網絡協議識別技術綜述
2019-01-06 07:27:07馮文博洪征吳禮發付夢琳
計算機應用 2019年12期
馮文博 洪征 吳禮發 付夢琳

摘 要:網絡流量的協議類型識別是進行協議分析和網絡管理的前提,為此研究綜述了網絡協議識別技術。首先,描述了網絡協議識別的目標,分析了協議識別的一般流程,探討了協議識別的現實需求,給出了評估協議識別方法的標準;然后,從基于數據包的協議識別和基于數據流的協議識別兩個類別分析了網絡協議技術的研究現狀,并對協議識別的各類技術進行了比較分析;最后,針對目前協議識別方法的缺陷和應用需求,對協議識別技術的研究趨勢進行了展望。
關鍵詞:應用層協議;網絡流量;協議識別;特征工程;網絡管理
中圖分類號: TP393.02計算機網絡與結果文獻標志碼:A
Review of network protocol recognition techniques
FENG Wenbo1, HONG Zheng1*, WU Lifa2, FU Menglin1
(1. College of Command and Control Engineering, Army Engineering University of PLA, Nanjing Jiangsu 210007, China;
2. College of Computer Science and Technology, Nanjing University of Posts and Telecommunications, Nanjing Jiangsu 210023, China)
Abstract: Since the protocol classification of network traffic is a prerequisite for protocol analysis and network management, the network protocol recognition techniques were researched and reviewed. Firstly, the target of network protocol recognition was described, and the general process of protocol recognition was analyzed. The practical requirements for protocol recognition were discussed, and the criteria for evaluating protocol recognition methods were given. Then, the research status of network protocol techniques was summarized from two categories: packet-based protocol recognition methods and flow-based protocol recognition methods, and the variety of techniques used for protocol recognition were analyzed and compared. Finally, with the defects of current protocol recognition methods and the practical application requirements considered, the research trend of protocol recognition techniques was forecasted.
Key words: application-level protocol; network traffic; protocol recognition; feature engineering; network management
0 引言
網絡協議是通信實體在互聯網環境中進行數據交換的基礎,是計算機網絡及數據通信不可缺少的組成成分。網絡協議描述了特定網絡環境下通信設備之間的通信過程,規定了通信報文的格式、處理方式和交互時序,其質量關乎網絡通信的安全性、可靠性和穩定性。常用的協議解析工具如Wireshark等[1]根據協議規范可以對協議實現快速準確識別。
網絡協議識別是指通過人工或自動化手段分析網絡協議或者應用所產生的網絡流量,提取出能夠標識網絡協議的關鍵特征,然后以這些特征為基礎標識網絡流量所隸屬的應用層協議[2]。網絡協議識別技術是管理和優化網絡資源的重要基礎,能夠對網絡流量的組成進行精確分析,為網絡管理與維護、網絡內容審計、網絡安全防御等多個研究領域提供技術支撐。隨著網絡規模的不斷擴大、網絡應用種類的迅速增加,對網絡協議識別的效率和準確性的要求越來越高,研究能夠提高協議識別準確率和自動化程度的方法具有重要的現實意義。
1 問題描述與定義
網絡協議識別技術的研究主要從序列載荷的內容特征和通信行為的外部特征兩個方面展開。基于序列載荷內容特征的協議識別可以理解為微觀、具體的方法。這類方法需要了解各層協議數據單元的字段結構和字節取值分布,如采用傳輸控制協議(Transmission Control Protocol, TCP)層的端口信息進行協議區分,基于特定協議字段的取值進行協議區分。基于通信行為外部特征的協議識別可以視為宏觀、抽象的方法。不同協議通常具有不同的傳輸特性和不同的統計分布規律,可以依據協議的各種宏觀統計信息來推斷流量所屬的網絡協議。為了剖析網絡協議識別的本質,分析現有方法的優勢與不足,本文將首先論述協議識別目標、協議識別需求和主要判別指標三方面的基礎內容。
1.1 協議識別目標
協議實體的通信通常是一個復雜的交互過程。出于簡單化處理的考慮,協議設計時通常采用分層思想,將不同的通信功能在不同層次上實現。
TCP/IP協議族是使用最為廣泛的四層協議系統,其層次系統自下而上分為:鏈路層、網絡層、傳輸層和應用層。鏈路層負責處理與傳輸媒介相關的問題;網絡層負責處理分組在網絡中傳輸;傳輸層為兩個傳輸節點提供端到端通信;應用層負責處理特定應用程序與用戶的交互細節。鏈路層、網絡層和傳輸層都定義了各自的協議格式,根據RFC(Request For Comments)文檔便可以分析通信過程。而應用層協議是根據應用需求進行定制,種類繁多。區分應用層協議是網絡協議識別的主要目標。
網絡協議識別往往會以協議的分層為基礎,首先依據協議解析工具識別出幀頭格式,如以太網幀、點對點協議(Point to Point Protocol, PPP)幀,確定數據包中的網絡層首部和傳輸層首部,進而提取出應用層協議數據進行分析。
網絡協議識別需要將連續的網絡流量按照一定粒度進行劃分,常見的粒度包括Bit-level、Packet-level、Flow-level、Stream-level四類。Bit-level關注網絡流量的內容特征,從比特流中挖掘用于區分協議的特征序列,適用于無任何先驗知識下的網絡協議識別。Packet-level關注數據包的內容特征及其交互行為,如數據包內容、大小分布、時間間隔等,適用于早期的互聯網流量的協議識別,現在多作為網絡協議識別的輔助分析手段。Flow-level關注數據流的內容特征與交互行為,如數據流內容、大小分布、到達時間等,這種以流為單位分析網絡傳輸數據的方法目前使用最為廣泛。Stream-level關注通信主機交互產生的流量,通過長期收集來統計通信特性,適用于研究粗粒度且時間跨度較長的骨干網流量。
同一種協議通信產生的網絡流量之間存在一定的相似性,可以利用這種相似性區分不同協議產生的網絡流量。網絡協議識別的本質就是利用網絡流量的內容信息或統計信息,建立一種函數映射關系f:X→C,將網絡流量映射為具體的協議類型,其中:X表示待分類的網絡流量集合,C表示協議類型集合,
1.2 協議識別需求
網絡協議識別技術有助于對網絡流量的組成結構進行分析,保障網絡的正常運轉。網絡協議識別的應用需求主要體現在以下領域:
1)網絡管理與優化。協議識別技術通過對網絡流量的分類識別與統計分析有助于了解流量分布情況和網絡運行狀態,通過細粒度的協議分析提高網絡監控效能,通過配置合理的管理策略提供差異化的網絡服務。
2)網絡內容監管。面對海量的通信內容,依賴人工識別的傳統內容監管方法難以為繼,網絡協議識別技術可以自動獲取流量所承載的內容,能夠針對性地過濾非法信息,有效降低監管成本,提高網絡內容監管的效率和水平。
3)網絡安全防御。網絡流量是網絡行為的體現,通過深層次分析網絡中傳輸的內容,可以發現通信流量中包含的病毒攻擊代碼和敏感信息,及時進行告警并提供應對方案,從而防范安全威脅,提高網絡安全防御水平。
1.3 主要判別指標
目前,衡量網絡協議識別方法,主要采用以下一些判別指標:
1)準確性。衡量協議識別方法的預測值與真實值之間接近程度,主要包括總體識別衡量指標(總體分類準確率Accuracy)和單類識別衡量指標(精確率Precision、召回率Recall和F值F-Measure)。在實際應用中,需要考慮流量種類的不平衡性,因為流量占比較高的協議更容易被識別。
2)實時性。評估協議識別方法是否能夠實時對網絡流量進行類型判別,較早識別出協議類型有利于后續處理,例如及時對惡意流量進行過濾攔截。
3)魯棒性。網絡數據傳輸過程中會發生一些特殊情況,如數據包亂序、丟失等。評估協議識別方法應該具備處理這些特殊情況的能力,包容這些異常并且保證協議識別結果的準確率。
4)擴展性。評估協議識別方法在不同粒度劃分下的準確率變化以及面對不同吞吐量的性能表現,擴展性好的方法能夠保證協議識別結果的準確率和效率。
5)安全性。衡量協議識別方法對于傳輸內容的保護能力,安全性高的方法在進行協議識別的同時能夠有效保護用戶隱私、防止隱私數據泄露。
6)協議無關性。協議識別方法除了能夠對已知協議實現準確識別,在實際應用中,還可能會遇到新出現的未知協議產生的流量或經過加密的流量,協議無關性好的方法應該能夠識別出未知協議的網絡流量。
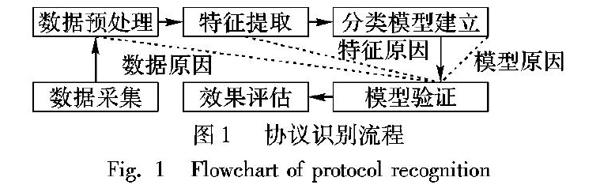
2 網絡協議識別流程
網絡協議的識別流程大體可分為五個階段:數據采集、數據預處理、特征提取、分類模型的建立和模型驗證,如圖 1所示。每個階段相對獨立,又互相關聯。模型驗證的結果與數據預處理、特征提取和分類模型建立密切相關。數據預處理是模型驗證的數據原因,合理、有效的預處理有助于提高協議識別的準確率;特征提取階段提取出的特征是模型驗證的特征原因,完備的特征集有利于提高協議識別的檢測效率;分類模型建立是模型驗證的模型原因,簡單、高效的分類模型有利于提高協議識別的準確率和檢測效率。數據采集和數據預處理階段的工作相對固定,本章將進行重點介紹。特征提取和分類模型的建立是協議識別領域的研究重點,將在后續章節結合研究進展進行介紹。
2.1 數據采集
網絡協議識別的第一步就是獲取網絡數據樣本。目前,協議識別的研究數據主要包括本地流量集和公開數據集。下面對兩類數據集進行介紹。
2.1.1 本地數據集
本地流量集是指協議分析人員根據實際需求捕獲的網絡流量,然后將網絡流量構造為研究所用的數據集。一些機器學習算法要求建立訓練數據集,其中的訓練數據需要進行標注。數據集標注的好壞會直接影響算法的學習性能,目前的標注方法主要包括人工標注方法和自動標注方法兩類。人工標注方法往往要求在實驗環境中模擬目標程序運行,依據端口等已知信息對目標程序產生的流量進行協議類型的標注。自動標注方法利用深度包檢測(Deep Packet Inspection, DPI)方法或基于DPI的工具自動地標記流量,如L7-filter[3]、nDPI[4]、Libprotoident[5]等。DPI技術不僅檢測端口等信息,而且檢查包括包頭和載荷的完整數據包,通常這種方法準確率優于簡單依賴于端口的方法。兩種標注方法各有優缺點,人工標注方法的實驗環境可能跟真實網絡環境有很大差距,因此產生的訓練數據集不具有代表性。工具輔助標記常常因應用繁多、通信量較大等問題,不能精確標記樣本,因此實際應用中常結合兩種方法進行目標數據的標記。
2.1.2 公開數據集
由于網絡流量可能包含用戶的隱私數據,出于對用戶隱私安全的考慮,協議識別領域缺乏廣泛認可的標準流量數據集。為了避免泄露用戶隱私,數據集一般需要進行匿名化處理。匿名化處理主要去除負載數據或載荷數據中的敏感信息,對IP地址匿名化。公開數據集是由相關研究機構收集而來,并對外公開的流量數據集,表1給出了目前協議識別領域常用的公開流量數據集:Moore[6]、CAIDA[7] 、UNIBS[8] 、WIDE[9] 、WITS[10] 、DARPA[11]。
表格(有表名)表1 常見公開流量數據集
Tab. 1 Common public traffic datasets
序號數據集數據實例標簽匿名處理1Moore248種統計特征有無2CAIDA流量數據無是3UNIBS無載荷數據有是4WIDE無負載數據無是5WITS64字節數據無是6DARPA流量數據無無
2.2 數據預處理
網絡協議識別的對象可以是數據包、流、會話等。數據預處理能夠將包含異常數據記錄的原始數據集轉化為適用于協議識別的數據集。
數據預處理主要包括數據清洗和數據轉換兩個步驟。數據清洗的目標是提高數據質量,保證數據的一致性。具體做法是對缺失數據、冗余數據、噪聲數據等異常進行清洗,清洗檢查內容包括包頭長度是否在合理范圍內、包到達時間間隔是否在合理區間內等。數據轉換步驟的目標是將數據從一個維度空間映射為另一個維度空間,常用的是歸一化處理方法。網絡流量從數學的角度看就是一種離散型數據,使用歸一化方法可以將離散特征取值映射到歐氏空間,離散特征值對應于歐氏空間的某點,這樣可以使離散特征之間距離或者相似度的計算更加合理。
經過數據預處理后,樣本集構造成功。此外,還需要考慮數據集中各類別數據的規模是否平衡,若不平衡,可以采取過采樣或欠采樣方法構造平衡數據集。為了評估方法效果,通常還需要將數據集進行分割,細分為訓練集和驗證集或訓練集、驗證集和測試集等形式。訓練集用于構建分類模型,驗證集用于驗證模型識別效果是否達到指定要求,測試集用于評估在實際應用中模型表現的泛化能力。數據集分割方法多樣,可以采用隨機抽樣、K折交叉驗證法等。
3 研究進展
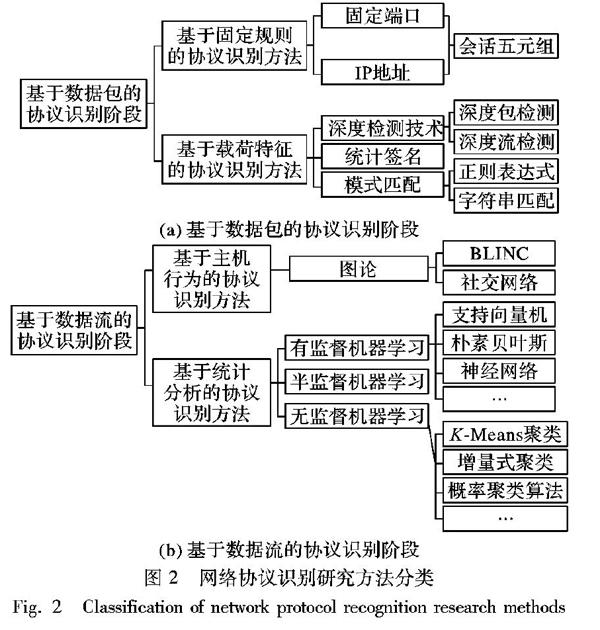
網絡協議識別技術的研究根據研究思路的不同,主要可以分為兩個階段,分別是:基于數據包的協議識別階段和基于數據流的協議識別階段。每一階段都有不同的研究方法,如圖 2所示。本章對兩個階段的一些代表性方法進行探討和分析。
3.1 基于數據包的協議識別階段
早期的網絡協議識別主要基于數據包進行分析,可以分為兩類協議識別方法:基于固定規則的協議識別方法和基于載荷特征的協議識別方法。
3.1.1 基于固定規則的協議識別方法
目前基于固定規則的協議識別方法多使用網絡傳輸的五元組信息(源IP地址、目的IP地址、源端口號、目的端口號、傳輸層協議),一般通過比對數據包的端口或IP地址相關信息推斷協議類型,可以細分為基于端口的協議識別方法和基于IP地址的協議識別方法。
基于端口的協議識別往往基于互聯網數字分配機構(Internet Assigned Numbers Authority, IANA)[12]提供的端口協議對照表進行查詢,在解析出數據包的端口號信息之后,推斷網絡流量所屬協議類型,如表 2所示。IANA規定系統應用端口號范圍為0~1023,用戶應用端口號范圍為1024~49151,動態端口號為49152~65535。但是隨著網絡應用的快速發展,很多應用都向用戶提供了自定義端口的功能,用戶可以根據自己的喜好設置網絡應用所使用的端口。此外,點對點傳輸(Peer-to-Peer, P2P)、基于IP的語音傳輸(Voice over Internet Protocol, VoIP)等應用為了避開運營商監控,采用動態端口技術。一些僵尸網絡程序為了躲避防火墻檢測,引入了端口偽裝技術,通過將通信端口更改為公認端口欺騙依據端口進行過濾的入侵檢測系統。這些技術的出現,導致基于端口的協議識別方法不再可靠。Moore等[6]與Madhukar等[13]分別通過實驗證實基于端口的協議識別方法的識別準確率從最初的70%已降低至20%以下。但是,由于此類方法實現簡單、運行速度高,現在還常常作為協議識別的輔助手段。
基于IP地址的協議識別主要是利用數據包的IP地址信息進行協議識別。這種方法的適用范圍較窄,多用于一些公開應用的識別,例如:如果數據包中包含的一方IP地址為31.13.83.16,該IP地址屬于Facebook站點,所有與此IP 地址交互的流量都被推斷為Facebook流量。以IP地址和通信端口作為協議特征進行協議識別。Yoon等[14]將應用流量與三元組〈IP,Port,Protocol〉進行關聯,通過匹配三元組信息可以確定哪些流量屬于公開應用產生的。在可控環境下主機的所有應用是前提已知的,通過篩查統計可以確定非公開應用產生的流量;但這種方法只能粗略地對流量進行分類,且在實際應用中準確率難以保證。基于固定規則的協議識別方法雖然存在很大缺陷,但能夠對流量進行初步分類,有利于后續進一步精確地進行協議識別。
表格(有表名)表 2 IANA提供的常見端口協議映射
Tab. 2 Common port-protocol mappings provided by IANA
端口號協議傳輸協議描述20FTP-DATATCP/UDP文件傳輸協議數據端口21FTPTCP/UDP文件傳輸協議控制端口23TELNETTCP/UDP遠程登錄協議25SMTPTCP/UDP簡單郵件傳輸協議53DNSTCP/UDP域名服務80HTTPTCP/UDP超文本傳輸協議110POP3TCP/UDP郵件接收協議
3.1.2 基于載荷特征的協議識別方法
為了提高協議識別的準確率,基于載荷特征的協議識別方法被提出,此類方法主要采用深度包檢測技術。深度包檢測技術不僅檢查數據包的頭首部信息,還對部分載荷或者全部載荷進行檢測,通過尋找預定義的字符串特征,與特征庫進行比對確定數據包的協議類型。表 3給出了部分應用協議的識別規則[15-16]。
基于載荷特征的協議識別方法能夠避免對端口的過分依賴,減小端口濫用、偽裝等技術對協議識別的影響。早期的特征提取需要一定專家知識,隨著技術的不斷發展,采用機器學習中深度學習方法可以自動完成特征提取。Sen等[17]通過對載荷的分析實現了P2P流的分類,通過檢查數據包載荷識別應用特征,能夠在高速網絡上基于特征準確識別P2P流量,相較基于端口的方法,準確率提高了3倍。Yun等 [18]提出了一種基于語義信息的網絡協議識別方法。該方法首先對原始流量進行3-gram切分處理,得到3-gram序列;然后,基于隱含狄利克雷分布(Latent Dirichlet Allocation, LDA)算法挖掘協議關鍵字,得到協議關鍵字模型;最后,通過協議關鍵字模型提取協議數據包特征,進而完成聚類,實現協議格式的提取。
從理論上看,分析數據包的載荷內容,協議識別的準確率可以接近100%[19]。但典型的深度包檢測方法存在以下三方面的問題:1)提取協議識別特征較為困難,特征庫需要不斷維護。協議識別特征的提取依賴于專家領域知識,需要人工手動確定;且當協議版本升級或新協議出現時,需要及時將特征存入特征庫中;面對網絡的快速發展,特征庫需要持續更新維護。2)適用范圍有限,該方法無法應用于加密流量和協議規范信息未知的網絡流量。流量的加密會使得網絡數據表現出隨機性和不確定性,難以進行協議特征的提取。而對于一些私有協議,由于協議規范信息未知,在特征庫中找不到特征與之匹配。3)系統開銷較高。當特征庫中的特征數量超過一定規模時,耗費的系統資源會急劇增加。
盡管存在許多不足,此類方法仍是目前較為準確的一類協議識別方法,在工業界應用廣泛,也是高速網絡環境部署的最佳選擇[16,20]。近年來,不少研究人員針對DPI的不足,提出了各類改進方法。DPI的技術研究不斷朝著智能化、系統化的方向發展。
深度流檢測(Deep Flow Inspection, DFI)技術是DPI技術一個改進,其檢測粒度從單一數據包擴展到完整數據流。DFI技術是基于流量行為的識別技術,即不同類型流量數據的流狀態不同。與DPI技術相比,DFI能夠對未知流量和加密流量進行識別;但總體上看,該技術的識別準確率低于DPI技術[21],具體如表 4所示。Wang等[22]綜合DPI和DFI的優勢,提出了一種基于DPI和DFI的新型P2P流量識別系統,該系統比單個基于DPI或DFI識別系統具有更廣泛的識別范圍,且具有自主學習能力。葉文晨等[23]提出了一種以DPI技術為主、DFI技術為輔的協議識別方法,并為此設計了軟硬件結合的識別設備,其中:DPI技術是由MPC8572網絡處理器提供硬件支撐,DFI技術則是通過軟件程序完成。該方法主要通過對內存池進行讀寫處理,DPI實現細粒度的分類,并在內存池中寫入涉及分類識別的相應信息,以此來更新會話流的統計信息和識別結果。DFI用于檢測DPI誤識別情況,若DPI與DFI識別結果一致,則確定識別結果;否則,清除識別結果,進行重新檢測。這種方法比簡單地使用DPI或DFI技術的識別方法效果好;但面對加密等情況,DPI技術失效,只能使用DFI進行流量的粗分類。
高效的特征匹配算法是實現高性能DPI的基礎,因此很多研究人員從降低特征匹配算法的復雜度著手改進DPI技術。特征匹配算法分為字符串匹配方法和正則表達式匹配方法。字符串匹配方法是對一個或多個固定特征串(模式)的簡單規則的匹配,通常對載荷的前幾十個字節進行匹配,包括KMP(Knuth-Morris-Pratt)、BM(Boyer-Moore)算法、WM(Wu-Manber)算法、AC(Aho-Corasick)自動機算法等。這類方法通過縮減檢測范圍,提高DPI的數據處理能力;但該類方法的主要缺點是面對協議特征位置不固定的協議,識別準確率較低。
正則表達式匹配方法可以面向復合型條件的查詢和模糊匹配,能夠實現復雜規則的匹配,即通過一個表達式表示一組規則,也支持規則之間的關聯[24]。與字符串匹配方法相比,此類方法具有更強的字符串描述能力,靈活高效,能夠識別非固定位置的協議特征,但存在空間開銷大、處理速度慢等問題。付文亮等[25]針對正則表達式的計算復雜度高、存儲消耗大等問題,提出了一種基于現場可編程邏輯門陣列(Field Programmable Gate Array, FPGA)的正則表達式匹配方法,通過對數據結構、流管理策略等方面進行優化,提高協議識別的處理能力。Kumar等[26]也提出了基于硬件的正則表達式方法,通過縮減確定有限狀態自動機(Deterministic Finite Automaton, DFA)硬件存儲空間來提高匹配識別的速率。Tong等[27]針對大多數協議識別方法存在的吞吐量性能瓶頸,從軟硬件兩方面提高協議識別的吞吐量。該方法首先利用C4.5決策樹構造識別器;然后,采用優化決策樹和分治技術,對協議識別器進行加速;最后,基于FPGA和多核處理器,對協議識別器進行硬件加速。
為了將DPI技術部署在高速網絡環境中,研究人員嘗試以自動化、半自動化方式獲得應用特征,比較常用的是基于統計指紋(即模式)的方法,采用統計方法自動推導網絡協議的指紋特征,然后利用特征進行協議識別。Finamore 等[28]提出了KISS方法處理用戶數據包協議(User Datagram Protocol, UDP)流量,利用UDP流量載荷的統計特征,通過卡方測試推導協議統計指紋。該方法在實驗測試中效果較好,不足之處是使用范圍有限,僅適用于UDP流量載荷。Crotti 等[29]提出一種基于數據包大小、到達時間和到達順序三個簡單屬性的協議識別方法,通過這些流量屬性來表示協議指紋;但此方法只考慮TCP流量載荷。
3.2 基于數據流的協議識別階段
網絡協議識別領域研究的第二個階段是基于數據流的協議識別階段,該階段最為典型的方法包括基于主機行為的協議識別方法和基于統計分析的協議識別方法。加密協議的使用導致依賴數據包固定特征串的方法不再可靠,研究者轉向分析數據包的行為特征、統計特征等外部信息,將分析粒度從單個數據包擴展到了完整的數據流。
3.2.1 基于主機行為的協議識別方法
基于主機行為的協議識別方法從宏觀的角度對網絡流量進行分類識別,主要利用了網絡流量的統計特性,如數據流持續時間、字節數、傳輸間隔時間等在網絡通信過程可直接測量的統計參數。此類方法有效避免了具體數據特征的提取,能夠防止用戶信息泄露,計算效率高,存儲開銷小,并且能夠處理加密數據流;但這種方法的主要缺點是統計信息采集繁瑣,且受網絡環境影響,統計結果可能不穩定,實時性差,協議識別的準確度偏低。
Karagiannis等[30]提出了基于主機行為的BLINC流量分類框架,提取網絡流的社會行為、功能行為和應用行為特征。其中:社會層關注主機與其他主機的交互行為,如連接數量、社區關系;功能層關注特定主機的網絡角色,如客戶端、服務器;應用層捕獲特定主機在特定端口傳輸的信息,如流的長度、大小。該方法首先基于經驗推導出每種協議的主機行為,并將這些行為以圖的形式存儲下來,BLINC通過圖匹配進行協議識別,實驗測試能夠識別80%~90%的網絡流量,且準確率超過95%。后續基于主機行為的協議識別方法多以BLINC的分類框架為基礎。
Iliofotou等[31]提出了一種利用流量散度圖監測、分析網絡流量的方法,首先通過TDG(Traffic Dispersion Graph)建模網絡通信場景,借鑒社交網絡理論,使用IP地址代替社交網絡中的個人,以散度圖的節點表示通信主機,邊代表主機間的信息交換,不同協議的TDG明顯不同,通過分析連通子圖、節點分布情況,可以推斷出網絡流的協議信息。
3.2.2 基于機器學習的協議識別方法
面對與日俱增的網絡流量,一些研究人員提出將機器學習方法應用于協議識別領域。機器學習是人工智能領域的一項重要技術,通過計算機對大規模數據進行挖掘,分析數據特征之間的規律。機器學習以強大的自適應性、自學習能力為分類問題提供了一種有效的決策手段。協議識別的本質是分類問題,可以通過機器學習的方法解決。這種方法雖具有很高的準確率以及很強的數據處理能力,但也存在對特征的依賴嚴重、在真實網絡環境部署困難等問題。
目前,基于機器學習的協議識別方法可以分為基于有監督學習的協議識別方法、基于無監督學習的協議識別方法,以及基于半監督學習的機器學習方法,其中有監督學習是研究較多的一類。下面對這三類方法的研究情況進行介紹。
1) 有監督學習方法。
有監督學習方法又稱分類方法,需要一個預先分類的標簽訓練集,即數據集中有輸入數據信息和期望的輸出結果。有監督學習的目標是通過分類模型能夠降低樣本實際標簽與期望結果之間的差距。有監督學習方法的基本識別流程分為訓練和測試兩個階段。在訓練階段,首先對網絡數據流進行預處理轉化為向量或矩陣形式;然后,通過特征工程方法獲取適合的特征作為判別依據;最后,選擇有監督學習算法構造訓練分類器,并對訓練分類器進行訓練。在測試階段,也需要進行預處理完成數據類型轉化,并通過特征工程選擇出代表網絡數據流的特征;然后,將提取出的特征信息輸入訓練好的分類器,預測網絡流量所對應的協議類型。目前,分類模型主要采用了樸素貝葉斯(Naive Bayesian, NB)、支持向量機(Support Vector Machine, SVM)、神經網絡(Neural Network, NN)、決策樹(Decision Tree, DT)、K近鄰(K-Nearest Neighbors, KNN)等方法。
貝葉斯網絡是一種概率圖模型,也是有向無環圖,節點代表變量,有向邊代表節點之間的條件概率。貝葉斯分類器是基于貝葉斯公式解決分類問題的概率模型,目前研究較多的貝葉斯分類器是樸素貝葉斯。該方法是基于特征向量各分量之間相互獨立的假設,首先基于此假設學習數據輸入與結果輸出的聯合概率分布模型,然后利用模型基于貝葉斯原理求出輸入數據后驗概率最大的輸出值。Moore等[6]使用有監督的簡單樸素貝葉斯分類算法對數據集進行分類,所使用的網絡數據集由248個統計特征組成,如流持續時間、包到達時間的傅里葉變換等,且已被人工分類,并指明了分類標簽,使用有監督的簡單樸素貝葉斯分類算法進行分類的準確率為65%,然而通過方法改進,使用基于核密度估計的樸素貝葉斯(Naive Bayes with Kernel density Estimation, NBKE)算法和基于快速相關的過濾器(Fast Correlation-Based Filter, FCBF)的樸素貝葉斯減少特征維度,分類準確率可以提高到95%以上。李君等[32]采用貝葉斯網絡進行流量分類,首先通過分析流統計特征確定所需提取的特征屬性,然后通過遺傳算法選擇最優的特征子集,最后基于特征子集采用貝葉斯網絡識別P2P流量。該方法能夠快速識別P2P業務,且分類準確率達95%。張澤鑫等[33]提出一種基于加權的樸素貝葉斯流量分類方法,采用特征選擇算法ReliefF和相關系數方法計算出每個特征的權重值,然后通過貝葉斯確定流量所屬類別。
支持向量機是針對二值分類問題提出的,但通過構造多個SVM分類模型或與二叉決策樹相結合,可以將其推廣到多分類問題[34]。支持向量機是一種基于結構風險最小化原理的分類方法,目標是尋找能夠分離樣本的分類超平面。Li等[35]和Yang等[36]針對以往方法復雜、難以實時分類,且在條件獨立假設不成立和先驗知識存有不足的情況下,使用SVM分別對校園流量和P2P流量進行識別分類,通過支持向量機將流量分類問題轉化為二次尋優問題,當面對流量各類別先驗概率未知或不足的情況時,其分類準確率比樸素貝葉斯方法要高。Groleat等[37]提出一種結合FPGA硬件加速技術的SVM協議識別模型,對于高速網絡環境,這種方法的分類性能遠遠超過純軟件實現,并且能夠實現實時分類。王一鵬等[38]提出一種基于主動學習和SVM的網絡協議識別方法。該方法能夠克服網絡數據流的獲取與標記工作對于領域知識的依賴,避免SVM分類器對無意義、重復樣本的學習,不僅能夠減少標記所用時間,而且提高了學習效率。曹杰[39]提出一種過濾式封裝式(Filter-Wrapper)特征選擇方法,該方法能夠改善特征維冗余引發分類性能的下降問題,增強SVM流量分類的泛化能力。Lobato等[40]提出了一種能夠實時檢測零日攻擊的流量識別方法,該方法從蜜罐中收集攻擊流量,將分類器的輸入視為合法輸入,若分類器識別為攻擊流量時報警,識別為正常流量時進行參數更新。
DBSCAN算法是一種基于密度的聚類算法,通過尋找密度相連的最大集合來確定聚類結果,將具有高密度的區域劃分為一類。何震凱等[61]提出一種基于DBSCAN的協議識別方法,以主成分分析作為特征選擇方法,選出合適的特征子集,進而利用DBSCAN算法聚類成簇,利用簇構建流量分類器。
無監督學習方法還包括層次聚類、譜聚類、高斯混合模型聚類和隱馬爾可夫模型聚類算法等方法。張鳳荔等[62]提出基于改進凝聚層次聚類的協議分類算法,該算法以層次凝聚(AGglomErative NeSting, AGENS)算法為基礎,采用邊聚類邊提取結果的方式,實現對數據的快速聚類。周文剛等[63]針對網絡流量復雜、動態的特性,采用譜聚類的思想將網絡流量的分類識別問題轉化為無向圖的多路劃分問題,使用拉普拉斯矩陣完成高維數據向低維數據的轉換,然后利用譜圖劃分的思想構建分類器,最終基于圖劃分結果對流量進行分類識別。Bernaille等[64]采用K均值、高斯混合模型、隱馬爾可夫模型這三種聚類方法對TCP網絡流量進行分類,研究發現高斯混合模型聚類和隱馬爾可夫模型聚類算法的分類準確率接近,且高于K均值聚類。
3) 半監督學習方法。
有標記數據少、無標記數據多的現象普遍存在,但它們具有相似的數據分布,為了解決這類問題出現了半監督學習。半監督學習方法介于有監督學習與無監督學習之間,能夠利用少量標記樣本和大量未標記樣本,指導進行分類工作。
趙英等[65]提出一種基于馬爾可夫模型的半監督學習方法。該方法利用馬爾可夫模型提取特征值,通過密度計算的方法估計聚類中心點,有效避免了傳統聚類算法不穩定的問題,提升了識別準確率。Erman等[66]提出一種基于K-Means的半監督學習方法,首次將半監督學習引入到流量分類領域,通過K均值算法將包含有少量標記樣本和大量未標記樣本數據的數據集劃分為若干簇,然后選擇簇中比例最大的已標記樣本,以相應的類標記作為簇的類別。Zhang等[67]利用網絡數據流的相關性信息擴展有監督數據集,根據未標記流和預先標記流之間的相關性自動標記未標記流,擴展了有監督數據集的規模和質量,提高了分類識別的性能。丁偉等[68]提出基于層次聚類的半監督學習方法,利用層次聚類將內容相近的數據流聚為一類,首先利用互信息選擇最相關的統計特征,縮減數據流的特征空間,然后采用高斯函數進行數據流的高維特征映射,根據高維空間的距離進行聚類,實驗結果表明該方法能夠對大部分流量進行準確的分類識別。Wang等[69]研究了基于先驗知識的協議識別方法,該方法將標記數據集和未標記數據集作為輸入,首先利用約束聚類算法提取未標記數據的新模式,且這些模式是標記數據未出現的,并以此模式代表未知協議,然后基于標記數據和未標記數據的新模式訓練多個二元分類器,根據分類器的結果確定樣本數據的協議類型。
3.3 方法比較
從上述的基于固定規則、載荷特征、主機行為、機器學習這四類協議識別技術可以看出,很難憑借一種方法識別出所有流量,大部分方法適用于特定場景。為了進一步分析四種技術的不同,本文從準確性、實時性、魯棒性、伸縮性、安全性、協議無關性這六種判別指標著手,對四種技術進行對比和分析,結果如表 5所示。
表格(有表名)表5 不同協議識別方法的性能比較
Tab. 5 Performance comparison of different protocol recognition methods
方法準確性實時性魯棒性伸縮性安全性協議無關固定規則低較高較高較高最高最低載荷特征較高較高低低最低最低主機行為較低較低中中最高中機器學習中中中最高最高最高
在準確性方面,基于固定規則的識別方法能夠很好識別常見的標準協議,如超文本傳輸協議(HyperText Transfer Protocol, HTTP)、文件傳輸協議(File Transfer Protocol, FTP)、域名系統(Domain Name System, DNS)等,但識別其他協議時,尤其是非固定端口的協議,準確性會大幅下降,總的來說,這種方法的準確性偏低。基于載荷特征的識別方法是目前工業界應用較多的方法,這種方法為每一種協議建立識別規則。雖然規則庫的建立和維護成本較高,但準確性是最好的,原因在于識別規則與協議規范是密切聯系的,建立規則可以理解為提取協議規范的固定模式。基于主機行為或機器學習的方法需要預先建立模型,識別準確性與模型完備性、訓練數據集等都密切相關,且大多情況下,識別準確性不如基于載荷特征的方法。
在實時性方面,基于固定規則、載荷特征的實時性較好,這與處理對象是有直接聯系的,匹配規則通常分析數據包的前幾十字節或是指定位置,能夠快速分析出流量的類型。基于主機行為的方法是對通信的網絡進行分析,對每一種協議的通信行為進行統計建模,該方法計算量大、耗時長,因此實時性較差。基于機器學習的方法需要提取數據流的內容或統計特征。若提取統計特征,則與基于主機行為方法相似,實時性較差。若提取內容特征,則實時性與提取特征的位置有關:有些方法認為特征應當從數據流開始和結束的幾十個字節中提取,這種特征提取方法難以保證實時性;也有的研究人員選擇從數據流開始的幾百個字節進行提取,這種提取方法實時性較好。總體來看,基于機器學習的協議識別方法實時性一般。
在魯棒性方面,基于固定規則的識別方法適用性較強,只需簡單地從IP頭或TCP頭提取地址和端口,便能作出判斷。這種方法能夠容忍網絡出現異常,魯棒性也是四種方法中最好的。基于主機行為、機器學習的識別方法的魯棒性取決于多種因素,如提取特征的質量或位置、數據集的完備性。整體來看,這兩種方法魯棒性一般。基于載荷特征的識別方法魯棒性較差,主要是因為對數據包的重傳、亂序等異常現象較為敏感,如果流量經過加密處理,數據的特性被隱藏,該方法將失效,因此這種方法的魯棒性相較其他三種方法是最差的。
在擴展性方面,基于固定規則的識別方法只需提取協議頭部的端口等信息,該方法簡單、高效,伸縮性最好。基于載荷特征的識別方法在面臨吞吐量較大的情況時,需要進行大量的特征匹配,計算開銷也會急劇增加,需要結合軟硬件設備才能滿足性能要求,其伸縮性偏低。基于主機行為、機器學習的識別方法當面臨吞吐量較大的情況時,也需要更大的內存空間來存儲特征。在對數據流進行分析時,伸縮性較好,因為從數據流提取的特征更完備;在數據包進行分析時,伸縮性相對較差。整體來看,這兩種方法伸縮性一般。
在安全性方面,基于載荷特征的識別方法需要檢測數據包的應用層數據,容易造成隱私泄露問題。基于固定規則的識別方法不需要對應用層數據匹配特征模式等,也就不存在安全問題。基于主機行為、機器學習的識別方法在對統計特征進行分析時,不分析流量的具體內容,只分析流量的通信行為,安全性較高。另外,基于機器學習的識別方法也存在分析應用層數據的情況,但不深入檢測應用層具體內容,安全性問題并不嚴重。
在協議無關性方面,基于固定規則的識別方法只能識別已知的標準協議,根據端口協議的映射關系進行識別,對未知協議的流量,尤其端口非固定的協議,該方法會失效。基于載荷特征的識別方法面對未知流量、加密流量都會失效。這種方法的識別依賴于識別規則庫,規則庫中因沒有未知流量的識別規則而失效;加密會掩蓋協議特征而使方法失效。基于主機行為的識別方法是對流量外部特征進行分析,因此不會受到流量內容加密所帶來的影響;但這種方法是對已知協議的通信行為進行建模,也就導致無法識別未知流量。基于機器學習的識別方法與基于主機行為的識別方法類似,當對統計行為特征進行分析時,能夠識別加密流量;當對內容特征進行分析時,根據同一協議內部特征表現出的相似性,可以識別出未知流量的協議信息。因此基于機器學習的識別方法適用范圍最廣。
4 未來研究方向
協議識別技術經過十幾年的研究,從傳統的基于固定規則和載荷特征的數據包識別階段,發展到目前的基于主機行為和機器學習的數據流識別階段,識別準確率和效率雖然有所提高,但還不能很好適應網絡的持續性變化。為了應對各類新興的網絡技術和紛繁復雜的應用,協議識別技術可以嘗試在以下方向有所突破:
1)數據采集與可信標注。目前協議識別缺乏公認的數據集,研究人員多采用自身實驗網絡環境下捕獲的原始流量數據,然后使用人工方法或DPI工具進行類別標注。人工方法繁瑣、工作量大,易出錯,適用于小樣本標記。DPI工具能夠大批量、自動化地標記樣本,但是Carela-espanol等[70]的測試發現L7-fiter的平均準確率只有38.13%,達不到結果可信的水平。然而協議識別需要大量的樣本,因為樣本越多越能反映出協議的特性,不能僅僅依賴于人工標記的方法,因此標準的數據集與值得信任的標注方法是需要研究人員考慮解決的問題之一。
2)未知協議的識別。未知協議在互聯網中越來越多,很多應用軟件使用了自己設計的通信協議,這類協議是Wireshark等通用協議解析工具無法解析的。但未知協議與已知協議一樣,具有相對固定的格式,當同一類型未知協議的流量數據不斷累積,流量數據在物理取值和統計分布方面的特性也會變得愈加明顯,從中尋找規律也成為可能。未知協議識別需要首先通過尋找相對固定的特征序列識別出幀頭,然后在此基礎上,挖掘出上層協議特征,最后使用協議特征指導后續的協議識別。
3)加密流量識別。一些軟件出于安全防護的考慮,采用了加密和隧道化傳輸技術,如安全套接層(Secure Sockets Layer, SSL)、安全外殼(Secure SHell, SSH)協議、虛擬專用網絡(Virtual Private Network, VPN)等,加密后的流量數據缺乏明顯的協議特性,增加了分類的難度。不僅要考慮這些加密流量的檢測,更要進一步識別它們的協議類型,這就顯得尤為困難。
4)P2P協議識別。P2P技術的普及,導致難以采集完整有效的數據。P2P節點在行為上兼具Server 和Client兩種身份,跟傳統的C/S或B/S訪問模式中通信端點的一一映射關系有很大的不同,只能收集到部分流量。除此之外,P2P應用類型多樣,包括文件下載、內容共享、即時通信、網絡電話和流媒體等。在這種情況下,如何細粒度地區分P2P協議是目前研究難點。
5)類別不平衡的協議識別。目前機器學習方法是協議識別的研究熱點,其分類模型多是由類別平衡的實驗環境下的數據訓練得到,但在實際網絡環境中,存在嚴重的類別不平衡現象。如果采用重采樣技術,多采樣小類別的樣本或從大類別中刪除一部分樣本,這種處理方式會破壞原本的樣本分布情況。若部署在真實網絡環境中,可能將小類別流量誤識別為大類別流量,在類別不平衡條件下,保證小類別協議識別的準確率也是研究人員需要考慮的問題。
5 結語
網絡協議識別技術在網絡安全領域具有重要的作用。隨著網絡技術的不斷升級,傳統的基于端口的協議識別技術識別效果越來越差。基于載荷特征的方法雖然準確,但容易泄露用戶隱私。基于主機行為的方法建模復雜,且多停在理論分析階段。基于機器學習方法的雖然高效、準確率高,但嚴重依賴于特征導致其難以在真實環境中部署。
本文綜述了網絡協議識別領域的研究方法和相關成果。首先介紹網絡協議識別的識別目標、識別需求和評估準則;然后分析網絡協議識別的基本流程;接著從兩個類別詳細分析了不同協議識別方法的優缺點;最后展望了未來的研究方向。
雖然研究人員在流量識別領域取得了不少成果,但是協議識別技術仍面臨著眾多的挑戰:
1)復雜網絡環境的挑戰,例如移動網絡、云平臺環境。移動互聯網發展迅速和智能終端的快速普及都極大改變了傳統互聯網的行為模式,智能終端的應用數量也不斷增加,所產生網絡流量也在急劇增長,如何在移動網絡下進行網絡流量的協議識別分類也顯得更加重要。越來越多的應用采用云平臺環境部署。云平臺的出入口流量混合了多種不同應用的流量,且經常對應用的部署進行動態調整,難以得到純凈的訓練樣本,實現精確的協議識別。
2)大數據高速網絡實時分類的挑戰。面對網絡流量的大數據,結合Hadoop、FPGA等并行處理技術和硬件加速技術成為研究趨勢。實時分類不同于離線分類,要求盡早識別出協議類型。從目前協議識別的研究情況來看,大多數研究方法都圍繞著提高識別準確率展開,基于固定規則、載荷特征兩種方法雖具有早期識別的優勢,但準確率和運行效率難以保證。基于主機行為和基于機器學習的兩類方法依賴于離線學習。除此之外,高速網絡越來越普及,如何將協議識別方法部署在高速網絡,實時進行協議識別且能保證識別準確率,是學術界、工業界面臨的重要挑戰。
3)網絡流量持續動態變化的挑戰。網絡流量持續性動態變化會導致概念漂移現象的產生,具體表現是處于不同網絡環境的同一類協議的流量數據分布會出現較大差異。然而現有方法假設同種協議具有相同分布的特性,且著重于流量的靜態識別,沒有考慮流量概念漂移的影響。面對網絡流量的持續變化,將不同網絡環境的流量進行統一處理,是協議識別領域的嚴峻挑戰。
參考文獻 (References)
[1]SANDERS C. Practical Packet Analysis: Using Wireshark to Solve Real-World Network Problems [M]. San Francisco: No Starch Press, 2011: 192-194.
[2]陳亮,龔儉,徐選.應用層協議識別算法綜述[J].計算機科學,2007,34(7):73-75.(CHEN L, GONG J, XU X. A survey of application-level protocol identification algorithm [J]. Computer Science, 2007, 34(7): 73-75.)
[3]SourceForge. L7-filter: application layer packet classifier for Linux [EB/OL]. [2019-04-14]. http://l7-filter.sourceforge.net/.
[4]DERI L, MARTINELLI M, BUJLOW T, et al. nDPI: open-source high-speed deep packet inspection [C]// Proceedings of the 2014 Wireless Communications and Mobile Computing Conference. Piscataway: IEEE, 2014: 617-622.
[5]ALCOCK S, NELSON R. Libprotoident: traffic classification using lightweight packet inspection: technical report [R/OL]. [2019-04-14]. http://www.wand.net.nz/publications/lpireport.
[6]MOORE A W, ZUEV D. Internet traffic classification using Bayesian analysis techniques [J]. ACM SIGMETRICS Performance Evaluation Review, 2005, 33(1): 50-60.
[7]CAIDA. CAIDA data-overview of datasets, monitors and reports [EB/OL]. [2019-04-14]. http://www.caida.org/data/overview/.
[8]Università degli Studi di Brescia. UNIBS: data sharing [EB/OL]. [2019-04-14]. http://netweb.ing.unibs.it/~ntw/tools/traces.
[9]The MAWI Working Group. MAWI working group traffic archive [EB/OL]. [2019-04-14]. http://mawi.wide.ad.jp/mawi/.
[10]WAND network research group. WITS: Waikato Internet traffic storage [EB/OL]. [2019-04-14]. https://wand.net.nz/wits/.
[11]LIPPMANN R, HAINES J W, FRIED D J, et al. The 1999 DARPA off-line intrusion detection evaluation [J]. Computer Networks, 2000, 34(4): 579-595.
[12]TOUCH J, MANKIN A, KOHLER E, et al. Service name and transport protocol port number registry [EB/OL]. [2019-04-14]. https://www.iana.org/assignments/service-names-port-numbers/service-names-port-numbers.xhtml.
[13]MADHUKAR A, WILLIAMSON C. A longitudinal study of P2P traffic classification [C]// Proceedings of the 14th International Symposium on Modeling, Analysis, and Simulation. Piscataway: IEEE, 2006: 179-188.
[14]YOON S H, PARK J W, PARK J S, et al. Internet application traffic classification using fixed IP-port [C]// Proceedings of the 12th Asia-pacific Network Operations and Management Conference on Management Symposium, LNCS 5787. Berlin: Springer, 2009: 21-30.
[15]KARAGIANNIS T, BROIDO A, FALOUTSOS M, et al. Transport layer identification of P2P traffic [C]// Proceedings of the 4th ACM SIGCOMM Internet Measurement Conference. New York: ACM, 2004: 121-134.
[16]汪立東,錢麗萍,王大偉,等.網絡流量分類方法與實踐[M].北京:人民郵電出版社,2013:122-126.(WANG L D, QIAN L P, WANG D W, et al. Network Traffic Classification [M]. Beijing: Posts and Telecom Press, 2013: 122-126.)
[17]SEN S, SPATSCHECK O, WANG D. Accurate, scalable in-network identification of P2P traffic using application signatures [C]// Proceedings of the 2004 13th International Conference on World Wide Web. New York: ACM, 2004: 512-521.
[18]YUN X, WANG Y, ZHANG Y, et al. A semantics-aware approach to the automated network protocol identification [J]. IEEE/ACM Transactions on Networking, 2016, 24(1): 583-595.
[19]MOORE A W, PAPAGIANNAKI K. Toward the accurate identification of network applications [C]// Proceedings of the 6th International Workshop on Passive and Active Network Measurement, LNCS 3431. Berlin: Springer, 2005: 41-54.
[20]BUJLOW T, CARELA-ESPANOL V, BARLET-ROS P. Independent comparison of popular DPI tools for traffic classification [J]. Computer Networks, 2015, 76: 75-89.
[21]CHEN H, HU Z, YE Z, et al. A new model for P2P traffic identification based on DPI and DFI [C]// Proceedings of the 2009 International Conference on Information Engineering and Computer Science. Piscataway: IEEE, 2009: 1-3.
[22]WANG C, ZHOU X, YOU F, et al. Design of P2P traffic identification based on DPI and DFI [C]// Proceedings of the 2009 International Symposium on Computer Network and Multimedia Technology. Piscataway: IEEE, 2009: 1-4.
[23]葉文晨,汪敏,陳云寰,等.一種聯合DPI和DFI的網絡流量檢測方法[J].計算機工程,2011,37(10):102-104,107.(YE W C, WANG M, CHEN Y H, et al. Network flow inspection method of joint DPI and DFI [J]. Computer Engineering, 2011, 37(10): 102-104, 107.)
[24]林冠洲.網絡流量識別關鍵技術研究[D].北京:北京郵電大學,2011:10.(LIN G Z. Research on the key technologies of network traffic classification [D]. Beijing: Beijing University of Posts and Telecommunications, 2011: 10.)
[25]付文亮,嵩天,周舟.RocketTC:一種基于FPGA的高性能網絡流量分類架構[J].計算機學報,2014,37(2):414 -422.(FU W L, SONG T, ZHOU Z. RocketTC: a high throughput traffic classification architecture on FPGA [J]. Chinese Journal of Computers, 2014, 37(2): 414-422.)
[26]KUMAR S, DHARMAPURIKAR S, YU F, et al. Algorithms to accelerate multiple regular expressions matching for deep packet inspection [J]. ACM SIGCOMM Computer Communication Review, 2006, 36(4): 339-350.
[27]TONG D, QU Y R, PRASANNA V K. Accelerating decision tree based traffic classification on FPGA and multicore platforms [J]. IEEE Transactions on Parallel and Distributed Systems, 2017, 28(11): 3046-3059.
[28]FINAMORE A, MELLIA M, MEO M, et al. KISS: stochastic packet inspection classifier for UDP traffic [J]. IEEE/ACM Trans on Networking, 2010, 18(5): 1505-1515.
[29]CROTTI M, DUSI M, GRINGOLI F, et al. Traffic classification through simple statistical fingerprinting [J]. ACM SIGCOMM Computer Communication Review, 2007, 37(1): 5-16.
[30]KARAGIANNIS T, PAPAGIANNAKI K, FALOUTSOS M. BLINC: multilevel traffic classification in the dark [C]// Proceedings of the 2005 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications. New York: ACM, 2005: 229-240.
[31]ILIOFOTOU M, PAPPU P, FALOUTSOS M, et al. Network monitoring using Traffic Dispersion Graphs (TDGs) [C]// Proceedings of the 7th ACM SIGCOMM Conference on Internet Measurement. New York: ACM, 2007: 315-320.
[32]李君,張順頤,王浩云,等.基于貝葉斯網絡的Peer-to-Peer識別方法[J].應用科學學報,2009,27(2):124-130.(LI J, ZHANG S Y, WANG H Y, et al. Peer-to-peer traffic identification using Bayesian networks [J]. Journal of Applied Sciences, 2009, 27(2): 124-130)
[33]張澤鑫,李俊,常向青.基于特征加權的樸素貝葉斯流量分類方法研究[J].高技術通訊,2016,26(2):119-128.(ZHANG Z X, LI J, CHANG X Q. Internet traffic classification using the attribute weighted naive Bayes algorithm [J]. High Technology Letters, 2016, 26(2): 119-128.)
[34]孫德山.支持向量機分類與回歸方法研究[D].長沙:中南大學,2004:10.(SUN D S. The researches on support vector machine classification and regression methods [D]. Changsha: Central South University, 2004: 10.)
[35]LI Z, YUAN R, GUAN X. Accurate classification of the Internet traffic based on the SVM method [C]// Proceedings of the 2007 IEEE International Conference on Communications. Piscataway: IEEE, 2007: 1373-1378.
[36]YANG A, JIANG S, DENG H. A P2P network traffic classification method using SVM [C]// Proceedings of the 9th International Conference for Young Computer Scientists. Piscataway: IEEE, 2008: 398-403.
[37]GROLEAT T, ARZEL M, VATON S. Hardware acceleration of SVM-based traffic classification on FPGA [C]// Proceedings of the 8th International Wireless Communications and Mobile Computing Conference. Piscataway: IEEE, 2012: 443-449.
[38]王一鵬,云曉春,張永錚,等.基于主動學習和SVM方法的網絡協議識別技術[J].通信學報,2013,34(10):135-142.(WANG Y P, YUN X C, ZHANG Y Z, et al. Network protocol identification based on active learning and SVM algorithm [J]. Journal on Communications, 2013, 34(10): 135-142.)
[39]曹杰.基于SVM的網絡流量特征降維與分類方法研究[D].長春:吉林大學,2017:10.(CAO J. Research of feature reduction and traffic classification method based on SVM [D]. Changchun: Jilin University, 2017: 10.)
[40]LOBATO A G P, LOPEZ M A, SANZ I J, et al. An adaptive real-time architecture for zero-day threat detection [C]// Proceedings of the 2018 International Conference on Communications. Piscataway: IEEE, 2018: 1-6.
[41]譚駿,陳興蜀,杜敏,等.基于自適應BP神經網絡的網絡流量識別算法[J].電子科技大學學報,2012,41(4):580-585.(TAN J, CHEN X S, DU M, et al. Internet traffic identification algorithm based on adaptive BP neural network [J]. Journal of University of Electronic Science and Technology of China, 2012, 41(4): 580-585)
[42]WANG W, ZHU M, ZENG X, et al. Malware traffic classification using convolutional neural network for representation learning [C]// Proceedings of the 2017 International Conference on Information Networking. Piscataway, NJ: IEEE, 2017: 712-717.
[43]王勇,周慧怡,俸皓,等.基于深度卷積神經網絡的網絡流量分類方法[J].通信學報,2018,39(1):14-23.(WANG Y, ZHOU H Y, FENG H, et al. Network traffic classification method basing on CNN [J]. Journal on Communications, 2018, 39(1): 14-23.)
[44]JAIN A V. Network traffic identification with convolutional neural networks [C]// Proceedings of the IEEE 16th International Conference on Dependable, Autonomic and Secure Computing, 16th International Conference on Pervasive Intelligence and Computing, 4th International Conference on Big Data Intelligence and Computing and 2018 International Conference on Cyber Science and Technology. Piscataway: IEEE, 2018: 1001-1007.
[45]陳雪嬌,王攀,俞家輝. 基于卷積神經網絡的加密流量識別方法[J].南京郵電大學學報(自然科學版),2018,38(6):40-45.(CHEN X J, WANG P, YU J H. CNN based encrypted traffic identification method [J]. Journal of Nanjing University of Posts and Telecommunications (Natural Science Edition), 2018, 38(6): 40-45)
[46]葉松.基于現代網絡的深度學習應用協議識別技術研究與實現[J].軟件導刊,2018,17(10):194-199.(YE S. Research and implementation of deep learning application protocol recognition technology based on modern network [J]. Software Guide, 2018, 17(10): 194-199.)
[47]REN J, WANG Z. A novel deep learning method for application identification in wireless network [J]. China Communications, 2018, 15(10): 73-83.
[48]WILLIAMS N, ZANDER S, ARMITAGE G. A preliminary performance comparison of five machine learning algorithms for practical IP traffic flow classification [J]. ACM SIGCOMM Computer Communication Review, 2006, 36(5): 5-16.
[49]徐鵬,林森.基于C4.5決策樹的流量分類方法[J].軟件學報,2009,20(10):2692-2704.(XU P, LIN S. Internet traffic classification using C4.5 decision tree [J]. Journal of Software, 2009, 20(10): 2692-2704.)
[50]周劍峰,陽愛民,劉吉財.基于改進的C4.5算法的網絡流量分類方法[J].計算機工程與應用,2012,48(5):71-74.(ZHOU J F, YANG A M, LIU J C. Traffic classification approach based on improved C4.5 algorithm [J]. Computer Engineering and Applications, 2012, 48(5): 71-74)
[51]王朝正.基于Hadoop的C4.5決策樹及其在網絡流量中的應用[D].重慶:重慶郵電大學,2016:10.(WANG C Z. C4.5 decision tree based on Hadoop and its application in network traffic [D]. Chongqing: Chongqing University of Posts and Telecommunications, 2016: 10.)
[52]程珊,鈕焱,李軍.基于網絡資源的KNN網絡流量分類模型的研究[J].湖北工業大學學報,2016,31(4):75-79,82.(CHENG S, NIU Y, LI J. A study on network traffic classification model of KNN based on network resources [J]. Journal of Hubei University of Technology, 2016, 31(4): 75-79, 82.)
[53]SU M Y. Using clustering to improve the KNN-based classifiers for online anomaly network traffic identification [J]. Journal of Network and Computer Applications, 2011, 34(2): 722-730.
[54]ZHANG J, XIANG Y, WANG Y, et al. Network traffic classification using correlation information [J]. IEEE Transactions on Parallel and Distributed Systems, 2013, 24(1): 104-117.
[55]WU D, CHEN X, CHEN C, et al. On addressing the imbalance problem: a correlated KNN approach for network traffic classification [C]// Proceedings of the 2015 International Conference on Network and System Security, LNCS 8792. Cham: Springer, 2015: 138-151.
[56]MCGREGOR A, HALL M, LORIER P, et al. Flow clustering using machine learning techniques [C]// Proceedings of the 2004 International Workshop on Passive and Active Network Measurement, LNCS 3015. Berlin: Springer, 2004: 205-214.
[57]LIU S, HU J, HAO S, et al. Improved EM method for Internet traffic classification [C]// Proceedings of the 8th International Conference on Knowledge and Smart Technology. Piscataway: IEEE, 2016: 13-17.
[58]ZANDER S, NGUYEN T, ARMITAGE G. Automated traffic classification and application identification using machine learning [C]// Proceedings of the 2005 IEEE Conference on Local Computer Networks 30th Anniversary. Piscataway: IEEE, 2005: 250-257.
[59]LIU Y, LI W, LI Y. Network traffic classification using k-means clustering [C]// Proceedings of the 2nd International Multi-symposiums on Computer and Computational Sciences. Piscataway: IEEE, 2007: 360-365.
[60]彭大芹,項磊,李司坤,等.多協議下智能家居協議的分類方法[J].重慶郵電大學學報(自然科學版),2018,30(3):321-328.(PENG D Q, XIANG L, LI S K, et al. Classification of intelligent home protocol under multi-protocols [J]. Journal of Chongqing University of Posts and Telecommunications (Natural Science Edition), 2018, 30(3): 321-328.)
[61]何震凱,陽愛民,劉永定,等.一種使用DBSCAN聚類的網絡流量分類方法[J].計算機應用研究,2009,26(9):3461-3464.(HE Z K, YANG A M, LIU Y D, et al. Method of network traffic classification using DBSCAN clustering [J]. Application Research of Computers, 2009, 26(9): 3461-3464.)
[62]張鳳荔,周洪川,張俊嬌,等.基于改進凝聚層次聚類的協議分類算法[J].計算機工程與科學,2017,39(4):796-803.(ZHANG F L, ZHOU H C, ZHANG J J, et al. A protocol classification algorithm based on improved AGENS [J]. Computer Engineering and Science, 2017, 39(4): 796-803.)
[63]周文剛,陳雷霆,董仕.基于譜聚類的網絡流量分類識別算法[J].電子測量與儀器學報,2013,27(12):1114-1119.(ZHOU W G, CHEN L T, DONG S. Network traffic classification algorithm based on spectral clustering [J]. Journal of Electronic Measurement and Instrument, 2013, 27(12): 1114-1119.)
[64]BERNAILLE L, TEIXEIRA R, SALAMATIAN K. Early application identification [C]// Proceedings of the 2006 ACM Conference on Emerging Network Experiment and Technology. New York: ACM, 2006: Article No. 6.
[65]趙英,韓春昊.馬爾科夫模型在網絡流量分類中的應用與研究[J].計算機工程,2018,44(5):291-295.(ZHAO Y, HAN C H. Application and research of Markov model in network traffic classification [J]. Computer Engineering, 2018, 44(5): 291-295.)
[66]ERMAN J, MAHANTI A, ARLITT M, et al. Semi-supervised network traffic classification [J]. ACM SIGMETRICS Performance Evaluation Review, 2007, 35(1): 369-370.
[67]ZHANG J, CHEN C, XIANG Y, et al. Semi-supervised and compound classification of network traffic [C]// Proceedings of the 32nd International Conference on Distributed Computing Systems Workshops. Piscataway: IEEE, 2012: 617-621.
[68]丁偉,徐杰,卓文輝.基于層次聚類的網絡流識別算法研究[J].通信學報,2014,35(Z1):41-45.(DING W, XU J, ZHUO W H. Net traffic identifier based on hierarchical clustering [J]. Journal on Communications, 2014, 35(Z1): 41-45.)
[69]WANG Y, XUE H, LIU Y, et al. Statistical network protocol identification with unknown pattern extraction [J]. Annals of Telecommunications, 2019, 74(7/8): 473-482.
[70]CARELA-ESPANOL V, BUJLOW T, BARLET-ROS P. Is our ground-truth for traffic classification reliable? [C]// Proceedings of the 2014 International Conference on Passive and Active Network Measurement, LNCS 8362 . Cham: Springer, 2014: 98-108.
This work is partially supported by the National Key Research and Development Program of China (2017YFB0802900).
FENG Wenbo, born in 1994, M. S. candidate. His research interests include network protocol recognition, machine learning.
HONG Zheng, born in 1979, Ph. D., associate professor. His research interests include network security, protocol reverse engineering.
WU Lifa, born in 1968, Ph. D., professor. His research interests include network security, network management.
FU Menglin, born in 1995, M. S. candidate. Her research interests include vulnerability mining, blockchain security.
收稿日期:2019-06-06;修回日期:2019-08-07;錄用日期:2019-08-08。基金項目:國家重點研發計劃項目(2017YFB0802900)。
作者簡介:馮文博(1994—),男,河南周口人,碩士研究生,主要研究方向:網絡協議識別、機器學習; 洪征(1979—),男,江蘇南京人,副教授,博士,主要研究方向:網絡安全、協議逆向工程; 吳禮發(1968—),男,湖北黃石人,教授,博士,CCF會員,主要研究方向:網絡安全、網絡管理; 付夢琳(1995—),女,江蘇南京人,碩士研究生,主要研究方向:漏洞挖掘、區塊鏈安全。
文章編號:1001-9081(2019)12-3604-11 DOI:10.11772/j.issn.1001-9081.2019050949
