個人O2O優惠券預測分析
2019-01-10 02:05:54陳浩陽曾誠
物聯網技術 2019年12期
陳浩陽 曾誠
摘 要:為了建立更加完善的特征體系和優化預測模型,提出優化特征工程體系,增加特征值數量,并改進傳統邏輯回歸預測模型,使用GBDT+邏輯回歸的組合模型及XGBoost+邏輯回歸的組合模型達到提高預測精度、提升模型預測能力的目的。實驗結果證明,通過優化特征工程體系和改進預測模型解決O2O優惠券發放這種預測方式可以更準確地預測消費者的消費行為,為優惠券的個性化投放提供可靠的決策支持。
關鍵詞:O2O;特征工程;邏輯回歸;GBDT;XGBoost;預測模型
中圖分類號:TP39文獻標識碼:A文章編號:2095-1302(2019)12-00-04
0 引 言
本課題基于商業O2O優惠券發放問題與機器學習相結合,使用經過特征提取的往期數據訓練數學模型,通過訓練好的數學模型對優惠券核銷二分類問題進行精準預測。隨機投放優惠券這種行為方式不僅會對無需求的用戶造成無意義的干擾,還可能致使商家品牌聲譽降低、營銷成本增高。個性化投放是提高優惠券核銷率的重要技術[1],利用該技術不僅可以讓具有一定偏好的消費者從中獲利,同時還可以使商家獲得更好的營銷效果。數據來源于天池大數據比賽《生活大實惠:O2O優惠券使用預測》,比賽提供O2O相關場景的豐富數據,通過分析建模,精準預測用戶是否會在規定時間內使用相應優惠券。
1 研究背景及意義
O2O是Online To Offline(在線離線/線上線下)的簡稱,是將線下商業機會與線上平臺相結合的一種電商發展方式[2],將線上平臺作為線下消費的前站。為了吸引互聯網用戶在線上瀏覽商業信息,商家采取發送優惠券(團購,如GroupOn)、提供優惠信息、服務(預定,如Opentable)等方式吸引顧客[3]。線下商店推送的消息會被互聯網用戶收到,從而增大網民轉化為自家店鋪線下消費者的幾率。同時店鋪的線下服務可以用于線上攬客,消費者又可以從線上平臺篩選線下服務,并在線結算,店鋪能夠很快達到規模[4]。
該模式最重要的特點是推廣效果可觀,交易流水可跟蹤。O2O作為下一代新興電子商務模式,其使命是把電子商務的效力引入目前消費中占比90%以上的本地消費中去[5-6]。除此之外,線上與線下的對接將打破電商、店商擠兌份額的競爭格局,兩者將化敵為友,相互彌補、相互促進,并且使整體消費市場迎來一個全新發展的局面。
2 研究現狀
很多學者對消費預測問題進行了研究,例如Zhu Zhenfeng等(2018)基于傳統GBDT(Gradient Boosting Decision Tree)算法,提出了一種具有層次化集成的改進預測模型(HGBDT)。該模型通過分析往期商品數據來預測商品未來的銷售趨勢[7]。Jain(2017)等通過使用XGBoost(eXtreme Gradient Boosting)模型來預測和估計歐洲主要藥店的零售額。與傳統的回歸算法相比,XGBoost模型算法性能優于傳統的建模方法[8]。國內學者郭倩(2018)對農村人均生活消費進行預測,運用BP神經網絡對農村居民的人均消費支出進行分析,結合數據擬合和精度檢驗,對農村居民未來三年的生活消費支出進行預測[9]。學者魏艷華(2015)通過對甘肅省農村居民在1978~2011年中支出與收入的數據進行分析,建立以ARIMAX模型為基礎的消費支出預測模型,通過此模型對甘肅省農村居民未來一年的消費支出進行了預測研究[10]。Qiumei Pu使用XGBoost模型對陜西省氣象干旱情況進行預測,分別以人工神經網絡算法和XGBoost算法構建數學模型,預測結果表明XGBoost模型比DLNM和人工神經網絡能更精確地預測SPEI[11]。Junqi Guo等學者在研究青少年身體體質情況時,使用XGBoost算法對每個青少年的身體健康水平進行分類,并通過貝葉斯優化自適應調整參數。實驗結果表明,該模型不僅比現有參考模型具有更高的評估精度,相較于傳統的經驗模型,通過XGBoost模型可以更好地為未來青少年的體質評估提供有效的解決方案[12]。
由上述論述可知,邏輯回歸、GBDT及XGBoost模型早已被用于實際應用中,很多學者在各領域中的研究均使用了這幾種模型和兩兩融合后的模型,預測效果得到顯著提升。在商品預測領域,這些模型在顧客行為和數據挖掘競賽中得到了深度使用[13]。將數學模型引入實際問題進行分析研究已成為預測產業發展走向的一種新的研究方式,并且在實際預測中得到了驗證[14]。
3 研究路線
本文利用天池大數據眾智平臺賽題《生活大實惠:O2O優惠券使用預測》中的真實消費者行為數據進行研究的步驟如下:
(1)對原始數據集中的字段進行解釋、數據探查、數據處理等操作。
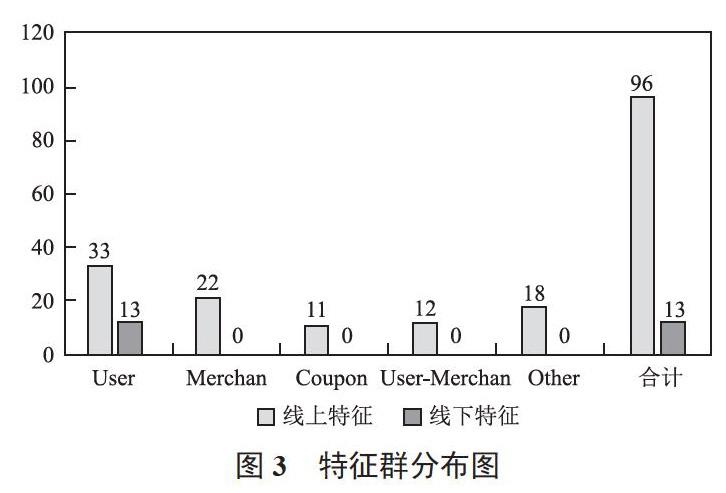
(2)利用特征工程對線下消費和優惠券領取行為數據集構造提取出用戶(User)、商家(Merchan)、優惠券(Coupon)、用戶-商家(User-Merchan)、其他特征(Other)等五大特征群,共96個特征值的線下特征集,再利用特征工程對用戶線上點擊/消費和優惠券領取行為數據集構造提取出13個用戶(User)特征值的線上特征集。
(3)通過線下特征集共96個特征值及線上和線下特征集共109個特征值,構建兩組不同的預測模型。
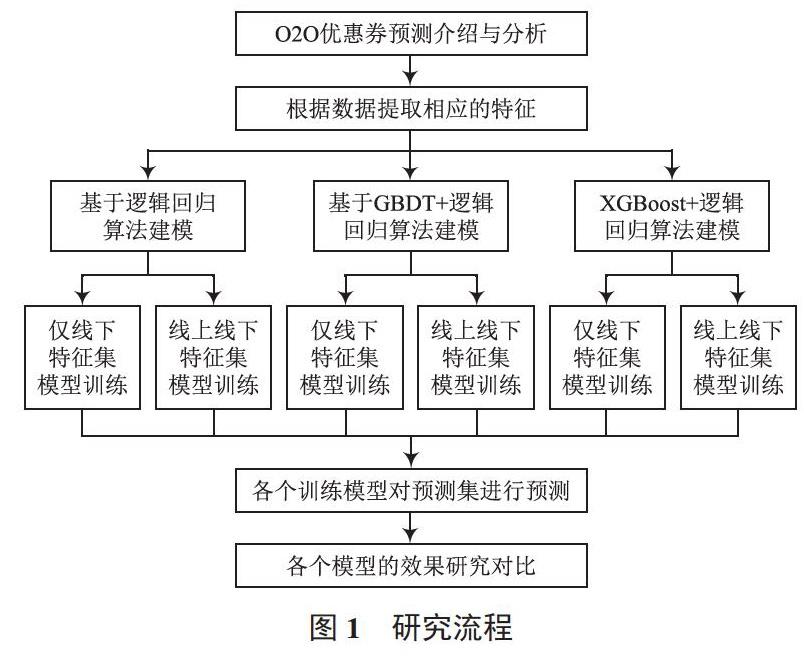
研究流程如圖1所示。
4 數據處理
4.1 數據介紹
根據天池大數據眾智平臺賽題《生活大實惠:O2O優惠券使用預測》提供的相關真實消費數據:2016年1月1日至2016年6月30日,O2O場景相關的消費者線上和線下發生行為數據,通過訓練模型預測2016年7月1日至2016年7月31日消費者領取優惠券后15天內優惠券的核銷情況。
模型預測結果的評判標準:使用數學模型對優惠券預測的概率值取平均AUC值。
賽題共提供4個數據集,分別對4個數據集進行數據分析。
用戶線下消費和優惠券領取行為數據集(后面稱為線下數據集)中共有1 754 884條消費者行為數據,其中1 053 282條數據對優惠券有操作行為,包含539 438個用戶,8 415個商家,9 738種優惠券,消費者領取優惠券的日期為2016年1月1日至2016年6月15日,消費者的消費日期為2016年1月1日至2016年6月30日。
用戶線上點擊/消費和優惠券領取行為數據集(后面稱為線上數據集)中共有11 429 826條數據,其中872 357條數據有優惠券ID,表明消費者對優惠券有操作行為,線上數據集中含762 858個用戶(其中267 448用戶在線下集)。
用戶O2O線下優惠券使用預測集(后面稱為預測集)中包含2 050種優惠券,領取日期為2016年7月1日至2016年7月31日,有76 309個用戶(其中76 307個在線下數據集,35 965個在線上數據集,線上與線下數據集中存在用戶交叉),1 559家商鋪(其中1 558家在用戶線下數據集)。
預測集提交字段和字段說明,選手提交文件字段。其中use_id,coupon_id與date_received均來自數據集,Probability字段為通過機器學習建立數學模型預測得到的預測值。
4.2 特征工程
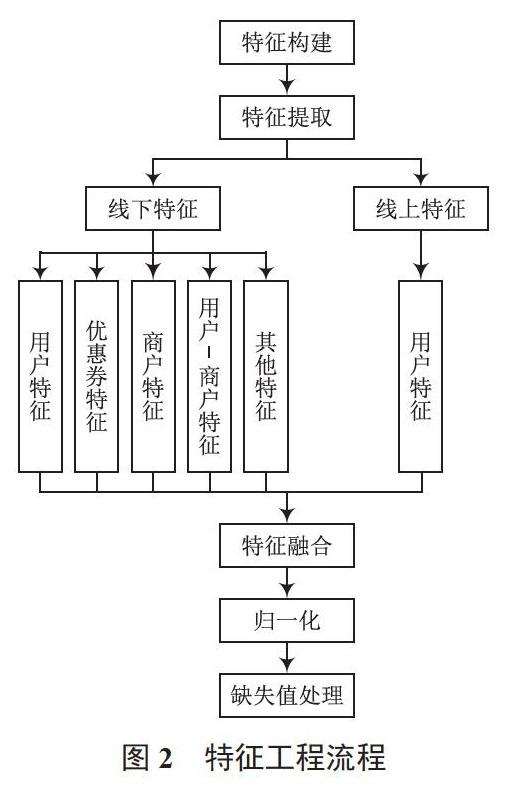
“數據決定了機器學習的上限,而算法只是盡可能逼近這個上限”[15],這句話中數據的含義是對原始數據經特征工程轉換和處理等一系列操作而得到的數據。特征工程流程如圖2所示。
圖3所示為特征群分布情況。
5 算法介紹
本文所使用的算法為邏輯規模,GBDT,XGBoost。
5.1 邏輯回歸
Logistic回歸是一種廣義線性回歸(Generalized Linear Model),它是一個分類算法而不是回歸算法[16]。其核心思想是:線性回歸的輸出結果是一個連續且范圍無法確定的值,如果出現需要利用結果值映射為判斷結果的情況,并且輸出結果是一個概率值,則可通過Sigmoid函數確定,所以Logistic函數又稱Sigmoid函數。Sigmoid函數曲線如圖4所示。
通常情況下,將一個已知的自變量預測成一個離散型因變量的值(如二進制值0/1,對/錯,男/女)。可考慮利用邏輯函數(logit fuction)建立的數學模型對事件發生的概率進行計算,得到一個預估值。而該預估值一般為概率值,因此輸出結果值在0~1范圍內。
5.2 GBDT
GBDT(Gradient Boosting Decision Tree)是一種基于迭代構造的決策樹算法,該算法是將決策樹賦予集成算法思想得到的一種數學模型。回歸決策樹、Gradient Boosting與縮減共同組成了GBDT模型[1]。
5.2.1 回歸決策樹
GBDT模型中的決策樹為回歸決策樹,而非分類決策樹。回歸決策樹可預測數值,如員工薪金、大樹高度等,對回歸樹得到的數值進行加減計算是有意義的,例如12歲+4歲-4歲=12歲,而這也是回歸樹區別于分類樹的一個顯著特征。GBDT正是利用回歸樹得到數值的性質,匯總所有樹的結果,從而輸出最終結果。
5.2.2 梯度上升
“Boosting”意為迭代,迭代多棵樹對結果值進行共同決策[17]。采用弱學習器的結論進行綜合評判,進而得到GBDT模型。整個過程采用增量思想對每個弱學習器進行累加。
5.2.3 縮減
縮減(Shrinkage)的思想:逐漸逼近實際結果值,該操作方式比快速逼近結果值的方式更容易降低出現過擬合的概率。因為每一個殘差弱學習器只學到了真理的一小部分,并且都有可能出現過擬合現象,但在這個學習過程中增加弱學習器的數量,使用多個弱學習器進行學習可以彌補上述不足。
5.3 XGBoost
GBDT算法的運行往往要生成一定數量的樹才能達到令人滿意的準確率。當面對的數據集結果較為龐大且復雜時,可能需要進行上千次迭代運算,還會造成一定的計算瓶頸,并增加計算空間的消耗。華盛頓大學的陳天奇博士研發出的XGBoost(eXtreme Gradient Boosting)解決了這一技術難點,此算法基于Gradient Boosting Machine框架,并使用c++實現,從而極大地提升了模型訓練速度和預測精度[18]。
XGBoost是一個優化的分布式梯度增強庫,作為GBDT模型的升級版,集高效性、靈活性和便攜性等特點于一身。利用XGBoost模型可以在較短周期內解決數據科學問題,得到較高精度的實驗結果。利用XGBoost算法構建的數學模型單臺機運行速度比當下使用的數學模型訓練速度快十倍以上,并且當分布式模式或內存設置需要限制時仍可獲得較為準確的實驗結果。
6 實驗結果
6.1 評判標準
在一些二分類問題中給出預測結果的同時也會給出相應的預測概率,例如假定0.6為正確的判定閾值,那么若預測概率大于0.7,則判定為正確值,否則為錯誤值;若閾值降低到0.5,則可以判斷出更多的正確值。數據中正確數占比提高的同時,也導致實際為真實值但判定為錯誤值的數量的升高。為了直觀表示該變化,引入ROC(Receiver Operating Characteristic Curve)。ROC曲線的橫坐標為FPR,縱坐標為TPR,ROC曲線下的面積即為AUC[19]。
6.2 實驗結果分析
通過提取特征數量和不同模型兩個角度總結實驗。
6.2.1 從特征數量分析實驗結果
通過圖5可以看到,邏輯回歸、GBDT+邏輯回歸融合模型、XGBoost單模型僅含受線下特征集訓練后的預測效果,沒有經線下和線上特征訓練后模型的預測效果好。說明特征數量適量增加可以提升數學模型的預測能力和實驗效果。
6.2.2 從模型的角度分析實驗結果
經過線上和線下特征模型訓練,XGBoost模型的預測效果最好,GBDT+邏輯回歸模型的效果次之,邏輯回歸模型的預測效果相對較差。在經線下模型的特征模型訓練后,GBDT+邏輯回歸模型的預測效果最好,XGBoost模型的預測效果次之,邏輯回歸模型的預測效果相比較差。說明先利用訓練完成的GBDT模型輸出邏輯回歸模型訓練所需要的實驗結果和實驗結果值,再將這些實驗結果和實驗結果值作為訓練邏輯回歸模型的特征值輸入到邏輯回歸模型中進行學習后,預測效率得到明顯提高。但總體來說,GBDT+邏輯回歸,XGBoost模型對此課題的預測有較好的準確性和穩定性。并且使用GBDT+邏輯回歸模型比傳統邏輯回歸模型有更好的預測效果、更高的預測精度。GBDT+邏輯回歸,XGBoost模型是比較理想的消費預測研究模型。圖6所示為不同模型對比預測集提交測試AUC值。
7 結 語
本論文研究基于簡單的集成模型,以O2O優惠券為數據載體對消費者領取優惠券(15天內)后對優惠券是否核銷進行了精確預測。采用簡單的集成學習模型預測用戶在領取優惠券后15天內的使用情況。
除此之外,對于大量往期數據,實際數據中無實際特征可直接使用,但這些數據中含有大量可以提取的特征,所以如何科學合理地利用應用特征工程是一個重點問題。如果沒有合理的特征工程,將極大地限制數學模型預測精度的提高。
在科技越來越發達的今天,數學模型已被大量用于醫療、餐飲、工業等領域,比如在醫學中使用數學模型對人體檢測數據進行掃描,使用數學模型預測餐飲店中的消費人數等。通過這種方式,精確預測行業運營及行業日常的管理對于后期事物的良性發展具有重要意義。
參 考 文 獻
[1] Keepreder. GBDT(MART) 迭代決策樹入門教程 | 簡介[OL]. https: //blog.csdn.net/keepreder/article/details/47259241
[2]朱妮.大數據時代下O2O營銷模式創新研究[J].電子商務,2019(3):42-43.
[3]劉赟.我國實體零售業O2O模式轉型發展分析[J].商業經濟研究,2017(2):17-20.
[4]林曉丹,宋驍.O2O團購商業模式發展現狀及對策淺析[J].中國管理信息化,2015,18(11):181-182.
[5]劉欣梅.O2O:本地生活服務業電子商務發展之路探究[J].經濟研究導刊,2014(1):103-104.
[6]吳鵬飛.基于大數據的O2O營銷模型研究[J].財訊,2017(5):91-92.
[7] ZHU Z F,TANG J Y,CHANG D X,et al. GBDT based hierarchical model for commodity distribution prediction [J]. Journal of Beijing Jiaotong University,2018,42(2):9.
[8] JAIN A,MENON MN,CHANDRA S.Sales Forecasting for Retail Chains [Z]. 2017.
[9]郭倩,王效俐.基于BP神經網絡的農村人均生活消費預測[J].商業經濟,2018(2):80-83.
[10]魏艷華,王丙參.基于ARIMAX模型的甘肅農村居民消費預測與決策[J].天水師范學院學報,2015,35(2):3-7.
[11] ZHANG R,CHEN Z Y ,XU L J,et al.Meteorological drought forecasting based on a statistical model with machine learning techniques in Shaanxi province [J]. Science of the total environment,2019:338-346.
[12] GUO J Q, DAI Y Z, WANG C X,et al.A data-driven framework for learners cognitive load detection using ECG-PPG physiological feature fusion and XGBoost classification [Z].
[13]葉倩怡.基于XGBoost方法的實體零售業銷售額預測研究[D].南昌:南昌大學,2016.
[14]中國信息化編輯部.2018實體經濟與數字經濟在融合中發展[J].中國信息化,2019(1):16-37.
[15]佚名.自動化技術、計算機技術[J].中國無線電電子學文摘,2011,27(2):166-241.
[16]單麗莉,林磊,孫承杰.基于異構信息融合的廣告響應預測方法[J].中國科學:信息科學,2019,49(1):17-41.
[17]劉高軍,李越洋.基于借閱信息的圖書個性化推薦算法研究[J].數字技術與應用,2017(3):156-158.
[18] CHEN T,GUESTRIN C.XGBoost:A scalable tree boosting system [Z]. 2016.
[19]雷一鳴,趙希梅,王國棟,等.基于一種改進的LBP算法和超限學習機的肝硬化識別[J].計算機科學,2017,44(10):45-50.
