一種基于HBase的RDF數據存儲改進方法
2019-01-02 09:01:18朱道恒,秦學,劉君鳳
軟件 2019年12期
關鍵詞:數據存儲


摘 ?要: 為高效地存儲和管理大規模語義Web數據,結合語義Web數據查詢的特點,提出一種基于HBase的資源描述框架RDF(Resource Description Framework)數據存儲改進方法。該方法將以主語+謂語、謂語+賓語、賓語+主語為索引的RDF數據存放在SP_O、PO_S、OS_P三張索引表中,同時將PO_S表按類劃分為P_SO和P_OS兩類,并給出改進的查詢索引方法。對數據的加載存儲,利用HBase自帶的BulkLoad工具將數據上傳至HBase存儲表中。通過理論分析和實驗結果顯示,改進的存儲方法對固定謂語的查詢能作出快速響應;BulkLoad并行加載數據具有較高的加速比,在縮短數據加載時間的同時能提升系統整體存儲性能。
關鍵詞: 語義Web;HBase;RDF;數據存儲
中圖分類號: TP391.9 ? ?文獻標識碼: A ? ?DOI:10.3969/j.issn.1003-6970.2019.12.003
本文著錄格式:朱道恒,秦學,劉君鳳. 一種基于HBase的RDF數據存儲改進方法[J]. 軟件,2019,40(12):1317
An Improved Method of RDF Data Storage Based on HBase
ZHU Dao-heng, QIN Xue, LIU Jun-feng
(College of Big Data and Information Engineering, Guizhou University, Guiyang Guizhou 550025, China)
【Abstract】: In order to efficiently store and manage large-scale semantic Web data , an improved method of data storage based on HBase's resource description framework RDF is proposed., which combines the characteristics of semantic Web data query. In this method, RDF data indexed by subject + predicate, predicate + object, object + subject is stored in three index tables of SP_O, PO_S and OS_P.At the same time, PO_S table is divided into two categories, P_SO and P_OS, and an improved query index method is given. To load and store the data, the BulkLoad tool that HBase brings is used to upload the data to the HBase storage table. The theoretical analysis and experimental results show that the improved storage method can respond quickly to the fixed predicate query; BulkLoad parallel loading data has a high acceleration ratio, which can improve the overall storage performance of the system while shortening the data loading time.
【Key words】: Semantic web; HBase; RDF; Data storage
0 ?引言
語義Web核心思想是:通過在Internet上的文檔中添加可被計算機所理解的語義,從而使整個Internet成為一個通用的信息交換媒介[1]。為規范化地描述Web資源及其屬性,W3C組織提出了一個Web資源之間語義關系的開放元數據框架RDF[2]。RDF作為一種典型的非結構化數據,是一種規范的語義Web描述方法。
近年來,由于語義網發展迅速,語義Web數據呈現井噴式的增長,這使得關系型數據庫管理系統已經很難管理這些數據。而關系型數據庫在處理大規模語義Web數據時存儲與查詢效率均低于分布式數據庫,越來越多的研究者開始利用分布式系統的海量數據存儲與并行計算能力來解決海量數據管理問題[3-4]。
RDF數據的存儲從以下兩個方面入手:
(1)存儲方面:建立合適的表結構使數據存儲空間開銷與查詢性能達到一定平衡;
(2)查詢方面:建立有效的索引使數據的查詢變得簡單、快速。
通過分析用戶的一些日常查詢數據,發現大部分的查詢都包含固定的謂語值。根據這一現象,結合當前RDF數據的查詢特點,提出一種基于HBase的RDF數據存儲方法。將包含語義的RDF數據存儲到設計好的三張HBase表中以實現海量RDF數據的分布式存儲,并用HBase自帶的BulkLoad工具完成數據的上傳,一方面,提升數據導入數據庫的效率,另一方面,提高RDF數據的查詢效率。
1 ?相關研究工作
傳統的關系型數據庫管理系統RDBMS(Rela tional Database Management System)存儲和管理RDF數據的弊端已經日漸凸顯。RDBMS通過數據、關系和約束條件組成模型來存放和管理數據。當前,垂直(三元組表)存儲模式[5]、水平存儲模式[6]、屬性存儲模式[7]、模式生成存儲模式[8]都是基于關系型
數據庫設計的。因為關系型數據庫的表結構一般需要提前設計好,而且部署環境是單機型,所以,對于動態性和可擴展性要求較高的大規模數據的存儲而言,關系型數據庫就難以滿足。
分析上述幾種存儲模式,三元組表[9]的存儲方式最簡單,一張包含主語、謂語和賓語三列的表可以存儲所有本體數據。垂直存儲模式是在三元組表模式基礎之上的一種優化。它把相同謂語的三元組存到同一張表中,一定程度上降低了存儲開銷。水平存儲模式先垂直劃分三元組,把相同的謂語作為列名,主語和賓語各存入一列,這樣有效避免了空值和多值屬性問題。屬性表存儲模式根據屬性的不同,設計了多元表列,把相同的主語及對應的屬性值存入同一行,這樣避免了多表連接和自連接問題。模式生成存儲主要是對表做水平和垂直切分,這樣大幅減少了表中的空值數量。表1對以上幾種存儲模式各自的優缺點作出簡單對比。
表1 ?基于關系型數據庫存儲方案的對比
Tab.1 ?Comparison of storage schemes based on relational database
存儲方案 優點 缺點
三元組表 結構簡單、易實現 自連接多、數據表大,查詢效率低
水平存儲 避免空值和多值屬性問題 數據表過多,大量表連接操作,不支持未知屬性查詢
屬性存儲 避免多表連接和自連接 存儲表稀疏,存儲空間浪費
模式生成 降低儲存開銷、查詢連接計算開銷 過多人工干預、大規模數據管理難
近些年,大量的研究機構都在研究RDF數據的存儲與查詢,分布式系統和并行技術被廣泛應用到語義Web的管理中,如Oracle公司開發的Oracle RDF,MPI研究所研發的RDF-3X[10],DERI研發的YARS系統等。RDF-3X系統將建立的索引存儲在B+樹的葉子節點上,通過各種索引表來分布式訪問集群資源,這種系統存在數據存儲結構復雜,通信開銷較大,安全性不高等缺點。
HBase[11]是谷歌BigTable[12]的開源實現,它是基于列存儲、可伸縮、性能較高的分布式數據庫,便于存儲非結構化和半結構化的數據。文獻[13]設計出六張HBase索引表S_PO、P_OS、O_SP、PS_O、SO_P和PO_S來存儲數據。S_PO表以主語為Row-Key,(謂語,賓語)為列標簽,P_OS等五張表依此類推。文獻[14]將文獻[13]的存儲表簡化到三張,用SO_P、PO_S、OS_P三張索引表來存儲數據。而S_PO、P_OS、O_SP這三種數據索引表就可以對應所有的三元組查詢模式,它們對應如表2所示的查詢組合。
當前,大多數的研究主要集中在Hadoop上進行數據的存儲設計和查詢處理。Hadoop是Apache
Software Foundation擁有的開源分布式計算平臺,在分布式環境下提供了海量數據的處理能力。有研究者基于上述索引表存儲機制,提出一種通過創建數據詞典來編解碼操作RDF數據的模型,該模型有效降低存儲開銷的同時保證了數據的安全性[15-17],但未對存儲模式作出優化。
2 ?改進的RDF數據存儲方法
2.1 ?存儲改進方法
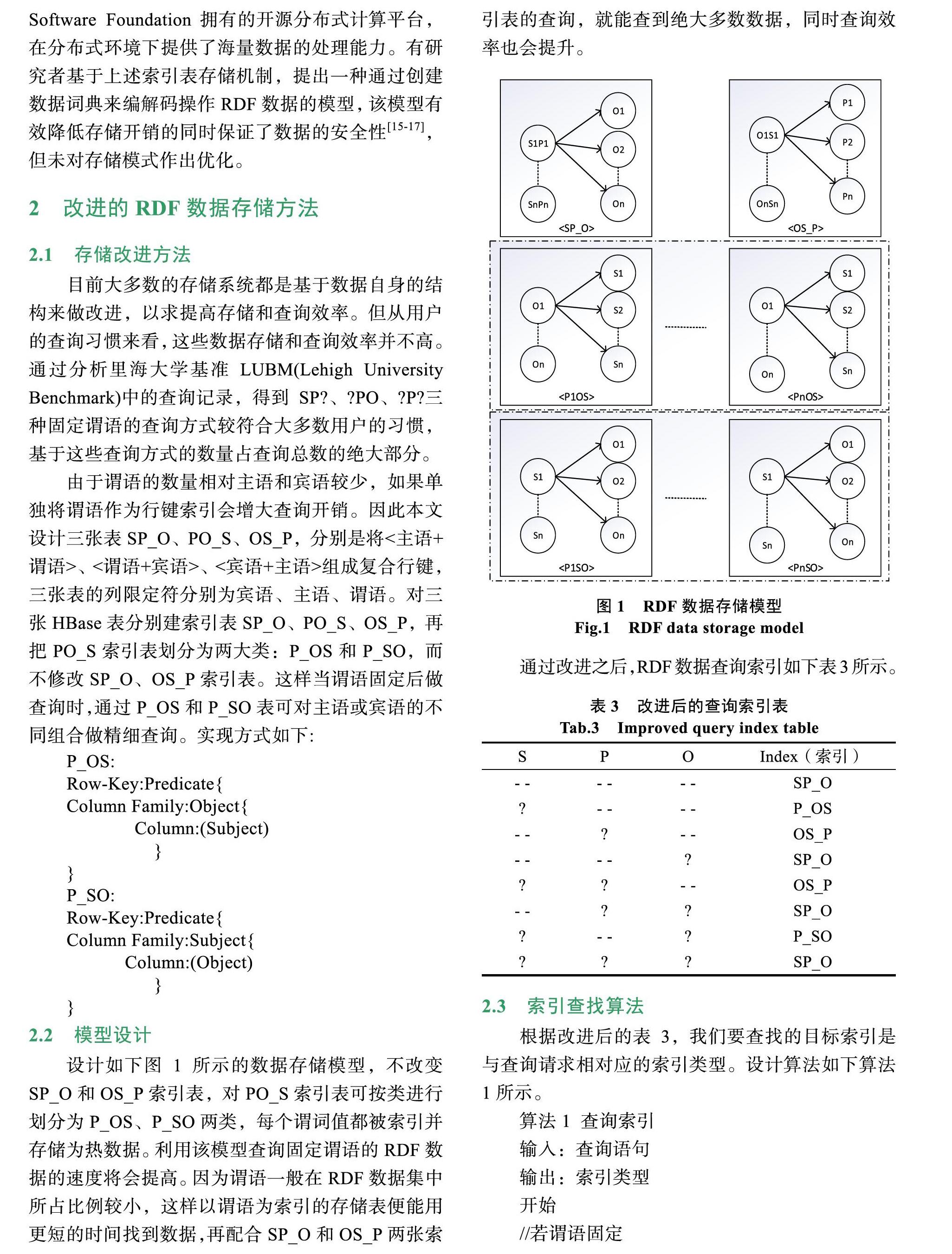
目前大多數的存儲系統都是基于數據自身的結構來做改進,以求提高存儲和查詢效率。但從用戶的查詢習慣來看,這些數據存儲和查詢效率并不高。通過分析里海大學基準LUBM(Lehigh University Benchmark)中的查詢記錄,得到SP?、?PO、?P?三種固定謂語的查詢方式較符合大多數用戶的習慣,基于這些查詢方式的數量占查詢總數的絕大部分。
由于謂語的數量相對主語和賓語較少,如果單獨將謂語作為行鍵索引會增大查詢開銷。因此本文設計三張表SP_O、PO_S、OS_P,分別是將<主語+謂語>、<謂語+賓語>、<賓語+主語>組成復合行鍵,三張表的列限定符分別為賓語、主語、謂語。對三張HBase表分別建索引表SP_O、PO_S、OS_P,再把PO_S索引表劃分為兩大類:P_OS和P_SO,而不修改SP_O、OS_P索引表。這樣當謂語固定后做查詢時,通過P_OS和P_SO表可對主語或賓語的不同組合做精細查詢。實現方式如下:
P_OS:
Row-Key:Predicate{
Column Family:Object{
Column:(Subject)
}
}
P_SO:
Row-Key:Predicate{
Column Family:Subject{
Column:(Object)
}
}
2.2 ?模型設計
設計如下圖1所示的數據存儲模型,不改變SP_O和OS_P索引表,對PO_S索引表可按類進行劃分為P_OS、P_SO兩類,每個謂詞值都被索引并存儲為熱數據。利用該模型查詢固定謂語的RDF數據的速度將會提高。因為謂語一般在RDF數據集中所占比例較小,這樣以謂語為索引的存儲表便能用更短的時間找到數據,再配合SP_O和OS_P兩張索引表的查詢,就能查到絕大多數數據,同時查詢效率也會提升。
2.3 ?索引查找算法
根據改進后的表3,我們要查找的目標索引是與查詢請求相對應的索引類型。設計算法如下算法1所示。
算法1 查詢索引
輸入:查詢語句
輸出:索引類型
開始
//若謂語固定
if(predicate is constrained)
{
//且賓語固定
if(object is constrained)
return P_OS
else
Return P_SO
}
elso
{
//賓語固定
if(object is constrained)
return OS_P
elso
return SO_P
}
結束
該算法詳細給出查詢索引的步驟。根據算法流程,如果謂語固定,那就判斷賓語是否固定來確定相對的索引類型。反之,如果謂語不固定,再進一步判斷賓語是否固定來確定相對的索引類型。根據大多數用戶查詢習慣,該算法先將數量級較小的謂語作為固定條件,能夠較快速地匹配出固定的元素,從而優化整體匹配索引的過程。
2.4 ?RDF數據導入HBase
設計完數據存儲模型之后,將RDF數據按照
SP_O、OS_P、P_OS、P_SO模型加載到建好的HBase表中。如圖2所示為導入RDF數據所需的環境。
圖2 ?系統環境配置
Fig.2 ?System environment configuration
RDF數據導入HBase的方法主要有兩種:交互式導入和BulkLoad工具導入。由于交互式導入數據效率較低,實際中一般不使用該方法。本文使用HBase自帶的BulkLoad工具將RDF數據批量導入HBase表中。導入HBase表之前先通過HDFS Shell命令hadoop dfs -put將文件先導入HDFS上,再用HBase Java API將HDFS上的文件轉化為HFile格式,最后通過BulkLoad批量導入數據到HBase表。
通過MapReduce的并行計算,HDFS中的文件轉化適合HBase存儲的HFile格式的文件,再用BulkLoad工具將HFile文件導入到每個Region,而每個Region的大小由HMaster自動平衡。HFile文件和Region都分布式地存儲在DataNode節點上。MapReduce處理數據如圖3所示。
圖3 ?MapReduce處理數據流向
Fig.3 ?MapReduce handles data flow
3 ?實驗測試與結果分析
3.1 ?實驗環境簡介
實驗環境為具有4個節點的Hadoop集群,每個節點的硬件和軟件配置如表4所示。實驗目的是將RDF數據均衡分布于各節點的HBase數據庫中。實驗采用LUBM測試集,LUBM[15]是里海大學基準,它包含OWL本體定義文件,UBA數據集生成器和
14個SPARQL查詢,能通過指定參數生成對應的數據集,參數的大小決定數據集規模的大小。
表4 ?硬件和軟件配置
Tab.4 ?Hardware and software configuration
處理器 Intel Core i7 3.60 GHz JDK版本 1.8.0
內存 16 GB Hadoop版本 2.7.1
硬盤內存 500 GB HBase版本 1.1.5
操作系統 Ubuntu16.04 Jena版本 3.10.0
3.2 ?實驗結果分析
用數據發生器UBA生成三組RDF數據集如表5所示。
表5 ?RDF數據集
Tab.5 ?RDF data sets
數據集大小 LUBM1 LUBM10 LUBM20
RDF三元組個數 84 612 955 823 2 128 324
利用MapReduce編程模型將大規模RDF數據并行加載到HBase,并分別統計串行加載和MapReduce并行加載三組不同數據集所用的時間并計算加速比,如表6所示。
表6 ?數據加載時間
Tab.6 ?Data loading time
數據集 串行/min MapReduce/min 加速比
LUBM1 0.9 0.77 1.17
LUBM10 4.8 3.55 1.35
LUBM20 15.6 8.12 1.92
實驗加速比由式(1)計算:
(1)
式中:T(S)表示串行加載運行時間T(P)表示并行加載運行時間。
由表6,對比兩種加載方法,當數據規模較小時,兩種加載方式所用時間相差不大。當數據規模逐漸增大時,并行加載算法加載操作RDF數據明顯比串行加載速度快,而且加速比也逐漸增大,說明加載性能也隨之提升。
為驗證本文對索引表PO_S分類之后的高效性,通過分別查詢存儲到SP_O和P_SO兩張表中的數據集,三組數據在兩張表中的響應時間如表7所示。使用固定謂詞,已知主語,未知賓語設計查詢方法如下:
SELECT s p ?o
WHERE
{
}
表7 ?SP_O與P_SO查詢響應時間
Tab.7 ?SP_O and P_SO query response time
數據集 SP_O索引/s P_SO索引/s 加速比
LUBM1 0.482 0.391 1.23
LUBM10 1.063 0.782 1.36
LUBM20 2.045 1.329 1.53
從表中可以看出,在查詢每一組數據集時,P_SO表都比SP_O表的查詢時間短,并且隨著數據集的增大,查詢加速比也逐漸變大。同時存儲在HBase表中數據的有序性能夠保證查詢效率。
4 ?結語
面對大規模RDF數據的存儲效率不高和管理混亂的問題,提出了一種改進的基于分布式數據庫HBase的RDF數據存儲方法。相比傳統的RDF三元組存儲方法,這種方法能根據索引更快速地查詢到對應的數據。不僅減小數據存儲開銷,而且能保證一定的查詢性能。為研究語義Web數據的高效查詢和推理奠定了一定的理論和應用基礎。由于本文主要針對RDF數據的存儲方案在做優化,未對RDF數據的查詢處理做深入的研究,后續的工作是要嘗試將優化查詢算法應用到該模型之中,從而進一步提升數據的查詢效率。
參考文獻
[1]R.Studer, R.Benjamins, D. Fensel. Knowledge Engineering: Principles and Methods. Data & Knowledge Engineering, 1998, 25(1–2): 161–198.
[2]杜方, 陳躍國, 杜小勇. RDF數據查詢處理技術綜述[J]. 軟件學報, 2013(06): 1222-1242.
[3]謝華成, 馬學文. MongoDB數據庫下文件型數據存儲研究[J]. 軟件, 2015, 36(11): 12-14
[4]牛亞偉, 林昭文, 馬嚴. 數據流信息從MySQL到HBase的遷移策略的研究[J]. 軟件, 2015, 36(11): 01-05.
[5]Harris S, Lamb N, Shadbolt N, et al. 4store: The design and implementation of a clustered rdf store[J]. Scalable Semantic Web Knowledge Base Systems, 2009, 4: 94-109.
[6]杜小勇, 王琰, 呂彬. 語義Web數據管理研究進展[J]. 軟件學報, 2009, 20(11): 2950-2964.
[7]鮑文, 李冠宇. 本體存儲管理技術研究綜述[J]. 計算機技術與發展. 2008, 18(1): 146-150.
[8]Zhou Q, Hall W, Roure D D. Building a Distributed Infra-structure for Scalable Triple Stores[J].Journal of ComputerScience & Technology, 2009, 24(3): 447-462.
[9]Kaoudi Z, Manolescu I. RDF in the clouds:a survey[J]. Vldb Journal, 2015, 24(1): 67-91.
[10]Zheng W, Zou L, Lian X, et al. Efficient Subgraph Skyline Search Over Large Graphs[C]//Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management. ACM, 2014: 1529-1538.
[11]George L. HBase: the definitive guide[M]. OReilly Media, Incorporated, 2001.
[12]Chang F, Dean J, Ghemawat S, et al. Bigtable: A distributed storage system for structured data[J]. ACM Transactions on Computer Systems (TOCS), 2008, 26(2): 4.
[13]Sun J, Jin Q.Scalable rdf store based on hbase and mapreduce[C]. Advancd Computer Theory and Engineering (ICACTE), 2010 3rd International Conference on IEEE, 2010, 1: V1-633-V1-636.
[14]Papailiou N, Konstantinou I, Tsoumakos D, et al. H2RDF: adaptive query processing on RDF data in the cloud[C]. Processing of the 21st international conference companion on the World Wide Web. ACM, 2012: 397-400.
[15]王又立, 王晶. 一種基于Kerberos和HDFS的數據存儲平臺訪問控制策略[J]. 軟件, 2016, 37(01): 67-70.
[16]申晉祥, 鮑美英. 基于Hadoop平臺的優化協同過濾推薦算法研究[J]. 軟件, 2018, 39(12): 01-05.
[17]王書夢, 吳曉松. 大數據環境下基于MapReduce的網絡輿情熱點發現[J]. 軟件, 2015, 36(7): 108-113.
猜你喜歡
文理導航(2017年2期)2017-02-16 13:18:46
辦公室業務(2016年11期)2017-01-09 18:02:44
中國科技博覽(2016年24期)2016-12-28 23:25:48
電子技術與軟件工程(2016年20期)2016-12-21 11:11:51
電腦知識與技術(2016年28期)2016-12-21 10:13:14
電腦知識與技術(2016年27期)2016-12-15 20:33:05
電腦知識與技術(2016年12期)2016-06-14 19:10:43
電腦知識與技術(2016年12期)2016-06-14 01:13:57
科教導刊·電子版(2016年11期)2016-06-03 19:01:33
電腦知識與技術(2016年8期)2016-05-19 13:33:11
