結合評分時間和用戶空間的協同過濾推薦算法
2018-12-13 09:17:26李炎艾均蘇湛
計算機應用與軟件 2018年12期
李 炎 艾 均 蘇 湛
(上海理工大學光電信息與計算機工程學院 上海 200093)
0 引 言
隨著科學技術和計算機應用的高速發展,人類進入了信息爆炸的時代。面對海量的信息,用戶需要根據其信息需求投入大量的時間進行信息過濾和信息選擇,產生了信息過載問題[1]。推薦系統是解決這個問題行之有效的方法,并且在這些年發展迅速。推薦系統根據用戶的信息需求,為其提供個性化的推薦,在海量的信息空間中,為用戶推薦有用的信息[2]。目前推薦系統主要包括基于協同過濾的推薦[3-4],基于內容的推薦技術[5],基于網絡的推薦技術[6]和混合推薦技術[7-9]四類。目前應用廣泛且頗受歡迎的是協同過濾推薦算法,在物品推薦的過程中只依賴推薦的社交性而不需要關注物品的信息就可以實現推薦。
協同過濾推薦算法通常根據用戶行為計算每一對對象的相似度度量,并向相似的用戶推薦一個類似的項目。例如,如果用戶A與用戶B相似,那么兩個用戶在項目上做了相同的評價,而用戶B喜歡項目C,但是用戶A還沒有對項目C進行評價,那么此算法可以假定用戶A喜歡項目C,并將其推薦給用戶A。該過程的核心步驟包括計算對象相似度,根據相似度選擇對象的鄰居,并根據鄰居的評級來預測評級。
傳統上,網絡科學一直專注于靜態網絡來探索鏈接預測。也就是說,在計算過程中,類似的方法會將節點之間的連接持久化。然而,越來越多的人認識到,大多數推薦系統最好被描述為時間網絡,其中的鏈接只是間歇性的或有一定的重量衰減。另外,在推薦系統中節點的空間分布很少是科學家考慮的因素,因為拓撲結構不保持任何空間信息或位置約束,并影響相似計算的結果。很多學者針對時序方面提出了一系列的方案。文獻[10]結合物品信息和情境上下文信息,發現情境上下文在提高推薦質量上有明顯作用。文獻[11]提出結合上下文信息得到的結果更容易獲得用戶信任。文獻[12]提出時間物品提前過濾的方法,也就是說選擇與目標時間相同的評分信息當作訓練集去訓練推薦模型的算法。文獻[13]提出結合用戶行為的時間信息對于提高推薦質量有明顯作用。文獻[14]提出的即時推薦系統能夠提供量身定制的推薦列表,充分滿足用戶的需求,幫助他們獲得有用的信息以及大數據空間里感興趣的資源。但以上算法主要研究了用戶行為時間特性,而忽略了用戶所處的空間對于推薦的影響,所以本文利用用戶行為的時間特性和用戶空間因素,采用結合評分時間和用戶空間的方法對推薦算法進行研究。
在現實生活中,用戶的興趣會隨著時間的變化而改變,用戶最近的評分相比用戶以前的評分更能體現用戶的興趣點。所以在進行用戶相似性計算時,對用戶評分進行時間衰減,將原來單一評分改為相對時間的評分來降低歷史評分對推薦的影響力,相應地增加最近評分對推薦的影響力。這樣用戶評分的時間特性對推薦的作用得以體現。
對于空間,假設用戶在這樣的推薦系統中構建一個隱藏的社交網絡,每兩個用戶之間的連接就會推斷出他們的品味或者友誼,以及用戶在一個空間中的分布情況。在每個用戶的空間約束下,可以通過使用用戶之間的距離來選擇鄰居,而不是通過相似性。本文把用戶抽象成網絡節點,用戶之間的相似度作為用戶之間連接的邊權重,利用復雜網絡拓撲布局算法[15]建立用戶空間網絡布局。通過用戶空間布局計算所有用戶之間的空間距離,根據用戶空間距離選取一定數量的鄰居用戶,最終計算用戶對未評分物品的預測評分值。
1 研究方法
1.1 協同過濾推薦算法
協同過濾推薦算法一般分為兩種類型:一種是基于用戶的協同推薦(UBCF),另一種是基于項目的協同推薦(IBCF)[3-4]。
UBCF算法從用戶角度出發,計算用戶相似度,從而確定目標用戶的鄰居用戶,為目標用戶進行項目推薦。
IBCF算法從項目角度出發,計算項目相似度,從而確定該項目的相似項目,為用戶進行項目推薦。
UBCF算法主要通過以下5個步驟實現物品的推薦:
(1) 初始化用戶行為信息,建立用戶評分矩陣;
(2) 通過相似度公式計算用戶相似度;
(3) 根據用戶相似度結果,選取目標用戶的鄰居用戶;
(4) 求出用戶對物品的預測評分,生成評分預測矩陣;
(5) 根據評分預測矩陣,選擇前N個項目組成推薦物品集合進行Top-N推薦。
推薦系統中用戶集合為U={ui|1≤i≤m},表示有m個用戶,物品集合為O={oj|1≤j≤n},表示有n個物品。用戶的評分矩陣集合為R={ria}∈Rm,n,其中ria表示用戶i對物品α的評分值,評分值的差異反映了用戶對物品興趣度。另外設置一個與評分矩陣集合對應的集合A={aiα}∈Rm,n,若用戶i對物品α評過分,則aiα為1,否則為0。表1即為UBCF算法的用戶-物品評分矩陣模型。雖然表1顯示了用戶對物品的行為信息,但用戶行為的時間特性并沒有表現出來。
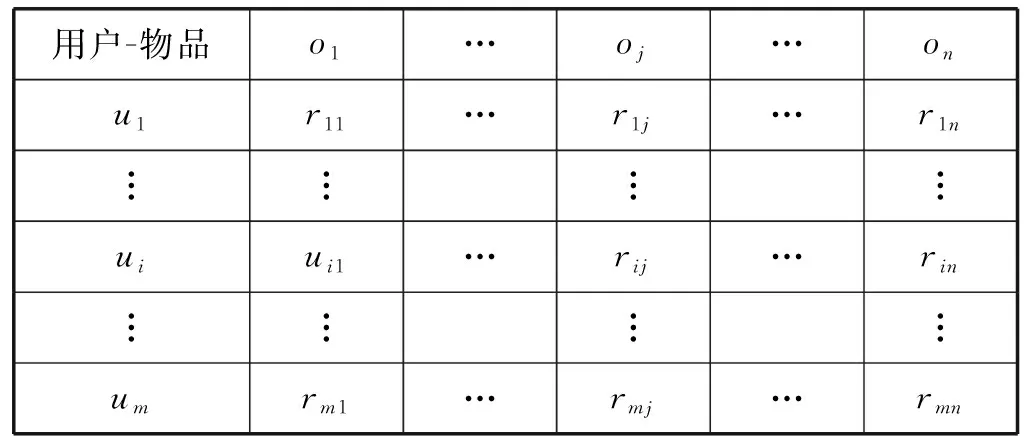
表1 用戶-物品評分矩陣
UBCF算法通過用戶相似度確定用戶的鄰居用戶。本文采用基于用戶的皮爾遜相似度計算公式計算用戶相似度[16],公式如下:
(1)
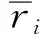
UBCF算法選擇相似度最高的前m個用戶作為其鄰居用戶,構成鄰居用戶集合Ti。由于已知用戶相似度以及鄰居用戶的評分信息,利用式(2)對目標用戶ui的所有未評分物品oj進行評分預測。
(2)
1.2 基于時間和空間的用戶相似算法
考慮到一個包含n個節點和m條邊的復雜網絡G,我們認為網絡G分布在一個空間區域內。其中t表示G的時間屬性,而且節點代表推薦系統中的用戶,邊代表用戶之間的連接,比如用戶之間的相似性。
基于時空的推薦算法由以下規則組成:
規則1初始化用戶之間的連接。
規則2初始化用戶之間的位置。
規則3用戶對物品的評分改變了它們的連接和位置。
規則4用戶對物品的評分隨著時間的變化而有一定程度的衰減。
規則5對于用戶的評分預測,其對項目的評分取決于項目的平均評分和用戶最近鄰居的評分。
把用戶集合U中所有用戶抽象成網絡節點,記用戶節點數n,通過式(1)計算用戶之間的相似度S(i,j),把用戶之間的相似度作為用戶節點之間連接的邊權重,記用戶之間的連接邊為m。利用復雜網絡拓撲布局算法建立用戶之間的網絡布局。由于數據量龐大,本文對用戶網絡布局中的邊進行篩選,公式如下:
(3)
以k=1為例,用戶空間網絡布局如圖1所示。

圖1 k=1時用戶網絡布局
在用戶空間網絡布局中,對于每一個用戶ui都會生成一個坐標(xui,yui,zui),因此,利用歐幾里得距離公式可以計算出相關聯用戶之間的空間距離,公式如下:
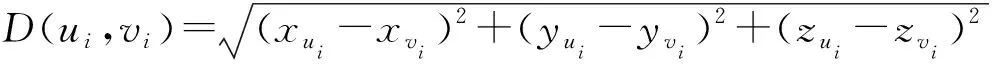
(4)
對用戶空間距離升序排列,用戶之間距離越小,說明用戶之間相關聯程度越高。取出與目標用戶距離最近的前m個用戶作為其鄰居用戶集合TDi。
例如,有10個用戶,用戶編號為1到10,其中用戶1為目標用戶,其余9個用戶為用戶1的相似用戶,取用戶1的5個鄰居用戶。用戶相似度如表2所示。
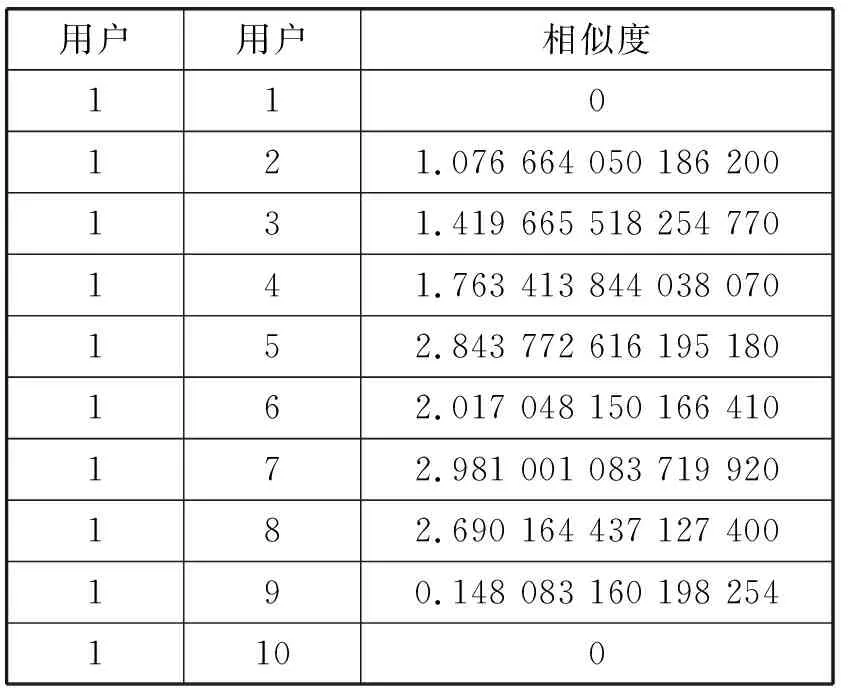
表2 用戶1與其余用戶相似度
本文對于鄰居用戶的選擇是基于用戶空間距離,有別于傳統的基于用戶相似度選取鄰居用戶的規則。用戶1的空間布局如圖2所示。
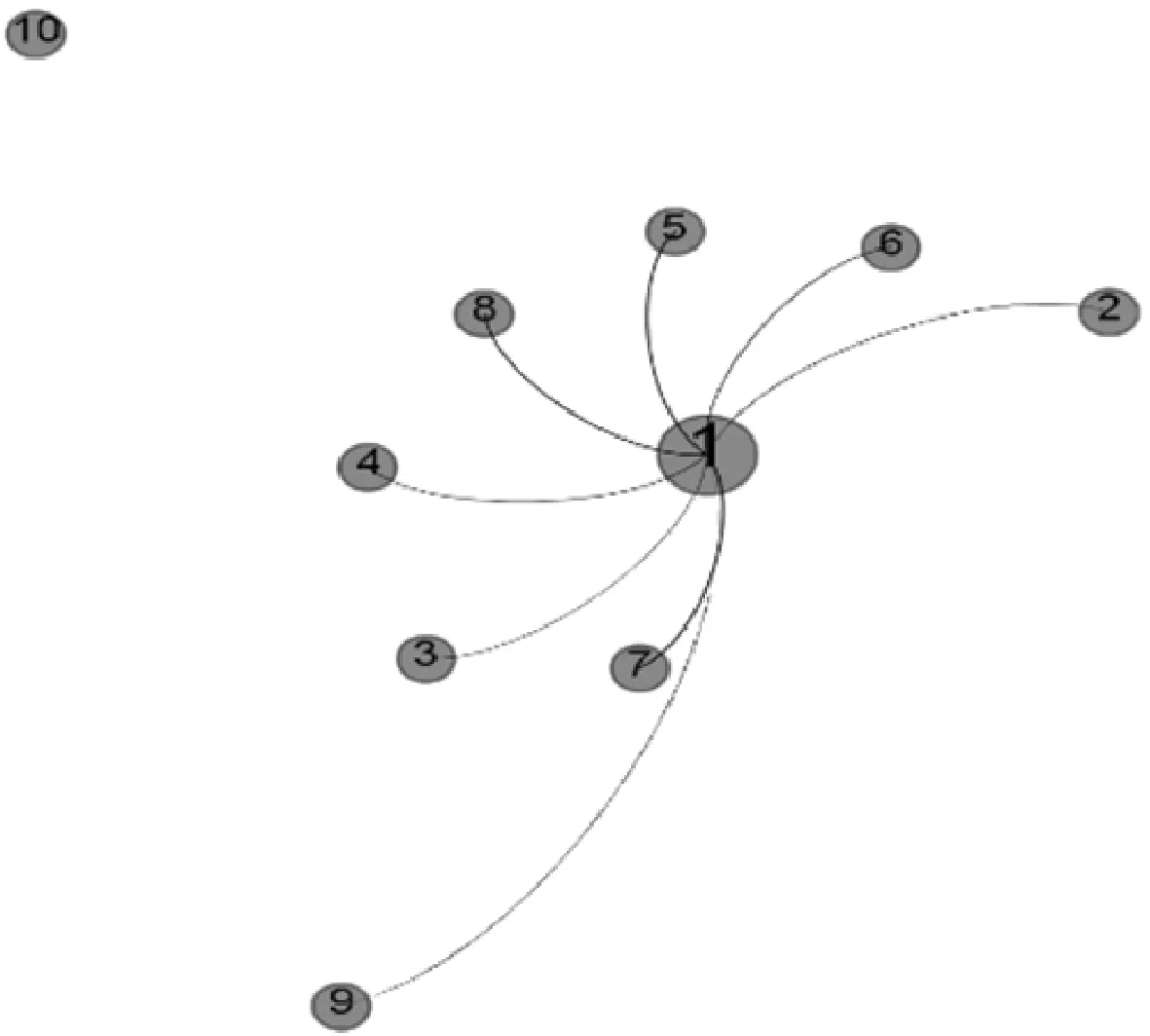
圖2 用戶1的空間布局
圖2清晰地展示了用戶1與其余用戶的拓撲結構圖。用戶之間的空間距離也能直觀地顯示在圖中,并且距離越近的鄰居,與用戶1的連邊越清晰。
本文使用拓撲布局算法,為空間中每個用戶生成空間坐標。利用式(4),計算用戶1與其他用戶的空間距離。需要說明的是,對于沒有連邊的用戶,即使也有相應的空間坐標,但是默認與用戶1的空間距離無限大。用戶1與其他用戶空間距離如表3所示。對表中與用戶1的空間距離進行升序排序,由于取用戶1的前5個鄰居,故取與用戶1距離最小的前5個用戶,分別為7,5,8,6,4。
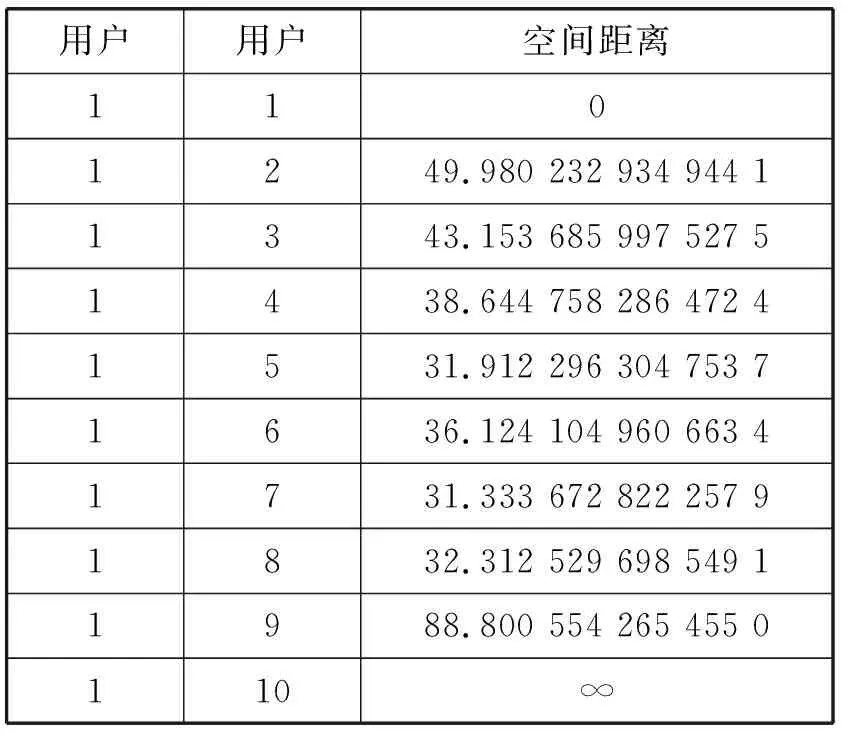
表3 用戶1與其余用戶的空間距離
對于用戶評分的時間效應,本文引入時間衰減函數,公式如下:
(5)
式中:t為推薦時間;t(riα)為用戶i對物品α的評分的時間信息;γ為時間衰減因子,取值為[0,1)之間的小數。當衰減因子γ遞增時,衰減函數w(t,t(riα))呈遞減趨勢,當γ越大時,說明時間的影響越大,可以動態的調整γ值來優化推薦結果。當衰減因子γ=0時,公式沒有衰減,即不考慮時間因素,僅考慮用戶空間因素對推薦結果的影響,這種情況需要與衰減后的情況進行對比。
式(5)按照歷史評分產生的時間對評分的重要性進行了衰減,生成用戶-物品的衰減評分值RT(ui,oj)。
1.3 算法基本思想
根據以上描述,本文的算法思想如下:
輸入:<用戶(user),物品(item),用戶行為(rating),時間戳(TimeStamp)>。
輸出:預測評分值矩陣
步驟1根據用戶對物品的評分信息建立“用戶-物品-評分-時間”模型。
步驟2利用式(1)計算用戶相似度S(i,j),利用復雜網絡拓撲布局算法建立用戶空間網絡布局,并且為每一個用戶生成空間坐標(xui,yui,zui)。
步驟3利用式(4)計算所有用戶之間的空間距離D(ui,vi),然后選取前m個用戶作為其鄰居用戶集合TDi。
步驟4在用戶-物品-評分-時間模型中,利用式(5),計算用戶-物品的衰減評分值RT(ui,oj),再利用式(1)計算評分衰減之后的用戶相似度ST(i,j)。

2 實驗結果及分析
2.1 實驗數據
在數據集選取方面,MovieLens數據集不僅記錄了943個用戶對1 682部電影的100 000條評分[17],而且記錄了用戶行為的時間戳信息,所以可以作為實驗的數據集。
實驗將數據集劃分為訓練數據集和測試數據集,其中訓練數據集占80%,測試數據集占20%。這樣有利于減少偶然因素帶來的不利影響,保證實驗的準確性。為了檢驗結合評分時間和用戶空間的協同過濾推薦算法(TS)的有效性,本文用基于皮爾遜用戶協同過濾算法(UCF-Pearson-Opt)和基于皮爾遜物品協同過濾算法(ICF-Pearson-Opt)作為對比[18]。
在實驗結果對比中,鄰居個數選擇從10開始,直到150,每次增加10。需要說明的是,鄰居個數為5的對比結果也一并列出。
2.2 評價指標與結果及分析
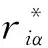
(6)
(7)
實驗使用MAE值和RMSE值度量推薦算法的準確度,MAE值和RMSE值越小,說明準確度越高。
本文提出的算法中,衰減系數γ是至關重要的參數。因此,首先通過實驗研究了衰減系數γ對推薦結果的影響,選取最優的衰減系數。評價指標結果如圖3和圖4所示。
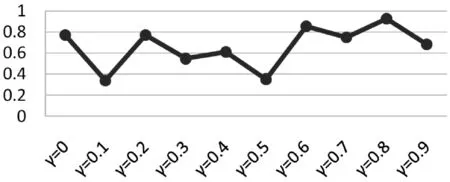
圖3 算法的MAE值隨著的變化
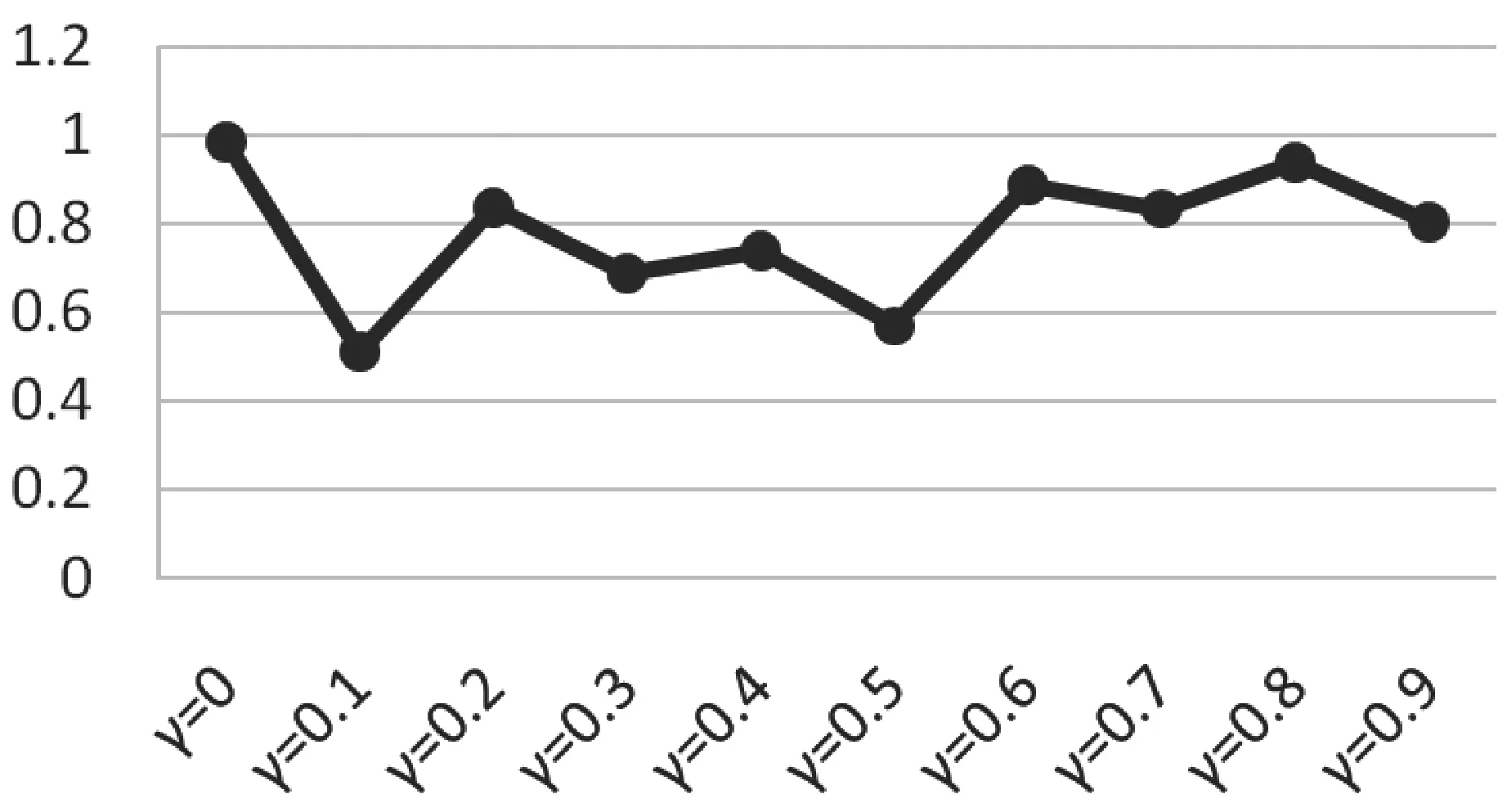
圖4 算法的RMSE值隨著的變化
在圖3和圖4中,橫坐標均代表衰減因子γ,縱坐標分別代表MAE值和RMSE值。可以看出,當衰減因子從0增加到0.9時,MAE值和RMSE值波動比較大。當衰減系數γ=0.1時,MAE值和RMSE值均取最小值。
為了比較不同算法的預測效果,計算UCF-Pearson-Opt和ICF-Pearson-Opt與本文提出的TS在不同鄰居數目的平均絕對誤差和均方根誤差。需要說明的是,當衰減系數γ=0時,即沒有考慮時間因素,僅考慮在用戶網絡布局中,空間距離因素對于推薦算法結果的影響。結果分別如圖5和圖6所示。
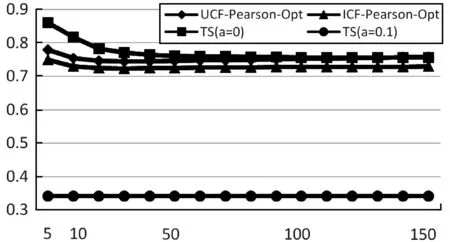
圖5 三種算法的MAE值,TS為本文算法

圖6 三種算法的RMSE值,TS為本文算法
在圖5和圖6中,橫坐標均代表目標用戶的鄰居用戶數目,縱坐標分別代表MAE值和RMSE值。可以看出,本文所使用的TS算法在衰減因子γ=0.1時效果最好,在目標用戶鄰居數目為5時MAE值最低,為0.340 102 736;當鄰居數目為80時RMSE最低,為0.508 920 893,并且隨著用戶相似鄰居數目的增長,曲線呈水平增長,說明TS算法的穩定性較好。
TS算法在衰減系數γ=0.1時的誤差比ICF-Pearson-Opt算法更低,MAE值提高了38%,RMSE值提高了41%,說明了本文算法的有效性。當衰減因子γ時,隨著鄰居數目的增加,MAE值和RMSE值由遠遠高于UCF-Pearson-Opt和ICF-Pearson-Opt算法逐漸歸為持平狀態,說明在僅考慮用戶空間因素方面還有待改進和優化。
3 結 語
結合三種算法的結果可知,TS算法在衰減系數γ=0時,推薦效果并不顯著。當衰減系數γ=0.1時效果最好,相比ICF-Pearson-Opt算法,MAE值提高了38%,RMSE值提高了41%。綜上所述,在MovieLens數據集上,通過實驗證明,與傳統的協同過濾算法比較,本文所用算法的準確率有顯著提高,并且算法的時間復雜度較低。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
