基于修辭結構理論的多模態語料庫研究
2019-01-15 08:03:24張培佳馮德正
當代修辭學 2018年2期
張培佳 馮德正
(香港理工大學英文系,香港)
提 要 多模態語篇分析發展到今天,面臨的主要挑戰是缺乏基于大量語料的實證研究,尤其是對平面媒體圖文語篇的語料庫研究。究其原因是圖文語篇的多維特性導致多模態語料庫的標注難度極大。而以修辭結構理論為重要基礎的GeM模型是現有標注圖文語料最系統的理論框架。本文以流程圖的方式展示了GeM模型的應用步驟,以公共衛生海報語料庫為例演示了修辭結構的XML標注,并介紹借助計算工具gem-tools實現自動生成修辭結構圖、統計語料庫數據、檢索修辭關系等多模態語料庫研究的基本方法,以期為國內學者進行多模態語料庫建設與實證研究提供有效的理論與方法。
一、 引 言
多模態語篇分析自20世紀90年代興起以來,研究者們已從社會符號學、互動分析、會話分析、語用學等不同角度出發構建理論框架和探索分析方法,但在理論建設和研究方法上仍有諸多局限,其面臨的主要挑戰是缺乏實證研究(Bateman 2014b;Batemanetal. 2017)。多模態語篇分析沿襲了語篇分析、會話分析等學科的理論驅動的闡釋性方法(hermeneutic method),而非語料驅動的分析方法。研究者們通常是提出一個理論框架,然后選取幾個典型例子證明理論的可操作性,語料起輔助作用。但一方面理論需要在真實的語料中驗證,另一方面質性文本分析中語料的代表性與分析結論的普適性受到局限(Bateman 2014b:238)。Bateman(2014b:238)進一步指出,在多模態理論創始階段,用個別例子演示分析框架是非常必要的。然而,隨著多模態研究的發展,研究者亟需通過大量真實的語料來驗證、評估多模態理論是否具有普適性。從語用學的角度,黃立鶴(2017:27)同樣指出,多模態語料庫的方法可以為語用研究增加定量分析的客觀性,從較大程度上彌補傳統語用研究的不足。因此,只有更廣泛地引入語料庫方法,更充分地利用數據科學,才能對日趨復雜的多模態語篇進行全面而深入的分析,保證多模態研究不斷向縱深發展。
多模態語料是指包含文字、圖像、副語言特征、表情、手勢等復雜表意的資源(詹姆斯·馬丁、米歇爾·扎帕維尼婭2018),大致可分為實時性和非實時性(real-time/non-real-time)兩類(Matthiessen 2009)。國內外多模態領域已認識到系統化語料庫建設與研究的重要性,但很多研究只是解釋標注方法,真正意義上的多模態語料庫標注與研究寥寥無幾。同時,大部分研究關注的是視頻形式的實時性語料(自然會話/即席話語),從會話分析或語用學視角基于時間軸對語言、副語言特征、肢體語言等進行標注(Adolphs & Carter 2013;Allwoodetal. 2003),而很少有對廣告、漫畫等具有明顯修辭設計的非實時性平面媒體語篇的實證分析。究其原因是實時性語料沿用了會話分析等學科對副語言特征、手勢等比較成熟的標注方法(Goodwin 1981;Schegloff 1984),而平面媒體的語篇特征,如語義關系、表達方式等,則沒有系統的標注框架可以綜合分析。這方面,體裁與多模態(Genre and Multimodality,GeM)模型(Bateman 2008)作為第一個多層描述分析多模態語篇的框架,為標注平面媒體語篇提供了有效工具。然而,該框架尚未被廣泛應用于多模態語料庫研究。目前已建成的GeM標注語料庫只有三例,即Thomas(2009)標注的英國和中國臺灣的牙膏、洗發水等日用品包裝,Hiippala(2015b)標注的赫爾辛基旅游宣傳冊與Zhang(2017)標注的紐約和中國香港的公共衛生海報。本文首先介紹GeM模型并討論為何修辭結構的分析是多模態語料庫建設的重要層次,著重闡述如何將修辭結構理論(Rhetorical Structure Theory,RST)(Mann et al. 1992;Mann & Thompson 1988)擴展應用于非實時性多模態語篇分析。隨后,本文以公共衛生海報語料庫(Zhang 2017)為例,演示如何使用可擴展標記語言(eXtensible Markup Language,XML)標注平面圖文語篇的修辭結構、如何利用計算工具gem-tools(Hiippala 2015a)進行GeM標注語料庫研究。最后,本文在展示基于GeM模型應用RST構建多模態語料庫的基礎上,討論此類標注語料庫對多模態研究的優勢以及未來發展的挑戰。
二、 多模態語料庫建設:GeM模型與RST
John Bateman等人于1999至2002年期間在斯特靈大學和不萊梅大學成立GeM項目組,開發一個旨在從多模態體裁的角度來解釋多模態語篇視覺風格(包括版式、排印等)上的一致性與多樣性的框架,即GeM模型。項目組假定體裁在多模態語篇的版式結構、印刷式樣和空間布局等的選擇上有一定的制約,以及對語篇的修辭結構和布局結構之間的轉化有一定的影響(Bateman 2014a:32)。為論證這一假設,項目組采用語料庫驅動的方法來設計GeM模型以支持實證研究。他們以插圖書籍、說明書、印刷版和網絡版報紙作為研究對象,探討這些非實時性語料的物質載體(紙張或電腦屏幕)及所使用的符號資源(文字、照片、插圖 、圖表、表格、地圖等)等,并以此確定模型的必要分析層。
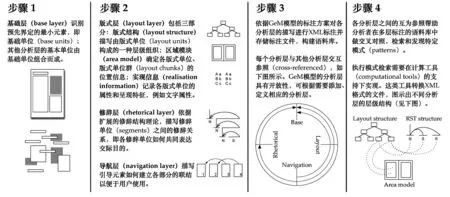
圖1 GeM模型應用步驟(譯自Hiippala 2017:278)
鑒于符號模態(semiotic mode)種類繁多難以作出清晰的界定,Bateman(2008)區分了三類主要的模態:文本流(text-flow)、圖像流(image-flow)、頁面流(page-flow)。文本流以線性展開邏輯文本實體;圖像流以序列(sequence)連接相關元素,如由多個元素構成的一個圖表、一幅漫畫等;頁面流以空間距離、元素群組(spatial proximity,grouping of elements)等統籌更多具有修辭功能的單位實現語篇的交際目的。根據這些定義,項目組選取的任何一個多模態頁面(如動物圖鑒、電話機使用說明書等),都可以視作是多種符號模態(如文本流、插圖、圖表等)相互協調與整合的多模態修辭結構體。因此,與交際目的的實現緊密相關的修辭結構、修辭潛勢的研究是多模態語篇分析的關鍵一環,也是GeM模型描述多模態語篇的重要組成部分。除此之外,該模型還涵蓋內容層中各符號系統的體現形式如文字特征等。項目組共設置了四個必要分析層:基礎層、版式層、修辭層、導航層(詳細介紹見圖1),并開發了第一套使用XML多層標注非實時性語料的方案(Henschel 2003)。
其中,修辭層借助RST分析多模態語料的修辭結構。以描寫語篇結構為出發點旨在實現自然語篇的計算機生成,William C. Mann、Sandra A. Thompson和Christian M.I.M. Matthiessen于20世紀80年代初在南加州大學創立了RST。該理論從功能的角度解讀各小句、句子、段落等語篇單位,通過對各單位之間修辭關系的分析來解釋語篇的整體性、連貫性和層級性。RST一誕生就為語篇分析提供了可行的理論框架(Delin & Bateman 2002;Matthiessen & Thompson 1988),也為語篇的自動生成帶來了建模上的靈活性(Hovy 1993;Moore & Paris 1993)。盡管RST在語篇分析、生成等不同學科領域有相當的影響力及廣泛的適用性(Taboada & Mann 2006),但也有學者質疑理論本身及其應用,主要包括語篇單位的切分、核心單位的確定等(Fritz 2014;Stede 2008)。當RST被擴展應用于多模態研究領域時,這兩個問題就顯得尤為突出。Bateman(2008:157-159)詳細闡釋了將RST應用于多模態語篇分析時四項特別值得注意的問題:修辭單位的界定、修辭關系核心性(nuclearity)的確定、修辭單位間的空間鄰接性以及同一修辭單位的重用現象(the reuse of a span/segment)。
第一,RST的研究始于小句,逐步過渡到句子、段落和語篇;但在多模態研究領域,這一分析模式將被打破。多模態語篇的最小修辭單位可以是比小句更小的元素。GeM項目組界定了可滿足項目研究要求的基礎單位(Bateman 2008:111)。例如圖表或列表中的基礎單位包括圖、圖表標題、圖表中的文字、列表起始句、列表條目。這其中不少基礎單位往往由小于小句的名詞短語甚至單詞構成,但都是修辭單位并通過一定的關系被連接起來:圖表中的圖與標題可構成詳述(elaboration)、多核心重述(multi-nuclear restatement)、識別(identification)等關系;列表中的起始句與條目可構成類別從屬(class-ascription)、屬性識別(property-ascription)等關系(Bateman 2008:160-163)。識別等關系是GeM項目組為處理多模態修辭現象而進行的擴展(馮德正等 2016:50)。RST最初定義了24種修辭關系(Mann & Thompson 1988),但修辭關系集具有開放性。在多模態、多語種等研究領域,分析者可根據研究目的細化和補充關系集,例如Carlson等(2003)的樹庫團隊設計了78種修辭關系。
第二,修辭關系核心性的確定。多模態語篇中的圖像往往極富視覺沖擊力,這也加大了判斷核心性的難度。例如當圖像與文字構成詳述關系時,很難判定哪一個是核心。在此類情況下,我們可以選擇多核心關系來避免判定的任意性(Bateman 2008:159;Matthiessen待發表)。圖2展示了兩個常見的標志牌及多核心關系的RST圖式。圖2a提醒大眾在此區域禁止吸煙,禁煙圖標和文字“no smoking”表達的意義一致,構成多核心重述關系。圖2b提示道路使用者右側為公共入口,文字“public access”和右箭頭圖標表達的意義相互疊加,共同預告入口設施及方位,構成多核心增添關系(addition)。Matthiessen(1995、待發表)系統化重構RST,對判斷修辭關系的核心性提出了核心性連續體(nuclearity cline)的概念。例如在漫畫、新聞等體裁中常見的投射關系(projection),對于說話人(projecting)與說的話(projected)之間是否構成單核心或多核心關系,構成單核心關系的情況下哪個語篇單位為核心,Matthiessen(待發表)指出判斷核心性應根據作者想要表達的交際效果,即不同的取向性(orientation)而定:若對說話人的表達更具主題性,說話人為核心(若更強調主題,即以說話人為核心);若對說的話的表達更具表述性,則說的話為核心(若更強調話語表述的內容,則以所說的話為核心)(可參閱Matthiessen & Teruya 2015)。

圖2 多核心修辭關系的示例(Matthiessen待發表)
第三,修辭單位間的非線性排列。傳統上,RST分析呈線性排列的句子及更高層次的語篇單位。但是,多模態語篇具有“多角度、多起點的特點,能夠從左到右、從上到下、從中心到邊沿組織信息,甚至是三種角度的結合,或者是相反的過程”(張德祿2012:126)。因此,修辭單位間的相互毗連,呈現二維甚至三維的空間排列,例如漫畫中的元素覆蓋(overlay)現象。Bateman(2008:158)認為分析者可以遵循多方位鄰接原則(adjacent in any direction)來處理這一問題。
第四,同一修辭單位的重用現象。例如使用說明書中的插圖往往既可以呈現產品的某一特定部分來幫助使用者識別,又可以展示某一具體操作動作。舉例來說,在iPhone使用手冊的“開始使用”部分,手機側邊的SIM卡托盤及回紋針這一圖例讓iPhone用戶一方面清楚該部分所在位置,另一方面了解如何安裝、取出或更換手機中的SIM卡。這一圖例因此可與多個修辭單位形成修辭關系。但在具體分析中,為維持修辭結構的樹形層級性,Bateman(2008:159)不建議重復使用同一修辭單位。
三、 多模態語料庫建設:標注、圖示及分析
1. 語料庫簡介
本節以基于GeM模型多層標注建立的CPHP(Corpus of Public Health Posters)(Zhang 2017)為例,演示基礎層和修辭層的標注、圖示,并介紹基于CPHP的多模態修辭研究。CPHP分為兩個子語料庫,即CPHP-NYC和CPHP-HK,涵蓋選自紐約和中國香港的公共衛生海報各30張。語料涉及健康飲食、體能活動、非傳染病、傳染病、口腔衛生、健康保險、器官捐贈、吸煙、吸毒、飲酒等20多個健康主題。本節選取CPHP-NYC中的一例海報NYC-2(見圖3)來作具體演示。NYC-2是Read’em Before You Eat’em公眾教育運動的海報之一,展示于紐約地鐵站等公共場所。2008年,紐約成為美國第一個強制要求連鎖餐廳在菜單上標示卡路里的城市,并出臺了標準的菜單標示法。該宣導活動隨之產生,提醒消費者用餐時查看卡路里含量并作出健康的選擇。

圖3 健康教育海報示例NYC-2
2. 語料庫標注
語料庫標注的第一步是確定、識別基礎單位(見圖1),基本原則是相對最小性與客觀全面性。基礎單位的最小性(atomicity)是相對于其他分析層的基本單位而言的,基礎單位是修辭單位等的組成基礎(Bateman 2008:111)。所有文字元素甚至可以以單詞為基礎單位進行標注,再在其他分析層進行組合,但為了避免基礎層的代碼爆炸,一般研究都無須把單詞界定為最小元素。此外,利用功能、體裁等特征可方便辨認及標識基礎單位,但識別的客觀全面性要求分析者保持獨立判斷,免受任何影響(如視覺感知特性、與研究的相關程度),不能過早組合或遺漏任何元素。所以NYC-2共包括14個基礎單位,并使用id屬性(u-02.01,u-02.02等)標識每個基礎單位(見表1)。
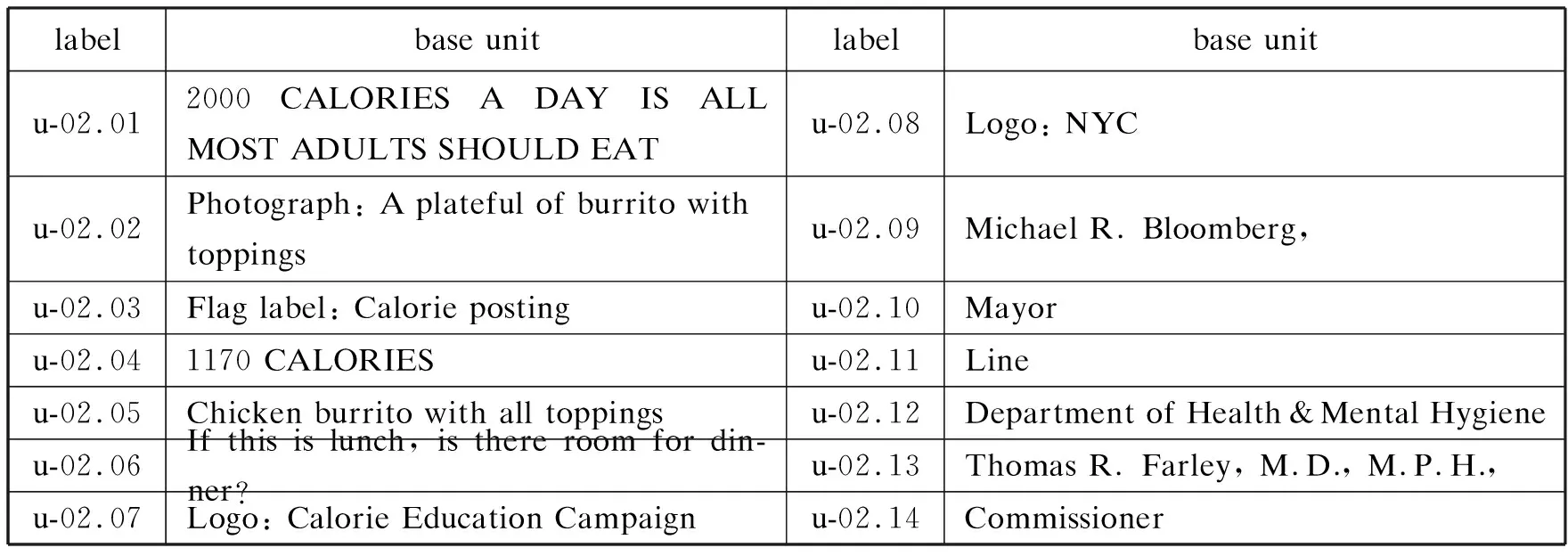
labelbase unitlabel base unitu-02.012000 CALORIES A DAY IS ALL MOST ADULTS SHOULD EATu-02.08Logo: NYCu-02.02Photograph: A plateful of burrito with toppingsu-02.09Michael R. Bloomberg,u-02.03Flag label: Calorie postingu-02.10Mayoru-02.041170 CALORIESu-02.11Lineu-02.05Chicken burrito with all toppingsu-02.12Department of Health & Mental Hygieneu-02.06If this is lunch, is there room for din-ner?u-02.13Thomas R. Farley, M.D., M.P.H.,u-02.07Logo: Calorie Education Campaignu-02.14Commissioner
表1 NYC-2的基礎單位
那么,如何標注這些復雜的基礎單位、修辭結構呢?如何實現基礎單位在其他分析層的可重復性以保證各分析層的交互式參照?如何使數據的處理能力(如統計、可視化、檢索等)更強?如何使數據的修改、不同語料庫之間數據的交換等更方便?GeM項目組使用可擴展標記語言XML來滿足各類要求。限于篇幅,本文對XML的基礎知識、特點等不作具體介紹。XML允許用戶自行定義描述性的標簽(tag)來標識數據,項目組因此設計了一系列標簽,例如基礎單位的標簽為

圖4 NYC-2的基礎層標注
修辭層的標注包括兩部分:修辭單位及修辭關系。不是所有的基礎單位都是修辭單位。嵌入式基礎單位、引導元素、某些圖案元素如分隔線等不視作修辭單位(Henschel 2003:17-18);體裁的一些固定元素(如書信的稱呼和信尾敬辭等)也不計作修辭元素。因此,除去海報出版機構的標志組合(logo lockup)等元素,NYC-2共包括6個修辭單位:海報標題、墨西哥卷餅圖片、熱量標示、圖片小標題、公眾教育運動標志、反問句。如圖5所示,修辭單位的標簽為

圖5 NYC-2的修辭層標注
3. 語料庫圖示與分析
標注完成、驗證后,利用計算工具gem-tools實現標注的可視化(如圖6的修辭結構圖)、統計語料庫數據(如修辭關系出現次數、不同模態的使用比重)、檢索模式(如RST圖式)等。這套gem-tools針對GeM標注語料庫開發,用程式語言Python編寫代碼,在交互式筆記本Jupyter Notebook中運行。Zhang(2017)在使用gem-tools過程中,發現、報告其缺陷,并協助Hiippala進行修正和改善;對不同體裁的語料進行反復測試后,gem-tools在體裁適用性、圖示高清度等方面已得到了顯著提高。運行命令啟動Notebook,在Jupyter界面導入NYC-2的基礎層、修辭層XML 文件,即刻輸出圖6。圖示修辭結構可再次判定修辭關系分析的準確性、驗證代碼的有效性。相比之下,手動繪圖費時耗力,只適合個案研究(如馮德正等 2016),RST繪圖軟件(如O’Donnell 1997的RST-Tool)既不如gem-tools快速便捷,也不具備合并不同層次結構圖(如修辭結構和版式結構)等功能。
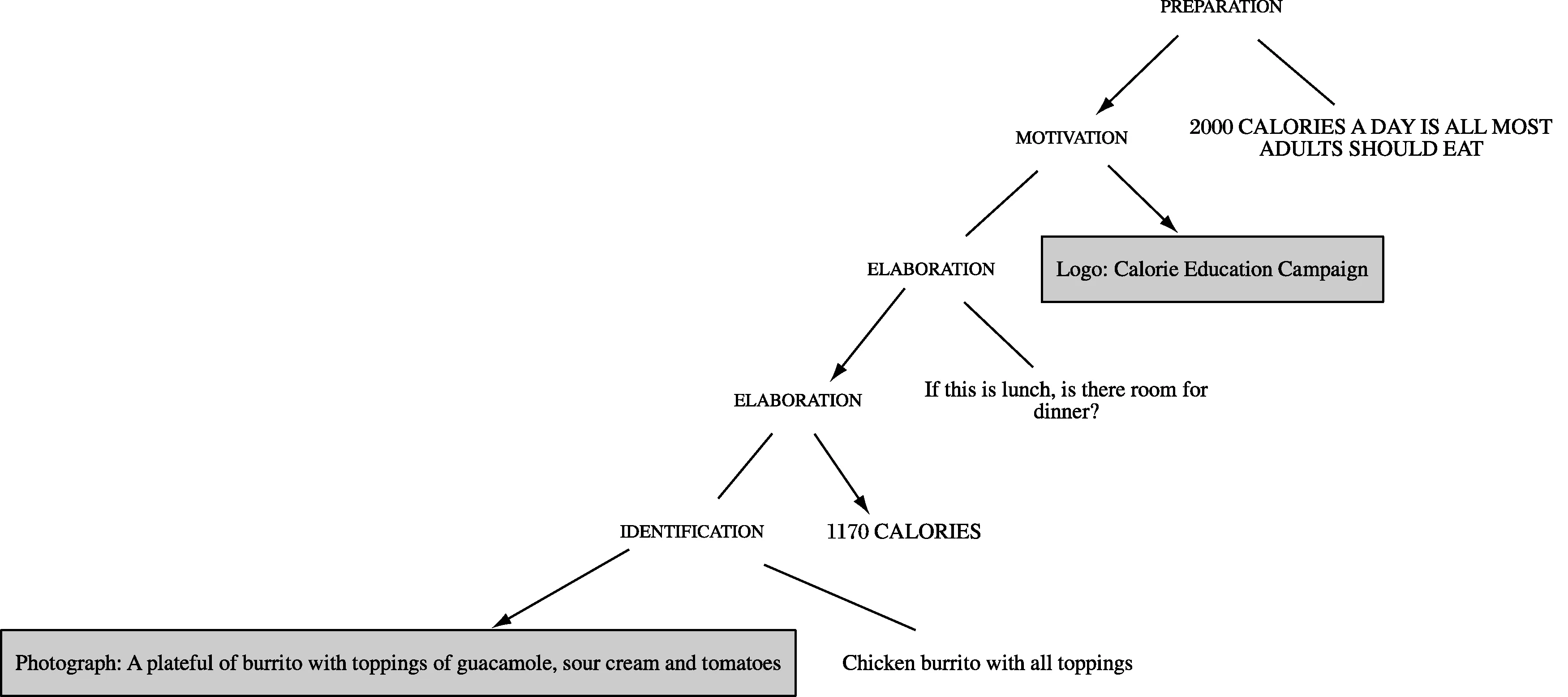
圖6 NYC-2的修辭結構圖
多層標注60張海報后,利用gem-tools統計與修辭結構分析相關的數據:29種修辭關系在CPHP中共出現了454次(見圖7)。其中,詳述、使能(enablement)、動機(motivation)、多核心重述、準備(preparation)等關系的出現頻率較高。運用gem-tools搜索特定修辭關系,對比所選定關系RST圖式中的核心、衛星單位,可以分析修辭關系在CPHP中的構成特征。例如,在Jupyter界面中輸入“preparation”,準備關系的RST圖式被突出顯示,搜索數據顯示其衛星單位往往是醒目的海報標題或/和視覺沖擊力強的圖像,這些衛星單位單獨或共同在較短時間內吸引觀賞者的注意力,并為整張海報的理解起準備作用。因此,以標注語料庫實證分析的統計、檢索信息為依據,結合對各符號資源的定性分析,可實現對不同修辭關系在檢索范圍內的使用情況的全面研究。接下來我們通過檢索在CPHP中高頻出現的幾種修辭關系,簡單討論公共衛生海報的意義配置以及子語料庫中海報的構意特征。
動機與使能這一對修辭關系在公益海報中的高頻出現是可以預見的,但如何出現需要實證考察。輸入“motivation”,搜索發現CPHP中所有海報的call-to-action(CTA),即動機關系RST圖式的核心單位,幾乎一律使用祈使語氣,直接明確。例如NYC-1中的“CUT YOUR PORTIONS. CUT YOUR RISK.”和HK-17中的“記得醒目防曬!Be SunSmart!”。在子語料庫中分別輸入“enablement”,對比顯示在CPHP-NYC中仍大量以祈使語氣呈現相關資源,與CTA緊密呼應且數量適中,例如NYC-1中的“Call 311 for your Healthy Eating Packet”。在CPHP-HK中相關信息卻幾乎以名詞短語的形式呈現,例如HK-17中的“免費熱線 3656 0800 更多防曬貼士:www.cancer-fund.org/sunsmart”。CPHP-HK中的有些海報甚至逐條列出專題網站、健康教育熱線等相關資源。輸入“elaboration”,對比顯示詳述關系在CPHP-NYC中主要出現在文本流中,通過補充細節、提供實例等來進一步闡釋與某一健康主題相關的知識及態度;在CPHP-HK中卻分別大比例地出現在圖像流、文本流中,或由海報標題與最明顯的圖像流構成。而CPHP-NYC中的海報標題與相關圖像流往往構成多核心重述關系,圖像本身易讀性也高,使得共同表達的含義更加清晰明了。此外,CPHP-HK中象征性圖像使用較頻繁,比CPHP-NYC中同類圖像的出現次數高出一倍多。因此初步分析表明,CPHP-NYC中的海報使人一目了然,CPHP-HK中的海報整體構意不夠明確。這是否與海報設計者對公眾視覺能力(visual competence)、文化背景等要素的不同預設相關,還需結合社會心理學、傳播學、文化研究等理論進一步實證分析。雖然已經超出本文關注的范圍,但我們需要強調將文本分析置于社會文化背景中進行闡釋的重要性。
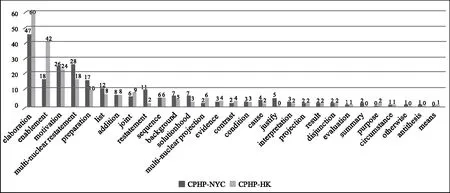
圖7 CPHP的修辭關系統計圖
最后需要說明的是,GeM模型的設計初衷并非是分析修辭結構,而是將多模態語篇視為多層次符號制品(multi-layered semiotic artefact)進行多層描述分析(Bateman 2008:108),如圖1所示。此外,根據系統功能語法(Halliday & Matthiessen 2014:26),語言為四層次系統,即內容層的語義層、詞匯語法層和表達層的音系、語音層或字系、字體層,而表達層的層次性對于多模態研究更為重要,因為人們需要知道表達資源是如何與其他各層的系統相關聯及互動的。所以,雖然修辭層是GeM模型的重要部分,但建庫分析更大的優勢是依據各分析層的互相參照而全面、準確闡釋多模態語篇的意義構建。例如,修辭結構與版式結構之間的關系被認為是對等的:修辭結構中的特定構型(configuration)會影響版式結構的設計,反之亦然。CPHP也包括各海報版式層的標注文件。通過對比修辭和版式結構、對照修辭單位在版式層的區域模塊等,可以揭示不同語篇單位在設計、排印等方面的資源選擇,有助于進一步分析多模態修辭潛勢。多層標注的多模態語料庫也是進一步研究多模態體裁、進行跨文化或跨媒介對比研究的理想工具。雖然有諸多優勢,GeM模型的標注方案還需完善。版式層的標注方案主要針對格狀基礎的設計(grid-based design),如GeM項目組所選取的各類語料。對于不同設計的多模態語篇,我們無法依據現有的標注方案確定各版式單位及版式單位群的空間位置信息。以polygon的方式進行更靈活更精準的三維定位可以解決這一問題(Zhang 2017)。此外,標注方式的發展趨勢是從人工標注到自動標注,應盡快開發基于Web的自動標注工具以提高標注的效率和精確度。
四、 結 語
作為語篇分析和生成的工具,RST已廣泛應用于語言學、計算語言學、計量語言學、人工智能等領域及其交叉研究,但都只是對單一模態語篇的語篇結構等進行標注的語料庫(Carlsonetal. 2002;Dasetal. 2015)。GeM模型則是唯一擴展RST建設多模態語料庫的框架。本文展示了應用GeM模型建庫的基本步驟,并演示了多模態語料庫的修辭結構標注、圖示及分析。總之,借鑒RST的GeM模型為多模態語料庫建設提出了可操作的理論與標注方案,發展了多模態實證研究的技術方法;而基于此模型的標注語料庫為更加系統、深入理解復雜多模態語篇的意義建構、模態關系以及多模態體裁空間(genre space)等概念提供了有力的分析框架與實證基礎。事實上,從20世紀90年代多模態語篇的自動生成(Batemanetal. 2001;Matthiessenetal. 1995)到本世紀初多模態語料庫的標注構建(Bateman 2008),RST一直起著關鍵性的作用,在多模態研究領域具有不可替代的優勢。作為語言學者,一方面,我們應進一步發展多模態修辭結構理論、完善應用此理論構建多模態語料庫的模型,通過大量的實證分析,研究多模態語篇的內容層、表達層等各個層次的特征、層次之間的關系,對比更多不同體裁的多模態語篇,據以加強多模態領域的理論建設。另一方面,我們應通過完善實證分析的研究方法增進與人工智能等領域的交流合作。例如為人工智能領域提供我們的語義標注數據并探討各類數據的結合應用。鑒于此,語言學領域自身也應更廣泛地布局人工智能,研究者可以了解人工智能諸多流派的研究現狀、難題以及趨勢,解決語言學與多模態研究的新問題并為人工智能研究提供新的思路。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
