基于自動文摘的答案生成方法研究
2018-12-13 09:07:44黃青松劉利軍馮旭鵬
計算機應(yīng)用與軟件 2018年12期
胡 遷 黃青松,2 劉利軍* 馮旭鵬
1(昆明理工大學(xué)信息工程與自動化學(xué)院 云南 昆明 650500)2(昆明理工大學(xué)云南省計算機技術(shù)應(yīng)用重點實驗室 云南 昆明 650500)3(昆明理工大學(xué)教育技術(shù)與網(wǎng)絡(luò)中心 云南 昆明 650500)
0 引 言
隨著自然語言處理技術(shù)的廣泛應(yīng)用和飛速發(fā)展,自動問答系統(tǒng)已然成為了自然語言處理領(lǐng)域的一個熱點。傳統(tǒng)的搜索引擎只能反饋給用戶一系列相關(guān)文檔,自動問答系統(tǒng)能夠使用戶以自然語言輸入問題,并且反饋給用戶一個簡潔、準(zhǔn)確的答案,而不是一系列相關(guān)文檔。這表明和傳統(tǒng)的搜索引擎相比,自動問答系統(tǒng)更加方便、準(zhǔn)確。答案生成是自動問答系統(tǒng)中的一個非常重要的環(huán)節(jié),其主要任務(wù)是對信息檢索得到的原始文檔進(jìn)行處理,得到問題的原始答案集,最終通過一定算法從原始答案集中抽取出正確答案。傳統(tǒng)的答案生成方法有:基于表層特征的答案提取,通過關(guān)系抽取答案、通過模式匹配抽取答案。自動問答中生成答案的形式主要為:以句子中關(guān)鍵詞相似權(quán)重最高的句子作為答案,以檢索文檔中相關(guān)詞的邏輯組合作為答案,以檢索文檔的摘要作為答案。孫昂等[2]提出一種基于句法分析的問句-候選答句組合特征集,并以此訓(xùn)練得到答案分類器完成答案抽取的方法,雖然答案抽取的準(zhǔn)確率有所提高但得到的是經(jīng)過分類的一系列候選答案。李鵬等[3]提出一種基于模式學(xué)習(xí)的形式化答案抽取方法,通過機器學(xué)習(xí)的方法自動生成用于答案抽取的形式化模板,通過問題模式和答案模式的自動匹配,直接獲取答案,雖然取得了較好的答案抽取效果但是不同問題模式的匹配分布不均衡影響了其答案抽取的準(zhǔn)確率。李超等[4]利用深度神經(jīng)網(wǎng)絡(luò)進(jìn)行深層特征的提取,將答案抽取問題轉(zhuǎn)化為特征學(xué)習(xí)與分類問題但是抽出的是精確的答案詞,而不是答案句。
大多數(shù)淺層模型在增加輸入層或隱層時容易出現(xiàn)過擬合現(xiàn)象,并且復(fù)雜函數(shù)的泛化能力變差。而深度學(xué)習(xí)作為淺層神經(jīng)網(wǎng)絡(luò)的延伸,具有較好的特征學(xué)習(xí)能力,可以較好地表征復(fù)雜函數(shù),大大降低了計算復(fù)雜度。隨著深度學(xué)習(xí)在自然語言處理上的廣泛應(yīng)用,近年來神經(jīng)網(wǎng)絡(luò)在自動問答系統(tǒng)中被深入探索并取得重大成果,例如,Mikolov等[5]使用神經(jīng)網(wǎng)絡(luò)模型得到一種名為詞向量(Word Embeding)的詞表示形式。Socher等[6-8]設(shè)計深度神經(jīng)網(wǎng)絡(luò)對句子建模實現(xiàn)了句子的向量表示。文獻(xiàn)[9-11]在基于循環(huán)神經(jīng)網(wǎng)絡(luò)的編碼-解碼(RNN Encoder-Decoder)結(jié)構(gòu)的機器翻譯和自動文摘任務(wù)上取得了突破。基于以上的研究成果,針對自動問答答案生成的兩個關(guān)鍵問題:如何實現(xiàn)答案的語義表示,如何減小實現(xiàn)問句答案間的語義匹配誤差,本文提出了基于自動文摘的答案生成方法,該方法利用LDA(Latent Dirichlet Allocation)模型[12]計算問題文本的主題概率向量并計算問題文本間相似度。獲取由與用戶問題相似的知識庫問題的答案構(gòu)成的原始答案集后,利用循環(huán)神經(jīng)網(wǎng)絡(luò)構(gòu)建基于編碼-解碼結(jié)構(gòu)的序列到序列學(xué)習(xí)模型Seq2Seq(Sequence to Sequence)對原始答案集進(jìn)行摘要生成答案句。
1 基于自動摘要的答案生成方法
本文方法主要工作包括問題之間的主題相似度計算和利用深度強化學(xué)習(xí)模型訓(xùn)練生成答案。任務(wù)流程如圖1所示,首先將知識庫中的問題文檔通過文本預(yù)處理轉(zhuǎn)換為文檔-特征詞矩陣,然后對用戶問題文檔進(jìn)行LDA建模計算獲得每篇問題文檔的主題分布向量θi,基于主題分布向量計算問題文本間的相似度得出與用戶問題相似主題的問題-答案對L=(Q,S),最后將這些答案順序拼接構(gòu)建成原始答案集S=(S1,S2,…,Sm)并利用Seq2Seq學(xué)習(xí)模型對原始答案集S進(jìn)行摘要獲得最終答案并反饋給用戶。

圖1 基于自動文摘的答案生成方法流程圖
本文充分考慮了自動問答中用戶以自然語言提出的問題句式結(jié)構(gòu)復(fù)雜并且存在多種語義的特點,提出通過多個相似問題答案的組合構(gòu)建原始答案集,然后抽取摘要形成最終答案的方法。相較于傳統(tǒng)自動問答中直接用最相似問題的答案作為最終答案的方法,本文所提出的方法不僅避開了傳統(tǒng)答案生成方法存在的單一主題偏向性問題,還提高了答案的主題覆蓋率并且提高了生成答案的準(zhǔn)確率。本文通過計算問題文本間的主題相似度查找出知識庫中用戶問題的相似問題集,相較于傳統(tǒng)以特征詞計算相似度,不僅減少了工作量,更提高了句子間相似度計算的準(zhǔn)確性。
1.1 基于主題的問題相似度計算
主題模型是文本挖掘的重要工具,用來在一系列文檔中發(fā)現(xiàn)隱含主題的一種統(tǒng)計模型,可以對文本進(jìn)行語義挖掘。主題模型自動分析每個文檔,統(tǒng)計文檔內(nèi)的單詞,根據(jù)統(tǒng)計的信息來斷定當(dāng)前文檔的主題信息[13]。常用的主題分析方法包括LSA(Latent Semantic Analysis)、PLSA(Probabilitistic Latent Semantic Analysis)和LDA。其中,LSA模型認(rèn)為特征之間存在某種潛在的關(guān)聯(lián)結(jié)構(gòu),將高維空間映射到低維的潛在語義結(jié)構(gòu)上,并用該結(jié)構(gòu)表示特征和對象,消除了詞匯之間的相關(guān)性影響,并降低了數(shù)據(jù)維度,增強了特征的魯棒性。但是LSA無法解決一詞多義的問題,由此在LSA的基礎(chǔ)上Hofman提出了PLSA模型。然而,PLSA中,主題分布和詞分布都是唯一確定的,而LDA則不同。在LDA中,主題分布和詞分布是不確定的,在LDA中主題分布和詞分布使用了Dirichlet分布作為它們的共軛先驗分布。針對自動問答中用戶以自然語言提出的問題句式結(jié)構(gòu)復(fù)雜并且存在多種語義的特點,本文采用LDA模型完成用戶問題和知識庫中問題文檔的主題相似度計算。
LDA模型是一種非監(jiān)督的文檔主題生成模型,用來高效率識別大規(guī)模語料庫中的主題信息。LDA模型由經(jīng)驗參數(shù)(α,β)確定。設(shè)θi=(T1,T2,…,TK)表示第i個問題主題的概率分布,而Tk表示該問題文本下第k個主題的概率。
利用LDA模型計算問題文本相似度過程如下:
(1) 根據(jù)Dirichlet分布Dir(α)得到m個問題文本的主題分布概率矩陣θ=(θ1,θ2,…,θm)作為m個問題文本的語義表示,每個問題的主題分布是一個服從參數(shù)為α的Dirichlet先驗分布中采樣得到的Multinomial分布,則根據(jù)LDA模型我們可以得到第i個文本的主題分布概率向量θi主題k的Dirichlet的分布期望Tk為:
(1)

(2) 利用余弦公式計算用戶問題文檔主題概率向量與知識庫中問題文檔主題概率向量的距離。從問答知識庫中選出與用戶問題最為相似的若干問題-答案集L=(Q,S),將問題-答案集L中的答案順序取出構(gòu)成原始答案集S=(S1,S2,…,Sm)作為下一步生成用戶問題的答案的訓(xùn)練集。利用余弦公式計算問題的主題相似度的過程如下:
(2)
式中:θ1表示用戶問題的主題概率向量,θ2表示知識庫問題的主題概率向量。余弦值越接近于1,表明兩個問題文本的主題概率向量的距離越近即問題文本的主題相似度越高。
1.2 基于自動文摘的答案生成
文中采用自動摘要的形式生成最后答案。自動摘要,從技術(shù)上來說主要分為抽取式摘要、壓縮式摘要和理解式摘要。本文以問答知識庫中選出的與用戶問題最為相似的若干問題的答案集構(gòu)成的初始答案集S=(S1,S2,…,Sm)作為原始語料,利用循環(huán)神經(jīng)網(wǎng)絡(luò)構(gòu)建Seq2Seq學(xué)習(xí)模型對訓(xùn)練語料進(jìn)行建模,形成基于多文檔的抽取式答案生成方法。
近年來基于神經(jīng)網(wǎng)絡(luò)的編碼-解碼結(jié)構(gòu)的序列到序列學(xué)習(xí)方法已經(jīng)在自然語言處理任務(wù)中取得了重大成果。Paulus等[14]提出一種結(jié)合注意力機制序列到序列學(xué)習(xí)方法和深度強化學(xué)習(xí)的摘要算法,在編碼時采用雙向長短期記憶網(wǎng)絡(luò)LSTM(Long Short-Term Memory),解碼時采用單向LSTM并引入注意力機制,最后使用監(jiān)督加強學(xué)習(xí)的方法優(yōu)化輸出。由于,本文的原始語料是基于原始答案S的簡單拼接而成,所以存在較多冗余信息,這嚴(yán)重影響了生成摘要的可讀性。為此,本文在上述模型的基礎(chǔ)上進(jìn)行了改進(jìn),提出在解碼部分引入詞頻估計子模型[15-16]WFE(word-frequency estimation sub-model)在摘要生成時進(jìn)行冗余剪除,得到簡潔的準(zhǔn)確答案。
本文所提出的基于自動摘要的答案生成方法是基于結(jié)合注意力機制的序列到序列學(xué)習(xí)模型。本文在編碼階段應(yīng)用兩層雙向LSTM進(jìn)行編碼,在解碼階段應(yīng)用一層單向的LSTM進(jìn)行解碼,并分別于編碼解碼階段引入注意力機制防止解碼階段對編碼的同一部分重復(fù)解碼,使得解碼器在處理長文檔時不會產(chǎn)生重復(fù),然后在解碼器中嵌入WFE模型控制解碼生成字符的頻率,防止冗余生成。其解碼流程圖如圖2所示。

圖2 解碼器流程圖
(3)

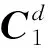
(4)
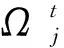
(5)
(6)

(3) 混合訓(xùn)練目標(biāo)。

(7)
通過每次迭代產(chǎn)生兩個獨立輸出序列:
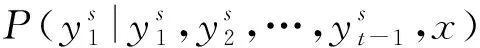

③ 定義r(y)為輸出序列y的獎勵函數(shù),將其與真值序列y*相比較作為我們的評估指標(biāo)。
(8)
從式(8)中可以看出,如果抽樣獲得比基線輸出更好的獎勵,最小化Lrl相當(dāng)于最大化抽樣序列ys的似然估計。
定義γ為Lml和Lrl大小差別的換算系數(shù),可以得到最終的混合訓(xùn)練目標(biāo):
Lmixed=γLml+(1-γ)Lrl
(9)
由于,我們的最大似然函數(shù)訓(xùn)練目標(biāo)本質(zhì)上是條件語言模型,基于先前序列yt-1來預(yù)測下一個序列yt的概率,最終的優(yōu)化目標(biāo)使得學(xué)習(xí)算法生成更為自然的摘要作為答案反饋給用戶。
2 實 驗
2.1 數(shù)據(jù)準(zhǔn)備
為了驗證模型在自動問答答案生成中的效果,本文從百度知道中獲取了來自文化領(lǐng)域12 756條、財經(jīng)領(lǐng)域11 044條、健康領(lǐng)域11 200條,共計35 000條問答語料作為自動問答知識庫進(jìn)行訓(xùn)練,通過數(shù)據(jù)清洗、分詞、詞性標(biāo)注之后進(jìn)行文摘訓(xùn)練。
2.2 實驗設(shè)計
本實驗使用準(zhǔn)確率(P)、召回率(R)和F-Measure(F)對實驗結(jié)果進(jìn)行分析。這里準(zhǔn)確率采用人工標(biāo)注的方式對檢索到的問題相似度等級進(jìn)行判定:
P=檢索到相似度高的問題數(shù)/實際檢索到總問題數(shù)
R=檢索到與用戶問題相似問題數(shù)/系統(tǒng)中所有相似度高文檔總數(shù)
在自動文摘部分,本實驗使用ROUGE[17](Recall-Oriented Understudy for Gisting Evaluation)和人工可讀性評價分?jǐn)?shù)作為自動文摘對比實驗性能標(biāo)準(zhǔn)。
本實驗計劃分為4個部分:預(yù)處理;參數(shù)設(shè)置;加入詞頻估計子模型的深度強化學(xué)習(xí)的摘要算法與普通深度強化學(xué)習(xí)的摘要算法的性能對比實驗;本文算法與傳統(tǒng)自動問答的答案抽取算法的對比實驗。
實驗中預(yù)處理部分,采用中文分詞工具對實驗語料進(jìn)行分詞處理,并除去停用詞,將文本表示為文本-詞向量。
基于循環(huán)神經(jīng)網(wǎng)絡(luò)的編碼-解碼框架在自然語言處理領(lǐng)域有著非常廣泛的應(yīng)用,在本文實驗中選用其作為基本框架,用雙向LSTM作為編碼器,單向LSTM作為解碼器。
實驗中參數(shù)設(shè)置部分,在自動問答中問題語句通常不會過長,因此本文在利用LDA模型對問題文本進(jìn)行相似度計算中設(shè)置主題個數(shù)為9。LDA處理中設(shè)置先驗超參數(shù)為α=5.55、β=0.01。在文本摘要算法部分,我們采用200維的LSTM用于雙向編碼,400維的LSTM用于單向解碼,限制輸入字符不大于150 000,輸出字符不大于50 000。
2.3 實驗結(jié)果及分析
在實驗的第3部分,為了評價本文所提出的基于摘要的答案生成算法,我們首先構(gòu)建原始答案集S,從問答語料中隨機抽取400組問答語料作為測試集,對其預(yù)處理后進(jìn)行LDA建模找出知識庫與測試集主題相似的5組問答語料集,實驗結(jié)果如表1和表2所示(以其中一條測試語料為例)。
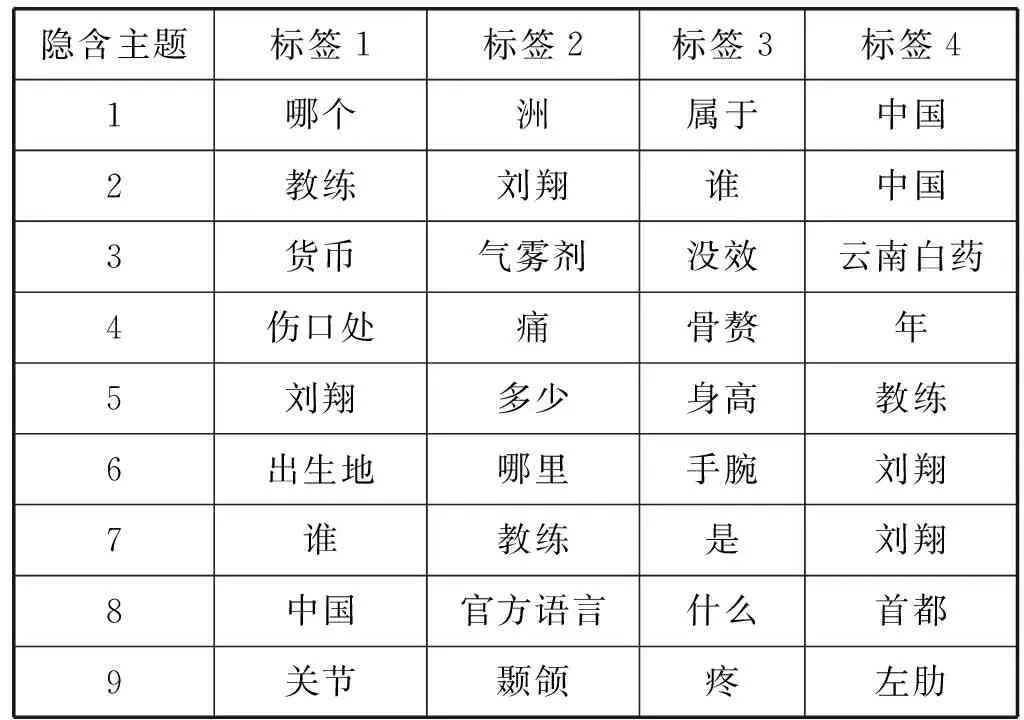
表1 隱含主題標(biāo)簽構(gòu)成
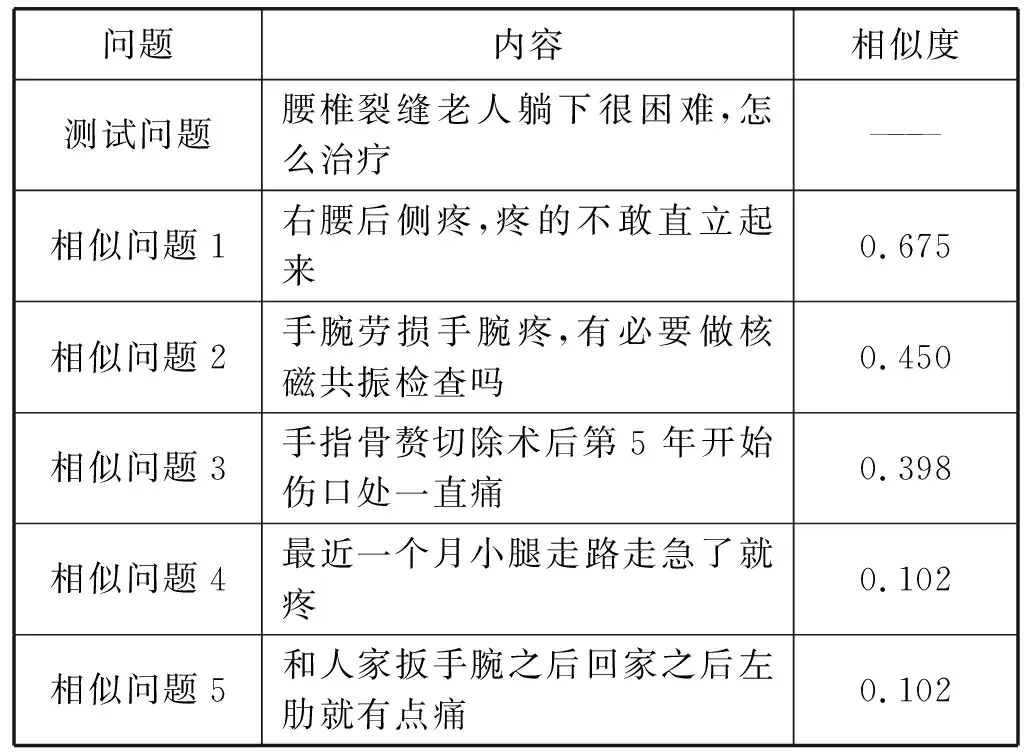
表2 與測試語料最為相似的5組問句語料
利用5個相似問題對應(yīng)的答案語料進(jìn)行順序拼接構(gòu)成原始答案集S=(S1,S2,S3,S4,S5),我們使用400組測試語料原始答案集的進(jìn)行文摘對比實驗,在對比實驗中采用ROUGE中ROUGE-1、ROUGE-2、ROUGE-L的分?jǐn)?shù)和人工可讀性評價分?jǐn)?shù)作為評價指標(biāo),并以ROUGE-L的分?jǐn)?shù)作為加強獎勵。實驗結(jié)果如表3所示。
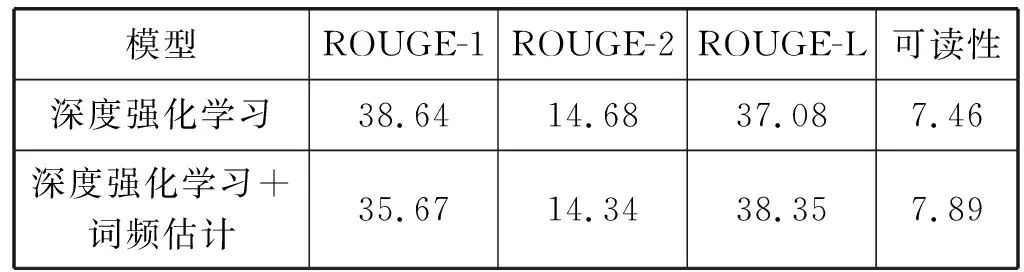
表3 文摘部分兩種模型的定量結(jié)果
從表3中可看出,雖然本文提出的算法在ROUGE-1和ROUGE-2的得分比深度強化學(xué)習(xí)稍低,但是在ROUGE-L與可讀性指標(biāo)上得分稍高,這表明在針對原始答案集S進(jìn)行摘要的問題上,本文提出的算法有著較優(yōu)的表現(xiàn)。由于本文提出的算法在解碼階段阻止了出現(xiàn)頻率過高字符的再次生成在一定程度上解決的原始答案集S本身存在大量冗余的問題,本文所提出的算法比單一的基于深度強化學(xué)習(xí)的摘要算法有著較優(yōu)的可讀性,實驗與預(yù)期結(jié)果相符。
在實驗的第4部分,本文分別就文化領(lǐng)域、財經(jīng)領(lǐng)域和健康領(lǐng)域的問答語料集,以準(zhǔn)確率(P)、召回率(R)和F-Measure為標(biāo)準(zhǔn)分別對本文所提出的答案生成方法與傳統(tǒng)自動問答中的答案生成方法進(jìn)行了對比實驗。在第4部分對比試驗中,本文設(shè)計了針對問答語料集,與文獻(xiàn)[2]提出的基于句法分析和答案分類的答案抽取方法(SA-AC)、文獻(xiàn)[3]提出的基于模式學(xué)習(xí)的形式化答案抽取技術(shù)(FAE)和文獻(xiàn)[4]提出的句法分析和深度神經(jīng)網(wǎng)絡(luò)的答案抽取方法(SA-DNN)的對比實驗。實驗結(jié)果如圖3-圖5所示。

圖3 各方法準(zhǔn)確率對比圖

圖4 各方法召回率對比圖
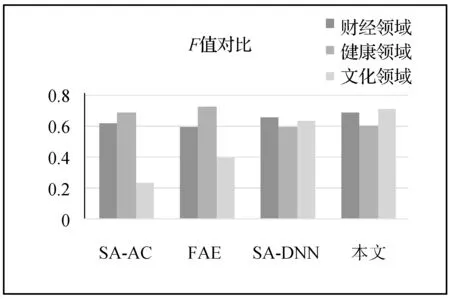
圖5 各方法的F值對比圖
(1) 從準(zhǔn)確率對比圖中可以看出,SA-AC、FAE、SA-DNN和本文在財經(jīng)領(lǐng)域的準(zhǔn)確率上的雖然差別并不大,但是本文所提出的方法有著最高的準(zhǔn)確率。然而就健康領(lǐng)域看,F(xiàn)AE有著相對較好的效果。這是因為在健康領(lǐng)域的測試語料中包含較多的醫(yī)學(xué)專業(yè)術(shù)語,基于模式學(xué)習(xí)的形式化答案抽取方法命名實體辨別性能較好,相反基于句法分析和神經(jīng)網(wǎng)絡(luò)的答案無法有效識別專業(yè)詞匯,但是在文化領(lǐng)域本文所提出的方法有著最高的準(zhǔn)確率。
(2) 從召回率對比圖中可以看出,本文所提出的方法在三個領(lǐng)域都有著較高的召回率。本文提出以問題文本的主題概率向量作為特征完成問題間相似度計算并最終完成答案抽取的方法,相較于其他方法有著較高的主題覆蓋度,所生成的最終答案也更為全面可靠。
(3) 從F值對比圖中可以看出,在財經(jīng)和文化領(lǐng)域本文所提出的方法有著最好的表現(xiàn),在健康領(lǐng)域本文所提出的方法雖然表現(xiàn)較差卻較SA-DNN有著較好表現(xiàn)。
由實驗結(jié)果對比圖可以看出,本文所提出的答案抽取方法在財經(jīng)領(lǐng)域和文化領(lǐng)域都有著相對較高的準(zhǔn)確率和召回率,取得了較好的結(jié)果,但是在健康領(lǐng)域結(jié)果較差。這是因為健康領(lǐng)域語料中包含了較多醫(yī)學(xué)上的專業(yè)術(shù)語導(dǎo)致本文在提取其主題向量并生成答案時產(chǎn)生了比較大的誤差。
綜合以上實驗結(jié)果可以得出,本文提出通過問題的主題向量計算問題相似度的方法相比SA-AC方法不僅減少了文本向量空間,還忽略了文本本身的結(jié)構(gòu),減小了句法分析中由于問題文本本身結(jié)構(gòu)混亂語義復(fù)雜帶來的誤差。除此之外,本文提出通過原始答案集摘要生成答案的方法相比FAE,避免了單一模式匹配生成答案的偏向性問題,主題涵蓋范圍更廣,并且本文以答案句作為結(jié)果相比SA-DNN的結(jié)果更具有可讀性。最終可以得出結(jié)論,本文所提出答案抽取方法可以有效提高生成答案的準(zhǔn)確度和可信度,但是在專業(yè)名詞的深層語義辨析上存在一定的缺陷。
3 結(jié) 語
本文提出了一種基于自動文摘的答案生成方法。將問句文本通過分詞、停詞等文本預(yù)處理轉(zhuǎn)換成文檔-詞向量矩陣,利用LDA模型對句子進(jìn)行建模得出每個問句的主題概率分布向量并計算問句間的相似度。根據(jù)問答知識庫中與用戶問題相似的若干問題的答案構(gòu)建原始答案文檔集,并進(jìn)行Seq2Seq學(xué)習(xí)模型訓(xùn)練摘要得出最終答案反饋給用戶。實驗表明本文的模型在自動問答答案生成的準(zhǔn)確度上有一定程度的提高,但是本文所提出的方法在專業(yè)名詞的深層語義理解上仍然存在很大的缺陷,本文后續(xù)將繼續(xù)探討基于自動問答的文本挖掘。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
