融合用戶信息和評價對象信息的文本情感分類
2018-12-06 03:37:34李俊杰宗成慶
廈門大學學報(自然科學版) 2018年6期
李俊杰,宗成慶,3*
(1.中國科學院自動化研究所,模式識別國家重點實驗室 北京 100190;2.中國科學院大學計算機與控制學院,北京 100190;3.中國科學院腦科學與智能技術卓越創新中心,北京 100190)
高速發展的互聯網給用戶提供了眾多的服務和產品評論平臺,例如餐飲領域的大眾點評和Yelp、電影領域的豆瓣電影和互聯網電影資料庫(IMDb)等.這些平臺包含了大量的用戶評論,對這些評論文本進行情感分類是自然語言處理領域的研究熱點之一.本研究關注的任務是文檔級別的情感分類,目的是根據文本所表達的含義和情感信息將文本劃分成兩種(褒義的或貶義的)或幾種類型[1].傳統方法[2-5]主要是從文本中抽取特征,用機器學習的方法訓練分類器,分類效果取決于特征的手動設計和選擇.
繼深度學習方法在計算機視覺、語音識別等領域取得成功之后,越來越多的學者關注如何用這項技術來提高情感分類的效果[6-9].基于深度學習的文本情感分類較傳統方法在準確率上有了大幅提升,但現有模型仍然存在著一個缺點:這些模型只考慮文本信息而忽略了評論發布者以及評論中評價對象的信息,然而這兩類信息對情感分類是非常有用的,主要體現在三個方面:1) 用戶的用詞差異.不同的用戶有著各自的用詞習慣和特點.假設評論的得分范圍為1~3分(其中1,2和3分分別表示貶義、中性和褒義),一個苛刻的用戶可能在評論中屢次出現“好”,“不錯”等這樣表現強烈褒義的詞匯,但是最后的整體得分可能是2分.而在一個較為隨意的用戶發表的評論中,可能會出現“一般”“還行”等,最后的得分卻是3分.充分考慮不同用戶的用詞習慣,對情感分類是有幫助的.2) 用 戶對不同評價對象的不同偏好.面對同一個產品,不同的用戶可能會關注它的不同屬性,這些屬性也常被稱為評價對象.例如在酒店領域,評價對象包括“服務”、“價格”、“地理位置”等,在選擇酒店時,一些用戶可能會比較在意“價格”,而另外一部分用戶可能會更關注于“地理位置”.針對不同的用戶,區別對待這些評價對象對情感極性判別會有幫助.3) 評價對象的修飾詞差異.同樣的詞匯修飾不同的評價對象可能表達不同的情感極性.比如“長”這個評價詞,修飾“手機的待機時間”時,表示的是褒義,修飾“酒店的服務等待時間”時,表示的是貶義.因此需要根據不同的評價對象區分對待詞匯.
針對用戶的用詞差異,文獻[10-12]在傳統的神經網絡的模型中融入了用戶信息,使得該模型可以捕捉用戶在選詞上的差異性,然而上述工作沒有考慮用戶對不同評價對象的不同偏好以及評價對象的修飾詞差異.為了能將這兩類信息充分考慮,本研究提出了一個基于用戶和評價對象的層次化注意力網絡(hierarchical user aspect attention networks,HUAAN)模型,該模型首先利用一個層次化的神經網絡結構來編碼不同層級的信息,包括詞匯層、句子層、評價對象層以及文檔層;然后為了同時考慮用戶在用詞上的差異和對評價對象的不同偏好,在得到詞匯層和評價對象層的表示之后,引入了基于用戶的注意力機制來區分對待不同的詞匯和不同的評價對象;最后為了考慮評價對象的修飾詞差異,還引入了基于評價對象的詞匯層注意力機制來區分對待不同的評價對象對上下文詞匯的影響.
1 HUAAN模型
HUAAN模型的整體結構如圖1所示,一共包含了5個部分:詞匯層編碼、詞匯層注意力機制、句子層編碼、句子層注意力機制和評價對象層注意力機制.表1給出了本研究使用的一些數學符號及其物理意義.
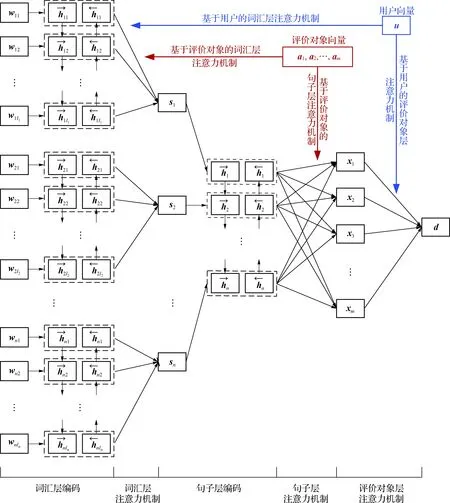
圖1 HUAAN的結構

符號物理意義D數據集d,d一篇評論文本及其向量表示mD中所有評價對象的數目nd中句子的數目ai,ai第i個評價對象及其向量表示u,ud的發布者及其向量表示si,sid中的第i個句子及其向量表示lisi中的所有詞匯數目wij,wijsi中的第j個詞及其向量表示AijAij=1表示句子si里面包含評價對象ajAij=0表示句子si里面沒有包含評價對象ajhijd中wij的隱層向量表示hid中si的隱層向量表示xid中評價對象ai的向量表示αij,βij,γi詞匯層、句子層和評價對象層的注意力權重p評論文本d被賦予各個類別的概率分布pk評論文本d被賦予類別k的概率gd評論文本d對應的情感類別C總類別數目
假設有一個關于某個領域(例如酒店)的評論文本的數據集D,該領域有m個評價對象a1,a2,…,am, 它們分別表示“服務”、“位置”和“食物”等.d是D中的一篇評論文本,它的發布者為u.為了獲取評論文本描述的評價對象,本研究采用文獻[13-14]提出的關聯規則挖掘算法為每個句子賦予一個評價對象集合,這部分內容將在2.1節詳細介紹.下面將介紹HUAAN基于長短時記憶網絡(long short-term memory network,LSTM)[15]的序列編碼模塊及HUAAN的其它各個組成部分.
1.1 基于LSTM的序列編碼
由于HUAAN的建模過程是從詞匯到句子,再從句子到文檔,并且句子是一個詞匯的序列,文檔是句子的序列,因此序列模型是HUAAN的一個基本模塊.該模塊使用的模型是LSTM模型.LSTM是循環神經網絡的一種特殊形式,它通常被用于處理序列數據并且可以避免傳統循環神經網絡出現的梯度爆炸或者是梯度消失的問題.LSTM通過引入記憶單元和門的機制來捕捉序列中長距離的依賴關系.LSTM的計算公式如下:
it=σ(Wixt+Uiht-1),
(1)
ft=σ(Wfxt+Ufht -1),
(2)
ot=σ(Woxt+Uoht -1),
(3)
(4)
(5)
ht=tanh(ot⊙ct),
(6)
其中:σ表示logistic sigmoid函數;⊙表示點乘的操作符;it、ft、ot和ct分別表示t時刻的輸入門、遺忘門、輸出門和記憶單元的激活向量,這些向量和隱層向量ht擁有相同的維度;Wi、Wf、Wo、Wc和Ui、Uf、Uo、Uc分別表示LSTM模型輸入門、遺忘門、輸出門和記憶單元的關于輸入向量和隱層向量的模型參數.
1.2 HUAAN模型基本部分介紹
詞匯層編碼:HUAAN首先將句子si中的每個詞wij編碼成向量wij,然后使用雙向LSTM來編碼wij的上下文信息,從而得到它的隱層表示.具體計算方法如下:
(7)
(8)
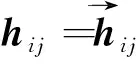
(9)
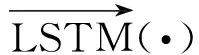
詞匯層注意力機制:句子中所有的詞匯在組成句子的表示時具有不同的重要性,并且不同的用戶有著不同的用詞習慣以及同一個詞匯修飾不同的評價對象時體現的情感極性可能會有差異.于是,本研究引入基于用戶和評價對象的注意力機制來區別對待句子中不同的詞匯,計算方式如下:
si=∑jαijhij,
(10)
其中,αij度量的是在考慮用戶信息和評價對象信息后,句子中第j個詞在構建整個句子si的表示時的重要程度.用戶u和評價對象ai被編碼成向量u和ai. 由于句子si可能會包含多個評價對象,這些評價對象向量的平均向量ti被用來表示這個句子中評價對象的編碼向量:
(11)
然后用式(12)和(13)計算αij:
(12)
(13)
其中,mij為未歸一化的注意力權重αij對應的值,vw、Ww h、Ww u、Ww a和bw分別表示計算mij時的前饋神經網絡中對應的點積權重、隱層向量權重、用戶向量權重、評價對象向量權重和偏置.
句子層編碼:在得到句子向量si之后,本研究使用雙向LSTM編碼句子并得到隱層表示hi:
(14)
(15)
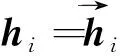
(16)
句子層注意力機制:這里介紹的是如何從句子層的表示得到評價對象層的表示.由于一篇評論中可能會有幾個句子同時描述同一個評價對象,然而這些句子對形成該評價對象的表示時所起的作用是有差異的.句子的前后順序以及句子之間的關系可能都會影響該句子在構成某評價對象表示時的重要性.于是本研究采用句子層注意力機制對這類差異進行建模,其計算公式如下:
(17)
(18)
xk=∑iβi khi,
(19)
其中,li k為未歸一化的注意力權重βi k對應的值,vs、Ws h、Ws a和bs分別指的是計算li k時的前饋神經網絡中對應的點積權重、隱層向量權重、評價對象向量權重和偏置.
評價對象層注意力機制:對于同樣的產品或者是服務,不同用戶關注的東西會有差異.這種差異會導致最后的文檔表示的不同,進而影響情感分類的結果.因此HUAAN在評價對象層時使用基于用戶的注意力機制來區分對待不同的評價對象,并最終得到整個評論文本的向量表示d[16-17]:
(20)
(21)
d=∑iγixi,
(22)
其中,ri為未歸一化的注意力權重γi對應的值,va、Wa h、Wa u和ba分別表示計算ri時的前饋神經網絡中對應的點積權重、隱層向量權重、用戶向量權重和偏置.
1.3 文檔級別情感分類
計算得到評論文本向量d后,可通過式(23)計算出評論文本d屬于各個類別的概率分布P,
P=softmax(Wlhd+b),
(23)
其中Wlh和b分別表示計算概率時的softmax層對應的權重參數和偏置.
最后采用最小化負對數似然為訓練目標:
(24)
其中,1{·}是一個示性函數,當函數內部值為真時,返回1,否則返回0.
2 實驗與分析
2.1 實驗設置
為了驗證HUAAN的有效性,在數據集IMDb和 Yelp2014中進行測試,這2個數據集為Tang等[10]構建的公開數據集.在進行測試之前,需對數據進行預處理,本研究采用 Stanford CoreNLP[18]對數據進行預處理:詞語切分、句子切分和詞性標注.文獻[13-14]提出的關聯規則挖掘算法可以從評論文本中的每個句子挖掘評價對象.該算法從評論語料里抽取頻繁出現的名詞組成評價對象集合.之后,通過簡單匹配句子里面的詞匯和評價對象集合里面的詞匯,為每個句子得到該句子描述的評價對象.假如一個句子里面的詞匯都沒有出現在評價對象集合中,這個句子會被賦予一個特殊的評價對象標簽 “others(其他)”.這里設定評價對象的數目是100,其中包括這個特殊評價對象(others)的符號.為了提高詞性標注的準確率和獲取評價對象集合的質量,本研究刪除了包含超過100個詞的句子的評論文本.表2給出了預處理后數據集的統計數據.
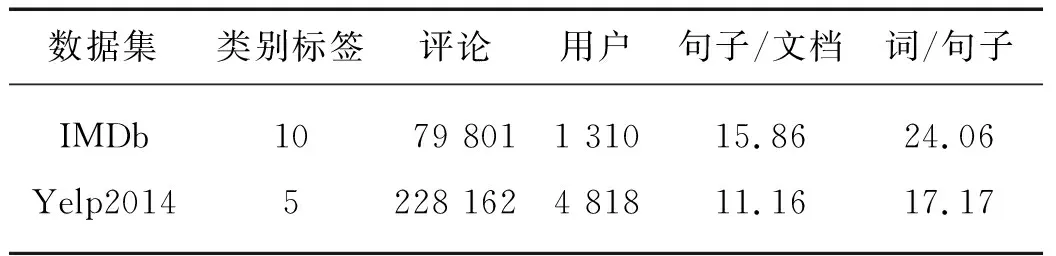
表2 IMDb和Yelp2014數據集的統計數據
數據集按照8∶1∶1的比例劃分為訓練集、開發集和測試集,使用準確率A來度量整體情感分類的性能并使用均方根誤差RMSE來度量預測的標簽與標準答案標簽的差異性.
采用文獻[11]中訓練好的詞向量來初始化HUAAN中的詞向量,詞向量的維度取200.用戶和評價對象的編碼向量維度均設定為200,并且隨機初始化.LSTM隱層參數和記憶單元的維度均設定為200維.訓練時使用adadelta算法更新參數,并使用開發集來調整超參數.
2.2 基線系統
HUAAN將與下面的基線系統進行比較.
1) Majority是一種啟發式的方法.首先統計得到訓練集出現最多的標簽,然后用這個標簽作為所有測試集樣本的標簽.
2) Trigram+支持向量機(SVM)是一種傳統方法.以評論文本的一元語法、二元語法和三元語法作為特征來訓練SVM分類器.
3) AvgWordVec+SVM是一種很簡單的基于詞向量的方法.通過平均評論中所有詞匯的詞向量得到評論向量,然后將這個評論向量作為特征來訓練SVM分類器.
4) HAN[19]用一個層次化的模型對評論進行建模,并且使用注意力機制來區分對待不同的詞匯.該方法僅僅依賴文本信息,并取得了在僅僅考慮文本信息的情況下目前的最好結果.
5) NSC+UPA[11]是目前最好的模型.通過考慮用戶信息和產品信息來提高文檔級別情感分類的效果.
2.3 模型對比
表3給出了HUAAN及基線系統的情感分類結果,這些結果可以分為2組:1) 僅僅考慮文本信息的,2) 同時考慮文本和用戶信息.
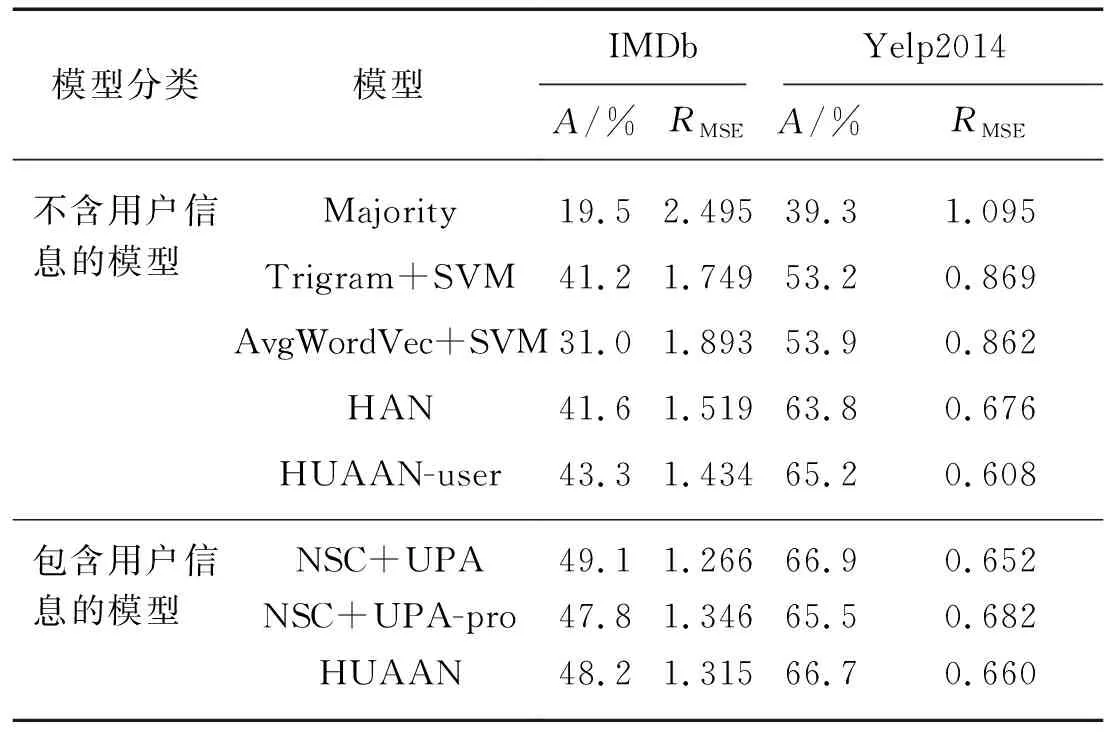
表3 IMDb和Yelp2014數據集上的情感分類結果
注:HUAAN-user為HUAAN的變體,刪減了用戶信息;NSC+UPA-pro為NSC+UPA的變體,刪減了產品信息.
第1組的實驗結果表明Majority效果非常差,因為它沒有包含任何的文本信息.基于一元語法、二元語法和三元語法的Trigram+SVM模型在文檔級別情感分類表現較好,遠好于基于平均詞向量的AvgWordVec SVM模型.HAN通過用一個層次化的模型對文本進行建模,取得了更好的結果.最后,HUAAN-user比HAN、AvgWordVec+SVM和Trigram+SVM在IMDb數據集上的情感分類準確率分別高出1.7,12.3和2.1個百分點,在Yelp2014數據集上分別高出了1.4,11.3和12.0個百分點.
第2組的實驗結果表明,用戶信息確實對文檔的情感分類效果有幫助.當考慮了用戶信息之后,HUAAN比HUAAN-user在IMDb和Yelp2014的準確率分別高出4.9和1.5個百分點.與當前最先進系統NSC+UPA相比,HUAAN也取得了接近的實驗結果.值得一提的是NSC+UPA不僅考慮了用戶信息,還用同樣的方式考慮了產品信息,然而HUAAN卻只考慮了用戶信息.為了公平比較HUAAN和NSC+UPA,本研究測試了NSC+UPA去掉產品信息后的模型NSC+UPA-pro的結果.與NSC+UPA-pro相比,HUAAN在數據集IMDB和Yelp2014上的準確率分別高出了0.4和1.2個百分點.這表明在同等的條件下HUAAN模型要優于NSC+UPA.
2.4 詞匯層、句子層和評價對象層的不同注意力模型的作用
本研究測試了幾種注意力機制模型在HUAAN不同層的作用,當測試某一層時,只改變當前層的注意力機制,其他層的注意力機制與HUAAN相同,結果如表4所示:
1) 與AVG相比,詞匯層、句子層和評價對象層的ATT模型都能提升情感分類的效果.
2) 與ATT相比,UsrATT和AspATT在各層都對情感分類效果有提升,表明本研究提出的這兩種機制可以很好地捕捉到用戶和評價對象在不同層的特點.
3) HUAAN在詞匯層的變體實驗結果表明,引入UsrATT會比引入AspATT效果要好.這個現象說明詞匯層面用戶的差異性會比評價對象的差異性對情感分類的影響更大.當這兩者被同時考慮時,模型可以取得最好的結果.
2.5 基于詞匯層注意力權重展示的樣例分析
為了展示HUAAN可以很好地捕捉不同的用戶用詞偏好,給出如表5所示(詞匯底色越深表示該詞匯的注意力權重越大)的例子.這個例子包含的兩句話,分別是“The hotel is really good with nothing.”和“The food is very good and the hotel is well located.”.前句由用戶A所寫,后句由用戶B發布.這兩句話都含有詞匯“good”,但是兩句話出現在不同的評論中:第一句話出現在一個評分為2星的評論里而第二句話出現在一個評分為5星的評論里,因此在預測這兩篇評論時,詞匯“good”的作用是不同的.HAN使用局部注意力機制來獲取詞匯權重無法區分這兩句話中“good”的差異,均賦予了很高的注意力權重;但是HUAAN基于用戶的模型區分對待這個詞匯,進而獲得更高的準確率.
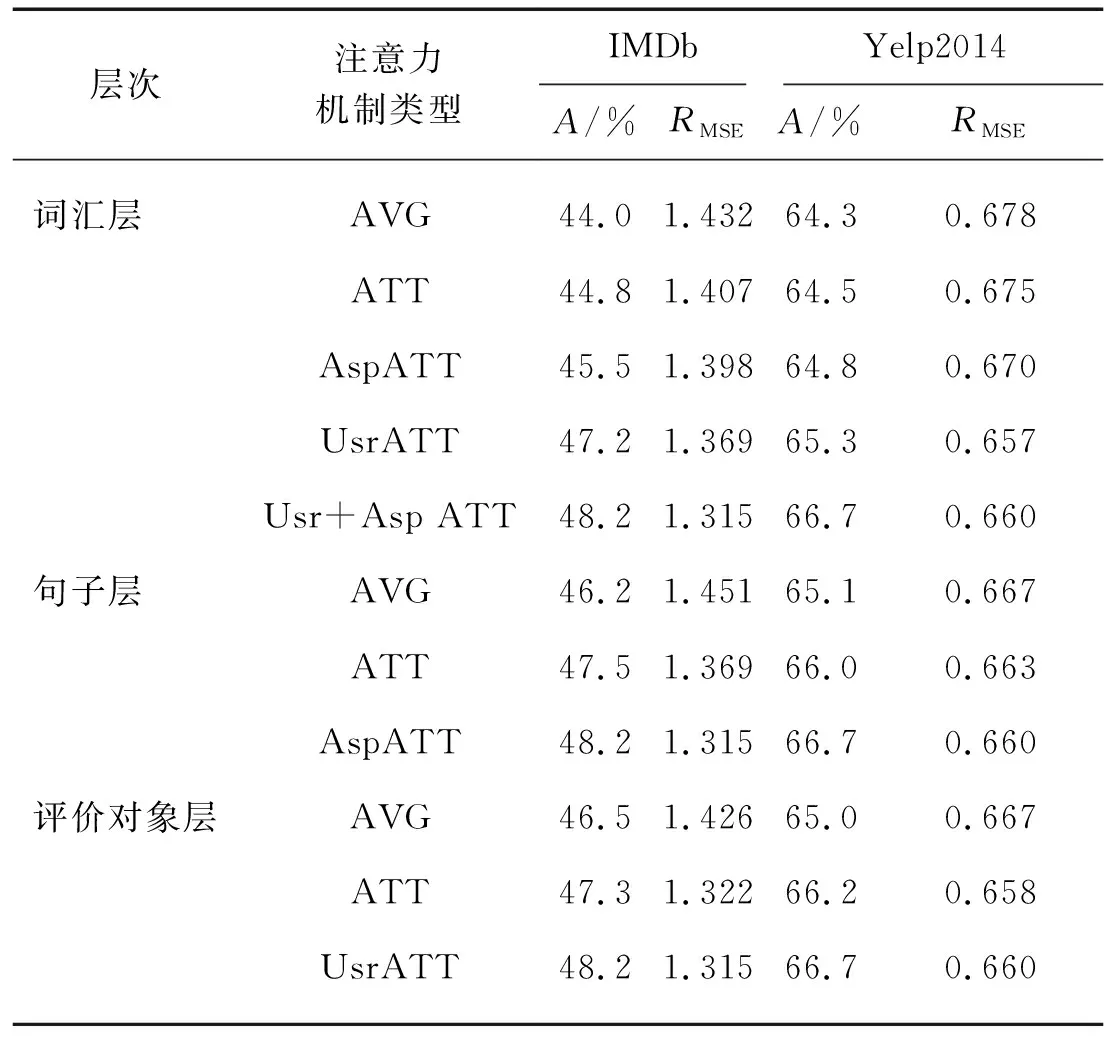
表4 不同的注意力機制模型的情感分類效果
注:AVG為平均池化層注意力機制;ATT是局部語義注意力模型[13];UsrATT為本研究提出的基于用戶的注意力機制;AspATT為本研究提出的基于評價對象的注意力機制;Usr+Asp ATT為將基于用戶的注意力機制和基于評價對象的注意力機制融合.HUAAN在詞匯層、句子層和評價對象層分別采用的是Usr+Asp ATT,AspATT和UsrAtt.
3 相關工作
情感分類是情感分析[20-21]中的一個很典型的問題.繼深度學習方法在計算機視覺、語音識別等領域取得成功之后,越來越多的學者關注如何用這項技術來提高情感分類的效果.它最大的優勢就是不依賴人工定義特征,自動從文本中抽取有用的特征來做分類.Socher等[6-7,22]構建了一系列的遞歸神經網絡的模型來學習句子的表示,取得了很好的效果.Kim[23]采用卷積神經網絡做情感分類也取得了不錯的結果.

表5 詞匯層注意力權重展示
很多工作[19,24]使用層次化的模型對文檔建模,通過得到詞匯層和句子層的語義表示得到整個文檔的語義表示,這類方法在文檔級別情感分類中取得了非常好的效果.盡管如此,這些工作都只關注于文本內容本身而忽視了發布文本的用戶,然而這些用戶卻對確定文本的傾向性有著至關重要的作用.目前已有一些工作[10-12,25-28]將用戶信息引入到情感分類中:Tang等[10]在卷積網絡的模型中添加用戶偏好的矩陣和向量;Chen等[11]將用戶表示成一個向量,然后將其融合到一個層次化的模型來考慮用戶信息對情感分類的作用;Amplayo等[27]研究了針對冷啟動的用戶,如何融入用戶信息來提升情感分類的效果.盡管這些方法都取得了較好的效果,但是它們對用戶信息的考慮還不夠充分,僅考慮了用戶對不同詞匯的偏好,而忽略了用戶對不同評價對象的喜好差異.本研究提出的HUAAN模型可以充分考慮用戶信息并同時考慮了這兩類信息,且在相同條件下優于NSC+UPA系統.
4 結 論
本研究提出了HUAAN模型來對評論文本進行情感分類,該模型用一個層次化的結構對詞匯信息、句子信息、評價對象信息和用戶信息進行編碼,并且引入基于用戶的注意力機制來充分考慮詞匯層面的用戶偏好和評價對象層面的用戶偏好.通過在兩個公開的數據集中做的實驗表明,融入了用戶信息和評價對象信息之后,HUAAN能在同等條件下超過NSC+UPA系統的情感分類準確率.
進一步的研究工作將著重從以下兩個方面入手:
1) 本研究僅使用了最簡單的評價對象抽取算法來抽取文本中的評價對象,下一步可以嘗試更加復雜的評價對象抽取的方法,對比不同評價對象抽取算法對模型的影響.
2) 本研究僅使用了用戶本身信息,還可以拓展為用戶的屬性,如年齡、地域等,下一步可以嘗試考慮如何引入這類信息到本研究的模型中,用來更好地提升情感分類的效果.
猜你喜歡
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
中國生殖健康(2020年5期)2021-01-18 02:59:48
山東醫藥(2020年34期)2020-12-09 01:22:24
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
小學教學參考(2015年20期)2016-01-15 08:44:38
