基于蟻群算法優化Hadoop平臺計算效能方法
2018-12-24 07:56:32
微型電腦應用 2018年12期
(寧夏財經職業技術學院 信息與智能工程系,銀川 750021)
0 引言
許多大型網站公司通過在世界各地建置大量服務器,為其它企業和民眾提供龐大服務器群的運算能力與儲存資源,讓使用者可利用任何具備網頁瀏覽器功能的設備,通過互聯網就能夠快速使用該公司所提供的軟件運算與儲存功能,而這樣的一種新型網絡應用概念,就是“云計算”[1]。隨著云計算的大量建置,伴隨而來的是大數據(Big Data)[2]。而大數據對云端平臺與應用程序所帶來了容量大、增加快、多樣性、可信度的等四個效能挑戰特性[3]。目前云服務的運算架構主要是MapReduce分散式處理架構,而Hadoop MapReduce是對應參考MapReduce運算架構與分布式系統等關鍵技術[4],以Java程序語言實現同時具備分布式儲存與分布式計算能力的整合式解決方式。目前,Hadoop平臺已相當普及,但應用程序若是在Hadoop平臺上使用預設參數值的情況下執行,其執行效能將不如預期[5]。
因此,本文針對大數據在Hadoop平臺數據運算的效能問題,結合基因表達編程與蟻群算法的Hadoop平臺云計算效能的優化研究(ACO-based Hadoop Configuration Optimization,ACO-HCO),主要結合基因表達編程與蟻群優化算法等相關技術,基于Hadoop的工作歷史紀錄,找出Hadoop平臺的參數與計算效能關聯模型,作為啟發式搜尋的目標函數,并利用蟻群算法快速收斂的特性,結合Hadoop平臺參數與效能關聯模型,搜尋出一組優化參數,從而改善應用程序的執行效能。
1 效能優化機制整體架構
由于Hadoop平臺的執行效能除了受到Hadoop參數設定的影響之外,也會受到系統資源、軟件與網絡的影響,因此,本文所提出的ACO-HCO效能優化機制主要有3個特性:(1)收集Hadoop工作歷史紀錄,避免產生額外負載,導致潛在的模型錯誤問題;(2)考慮參數設定與運行時間復雜的非線性關系;(3)能夠快速收斂產生優化參數結果。
本文所提ACO-HCO效能優化機制的整體架構圖,如圖1所示。
ACO-HCO效能優化機制的主要運作過程為三個階段:(1)在ACO-HCO特征分析階段,通過Hadoop工作特征分析器(Job Log Parser)讀取Hadoop程序輸出路徑中的工作歷史日志目錄[6],輸出符合參數關聯建模方法所需的模型輸入數據格式;(2)在ACO-HCO參數與效能關聯建模階段,將Hadoop特征分析的結果區分為訓練資料與測試數據集,利用基因表達編程法[7],建立Hadoop參數與效能關聯模型;(3)在ACO-HCO參數優化階段,蟻群算法會依據Hadoop參數與效能關聯模型,針對荷爾蒙與狀態轉換機率完成初始化,然后通過蟻群算法的啟發式搜尋過程[8],產生Hadoop平臺優化參數結果。最終,在Hadoop叢集上,針對給定的Hadoop程序、原始輸入數據與ACO-HCO的優化參數設定,觀察Hadoop應用程序的執行效能變化情形。

圖1 ACO-HCO效能優化機制的整體架構圖
2 ACO-HCO參數關聯建模
2.1 GEP應用設計
在GEP應用設計部分,針對Hadoop參數設定與運行時間而言,Hadoop的運行時間ET是參數集(x0,x1,…,xn)的一個函數。根據GEP演化機制,能夠挖掘出重要Hadoop平臺參數與效能關聯模型。ACO-HCO利用GEP的染色體儲存Hadoop平臺參數,每個GEP染色體是由以Hadoop平臺參數作為輸入,經由演化程序最終產生預測運行時間與實際運行時間最為接近的染色體[9],并譯碼為表示樹,輸出形式為f(x0,x1,…,xn)。
2.2 GEP實際結果
在GEP實際結果部分,GEP算法[10]的輸入項是一組經由Hadoop工作特征分析器所過濾產生的Hadoop工作的執行樣本,作為GEP方法的模型輸入數據。而這些數據的產生方式是通過實驗環境的Hadoop平臺,實驗所使用的Hadoop程序包含內建的WordCount與Sort程序,并使用5GB、10GB與15GB的輸入數據。每次實驗過程隨機調整參數設定,母種Hadoop程序執行三次計算后的平均執行時間。
當GEP演化過程的世代數量從20 000個調整至80 000個時,可以得到最終染色體質量(適應值與訓練樣本數量的比例)大于90%的結果。因此,實驗過程將GEP演化過程的世代數量設定為80 000個,并采用典型的基因調整活動發生概率參數,包含單點重組率(0.3)、插入轉換率(0.1),反轉率(0.1)與基因突變率(0.44)。在完成80 000個迭代的GEP演化過程后,GEP最終輸出一個能夠代表Hadoop程序的運行時間與10個重要參數間的關聯函數:
f(x0,x1,…,xn)=
(x6+x4)×(x8+x9)
(1)
其中,a=sqrt(x0×x8+x3×x1),b=pow(x5,(x2+x1))。當輸入參數x0至x9的設定值時,即可通過上式得到Hadoop程序的預估運行時間。因此,上式將作為ACO-HCO參數優化階段,螞蟻選擇下一個參數節點的目標函數,預估運行時間越短的Hadoop參數節點對螞蟻的吸引力則越強。
3 ACO-HCO參數優化算法
ACO-HCO參數優化的執行步驟如下:
步驟1:初始化及ACO參數設定
給定程序運行時間上限(tmax)、螞蟻數量(S)、初始荷爾蒙濃度(τ0)、探索或追隨偏向程度參數(q0)、荷爾蒙衰退參數(ρ)、荷爾蒙重要程度參數(α)、執行時間長短重要程度參數(β)。
步驟2:建構最佳參數節點路徑
若x0為起始狀態,則將S只螞蟻隨機放置在Hadoop參數節點上。每只螞蟻從目前所在節點出發,計算轉換規則[11],以便選擇下一個拜訪節點、逐步完成一趟完整的里程。
轉換規則如式(2)。
(2)
其中,Js(i)是位于節點i的螞蟻s尚未拜訪的鄰近節點集合,而不屬于Js(i)的節點或是拜訪過的節點,其選擇機率為0,這樣的設計可避免螞蟻重復經過相同節點;τiu(t)為線段(i,u)在時間t的荷爾蒙濃度,ηiu是選擇候選參數值的期望值。q為(0,1)間呈現均勻分布的隨機數,q0為設定參數,0≤q0≤1。maxf(x)是找出高荷爾蒙濃度(τ)及GEP目標函數最小預測運行時間成本(η)的節點u,而p為選擇下一節點的轉換機率,由下式計算得到式(3)。
當q>q0時,雖然荷爾蒙濃度高且預測運行時間最短的節點被選擇的概率較高[12],但因螞蟻仍以隨機方式選擇節點,因此概率最高的節點未必會被選到,因此其行為較偏向探索。當q≤q0時,螞蟻被設定必須選擇荷爾蒙濃度高及預測運行時間短的節點,故其行為較偏向追隨。
步驟3:局部更新荷爾蒙濃度
每只螞蟻在找尋一個可行解(可能路徑)的過程中,每經過一個邊(i,j),即對該邊進行一次荷爾蒙更新,以避免其它螞蟻收斂在局部解,并增加路徑找尋的多樣性。更新幅度與目前這群螞蟻的表現及選擇結果無關,計算方式如式(4)。
τij(t+1)=(1-ρ)τij(t)+ρτ0
(4)
其中,ρ為荷爾蒙衰退比例參數,(1-ρ)為荷爾蒙殘留因子,0<ρ<1。區域更新法使拜訪過的路段的荷爾蒙減少,因此拜訪過的路徑對螞蟻的吸引力越來越小,故可誘導螞蟻偏向開發新路徑,避免螞蟻局限在定義狹小范圍內[13]。返回步驟2直到每只螞蟻均產生一條完整路徑為式(5)。
步驟4:整體更新荷爾蒙濃度
當所有螞蟻均完成一條完整路徑后,便執行荷爾蒙“整體更新法”以強化目前最佳路徑的荷爾蒙濃度,計算方式如下所示:
τij(t+1)=(1-ρ)τij(t)+ρΔτij
(5)
其中:若路徑(i,j)∈T+,則Δτij=Q/L+;否則Δτij=0,而T+是先前所找到的最佳路徑,L+是先前所找到最佳路徑的總運行時間。Q為表示荷爾蒙強度的參數,在一定程度上會影響到收斂速度,一般設為100。
只有表現最好的那一只螞蟻才有遺留荷爾蒙的權力,原因是只在最好的解上增加費洛蒙的設計,有助于螞蟻盡快搜尋到最佳解。而目前最佳路徑未必是目前這群螞蟻所找到的,可能是先前螞蟻的搜尋成果。
步驟5:更新最佳路徑
若min(Ls) 步驟6:測試停止條件 ACO停止條件一般設定為時間到達時間上限時間tmax停止。此時,T+為找到的最佳路徑,L+為其總運行時間;否則,回到步驟2。 利用所建置的Hadoop實驗叢集環境,比較ACO-HCO機制、經驗法則(RoT)、Starfish機制以及預設的Hadoop參數(Default)下Hadoop執行效能。通過配置不同的Hadoop平臺參數后,在Hadoop實驗叢集環境,分別執行典型的WordCount、Sort效能測試工具程序與特殊應用的MR-based LSB程序。其中,WordCount與Sort效能測試工具程序的輸入數據量區分為5GB、10GB、15 GB與20GB四個實驗量級,輸入資料的形態為文字內容,而MR-based LSB程序的輸入數據固定為1 500張載體影像圖片文件(Lena.bmp),用以比較藏密與取密的運行效能的差異。每組實驗執行3次,并取運行時間的平均值作為執行效能結果。 如圖2所示。 圖2 WordCount程序執行效能比較 在四種不同輸入數據的量級下,ACO-HCO機制的WordCount程序執行效能比默認值Hadoop平臺執行效能的效能改善率為49%,比經驗法則的執行效能的效能改善率為34%,比Starfish機制的執行效能的效能改善率為10%。其中,在輸入數據級距為20GB時,最大效能的效能改善率能夠達到53%。 不同機制下Sort程序的執行效能比較如圖3所示。 圖3 Sort程序執行效能比較 從圖3可以看出,在四種不同輸入數據量級下,ACO-HCO的執行效能比默認值Hadoop平臺的執行效能的效能改善率為37%,比經驗法則的執行效能的效能改善率為30%,比Starfish機制的執行效能的效能改善率為20%。其中,在輸入數據級距為20GB時,最大效能的效能改善率為44%。 ACO-HCO機制執行WordCount程序與Sort程序的效能差異主要原因是由于兩者在執行時對系統資源的使用特性不同所導致,WordCount程序執行時是屬于CPU密集的運算工作;而Sort程序是屬于中等CPU但硬盤I/O密集的運算工作,由于本文所建置的虛擬化Hadoop實驗環境,由虛擬化軟件管理共享式磁盤,所有VM都必須在隊列中排隊等候磁盤I/O存取,因此,執行硬盤I/O密集的Sort程序時,效能改善率會明顯下降。 ACO-HOC與經驗法則、Starfish機制在藏密效能與取密的效能方面的比較,如圖4所示。 圖4 MR-based LSB程序執行效能比較 從圖4可以看出,ACO-HOC 相比于經驗法則和Starfish機制的效能改善率分別為6%與3%。由于MR-based LSB程序所處理的輸入數據型態是圖片文件,有別于輸入數據型態為文字型的WordCount與Sort程序能夠將輸入數據進行切割處理,MR-based LSB程序的Map任務在產生Key-Value數據文件時,是以整個載體圖像文件做為Vaule的部分,必須耗量大量讀取與寫入本機硬盤I/O的處理時間,因此,ACO-HOC的效能改善率明顯下降。 在Hadoop平臺使用預設參數值執行Hadoop應用程序會存在效能不佳、人工效能調校執行效率差。ACO-HCO機制通過自動化效能調校Hadoop平臺參數,改善Hadoop應用程序的執行效能,屬于通用性較高的效能調整方法。ACO-HCO效能優化機制主要利用GEP演化機制輸入Hadoop歷史工作紀錄,建立Hadoop參數與效能關聯模型,并實作蟻群優化算法進一步搜尋最佳化參數設定。實驗結果顯示,ACO-HCO機制與采用默認值時相比較,能夠明顯改善Hadoop應用程序的執行效能。此外,ACO-HCO機制也比目前極具代表性的Hadoop參數優化方法,能夠提供更好的執行效能。4 Hadoop執行效能的比較與分析
4.1 實驗準備
4.2 WordCount效能測試
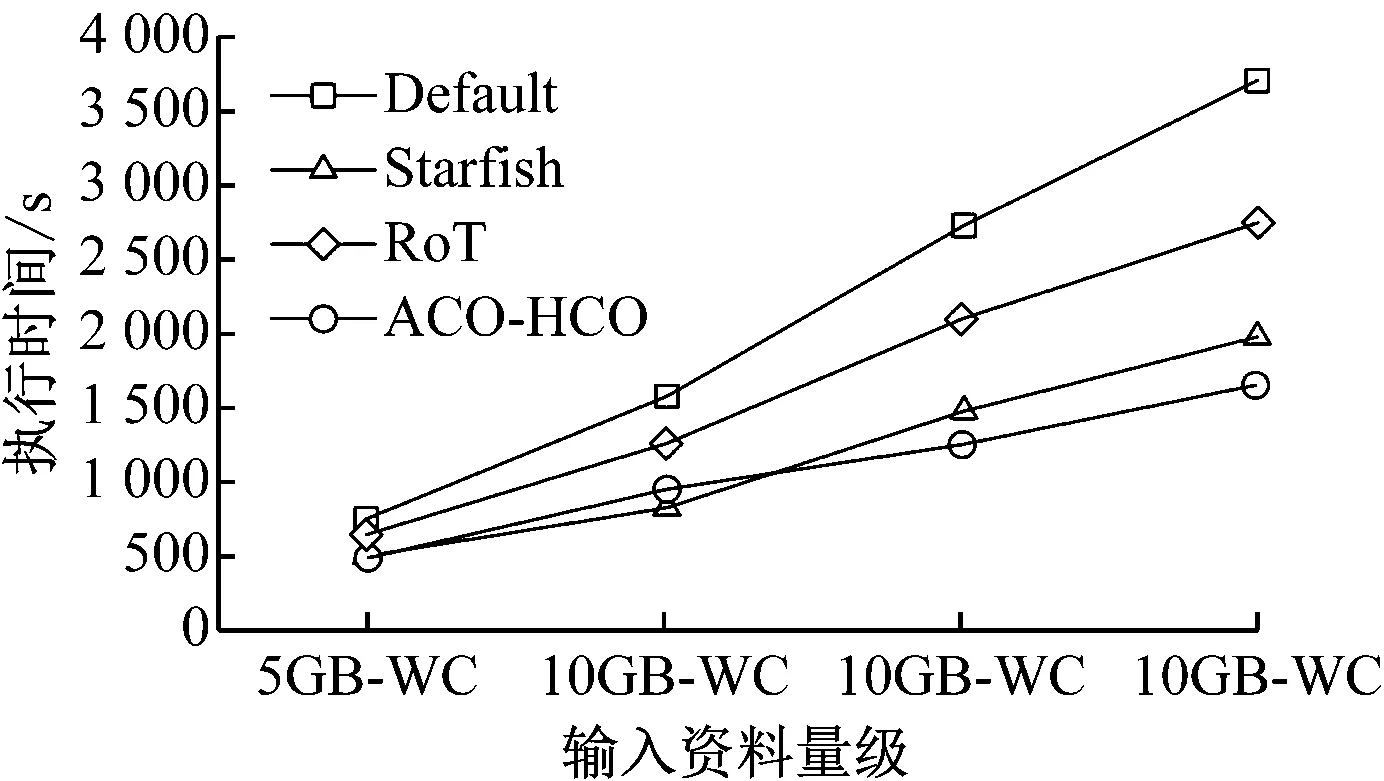
4.3 Sort效能測試
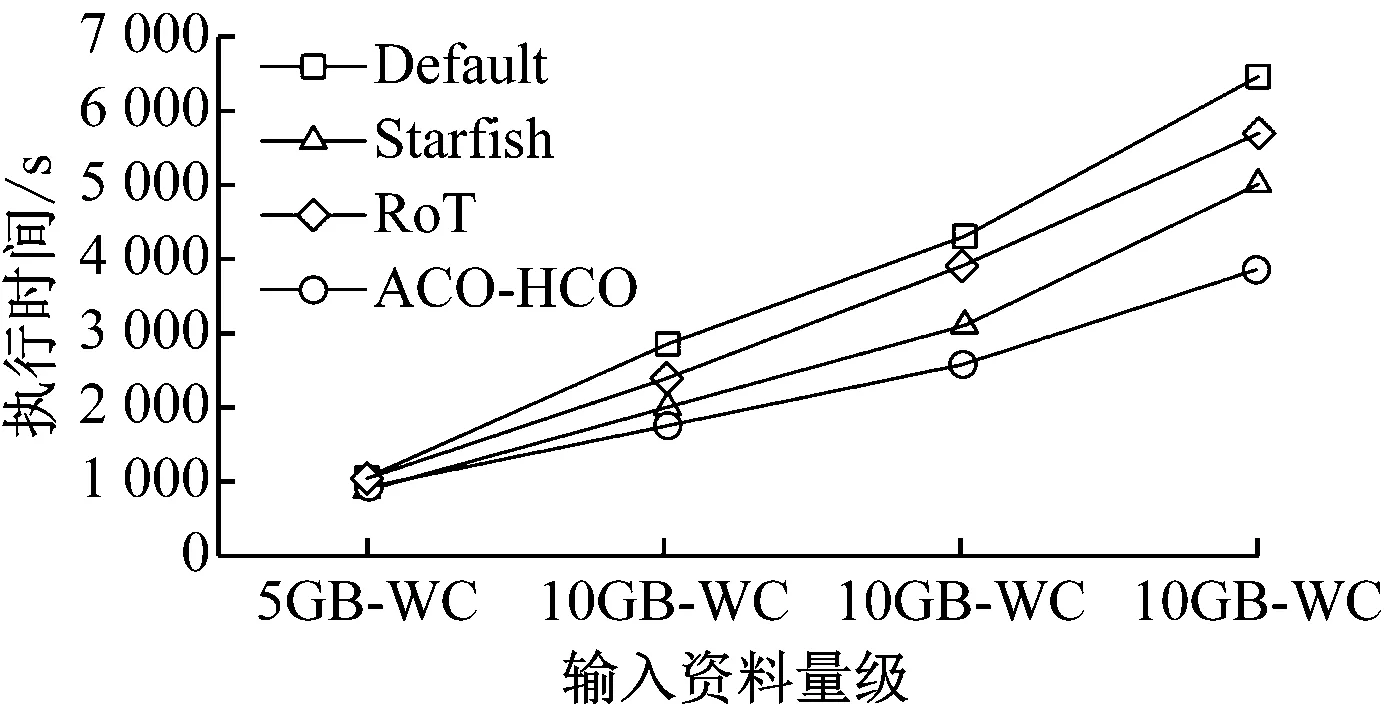
4.4 MR-based LSB效能測試
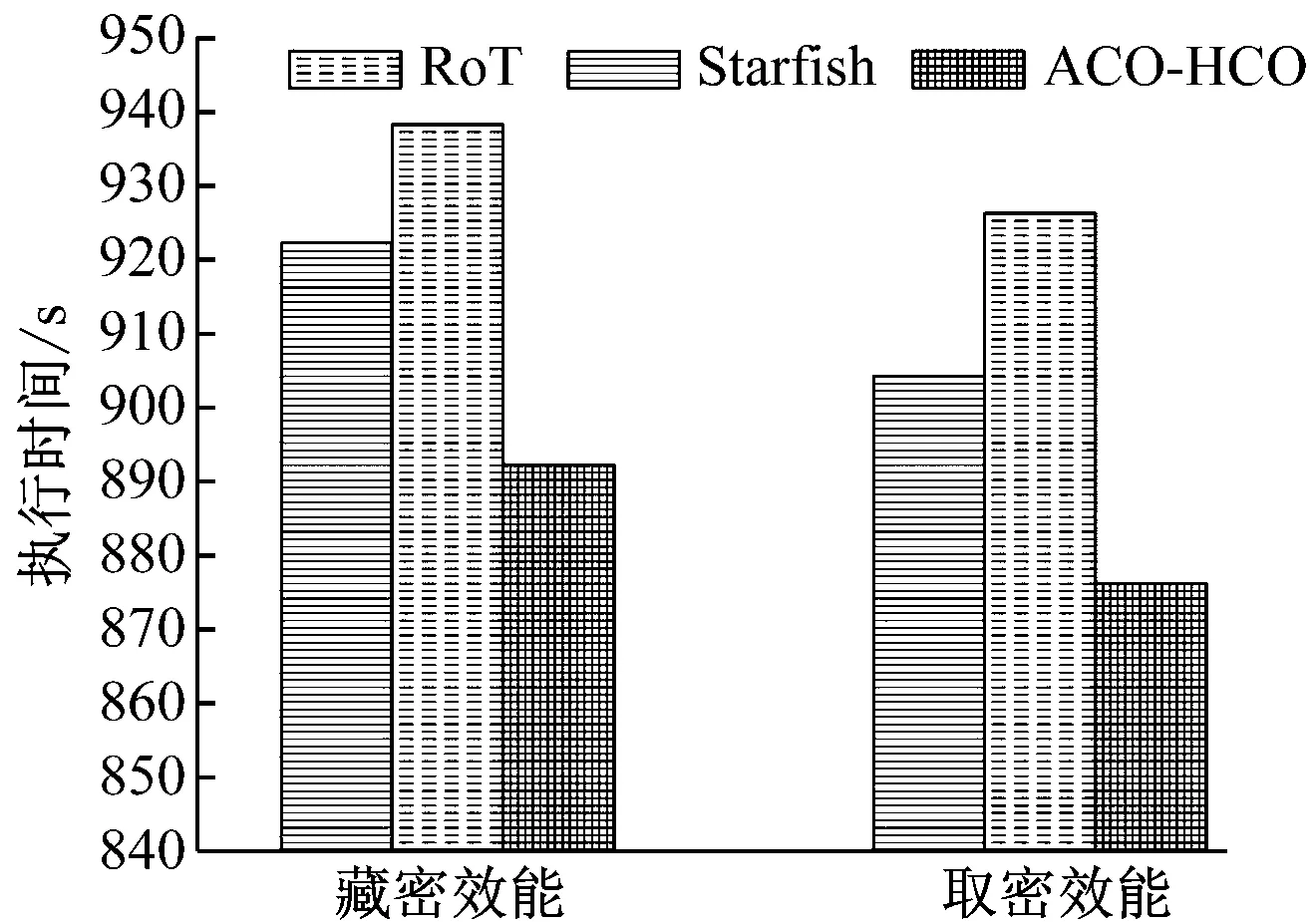
5 總結
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
人大建設(2019年12期)2019-05-21 02:55:44
文苑(2018年21期)2018-11-09 01:23:06
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
中國衛生(2015年3期)2015-11-19 02:53:32
中國衛生(2015年9期)2015-11-10 03:11:12
