基于ID3算法的質量保證體系數據關聯度研究
2018-12-08 07:14:00曹安林
網絡安全技術與應用 2018年12期
◆曹安林
?
基于ID3算法的質量保證體系數據關聯度研究
◆曹安林
(南京機電職業技術學院 江蘇 211135)
高等職業院校建立質量保證體系是社會主義市場經濟發展的需求,是區域經濟發展和行業企業發展總趨勢。為社會培育大量高素質應用型技能人才是高等職業院校最基本的人才培養方案和目標。目前,基于網絡的綜合教學管理信息系統得到了各高等職業院校的廣泛應用,在這些管理信息系統的使用過程中,積累了大量的原始數據,然而這些數據只是靜態的儲存在數據庫中,沒有進行深層次的分析并有效利用,不能不說是一種浪費。如何從這些原始數據中發現并提煉出有用的信息,精準的對數據進行分析,并將分析結果加工成有效的信息供管理層決策使用,已經成為了高職院校質量管理與控制體系的應用需求。
ID3算法;質量保證;數據關聯
0 前言
目前,基于網絡的綜合教學管理信息系統越來越廣泛的應用在高職院校,系統中數據基本涵蓋了《高等職業學校設置標準(暫行)》(教發〔2000〕41號)規定的所有辦學指標。單純就某一所高職院校來說,利用人工計算和比對的方式核準辦學指標相對容易,一旦數據中包含了大量院校信息時,人工方式將很難保證準確性和完整性。因此本文以南京機電職業技術學院為案例,將數據挖掘技術的ID3算法歸納決策樹擴展到建立高職院校的質量管理與控制體系,達到應用創新的目的。主要研究內容如下:
1 科學的對基本數據庫中數據進行預處理
如何對基本數據庫中的數據進行預處理,主要采用決策樹的算法分析。決策樹是數據挖掘分類算法的一個重要方法,是在已知各種情況發生概率的基礎上,通過構成決策樹來求取凈現值的期望值大于等于零的概率,評價項目風險,判斷其可行性的決策分析方法,是直觀運用概率分析的一種圖解法。
生成決策樹是采用自上而下的遞歸構造方法。它的輸入是一組帶有類別標記的訓練數據集合,結果是一棵二叉樹或多叉樹。決策樹如果依靠數學的計算方法可以取得相對更加理想的效果。例如:

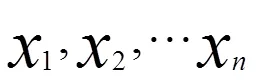
決策樹的生成過程主要是依據對于數據源的采集分析,對數據源進行分類測試,在整個過程中進行單一方向的或者是多個類別的測試和修剪,當一個數據決策樹不能再進一步分割或修剪的時候,對于數據來說整個生成過程也就完成了,也達到了基本數據預處理的目標。
2 ID3算法下的決策樹的剪枝
通常在實際應用中,直接生成的決策樹并不能立即用于對未知樣本來進行分類和應用。由于訓練數據集合存在噪聲,無法實現對新樣本的合理分析,這種條件下,必須要對決策樹進行后期處理——即決策樹的剪枝處理。這樣才能有效的控制和掌握決策樹的發展規模,進而提高預測精度,同時也變得更容易理解。

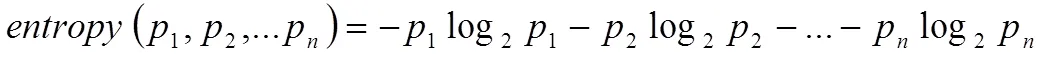
當系統的信息熵降為0時,就沒有必要再往下構造決策樹了,此時葉節點都是純的——這是理想情況。最壞的情況下,決策樹的高度為屬性(決策變量)的個數,葉節點不純(這意味著我們要以一定的概率來做出決策)。
高職院校的質量管理與控制體系數據覆蓋面比較廣,包含種類較多,然其中大部分數據指標以定性屬性為主,即離散型訓練數據集合為主,計算量相對來說并不是很大。選用ID3算法歸納決策樹方法用于質量保證體系數據挖掘系統是較為合適的算法。
3 基于ID3算法的質量保證數據關聯分析
ID3采用自頂向下不回溯的策略搜索全部的屬性空間,它建立決策樹的算法簡單,深度小,分類速度快,相對適宜計算量較小的培訓數據集合。其關鍵在于選取“各個決策屬性中可對訓練數據集合進行最佳分類的屬性”,自上而下的歸納成一組if_then規則,所以計算各個決策屬性的信息增益并加以比較是ID3算法的關鍵步驟。其基本算法如下偽代碼描述:
Define:Decision_Tree(samples,attribute_list);
Input:具有離散型屬性的訓練數據集合samples、決策屬性集合attribute_list
Output:一棵決策樹。
Function:
(1)創建根節點N;
(2)if samples同為類C then;
(3)return N作為葉節點,以C標記;
(4)if attribute_list = null then;
(5)return N作為葉節點,標記為samples中最普通的類;
(6)選擇attribute_list中具有最大信息增益的決策樹性test_attribute;
(7)標記N為test_attribute;
(8)switch case each test_attribute中已知的值;
(9)節點N生長出一個條件為test_attribute的分支;
(10)設置Si為samples中test_attribute=Ai樣本的集合;
(11)if Si=null then;
(12)生成一個葉節點,標記為samples中最普通的類;
(13)else加入由Decision_Tree(Si,test_attribute)返回的節點。ID3通過不斷的遞歸方式,逐步精確決策樹,直到找到一棵完全正確的決策樹。
其數學理論依據:


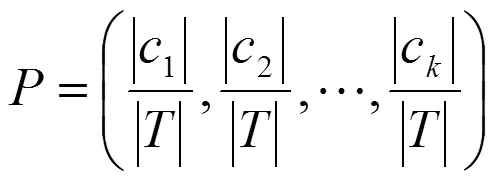
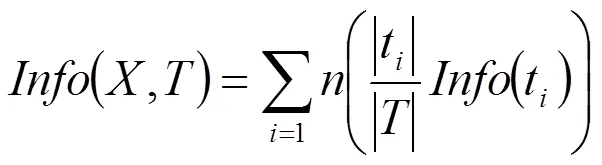
(5)信息增益度是兩個信息量之間的差值,其中一個信息量是需確定T的一個元素的信息量,另一個信息量是在已得到的屬性X的值后需確定的T一個元素的信息量,信息增益度公式為:

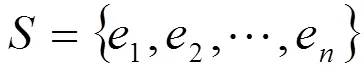

出來的分支。根據有A劃分成子集的熵為:
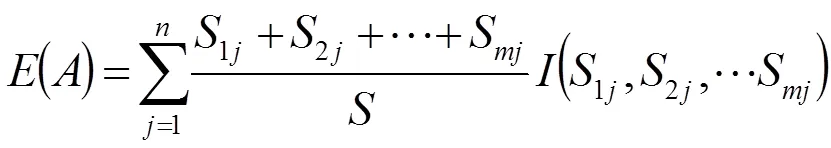
分類后,分類的信息量計算公式為:

其中:
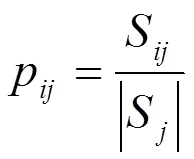
綜上所述,信息增益為:

根據貪心算法,為使下一步所需的信息量最小,則要求每一次都選擇信息增益最大的屬性作為決策樹的新節點。
下面,通過一個具體實例來說明其具體應用過程。學校部分專任教師信息數據:

表1 專任教師信息表
選取部分專任教師職稱作為類別標識屬性,其他屬性為決策屬性,圖1是一棵關于“專任職教師是否具有高級職稱”的決策樹的子樹示意圖:

圖1“專任教師是否具有高級職稱”決策樹示意圖
設訓練數據集合S,S中共有14條記錄,其中職稱分為初級、中級、高級(含副高級)三種,決策屬性數據量相對較為平均,所以套用公式3計算S的期望信息量:
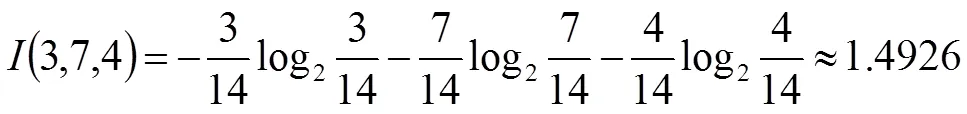
接下來根據公式9計算每個一個決策屬性的信息量,也就是熵,以年齡為例,將年齡分為30~40之間、40~50之間、50以上三個區間,當年齡為30~40之間時:
當年齡為40~50之間時:
當年齡為50以上時:
由此得到年齡的熵為:
所以根據公式11年齡的信息增益G(Age)為:
同理可得性別信息增益G(Sex)=0.0266、學歷信息增益G(Education)=0.4926,當訓練數據集合擴大到全校400名教職、教輔員工時得到的性別信息增益G(Sex)為0.0054,而對于其他的決策屬性大小次序未發生改變,由此可以看出性別對于教師的職稱屬性幾乎不存在影響,所以在對圖1所示的決策樹中刪除性別決策屬性,因為G(Age)值最大,所以選擇年齡作為決策樹的根節點,對每一個分支進行遞歸計算,進行剪枝,剪枝后的決策樹如圖2所示:
4 總結
利用ID3算法對高等職業院校的教育教學進行質量的管控分析,并不是提出改進算法為目的。因此如何通過ID3算法構造一棵最簡決策樹是整個項目中最核心的部門,同時決策樹的剪枝問題是決策樹技術中一個重要的部分。ID3算法能利用直觀的算法描述、數學描述ID3在構造決策樹以及剪枝的詳細過程,同時結合案例進行實例化操作,對建立學院質量保證體系關鍵數據的確立起到很大的指引作用。

圖2 對決策屬性Sex剪枝后的決策樹示意圖
[1]李榮俠.高職院校教學質量監控與評價體系研究[D].南京理工大學碩士學位論文,2007.
[2]彭慧伶,劉發升.關聯規則挖掘與分類規則挖掘的比較研究[J].計算機與現代化.2006.
[3]張保華.數據挖掘現狀及常規分類算法[J].科技創新導報,2008.
[4]季桂樹,決策樹分類算法研究綜述[J]科技廣場,2007.
本文系江蘇省高校哲學社會科學研究基金(專題)項目-基于數據挖掘高職院校質量保證體系的研究 (2017SJB0708) 項目負責人:曹安林。
