無監(jiān)督混階棧式稀疏自編碼器的圖像分類學習
2019-01-06 07:27:07楊東海林敏敏張文杰楊敬民
計算機應用 2019年12期
楊東海 林敏敏 張文杰 楊敬民


摘 要:目前多數(shù)圖像分類的方法是采用監(jiān)督學習或者半監(jiān)督學習對圖像進行降維,然而監(jiān)督學習與半監(jiān)督學習需要圖像攜帶標簽信息。針對無標簽圖像的降維及分類問題,提出采用混階棧式稀疏自編碼器對圖像進行無監(jiān)督降維來實現(xiàn)圖像的分類學習。首先,構(gòu)建一個具有三個隱藏層的串行棧式自編碼器網(wǎng)絡(luò),對棧式自編碼器的每一個隱藏層單獨訓練,將前一個隱藏層的輸出作為后一個隱藏層的輸入,對圖像數(shù)據(jù)進行特征提取并實現(xiàn)對數(shù)據(jù)的降維。其次,將訓練好的棧式自編碼器的第一個隱藏層和第二個隱藏層的特征進行拼接融合,形成一個包含混階特征的矩陣。最后,使用支持向量機對降維后的圖像特征進行分類,并進行精度評價。在公開的四個圖像數(shù)據(jù)集上將所提方法與七個對比算法進行對比實驗,實驗結(jié)果表明,所提方法能夠?qū)o標簽圖像進行特征提取,實現(xiàn)圖像分類學習,減少分類時間,提高圖像的分類精度。
關(guān)鍵詞:無監(jiān)督學習;棧式自編碼器;降維;混階特征;圖像分類
中圖分類號: TP391.41圖像識別及其裝置文獻標志碼:A
Image classification learning via unsupervised mixed-order stacked sparse autoencoder
YANG Donghai1,2, LIN Minmin1,2, ZHANG Wenjie1,2, YANG Jingmin1,2
1. School of Computer Science, Minnan Normal University, Zhangzhou Fujian 363000, China;
2. Fujian Key Laboratory of Granular Computing and Application (Minnan Normal University), Zhangzhou Fujian 363000, China
Abstract: Most of the current image classification methods use supervised learning or semi-supervised learning to reduce image dimension. However, supervised learning and semi-supervised learning require image carrying label information. Aiming at the dimensionality reduction and classification of unlabeled images, a mixed-order feature stacked sparse autoencoder was proposed to realize the unsupervised dimensionality reduction and classification learning of the images. Firstly, a serial stacked sparse autoencoder network with three hidden layers was constructed. Each hidden layer of the stacked sparse autoencoder was trained separately, and the output of the former hidden layer was used as the input of the latter hidden layer to realize the feature extraction of image data and the dimensionality reduction of the data. Secondly, the features of the first hidden layer and the second hidden layer of the trained stacked autoencoder were spliced and fused to form a matrix containing mixed-order features. Finally, the support vector machine was used to classify the image features after dimensionality reduction, and the accuracy was evaluated. The proposed method was compared with seven comparison algorithms on four open image datasets. The experimental results show that the proposed method can extract features from unlabeled images, realize image classification learning, reduce classification time and improve image classification accuracy.
Key words: unsupervised learning; stacked sparse autoencoder; dimensionality reduction; mixed-order feature; image classification
0 引言
隨著計算機視覺應用的普及,圖像分類在各領(lǐng)域有著廣泛的應用,是人工智能領(lǐng)域的研究熱點。目前在機器學習領(lǐng)域主要有監(jiān)督學習、無監(jiān)督學習和半監(jiān)督學習三大類,其中監(jiān)督學習和半監(jiān)督學習處理圖像需要圖像攜帶標簽信息,對無標簽圖像的處理是監(jiān)督學習和半監(jiān)督學習面臨的一大難題。因而利用圖像自身的特征,進行處理后分類,實現(xiàn)圖像分類,是一種有效的方法。
現(xiàn)實中很多圖像都具有較高的像素,直接處理高維數(shù)據(jù)會有“維數(shù)災難”的問題。從高維數(shù)據(jù)中提取出有用信息至關(guān)重要。當前,常用的方法是對高維數(shù)據(jù)進行降維。目前主要有兩類降維方法:線性降維和非線性降維。典型的線性降維方法有主成分分析(Principal Component Analysis, PCA)[1]和線性判別分析(Linear Discriminant Analysis, LDA )[2]。常見的非線性降維算法有界標等距映射(Landmark IsomaP, LIP)算法[3]、局部線性嵌入(Locally Linear Embedding, LLE)算法[4]、擴散映射(Diffusion MaP, DMP)算法[5]、隨機距離嵌入(Stochastic Proximity Embedding, SPE)算法[6]和基于神經(jīng)網(wǎng)絡(luò)的自編碼器(AutoEncoder, AE)。
自編碼器是一種無監(jiān)督的神經(jīng)網(wǎng)絡(luò),該網(wǎng)絡(luò)一般包含三個部分:輸入層、隱藏層和輸出層。自編碼器的核心思想是通過限制輸出數(shù)據(jù)與輸入數(shù)據(jù)間的歐幾里得距離,實現(xiàn)對編碼權(quán)重矩陣和解碼權(quán)重矩陣的調(diào)整,該方法的優(yōu)點是不需要數(shù)據(jù)攜帶標簽信息即可實現(xiàn)網(wǎng)絡(luò)的訓練,通過提取自編碼器隱藏層的信息,解決了無標簽高維數(shù)據(jù)降維問題,該過程是一種無監(jiān)督降維的學習過程。近年來,眾多學者把注意力放在了研究自編碼網(wǎng)絡(luò)的應用上,文獻[7-9]使用自編碼器對圖像進行處理。在文獻[7-9]的基礎(chǔ)上,文獻[10]將棧式自編碼器應用于提高圖像檢索的效率。文獻[11-13]在醫(yī)學診斷方面取得了不錯的成就,實現(xiàn)了計算機輔助診斷。上述研究均將自編碼應用于單標簽分類任務。除此之外,文獻[14]用自編碼解決多標簽問題,文獻[15]用多標簽的方法對癌癥進行基因注釋,文獻[16]將自編碼網(wǎng)絡(luò)應用于運動目標的檢測。這些采用自編碼的方法,均在其特定的應用上獲得了不錯的效果。
為了解決監(jiān)督學習需要數(shù)據(jù)帶標簽及緩解高維數(shù)據(jù)的“維數(shù)災難”問題,本文采用無監(jiān)督的混階棧式自編碼器(Mixed-Order Stacked Sparse AutoEncoder, MOSSAE)來實現(xiàn)對圖像的特征提取與拼接融合,進行圖像分類學習。具體過程如下:首先,建立一個具有三個隱藏層的串行棧式自編碼器網(wǎng)絡(luò),采用貪婪算法逐層訓練自編碼器,得到每一層接近最優(yōu)的自編碼器網(wǎng)絡(luò),然后微調(diào)整個網(wǎng)絡(luò),使整個網(wǎng)絡(luò)接近整體最優(yōu)。網(wǎng)絡(luò)是逐層訓練,每一層都是特征的表達,并且把前一層的輸出用來當作下一層的輸入,所以越往后的隱藏層,其特征階數(shù)就越高。其次,將訓練好的網(wǎng)絡(luò)的第一隱藏層和第二隱藏層的特征進行拼接融合,形成混階特征矩陣,實現(xiàn)圖像的特征提取。最后,使用融合得到的混階特征矩陣,用支持向量機(Support Vector Machine, SVM)[17-18]進行分類得到分類結(jié)果,將該分類結(jié)果與原始圖像的標簽進行比對得到分類精度。在公開的四個圖像數(shù)據(jù)集上進行實驗,結(jié)果表明所提方法能夠在無監(jiān)督情況下有效提取圖像特征,降低圖像維度,得到較好的圖像分類學習效果。
1 相關(guān)工作
假設(shè)原始高維空間圖像集X={xi|i=1,2,…,N}是N個樣本集合構(gòu)成的矩陣,xi是m×m維的圖像轉(zhuǎn)成的一維向量,滿足D=m×m,X是D×N維矩陣。Y={yi|i=1,2,…,N}是降維后N樣本集合構(gòu)成的矩陣,yi是d維向量,Y是d×N維矩陣,且dD,降維目的是得到一個從X→Y的映射關(guān)系,即Y=f(X)。基于自編碼器的降維算法在圖像識別與分類領(lǐng)域應用廣泛,是一種基于無監(jiān)督學習的非線性降維方法,其分類結(jié)果一般要優(yōu)于線性降維方法。本文應用混階棧式自編碼器,通過該方法來實現(xiàn)對圖像特征的提取,使用提取的混階特征進行圖像分類。分類方法采用SVM,通過分類精度和降維時間這兩指標來描述降維方法的有效性。
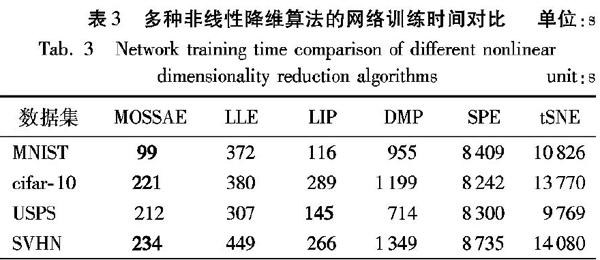
降維方法分為兩大類:線性降維和非線性降維。主成分分析(PCA)[1]是線性降維方法,該方法通過分析計算矩陣的特征值、特征向量來實現(xiàn)降維的目的,PCA是將n維特征映射到k(n 2 自編碼器 自編碼器在圖像分類領(lǐng)域具有廣泛的應用,是一種無監(jiān)督的學習方法,對樣本的訓練不需要添加特定的標簽。目前常見的自編碼器包括稀疏自編碼器、棧式自編碼器等,都是在基本的自編碼器上發(fā)展得到的。 2.1 自編碼器 自編碼器是一種無監(jiān)督的神經(jīng)網(wǎng)絡(luò),其核心是讓網(wǎng)絡(luò)輸出盡可能地等于或者逼近于輸入,結(jié)構(gòu)如圖2所示。自編碼器網(wǎng)絡(luò)結(jié)構(gòu)主要分為三部分:輸入層、隱藏層和輸出層,其中隱藏層可以單層或多層。為了使輸出X′能夠盡可能地逼近輸入X,中間的隱藏層必須能夠盡可能地保留輸入層的特征。圖2表明隱藏層的神經(jīng)元數(shù)目要少于輸入層,故利用自編碼器可以有效地對高維數(shù)據(jù)進行降維。為了更好地描述自編碼器網(wǎng)絡(luò)的特點,定義目標函數(shù)為: J(W,b,X)=12‖hW,b(X)-X‖。假定隱藏層神經(jīng)元j的激活度用j(x)來描述,假設(shè)j(x)=ρ,其中ρ為稀疏性參數(shù),當ρ的值趨近于零時,表明該神經(jīng)網(wǎng)絡(luò)的隱藏神經(jīng)元激活度低,去掉數(shù)據(jù)的冗余信息,降低數(shù)據(jù)復雜度[22]。引入稀疏懲罰項,即: ∑S2j=1ρ lgρj+(1-ρ)lg1-ρ1-j (2) 其中,S2是隱藏層中隱藏神經(jīng)元的數(shù)量,而j依次代表隱藏層中的每一個神經(jīng)元。接著把懲罰項加入到自編碼器的目標函數(shù)中,構(gòu)成了稀疏自編碼器的總體代價函數(shù)為: Jspares(W,b)=J(W,b)+β∑S2j=1KL(ρ‖j) (3) 其中β為稀疏懲罰項的權(quán)重系數(shù)。 2.3 棧式自編碼器 由多個稀疏自編碼器疊加構(gòu)造的網(wǎng)絡(luò)稱為棧式稀疏自編碼器網(wǎng)絡(luò)(Stacked SAE, SSAE)[23-25]。棧式自編碼器結(jié)構(gòu)如圖3所示,棧式自編碼器的訓練過程如圖4所示。 圖片 由圖4可以看出,棧式自編碼器訓練某一層時,其他層的參數(shù)保持不變,并且把前一層的輸出用來作為下一層的輸入,當所有層的參數(shù)快要收斂的時候,再用反向傳播算法對所有層進行微調(diào),達到較優(yōu)的結(jié)果。 3 混階棧式自編碼器的分類方法 通常圖像數(shù)據(jù)具有較高的維數(shù),直接對高維數(shù)據(jù)進行處理會面臨“維數(shù)災難”。針對該問題,較為有效的方法是對高維圖像數(shù)據(jù)進行特征提取,去除圖像中的冗余信息,實現(xiàn)高維數(shù)據(jù)的降維。自編碼器是一種無監(jiān)督的數(shù)據(jù)降維方法,混階棧式自編碼器(MOSSAE)利用棧自編碼器的結(jié)構(gòu)特點,同時使用棧自編碼器多個隱藏層的特征,并對特征進行拼接融合,對圖像進行特征提取。融合的隱藏層是多層,提取出來的是混階特征。通過提取的特征,用SVM對圖像進行分類。 3.1 支持向量機 通常情況下,圖像數(shù)據(jù)集的數(shù)據(jù)在低維度空間線性不可分。用SVM的方法來解決上述問題。SVM的目標是要找到一個超平面,使得需要分類的滿足分類要求的同時又盡可能地遠離超平面的分界區(qū)。定義超平面如下: W*X+b=0(4) 并且使得: Ci=-1; W*X+b≤-1(5) Ci=1; W*X+b≥1(6) 其中:W為系數(shù)矩陣;b為偏置向量;X為輸入數(shù)據(jù);Ci(i=1,2,…,N)為分類類別。 3.2 混階棧式自編碼器 在棧式自編碼器的基礎(chǔ)上充分利用多個隱藏層的數(shù)據(jù)得到混階棧式自編碼器。首先,利用棧式自編碼器的優(yōu)點,即采用無監(jiān)督的方式實現(xiàn)對高維圖像數(shù)據(jù)的降維,進而拼接融合多個隱藏層的特征,實現(xiàn)對圖像的特征提取與拼接融合。融合的混階特征優(yōu)點在于它能夠更加完整地保留多個層次的圖像特征,最后使用SVM進行分類,具體的特征拼接融合過程如下:假設(shè)第i層隱藏層的特征為征為hi,此時可表示為: hi=hi-1*Wi (7) 當i=1時,h0=X1。Xi是輸入的圖像特征,Wi是對應的權(quán)值矩陣。混階特征矩陣H可表示為: 其中:⊕表示對特征進行拼接融合;n表示融合的特征層數(shù)。特征融合得到混階特征矩陣H送入SVM分類器進行分類,得到分類結(jié)果。為了得到分類精度,應用監(jiān)督學習的方法把圖像的原始標簽與SVM分類結(jié)果進行比對,得到分類精度。通過分類精度這個指標來對該算法進行評價。具體過程如圖5所示。 3.3 混階棧式自編碼器分類算法 建立一個具有三個隱藏層的五層自編碼網(wǎng)絡(luò),輸入層根據(jù)輸入圖像的尺寸進行調(diào)整,第一隱藏層神經(jīng)元個數(shù)固定為196個,第二隱藏層的神經(jīng)元個數(shù)d動態(tài)變化用來比較降至不同維數(shù)的分類效果,調(diào)整優(yōu)化網(wǎng)絡(luò)的學習率α。首先用訓練集預訓練自編碼網(wǎng)絡(luò),使其權(quán)重矩陣W和偏置b接近最優(yōu)值,提高訓練的效率。網(wǎng)絡(luò)訓練的目標是最小化代價函數(shù),即: 網(wǎng)絡(luò)訓練采用逐層貪婪算法進行訓練,把上一層的輸出用作下一層的輸入,訓練時使用梯度下降法對參數(shù)進行更新。權(quán)重矩陣W和偏置b參數(shù)更新過程如下: 式中: W為權(quán)重系數(shù)矩陣,W所示,MOSSAE在MNIST數(shù)據(jù)集上分類精度最高,且在分類精度一直保持在較高的水平。PCA算法分類精度也較高,但比MOSSAE差。LIP精度隨著維度的增加呈現(xiàn)劇烈波動的狀態(tài),魯棒性較差,其余算法分類精度都維持在10%左右上下小幅波動。如圖10(b)所示,對cifar-10數(shù)據(jù)集,MOSSAE的分類精度遠高于其他降維方法。PCA、LLE、DMP分類精度在10%上下波動,分類進度遠低于MOSSAE。LIP、SPE、tSNE分類精度波動較大,分類精度最高不超過15%。如圖10(c)所示,對USPS數(shù)據(jù)集,MOSSAE和PCA分類精度相當。LIP算法在某些局部性能可達到最佳,但整體波動大、魯棒性不佳。其他算法分類精度波動較大,總體上分類精度不超過20%,分類性能不如MOSSAE。如圖10(d)所示,對SVHN數(shù)據(jù)集,MOSSAE遠遠優(yōu)于其他算法,且分類精度的波動幅度較小,具有較好魯棒性。PCA、LLE、DMP算法分類精度都維持在18%左右,且波動幅度較小。LIP、SPE、tSNE算法分類精度較差,且魯棒性不佳。 如圖11所示,融合了混階特征的MOSSAE算法要比未進行特征融合的SSAE算法分類精度更高,特別是在低維的時候差距更加明顯,且MOSSAE整體波動幅度不大,魯棒性較好。 表2~3中,數(shù)據(jù)加粗形式為對比數(shù)據(jù)中最好結(jié)果,數(shù)值越小,性能越好。如表2所示,經(jīng)過MOSSAE降維后,使用混階特征矩陣分類與直接SVM分類相比,在實驗所用的四個數(shù)據(jù)集上,平均分類速度提升了68.6%。從表3可以得出,MOSSAE與典型的非線性降維算法相比,降維平均運行時間最少,比LIP算法平均運行效率提升了49.2%,因為MOSSAE網(wǎng)絡(luò)經(jīng)過預訓練,預訓練使權(quán)重系數(shù)及偏置矩陣值接近最優(yōu)值,減少網(wǎng)絡(luò)訓練時間,參數(shù)接近收斂,再微調(diào)整個網(wǎng)絡(luò),這樣就能快速收斂到最優(yōu)值。 綜上所述,進行特征拼接融合的混階特征的棧式自編碼網(wǎng)絡(luò)性能要優(yōu)于未融合特征的一般棧式自編碼器。混階棧式自編碼器能夠有效進行無監(jiān)督圖像數(shù)據(jù)降維,并且同七種降維算法對比,具有較高的分類精度及運行效率。 5 結(jié)語 本文應用混階棧式自編碼器,通過用無監(jiān)督的方法對圖像進行降維,解決了無標簽圖像的降維及分類問題。混階棧式自編碼器通過同時提取兩個隱藏層的特征拼接融合形成混階特征矩陣,利用融合后的混階特征矩陣實現(xiàn)圖像降維及分類問題。通過實驗可知,該方法具有較高的分類精度、較高的運行效率、魯棒性好。這驗證了混階棧式自編碼器能夠更加有效地提取圖片的特征,并進行圖像分類。然而,本文實驗采用的圖像數(shù)據(jù)集特征維數(shù)最高為1024維,圖像類別最多才10類,在實際的醫(yī)學影像圖像應用中,需要處理的圖像數(shù)據(jù)集的特征維數(shù)在幾十萬到上百萬維,圖像類別更多,后續(xù)將改進此方法對醫(yī)學圖像進行進一步研究。 參考文獻 (References) [1]LEE J, CHOE Y. Robust PCA based on incoherence with geometrical interpretation [J]. IEEE Transactions on Image Processing, 2018, 27(4): 1939-1950. [2]LIU C, JIN T, HOI S C H, et al. Collaborative topic regression for online recommender systems: an online and Bayesian approach [J]. Machine Learning, 2017, 106(5): 651-670. [3]RAFAILIDIS D, MANOLOPOULOU S, DARAS P. A unified framework for multimodal retrieval [J]. Pattern Recognition, 2013, 46(12): 3358-3370. [4]JIN X, HAN H, DAI Q. Plenoptic image coding using macropixel-based intra prediction [J]. IEEE Transactions on Image Processing, 2018, 27(8): 3954-3968. [5]BERRY T, HARLIM J. Iterated diffusion maps for feature identification [J]. Applied and Computational Harmonic Analysis, 2018, 45(1): 84-119. [6]焦斌亮,張可.基于SPE的無線傳感器網(wǎng)絡(luò)定位算法[J].小型微型計算機系統(tǒng),2013,34(2):269-271.(JIAO B L, ZHANG K. Localization algorithm based on stochastic proximity embedding in wireless sensor networks [J]. Journal of Chinese Computer Systems, 2013, 34(2): 269-271.) [7]ZABALZA J, REN J, ZHENG J, et al. Novel segmented stacked autoencoder for effective dimensionality reduction and feature extraction in hyperspectral imaging [J]. Neurocomputing, 2016, 185: 1-10. [8]FAN Z, BI D, HE L, et al. Low-level structure feature extraction for image processing via stacked sparse denosing autoencoder [J]. Neurocomputing, 2017, 243: 12-20. [9]張春雨,韓立新,徐守晶.基于棧式自動編碼的圖像哈希算法[J].電子測量技術(shù),2016,39(3):46-49,69.(ZHANG C Y, HAN L X, XU S J. Image hashing algorithm based on stacked autoencoder [J]. Electronic Measurement Technology, 2016, 39(3): 46-49, 69.) [10]ZHANG Y, THING V L L. A semi-feature learning approach for tampered region localization across multi-format images [J]. Multimedia Tools and Applications, 2018, 77(19): 25027-25052. [11]MAO K M, TANG R J, WANG X Q, et al. Feature representation using deep autoencoder for lung nodule image classification [J]. Complexity, 2018, 2018:Article ID 3078374. https://doi.org/10.1155/2018/3078374 [12]DAI Y, WANG G. Analyzing tongue images using a conceptual alignment deep autoencoder [J]. IEEE Access, 2018, 6: 5962-5972. [13]ZHAO G, WANG X, NIU Y, et al. Segmenting brain tissues from chinese visible human dataset by deep-learned features with stacked autoencoder [J]. BioMed Research International, 2016, 2016: Article ID 5284586. [14]楊文元.多標記學習自編碼網(wǎng)絡(luò)無監(jiān)督維數(shù)約簡[J].智能系統(tǒng)學報,2018,13(5):808-817.(YANG W Y.Unsupervised dimensionality reduction via autoencoder networks [J]. CAAI Transactions on Intelligent Systems, 2018, 13(5): 808-817.) [15]GUAN R, WANG X, YANG M Q, et al. Multi-label deep learning for gene function annotation in cancer pathways [J]. Scientific Reports, 2018, 8(1):Article ID 267. [16]徐培,蔡小路,何文偉,等.基于深度自編碼網(wǎng)絡(luò)的運動目標檢測[J].計算機應用,2014,34(10):2934-2937,2962.(XU P, CAI X L, HE W W, et al. Motion detection based on deep auto-encoder networks [J]. Journal of Computer Applications, 2014, 34(10): 2934-2937, 2962.) [17]ZHENG W, GONG S, XIANG T. Towards open-world person re-identification by one-shot group-based verification [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(3): 591-606. [18]BRERETON R G, LLOYD G R. Support vector machines for classification and regression [J]. The Analyst, 2010, 135(2): 230-267. [19]VAN DER MAATEN L. Accelerating t-SNE using tree-based algorithms [J]. Journal of Machine Learning Research, 2014, 15(1): 3221-3245. [20]YUAN S, WU X, XIANG Y. SNE: Signed Network Embedding [C]// Proceedings of the 2017 Pacific-Asia Conference on Knowledge Discovery and Data Mining, LNCS 10235. Cham: Springer, 2017: 183-195. [21]ZHANG S, WANG J, TAO X, et al. Constructing deep sparse coding network for image classification [J]. Pattern Recognition, 2017, 64: 130-140. [22]OTHMAN E, BAZI Y, ALAJLAN N, et al. Using convolutional features and a sparse autoencoder for land-use scene classification [J]. International Journal of Remote Sensing, 2016, 37(10): 2149-2167. [23]沈承恩,何軍,鄧揚. 基于改進堆疊自動編碼機的垃圾郵件分類[J].計算機應用,2016,36(1):158-162.(SHEN C E, HE J, DENG Y. Spam filtering based on modified stack auto-encoder [J]. Journal of Computer Applications, 2016, 36(1): 158-162.) [24]BADEM H, CALISKAN A, BASTURK A, et al. Classification of human activity by using a stacked autoencoder [C]// Proceedings of the 2017 Medical Technologies National Congress. Piscataway:IEEE, 2017: 1-4. [25]楊帥,王鵑.基于堆棧降噪自編碼器改進的混合推薦算法[J].計算機應用,2018,38(7):1866-1871.(YANG S, WANG J. Improved hybrid recommendation algorithm based on stacked denoising autoencoder [J]. Journal of Computer Applications, 2018, 38(7): 1866-1871.) This work is partially supported by the National Natural Science Foundation of China (61701213), the Special Research Fund for Higher Education of Fujian (JK2017031), the Cooperative Education Project of Ministry of Education (201702098015, 201702057020), the Natural Science Foundation of Zhangzhou (ZZ2018J21). YANG Donghai, born in 1988, M. S. candidate. His research interests include computer vision. LIN Minmin, born in 1994, M. S. candidate. Her research interests include machine learning, wireless communications. ZHANG Wenjie, born in 1984, Ph. D., professor. His research interests include cognitive radio, computer network architecture. YANG Jingmin, born in 1980, M. S., associate professor. His research interests include cognitive radio, computer network architecture, machine learning. 收稿日期:2019-04-29;修回日期:2019-06-25;錄用日期:2019-06-26。 基金項目:國家自然科學基金資助項目(61701213);福建省省屬高校科研專項資助項目(JK2017031);教育部產(chǎn)學合作協(xié)同育人項目(201702098015,201702057020);漳州市自然科學基金資助項目(ZZ2018J21)。 作者簡介:楊東海(1988—),男,福建漳州人,碩士研究生,CCF會員,主要研究方向:計算機視覺;林敏敏(1994—),女,福建州人,碩士研究生,CCF會員,主要研究方向:機器學習、無線通信;張文杰(1984—),男,福建漳州人,博士,教授,CCF會員,主要研究方向:認知無線電、計算機網(wǎng)絡(luò)體系結(jié)構(gòu);楊敬民(1980—),男,福建漳州人,碩士,副教授,CCF會員,主要研究方向:認知無線電、計算機網(wǎng)絡(luò)體系結(jié)構(gòu)、機器學習。 文章編號:1001-9081(2019)12-3420-06 DOI:10.11772/j.issn.1001-9081.2019061107
