基于深度殘差和特征金字塔網(wǎng)絡(luò)的實時多人臉關(guān)鍵點定位算法
2019-01-06 07:27:07謝金衡張炎生
計算機(jī)應(yīng)用 2019年12期
謝金衡 張炎生


摘 要:針對人臉關(guān)鍵點定位算法需要分為人臉區(qū)域檢測與單人臉關(guān)鍵點定位兩個步驟,導(dǎo)致處理時間成倍增加的情況,提出一步到位的實時且準(zhǔn)確的多人臉關(guān)鍵點定位算法。該算法將人臉關(guān)鍵點坐標(biāo)生成對應(yīng)的熱度圖作為數(shù)據(jù)標(biāo)簽,利用深度殘差網(wǎng)絡(luò)完成前期的圖像特征提取,使用特征金字塔網(wǎng)絡(luò)融合在不同網(wǎng)絡(luò)深度中表征不同尺度感受野的信息特征,應(yīng)用中間監(jiān)督思想,級聯(lián)多個預(yù)測網(wǎng)絡(luò)由粗到精地一次性回歸圖中所有人臉的關(guān)鍵點,而無需人臉檢測步驟。在保持高定位精度的同時,該算法完成一次前向傳播只需要約0.0075s(約每秒133幀),滿足了實時人臉關(guān)鍵點定位的要求,且在WFLW測試集中取得了6.06%的平均誤差與11.70%的錯誤率。
關(guān)鍵詞:殘差網(wǎng)絡(luò);特征金字塔網(wǎng)絡(luò);實時人臉關(guān)鍵點定位;中間監(jiān)督
中圖分類號: TP391.4文獻(xiàn)標(biāo)志碼:A
Real-time multi-face landmark localization algorithm based on
deep residual and feature pyramid neural network
XIE Jinheng, ZHANG Yansheng*
(College of Electronic and Information Engineering, Guangdong Ocean University, Zhanjiang Guangdong 524088, China)
Abstract: Most face landmark detection algorithms include two steps: face detection and face landmark localization, increasing the processing time. Aiming at the problem, a one-step and real-time algorithm for multi-face landmark localization was proposed. The corresponding heatmaps were generated as data labels by the face landmark coordinates. Deep residual network was used to realize the early feature extraction of image and feature pyramid network was used to fuse the information features representing receptive fields with different scales in different network depths. And then based on intermediate supervision, multiple landmark prediction networks were cascaded to realize the one-step coarse-to-fine facial landmark regression without face detection. With high accuracy localization, a forward propagation of the proposed algorithm only takes about 0.0075s (133 frames per second), satisfying the requirement of real-time facial landmark localization. And the proposed algorithm has achieved the mean error of 6.06% and failure rate of 11.70% on Wider Facial Landmarks in-the-Wild (WFLW) dataset.
Key words: residual network; feature pyramid network; real-time face landmark localization; intermediate supervision
0 引言
人臉在視覺信息傳達(dá)中有著重要的作用,通過人臉信息可以獲得許多非語言信息,例如人的身份、年齡、表情和意圖。為準(zhǔn)確獲取這些信息,人臉關(guān)鍵點定位通常是許多人臉應(yīng)用中一個首要且非常關(guān)鍵的步驟,例如人臉識別[1-2]、人臉驗證[3-4]、表情分析。但由于人臉常常伴隨著豐富的表情變化、外界光照程度、妝容以及物體遮擋等隨機(jī)因素,同時實際應(yīng)用中需要得到快速的響應(yīng),使得快速且精準(zhǔn)定位人臉關(guān)鍵點仍是計算機(jī)視覺中一個非常具有挑戰(zhàn)性的任務(wù)。
目前,絕大多數(shù)人臉關(guān)鍵點定位算法直接使用數(shù)據(jù)集中提供的人臉區(qū)域坐標(biāo),著重針對單張人臉關(guān)鍵點定位,對多人臉情況未作充分考慮,使得實際應(yīng)用中需要定位圖中多個人臉的關(guān)鍵點時,首先需要額外使用人臉檢測網(wǎng)絡(luò)獲得圖片中的人臉區(qū)域坐標(biāo),然后將檢測得到的人臉區(qū)域依次送入關(guān)鍵點定位網(wǎng)絡(luò),最后獲得人臉關(guān)鍵點坐標(biāo)。圖片中人臉數(shù)量增多時會直接導(dǎo)致處理時間成本成倍增加,同時,人臉檢測效果的好壞也會直接影響人臉關(guān)鍵點定位的準(zhǔn)確性。因此,本文提出算法一次性定位圖中所有人臉的關(guān)鍵點,解除了人臉檢測步驟與關(guān)鍵點定位步驟的耦合性,在更短時間內(nèi)檢測更多人臉的關(guān)鍵點。
與直接利用坐標(biāo)回歸關(guān)鍵點的方法不同,本文借鑒了人體姿態(tài)估計算法[5-10]利用熱度圖來回歸人體關(guān)鍵點的思想,采用一個中間監(jiān)督網(wǎng)絡(luò),由粗到精地回歸關(guān)鍵點。本文算法的網(wǎng)絡(luò)結(jié)構(gòu)使用特征金字塔網(wǎng)絡(luò)融合不同尺度的感受野信息,從而充分利用卷積神經(jīng)網(wǎng)絡(luò)淺層與深層的語義特征,減少關(guān)鍵點預(yù)測網(wǎng)絡(luò)中卷積核的使用來減少參數(shù)冗余,使網(wǎng)絡(luò)完成一次前向傳播過程只需要約0.0075s(約每秒133幀),完全滿足了實時人臉關(guān)鍵點定位的需求。本文算法的流程如圖1所示。
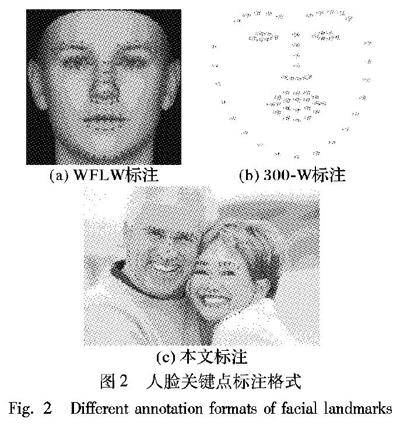
訓(xùn)練與評估數(shù)據(jù)集中的每張圖片中只有部分人臉標(biāo)注有98個關(guān)鍵點,而本文方法是回歸圖中所有人臉的關(guān)鍵點,導(dǎo)致圖中未被標(biāo)注的人臉成為了訓(xùn)練過程中的強(qiáng)烈干擾,所以必須首先對數(shù)據(jù)集作充分的預(yù)處理,即為圖中未被標(biāo)注的人臉生成矩形二進(jìn)制掩碼,在計算網(wǎng)絡(luò)損失前將其與預(yù)測網(wǎng)絡(luò)的輸出進(jìn)行點乘,去除干擾。本文還將人臉標(biāo)注分為上半臉45個關(guān)鍵點與下半臉53個關(guān)鍵點兩部分,如圖2(c),分別采用上、下兩個并行分支與一級中間監(jiān)督網(wǎng)絡(luò),使其達(dá)到更容易、由粗到精地回歸人臉關(guān)鍵點的效果。
1 相關(guān)工作
目前,基于深度學(xué)習(xí)的人臉關(guān)鍵點定位方法主要包含兩種:一是將關(guān)鍵點坐標(biāo)向量作為標(biāo)簽,利用神經(jīng)網(wǎng)絡(luò)建立輸入圖片與人臉關(guān)鍵點坐標(biāo)向量間的映射關(guān)系;二是利用人臉關(guān)鍵點坐標(biāo)生成各類關(guān)鍵點的概率分布熱度圖,建立輸入圖片與關(guān)鍵點熱度圖間的映射關(guān)系,將坐標(biāo)回歸問題轉(zhuǎn)化為熱度圖回歸問題。總體而言,基于熱度圖回歸的模型往往更容易訓(xùn)練,并且可以取得更好的效果。
其中關(guān)鍵點坐標(biāo)回歸這種方法將關(guān)鍵點坐標(biāo)向量作為標(biāo)簽,神經(jīng)網(wǎng)絡(luò)直接學(xué)習(xí)如何將輸入圖片映射為關(guān)鍵點坐標(biāo)向量。多任務(wù)卷積網(wǎng)絡(luò)(Multi-Task Convolutional Neural Network, MTCNN)[11]用三個獨立的神經(jīng)網(wǎng)絡(luò)P-Net、R-Net與O-Net由粗到精地回歸人臉關(guān)鍵點,用P-Net網(wǎng)絡(luò)生成人臉建議框并使用非極大值抑制得到第一階段的候選窗口,將結(jié)果輸入到R-Net網(wǎng)絡(luò),對得到的輸出進(jìn)一步使用非極大值抑制剔除重復(fù)的候選窗口,最后通過O-Net同時輸出人臉區(qū)域坐標(biāo)與五個關(guān)鍵點坐標(biāo)。雖然獨立的多階段網(wǎng)絡(luò)可以使結(jié)果逐漸優(yōu)化,但是數(shù)據(jù)預(yù)處理復(fù)雜,訓(xùn)練過程調(diào)試難度高,較難保證獲得最優(yōu)的結(jié)果。兩步重初始化(Two-Stage Re-initialization, TSR)方法[12]將人臉分為多個部分,分別對每個部分的關(guān)鍵點坐標(biāo)進(jìn)行回歸,降低了輸入圖像特征的復(fù)雜度,卻也忽略了整個人臉區(qū)域的全局關(guān)系。雖然關(guān)鍵點坐標(biāo)回歸方法直接將坐標(biāo)作為數(shù)據(jù)標(biāo)簽,無需作任何的坐標(biāo)預(yù)處理,但是此類方法往往沒有基于熱度圖回歸的方法表現(xiàn)優(yōu)異。
而關(guān)鍵點熱度圖回歸方法對每類關(guān)鍵點生成對應(yīng)的概率分布熱度圖,讓網(wǎng)絡(luò)回歸關(guān)鍵點熱度圖。這類方法在人體姿態(tài)估計[5-10]、人臉關(guān)鍵點定位等計算機(jī)視覺任務(wù)中均取得了非常好的成績。Kowalski等[13]采用級聯(lián)深度神經(jīng)網(wǎng)絡(luò),將整張人臉作為輸入,充分考慮人臉的全局信息,解決了頭部姿態(tài)變化帶來的泛化能力降弱的問題,輸出為人臉關(guān)鍵點熱度圖。Cao等[5]使用圖像分類網(wǎng)絡(luò)提取圖像特征,并級聯(lián)多個7×7大卷積核組成預(yù)測網(wǎng)絡(luò)使其擁有更充足的參數(shù)來更準(zhǔn)確地擬合人體關(guān)鍵點檢測數(shù)據(jù)集。Wu等[14]不僅采用關(guān)鍵點熱度圖回歸方法,而且考慮到人臉部分關(guān)鍵點間具有一定的幾何邊界關(guān)系,同時生成邊界熱度圖來輔助神經(jīng)網(wǎng)絡(luò)對人臉關(guān)鍵點的定位,提升了定位精度。此類方法利用生成的概率分布的關(guān)鍵點熱度圖,巧妙地將坐標(biāo)回歸轉(zhuǎn)化為學(xué)習(xí)關(guān)鍵點坐標(biāo)周圍的概率分布,容許一定的偏差,且建立的是圖像像素矩陣與熱度圖矩陣之間的映射關(guān)系,更契合在圖像識別領(lǐng)域中表現(xiàn)優(yōu)異的卷積神經(jīng)網(wǎng)絡(luò),使網(wǎng)絡(luò)更容易擬合數(shù)據(jù)。
2 本文方法
近年來,深度學(xué)習(xí)方法在各項計算機(jī)視覺任務(wù)中表現(xiàn)出色,基于深度學(xué)習(xí)方法的人臉關(guān)鍵點定位算法在WFLW(Wider Facial Landmarks in-the-Wild)[14]、300-W(300 faces in-the-Wild challenge)[15]、AFLW(Annotated Facial Landmarks in-the-Wild)[16]、COFW(Caltech Occluded Faces in-the-Wild)[17]等數(shù)據(jù)集中也取得了非常出色的成績。同時,數(shù)據(jù)集中標(biāo)注的人臉關(guān)鍵點個數(shù)也日益趨多,CelebA(CelebFaces Attributes dataset) 、300-W[15]和WFLW[14]標(biāo)注的人臉關(guān)鍵點分別是5、68、98,見圖2(a)、(b)。本文采用WFLW[14]數(shù)據(jù)集作為算法的訓(xùn)練集和測試集,為使網(wǎng)絡(luò)更容易地學(xué)習(xí)關(guān)鍵點周圍的概率分布,降低單個預(yù)測網(wǎng)絡(luò)擬合數(shù)據(jù)的難度,將人臉分為上、下兩個部分,見圖2(c),采用兩個并行分支回歸人臉關(guān)鍵點,同時采用一個中間監(jiān)督網(wǎng)絡(luò),驅(qū)使預(yù)測網(wǎng)絡(luò)由粗到精地回歸關(guān)鍵點熱度圖。
2.1 數(shù)據(jù)集預(yù)處理
WFLW數(shù)據(jù)集(來源于Wider Face人臉檢測數(shù)據(jù)集)中有7500張標(biāo)記了98個關(guān)鍵點的人臉作為訓(xùn)練集,2500張人臉作為測試集。本文方法是一次性回歸圖片中所有人臉的關(guān)鍵點,沒有經(jīng)過人臉檢測步驟,導(dǎo)致與WFLW數(shù)據(jù)集的標(biāo)注方式中存在這種矛盾——WFLW中一張圖片中出現(xiàn)多個人臉時,只有其中的一部分人臉被標(biāo)注關(guān)鍵點,這使得未被標(biāo)注的人臉成為網(wǎng)絡(luò)訓(xùn)練時的強(qiáng)烈噪聲,嚴(yán)重影響神經(jīng)網(wǎng)絡(luò)的模型學(xué)習(xí)。為去除這些干擾,本文利用Wider Face數(shù)據(jù)集中的人臉區(qū)域標(biāo)注,將其與WFLW數(shù)據(jù)集中已被標(biāo)注的人臉區(qū)域作差集,獲得未被標(biāo)注的人臉區(qū)域,利用它生成二進(jìn)制掩碼M∈R384×384×1,掩碼M中,在未被標(biāo)注的人臉區(qū)域像素值為0,其余為1,圖3為掩碼效果。實際操作是在網(wǎng)絡(luò)計算損失之前將二進(jìn)制掩碼分別與正確的關(guān)鍵點熱圖和預(yù)測的關(guān)鍵點熱度圖點乘,使噪聲區(qū)域不參與損失計算和反向傳播。通過數(shù)據(jù)標(biāo)簽格式的改變,將單人臉關(guān)鍵點定位轉(zhuǎn)化為多人臉關(guān)鍵點定位。
2.2 關(guān)鍵點熱度圖
為將人臉關(guān)鍵點坐標(biāo)回歸轉(zhuǎn)化為關(guān)鍵點熱度圖回歸,首先對每類人臉關(guān)鍵點生成二維關(guān)鍵點熱度圖C*n,k(p)作為正確標(biāo)簽,即每張熱度圖像素中的數(shù)值代表輸入圖片中第n個人臉的第k個關(guān)鍵點存在于像素點p∈R2的概率,如圖4所示。假設(shè)Xn,k為已標(biāo)注的人臉關(guān)鍵點的坐標(biāo),則C*n,k中像素點p∈R2的數(shù)值可由以下計算式表示:
在WFLW數(shù)據(jù)集中,本文對每張樣本圖片生成了100張48×48分辨率的關(guān)鍵點熱度圖(其中有兩張為其余關(guān)鍵點熱度圖的疊加,無預(yù)測意義,但可形成一定的人臉邊界關(guān)系,類似于邊界熱度圖輔助關(guān)鍵點回歸)作為正確標(biāo)簽,其中每張熱度圖對應(yīng)樣本圖片中全部人臉的其中一類關(guān)鍵點,并將其分成上分支46個與下分支54個分別對應(yīng)圖2(a),上半臉(標(biāo)號:33~75,96~97)與下半臉(標(biāo)號:0~32,76~95)。
為更方便代碼復(fù)現(xiàn),本文提供訓(xùn)練網(wǎng)絡(luò)時使用的硬件設(shè)備參數(shù)。CPU為i7-8700 3.4GHz,內(nèi)存為16GB RAM,顯卡為8GB GTX1080 Graphics。訓(xùn)練時使用Pytorch深度學(xué)習(xí)框架,Adam優(yōu)化器,未設(shè)置正則化,設(shè)置初始學(xué)習(xí)率為0.0001,Batch size為10,迭代120輪后,將學(xué)習(xí)率調(diào)整為0.00001。大約花費一天時間在WFLW數(shù)據(jù)集中迭代了200輪,最后的損失在0.00015左右震蕩,見圖7。從訓(xùn)練損失曲線圖看來,最終,fine效果比coarse的效果更好,表明本文使用的中間監(jiān)督網(wǎng)絡(luò)對后續(xù)預(yù)測網(wǎng)絡(luò)具有一定的優(yōu)化作用。
3.3 評估結(jié)果
在WFLW的2500張人臉測試集中的評估結(jié)果見表1,測試集Testset包括6個子集,分別為Pose、Expression、Illumination、Make-up、Occlusion與Blur。表1中:ESR(Explicit Shape Regression)[20]是通過形狀回歸的方法獲得人臉矯正結(jié)果;SDM(Supervised Descent Method)[21]利用線性模型與尺度不變特征變換(Scale Invariant Feature Transform, SIFT)特征獲得人臉矯正結(jié)果;CFSS(Coarse to Fine Shape Regression)[22]也是通過形狀回歸的方法獲得人臉矯正結(jié)果;LIIV(Leveraging Intra and Inter-dataset Variations)[23]則是利用數(shù)據(jù)集內(nèi)與數(shù)據(jù)集間的某種變化來獲得更好的人臉關(guān)鍵點定位效果。值得說明的是,本文使用的關(guān)鍵點標(biāo)注格式與其他算法有所不同,大多數(shù)算法分為人臉檢測與人臉關(guān)鍵點定位兩個步驟,而本文是直接檢測圖中所有人臉的關(guān)鍵點,這使得本文算法在評估時對人臉的裁取方法有些不同,對預(yù)測結(jié)果有一定影響,但本文算法在多個測試子集中最終取得的平均誤差和錯誤率比表中算法仍均有所降低。
在保持高檢測精度的同時,本文一步到位的定位方法與高效的模型相較于其他算法有更快的檢測速度,如表2所示。表2中:Size指的是模型的大小,Speed指的是處理單張圖片所需時間,Graphics為顯卡。其中SAN(Style Aggregated Network)[24]是利用多階段預(yù)測網(wǎng)絡(luò)檢測人臉關(guān)鍵點的方法。本文提出的算法運行在相對較低級的設(shè)備中的處理速度卻仍能優(yōu)于表中其他對比算法8倍多(文獻(xiàn)[14]算法與SAN均未算上人臉檢測時間)。對于圖中有多張人臉的情況,本文算法可避免多個人臉區(qū)域的多次關(guān)鍵點檢測,而是一步到位,在更短的時間內(nèi)一次性定位更多人臉的關(guān)鍵點,處理時間不受限于人臉數(shù)量。
4 結(jié)語
通過使用二進(jìn)制掩碼去除干擾,改變了人臉關(guān)鍵點數(shù)據(jù)集的標(biāo)注方式,利用殘差網(wǎng)絡(luò)模塊與特征金字塔的特征融合、中間監(jiān)督層建立起網(wǎng)絡(luò)間的前后緊密聯(lián)系,以及卷積神經(jīng)網(wǎng)絡(luò)習(xí)得的細(xì)節(jié)與高級特征,使得算法在保證高定位精度的同時,一次性快速定位圖中所有人臉的關(guān)鍵點。但是缺點也隨之而來,本文提出的網(wǎng)絡(luò)對圖片中小區(qū)域與妝容非常嚴(yán)重的人臉關(guān)鍵點定位的能力還有待提高。在接下來的研究中會對算法作進(jìn)一步優(yōu)化,嘗試通過增大關(guān)鍵點熱度圖的分辨率,數(shù)據(jù)增強(qiáng)中采用跨度更大的縮放因子,訓(xùn)練時使用在線艱難樣本與關(guān)鍵點尋找的技巧,達(dá)到更加精確定位小區(qū)域與妝容嚴(yán)重的人臉的關(guān)鍵點的效果。嘗試運用神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)搜索(Neural architecture search)策略來搜索更優(yōu)的預(yù)測網(wǎng)絡(luò)結(jié)構(gòu)。
參考文獻(xiàn) (References)
[1]SCHROFF F, KALENICHENKO D, PHILBIN J. FaceNet: a unified embedding for face recognition and clustering [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 815-823.
[2]ZHU Z, LUO P, WANG X, et al. Deep learning identity-preserving face space [C]// Proceedings of the 2013 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2013: 113-120.
[3]SUN Y, WANG X, TANG X. Deep learning face representation from predicting 10000 classes [C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2014: 1891-1898.
[4]SUN Y, WANG X, TANG X. Hybrid deep learning for face verification [C]// Proceedings of the 2013 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2013: 1489-1496.
[5]CAO Z, SIMON T, WEI S E, et al. Realtime multi-person 2D pose estimation using part affinity fields [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1302-1310.
[6]OSOKIN D. Real-time 2D multi-person pose estimation on CPU: lightweight OpenPose [EB/OL]. [2019-01-02]. https://arxiv.org/pdf/1811.12004.pdf.
[7]FANG H, XIE S, TAI Y W, et al. RMPE: regional multi-person pose estimation [C]// Proceedings of the 2017 IEEE Conference on Computer Vision. Piscataway: IEEE, 2017: 2353-2362.
[8]LI W, WANG Z, YIN B, et al. Rethinking on multi-stage networks for human pose estimation [EB/OL]. [2019-01-02]. https://arxiv.org/pdf/1901.00148.pdf.
[9]CHEN Y, WANG Z, PENG Y, et al. Cascaded pyramid network for multi-person pose estimation [C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7103-7112.
[10]WEI S E, RAMAKRISHNA V, KANADE T, et al. Convolutional pose machines [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 4724-4732.
[11]ZHANG K, ZHANG Z, LI Z, et al. Joint face detection and alignment using multi-task cascaded convolutional networks [J]. IEEE Signal Processing Letters, 2016, 23(10): 1499-1503.
[12]LV J, SHAO X, XING J, et al. A deep regression architecture with two-stage re-initialization for high performance facial landmark detection [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 3691-3700.
[13]KOWALSKI M, NARUNIEC J, TRZCINSKI T. Deep alignment network: a convolutional neural network for robust face alignment [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2017: 2034-2043.
[14]WU W, QIAN C, YANG S, et al. Look at boundary: a boundary-aware face alignment algorithm [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 2129-2138.
[15]SAGONAS C, TZIMIROPOULOS G, ZAFEIRIOU S, et al. 300 faces in-the-wild challenge: the first facial landmark localization challenge [C]// Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops. Piscataway: IEEE, 2013: 397-403.
[16]KOSTINGER M, WOHLHART P, ROTH P M, et al. Annotated facial landmarks in the wild: a large-scale, real world database for facial landmark localization [C]// Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops. Piscataway: IEEE, 2011: 2144-2151.
[17]BURGOS-ARTIZZU X P, PERONA P, DOLLR P. Robust face landmark estimation under occlusion [C]// Proceedings of the 2013 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2013: 1513-1520.
[18]HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778.
[19]LIN T Y, DOLLR P, GIRSHICK R, et al. Feature pyramid networks for object detection [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 936-944.
[20]CAO X, WEI Y, WEN F, et al. Face alignment by explicit shape regression [J]. International Journal of Computer Vision, 2014, 107(2): 177-190.
[21]XIONG X, DE LA TORRE F. Supervised descent method and its applications to face alignment [C]// Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2013: 532-539.
[22]ZHU S, LI C, LOY C C, et al. Face alignment by coarse-to-fine shape searching [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 4998-5006.
[23]WU W, YANG S. Leveraging intra and inter-dataset variations for robust face alignment [C]// Proceedings of the 2017 IEEE Conference on computer vision and Pattern Recognition Workshops. Piscataway: IEEE, 2017: 2096-2105.
[24]DONG X, YAN Y, OUYANG W, et al. Style aggregated network for facial landmark detection [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 379-388.
XIE Jinheng, born in 1998. His research interests include object detection, face detection and recognition, pose estimation, pedestrian reidentification.
ZHANG Yansheng, born in 1962, associate professor. His research interests include information and communication engineering, image processing.
收稿日期:2019-04-11;修回日期:2019-07-04;錄用日期:2019-07-04。
作者簡介:謝金衡(1998—),男,廣東河源人,主要研究方向:目標(biāo)檢測、人臉檢測與識別、姿態(tài)估計、行人重檢測; 張炎生(1962—),男,湖北天門人,副教授,主要研究方向:信息與通信工程、圖像處理。
文章編號:1001-9081(2019)12-3659-06 DOI:10.11772/j.issn.1001-9081.2019040600
