基于卷積神經網絡的RGB-D圖片分類
2018-12-20 07:55:00徐小杰
電子設計工程 2018年24期
柳 暢 ,徐小杰
(1.中國科學院上海微系統與信息技術研究所,上海200050;2.上海科技大學信息學院,上海201210;3.中國科學院大學北京100049)
近年來,深度感知設備發展迅速,傳統照相機和深度感知設備的結合廣泛應用于各個領域。為獲得同一場景的彩色(RGB)圖片和深度(D)圖片,常用的方法是使用一種同時具備相機鏡頭和深度傳感器的設備,比如已經廣泛商用的Kinect。RGB-D圖片比傳統的RGB圖片多出的深度信息帶來了更多三維空間的立體感。因此,學術界特別是機器人和計算機視覺領域,對RGB-D圖片的應用研究日益廣泛。網上大量公開的RGB-D數據集[1-3]也方便了不具備人力物力條件自己制作數據集的學術研究者們使用。
深度學習[4]作為一種近幾年提出的方法,在高級信息感知方面的成就遠遠超越了傳統的機器學習方法。在圖像處理的相關應用中,一個非常重要的網絡結構是卷積神經網絡(CNNs)。這種網絡結構可以有效地提取二維圖像中某一點鄰域內的信息。因此,對于圖片這種相鄰像素點間具有很強相關性的數據,CNNs是非常合適的網絡結果。就目前來說,CNNs已經在圖像分類[5-8]、分割[9-11],目標識別與檢測[12-14]等方向得到了成功的應用。
在圖像分類問題上,基于CNNs的方法[5]已經超越了傳統的機器學習方法,但是它們往往是以彩色(RGB)圖像作為輸入數據。如果增加一維深度(D)信息,是否能再次提高分類準確率?針對該問題,本文提出了一種將深度信息和彩色信息結合的方法,探索并發現了它們的最佳組合方式,最后設計實驗證明了深度信息能夠將圖片分類準確率提升至少5%。
1 RGB-D數據預處理
1.1 建立訓練數據集
由華盛頓大學(University of Washington,UW)維護的RGB-D物體數據集(RGB-D Object Dataset)[1]是目前學術研究領域應用最為廣泛的數據集之一。它包括了51類常見物品,包括水果、蔬菜和各種日用品,每一類包括5到10種顏色形狀不同的個體。整體算來,共有約300種獨立的個體(instance)。對于每個個體,該數據集提供了分別從 30°、45°、60°俯視角下,用Kinect環拍的視頻。為方便圖像處理領域的研究工作,該數據集也提供了由環拍視頻轉換來的圖像數據:每個個體約600對RGB-D圖片和對圖片中物體的掩碼圖(mask)。
由于該數據集包含的圖片總量達到了207,920對,為減少實驗時間同時得到合理可靠的實驗結果,我們在每個大類中隨機抽取687對圖片,組成數據子集用來訓練。由于每個大類中包括不同外形的個體和拍攝角度,我們從30°和60°俯視角的圖片集中抽取訓練集和驗證集,從45°俯視角中抽取測試集。以“蘋果”為例,該大類中共包括5種不同外形的個體,那么就需要均勻地從每個個體的兩個俯視角度的圖像集中分別隨機選擇687/5/2≈69對RGB-D圖。最后,保留35 000對并打亂順序。它們將作為本文實驗的訓練集和驗證集。在45°俯視角的圖片集中,用同樣的方式選出5 000對圖片作為測試集。本文中所有實驗結果均為測試集上的實驗結果。
1.2 RGB-D數據預處理
本文使用的RGB-D數據如圖1,2所示,分別是彩色圖像和深度圖像。圖2中的黑色部分表示此處的深度信息缺失。為降低其對于網絡訓練的影響,我們采用NYU Depth V2數據集提供的補洞腳本來填補這些缺失的深度數據(然后將灰度值縮放到[0,1]),結果如圖3所示。

圖1 RGB圖

圖2 D圖

圖3 填充D圖
為避免復雜背景對算法效果的影響,該數據集的制作者已經嚴格控制了環境顏色。在此基礎上,我們使用提供的掩碼圖對目標物體摳像,最后我們的訓練數據如圖4,5所示。

圖4 RGB圖去背景
由于數字圖像在不同的色彩空間內有不同的表達形式,我們將本屬于RGB色彩空間的數據分別轉化到HSI、Lab、YUV等空間,或轉為灰度圖像(Grayscale)共訓練使用。

圖5 D圖去背景
2 CNNs網絡設計
2.1 CNNs網絡結構
本文的CNNs結構如表1所示。輸入數據是36×36×n的圖像,n取1、3、4,分別表示深度圖像、彩色圖像和RGB-D圖像。卷積層#1_1包括48個5×5卷積核,移動步長(stride)為1,池化層#1_2對每個2×2的格子做max-pooling,格子移動步長為2(即格子間互不重疊)。在每個卷積和全連接層后使用線性整流函數(Rectified Linear Unit,ReLu)作為激活函數。最后使用Softmax分類器做51分類。

表1 CNNs結構
2.2 概率累加
多個CNNs的連接方法通常是從每個網絡取出某個激活函數的輸出,串聯成一個更長的列向量,送入后面的網絡層,以此合并成一個樹形網絡。這種網絡往往需要較復雜的調參技巧才能收斂到較好的結果。本文將n個Softmax分類器的輸出結果進行疊加,并再次歸一化,得到最終用來分類的概率向量(如圖6)。這種設計參考了Boosting算法的思想,希望色彩信息和深度信息能夠互相取長補短,以達到更好的分類效果。
圖6中算子f進行逐元素計算,公式如下:
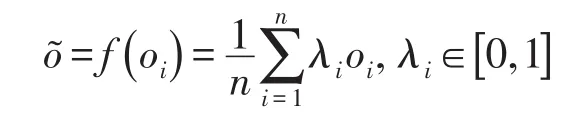
其中,oi表示第i個網絡輸出的概率向量。權重λi體現了不同網絡對最終結果的影響程度。本文中固定λi=1。
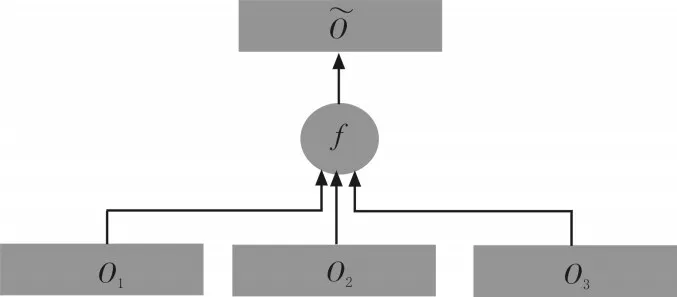
圖6 概率累加示意圖
3 實驗分析
本文使用MatConvNet作為CNNs網絡搭建和訓練的框架。硬件設備是配有Intel Core i7 3.60 GHz的CPU和8GB內存的計算機。
CNNs訓練時,我們用正態分布于[0,0.01]的隨機數初始化卷積層和全連接層的權值矩陣W,偏置b統一設為0。為加快收斂速度,使用批梯度下降法(Batch Gradient Descent)來優化網絡參數,batch大小為200。經初步測驗,對整個訓練集反復使用16次,即16個epoch后,目標函數收斂到較低值,因此我們在前8個epoch中,設學習率為0.01,后8個epoch降至0.001,使得訓練損失(loss)能夠平緩地下降。
3.1 CNNs預訓練結果
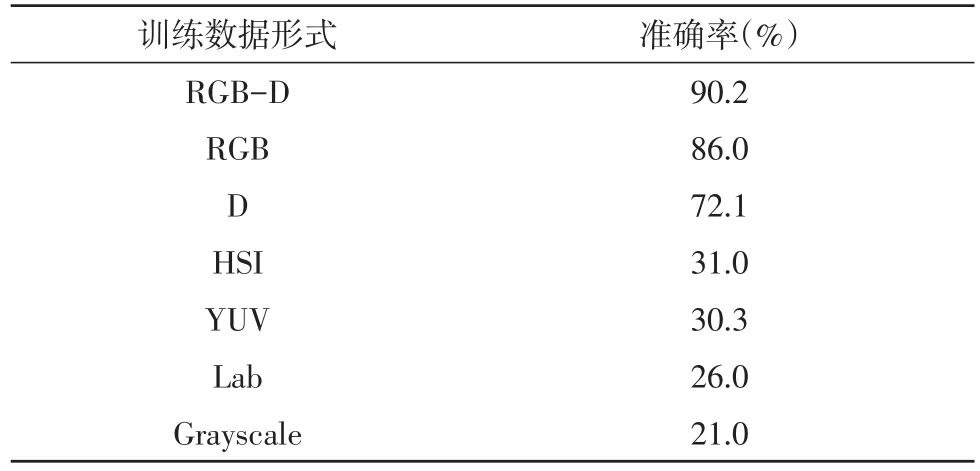
表2 預訓練準確率
表2展示了將同一個物體的不同表達形式作為網絡輸入,得到的預測準確率。其中RGB-D的準確率遠高于其他的如入形式,但數值上也不盡如人意。用HSI、YUV、Lab和Grayscale訓練分類網絡是失敗的。原因在于訓練出的網絡泛化性能較差。在訓練集上,它們的loss普遍下降很快最終收斂,但是在驗證集和測試集,loss達到某個值(0.05)左右便不再下降。
概率累加的思想需要選擇分類效果相對較好的弱分類器來實現由弱到強。下一節中我們將RGBD、RGB、D 3個網絡自由組合,找出分類效果最好的一組。
3.2 概率累加結果
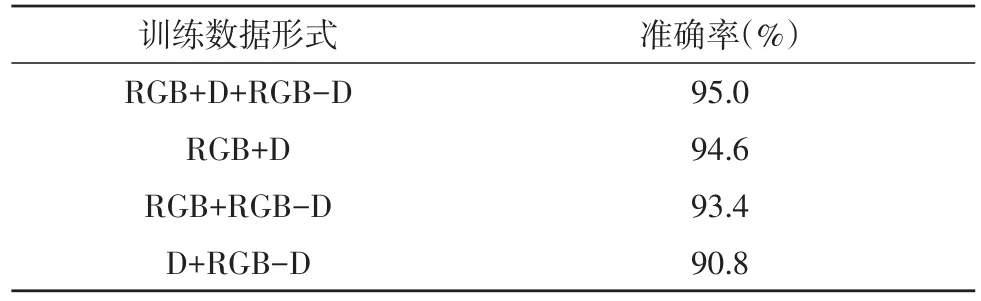
表3 組合準確率
實驗證明,由RGB-D、RGB和D三者的組合表現最佳,達到了95.0%的準確率。RGB和D的組合也達到了94.6%,非常接近最高值。從本質上來看,RGB-D在三者組合中其實是冗余的,對RGB和D的組合,通過增加epoch和適當調參能夠達到95%以上的效果。比較RGB+RGB-D和D+RGB-D的組合可以看出,色彩信息在分類任務中的作用大于深度信息。

表4 與其他算法結果對比
表4將本文實驗的最佳結果與目前發表的兩個成熟算法進行比較。本文使用了相對簡單的網絡結構,結合Boosting的思想,在本文的數據集上達到了比文獻[15-16]更高的準確率。對于每個大類的分類結果如圖7,X軸表示正確的標簽(label),Y軸表示網絡預測的標簽,灰色方格表示將標簽X預測為標簽Y的概率。整體看來,預測結果準確。
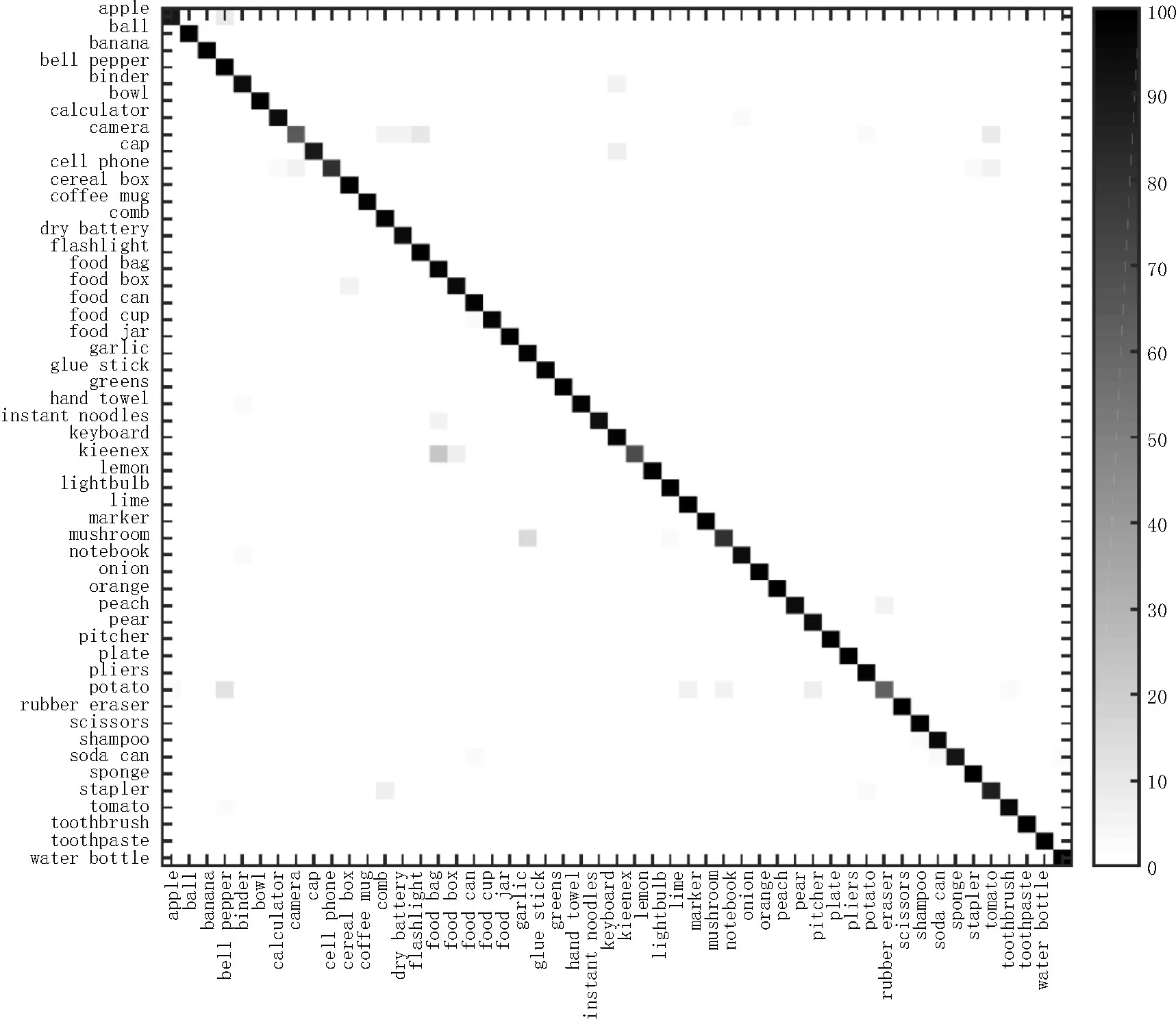
圖7 每一類的分類準確率
4 結束語
本文針對基于圖像的物體分類問題,借鑒了Boosting算法的思想,提出了將若干CNNs網絡結合以實現更好的分類結果。本文將圖像[17]的色彩信息和深度信息利用CNNs進行結合,發現RGB-D、RGB和D三者的組合能夠使分類效果達到最高值95.0%,比單獨使用其中任何一種信息提高了至少5%。另外,實驗發現HSI、YUV、Lab等顏色空間下訓練的網絡泛化性能較差,側面印證了機器人[18]及計算機視覺領域廣泛基于RGB圖像進行算法設計的合理性。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
