一種受限玻爾茲曼機的詞義消歧方法
2019-01-14 02:31:21張春祥李海瑞高雪瑤
哈爾濱理工大學學報 2019年5期
張春祥 李海瑞 高雪瑤
摘 要:針對漢語一詞多義現象,根據上下文所蘊含的語言學知識,采用受限玻爾茲曼機(restricted boltzmann machine,RBM)來確定歧義詞匯的真實含義。選取歧義詞匯左右鄰接的四個詞單元中的詞形、詞性和語義類作為消歧特征。同時,使用RBM來構建詞義消歧模型。結合SemEval-2007: Task#5的訓練語料和哈爾濱工業大學的語義標注語料來優化RBM的參數。利用SemEval-2007: Task#5的測試語料對詞義消歧模型進行測試。實驗結果表明:相對于貝葉斯詞義消歧分類器而言,受限玻爾茲曼機詞義消歧方法的消歧準確率有所提高。
關鍵詞:受限玻爾茲曼機;消歧特征;詞義消歧;訓練語料
DOI:10.15938/j.jhust.2019.05.019
中圖分類號: TP391.2
文獻標志碼: A
文章編號: 1007-2683(2019)05-0116-06
Abstract:For polysemy phenomenon in Chinese, Restricted Boltzmann Machine (RBM) is adopted to determine the true meaning of ambiguous vocabulary where linguistic knowledge in context is used. Word form, part of speech and semantic categories in four left and right lexical units adjacent to an ambiguous word are selected as disambiguation features. At the same time, RBM is used to construct word sense disambiguation (WSD) model. Training corpus in SemEval-2007: Task#5 and semantic annotation corpus in Harbin Institute of Technology are used to optimize parameters of RBM. Test corpus in SemEval-2007: Task#5 is used to evaluate WSD model. Experimental results show that compared with Bayesian word sense disambiguation classifier, disambiguation accuracy of WSD method with RBM is improved.
0 引 言
詞義消歧是計算語言學領域的關鍵性研究課題。近年來,隨著文本數量的激增,自動判別詞語的含義有著越來越廣泛的需求。針對這一問題,國內外許多學者開展了大量的研究。
高雪霞[1]針對詞義錯誤配對問題,提出了基于Jaccard系數的詞義消歧算法,利用WordNet知識庫中的知識源來表示歧義詞的詞義信息并生成詞義資源庫。同時,結合提出的基于Jaccard系數詞義消歧算法來完成信息檢索。楊陟卓[2]提出了一種基于上下文翻譯的有監督詞義消歧方法,將由譯文所組成的上下文當作偽訓練語料,并利用真實訓練語料和偽訓練語料共同確定歧義詞的詞義。陳浩[3]提出了一種基于語言模型的無指導詞義消歧方法,在基于術語抽取的基礎上,使用基于統計的語言模型來提高消歧性能。史兆鵬[4]提出了一種多特征詞義消歧方案,通過依存句法分析提取上下文中多義詞及義項的詞性、依存結構和依存詞特征。同時,細化特征粒度,根據多特征構造權值函數,選擇權值最大的義項作為多義詞的義項。李冬晨[5]將句法分析與詞義消歧相結合。根據層次化語義知識的句法分析框架,并利用句法結構信息對文法模型進行調整。同時,給出了一種句法分析和詞義消歧一體化方法。閆蓉[6]提出了一種上下文邊界可變的中文詞義消歧模型。通過分詞來調整消歧上下文邊界,構建多義詞義項搭配庫,來計算詞語之間的語義相關度。錢濤[7]提出了一種基于超圖的詞義歸納模型。首先根據詞匯鏈來發現目標單詞的上下文實例之間的高階語義關系;然后使用上下文實例表示結點,利用詞匯鏈發現超邊以構建超圖;最后使用基于最大密度超圖譜聚類算法來發現詞義。王少楠[8]將出現在歧義詞上下文語境中有明確含義的實詞作為模型的輸入。在上下文中,獲取可以表示歧義詞詞義的其它特征。利用貝葉斯模型來整合這兩種信息,共同實現歧義詞的詞義表示和歸納。張仰森[9]針對中文文本語義錯誤,提出了一種基于語義搭配知識庫和證據理論的語義錯誤偵測模型。利用知網來提取詞語搭配的語義信息,使用詞語搭配聚合度來進行輔助過濾。同時,利用證據理論來判定語義搭配錯誤。Ivan[10]提出了一種特定領域的詞義消歧方法。該方法使用了特定領域的測試語料庫和特定領域的輔助語料庫。通過抽取相關詞語來獲得特定領域的輔助語料庫。Koppula[11]提出了一種基于圖的詞義消歧方法。使用詞匯知識庫來構建無向圖模型,利用頁面排序算法和隨機游走算法來進行詞義消歧。Iacobacci[12]研究了如何利用詞語嵌入來進行詞義消歧。將詞語嵌入應用于有監督詞義消歧之中,并深入分析了不同參數對性能的影響。Bennett[13]分析了現有的語義分布學習方法,統計語義頻率,生成了一個大規模的語義數據集。Henderson[14]以分布式語義為基礎提出了一個向量空間模型,使用邏輯向量代替消歧特征,利用半監督方法進行詞義消歧。唐共波[15]將知網(HowNet)中表示詞語語義的義原信息融入到語言模型的訓練中,利用義原向量對多義詞進行向量化表示,并將其應用于詞義消歧。通過義原向量對詞語進行向量化表示,實現了詞語語義特征的自動學習,提高了特征學習效率。
本文將歧義詞左右鄰接的4個詞單元的詞形、詞性和語義類作為消歧特征,將受限玻爾茲曼機作為消歧模型,提出一種基于RBM的詞義消歧方法來判別歧義詞的語義類別。
1 消歧特征的選擇
大多數的文本中存在著一詞多義[16]的現象,這種現象給機器翻譯帶來了很大的困擾。只有先判別歧義詞的真實語義,才能對文本進行有效快速的分類和翻譯。在消歧過程中,結合相關的語言學知識,根據歧義詞所在的上下文語境中的消歧特征可以有效地判別歧義詞的真實含義。因此,消歧特征對于語義分類而言將是至關重要的。
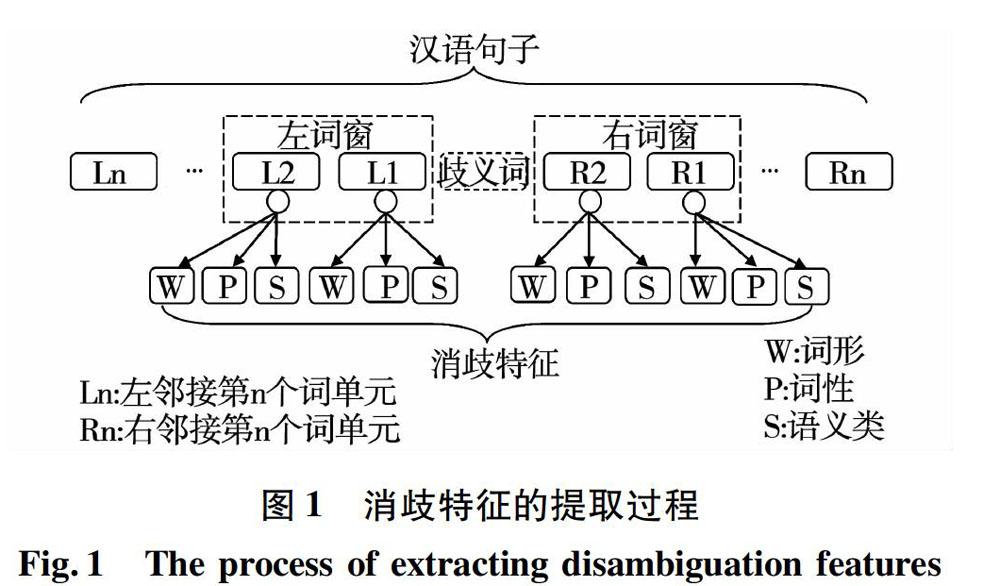
本文以歧義詞為中心,使用左右詞窗來提取上下文中的語言學信息作為消歧特征。消歧特征的提取過程如圖1所示。在左右詞窗中,分別包含了兩個鄰接的詞單元。選取左右詞窗中的詞形(w)、詞性(p)和語義類(s)作為消歧特征,來判別歧義詞的語義類別。
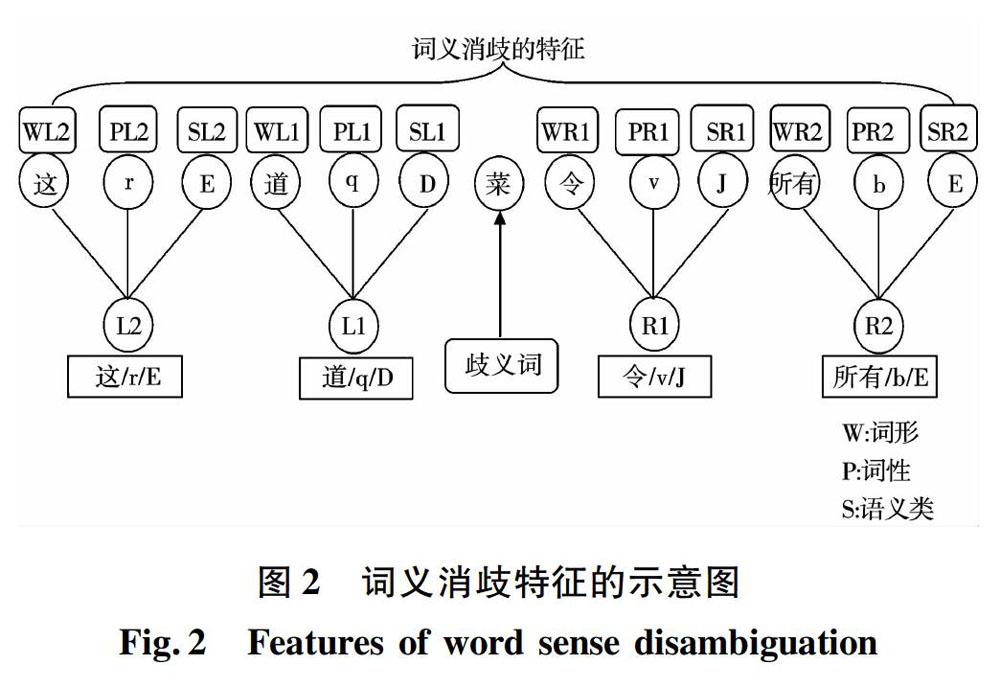
歧義詞“菜”具有兩種語義類別,分別是“dish”和“vegetable”。以包含歧義詞“菜”的漢語句子為例,來說明消歧特征的選取過程。
漢語句子:“在廚師大賽上,他完成的這道菜令所有評委都贊口不絕。”。
對該漢語句子進行分詞處理,其結果如下所示:
分詞結果:“在 廚師 大賽 上 , 他 完成 的 這 道 菜 令 所有 評委 都 贊口不絕 。”。
以該漢語句子的分詞結果為基礎,標注出每個單詞的詞性,其結果如下所示:
詞性標注結果:“在/p 廚師/n 大賽/n 上/nd,/wp 他/r 完成/v 的/u 這/r 道/q 菜/n 令/v 所有/b 評委/n 都/d 贊口不絕/i 。/wp”。
根據《同義詞詞林》,標注出每個單詞的語義類別[17],其結果如下所示:
語義類標注結果:“在/p/K 廚師/n/A 大賽/n/H 上/nd/C ,/wp/-1 他/r/A 完成/v/I 的/u/K 這/r/E 道/q/D 菜/n/B 令/v/J 所有/b/E 評委/n/D 都/d/K 贊口不絕/i/K 。/wp/-1”。
以歧義詞“菜”為中心,開設長度為2的左右詞窗,獲得了歧義詞左右鄰接的4個詞單元。它們分別是:“這/r/E”、“道/q/D”、“令/v/J”、“所有/b/E”。從每個詞單元中,抽出詞形、詞性和語義類作為消歧特征。詞形特征分別為:“這”、“道”、“令”和“所有”;詞性特征分別為:“r”、“q”、“v”和“b”;語義類特征分別為:“E”、“D”、“J”和“E”。此處,共得到了12個消歧特征,分別為:這、r、E、道、q、D、令、v、J、所有、b、E。
從該實例中所提取的詞義消歧特征如圖2所示。12個詞義消歧特征分別為:wL2、pL2、sL2、wL1、pL1、sL1、wR1、pR1、sR1、wR2、pR2、sR2。
2 基于受限玻爾茲曼機的消歧過程
受限玻爾茲曼機是一種隨機遞歸的神經網絡[18],具有接收輸入數據集并學習其概率分布的功能。RBM有兩層,一層是可視層,另一層是隱藏層[19]。每層都由若干個神經元組成,每個神經元取1或0兩種狀態。其中,狀態1表示激活狀態;狀態0表示關閉狀態。在同一層中,神經元之間是相互獨立的。在不同層中,神經元相互之間處于連接狀態。因此,每個神經元的激活條件是相互獨立的。
RBM可以作為多種深度學習網絡的基本組成單元[20]。在降維、分類和特征學習中,RBM有著廣泛的應用。通常,使用監督學習方法來訓練RBM的相關參數。
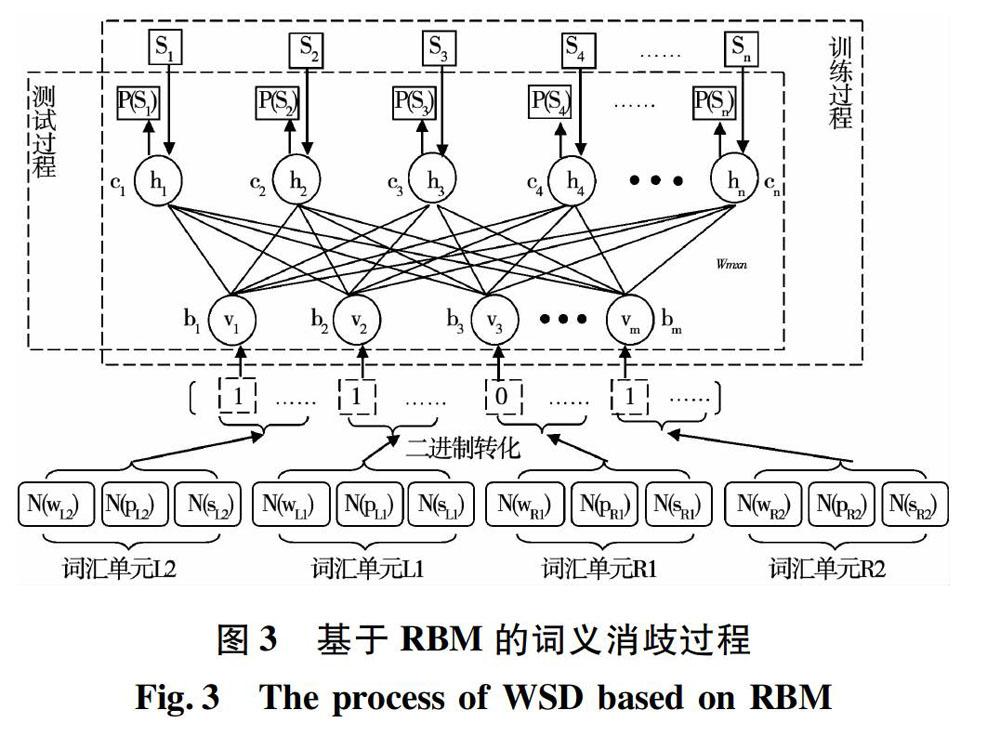
在哈爾濱工業大學人工語義標注語料中,每個漢語句子都進行了分詞、詞性標注和語義標注處理。從語義標注語料中,分別提取詞形、詞性和語義類。分別構造詞形表、詞性表和語義類表。在詞形表中,每個單詞都有唯一的序號;在詞性表中,每個詞性都有唯一的序號;在語義類表中,每個語義類都有唯一的序號。選取歧義詞的左右鄰接四個詞單元的詞形、詞性和語義類作為消歧特征。從詞形表、詞性表和語義類表中,可以得到消歧特征所對應的序號(N)。這些序號構成了消歧特征向量Feature。
本文使用RBM來對歧義詞進行語義分類。基于RBM的詞義消歧框架如圖3所示。在圖3中,v={v1, v2, …, vm}表示RBM可視層中的m個神經元,h={h1, h2, …, hn}表示RBM隱藏層中的n個神經元。Wm×n表示連接可視層與隱藏層之間的權值矩陣。參數b={b1, b2, …, bm}和c={c1, c2, …, cn}為RBM的偏移量。Feature={N(wL2), N(pL2), N(sL2), N(wL1), N(pL1), N(sL1), N(wR1), N(pR1), N(sR1), N(wR2), N(sR2), N(sR2)}作為受限玻爾茲曼機的消歧特征向量。
在訓練過程中,輸入消歧特征向量Feature={N(wL2), N(pL2), N(sL2), N(wL1), N(pL1), N(sL1), N(wR1), N(pR1), N(sR1), N(wR2), N(sR2), N(sR2)}和所對應的語義類S={S1, S2, …, Sn}。經過k次訓練后,可以得到RBM的優化參數,即權重矩陣Wm×n、偏移量b={b1, b2, …, bm}和c={c1, c2, …, cn}。在測試過程中,輸入消歧特征向量Feature={N(wL2), N(pL2), N(sL2), N(wL1), N(pL1), N(sL1), N(wR1), N(pR1), N(sR1), N(wR2), N(sR2), N(sR2)}。優化后的RBM將輸出歧義詞在每個語義類下的概率分布。對于歧義詞匯而言,它有n種語義類別S1, S2, …, Sn。基于RBM的詞義消歧模型的輸出結果為概率分布P(S1), P(S2), …, P(Sn)。
3 基于RBM的詞義消歧模型訓練
在訓練過程中,RBM的神經元只能接收0或1形式的二進制數。因此,需要將訓練數據轉換成二進制數。訓練數據包括消歧特征向量(Feature)和語義類(S)兩個部分。
Feature和S轉化為二進制數的過程如圖4所示。在圖4中,Ni(wL2)表示Feature的第i個特征向量中左側鄰接的第2個詞單元的詞形特征序號;Ni(pL2)表示Feature的第i個特征向量中左側鄰接的第2個詞單元的詞性特征序號;Ni(sL2)表示Feature的第i個特征向量中左側鄰接的第2個詞單元的語義類特征序號。Sij表示第i個特征向量所對應的語義類。
在圖4中,Feature和S經過二進制轉換,得到了圖中右側的標準消歧特征向量(S_Feature)和標準語義類(S_S)。在標準消歧特征向量中,共有n個特征向量,每個特征向量用m位二進制數來表示。在標準語義類中,共有n個特征向量,每個特征向量用n位二進制數來表示。因此,標準消歧特征向量為n×m階的二值矩陣,標準語義類為n×n階的二值矩陣。
本文改進了對比散度(contrastive divergence,CD)算法[21],并對基于RBM的詞義消歧模型進行訓練。
4 實 驗
在實驗中,所使用的訓練數據和測試數據選自于SemEval-2007: Task#5的訓練語料和測試語料。SemEval-2007: Task#5是ACL2007的一個組成部分,即SemEval-2007國際語義評測的中英文詞匯任務。該任務共包含40個歧義詞,從中選取18個常見的歧義詞。所選取歧義詞的訓練語料和測試語料分布如圖5所示。
為了度量本文所提出方法的性能,共進行了兩組實驗。在第1組實驗中,選取歧義詞左右鄰接的兩個詞單元的詞形作為消歧特征,使用貝葉斯消歧模型來判別歧義詞的語義。使用SemEval-2007: Task#5的訓練語料對貝葉斯消歧模型進行訓練。利用優化后的貝葉斯消歧模型對SemEval-2007: Task#5的測試語料進行詞義消歧。
在第2組實驗中,選取歧義詞左右鄰接的四個詞單元的詞形、詞性和語義類作為消歧特征,利用RBM消歧模型來判別歧義詞的語義。使用SemEval-2007: Task#5的訓練語料,結合詞形表、詞性表和語義類表來獲得消歧特征向量Feature。將消歧特征向量Feature轉換成標準消歧特征向量。同時,將該特征向量所對應的語義類轉換為標準語義類。使用標準消歧特征向量和標準語義類對RBM消歧模型進行訓練。使用優化后的RBM對SemEval-2007: Task#5的測試語料進行語義分類。兩組實驗的消歧準確率如表1所示。
為了更清楚地比較兩組實驗的消歧性能,根據表1畫出了兩組實驗的折線圖來對比它們的消歧精確率,如圖6所示。
從圖6可以看出,RBM詞義消歧分類器的準確率要高于貝葉斯詞義消歧分類器。其原因是:在第1組實驗中,只選取了詞形一種消歧特征。在第2組實驗中,選取了詞形、詞性和語義類3種消歧特征,能夠覆蓋更多的語言學現象。此外,RBM的分類性能要強于貝葉斯模型。
5 結 論
本文提出了一種受限玻爾茲曼機的詞義消歧方法。以歧義詞左右相鄰的四個詞單元的詞形、詞性和語義類為消歧特征,使用RBM分類器來判別歧義詞的語義類。使用SemEval-2007:Task#5的訓練語料結合哈爾濱工業大學的語義標注語料來優化受限玻爾茲曼機的參數,以提高詞義消歧精度。使用優化后的RBM分類器對SemEval-2007:Task#5的測試語料進行詞義消歧。實驗結果表明:所提出方法的詞義消歧性能要優于貝葉斯分類器。
參 考 文 獻:
[1] 高雪霞, 炎士濤. 基于WordNet詞義消歧的語義檢索研究[J]. 湘潭大學自然科學學報, 2017, 39(2): 118.
[2] 楊陟卓. 基于上下文翻譯的有監督詞義消歧研究[J]. 計算機科學, 2017, 44(4): 252.
[3] 陳浩. 基于統計語言模型的無導詞義消歧[J]. 電腦知識與技術, 2015(1): 178.
[4] 史兆鵬, 鄒徐熹, 向潤昭. 基于依存句法分析的多特征詞義消歧[J]. 計算機工程, 2017, 43(9): 210.
[5] 李冬晨, 張獻濤, 樊揚, 等. 融合詞義消歧的漢語句法分析方法研究[J]. 北京大學學報(自然科學版), 2015, 51(4): 577.
[6] 閆蓉, 高光來. 上下文邊界可變的詞義消歧[J]. 計算機工程與設計, 2015(10): 2843.
[7] 錢濤, 姬東鴻, 戴文華. 一個基于超圖的詞義歸納模型[J]. 四川大學學報(工程科學版), 2016, 48(1): 152.
[8] 王少楠, 宗成慶. 一種基于雙通道LDA模型的漢語詞義表示與歸納方法[J]. 計算機學報, 2016, 39(8): 1652.
[9] 張仰森, 鄭佳. 中文文本語義錯誤偵測方法研究[J]. 計算機學報, 2017, 40(4): 911.
[10]IVAN L A, VICTOR J S S, FRANCO R L, et al. Improving Selection of Synsets from WordNet for Domain-specific Word Sense Disambiguation[J]. Computer Speech & Language, 2017, 41(1): 128.
[11]KOPPULA N, RANI B P, RAO K S. Graph Based Word Sense Disambiguation[J]. Advances in Intelligent Systems and Computing, 2017, 507(1): 665.
[12]IACOBACCI I, PILEHVAR M T, NAVIGLI R. Embeddings for Word Sense Disambiguation: An Evaluation Study[C] // Proceedings of the 54th Annual The Meeting of the Association for Computational Linguistics. 2016: 897.
[13]BENNETT A, BALDWIN T, LAU J H, et al.LexSemTm: A Semantic Dataset Based on All-words Unsupervised Sense Distribution Learning[C] // Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. 2016: 1513.
[14]HENDERSON J, POPA D N. A Vector Space for Distributional Semantics for Entailment[C] // Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2016: 2052.
[15]唐共波, 于東, 荀恩東. 基于知網義原詞向量表示的無監督詞義消歧方法[J]. 中文信息學報, 2015, 29(6): 23.
[16]張春祥, 鄧龍, 高雪瑤, 等. 結合語義知識的漢語詞義消歧[J]. 計算機工程與應用, 2016, 52(3): 119.
[17]李國臣, 呂雷, 王瑞波, 等. 基于同義詞詞林信息特征的語義角色自動標注[J]. 中文信息學報, 2016, 30(1): 101.
[18]LU N, LI T, REN X, et al.A Deep Learning Scheme for Motor Imagery Classification based on Restricted Boltzmann Machines[J]. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 2017, 25(6): 566.
[19]劉明珠, 鄭云非, 樊金斐, 等. 基于深度學習法的視頻文本區域定位與識別[J]. 哈爾濱理工大學學報, 2016, 21(6): 61.
[20]呂淑寶, 王明月, 翟祥, 等. 一種深度學習的信息文本分類算法[J]. 哈爾濱理工大學學報, 2017, 22(2): 105.
[21]MA X, WANG X. Average Contrastive Divergence for Training Restricted Boltzmann Machines[J]. Entropy, 2016, 18(2): 35.
(編輯:溫澤宇)
