基于層級深度強化學習的間歇控制算法
2019-01-22 06:54:48李廣源史海波孫杳如
現代計算機 2018年35期
李廣源,史海波,孫杳如
(同濟大學電子與信息工程學院計算機科學與技術系,上海 201804)
0 引言
近年來,人工智能領域中出現了多種針對強化學習算法的測試平臺,例如OpenAI的Universe、Gym、DeepMind 的 DeepMind Lab 等[1-2]。其中,MuJoCo通過模擬對仿真機器人的控制,搭建了針對高維、連續動作空間的強化學習測試平臺[3]。由于在這些測試平臺的仿真過程中,動作的執行不能獲得即時的標簽,因而動作策略的訓練多采用如進化算法、強化學習等學習方法。近年來,由深度網絡和強化學習結合的算法(深度強化學習)在連續動作空間問題中取得了接近人類水平的成績,從而成為求解該類任務的研究熱點[4-5]。
在連續動作空間任務中,如果能夠得到任務環境的動力學方程就可能構建出高效的算法。例如在知道MuJoCo機械臂(Reacher)的動力學模型的前提下,Hall使用在線軌跡優化(Online Trajectory Optimization)算法規劃機械臂的控制動作序列[6]。在沒有進行離線訓練的情況下,該算法能夠實時高效的控制機械臂完成指定動作。然而,該算法需要事先確定任務環境的動力學模型,而大部分仿真環境具有較為復雜非線性動力學系統,其動力學方程難以使用解析式表達。
當仿真任務的環境支持離線的暫停和探索時,可以用蒙特卡洛樹搜索(Monte Carlo Tree Search,MCTS)算法對決策進行探索。在可以使用Atari模擬器進行探索的前提下,利用MCTS算法對每一步決策進行搜索,最終在多數Atari游戲中取得超過人類水平的分數[7]。然而多數仿真環境以及真實世界中是不支持暫停和探索功能。
文獻[6]中的算法利用了任務環境的先驗知識,文獻[7]中的算法需要仿真平臺的特殊支持。為了提高算法的魯棒性,Lillicrap等人在2016年提出了深度確定性策略梯度(Deep Deterministic Policy Gradient,DDPG),該算法實現了端到端、無模型的學習過程,并且在多種連續動作控制任務中表現出色。然而該方法在訓練時收斂速度慢,同時在面對復雜的仿真環境時學習效果不穩定。
受到生物運動控制系統啟發而提出了間歇控制(Intermittent Control,IC)[8,9]。間歇控制是一種具有層級結構的算法,其基本思想是將復雜的任務分解成具有層級結構的多個子任務,再針對每個子任務進行單獨優化,從而實現高效的動作空間探索,提高算法的收斂速度[10]。在軌跡跟蹤任務中,Wada等人提出了基于最小轉換原則的曲線生成算法[11-12],用以生成仿真的手寫體字母。然而該算法中的目標點參數數量和位置是由人工調參得到,整個調參過程需要大量時間。
為了進一步提高算法的收斂時間,Schroecker提出了基于模仿學習的間歇控制算法。針對Reacher任務,該算法首先收集一批人工控制下得到的樣本,在模型學習過程中,將動作的搜索空間限制在已有樣本空間的附近,從而顯著加快模型收斂的速度[13]。然而該算法最終效果和樣本的質量相關性較大,當已有樣本偏離最優解時,算法最終難以收斂到較好的水平。
針對具有連續動作空間和非線性動力學系統的仿真任務,為了提高算法的收斂速度和最終效果,以及實現無模型、高魯棒性的策略學習,本文中融合間歇控制框架和DDPG算法提出了層級深度確定性策略梯度(Hierarchy Deep Deterministic Policy Gradient,HDDPG)模型。該模型由兩個控制器組成,分別為高層控制器和低層控制器。高層控制器負責分解任務,將任務在時間上分解成多個離散的子任務。低層控制器負責完成具體的子任務執行,在每個時刻給出智能體(任務主體,例如在Reacher任務中,代理表示機械臂)需要執行的動作。其中低層控制器使用DDPG模型進行學習,實現了端到端,無模型的學習過程,避免了對任務環境的動力學模型的依賴和人工調參的過程。高層控制器同樣使用DDPG模型,在模型學習的過程中,引入最小轉換原則以啟發模型找到最優的任務分解模式。最后在經典仿真任務軌跡跟蹤(Tracking)和二連桿機械臂(Reacher)來驗證算法。兩個實驗證明了HDDPG相對DDPG模型可以在更短的學習時間內找到最優解。
1 HDDPG算法
針對連續運動控制的層級控制模型HDDPG(Hier?archical Deep Deterministic Policy Gradient,HDDPG)。在HDDPG中,模型分為高層控制器和低層控制器,高層和低層控制器以兩種不同粗細的時間粒度工作。高層控制器規劃次級目標以及次級目標執行的時間。低層控制器在高層控制器規劃的時間內執行與環境交互的動作,以期達到高層控制器規劃的次級目標。高層控制器輸出的次級目標和次級目標的執行時間是由連續的值表示,次級目標一般表示為環境中某個坐標。高層控制器和低層控制器都使用DDPG模型。
下面給出具體的算法描述:
低層控制器是一個典型的DDPG模型,在一個連續動作控制任務中,低層控制器環境的狀態空間S,t時刻的環境狀態st,其動作空間為A,時刻t的動作at,狀態轉移概率 p(st+1|st,at),獎勵函數r∈S×A。代理通過調整策略πθ的參數θ∈?n來最大化獎勵函數。使用隨機策略梯度法來更新參數θ。在每個時刻,環境的狀態由上一個時刻環境的狀態st-1和代理的動作at-1決定,同時,環境會給代理一個獎勵r(st-1,at-1)。根據狀態s,動作a和獎勵r的序列{s1,a1,r1,…,sT,aT,rT} 來更新策略。每個時刻對應的累計獎勵?(s ,a)由公式決定,其中是γ衰減因子,取值范圍為(0,1),其中動作價值函數為Qπ(st,at)=E[?(s ,a)|s=s1,a=a1,πθ],價值函數為 Vt(st)=E[?(s ,a)|s=st,πθ],模型學習的目標是最大化累計回報?(s ,a)。使用梯度 ?aQ(s ,a|θQ)來優化策略,其中Q是一個可微函數相應的,策略網絡的梯度可以表示為使用Q-learning來更新動作價值函數,通過最小化δQ來優化動作價值網絡,δQ是網絡預測出的價值與累計回報之間的均方差。
DDPG算法在訓練連續動作控制模型時往往需要較長的訓練時間,且訓練時間和難度隨著任務自由度上升而變大,同時在針對復雜的運動控制任務時模型最終難以收斂。受到生物運動控制系統的層級結構的啟發,我們將DDPG融入到間歇控制的框架中,即HD?DPG。HDDPG分為兩層控制結構,每個控制結構均是由一個DDPG網絡組成。高層控制器的目標是從宏觀上分解整個任務,同時向低層控制器發出離散的命令,通過低層控制器間接與環境交互,從而完成整個控制任務。
相對于低層控制器,高層控制器在整個決策過程中的輸出以更大的粒度表示。如圖1所示,高層動作網絡 μ(s|θμ)根據當前環境的狀態信息輸出次級目標gti∈S和低層控制器持續時間T(ti)。在代理執行任務的時候,低層控制器接受高層控制器輸出的間歇目標gti和持續時間T(ti),由低層控制器去生成與環境交互的動作ak,并且執行持續時間T(ti),代理得到新環境這段時間的累計回報由環境在時間T(ti)內的累計回報。高層控制器的目標是最大化整個間歇控制過程中的累計回報高層控制器中價值網絡E[Fti|μθμ]是環境和高層控制器的動作決定(gti,,Tti)的。動作網絡的學習策略是
評價網絡的學習策略是最小化評價網絡δQ根據當前狀態s和動作a預測出的q和累計回報之間的均方差。是環境在時間Ti內的累積回報。高層控制器根據來自環境的累積回報 fti進行學習。低層控制器根據 fti進行學習。是下一個關鍵點的預測動作價值
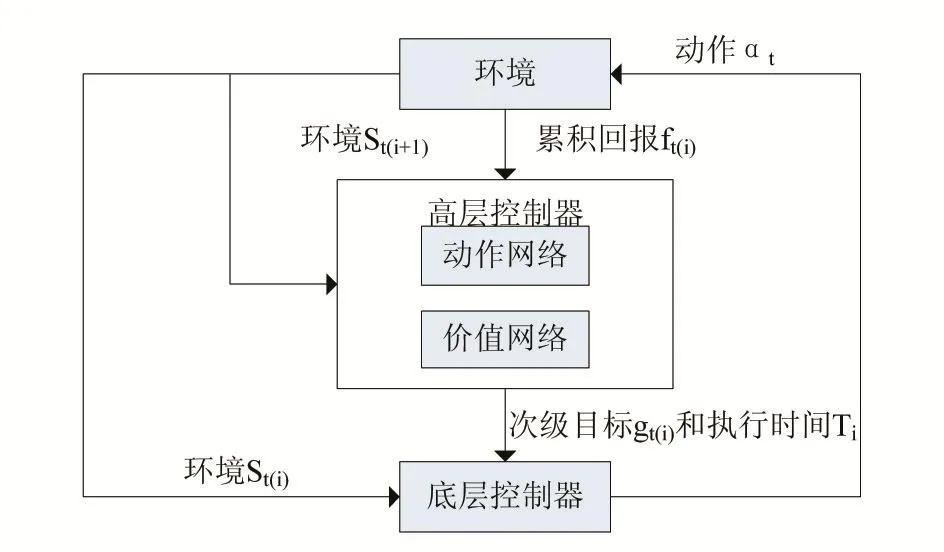
圖1 HDDPG的層級架構
2 實驗設計
為了驗證HDDPG模型能夠有效地完成連續動作控制任務,我們使用了兩個虛擬任務來驗證模型的效果。第一個任務是軌跡跟蹤任務軌跡跟蹤(Puck World)。Puck World是一個虛擬的二維矩形平面,以其中心為原點,x和y軸的范圍均為[- 1,1],假設平面上存在一質點,并且該質點與平面之間存在摩擦力,軌跡跟蹤任務指在規定時間內通過給出作用于質點在x和y軸方向的力,使得質點從起點到終點所走過的路徑符合預期的軌跡。其中環境(xt,yt)分別為質點在t時刻的坐標,(vt,ut)為質點在t時刻在x和y軸方向的分速度,(x′,y′) 為終點所在的坐標,(v′,u′)為終點在x和y軸方向的分速度。作用于質點的動作at=( ft,gt),( ft,gt)分別為t時刻作用于質點x和y軸方向的力。
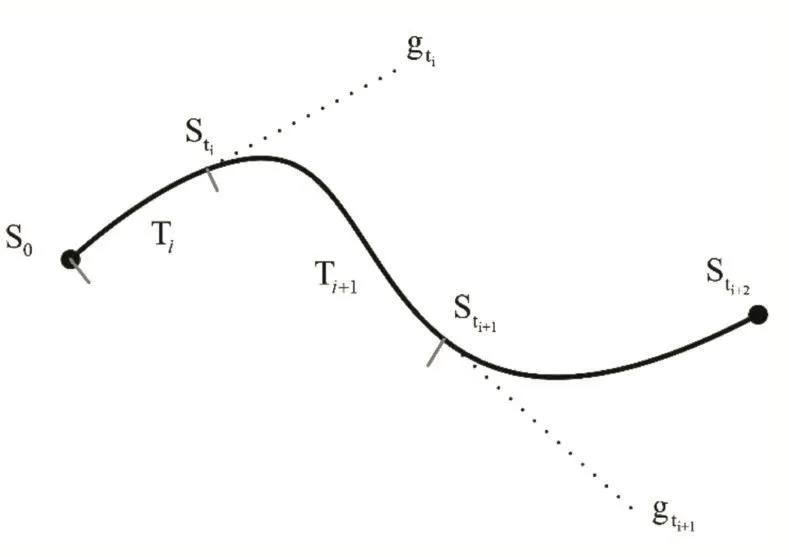
圖2 連續動作控制任務在時間上分解的示意圖
如圖2所示在軌跡跟蹤任務中,低層控制器直接與環境交互(質點),低層控制器的環境 sit=(xt,yt,vt,ut,xi,yi,vi,ui),其中(xi,yi,vi,ui)為高層控制器給出的第i個間歇目標點,Ti為高層控制器給出的第i個執行時間,在時間Ti中低層控制器每個時刻t都給出一個動作at=( ft,gt)直接作用于質點。高層控制器的環境高層控制器給出的動作ai=(xi,yi,vi,ui,Ti)。
HDDPG的學習過程分為兩個階段,第一個階段是低層控制器的學習,第二階段是高層控制器的學習。低層控制器的學習是一個典型的DDPG學習過程。其中環境s=(x ,y,v,u,x′,y′,v′,u′) ,每次采集樣本都是隨機生成一個新的s,每次迭代固定步數為40。低層控制器的每步獎勵函數為
3 結果分析
模型最終學會控制低層控制器去跟蹤這些軌跡。圖11展示了HDDPG和DDPG在軌跡跟蹤任務中的累積獎勵隨著訓練時間的變化。DDPG模型收斂于一個較低的累積獎勵值并且具有較大的波動,而HDDPG則能較快的收斂于一個很高的累積獎勵值,同時具有較好的穩定性。x軸是訓練時間,單位是小時,y軸是累積獎勵。這里累積獎勵是10個HDDPG和10個DDPG模型的累積獎勵的平均值。
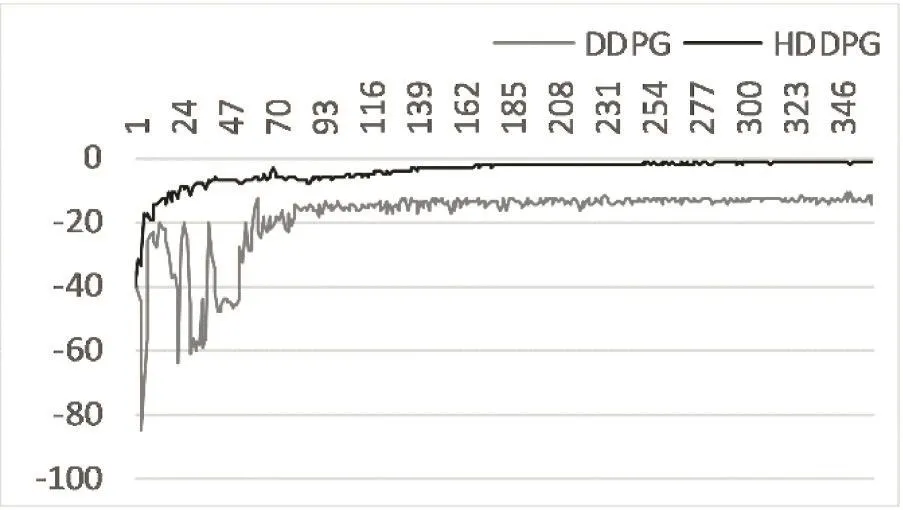
圖3 DDPG與HDDPG在軌跡跟蹤任務學習過程中累計獎勵變化
圖4描述了HDDPG模型與DDPG模型在軌跡跟蹤任務中最終位置與目標點的距離。從圖中可以看到,在DDPG模型中,7個模型不能收斂,3個收斂的模型也沒有到達終點附近(距離終點歐氏距離0.1以內算作到達附近)。在HDDPG中,最終有6個模型能夠到達終點附近,剩下4個模型進行了無效的探索。值得注意的是,如果在運行過程碰到環境范圍邊界,則本回合直接結束。
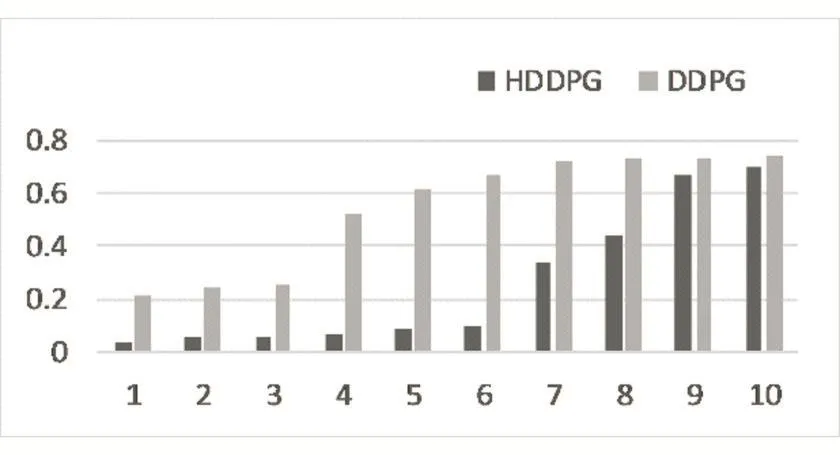
圖4 DDPG與HDDPG任務完成時末端與終點距離
4 結語
HDDPG與普通DDPG相比,在連續控制任務中具有更快的收斂速度和更好的效果。其原因可歸于兩點,第一點是HDDPG直接在高層空間進行探索。高層控制器輸出的是低層控制器的間歇目標和持續時間,其中微小的變化可以導致最終軌跡出現較大的不同,具有更高的探索效率,有利于模型快速的探索環境信息。這一點和遺傳算法中的間接編碼有些類似。同時高層控制器模型的值函數的復雜程度隨著層級的提高而提高,將值函數以層級的結構表示有助于學習得到更準確的值函數,從而進一步提升復雜運動控制的性能。
第二點在學習過程中,估值網絡通過時間差分從后往前的迭代來逼近正確的值函數。如果動作序列較長,則迭代的次數較多,所需的計算資源也較多,訓練所需時間長。而對于高層控制器的估值網絡來說,只需產生個位數的間歇控制動作,具有較短的動作序列,減少了計算所需資源。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2020年6期)2020-02-01 06:28:50
中國生殖健康(2019年11期)2019-01-07 01:28:02
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
