天地一體化網絡中基于HDFS的元數據優化策略
2018-12-29 03:07:03邱雪松
無線電通信技術 2018年1期
王 坤,楊 楊,邱雪松
(北京郵電大學 可信網絡通信協同創新中心,北京 100876)
10.3969/j.issn.1003-3114.2018.01.02
王坤,楊楊,邱雪松.天地一體化網絡中基于HDFS的元數據優化策略[J].無線電通信技術,2018,44(1):09-13.
[WANG Kun,YANG Yang,QIU Xuesong.Metadata Optimization Strategy Based on HDFS in Integrated Space-ground Network [J].Radio Communications Technology,2018,44(1):09-13.]
天地一體化網絡中基于HDFS的元數據優化策略
王 坤,楊 楊,邱雪松
(北京郵電大學 可信網絡通信協同創新中心,北京 100876)
Hadoop分布式文件系統(HDFS)是Hadoop的核心之一,已經廣泛應用于天地一體化網絡數據的存儲。但由于HDFS存儲和管理的數據容量受限于命名節點(NameNode)的內存大小,其擴展性受到制約。針對NameNode管理元數據時存在的加載文件系統鏡像(FSImage)時間過長、容量受內存大小限制等問題,提出將HDFS層級化的元數據結構調整為扁平化結構,并將元數據移出內存的優化思路,設計了基于日志結構合并樹(Log-Structured Merge-Tree,LSM)與內存映射文件進行元數據管理的F-HDFS架構,并介紹了F-HDFS的元數據管理方式。通過F-HDFS的原型系統與HDFS的對比實驗,表明F-HDFS性能整體優于HDFS,可提供穩定快速的元數據服務,能存儲與管理超過HDFS 5.3倍以上的數據。
Hadoop; HDFS; 元數據管理; 擴展性; 內存映射文件
TP274
A
1003-3114(2018)01-09-5
2017-09-19
北京郵電大學可信網絡通信協同創新中心預研基金項目;中央高校基本科研業務費專項資金項目;國家科技支撐計劃項目 (2015BAI11B01)
MetadataOptimizationStrategyBasedonHDFSinIntegratedSpace-groundNetwork
WANG Kun,YANG Yang,QIU Xuesong
(Collaborative Innovation Center of Trusted Cyber Communications, Beijing University of Posts and Telecommunications,Beijing 100876,China)
Hadoop distributed file system (HDFS) is one of the cores of Hadoop.It has been widely used in data storage of integrated space and terrestrial information network.However,the scalability of HDFS is limited by the memory size of the NameNode.In order to solve the problem of long time when loading file system mirror (FSImage) to NameNode memory and the problem of capacity restricted by memory size,F-HDFS is designed by adjusting the HDFS hierarchical metadata structure to flat structure and moving metadata out of memory.The design of F-HDFS is based on log structured merge tree and memory mapped files.Through the contrast experiment of F-HDFS prototype system and HDFS,it's proved that the performance of F-HDFS is better than HDFS in general,and it can provide stable and fast metadata service,and can store and manage more than 5.3 times more data than HDFS.
Hadoop; HDFS;metadata management; expansibility; memory mapped file
0 引言
大數據和云計算技術獨有的無限擴展、隨時獲取的資源管理方式對于部隊作戰數據平臺的建設將帶來深刻影響與變革。足夠高的、可靠的、低成本的、容易獲取的帶寬資源,是云計算和大數據產業發展的前提和基礎。但是在天地一體化網絡中,由于通信、偵察、導航氣象等多種功能的異構衛星/衛星網絡、深空網絡、空間飛行器以及地面有線和無線網絡設施所產生的空、天、地、海等多維信息的海量性和安全性將對大數據平臺的構建提出挑戰。同時,帶寬競爭所引發的數據同步過程中傳輸中斷、網絡延遲、內容丟失等問題將嚴重制約天地一體化網絡中大數據同步的效率。HADOOP因其具有高可靠性、高擴展性、高效性、高容錯性和低成本等優點,自推出以來在學術界得到了廣泛的關注,同時得到了迅速的普及和應用。隨著HADOOP的不斷成熟,現已發展成為包含HBASE、HIVE、ZOOKEEPER、MAHOUT等基本子系統的完整的大數據處理平臺。在進行天地一體化網絡數據的存儲中,HDFS文件系統因其流式讀寫等特點,性能較為高效。
與PVFS[1]、MooseFS[2]和GFS[3]等分布式文件系統類似,HDFS也采用主從模式,在一個HDFS集群中有一個NameNode和多個DataNode,NameNode負責存儲和管理元數據[4],DateNode負責以塊為單位存儲實際文件數據。此外,集群中通常還會有Standby Node用來保證高可用性。由于Namenode負責管理整個集群的所有元數據, HDFS將集群中每個文件、數據塊和目錄項都視為一個對象(Object),保存每個對象的元數據,并在集群運行期間將所有元數據加載入NameNode內存,以提供高速的元數據訪問服務。因此,HDFS的NameNode會由于元數據過多而導致內存溢出,限制整個集群可存儲的文件數和塊數量。
在NameNode中,命名空間(NameSpace)占據了NameNode的大部分內存[5]。NameNode是HDFS文件系統的入口,訪問HDFS的應用或客戶端需要從NameNode處獲知分布式文件系統的樹狀目錄和文件結構,進而訪問實際的文件內容。NameNode對命名空間的管理數據除在內存中常駐外,還會保存到磁盤的FSImage和Editslog文件中。當NameNode重啟或災備切換后,會根據磁盤中數據在內存中重新構造命名空間。NameNode采用這種方式的主要問題在于:
① 元數據擴展性受限。NameNode在內存中加載所有元數據,元數據量過大將會引起JVM頻繁的垃圾回收,影響集群性能;若超過NameNode內存大小,集群將完全不可用。
② 元數據加載耗時。NameNode每次重啟都要根據磁盤中的Editslog和FSImage還原命名空間,并逐步加載入內存。元數據加載十分耗時,且在該階段NameNode無法提供服務。
為突破上述限制,提高HDFS元數據管理性能,本文從NameNode層次化的元數據管理方式入手,將元數據分離出內存,借鑒LSM[6-7]設計了一種輕量化元數據存儲結構MDDB(Metadata Data Base),將元數據從內存轉移到內存映射文件與磁盤中,不受NameNode內存容量限制,且可提供優秀的元數據操作訪問性能。通過基于LSM與內存映射文件的扁平化方式進行元數據管理與操作,并構建了原型系統F-HDFS驗證其可行性與有效性。
1 F-HDFS方案設計
將文件目錄進行扁平化處理,在NameNode中加入了新的元數據存儲組件元數據數據庫(MetaData Data Base,MDDB),NameNode通過與MDDB交互進行元數據操作,為客戶端提供文件服務。F-HDFS的架構如圖1所示,其中元數據存儲在MDDB中,MDDB采用LSM與內存映射文件和針對性的優化措施,提供高效的元數據訪問。由于將元數據的存儲和處理分離出了NameNode內存,F-HDFS對于文件系統的操作也與原本的HDFS不同,下面將詳細介紹F-HDFS中MDDB和元數據操作的相關設計與優化。
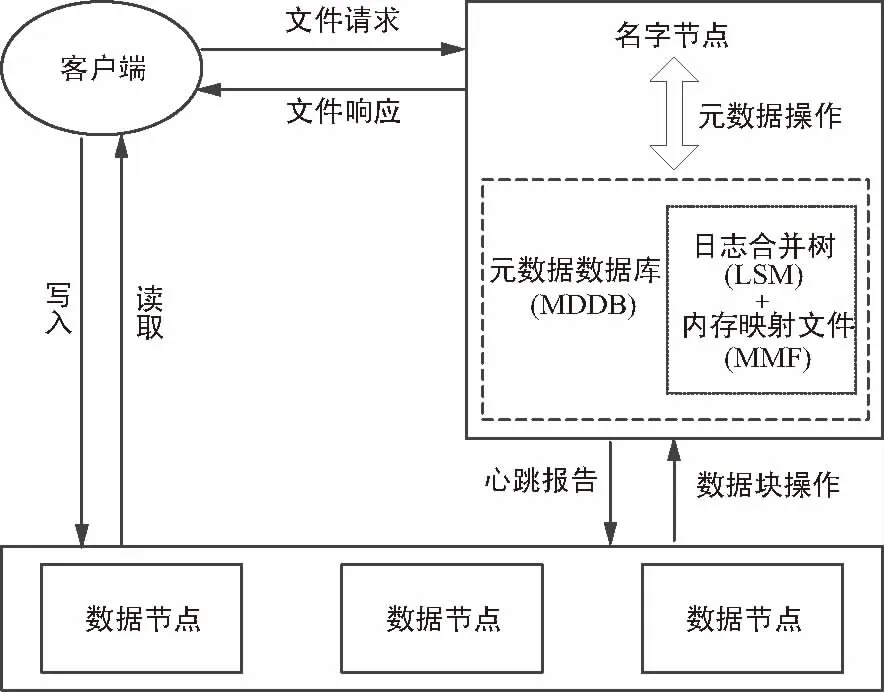
圖1 F-HDFS架構
1.1 MDDB設計
針對F-HDFS的NameNode元數據存取場景設計了MDDB,它是一種基于LSM樹(Log-Structured Merge-Tree)與內存映射文件[8]的輕量化鍵值數據庫。不同于HDFS將元數據加載入內存,并在磁盤中持久化存儲FSImage的方式,F-HDFS的元數據存儲和處理都在MDDB中進行。MDDB借鑒了LevelDB的設計思想,針對F-HDFS的應用場景進行了重新設計和優化。
MDDB由4個層次組成,包括活躍層、L0層、L1層和L2層,結構如圖2所示。
其中,頂層為活躍層。元數據的插入和刪除操作僅發生在活躍層,該層包含一個活躍表。當活躍表的大小超過閾值時,將轉變為只讀表并被放入L0層。同時,一個新的空表將會被創建,成為當前活動的活躍表。
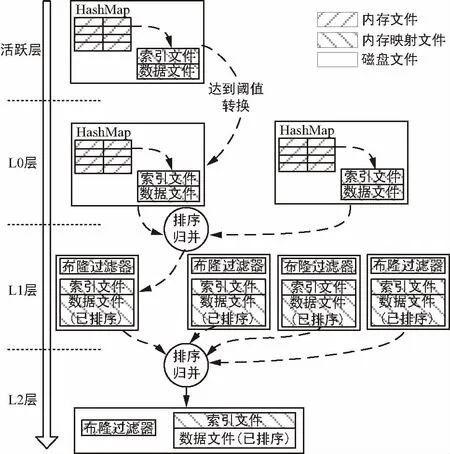
圖2 MDDB層次結構
活躍表包含兩部分,一部分是駐留在NameNode內存中的HashMap,一部分是以內存映射方式加載的索引文件和數據文件。數據文件包含實際的元數據內容,索引文件是對數據文件每條元數據的索引,便于快速訪問。
當NameNode向MDDB中插入新的文件元數據時,例如對于文件K及其元數據V,首先K與V將被追加到活躍表的數據文件末;然后,索引文件中將生成對應的索引i,記錄K、V的位置;接著,HashMap中將插入一條映射記錄,該記錄的關鍵字為K,值為索引i。若從活躍層讀取文件K的元數據,需要先根據K從HashMap中取出對應的索引i,然后根據索引i到數據文件中讀取元數據V的值。為了加快數據讀寫速度,數據文件和索引文件均以內存映射的形式加載與訪問。
L0層中表的構成成分、讀取過程和活躍表一致,但從L0層開始,只支持表讀取操作。當L0層的表達到一定數量(如2個),多個表將會被排序歸并為一個表,歸并結果將被放入L1層。在排序和歸并過程中,表中鍵重復的舊數據將被淘汰。
L1層的每個表包含兩部分內容,一部分是布隆過濾器[9](BloomFilter),另一部分是數據文件。數據文件經由L0層排序歸并得到。在L0層的排序與歸并過程中,數據同時被寫入BloomFilter和數據文件中。L1層的讀取操作需要先在布隆過濾器中檢索,若布隆過濾器報告目標項可能存在,則通過二分法查詢索引文件。
當L1層的表達到一定數量(如4個或8個),多個表將會被排序歸并為一個新表,并放入L2層中。如果L2層中存在舊表,則舊表將參與排序歸并,最終L2層中只保留一張表。在歸并過程中,所有被刪除或更新的舊數據都會被清除。
MDDB中的刪除操作可以視為特殊的插入操作,對于待刪除的文件或目錄,MDDB會針對該條目插入一條擁有刪除標記特殊數據,在后續的歸并中會將標記刪除的無效數據清除。查詢與讀取操作從活躍層開始,根據數據新鮮度按從上往下、同層內從表隊列隊首向隊尾的順序搜索。
由于NameNode是運行在Java虛擬機上的, HDFS在運行期間將元數據駐留在NameNode的JVM堆內存中,因此元數據存取性能較高。但JVM存在垃圾回收機制,存儲大量元數據會頻繁觸發垃圾回收,影響NameNode的正常使用。內存映射文件的性能介于純內存和純磁盤之間,并持久化保存在磁盤上,無數據丟失風險,且不受垃圾回收機制影響。F-HDFS可在NameNode重啟后,節省將FSImage文件反序列化和載入內存的時間。此外L2層的數據文件以磁盤文件的形式存放,避免大量的“冷數據”[10]浪費內存地址空間。MDDB中所有數據文件都是直接或間接持久化保存的,如果NameNode宕機或進程意外結束,元數據不會丟失,重啟后即可快速恢復。
1.2 元數據扁平化管理機制
F-HDFS對于HDFS的扁平化處理包括兩方面:一方面是目錄結構的扁平化。在F-HDFS中,每個目錄項的目錄名和父目錄編號“pid”構成唯一的標識依據“(pid,name)”,與目錄項對應的訪問控制信息、數據塊信息等內容一并保存在MDDB中,形成扁平化的目錄結構。另一方面是元數據的扁平化。F-HDFS按照原HDFS中INode的格式,將INode處理為扁平字節數組,其中每一種元數據屬性都是定長。NameNode可通過預定義的偏移位置,直接讀取元數據字段內容,而不用將全部元數據反序列化為INode對象再讀取,節省了訪問時間。
在扁平化目錄中,訪問目錄的過程也異于樹形結構。例如圖3所示的目錄結構,訪問目錄“/foo/dira”的步驟為:① 由根目錄出發,通過“(0,root)”得到根目錄root的ID為1;② 構造“(1,foo)”得到目錄foo的ID為2;③ 通過“(2,dira)”即可查找到目錄dira的元數據信息。本示例為了簡潔省略了實際中訪問控制的檢查過程。
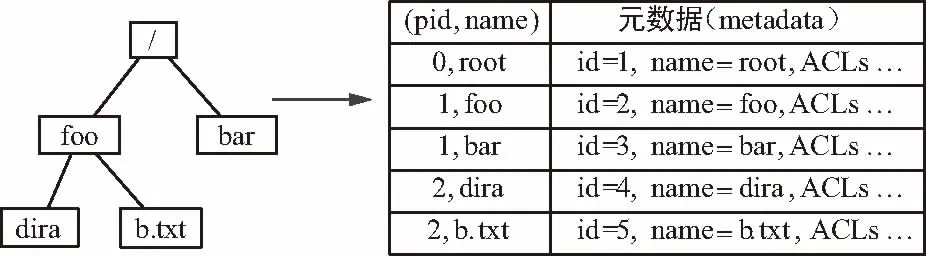
圖3 扁平化目錄示例
與訪問目錄的步驟類似,對于mkdir等操作,例如“mkdir /foo/a”,首先需要根據“/foo/a”查找是否存在該目錄項,若不存在,直接向MDDB活躍層插入“(2,a)”與目錄a的元數據即可。若需更新某目錄項的元數據,如rename等操作,則需要執行一次原子更改操作,同時將操作記錄寫入Editslog。刪除文件或目錄的操作與更新操作類似,更新或刪除操作完成后,無效數據在L1、L2層發生排序歸并時才會被清除。
2 仿真實驗
以Hadoop 2.7.3版本源碼為基礎,修改并編譯完成了F-HDFS的原型系統,另外還將扁平化處理適配了LevelDB,以驗證本文方案所設計的MDDB及相關元數據訪問優化的有效性。本節將展示本文針對HDFS、F-HDFS(以MDDB為引擎的F-HDFS記為F-HDFS_M、以LevelDB為引擎的F-HDFS記為F-HDFS_L)的對比實驗結果。
2.1 實驗環境
本文實驗在3個規格相同的集群上展開,各集群的NameNode配置均為2.4 GHz CPU、8 GB RAM、1 GB Ethernet、200 GB HDD。每個集群包含5個DataNode,配置為4 GB RAM、1 GB Ethernet、500 GB HDD。所有節點的操作系統為Ubuntu 14.04 64 bit、Java 1.8。HDFS、F-HDFS_M與F-HDFS_L分別運行在3個獨立的集群上。
2.2 元數據操作基準測試
實驗首先采用Hadoop官方提供的Benchmark測試套件[11]作為測試工具,測試HDFS和F-HDFS的NameNode對元數據和目錄項的“mkdir”操作性能。
對于“mkdir”操作,本文利用測試工具分別以1、2、4、8、16、32和64線程,對HDFS、F-HDFS_M和F-HDFS_L各創建100 000個目錄。針對不同線程數量分別測試3次,每次測試完成都重新格式化NameNode,每種線程數量取3次每秒操作數(op/s)的平均數為測試結果。測試結果的單位是每秒的操作數,數值越大表明性能越好。從圖4中可以看出,雖然在64線程的實驗中,F-HDFS_M的數據為9 569.97 op/s,低于HDFS的數據10 512.7 op/s,但F-HDFS_M結果整體優于對比項。F-HDFS_L在1、2、4線程時與HDFS性能接近,但隨著線程數的增加,測試結果增長緩慢。F-HDFS_L與F-HDFS_M相差較大的原因在于LevelDB僅采用內存和磁盤存儲數據,每次新建目錄項之前的判存操作都要查詢,形成了性能瓶頸。而F-HDFS_M通過集中式的追加寫和優化的索引,實現了優于HDFS的性能。

圖4 mkdir測試結果
2.3 FSImage負載測試
除了針對NameNode的元數據性能測試,還利用Load Generator[12]對3個集群進行了實際文件讀寫的負載測試。實驗測試3個集群在不同文件數量負載下的吞吐量,每次測試分為3個步驟:首先以最大目錄深度為8、子目錄數最大為100、文件平均大小1 MB,副本數為3、本次文件數量為基數,生成目錄結構文件;然后根據目錄結構文件,在集群中自動生成相應的目錄和文件;最后建立64個客戶端對NameNode進行文件讀寫和目錄訪問,最終輸出本次測試的綜合吞吐量。
雖然在元數據操作基準測試中,F-HDFS_M的mkdir操作吞吐量優于HDFS,而對于open操作,F-HDFS_M的最大吞吐量低于HDFS。但在圖5所示結果中,F-HDFS_M響應多客戶端操作的的綜合吞吐量均優于HDFS。由于本實驗中副本數為3,實際上當HDFS達到可用極限時,該集群的NameNode共管理至少600萬個對象(包括文件、目錄、塊等),而當F-HDFS達到可用極限時,NameNode共管理至少3 200萬個對象,是HDFS的5.3倍以上。
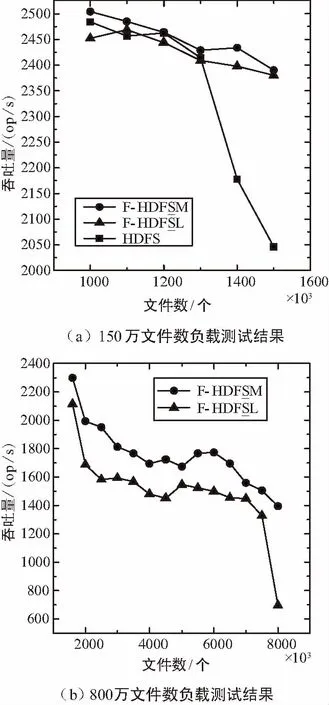
圖5 負載測試結果
3 結束語
針對天地一體化信息網絡背景中基于HDFS文件系統進行元數據管理的局限,提出了F-HDFS改進方案,通過將元數據分離出NameNode內存與FSImage,實現元數據擴容與快速加載。首先,本文介紹了F-HDFS的設計方案,包括元數據的存儲引擎MDDB、扁平化的目錄與元數據管理措施。其次,通過原型系統與HDFS的對比實驗,展現并分析了F-HDFS的性能。實驗結果表明,F-HDFS具有優秀的元數據操作性能,能提供多于HDFS容量5.3倍以上的數據存儲和管理能力。
[1] Haddad I F.PVFS: A Parallel Virtual File System for LinuxClusters[J].Linux Journal,2000,2000(80es):5.
[2] Bai S, Wu H.The Performance Study on Several Distributed File Systems[C]∥ International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery.IEEE,2011:226-229.
[3] Ghemawat S, Gobioff H,Leung S T.The Google File System[C]∥ Nineteenth ACM Symposium on Operating Systems Principles.ACM,2003:29-43.
[4] Shafer J,Rixner S,Cox A L.The Hadoop Distributed Filesystem: Balancing Portability and Performance [C]∥ Performance Analysis of Systems & Software (ISPASS).2010 IEEE International Symposium on.IEEE,2010:122-133.
[5] Shvachko K V.HDFS Scalability: the Limits to Growth[J].login:the Magazine of USENIX & SAGE,2010,35: 6-16.
[6] O'Neil P,Cheng E,Gawlick D,et al.The Log-structured Merge-tree (LSM-tree)[J].Acta Informatica ,1996,33(4): 351-385.
[7] Chang F.Bigtable: A Distributed Storage System for Structured Data[J].ACM Transactions on Computer Systems (TOCS),2006,26(2):205-218.
[8] Song N Y,Son Y,Han H,et al.Efficient Memory-mapped i/o on Fast Storage Device[J].ACM Transactions on Storage (TOS),2016 ,12(4): 19.
[9] Kumar A,Xu J,Wang J.Space-code Bloom Filter for Efficient Per-flow Traffic Measurement[J].IEEE Journal on Selected Areas in Communications ,2006,24(12): 2327-2339.
[10] Run A K,Chitharanjan K.A review on hadoop — HDFS infrastructure extensions[C]∥ Information & Communication Technologies.IEEE,2013:132-137.
[11] Hadoop Benchmarking [EB/OL].http:∥hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/Benchmarking.html.
[12] Load Generator[EB/OL].http:∥hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/SLGUser Guide.html.
[13] Dev D,Patgiri R.Dr.Hadoop:an Infinite Scalable Metadata Management for Hadoop-How the Baby Elephant Becomes Immortal[J].Frontiers of Information Technology & Electronic Engineering,2016,17(1):15-31.

王坤(1994—),男,碩士研究生,主要研究方向:大數據與分布式存儲系統;
楊楊(1981—),女,副教授,主要研究方向:無線傳感網應用與大數據分析;
邱雪松(1973—),男,教授,主要研究方向:網絡管理與通信軟件。
