基于隨機森林的屋頂機空調系統故障診斷研究
2019-01-19 08:10:28吳斌杜鑫杜志敏晉欣橋
制冷技術 2018年5期
吳斌,杜鑫,杜志敏,晉欣橋
(上海交通大學制冷與低溫工程研究院,上海 200240)
0 引言
隨著社會的發展,人們需求的提高,空調系統在日常生活中應用越來越普遍,據統計,空調的耗電量已占建筑總能耗的50%以上[1-2]。隨著各部件的老化、設備的性能衰減,空調系統常常運行在亞健康狀態,導致能耗大幅上升,維護成本增長以及使用者舒適度下降[3],因此針對空調系統的故障診斷勢在必行。目前空調系統的故障診斷技術主要分為3大類:基于模型的方法、基于規則的方法和基于數據挖掘的方法[4]。基于模型方法依賴準確的數學物理模型,NORFORD等[5]開發了一種物理模型來檢測空調箱的常見故障,此外還有黑箱模型[6]和灰箱模型[7];與基于模型方法不同,基于規則的方法不需要構建準確的數學模型而是依靠專家知識或經驗規則,VISIER等[8]構建了專家系統用于診斷學校空調系統故障,HOUSE等[9]提出了一系列的規則來判斷空調箱的運行狀況,但如果專家規則構建的不夠詳細,診斷效率就會下降;基于數據挖掘的方法近幾年發展非常迅速,主元分析[10-11]、支持向量機[12]、神經網絡[13-15]等方法均已用在空調系統的故障診斷中,該方法通過挖掘數據之間的固有關系來區分正常與故障數據,如 LEE等[16]提出了回歸神經網絡診斷空調箱的突發性性能衰退故障,WANG等[17]在變風量系統中提出了基于神經網絡的傳感器故障檢測模型。近幾年計算能力的提高,新型算法的出現,使得機器學習在數據挖掘、計算機視覺、自然語言處理等領域的應用效果有了明顯提升,而隨機森林作為機器學習中一個重要的分支也擁有著廣泛的應用。
本文以3個屋頂機空調系統作為研究對象,采用了隨機森林的方法,分別構建并研究了不同屋頂機系統的故障檢測與診斷的模型。首先,本文介紹了隨機森林方法的基本原理。接著說明了RF模型具體構建過程并驗證了該方法的準確性。然后,本文研究了不同故障程度的訓練數據產生的模型與檢測結果的關系并進行了對比驗證。最后研究了相似系統間模型通用性的問題,驗證了本文所建立的RF模型具有一定的通用性能力。
1 研究對象
1.1 屋頂機空調系統
本文研究對象為3個屋頂機空調系統,分別記為RTU1,RTU2和RTU3,系統組成如圖1所示,由壓縮機、冷凝器、節流裝置和蒸發器4大部件組成。3個屋頂機系統之間,節流裝置形式相同,不同之處在于壓縮機的形式、制冷劑的種類以及制冷能力,具體見表1。
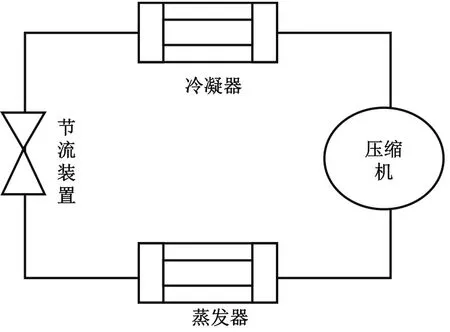
圖1 屋頂機空調系統簡圖
3個系統之間具有相同的傳感器測點布置,分別測取:室內回風干球溫度、室內回風濕球溫度、室內送風干球溫度、室內送風濕球溫度、室外送風干球溫度、室外回風干球溫度、液管溫度、吸氣溫度、排氣溫度以及液管壓力、吸氣壓力和排氣壓力共計12個變量。

表1 3個屋頂機空調系統構成
1.2 故障類型與程度
本文共研究了屋頂機系統的6種熱力故障,分別為冷凝器結垢(Condenser Low Airflow Fault,CA)、蒸發器結垢(Evaporator Low Airflow Fault,EA)、壓縮機閥門泄露(Compressor Valve Leakage,VL)、液管堵塞(Liquid Line Restriction,LL)、制冷劑不足(Undercharged,UC)與制冷劑過多(Overcharged,OC),故加上正常類型(Normal)的數據,共計 7個類型。
表2為實驗故障程度,其中每個故障類型下均有較大范圍的實驗故障程度覆蓋,故本數據集能夠支持不同故障程度的訓練數據產生的模型與檢測結果關系的研究。但對比不同機組可以發現,在相同的故障類型下,不同機組的故障程度范圍并不統一,如UC故障下,RTU3的故障程度范圍僅為RTU1的1/3,這給跨系統對比增加了難度。
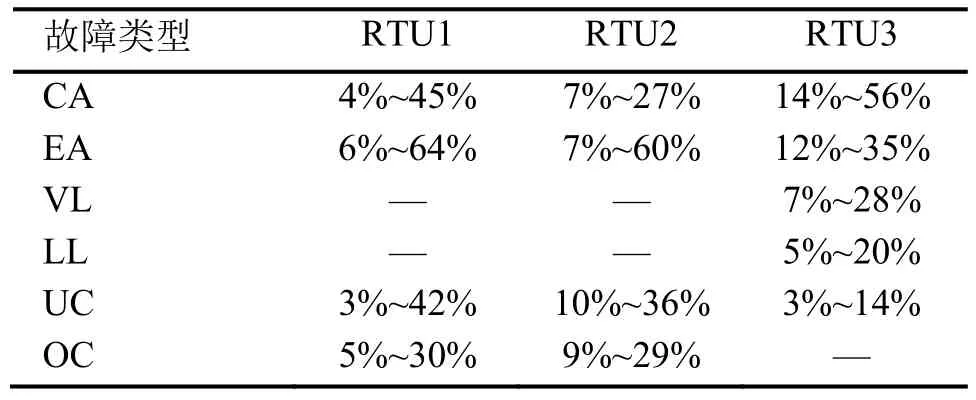
表2 實驗故障程度
因此,本文將任一故障類型的數據均劃分為 3類,分別為輕度、中度和重度,并保證在每類中故障等級大小相近,不同類中故障等級大小無重疊的前提下,將樣本數據均分到3類中,劃分后具體結果見表3所示。
本文中所采用的數據均來自具體實驗,關于故障的引入,以及故障程度衡量方式可以參考文獻[18],本文由于篇幅有限,不作展開介紹。
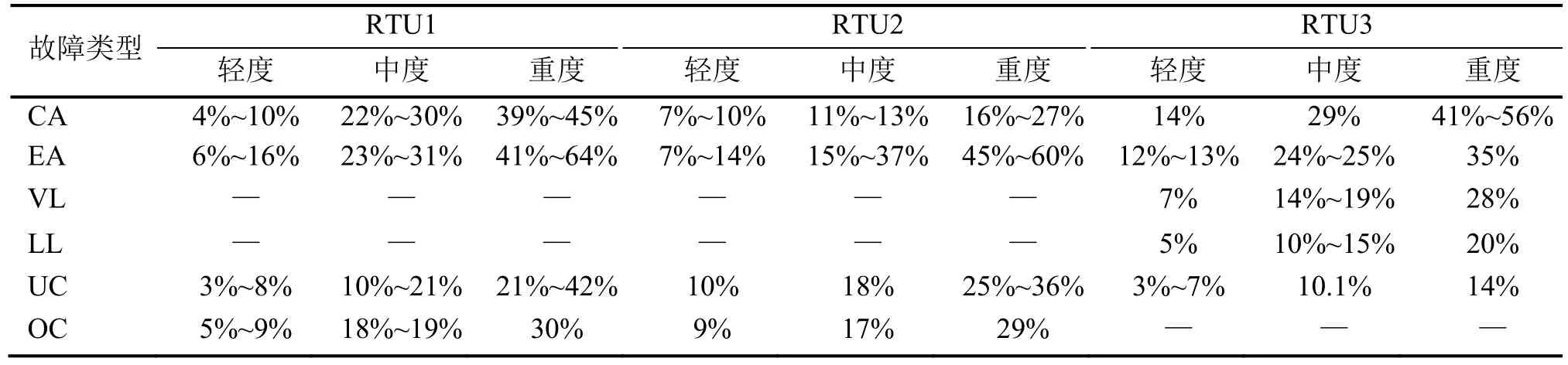
表3 分類后故障程度
2 基于隨機森林的診斷模型
隨機森林是2001年BREIMAN提出[19],具有很高的分類精度,對噪聲和異常值有較好的穩健性和較強的泛化能力等優勢。RF屬于集成學習法(使用一系列學習器進行學習,并使用某種規則把各個學習結果進行整合從而獲得比單個學習器更好效果的一種機器學習方法),而組成RF的基本元素為決策樹。
2.1 決策樹
決策樹是20世紀80年代非常流行的人工智能技術,為樹狀結構,見圖2左,由一系列的節點與分支構成,其在節點處根據屬性的不同對樣本進行分類并一直持續到葉節點,該處就是決策結果。決策樹的分類結果示意圖見圖2右側,從中可見,決策樹的分類是采用二分法在數據平面中依據數據的特征屬性劃分出諸多區域,每一個區域代表了一個決策結果。在決策樹的構建時,常用算法有迭代二叉樹3代(Iterative Dichotomiser 3,ID3),C4.5決策樹(Classifier 4.5, C4.5),CART決策樹(Classification And Regression Tree, CART)等[20]。決策樹易于實現,訓練時間短,訓練完畢的模型便于理解,但有過度擬合的問題,常通過“剪枝”來改善。圖2中,t1~t2均為節點,且t1為根節點,n1~n3為葉節點,代表了決策結果。
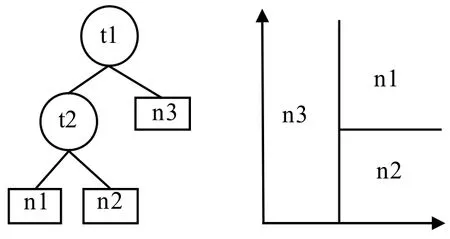
圖2 決策樹結構以及劃分示意圖
2.2 隨機森林
隨機森林由多個決策樹分類器{h(x,θ_i),i=1,2,…,k}組成,其中h(x,θ_i)為 RF 中第i棵決策樹,x為該決策樹的訓練集,θ_i為相互獨立且同分布的隨機向量,該隨機向量決定該決策樹的生成過程[21]。最終RF的輸出結果由所有決策樹投票得到。故RF算法包括決策樹的生成和投票決定結果兩部分,圖3為RF方法的示意圖。隨機森林包含了兩大隨機化思想:
1)套袋思想,從原始樣本中有放回抽取(即原始樣本中某些樣本可能在訓練樣本中多次出現)與原樣本數量相同的訓練樣本集以構建單棵決策樹;
2)特征子空間思想,在決策樹節點進行分裂時,從全部特征中抽取一個特征子集,再從子集中選擇一個最優特征進行分裂,這保證了每個決策樹的訓練數據只是部分訓練樣本中部分特征,雖然單顆樹的分類能力不強,但大量的樹的存在卻有較高的預測準確性。
2.2.1 決策樹的生成
單個決策樹的生成如下:
1)從數據量為N的原始樣本數據中采取放回抽樣的方法隨機抽取樣本,重復N次形成一個新的訓練數據集。
2)該訓練數據集是該棵決策樹所有訓練數據,該訓練數據集中有M個特征,從M個特征中隨機挑選m個作為該決策樹的訓練特征。在該樹的每個節點處,按照節點不純度最小的原則從m個特征選一個特征進行分支生長,直到該樹可以準確分類訓練數據集或者所有屬性已被用過,并且在森林的生長中,m保持不變,其中m的值采用如下公式確定:

3)決策樹不進行剪枝操作,充分生長,從而使得每個節點的不純度達到最小。
重復k次1~3步驟,從而生成由k棵決策樹構成的隨機森林。
2.2.2 投票決定結果
多棵決策樹組合成的隨機森林,在得到新的測試數據后,其結果由決策樹分類器投票數確定,即對測試數據X,隨機森林預測多個結果,得票數最多的類即為測試數據的最終標簽,隨機森林的投票公式如下:
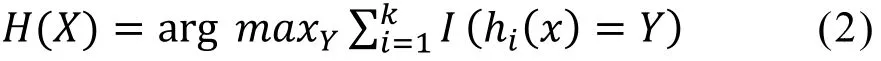
式中:
H(X)——組合分類模型;
hi——單個決策樹分類模型;Y——輸出變量;
I(*)——示性函數。
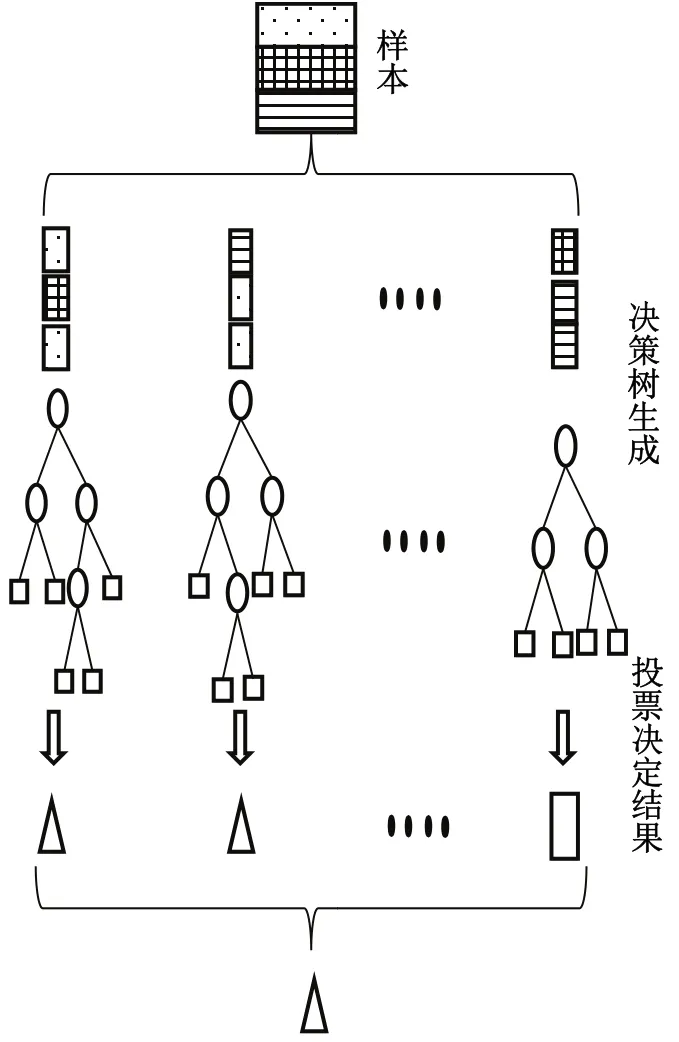
圖3 隨機森林示意圖
2.3 基于隨機森林的故障診斷系統
本文采用的隨機森林,其包含的決策樹數量為500,m為4。輸入的數據包括實際系統中測量值、部分物性計算等,分別為:室內回風干球溫度、室內回風濕球溫度、室內回風露點溫度、室內回風相對濕度、室內送風干球溫度、室內送風濕球溫度、室內送風露點溫度、室內送風相對濕度、室外送風干球溫度、室外回風干球溫度、液管溫度、吸氣溫度、排氣溫度以及液管壓力、吸氣壓力和排氣壓力、冷凝溫度、蒸發溫度、過冷度、過熱度、COP(Coefficient of Performance)、室內送風量與正常值的比值共計22個。所有采集的數據均需通過異常數據剔除和穩態數據判別兩個過程。
異常數據剔除,本文采用方法為箱圖法,將一組特征數據從大到小排列,分別計算出上邊緣、上四分位數Q3、中位數、下四分位數Q1、下邊緣,其中內距(IQR)等于Q3與Q1的差,上下邊緣分別為Q3+1.5IQR和Q1-1.5IQR,超出上下邊緣的為異常值,如圖4中黑叉所示。
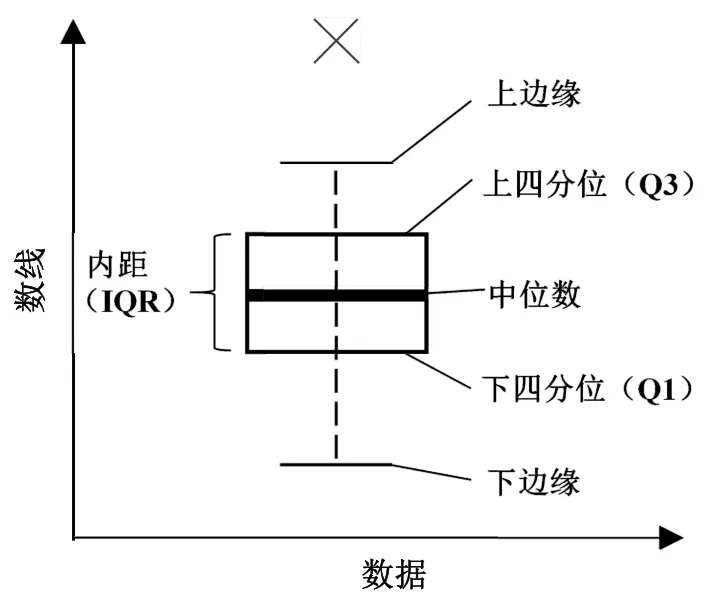
圖4 箱圖法示意
本文使用移動窗口均值法判別穩態數據,即在k時刻、寬度為n的窗口內數據平均值如下式計算:

式中:
n——時間窗口寬度,s;

表4 類型編碼
圖5為本文中基于隨機森林的故障診斷系統示意圖,數據處理之后再根據研究具體內容,劃分好訓練數據集和測試數據集,利用訓練數據集生成隨機森林,再用測試數據進行驗證,比較測試數據的預測類型與真實類型從而得出檢測有效性。
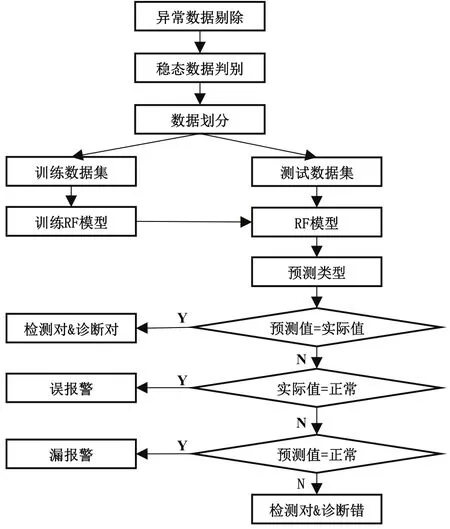
圖5 基于隨機森林的故障診斷系統
3 實驗驗證
3.1 基于隨機森林的診斷模型驗證
在適用性驗證部分,本文選用的數據為所有的故障程度,即輕度、中度、重度的總和。隨機抽取66.6%樣本用于訓練RF模型,其余部分用于測試。
測試數據集的檢測結果(本文之后所提到的檢測結果均為測試數據集)如圖6所示,3個系統的檢測正確率分別為 81.5%、80%與 98.1%,均表現了較高的準確率,尤其RTU3,這與RTU3數據量較多有關。對于檢測出錯的樣本,可以發現大部分為漏檢,即實際為有故障,但模型預測為正常,其百分比分別為14.8%、12.0%與0%。3個機組的診斷正確率分別為73.7%、78.9%和100%,也表現出了不錯的故障分辨能力。
考慮到本次測試的數據中包含有6種故障類型,RF方法在每一種故障類型下其檢測正確率如圖 7所示。從中可見,RTU3機組部分,所有類型的故障檢測成功率均為 100%,只有對正常類型的數據出現了4.2%的檢測錯誤。而RTU1在UC和OC故障下表現較差只有62.5%和75%,RTU2最差的結果發生在正常類型下,只有 66.7%并且EA和 UC的結果也不高,導致了RTU2的整體檢測正確率3個系統中最低。
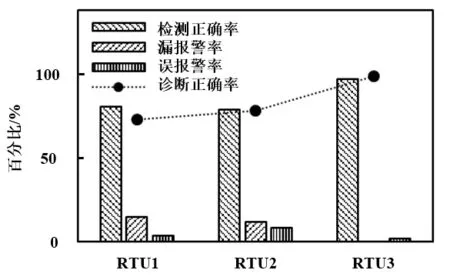
圖6 隨機森林方法總體適用性結果
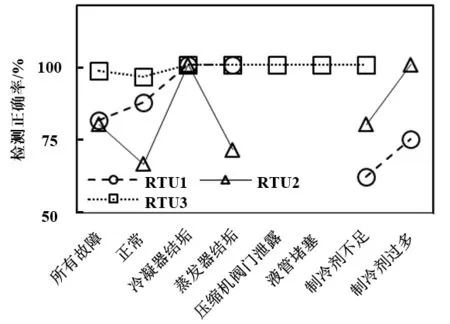
圖7 各種故障類型下RF方法的適用性結果
通過上文的簡單驗證之后可以發現,隨機森林在RTU3數據部分表現優異,但另外兩個屋頂機系統上卻與RTU3的結果有明顯差異。為了避免因為數據量的問題導致了檢測結果的偏差,本文采用 k折交叉驗證的方法。k折交叉驗證是將原始樣本集分為k個子樣本,一個單獨子樣本集作為測試數據集,其余k-1個為訓練數據集,并重復k次,而本文中k取3。使用三折交叉驗證所得結果如下表所示,P1~P3 分別為 3 次驗證的結果,AVRG(Average)為3次結果的平均值。從中可以發現,前文的簡單驗證結果即是P1部分結果。其次,對于RTU3各次檢測的結果相差并不大,可認為RTU3的模型穩定可靠,這也驗證了隨機森林方法在RTU3系統中有著優異表現;而對于RTU1和RTU2,由于選取樣本的不同,結果仍舊存在較大的跳動,如 RTU1的P1和P3的診斷正確率,但從平均值來看,其檢測正確率、診斷正確率都處于一個相對不錯的水平。
綜上所述,隨機森林的方法可以適用于屋頂機空調系統的故障檢測與診斷。

表5 三折交叉驗證結果
3.2 故障程度對模型的影響分析
本文已將所有的數據根據故障程度分為了輕度、中度和重度3類,在本節中,模型訓練數據集選用輕度、重度、所有故障等級和輕重混合四類。其中輕重混合由輕度中故障程度最小的一半和重度等級中最大的一半共同組成。在具體劃分訓練和測試數據時,所有故障程度與3.1節相同,另外3個,如輕度,選用部分輕度故障數據以及部分正常數據用作訓練,測試數據為其余正常數據、其余最小故障等級數據以及其他故障等級下的所有數據。
測試數據集結果如圖8所示,RTU1機組在4種不同的故障程度下,檢測正確率分別為81.5%、63.0%、31.2%和72.3%,診斷正確率分別為73.7%、55.3%、17.5%和66.7%。對比所有故障程度,減少訓練數據的故障程度后,檢測效果均出現了下降,其中輕重混合效果最佳。
對比3個屋頂機系統,可以發現統一規律,按照檢測正確率和診斷正確率從高到低排列均為:所有故障程度>輕重混合>輕度>重度。
此外,為了證明在各個故障類型下均有上述結論存在,本文還對比研究了單一故障類型下訓練數據的故障程度與檢測結果關系。由于 RTU3的故障類型最齊全,故以其為例。圖9列出了RTU3機組在5種故障類型下的結果。從中可見,正常類型的訓練和測試數據由于未發生變動,故其效果均表現不錯,其他故障下,大部分結果與前文結論相同,除了在EA故障下,重度的結果略微優于輕度。RT1與RTU2的結論與RTU3類似,除了在OC故障下結果出現了個例:所有故障程度>輕度>輕重混合>重度。
故可得出結論,在大部分的故障類型下,故障程度與其檢測正確率關系均為:所有故障程度>輕重混合>輕度>重度。對此可以解釋為在減少訓練用故障等級數據后,RF模型所能識別的故障特征信息數量也有所下降,所以檢測結果在所有故障程度時為最好,而輕重混合較另外兩個含有更多的故障特征信息,故其效果為第二好。此外,輕度下包含有部分重度下的故障特征信息,而重度下含有的輕度的信息較少,故輕度的效果好于重度。
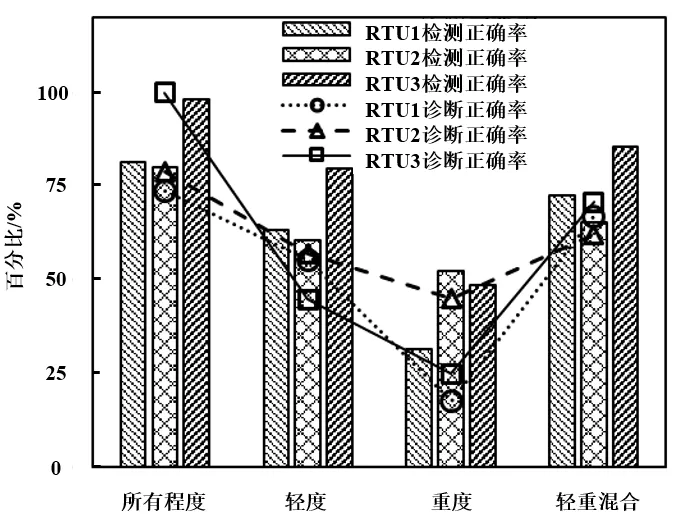
圖8 不同故障程度結果
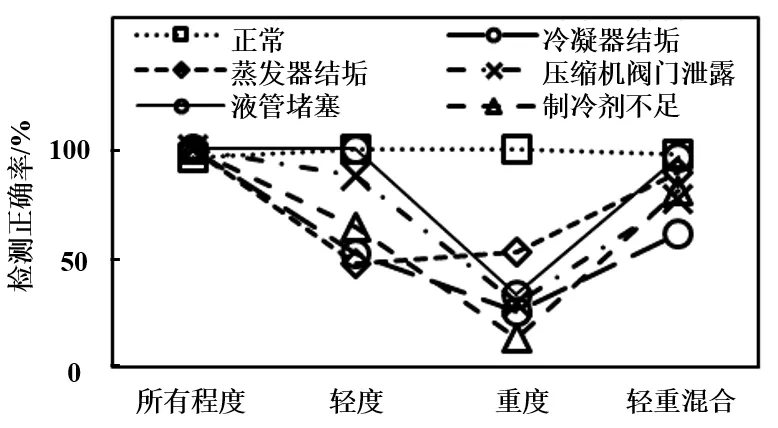
圖9 RTU3系統不同故障類型下結果
3.3 模型的通用性驗證
本節中模型的通用性指的是由某一系統數據訓練生成的RF模型能否檢測其他系統的數據。本次檢驗部分,RF模型采用3.1節中模型,測試數據為其他系統的所有數據,如對于RTU1的RF模型,其測試數據為RTU2和RTU3的所有數據。
進行初步檢測后,可以發現模型有兩種完全不同的響應,如圖 10所示,橫坐標為樣本序號,縱坐標為數據類型。圖中采用的樣本數據均為 RTU2數據,分別用RTU1的RF模型和RTU3的RF模型進行測試。前者,樣本的真實類型與模型的預測類型大部分吻合,而后者輸出為定值,均表現為“正常”,雖然總體的檢測正確率不為零,但該種檢測沒有實用價值,故本文將以“無效”標記。
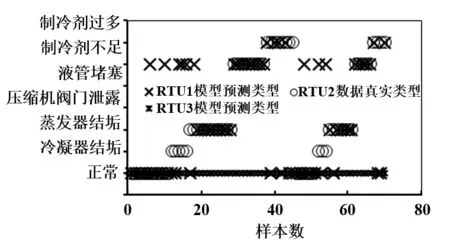
圖10 兩種響應
通過交叉驗證可得到表6的結果,其中驗證方式1~2表示為RTU1模型檢測RTU2數據。從中可以發現RTU3的模型對RTU1和RTU2的數據均為上文所述的定值輸出為無效檢測,而RTU1與RTU2的模型在3個系統的數據下均有正常的輸出,并且檢測的正確率均在50%以上,尤其是RTU1模型RTU2數據(1~2)和RTU2模型RTU1數據(2~1),檢測正確率都接近80%,幾乎與檢測自身模型的數據結果相等。故可以推出,RTU1和RTU2之間模型的通用性較強,但RTU3與另兩者通用性較差。考慮到3個系統之間特征輸入值的范圍并不相同,如圖11所示。從中可見,在液管壓力、吸氣壓力、排氣壓力3個特征下,RTU1與RTU3機組數據幾乎不重合,并且這種數據范圍不統一的情況在其他溫度類的特征中也有體現,這也有可能影響模型的通用性。
為了減少數據范圍的影響,本文采用了3種方式對數據處理并重新訓練隨機森林,分別為:溫度特征值不變,所有的壓力均除以排氣壓力,記為數據處理 1;所有的溫度除以室外溫度,所有的壓力除以排氣壓力,記為數據處理2;以RTU2的數據中最大值和最小值為基礎,分別對所有機組數據進行歸一處理,記為數據處理3。重新訓練并測試后,得到的結果如圖12所示,縱軸坐標為檢測正確率。

表6 模型通用性結果
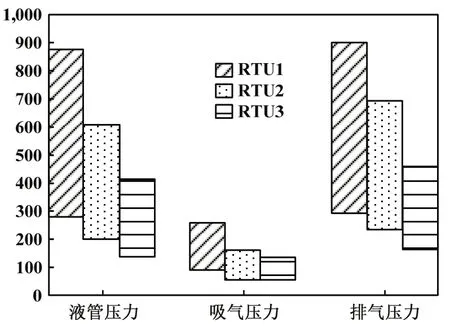
圖11 數據分布
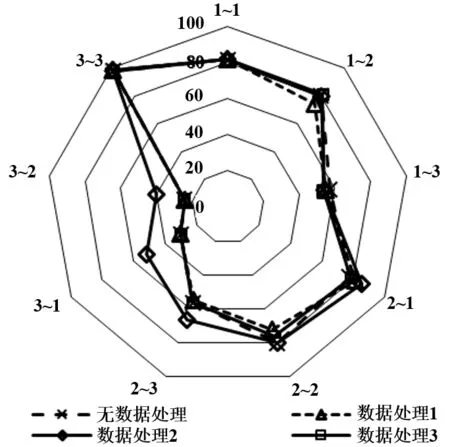
圖12 通用性提高結果
從圖中可知,數據處理的方式對模型的通用性有一定影響,其中數據處理2的結果表現最好,在RTU2模型RTU1數據(2~1)、RTU2模型RTU3數據(2~3)、RTU3模型 RTU1數據(3~1)和RTU3模型RTU2數據(3~2)4種情況下,檢測正確率分別提高了7.7%、10.5%、21.9%和15.7%。其次,這3種數據處理后其 RF模型對自身數據檢測結果與原始結果重合,除了RTU2的數據處理1和數據處理3生成的模型的檢測正確率下降了8%和4%,這證明了數據處理的方式幾乎不影響RF模型對自身數據的檢測效果。并且還可以發現數據處理的方法對原先效果較差的情況提升效果較大,但原先效果較好時,提升并不明顯。
4 結論
本文通過隨機森林的方法對3個屋頂機空調系統,共計6種故障類型進行了故障檢測與診斷的研究,從實驗數據的分析可知:
1)隨機森林方法可以適用于屋頂機系統的故障檢測與診斷,具有不錯的效果;
2)在本文研究的 3個系統下,不同故障等級的訓練數據與檢測結果出現了統一的規律:所有故障程度>輕重混合>輕度>重度,并且在大部分單一故障類型下,也都存在該規律。這為之后設計實驗的故障程度提供了依據,即可以采用輕重混合的類型,既能保持較高的準確性,又能減少實驗次數;
3)本文研究所用的膨脹閥類型相同,制冷量、制冷劑和壓縮機不同的屋頂機空調系統之間,隨機森林生成的模型具有一定的通用性,RTU1和RTU2的模型之間具有較強的通用性,而RTU3模型則相對較弱;
4)本文以數據處理的方式,調整了特征數據的范圍,從而提升了模型之間的通用性,其中以數據處理2的效果最好。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
汽車維修與保養(2019年7期)2020-01-06 03:30:42
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車維護與修理(2016年10期)2016-07-10 08:17:41
海峽科技與產業(2016年3期)2016-05-17 04:32:12
