分析基于Hadoop的醫療信息存儲及檢索技術研究
2018-12-18 11:09:40南陽醫學高等專科學校
電子世界 2018年23期
南陽醫學高等專科學校 張 琪
本文在研究中以Hadoop醫療信息管理系統為核心,分析Hadoop技術的應用價值,構建基于Hadoop的醫療信息管理系統,提出醫療信息儲存技術和檢索技術,實現醫療信息管理的現代化和智能化,并為相關研究人員提供一定的借鑒和幫助。
在國民經濟不斷發展中,醫院經營管理逐漸朝著信息化的方向發展,像電子病歷或是PACS系統等臨床信息系統都逐漸應用,大大提高了運行效率。在信息化發展中,醫療信息儲存和檢索中的問題逐漸暴露出來,傳統分散式數據儲存模式的弊端較大,無法保證數據的安全性和可靠性,再加上數據備份流程過于繁瑣,無法發揮出數據信息的潛在價值。傳統數據中心主要以Unix服務器為主,運行成本高,數據讀取速度較慢,再加上計算能力低,無法滿足醫療信息的管理需求和使用需求。對此,本文依托于Hadoop技術,構建基于Hadoop的醫療信息管理系統,優化醫療信息儲存技術和檢索技術,有助于醫療信息的利用,進而提高醫療水平。在這樣的環境背景下,探究基于Hadoop的醫療信息存儲及檢索技術具有非常重要的現實意義。
一、Hadoop技術的應用價值
(一)安全而可靠
醫療信息儲存的安全性和可靠性直接關系到醫院各項醫療業務的連續性,一旦醫療信息系統發生故障,數據儲存能力、備份能力以及恢復能力就顯得至關重要,安全性和可靠性是醫療信息儲存的首要標準。Hadoop系統可以提供十分可靠的數據儲存,各個類型的數據存在三份備份,這對數據儲存形成保障。同時,數據中心會對醫療信息數據進行統一保存,臨床信息系統不會直接保存數據,而是將產生的數據傳輸到數據中心保存,臨床所需數據會直接從數據中心調取,避免數據丟失的情況發生,保證數據的完整恢復。
(二)儲存成本低
以Unix為主的傳統服務器具有價格高、擴展儲存空間小的特點,以SSD固態儲存器為核心元件,不僅價格貴,在擴展容量的過程中,會受到服務器柜容量的影響,而服務器的軟件成本也很高。而基于Hadoop為主的數據中心,選擇傳統PC集群進行數據中心的構建,無論是整個電腦還是傳統硬盤,價格較低,便于達到動態擴展的效果。與此同時,Hadoop平臺可以支持和開發開源軟件,無需軟件費用,節省不必要的軟件成本。在構建基于Hadoop的數據中心容量中,一般存在兩種方式,一是擴充傳統PC硬盤容量,便于操作;二是添加廉價PC,為信息挖掘和利用提供根本保障。
(三)查詢速度快
傳統服務器以機械硬盤為主,數據讀取速度慢,若選擇固態硬盤,其建設運營成本較高,無法長期負擔。而基于Hadoop分布式框架為基礎的數據中心,底層為分布式文件系統,可以讓文件儲存與查詢同步進行,以多線程的方式,提高系統的運行速度,數據讀寫速度也遠遠高于傳統服務器,協助醫生快速獲取到PACS映象文件速度,進而保證工作效率。
二、構建基于Hadoop的醫療信息管理系統
(一)系統框架
如圖1所示,為基于Hadoop的醫療信息管理系統框架,由MapReduce、HDFS等組件構成,其中Hadoop Common為支持項目運行的功能模塊,MapReduce組件協助Map與Reduce處理,而HDFS分布式文件系統以文件分布式儲存為主要功能,ZooKeeper則為分布式鎖服務,支持分布式應用程序的構建。
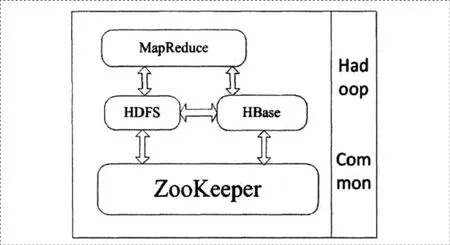
圖1 基于Hadoop的醫療信息管理系統框架
在這一系統框架中,各種功能模塊和應用程序為海量醫療數據讀取與計算提供支持,用戶不需要關注程序就可以實現,特別是在分布式系統運行中,PC集群屬于硬件資源池,可以拆分即將執行的任務,安排空閑機器資源進行數據處理,通過并行計算的方式,提高系統運行速度,使得任務分解后逐一完成,并通過Reduce來整合結果,進而實現醫療信息的存儲和檢索。
(二)HDFS系統
HDFS系統是一種分布式文件系統,具有命名空間單一、數據專一性強、可以被分割和分配等特性,主要以master/slave架構為主,由命名節點、數據節點以及客戶端等模塊構成,內部通信以TCP/IP協議為主。在實際運行中,命名節點與數據節點均運行在商用機器上,而商用機器主要運行Linux操作系統,可以兼容其他機器的DataNode,通過集群單一命名的方式,簡化整個為系統構架,將NameNode作為HDFS元數據的判定者,提高系統運行的穩定性。
(三)MapReduce系統
MapReduce為編程模型,應用在大規模醫療數據集并行運算中,依托于Map和Reduce思想,借鑒于函數式編程語言與矢量編程語言,針對函數式編程語言而言,map為列表中的各個元素計算,Reduce為列表中的各個元素迭代計算,利用傳輸函數的方式實現計算,Map和Reduce主要是提供計算框架。在MapReduce系統運行中,map會對原始數據進行處理,每個原始數據間無任何關聯,在Reduce階段中,數據會通過key下的若干Value進行組織,各個Value間已經形成一定的關聯性。對此,MapReduce就是將一些無規律數據根據某一特征進行歸納和處理之后的結果,map針對無規律不關聯的數據信息,對各個數據進行解析,提煉出key與value,找到數據特征,再通過歸納和處理得到結果。
三、基于Hadoop的醫療信息存儲和檢索
(一)信息儲存
在醫療數據分析處理中,Hadoop平臺能夠實現分布式存儲,并且對大量廉價計算機進行集合整理來存儲數據,實現PB數據集數據的存儲。理論意義上來說,Hadoop平臺能夠盡可能滿足海量電子病歷文檔以及醫療信息數據的存儲需求。另一方面,云計算具有較強的靈活性,而Hadoop平臺的擴展性好,當出現突發情況,特別是患病高發期或者集體性醫療事件會導致醫療數據劇增的問題,這時Hadoop平臺就可以快速、有效的向集群中添加計算機節點和儲存資源。
在醫療信息儲存中,分別有讀寫控制模塊、寫入模塊和刪除模塊進行控制,包括結構化數據和非結構化數據,及時將數據寫入到系統中,通過創建數據表接口與寫數據接口,結合讀寫模塊制定的規定進行信息重構,將時態集合當成操作對象,把信息數據周期性傳輸至Hadoop儲存模型中,獲得標識變量與指定數據包屬性,并把對應數據記錄到HBase中,保證數據信息的一致性,并添加至索引結構中,對HDFS中的原始數據進行處理得到存儲數據,再利用寫數據接口對處理后的數據進行存儲。
(二)信息查詢
Hadoop平臺提供了強大的分布式并行處理數據的能力,Hadoop平臺主要是針對海量數據的批處理進行操作。并且它具有一次寫入多次讀取的特點,能夠滿足醫生、專家在海量的醫療數據或者電子病歷數據中查找閱讀有關的信息。醫療數據檢索查詢可以通過Hadoop的計算資源對醫療數據及電子病歷文檔進行處理,不僅速度快、準確性高,從而大大提高醫療信息數據的檢索效率。
在醫療數據儲存系統中,數據查詢包括基于主鍵的非時態數據查詢與時態數據查詢,利用顯示層應用接口支持可擴展API,實現填充式數據讀取,用戶可以根據需求在顯示界面窗口中設定關鍵詞進行數據整合和讀取,通過并行計算機框架Map/Reduce編程進行數據查詢。針對用戶查詢請求而言,系統會預先判斷,在不干擾時態查詢操作的基礎上,把查詢結果直接輸入到用戶程序中,通過可視化界面進行查閱。若干擾時態查詢操作,則需要將Map/Reduce處理所產生的基于關鍵字的查詢結果導入到與原始存儲數據結構一致的另一張HBase數據表中,在時態元素的標量化處理后調用數據查詢模塊進行時態關系代數演算處理,完成數據的查找操作。(封朝永.導師:左亞堯基于Hadoop的時態信息存儲與檢索策略的研究[D].廣東工業大學碩士論文,2014-05-01)
四、結束語
綜上所述,在醫療信息存儲和檢索中,為了改變傳統醫療信息管理系統的避免,需要引入Hadoop系統,構建基于Hadoop的醫療信息管理系統,提高系統運行效率,減少運行成本,并通過系統構架的簡化,提高計算運行速度,進而保證信息存儲和檢索的綜合效率。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
