電梯乘客交通分布的混合算法求解
2019-01-23 09:52:06金逸喬
微型電腦應用 2019年1期
金逸喬
(上海交通大學 電子信息學院,上海 200240)
0 引言
電梯作為垂直交通運輸的重要工具,隨著文明的不斷發展,早已成為了人類生活必不可少的部分。根據國家質量監督檢驗檢疫總局“關于2016年全國特種設備安全狀況情況的通報”顯示,截至2016 年底,全國在用電梯登記數量為493.69萬臺,我國電梯保有量、年產量、年增長量均為世界第一。面對如此龐大且復雜的輸送能力需求,如何通過改進電梯的配置方案以及服務性能來應對這些需求,一直是電梯行業專家以及各國學者研究的課題。
電梯的交通客流情況,是各項研究的基礎數據。通過對客流情況的分析,可以調整和優化電梯的群控系統,可以研究不同建筑的客流特性,可以檢驗和預測電梯的配置是否合理。電梯交通客流數據包含的內容非常寬泛,理論上來說包含了乘客乘坐電梯發生的交通行為的所有數據。其中“每層進出電梯的乘客數”,能直接反映電梯乘客在建筑中交通狀況,同時獲取手段也比較多,因此在研究中較為常見。以往的研究中,側重點通常是電梯群控系統的優化,因此每層進出電梯乘客數能夠符合要求。但如要進行電梯配置規劃及建筑客流分析,評價方式一般是一個絕對指標,此時就需要討論電梯及乘客在樓層間的交通情況,即電梯交通分布的信息。
隨著電梯遠程監控與服務系統的大力發展[1],每層進出電梯的乘客數已經可以通過該系統記錄的電梯稱量裝置的相關數據來獲取,但是電梯交通分布信息難以通過簡單的方式大規模獲取。鑒于現狀,本文以每層進出電梯的乘客數為基礎,建立了乘客交通分布求解的模型,然后通過遺傳算法(Genetic Algorithm)與列文伯格-馬夸爾特算法(Levenberg-Marquardt Algorithm)結合的混合算法來求解模型,最終獲得電梯乘客交通分布信息。
1 電梯乘客起訖點矩陣
起訖點是一個在交通運輸規劃中被廣泛提及的概念,其描述的是交通網絡中從起點(origin)到終點(destination)的相關信息。而起訖點表,或稱OD表,就是一個交通網絡中所有起點與終點間產生的交通流量構成的表格,是交通網絡的出行分布交通量的直觀表達,體現了用戶對于交通網絡的基本需求。根據起訖點數據表構成的起訖點矩陣是進行進一步的交通規劃必不可少的基礎數據,是進行交通流量分配的前提,也是進行交通管理與控制優化的重要基礎[2,3]。一個存在n個區域(即n個起點,n個終點)的交通網絡,其起訖點表如表1所示。
電梯作為垂直運輸工具,在許多地方與水平方向的交通運輸工具有著相似點。電梯運行產生的乘客交通量同樣存在起訖點的概念并形成一定的交通分布,在電梯的運行過程中,電梯運行的樓層是對交通區域的劃分,每個交通區域的發生量與吸引量相應的是每一層進入電梯的乘客數與離開電梯的乘客數,乘客通過在起點樓層與終點樓層間的移動構成了一張起訖點表,表的形式與表1一致,由ODij組成的n×n階的矩陣就是電梯乘客起訖點矩陣。
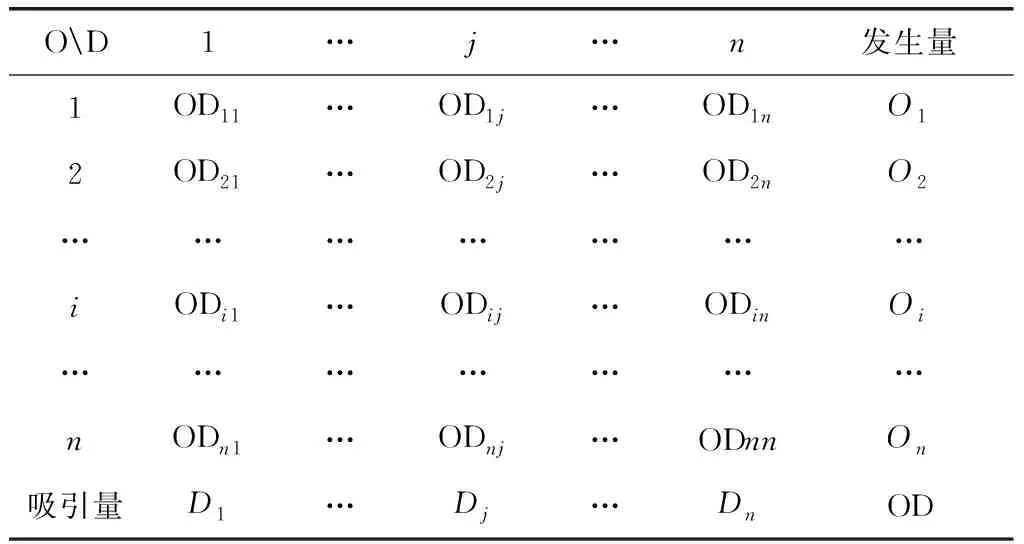
表1 起訖點表
求電梯乘客交通分布的問題可以作如下描述:在一個服務n層樓的電梯群組中,設Bi表示第i層進入電梯(boarding)的乘客數,Ai表示第i層離開電梯(alighting)的乘客數,xij表示從第i層進入、第j層離開的電梯乘客數,其組成了n×n階的矩陣X。其簡單示意如圖1所示。
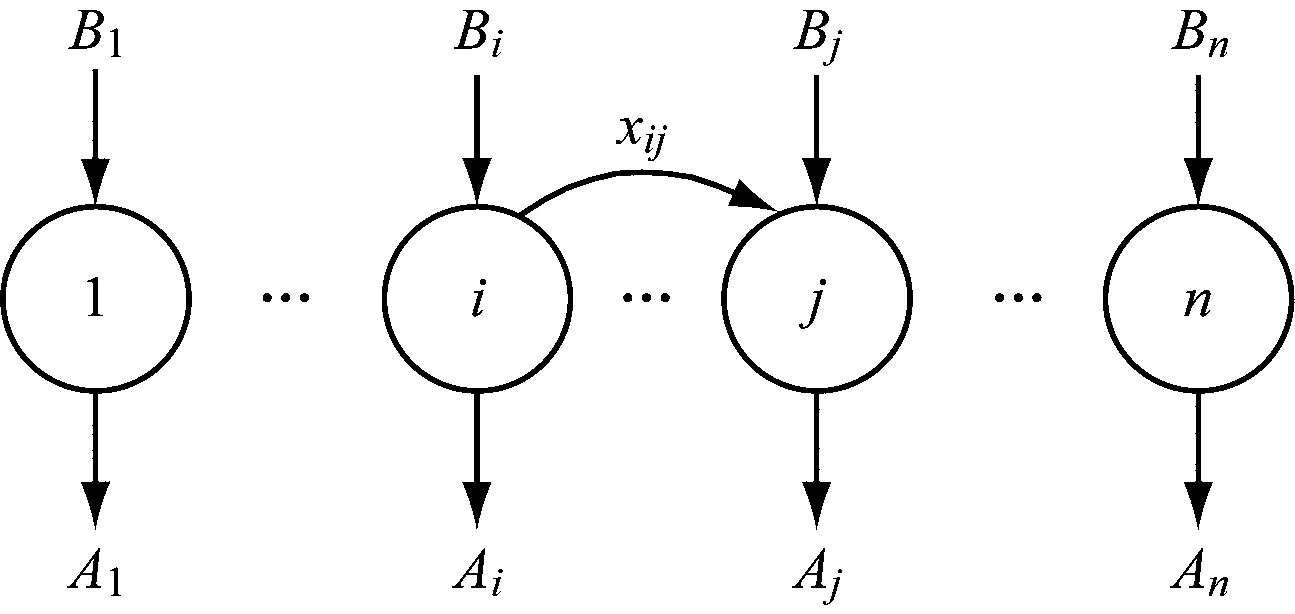
圖1 電梯運行起訖點描述示意
根據起訖點的概念,Bi、Ai與xij具有如下關系如式(1)。
(1)
上述問題中,Bi和Aj是我們通過電梯遠程監控與服務系統得到的數據,共有2n個已知量,而xij為未知量,共n2個,式(1)可以組成2n個線性方程,一般情況下,電梯乘客基本不會發生同一樓層進出的情況,即當i=j時xij=0,因此實際問題中未知量的個數可以減小為n(n-1)個,即要求的乘客起訖點矩陣X是個對角矩陣。同時,實際問題中,電梯服務層數超過3(即n>3)時,n(n-1)>2n,因此僅上述條件,無法求得xij。
2 電梯乘客起訖點矩陣的最大熵模型
Willumsen提出了的一種在交通運輸領域推算起訖點矩陣的模型——最大熵模型。將每個起訖點對的一次出行看作一次隨機的事件,每種可能出現的起訖點狀態都相應存在一個出現概率,出現概率最高的就是實際存在的起訖點狀態[4]。
根據最大熵理論,在一個有n個區域的交通網絡中,從起點i到終點j的交通流量Tij就表示第ij個事件的發生次數,而網絡的總流量T,即事件的總次數就是式(2)。
(2)
根據特定的排列形成Tij的概率就是式(3)。
(3)
按照最大熵原理的思想,實際存在的Tij是使W(Tij)熵值最大的矩陣。因此,將其存在概率設為目標函數,為方便求解,目標函數設為式(4)。
(4)
根據斯特林公式(Stirling approximation)lnx!≈xlnx-x,式(4)可以化簡得式(5)。
(5)
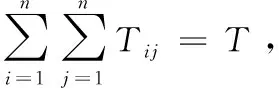
(6)
(7)
Tij≥0
(8)
α=1,2,…,m
(9)
i,j=1,2,…,n
(10)
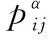
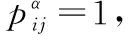
(11)
(12)
(13)
i≠j
(14)
i,j=1,2,…,n
(15)
其中,Bi是第i層離開電梯人數,Aj是第j層離開電梯人數,在實際問題中,同一層上下電梯的情況可以忽略,因此令i≠j,由xij組成的對角矩陣X就是所要求得的起訖點矩陣。
針對上述基于最大熵模型表述的優化問題,是一個帶約束的非線性優化問題,無法直接求解。易知(11)為凸函數,因此利用拉格朗日乘數法(Lagrange Multiplier Method),構造拉格朗日函數:
(16)
根據庫恩-塔克條件(Kuhn-Tucker Condition),最優解通過計算L(xij,λ)對xij的偏導數,即式(17)。
(17)
可得式(18)。
xij=e-1-λi-λn+j
(18)
根據式(12),(13),(14)和(18),可得式(19)。
(19)
上述方程組是以拉格朗日乘子λ=(λ1,λ2,…λ2n)T為變量,共有2n個未知數的非線性方程組。那么,原問題就可以通過求解拉格朗日乘子,再代入式(4-23)來求得xij和X即起訖點矩陣。
傳統的求解方法是迭代法數值求解。以最典型的牛頓法為例,其求解方法如下。建立方程組F(λ)式(20)。
(20)
牛頓迭代格式為式(21)。
λk+1=λk-[J(λk)]-1F(λk)
(21)
其中,k為迭代次數,J(λ)為F(λ)的雅克比(Jacobi)矩陣。迭代的算法如下。
Step1:給定初始值λ0,和精度閾值ε>0,并令k=0;
Step2:計算F(λk),J(λk);
Step3:求解線性方程組J(λk)Δλk=-F(λk),得Δλk;
Step5:計算新的迭代點λk+1,λk+1=λk+Δλk;
Step6:令k=k+1,轉至Step2。
3 混合算法求解最大熵模型
求解最大熵模型的傳統牛頓法在求解中有著不足:迭代過程中計算矩陣必須是非奇異矩陣。而在實際問題中,其最大的限制是必須給出初值。但考慮到實際的電梯乘客分布問題中,針對每一次采集到的電梯進出人數信息,是無法給出初始分布的,這也就意味著沒有辦法給出符合實際情況的初值,因此牛頓法包括其他一些改進的牛頓法難以適用。針對這個問題,本文提出一種遺傳算法(Genetic Algorithm)與列文伯格-馬夸爾特算法(Levenberg-Marquardt Algorithm)結合的混合算法來求解。遺傳算法的全局尋優能力強,能夠在缺少初值信息的情況下,獲得一個較優的數值解[6]。以此較優解為初值,利用列文伯格-馬夸爾特算法開始迭代,能夠以良好的速度和精度獲得最優解。這樣混合算法可以避免遺傳算法收斂慢的問題,同時能夠在實際問題中產生合適的初始值并快速求得模型的解。
遺傳算法的各項操作如下:
(1) 目標函數和適應度函數
首先要確定遺傳算法的目標函數。本文基于式(19)和式(20)構造目標函數如下式(22)。
(22)
式中,λ=(λ1,λ2,…λ2n)T,且i≠j。
適應度函數為式(23)。
N(λ)=Cmax-M(λ)
(23)
式中,Cmax取一個M(λ)最大估計值,根據實際問題的情況而定。
(2) 編碼方式及種群初始化
本文采用浮點數編碼。考慮到二進制編碼或格雷碼編碼的長度較大,計算量會增大,而對于本問題,變量的取值有負數存在,需要搜索的范圍較大,因此綜合相應的選擇、交叉與變異方式,確定采用浮點數編碼。初始種群通過隨機的方式產生,種群規模需要根據不同情況進行設計,會由于實際問題中電梯的樓層數而改變,但是原則上,考慮到混合算法的目的是通過遺傳算法輸出一個供LM算法使用的初始值,因此種群規模不宜過小,否則會對全局搜索產生影響。
(3) 適應度計算
算法需要通過個體適應度來判斷個體的優劣程度,來決定優秀個體的遺傳。適應度比例參數是把適應度函數所返回的適應度值轉換為適合于選擇函數使用范圍的值。本文通過個體適應度值的排列順序而不是個體適應度值的大小來衡量個體的優劣,最適合個體的排序為1,次最適合個體的排序為2,依此類推,這樣可以消除原始適應度值的影響。
(4) 選擇
選擇運算,又稱為復制運算。是在當前群體中選擇適應度較高的個體按某種規則或模型遺傳到下一代群體中。在本文中采用輪盤賭規則,即與適應度成正比的概率來確定各個體復制到下一代群體中的數量。具體的操作過程是:首先,計算出群體中所有個體的適應度值的總和;其次,計算出每個個體的相對適應度大小,每個個體都會在某個概率區間內,該區間表示個體會被遺傳下去的概率大小,所有區間的概率值總和為1;最后,產生一個0~1之間的隨機數,通過判斷該隨機數落在上述哪一片概率區間來確定該各個體所對應的被選中的機率。
(5) 交叉
交叉運算是遺傳算法中產生新個體的主要操作過程,它以某一概率相互交換某兩個個體之間的部分染色體。本文采用如下交叉的方式:在1到變量個數之間選擇兩個隨機數m和n,在第一個父輩中選擇序號小于或等于m的向量項,在第二個父輩中選擇序號在m+1到n的向量項,序號大于n的向量項也來自于第一個父輩。這樣可以有效提高遺傳算法的搜索速度,為盡快得到初始值,轉到LM算法做準備。
(6) 變異
變異運算對個體的某一些基因編碼串中的基因按某一概率進行改變以產生新的種群,指明了個體在子種群間的遺傳。本文采用基本位的方式進行變異。
(7) 算法終止
本文考慮的是通過遺傳算法得到LM算法的初始解,避免遺傳算法陷入局部過慢的收斂中,因此需要根據實際問題中不同的情況設置算法終止條件,一般通過設置進化代數限制來實現。
綜合上述分析,結合LM算法后,整個混合算法的步驟是:
Step1:遺傳算法初始化種群;
Step2:遺傳算法求解,得到局部最優解及變量值;
Step3:變量作為初始值輸入LM算法作為初始迭代點λ0;
Step4:設置LM算法初始步長因子μ0,步長調整因子v>1,精度閾值ε>0,并令k=0;
Step5:計算F(λk),J(λk);
Step7:求解方程組(J(λk)TJ(λk)+μkI)Δλk=-J(λk)TF(λk),得Δλk
Step8:計算F(λk+Δλk),如果F(λk+Δλk)>F(λk),則轉至Step9,否則轉至Step10;
Step9:令μk=vμk,轉至Step7;
4 實例分析
通過前文提及的電梯遠程監控與服務系統采集了某醫院病房大樓電梯的每層進出電梯乘客數,采集時段是一個工作日,從電梯啟動到電梯停運為止,如表2所示。
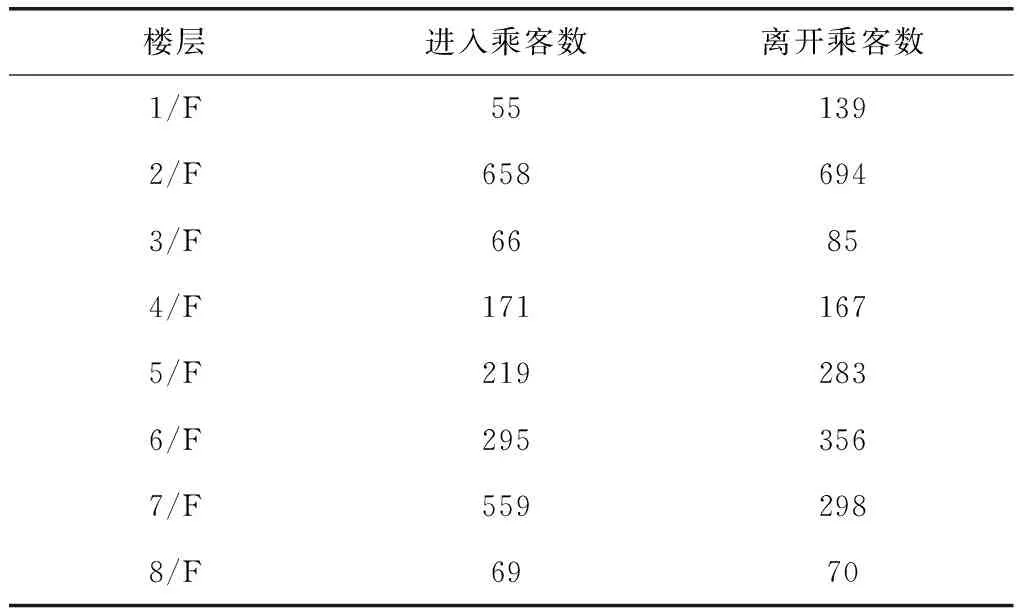
表2 某大樓一天年內進出電梯的乘客數據
使用混合算法求解最大熵模型,遺傳算法的相關參數為:種群規模POPSIZE=160,交叉概率PCROSS=0.8,變異概率PMUT=0.15,終止代數MAXGENS=400。400代進化結束后,算法結果如圖2所示。
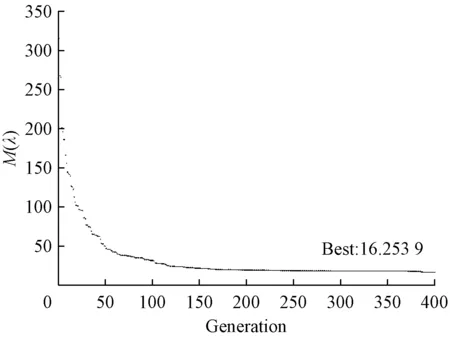
圖2 遺傳算法結果
以遺傳算法的結果作為初始值,開始LM算法。結果如圖3所示。
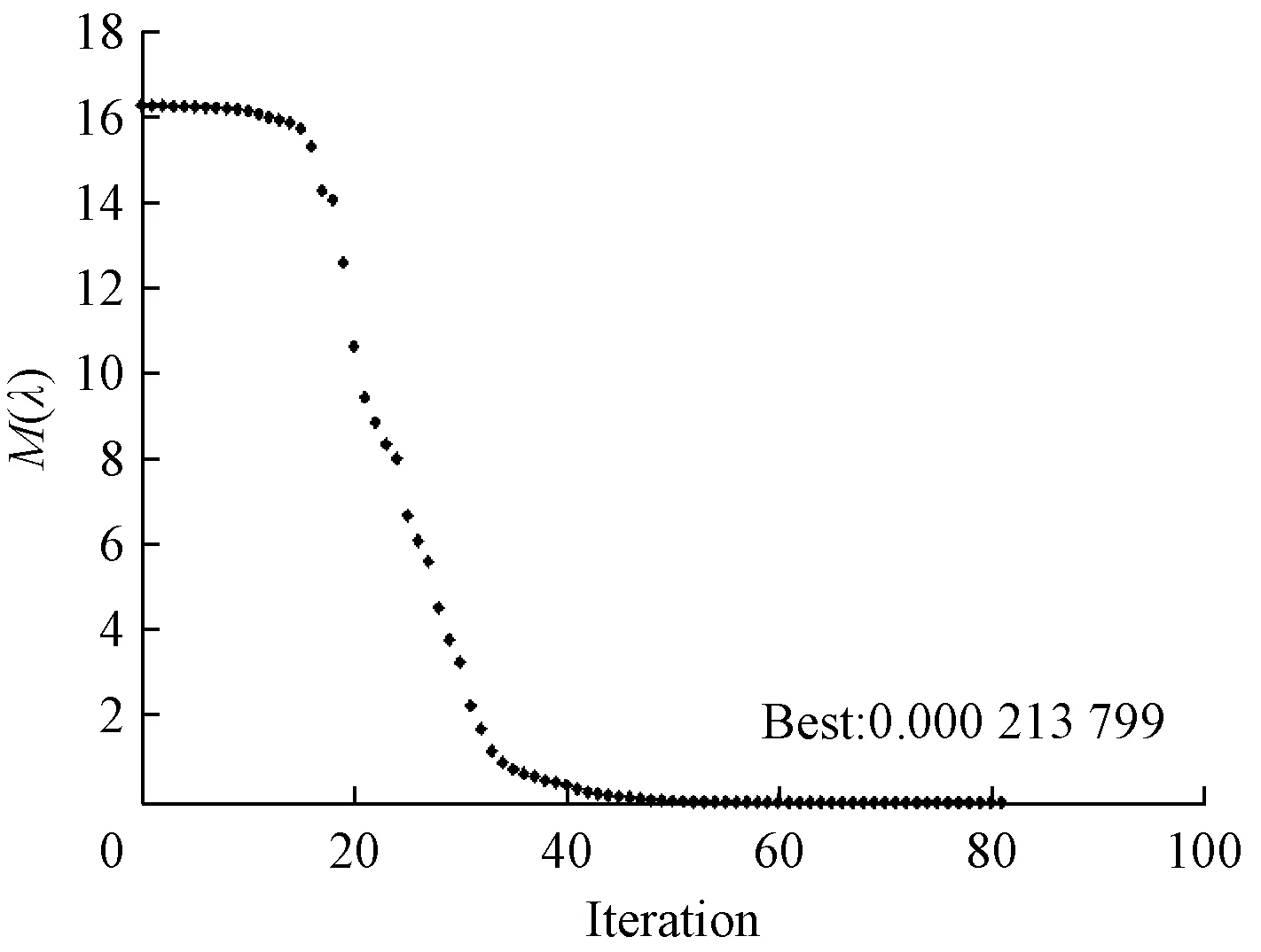
圖3 LM算法結果
將LM算法得到的變量值代入,最終求得,大樓的乘客交通分布如表3所示。
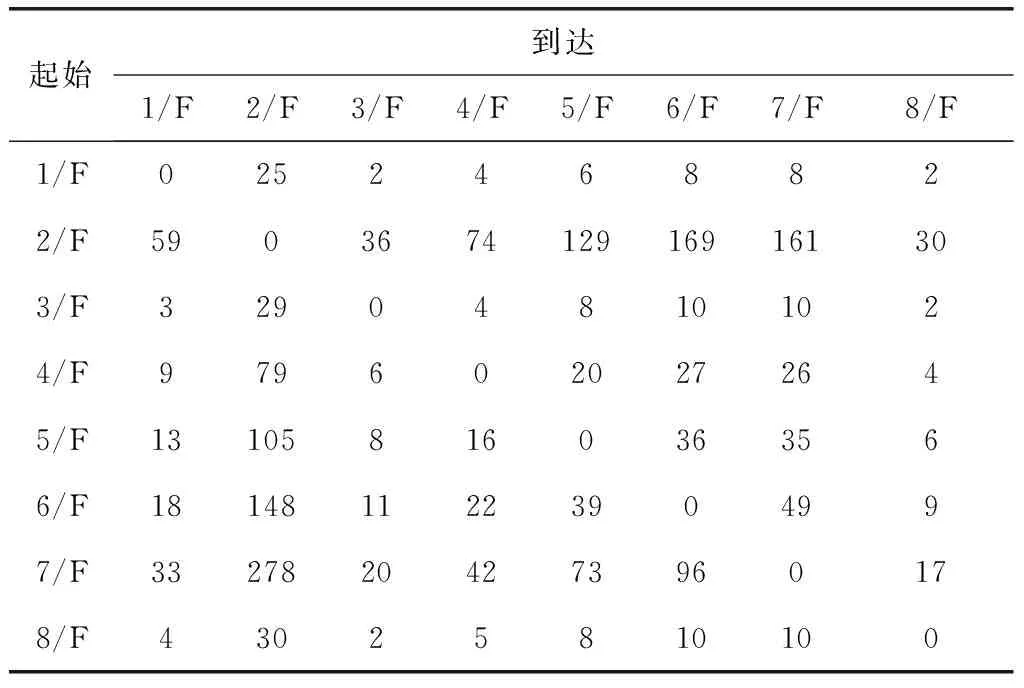
表3 電梯乘客交通分布表
5 總結
作為電梯群控系統優化、電梯配置規劃和建筑客流分析的基礎,電梯乘客交通分布的情況是一個重要的信息。本文在最大熵模型的基礎上提出了遺傳算法和LM結合的混合算法,求得電梯乘客交通分布,可以作為群控仿真、電梯配置規劃的輸入數據,無需進行費時費力的人工調查,有著很強的實用性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國品牌(2019年10期)2019-10-15 05:57:12
小學生學習指導(低年級)(2018年3期)2018-01-31 02:18:58
光學精密工程(2016年6期)2016-11-07 09:07:19
小學生時代·綜合版(2016年7期)2016-05-14 17:53:49
核科學與工程(2015年4期)2015-09-26 11:59:03
小說月刊(2015年11期)2015-04-23 08:47:36
小說月刊(2015年4期)2015-04-18 13:55:18
