新訓練得到的。基線系統中最大熵模型均借助張樂的最大熵工具包進行具體實現。本文將訓練集中標記次數少于10次的謂詞看作稀疏謂詞,重點對這部分謂詞進行了研究。
為構建所有謂詞的詞向量表示,本文采用了開源軟件word2vec,在語料Chinese Gigaword corpus上運行CBow模型,窗口設置為10,向量維數設置為200。
3.2 評價指標
語義角色標注領域普遍采用準確率(precision)、召回率(recall)和F1來評價系統的性能。Numright表示正確標注為語義角色的個數,Numtest表示系統預測為語義角色的總數,Numgold表示測試數據中語義角色的總數。那么,它們的定義分別為
3.3 實驗結果對比
圖3給出了原中文語義角色標注系統的性能,以F1值作為評價指標。本文把所有的謂詞按照在訓練集中出現次數對測試集數據進行了分組,其中‘0’組表示該謂詞從未在訓練集中出現,‘1’組表示該謂詞在訓練集中出現了1次,以此類推。
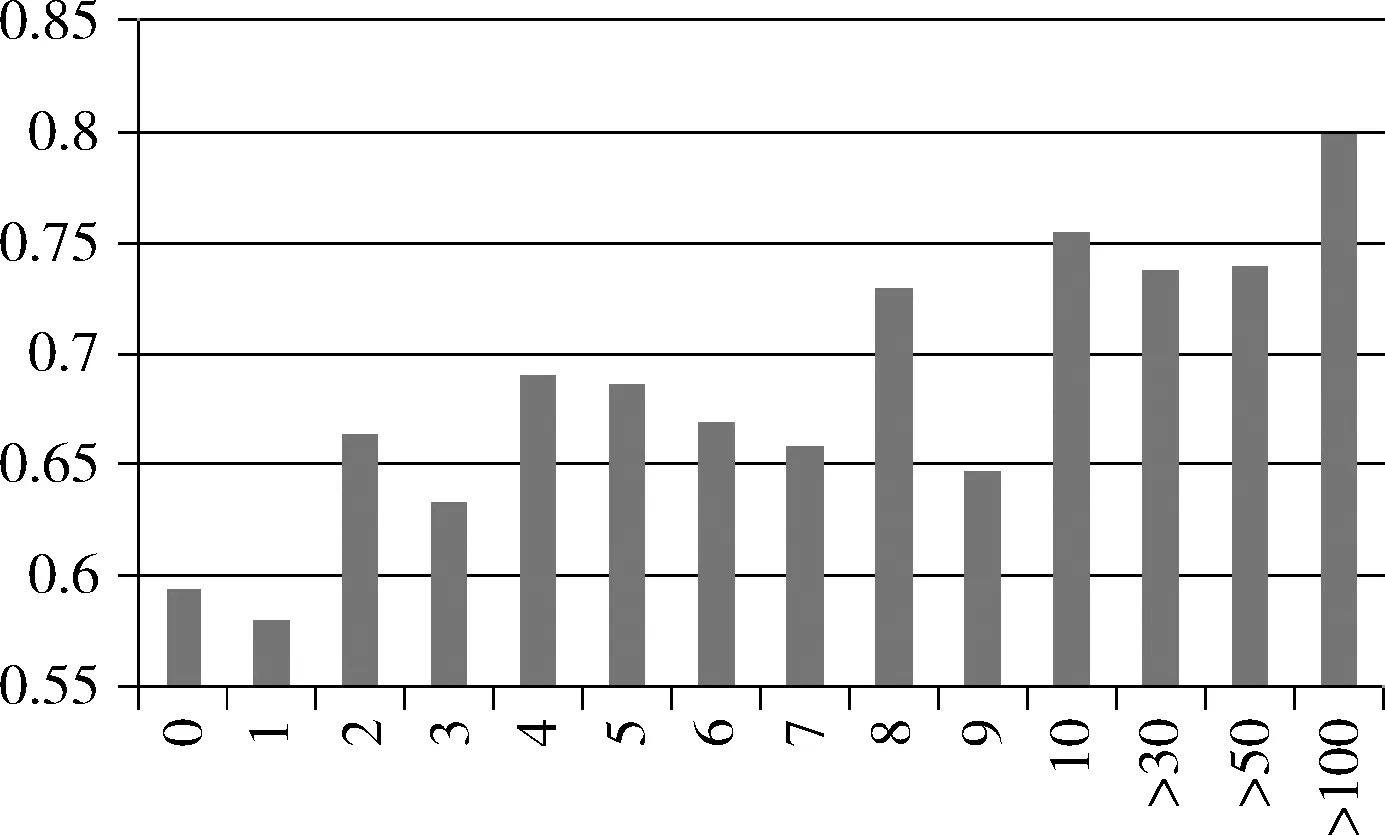
圖3 中文語義角色標注系統對于不同謂詞的性能對比
從圖中首先可以看到一個整體趨勢是謂詞被標注的次數越多,標注系統對該謂詞的語義分析越準確,該現象是符合預期的,因為有監督學習的系統要達到比較好的性能需要一定數量的訓練數據。而對于稀疏謂詞而言,正是因為不能提供足夠的訓練數據導致性能遠遠低于常用謂詞。性能最低的謂詞組‘0’比性能最高的謂詞組‘≥100’低了將近20個百分點F1,這突出反映了稀疏謂詞問題的嚴重性。需要注意的一點是,‘0’組謂詞即從未在訓練集中出現的謂詞,在測試集中占比達到20%,但是該組謂詞的語義分析性能最低。在實際應用中,如果一個標注系統一旦遇到未出現過的謂詞,經常會輸出錯誤的分析結果,顯然該標注系統是不能滿足實際需求的。因此,一個實用的語義角色標注系統應能處理各種謂詞。研究稀疏謂詞的語義分析方法也具有較大的現實意義。
表1給出了本文提出的方法的性能。從表中可以看到本文提出的方法可以顯著地提升稀疏謂詞的語義分析性能。‘0’組謂詞的性能提升幅度最大,F1值由59.32%提升到61.05%,約1.7%的提升幅度,其它組稀疏謂詞也均具有較大幅度提升。所有稀疏謂詞的F1值由68.70%提升至69.75%,平均約有1%的提升幅度。為檢驗本文提出的方法的結果是否是統計顯著的,本文采用了重采樣的方法對結果進行顯著性檢驗。檢驗結果表明在p<0.05的設置下,本文提出的方法的結果顯著優于原中文語義標注系統的結果。
下面通過一個具體實例進行進一步的分析。下面是原中文語義角色標注系統的一個分析結果,[各項存款]Arg0[比七五]ArgM-TMP凈增五十億元[Arg2],然而,上述結果對于論元‘五十億元’的標注結果是錯誤的,它的正確標記應為Arg1。該句中的謂詞是‘凈增’,但該謂詞在訓練集中從未出現過,所以導致謂詞相關的分類特征的缺少,進而使得分類器出現分類錯誤。本文通過構建的層次化樹結構找到與‘凈增’語義最相近的常用謂詞是‘增長’,該謂詞在訓練集中出現了237次,擁有足夠的訓練數據,因此分類器可以學習到較好的模型參數。最終,本文提出的方法正確的修正了上述例句中的錯誤結果。
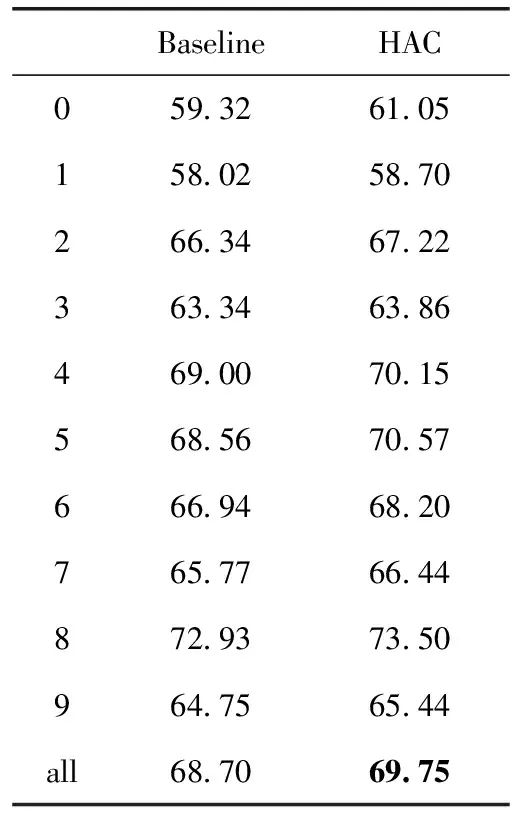
表1 實驗結果對比
本文還測試了提出的方法在跨領域數據上的性能。領域適應問題是語義角色標注的亟待解決的問題之一。導致領域適應問題的主要原因是領域外與領域內之間的數據分布差異,而其中謂詞的差異也較為突出。由于中文缺乏跨領域的語義角色標注數據,本文在英文的布朗數據集(brown corpus)進行了測試,實驗數據選擇了英文命題庫(English PropBank,EPB)作為訓練集。表2給出了詳細的實驗結果對比。從表中首先可以看到,在領域外數據集上語義角色標注系統也表現出了謂詞被標注的次數越多,標注系統對該謂詞的語義分析越準確的趨勢,反之,謂詞被標注次數較少的話,語義分析性能較差。同樣地,‘0’組謂詞的語義分析性能最差,比最高得分的謂詞組低了20%。可見,在領域外數據集上,稀疏謂詞的情況也非常嚴重。從表中可以看到本文提出的方法可以顯著地提升稀疏謂詞的語義分析性能。‘0’組謂詞的分析性能提升幅度最大,由44.64%提升到46.22%,約1.6%的提升幅度,其它組稀疏謂詞也均具有較大幅度提升。所有稀疏謂詞的F1值,由60.15%提升至61.40%,平均約有1.3%的提升幅度。在p<0.05的設置下,本文提出的方法的結果顯著優于原語義標注系統的結果。
4 結束語
在有監督的方法體系下,語義角色標注系統最終效果和性能受到標注數據的規模和質量的影響。然而,當前公開的標注語料對于不同謂詞的標注是不平衡的,有些謂詞被多次標注,而有些稀疏謂詞僅僅被標注一次或兩次,甚至還有大量謂詞未被標注。所以,稀疏謂詞問題嚴重限制了語義角色標注在實際中的應用。而目前,語義角色標注領域尚未有稀疏謂詞的研究工作。本文對語義角色標注任務中的稀疏謂詞問題進行了細致地分析,并對該問題提出了一種基于聚合層次化聚類的方法。實驗結果表明本文提出的方法可以顯著提升稀疏謂詞的標注性能。

表2 領域外實驗結果對比
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
開放教育研究(2020年2期)2020-03-31 01:54:14
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
