人工蜂群算法優化的特征選擇方法*
2019-02-13 06:59:20巢秀琴
計算機與生活 2019年2期
巢秀琴,李 煒
1.安徽大學 計算智能與信號處理重點實驗室,合肥 230039
2.安徽大學 計算機科學與技術學院,合肥 230601
1 引言
隨著大數據時代的到來,人們獲得的數據量和數據維數日益龐大,維度災難隨之而來[1],高維數據中往往包含成百上千個特征,然而,這其中包含的許多無用以及被噪聲污染過特征,不僅對分類算法的效果沒有幫助,反而會增加計算復雜度和算法執行的時間,給數據的分析和整理帶來極大的困難。特征選擇就是為了能夠有效地解決這些問題而提出的一種方法,其從原始特征集中提取特征子集,去除冗余特征和無關特征,實現特征維數的有效約減,提高后續數據處理的效率和預測準確率[2]。
按照特征子集生成方式,特征選擇方法可以分為三類:(1)全局最優;(2)啟發式搜索;(3)隨機搜索。全局最優方法屬于窮舉類的算法,通過遍歷特征空間內的所有組合進而找到最佳的子集組合,啟發式搜索包括序列向前和向后選擇,時間復雜度較全局搜索小,隨機搜索包括隨機方法和概率隨機兩種方法,該方法結合進化算法對所有的特征子集進行進化選擇,能夠很大程度上加快搜索的進程。
人工蜂群算法(artificial bee colony algorithm,ABC)是一個由蜂群采蜜的行為所啟發的群智能進化算法[3],在2005年由Karaboga小組為優化代數問題而提出。該算法通過模擬自然界中蜂群的采蜜行為來尋找優化問題的近似最優解集合,具有初始參數少,步驟簡單等優點。
由于特征選擇中存在兩個相互矛盾的目標,即最小化分類錯誤率和最小化特征子集大小,因此,特征選擇可以看作一個多目標優化問題,可以使用多目標人工蜂群算法來解決此類問題。Palanisamy與Kanmani在2012年首次將單目標人工蜂群算法用來解決特征選擇問題[4],但是該算法采用傳統的單目標人工蜂群算法,僅僅使用分類準確率作為評價標準,在數據量日趨龐大的現代,僅僅優化一個目標忽略了選擇特征數在實際應用中的重要性,無法滿足不同的優化需求。在該算法的基礎上,2017年,Hancer和Xue首次將改進的多目標人工蜂群算法應用到特征選擇中,提出了一種基于人工蜂群優化的pareto前沿面特征選擇方法[5],該算法通過改進算法中的引領蜂和跟隨蜂變異算子,以達到同時優化分類準確率以及減小選擇特征數的目的。Xue的算法中首次將多目標算法應用到特征選擇中,并且該算法考慮到了特征選擇問題中特征數的同等重要性,但其存在著后期收斂壓力偏小導致算法收斂過慢,無法找到算法最優值點的問題,同時算法在處理局部最優值點上存在不足而引起收斂精度下降。
由于Knee Points在提升算法進化速度以及最后得到的結果方面具有優越性[6],其對于增強特征選擇分類準確率和減小分類特征數也具有一定的作用[6],因此,本文設計了一種基于Knee Points的改進多目標人工蜂群算法,將Knee Points引入引領蜂以及改進跟隨蜂過程中,在兩個階段優先開采Knee Points,并改進算法適應度值的計算,在算法執行過程中采用外部集合記錄與維護pareto最優解。在11個UCI分類測試數據集上的結果顯示,本文提出的基于改進多目標人工蜂群算法的特征選擇方法對提升分類準確率以及消減數據集冗余特征數具有顯著作用。
2 基本內容介紹
2.1 人工蜂群算法
人工蜂群算法是受蜜蜂采蜜機制啟發而提出的一種群智能進化算法,在原始ABC算法中蜂群一共分為引領蜂、跟隨蜂和偵查蜂3類。蜜源代表了優化問題的一個可行解,蜜源的質量對應可行解的適應度,也就是目標函數的函數值[7]。
首先初始化大小為SN的種群,種群初始化公式如式(1)所示[8]。

式中,j=1,2,…,D;i=1,2,…,SN;SN為蜜源的個數;D為個體向量的維度;lbj為第j維下界;ubj為第j維的上界。初始化后,種群中3類蜜蜂開始搜索[9]。
(1)引領蜂。它的數量是總共蜜源數量的一半,并一直處于較好的一半蜜源位置上,以獲得最好的解,它們在自身蜜源左、右按照式(2)開采蜜源[10]:

式中,Vij為新蜜源的位置;xij和xkj分別為蜜源i和蜜源k的第j維位置;Rij為[-1,1]間的隨機數[11]。
引領蜂找到新蜜源后,依照式(3)計算其適應度,并留下適應度好的蜜源。

式中,f(xi)是蜜源xi對應的目標函數的函數值。
(2)跟隨蜂。該類型蜂群根據式(4)計算每個蜜源被選擇概率[12],并采用輪盤賭方式選擇較優蜜源并在其附近位置按照式(5)進行搜索,產生新蜜源[13]:

式中,k為依照輪盤賭方式選擇的較優蜜源,g為隨機選擇的不同于k的蜜源。
(3)偵查蜂。若某一蜜源連續limit代沒有被更好的解取代,則啟動偵查蜂,按照式(1)隨機產生新蜜源代替原蜜源[14]。
ABC算法通過這3種蜂群對解空間的反復搜索、轉換最終獲得最優解[15]。
2.2 多目標優化
在工程應用和決策過程中遇到的大多數問題皆可歸納為多目標優化問題,由于多目標優化問題的研究具有較強的實用性和較高的研究價值,因此對于該類問題的研究顯得十分重要。多目標優化問題可描述如下[16]:

式(6)中,fi(x)表示優化問題的第i個目標函數,n表示目標函數的數量,x表示優化問題中的自變量,ub、lb分別表示自變量x的上下限約束,等式Aeq×x=beq表示對自變量x的線性約束,不等式A×x≤b表示自變量x的非線性約束[17]。
2.3 特征選擇
特征選擇是一種典型的組合優化問題,其從N個特征集合中選出M個特征的子集(M≤N),去除冗余或不相關的特征,使得處理后的數據集不僅包含的特征個數更少,而且能夠提高分類算法在原有特征集合的分類性能[18]。
特征選擇按照評價函數與分類算法之間的關系,可以分為過濾式和封裝式。如圖1所示,過濾式的子集評價與分類算法無關,一般根據數據內部特性(如互信息、相關性)得到。封裝式的特征選擇方法使用特定的分類器算法進行評價,如圖2所示,產生的特征子集都通過特定的分類器進行評價之后再進行下一步選擇,該方法產生的子集與使用的分類算法有關。

Fig.1 Filter feature selection圖1 過濾式特征選擇

Fig.2 Wrapper feature selection圖2 封裝式特征選擇
2.4 Knee Points
在多目標優化算法中,Knee Points作為Pareto最優解集的子集中的解,如圖3所示,該類解在直觀上表現為Pareto前沿面上最“凹”的部分。在這些Knee Points附近,任何一維目標值的稍微減少都會導致其他維目標值的大幅增大。因此,雖然Pareto前沿面上的解都是互相非支配的,但其中的Knee Points要在一定程度上優于其他的解,從算法決策的角度來看,若沒有指定特定的偏好點,則Knee Points應當被優先選擇。文獻[7]中具體說明了Knee Points在增加多目標優化算法收斂性方面的效果,本文將特征選擇的兩個目標(最小化分類錯誤率和最小化選擇特征數)作為多目標的兩個目標,將Knee Points加速收斂的能力利用到特征選擇中,使得最終獲得結果在分類性能和選擇的特征數上都具有一定優勢。

Fig.3 Knee Points explaination圖3 Knee Points示意圖
3 基于改進多目標人工蜂群算法的特征選擇方法
為了將Knee Points加速收斂的能力應用到特征選擇中,本文首先提出了一種快速識別Knee Points的算法,并在多目標人工蜂群算法的引領蜂階段和跟隨蜂階段,使用Knee Points來引導整個種群的進化,在跟隨蜂階段,優先開發Knee Points,進而達到利用Knee Points加速整個種群收斂的目的,最后將改進后的算法結合5-NN分類器應用到特征選擇問題中并在多個UCI數據集上進行測試。
3.1 種群蜜源的編碼、解碼與評價
種群中每個蜜源對應特征選擇的一個解,蜜源采用離散編碼,如式(7)所示,每個解X中包含n個實數,n為對應數據集的總特征數,其中每一維xi代表是否選擇該特征。

對于每個蜜源的每個維度,規定:如果該維值大于給定的閥值(本文中設為0),則表示該維對應的特征被選擇;如果小于給定的閥值,則表示不選擇該維對應的特征。該過程為解碼過程。
將每個蜜源解碼轉換為對數據集中所有特征的選擇方案,也即解碼。之后,使用KNN分類器(K=5)對每個蜜源對應的選擇方案進行測試分類性能,并依照式(8)計算出該種選擇方案對應的分類錯誤率,其中,TP表示正樣本被預測正確的個數,TN表示非正樣本被正確預測的個數,FP表示正樣本被預測錯誤的個數,FN表示非正樣本被預測錯誤的個數。將分類錯誤率結合每個蜜源選擇的特征數作為衡量每個蜜源適應度值的兩個指標。

3.2 一種快速識別Knee Points的算法
識別Knee Points示意圖如圖4所示。在圖4中,首先,一條極線L由該層Pareto非支配面上的兩個極值點D和E(D點在第二維目標上擁有最大值,E點在第一維目標上擁有最大值)根據式(9)確定,式中xD、xE、yD、yE分別為D和E的橫坐標和縱坐標,將直線方程標準化為ax+by+c=0形式。接著,通過式(10)計算該層非支配面中的所有點到極線L的距離,式中a、b、c為標準化后極線L方程中的參數,xA和yA分別為點A的x軸和y軸坐標,并通過式(11)計算每個鄰域的大小,每個鄰域中距離極線L最大距離的點為Knee Point,式中,Range(j,g)表示第g代中第j維上的鄰域大小,fmax(j,g)表示第g代中第j維的最大值,fmin(j,g)表示第g代中第j維的最小值,rg為第g代自適應參數,用于自動調節鄰域大小,以實現算法整個種群的開采與開發上的平衡。由圖中示意可知,A點被識別為Knee Point,因為其在整個鄰域中到極線L的距離最大。

Fig.4 Diagram for recognizing Knee Points圖4 識別Knee Points示意圖

在識別Knee Points的算法中,通過調節r(g)改變鄰域大小會直接影響識別出的Knee Points的數量,影響算法種群的進化趨勢。為了平衡算法的開發和開采能力,本文設計了一種自適應變化的rg策略。在式(12)中,rg-1為第g-1代中鄰域控制因子,tg-1為第g-1代中Knee Points占Pareto集合的比例,T為預先設置的閥值,用于控制Knee Points比例的上限。初代中,t0設置為0,r0設置為1。

識別Knee Points算法流程圖如圖5所示。

Fig.5 Flow chart of recognizing Knee Points圖5 識別Knee Points算法流程圖
3.3 基于Knee Points的引領蜂精英搜索機制
文獻[19]中指出:算法種群中的精英解是種群中質量較好候選解,在算法對解空間的搜索過程中,充分利用精英解的特征信息引導其他候選解,能夠有效促進種群的進化。在原始MOABC(multiobjective artificial bee colony algorithm)算法中,引領蜂尋找優秀的蜜源,并進行記錄,之后由跟隨蜂進行開采,在此過程中,引領方向決定著整個種群的進化方向。原始MOABC[17]中,采用式(2)所示的方法進行引領蜂的搜索過程,其開發過程遵循完全隨機的原則,一定程度上能夠增強算法的全局搜索能力,但也存在著搜索方向隨機,搜索效率低下的問題。為此,本文重新設計了算法中引領蜂的策略,利用精英解的引導加快算法的搜索,參考了文獻[12]中的全局最優引導思想引入gbest個體帶領種群進化,從而實現對蜜源解空間的開發,加快種群進化速度提高種群多樣性。一方面,通過人工蜂群算法中已存在的基于鄰域的搜索機制,使得種群在搜索過程中保持了良好的局部尋優能力,同時,引入gbest引導種群的進化方向,帶領種群中的個體向著可能的最優方向搜索,與原始人工蜂群算法相比,較好地保證了算法對全局最優值的搜索能力,兩方面結合,本文中提出的算法,保證了算法種群局部尋優與全局尋優能力,且取得了非常好的平衡效果。基于以上,本文提出了基于Knee Point的引領蜂搜索機制,如式(13)所示。

式中,Vij為新蜜源的位置;xij和xkj分別為蜜源i和蜜源k的第j維位置且i≠k;xmj是當前蜜源的Knee Points集合中隨機選擇的蜜源m的第j維位置;Rij為[-1,1]間的隨機數;Tij為[0,2]間的隨機數。
3.4 基于Knee Points的跟隨蜂搜索機制
多目標函數的評價值包含至少兩維的適應度值指標,式(4)所示的單目標ABC算法中的蜜源選擇概率的計算方式已經不適用于多目標MOABC算法的跟隨蜂過程,而且由于算法種群后期進化壓力的缺失,在跟隨蜂階段優先選擇Knee Point作為鄰域搜索的對象,能夠很大程度上提升種群的進化速度。基于以上兩點,本文中提出了一種將二元聯賽方法[17]應用到引領蜂的選擇過程并優先考慮Knee Points的搜索機制,如圖6所示。首先整合已有信息得到每個蜜源的適應度值,分為三方面:(1)該蜜源所在的Pareto面序號;(2)該蜜源是否為種群中的Knee Point;(3)該蜜源的擁擠距離。接下來,根據該適應度對每個蜜源進行排序,分配優先級序號,適應度越好的蜜源優先級越高。最后,使用二元聯賽方法[17],隨機選擇兩個蜜源進行比較,將優先級高的蜜源加入待進化蜜源集合中,重復以上選擇操作,直到集合中保存指定數量的蜜源,最后根據式(5)使用跟隨蜂算子對ES(external strategy)中的蜜源進行開發。
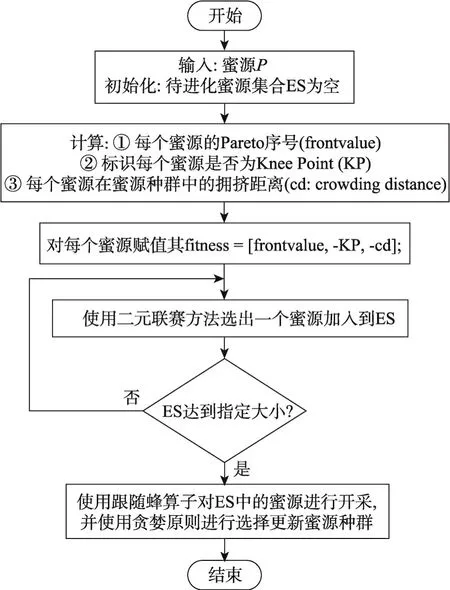
Fig.6 Flow chart of onlooker bee圖6 跟隨蜂算法流程圖
3.5 基于Knee Points的改進多目標人工蜂群算法的特征選擇方法流程
本文首先提出一種基于Knee Points的改進多目標人工蜂群算法,主要工作為:(1)設計一種快速識別Knee Points的算法;(2)將Knee Points應用到引領蜂過程中,幫助引領蜂確定進化的方向;(3)提出一種整合適應度值的方案,并將其與二元聯賽方法結合應用到跟隨蜂的開采過程中;(4)改進跟隨蜂階段,在該過程中優先選擇非支配前沿面上且具有較大擁擠距離的Knee Points蜜源進行開采,確保算法更快地找到最優的蜜源。最后將該改進算法應用到特征選擇問題中,具體流程如下。
步驟1初始化。給出算法的相關參數,其中包括算法種群大小N;最大迭代次數Iter;識別Knee Points算法中的參數r0和t0;每個蜜源可嘗試的最大失敗開采次數limit。并根據數據集信息隨機產生數目為N的初始種群,其中每個蜜源的維度與數據集每個樣本的特征數一致,每個蜜源采用實數編碼。
步驟2按照3.1節所述對每個蜜源進行解碼和評價,計算該蜜源對應的分類錯誤率和選擇的特征個數作為該蜜源的適應度值。
步驟3根據式(5)和式(9)~(11)識別蜜源集合中的Knee Points蜜源,并記錄為KP。
步驟4進行引領蜂的開采過程,對每個蜜源按式(13)搜索產生新蜜源,使用貪婪選擇機制保存處于支配位置的蜜源,若兩個蜜源互相非支配,則隨機選擇。
步驟5根據3.1節計算每個蜜源的適應度,并添加到集合T中用來進行跟隨蜂開發過程。
步驟6根據式(5)進行跟隨蜂的開發過程,對步驟4中產生的集合T中每個蜜源進行開發,運用貪婪機制保存較好的蜜源。
步驟7根據式(1)進行偵查蜂過程對指定的蜜源重新初始化,代替原來的蜜源。
步驟8判斷是否達到預設的Nmax,若是,則輸出所有蜜源的第一層Pareto面上的蜜源作為結果;否則,轉至步驟2。
4 性能仿真和分析
4.1 數據集以及實驗參數設置
表1所示的是實驗中采用的11個UCI機器學習數據集的具體信息,包含二分類和多分類數據集,特征數規模從13到166,樣本數從32到1 212。該11個數據集具有一定的代表性,其中,Musk1數據集的特征數達到了166,十分考驗算法消除冗余特征的能力,該數據集上的選擇結果能夠充分代表算法在大規模特征數數據集下的優化效果;Wine數據特征數最少,為13,對這種特征數少的數據集,要求算法能夠精確識別非冗余特征,并要求具有足夠的跳出局部最優的能力,防止提前收斂;Hillvalley數據集具有最多的樣本數,在樣本數非常大的數據集上,算法的收斂速度顯得至關重要,同時,該數據集上的結果也顯示了算法解決過擬合問題的能力;Lungcancer數據集只有32個樣本,使得算法很難在運行過程中達到充分的訓練,該數據集上的結果能夠充分驗證算法在樣本不足的情況下優化性能;其他數據集結合了以上數據集的優化難點,對算法的全面優化能力提出了更高當前要求,因此,在這11個數據集上的測試結果能夠較為全面地反映各種算法的性能指標。實驗仿真在主頻為2.93 GHz,內存為8.0 GB的PC機上實現。軟件環境為MATLAB R2013b。

Table 1 Description for datasets表1 數據集說明
為了驗證算法的有效性,將本文中的算法與MOPSO(multi objective particle swarm optimization)[20]、NSGAII(nondominated sorting genetic algorithm)[21]和PAES(Pareto archived evolution strategy)[21]3種經典多目標算法在上述11個UCI數據集上進行測試對比。算法具體參數如下,種群大小P=30,算法最大迭代次數T=100,對每種算法單獨運行40次后的結果進行求均值處理以公平比較。各種算法中的參數設置如下,KnABC(artificial bee colony algorithm based on Knee Points)中,蜜源最大可重復開采次數limit=60,用于識別Knee Points的自適應參數r0=1,t0=0,解碼中預值設置為0,大于0表示選擇對應的特征,小于0表示舍棄對應的特征。MOPSO中粒子最大速度vmax=0.6,慣性權重w=0.729 8,加速因子c1=c2=1.496 18。NSGAII中,變異概率mrate=1/n,n為種群個體的維度,也即對應的數據集的維度,交叉概率crate=0.9,PAES算法中的參數同上。上述所有算法都嵌套進封裝方式的特征選擇中,并采用五近鄰(5-NN)算法測試每個蜜源代表的特征子集優劣。
本文實驗中,參考機器學習中的實驗設置,每個測試數據集被劃分為訓練集和測試集。其中,訓練集占70%,測試集占30%,在訓練過程中,每一個蜜源代表一種特征子集選擇方式,通過5-NN分類器并采用十折交叉驗證[2]計算每一種特征子集選擇方式的分類錯誤率和特征選擇數以此代表該蜜源的適應度值,并在算法最后,在測試集上對這些蜜源進行測試并將得到結果作為最后算法得到的結果。
4.2 實驗結果分析
實驗中,KnABC與MOPSO、NSGAII以及PAES每種算法在11個數據集上分別運行40次進行測試,得到每次運行的第一前沿面,并將這40次運行得到的第一前沿面依照特征數計算分類錯誤率的平均值,該結果用于表示算法最后的性能,此方式能夠很好地避免算法的隨機擾動,同時將特征數和錯誤率作為兩個指標并作出相關對比圖能夠直接地展示算法的性能。
如圖7所示,是本文算法與3種對比算法在11個數據集上的結果。其中,X軸坐標表示選擇的特征數,Y軸坐標表示40次運行所得到的結果在X軸特征數下的平均錯誤率,其中分類錯誤率ErrorRate=,該公式具體含義已在3.1節中具體介紹。
圖7所示的11個數據集的結果圖像中,在所有數據集上,相較于選擇所有特征進行分類得到的結果,4種算法都能夠使用較少的特征數而實現較小的錯誤率,成功排除了部分冗余特征,提升了分類器的分類性能。與此同時,KnABC得到的結果在各個測試集上的最小錯誤率上均優于其他3種對比算法,充分驗證了本文算法的優越性。

Fig.7 Comparison between KnABC and contrast algorithms on 11 datasets圖7 KnABC與對比算法在11個數據集上的對比結果
對每個具有代表性的數據集進行單獨分析。German數據集是一個樣本數1 000,特征數24的二分類數據集,在該數據集上,與另外3種多目標算法的對比結果顯示,KnABC在相同的特征數下,實現了更小的分類錯誤率,而且與采用所有特征進行分類得到的錯誤率相比,本文算法提升了約10%的準確率,與此同時,消除了14個冗余特征,表示算法在實際分類應用中,能夠很大程度上減小分類算法的時間復雜度,提高分類效率。Hillvalley是一個特征數100,樣本數1 212的數據集,MOPSO和NSGAII的結果中特征數最小為1,相較而言,本文算法在該數據集上的最小特征數為7,在消減冗余特征方面,不如MOPSO和NSGAII,然而在減小錯誤率方面,本文算法明顯小于其他3種對比算法,該數據集上的結果顯示本文算法在數據集樣本數很大時,依然能夠獲得很好的效果。Lungcancer數據集是一個特征數56,然而樣本數只有32的數據集,在樣本數不足的情況下,已有的算法通常情況下無法通過已有的信息排除無效特征[2],但本文算法在選擇特征數為6的時候,得到了約10%的分類錯誤率,比采用所有特征進行分類的錯誤率低了46.56%,極大提升了算法性能,隨著選擇特征數的增加,分類錯誤率反而增大,該現象也間接表明了冗余特征對分類算法性能的巨大影響。Hillvalley和Lungcancer數據集上的結果表明,本文算法在面對樣本數差異非常大的數據集時都具有很好的優化作用。
數據集的特征數大小也是影響算法優化性能的關鍵,在11個數據集中,Musk1數據的特征最大,為166,在該數據集上,KnABC在最好的一次結果中,剔除了131個冗余特征,并將分類錯誤率從19.30%降低至3%左右,同時,KnABC在選擇的特征數和分類錯誤率方面均優于其他3種對比算法;特征數最少的數據集為Wine數據集,該數據集總特征數為13,采用所有特征進行分類時,其錯誤率為32.47%,使用4種算法對這些特征進行選擇之后,得到的分類錯誤率均小于32.47%,并且在分類錯誤率上,KnABC也比其他3種對比算法更優秀。
對于多分類數據集Zoo,從圖中的結果可以看出,本文算法在特征數為7時,得到了2.3%的分類錯誤率,小于其他3種對比算法的最小分類錯誤率,并且在特征數為1、3、4和5時,分類錯誤率均低于其他3種算法,但隨著選擇特征數的上升,本文算法在特征數為8時,分類錯誤率明顯增加,表明算法的穩定性還具有改進的空間。
在上述6種數據集上的單獨分析表明,KnABC面對特征數,樣本數多樣,以及多分類和二分類數據集時,都能取得良好的效果。
如表2所示,是4種算法在11個數據集上的最小錯誤率對比,其中加粗顯示的是最好的結果,從中可以看出在這11個數據集上,KnABC的結果都優于其他3種算法,表明本文算法在消除數據集冗余特征方面具有明顯作用,能夠極大地減小數據集的實際特征數,提高分類算法性能。

Table 2 Comparison of minimum error rate of algorithms表2 算法最小錯誤率比較 %
5 結束語
本文針對傳統分類算法中存在的缺陷,結合當今大數據的趨勢,分析當前分類算法面臨的特征冗余,維度爆炸等問題,提出了一種基于Knee Points的多目標人工蜂群算法并將其應用到特征選擇中,以去除數據集中的冗余特征,減小分類錯誤率,提高分類器性能。在11個UCI數據集上的結果顯示,本文算法在減小數據集特征數的同時能夠極大地提高分類的準確度,相較于采用所有特征的分類方式,應用本文算法削減特征數后,能夠大體上減小約10%的錯誤率,個別數據集能夠達到50%左右,與其他3種多目標經典算法對比結果顯示,本文算法也具有極大的優勢。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
