數字時代的法律實踐:一份人工智能法學課程大綱
2019-02-19 01:08:44凱文艾希禮楊安卓陳曉莉
法治現代化研究 2019年1期
[美]凱文·艾希禮 著 楊安卓 陳曉莉 譯
一、導 論
當前,法學院應該開設一種“人工智能(AI)與法律”研討班,為法律專業學生講授一些數字時代的法律推理和法律實踐的課程。“人工智能與法律”是人工智能/計算機科學研究的一個子領域,致力于設計能夠執行法律推理的計算機程序——計算模型。這些計算模型可以用于建立法律實踐和教學的輔助工具以及研究法律推理,從而促進認知科學和法理學的發展。今天,在一定的條件下,計算機程序可以根據法律條例進行推理,可以適用判例,甚至可以像律師一樣進行辯論。
我們應該在部分法學院開設關于“人工智能與法律”的研討班,這樣就能夠為學生講授有關法律和法律推理的基本技能,包括:①法律規則固有的模糊邏輯和語義歧義;②與法律規則本身同樣重要的對法律規則的推理;③ 從一般法律問題中辨認出重難點的挑戰;④關于法律規則基礎價值的爭論方式。
“人工智能與法律”的研究者從慘痛的教訓中吸取了經驗。正如每個程序員都知道,要讓程序執行一項任務,需要詳細地安排一系列步驟(或者通過機器學習提供許多帶標注的實例)。如果程序要將某些輸入轉換為某些輸出,如輸出一個法律結論和解釋,則需要詳細說明推理的每個步驟。在這個過程中,研究者需要解決學生在法律教育中發現或應該發現的所有問題。例如,研究者必須解釋學生們提出的這些問題:在法律規范中通常出現的某些概念沒有明確規定含義的情況;不明確法律規范有哪些例外的情況;法規的邏輯可能很模糊的情況;在解釋法規應該如何應用于問題時,還存在除了問題、規則、應用和結論(IRAC)之外其他有用的法律論證模式的情況;對某些案例而言,類推比另一些法律論證模式更有效的情況。
通過讓學生關注這些給試圖用計算機為法律推理建模的科學家們帶來麻煩的問題,學生就可以以一種新的方式學習有關法律和法律推理的基本原理。正如他們的研究論文所證明的,“人工智能與法律”研究者習慣性地“追溯至元問題”,他們使法律推理的過程清楚明確,而這些過程在法律教育中常常被隱晦地處理。他們具體化了過程的步驟,并用擴展的示例進行了說明。考慮到人類和計算機之間的認知差異,法律專業的學生不會像計算機一樣執行這些步驟,但是關注這些過程會使法律專業的學生對法律推理中的漏洞和誤區更加敏感,而這些漏洞和誤區正是法律推理所要解決的,結果便會提高學生認真閱讀法律資料的能力、準確起草法律文件的能力、合理管理法律風險的能力和有效管理信息的能力。
將計算模型與律師、法官和法律學生在日常實踐中實際執行的任務以及他們實際使用的文本聯系起來,是“人工智能與法律”的一個持續挑戰,越來越多的人正在應對這種挑戰。一些計算機程序正在幫助荷蘭的移民局根據大量的管理規定來處理客戶,同時向監管者提供信息,說明如何根據程序的執行來改進規定。計算機程序還從現代訴訟活動所產生的大量電子文檔中,學習選擇和聚類那些與當事人的訴訟理路最接近的文檔,這些文件的選取基于訴訟當事人對與證據和辯護相關或不相關的小組文件所做的標記。
今天,隨著電子發掘、①訴訟審前發現,是指處理當事人查閱對方當事人和其他人手中的材料請求,來披露事實和形成審理證據。電子發掘涉及審前發現中電子存儲信息的收集、交換和分析。大型訴訟通常涉及數以百萬計的電子文檔,這是對傳統的使用關鍵字搜索來檢索文檔,然后手動檢查它們的相關性的方法的一個挑戰。法律信息檢索、基于網絡的電子合同信息的語義處理、法律論證計算模型等技術的進步,學生在實踐中使用甚至依賴這些系統的機會正在增加。學生越來越精通計算機,他們從小就與互聯網相連,他們見證了IBM的“危險的沃特森”(JeopardyTM-winningIBMWatson)程序,這個程序能夠瞬間吃透數百萬頁的文本,回答問題比最優秀的人類選手更快、更準確。今天的學生相信,智能計算機在法律實踐中可以扮演更重要的角色。通過讓學生思考像沃特森(Watson)這樣的程序如何回答法律問題并解釋其答案,“人工智能與法律”研討班可以引發學生的這種興趣。研討班鼓勵學生思考法律推理和法律實踐的過程,以及這些過程如何利用信息。如下所述,鑒于法律服務和法律就業市場的發展,學生從計算機程序的角度思考是有用的。研討班還告訴學生一些新的數字文檔技術如何工作,它們能做的和不能做的,它們如何測量性能,它們如何評估技術主張,以及如何成為精明的消費者和技術用戶。
通過“人工智能與法律”研討班,本文為法律專業學生做好數字時代的準備提供了指導和案例。在介紹了人工智能科學及其在法律中的應用之后,本文給出了最新的“人工智能與法律”研討班的教學大綱。本文以《教學大綱》為框架,介紹了人工智能與法律課程的一些特點,闡明了“人工智能與法律”課程在法律實踐中關于用法律規范與案例進行推理、法律論證、數字文檔技術甚至規范等方面的重要教學經驗。
二、關于人工智能與法律概要
如前所述,人工智能是計算機科學研究的一個分支,其研究重點在于計算機建模行為,當人類執行建模行為時,行為通常被認為是智能的。②Semantic Information Processing (Marvin Minsky,ed.,1968).所謂智能行為的計算模型,是指能夠執行或模擬行為的計算機程序。“人工智能和法律”研究者建立了法律推理的計算模型,這些模型是執行或模擬法律推理的計算機程序。如果程序的輸入是對法律問題的描述,那么它的輸出可以包括法律問題的解決方案和解釋。法律問題的解決除了需要一個決定或預測之外,還經常需要合理的解釋。事實上,支持決策的論據可能比決策本身更重要,否則人類用戶無法判斷是否要依賴其給出的法律建議。對解釋和論證的關注是“人工智能與法律”對人工智能研究作出貢獻的一個關鍵領域。
像計算機程序一樣,計算模型可以按照程序的輸入、輸出以及將前者轉換為后者的中間步驟來描述。中間的一組步驟(或算法)將輸入的問題描述轉換為輸出。在指定AI程序的輸入/輸出(I/O))行為時,三個問題尤其相關:① 知識表示和搜索,即輸入和用于分析它們的信息如何在可以系統搜索的問題空間中表示?②推理控制機制,即在效率和相關性方面,對解決方案的搜索由什么支配?③ 學習,即為了提高性能,程序如何從錯誤和成功以及其他信息來源中學習?③Neil Stillings,Steven E.Weisler,Christopher H.Chase,Mark H.Feinstein,Jay L.Garfield,Edwina L.Rissland,Neil A.Stillings&Steven W.Weisler,Cognitive Science:An Introduction 140-142,177,192(2d ed.1995).
在“人工智能與法律”程序的案例中,只有少數能接受自然語言文本輸入的問題,或用文本表達的案例或法律規范。更多的情況是問題以專門的表示形式呈現,例如,作為專家系統④Donald A.Waterman&Mark A.Peterson,Models of Legal Decisionmaking14(1981)[“專家系統”是體現人類專家提供的專業知識和知識的計算機程序,使用人工智能技術為(用戶)提供推論]。產生的問題的答案,或作為問題中出現的維度因素列表,如加強或削弱一方聲明的陳規定型事實模式。⑤Kevin D.Ashley,Reasoning with Cases and Hypotheticals in HYPO,34 Int'l J.of Man-Mach.Stud.753,763-764(1991).類似地,程序知識庫中的規則可以用邏輯表達式和案例來表示,正如問題也可以用要素來表示。在討論一些具有代表性的“人工智能與法律”方案時,重點將放在如何系統地尋找解決辦法以及學習上,例如如何檢測案例文本中的因素或如何對法律規范的文本進行分類。
在理論上,以及往往在實踐中,人工智能或“人工智能與法律”程序的問題解決行為可以按照類似于應用于人類問題解決的相關性和性能度量來評估(例如在給定輸入下的預測準確度、覆蓋范圍、精確度、召回以及輸出的解釋的充分性)。此外,人工智能程序可能受到修改的圖靈測試,其中人類法官與源進行互動,向源提出問題和接收反饋。法官在對源的性質不知情的情況下,試圖確定源是人還是機器。⑥Amela McCorduck,Machines Who Think 70(2d ed.2004).
“人工智能與法律”程序的算法,即將輸入的法律問題描述轉換成輸出的解釋方案的一組中間步驟,這從法律教學的觀點來看可能特別有趣。在將法律推理過程分解為一組步驟的過程中,研究者明確了一些在教學或法理學陳述中經常被遺漏或未解釋的方面。程序的I/O行為的例子說明了運行中的法律推理模型,包括在問題環境中應用的步驟。這些例子突出了程序的成功和失敗之處,其中成功是指輸出符合我們從律師那里期望得到的智能行為,失敗是指輸出不那么符合上述智能行為。研究者利用一個漸進過程來構思如何提高模型的(法律)性能和擴展成功的范圍。通過I/O實例說明推理步驟、假設、成功與失敗,為學生提供法律推理過程的窗口。
三、教授法學專業學生“人工智能與法律”
“人工智能與法律”研討班具有教學價值的關鍵原因在于,“人工智能與法律”程序把輸入的法律問題轉化為輸出的解釋方案的步驟。研討班向法學院學生提供一些思考機會,讓他們思考人類法律推理是否能夠、如何以及如何很好地處理同樣的問題。
在觀察將法律推理過程分解為一組步驟的過程中,學生會意識到,在推理過程中,有些漏洞可能需要通過一些特殊的方法來“填補”,這些漏洞的細節是隱晦的、無法解釋的,有時甚至是不合理的。這些漏洞案例包括區分法律的困難問題和簡單問題,確定案件之間哪些相似點和不同點在法律上是相關的,分解相互沖突的規則,以及對規則背后的價值進行論證。“人工智能與法律”研究者在某種意義上并沒有填補這些漏洞來讓一些法律或法學學者滿意,但是他們已經在關注填補這些漏洞的問題以及實現工程化的過程,從而為某些目的充分地解決這些問題。法學院學生花時間和精力來觀察這些漏洞如何被填補是非常值得的。即使“人工智能與法律”研究涉及計算模型,一般沒有計算機編程經驗的非技術學生仍然可以通過學習模型和實例來提高他們對法律的理解。這些算法十分抽象地被描述為流程圖或文本描述的步驟集。
這些算法的例子在操作中是法律推理的直觀實例,法律學生可以從中學習。如前所述,自動法律推理程序的I/O示例說明了程序的成功和失敗。失敗是更有趣的,因為學生可以觀察人類智能如何填補漏洞,思考其對法律和“人工智能與法律”的影響。作為思維實驗,學生可以在一個漸進過程中(如擴展示例的解釋)參與構建如何提高程序(法律)性能的問題,從而設計出更好的法律推理計算模型。當然,它需要技術專家來詳細理解計算模型的知識如何表示(例如用邏輯形式表示)以及搜索、推理控制和學習如何實現。幸運的是,法律專業的學生不需要理解技術細節,就可以從法律推理的范例中學習。
如上所述,“人工智能與法律”研討班具有教學價值的第二個關鍵原因在于幫助學生理解現代法律實踐技術。由于當前越來越多的律師被要求評估、購買和依賴使用機器學習、⑦機器學習是根據經驗自動改進的計算機算法研究。Tom M.Mitchell,MachineLearning 1-2(1997).數據挖掘、⑧見后引[17][“機器學習算法……尤其適用于……可能包含可自動發現有價值的隱式規則的大型數據庫的數據挖掘問題(例如,從患者數據庫中分析醫療治療結果或從財務數據庫中學習信貸價值的一般規則)”]。自然語言處理和信息檢索的產品(例如在電子發掘中),對于非程序設計法律專業的學生來說,了解如何使用這些工具以及這些工具如何工作是非常有價值的。電子發掘工具將不僅很快可以被允許使用,而且需要達到專業的護理標準和大型企業客戶的要求。
盡管諸如從大型數據組中進行機器學習、數據挖掘或自然語言處理等技術很復雜,并且其摒棄了法律直覺,律師們仍將越來越多地必須選擇這些工具,并用它們或指導其他人使用它們、解釋它們的輸出,并向其他人(如法官)證明它們的可靠性和有效性。基于這些類型的模型和軟件產品,法學院的學生至少可以學習概念詞匯、技術如何工作的高級描述、測量性能的方法、度量的意義、模型捕獲了什么以及模型遺漏了什么。從以下方面進行思考的經驗將使學生了解針對法律職業的數字工具的消費者:① 對算法的高級描述;② 算法在何處工作以及在何處失效的實例;③ 測量性能的方法。
在過去的25年中,“人工智能與法律”研討班定期在哈佛大學、斯坦福大學、東北大學、芝加哥-肯特大學和匹茲堡大學的法學院開授。⑨見 后 引 [13]、[17] 、[23] 、[24] 。 自 1989年 以 來 ,Kevin Ashley一 直 在 匹 茲 堡 大 學 教 授 人 工 智 能 與 法 律 研 討 課 。通常,研討班主要集中讓學生學習在該領域主要渠道出版的可用文獻,這些渠道有如人工智能與法律(ICAIL)國際大會、⑩International Association for Artificial Intelligence and Law,http://www.iaail.org(last visited Apr.23,2013).法律知識與信息系統年會(JURIX)[11]Jurix,The Foundation for Legal Knowledge Based Systems,http://www.jurix.nl(last visited Apr.20,2013).和《人工智能與法律》雜志。[12]見Artificial Intelligence&L.,available atwww.springer.com/computer/aijournal/10506.這些文獻說明了法律推理的I/O實例和中間步驟。他們還指出了一個關于重要法律/教育挑戰相關的漏洞,人類推理者很容易跨越、躲避或忽視這個漏洞,而計算推理者需要特殊的技術來解決這個漏洞。有時,“人工智能與法律”研討班會聯合學習人工智能的法律學生和計算機科學研究生。這為法學院的學生提供了一個教學上非常寶貴的機會來練習向非法學院的學生解釋法律(以及讓研究生向非技術人員解釋計算機科學)。學生也獲得了與具有技術和技術頭腦的人進行互動的經驗,許多學生在實踐中,可能會在客戶或供應商中遇到這些人。
通過讓學生參與構建、應用或使用法律推理的計算模型或用于法律推理的某些方面。“人工智能與法律”實踐課程可以讓他們更進一步。斯坦福大學、東北大學、芝加哥-肯特大學、[13]在芝加哥-肯特大學,理查德·懷特(Richard Wright)教授使用SAGE教授了一門關于“計算機和法律推理”的課程:一個教學專家系統開發工具,一套他自己設計的計算機程序,使得快速、超文本驅動的綜合規則庫和案例庫的構建能夠代表法律知識并模擬法律推理,尤其是在法律領域。羅恩·斯塔德(RonStaudt)教授教授“司法和技術實踐”,讓學生參與構建基于網絡的工具(包括專家系統),以支持法律服務倡導者、公益志愿者和公益訴訟人。和匹茲堡大學的法學院已經開展了“人工智能與法律”實踐課程,為學生提供了使用適用于非程序員的軟件開發工具來開發專家系統的機會。實習活動可以作為“實驗室”的一個組成部分與“人工智能與法律”研討班結合在一起,也可以在下一學期跟進。無論有沒有編程技能的學生實際上都可以構建法律專家系統的組件,并且這樣做之后,他們將努力彌補差距。即使他們沒有跨越這個差距,他們也會了解到這個差距。
由于許多計算機程序都涉及一個不斷改進的設計過程,通過確定目標和子目標,并描述實現每一級別目標的一系列步驟,法學院的學生即使在不懂得編程語言的情況下也能夠從事高級設計任務,能系統地思考解決法律程序過程的法學院學生可以逐步分解問題,然后集中精力“發明”解決某個子目標的技術(例如一組步驟)。他們不需要通過編寫程序來學習描述這些步驟的過程或舉例說明這些步驟的過程。
計算機編碼中的實際編程只發生在過程的末尾,在任何情況下,它可能不需要特殊的技能。越來越多的工具可以使用,非程序設計專業的法律學生可以利用這些工具為實際的法律問題建立解決方案,從而慢慢落實他們的智能專家系統組件。最近,在喬治城法學院的“技術、創新和法律實踐”研討班上,學生們使用利奧塔邏輯(NeotaLogic)公司開發的工具在各個領域建立了法律專家系統,一些律師事務所也使用NeotaLogic來創建用于專業實踐的專家系統。[14]Press Release,Neota Logic,Inc.,Georgetown Law Students Challenge Tradition by Building Online Legal Advisors with Neota Logic (Apr.24,2012)available at,http://www.prweb.com/releases/neotalogic/irontechlawyer/prweb9438690.htm.沒有編程技能的學生也可以參與設計和使用注釋法律文本的方案(包括使用下文[15]見后引[40]。所述的論證圖解工具),然后它們就可以用于法律推理的計算模型,或者應用機器學習根據其法律意義對文本進行分類。例如,霍夫斯特拉大學法學院的“法律、邏輯和技術研究實驗室”的學生通過參加有關法律意見中的證據推理注釋和有關深入學習的經驗研究活動,從而學習法律推理。[16]Law,Logic&Technology Research Laboratory,http://www.lltlab.org(lastvisited Apr.23,2013).
四、“人工智能與法律”研討班教學大綱
“人工智能與法律”研討班的教學大綱包括兩個關鍵教學點,即從法律推理的逐步分解中吸取教訓和理解法律實踐的新技術。
(一)基于法律規范與案例推理的計算模型
教學大綱的第一部分“法律推理計算模型導論”的第一節包含一項豐富的調查和兩個與學生特別相關的解決法律問題的計算模型的早期實例,這些學生都上了第一年的侵權和合同課程。
埃德溫娜·里斯蘭(Edwina Rissland,中文名:李詩蘭)的調查向法學院的學生介紹了人工智能、人工智能在法律領域的應用以及法律推理的計算模型。[17]Edwina L.Rissland,Artificial Intelligence and Law:Stepping Stones to a Model of Legal Reasoning,99 Yale L.J.1957,1957-1958(1990).作者系馬薩諸塞大學計算機科學名譽教授,定期在哈佛法學院教授人工智能與法律研討課。除分配閱讀材料外,她還強烈建議法學院學生以及她的研究生(我是其中之一,我永遠感激這一機會)準備一份一頁的閱讀材料摘要,包括以下主要條目:① 對工作內容的簡要描述(即不超過兩到三句話);②STRE方法的長度;③ 方法的弱點;④ 與學生的某些項目、任務、任務或觀點相關的方法。我發現準備這些閱讀摘要總是很有幫助的,我請我的學生也做同樣的事情。這種模型的第一個例子是唐納德·沃特曼(Donald Waterman)的專家系統,該系統使用啟發式規則(基于專家經驗的拇指法則)來給出解決產品責任索賠問題的建議。[18]Waterman&Peterson,見前引④。唐納德·沃特曼是人工智能的先驅,他的論文項目模擬了撲克賭博。第二個樣本模型由安妮·加德納(Anne Gardner)所提出,它分析了學生在第一年的侵權和合同課程中遇到的考試問題。[19]Anne von der Lieth Gardner,An Artificial Intelligence Approach to Legal Reasoning.4(1987).安妮·加德納畢業于斯坦福大學,獲計算機科學博士學位。每一個例子都說明了用于得出法律結論的計算機制。Rissland的調查也關注Waterman和Gardner的例子,并將它們與下面描述的基于案例的法律推理模型的開發相關聯。
Waterman的程序包含三種源于法律機構、訴訟律師和保險理賠人的規則:定義法律概念的規則,如產品責任、嚴格責任和相對過錯責任;處理不確定法律術語的解釋陪審員對外表和同情的可能反應的非正式規則,以及指導解決計算的規則(例如計算疼痛和痛苦的量)。該系統以自下而上的方式應用規則,它基于這樣一種規則:反復詢問用戶問題,然后給出答案,使用適用的規則得出結論,說明爭端對于解決問題有多大價值。通過解釋其結論,程序可以輸出一棵推理樹,一棵被“激發”的規則樹(即其條件被滿足的規則樹),從而得出結論。
Gardner的程序作為四個中間結論或狀態之間的有序進程,實現了報價和接受的模型:(0)沒有相關性,(1)未決的報價,(2)合同的存在,(1+2)合同的存在加上修改合同的未決提議。圓弧表示從一個狀態移動到另一個狀態的方式。例如,從(0)移動到(1)需要找到要約,從(1)移動到(2)需要找到對未決要約的接受,從(2)移動到(0)需要撤銷要約并拒絕承諾。并且在該模型中存在與每個弧相關的規則,這些規則定義了條件并確定條件是否已經滿足(即事實是否披露了要約,接受,撤銷等)。
法律推理的邏輯模型部分包括馬雷克·斯國特(Marek Sergot)等人的早期程序,其分析了涉及英國公民的法律問題,它是試圖“計算”法規的代表之一。這個程序包括150條來自《英國國籍法》的規定(人工表示),可以分析涉及國籍的問題,并使用它所得出的邏輯推理來解釋其答案。[20]Marek J.Sergot,Fariba Sadri,Robert A.Kowalski,Frank Kriwaczek,P.Hammond&H.T.Cory,The British Nationality Actasa Logic Program,29Comm.of the ACM 370(1986).Marek Sergot是倫敦帝國理工學院的計算邏輯教授。
在計算大型法規時,出現了一個實際問題:法令規則的形式表示有脫離法定文本的趨勢。這個問題使系統結果的解釋變得復雜,也使維護規則隨法定文本的修改而更新的大型系統變得復雜。特雷弗·本奇-卡波(Trevor Bench-Capon)和弗蘭茲·科內(Franz Coenen)開發了一種協調法定規則表示的方法,以便它們與法定代碼的結構同構。[21]Trevor Bench-Capon&Franz Coenen,Exploiting Isomorphism:Development of a KBS to Support British Coal Insurance Claims,1991Proc.of the Third Int'l Conf.of Artificial Intelligence &L.62.
本節中的其他著作對在將法定文本解釋為邏輯規則時出現的問題提出警示。其中一個問題是需要處理由于自然語言文本中邏輯連接器的范圍不確定而引起的邏輯歧義。[22]見Layman E.Allen&C.Rudy Engholm,Normalized Legal Drafting and the Query Method,29 J.Legal Educ.380(1977—1978).另一個問題源自這樣一個事實,即古典邏輯是單調的,一旦得出結論,即使根據新的信息,也不能“收回”。因此,它不太適合法律推理,這是由于在法律推理中,法律結論通常可以被某種方式加以辯駁。[23]Donald Berman&Carole Hafner,Obstacles to the Development of Logic-Based Models of Legal Reasoning,in Computer Power And Legal Language 183- 214(Charles Walter ed.,1986).唐納德·伯曼,前法律和計算機科學中心教授和副主任,定期在馬薩諸塞州波士頓東北大學教授人工智能與法律研討課。
基于案例的法律推理模型和預測法律結果的模型部分包括了對純粹基于規則的、演繹性的法律推理模型的替代方案進行建模的技術。通過可定義的原型機和論點驅動的形態分析機制,[24]見L.Thorne McCarty,An Implementation of Eisnerv.Macomber,1995Proc.of the Fifth Int'l Conf.OnA rtificial Intelligence&L.276.索恩·麥卡蒂是羅格斯大學的計算機科學和法律教授,他在那里教授關于人工智能與法律的研討課,并作為斯坦福法學院的訪問學者。再加上若干可以通過表示和調節事實因素的原型來增強或削弱特定的主張的維度,[25]Ashley,見前引⑤,at763-764.這些模型就能夠更靈活地表示法律概念。第三個模型GREBE使用語義網絡來表示法官在解釋其所有權認為很重要(或判別性的)的事實。[26]L.Karl Branting,Building Explanations from Rules and Structured Cases,34 Int'l J.of Man-Mach.Stud.797(1991).這些程序使用案例來產生支持和反對提出的結論(如HYPO的三層論證[27]Ashley,見前引⑤,at764.)的論據,這明顯偏離了邏輯演繹模型的推理。
基于實例的模型也集中在開發新的技術來經驗地評估計算模型的領域,例如GREBE的圖靈測試。卡爾·布蘭廷(L.Karl Branting)聘請一位人類專家對法學院學生或程序產生的論據進行評分。評分員沒有被告知論據的來源(也就是說,沒有人提示他有任何論據是由計算機生成的),而程序的論據看起來像法學院學生的論文。[28]Branting,見前引[26]。
基于案例的模型啟發了基于要素的方法,CATO[29]見Vincent Aleven,Using Background Knowledge in Case-Based Legal Reasoning:A Computational Model and an Intelligent Learning Environment,150Artificial Intelligence183(2003).和IBP,[30]見Kevin D.Ashley&Stefanie Brüninghaus,Computer Models forLegal Prediction,46 Jurimetrics 309(2006).它們基于正反兩面論據來預測法律案例的結果。這使人們重新對評估模型和預測準確性的客觀標準產生了興趣,自從早期的研究者應用了最近鄰方法預測涉及資本收益問題的加拿大稅務案件的結果,這就是“人工智能與法律”中一個反復出現的線索。[31]見Ejan Mackaay&Pierre Robillard,Predicting Judicial Decisions:The Nearest Neighbour Rule and Visual Representation of Case Patterns,3Datenverarbeitungim Recht302(1974).除了預測,CATO和IBP還增加了根據論點解釋預測結果的能力。
題為“模型結合案例、法令、法規、概念和價值”的部分著重于對基于案例的計算模型的其他改進。GREBE程序集成了基于案例和基于規則的推理,使用在《工人賠償法》[32]Branting,見前引[26]。中具有經常被訴訟的法律概念,索引了過去案例中標準事實的語義網絡。
另一種結合案例和規則的方法,CABARET聯合了國稅局規定內政部扣除量的邏輯表示和條款的開放式結構法定術語。這種方法索引了術語的正面和負面的案例實例。[33]Edwina L.Rissland&David B.Skalak,CABARET:Statutory Interpretation in a Hybrid Architecture,34 Int'l J.of Man-Mach.Stud.839(1991).值得注意的是,CABARET采用議程機制在基于規則的分析和基于案例的分析之間切換,生成了支持和反對納稅人立場的論據。
1993年,一個有影響的評論改變了“人工智能與法律”對基于案例的計算模型的研究進程。[34]Donald H.Berman&Carol Hafner,Representing Teleological Structure in Case-Based Legal Reasoning:The Missing Link,1993Proc.of the Fourth Int'l Conf.on Artificial Intelligence &L.50.唐納德·H.伯曼(Donald H.Berman)和卡羅爾·哈芬(Carol Hafner)指出,這些模型缺乏目的論成分,即法律法規所服務的隱藏目的或價值——這些目的和價值原本是人類法律解釋活動的焦點——在這些模型中卻被遺漏了。這種批評引導了未來10年的工作的轉向,繼而導致了Bench-Capon和薩特(Sartor)的具有里程碑意義的法律推理模式,其使用的案例吸收了從先例中引出的價值偏好理論中的價值因素。[35]Trevor Bench-Capon&Giovanni Sartor,A Model of Legal Reasoning with Cases Incorporating Theories and Values,150Artificial Intelligence97(2003).另一種方法集中于案例決策如何延伸地定義職業道德中的原則。它以“法官”(實際上是工程倫理學專家)作出的倫理決策中標準事實語義網絡的廣義版本來表示案例。[36]見Bruce M.McLaren,Extensionally Defining Principles and Cases in Ethics:An AI Model,150Artificial Intelligence 145(2003).在一次實驗中,布魯斯·M.麥克拉倫(Bruce M.McLaren)通過實驗證明了作為填充抽象倫理規則意義的案例,他對SIROCCO程序檢索效率貢獻頗大。
(二)具有論證方案的可廢除法律推理
這一節介紹當前“人工智能與法律”研究的重點,使用吸收和重述上述邏輯演繹、基于案例和基于價值的方法來評估法律權利索賠的論證模式,開發非單調、可廢除的法律推理的統一計算框架。非單調或可廢除的推理模型能夠根據新的信息(法律推理的一個重要特征)恢復先前的推理結果。
關于用參數模式評估法律主張的章節概述了由凱蒂·阿特金森(Katie Atkinson)和 Bench-Capon[37]Katie Atkinson&Trevor Bench-Capon,Argumentation and Standards of Proof,2007Proc.of the Eleventh Int'l Conf.on Artificial Intelligence &L.107.以及托馬斯·F.戈登(Thomas F.Gordon)和道格拉斯·沃爾頓(Douglas Walton)[38]Thomas F.Gordon&Douglas Walton,Legal Reasoning with Argumentation Schemes,2009 Proc.of the Twelfth Int'l Conf.on Artificial Intelligence &L.137.提出的統一框架。該工作還包括對關于法律主張的證據論證和證明標準的建模。
馬提亞·格拉巴(Matthias Grabmair)和筆者開發了用于美國最高法院口頭辯論中使用的價值判斷、中間法律概念和虛擬案例進行案例比較的參數模型。[39]Matthias Grabmair&Kevin D.Ashley,Facilitating Case Comparison Using Value Judgments and Intermediate Legal Concepts,2011Proc.of the Thirteenth Int'l Conf.on Artificial Intelligence&L.161;Matthias Grabmair&KevinD.Ashley,Argumentation with Value Judgments-An Example of Hypothetical Reasoning,2010 Proc.of the 23rd Ann.Conf.on Legal Knowledge&Info.Sys.67.韋恩·R.沃克(Vern R.Walker)的模型將案例中的證據推理的例子與模型法定要求的決策樹連接。[40]Vern R.Walker,Nathaniel Carie,Courtney C.De Witt&Eric Lesh,A Framework for the Extraction and Modeling of Fact-Finding Reasoning from Legal Decisions:Lessons from the Vaccine/Injury Project Corpus,19 Artificial Intelligence&L.291,296-298(2011).
隨著參數模式對程序建模法律論據種類的改進和擴展,它們增加了對更好地表示法律事實情況和概念的方法的需求。索恩·麥卡蒂(L.Thorne McCarty)[41]McCarty,見前引[24]。和Rissland[42]Rissland,見 前 引 [17];Rissland&Skalak,見 前 引[33],at 839-840.提出的對靈活概念模式的需求變得更加迫切。作者通過實證分析證明,[43]Kevin D.Ashley&Stefanie Brüninghaus,A Predictive Role for Intermediate Legal Concepts,2003 Proc.of the Sixteenth Ann.Conf.on Legal Knowledge&Info.Sys.153,155.中間法律概念對預測法律結果起著重要作用。隨著時間的流逝,其含義變化可以被監控,[44]Edwina L.Rissland&M.Timur Friedman,Detecting Change in Legal Concepts,1995 Proc.of the Fifth Int'l Conf.on Artificial Intelligence &L.127.并且參數模式導致了對關于特定中間法律的含義進行更加詳細的參數建模。[45]Grabmair&Ashley,前引[39],at 164-166.
所謂法律本體,是指用于法律規范和事實情景的領域概念的系統的、明確的規范,它可以幫助計算模型靈活地用法律概念進行推理。某些時候,法律本體是從以形式表示的案例進行推理的計算模型轉變為以文本表示的案例的關鍵。在法律本體中表示法律概念和案例知識的部分介紹了法律本體的基礎工作;[46]Trevor J.M.Bench-Capon&Peppin R.S.Visser,Ontologies in Legal Information Systems;The Need for Explicit Specifications of Domain Conceptualisations,1997 Proc.of the Sixth Int'l Conf.on Artificial Intelligence&L.132;Joost Breuker,Andre Valente&Radboud Winkels,Legal Ontologies in Knowledge Engineering and Information Management,12Artificial Intelligence&L.241(2004).一些本體需要被用于支持使用參數模式的類推、目的論和假設法律推理;[47]見KevinD.Ashley,Ontological Requirements for Analogical,Teleological,and Hypothetical Legal Reasoning,2009 Proc.of the Twelfth Int'l Conf.on Artificial Intelligence &L.1.用于從法律文本構建法律本體論的最新的半自動化手段。[48]Enrico Francesconi、Simonetta Montemagni、Wim Peters和Daniela Tisconia,在法律文本的語義處理中,整合了自下而上和自上而下的方法,為多語言法律領域構建語義資源:法律語言符合語言法95(Enrico Francesconi、Simonetta Montemagni、Wim Peters和Daniel A Tisconiaeds.,2010)。
(三)法律信息檢索、信息提取和文本處理
第三部分解釋了全文法律信息檢索系統如何工作,從而向學生介紹法律信息檢索(“IR”)的實用性(第五部分進行更詳細的解釋),[49]Howard Turtle,Text Retrieval in theLegal World,3Artificial Intelligence&L.5,5-6(1995).包括倒排索引的使用、術語頻率在評估相關性中的作用、使用貝葉斯網絡的檢索概率模型,[50]見Eugene Charniak,Bayesian Networks Without Tears,12 AI Magazine,Winter 1991,at 50.評估法律IR的方法及適用措施,精確度和召回,[51]DavidC.Blair&M.E.Maron,An Evaluation of Retrieval Effectiveness for a Full-Text Document-Retrieval System,28 Comm.of the ACM289(1985).以及從法律文本中提取信息的 方 法 。[52]Peter Jackson,Khalid Al-Kofahi,Alex Tyrrell&Arun Vacher,Information Extraction from Case Law and Retrieval of Prior Cases,150Artificial Intelligence239(2003).
結合法律IR和人工智能來分析法律權利要求這一部分探討了全文法律信息檢索和“人工智能與法律”模型可能互補的優缺點。這部分還探討了結合它們的方法,包括使用基于案例的模型在SPIRE程序中自動發現案例意見中的法律相關段落,[53]Jody J.Daniels&Edwina L.Rissland,Finding Legally Relevant Passages in Case Opinions,1997 Proc.of the Sixth Int'l Conf.on Artificial Intelligence &L.39.使用法律本體來提高檢索效率,[54]M.Saravanan,B.Ravindran&S.Raman,Improving Legal Information Retrieval Using an Ontological Framework,17Artificial Intelligence&L.101,103(2009).從案例法中自動提取信息,[55]Jackson等,見 前 引 [52]。支持其他法律研究范式,諸如通過法律信息網絡進行啟發式搜索。在SCALIR中,由法律案例組成的網絡通過共享術語或引文連接。[56]Daniel E.Rose&Richard K.Belew,A Connectionist and Symbolic Hybrid for Improving Legal Research,35 Int'l J.of Man-Mach.Stud.1(1991).在Bank XX中,法律知識網絡連接有注釋的節點,這些節點將案例表示為因素集合和引文束,并將原型故事和法律理論的示例表示為因素束。[57]Edwina Rissland,David Skalak&Timur Friedman,Bank XX:Supporting Legal Arguments through Heuristic Retrieval,4 Artificial Intelligence&L.1,5-8(1996).
法律信息提取和文本處理部分的工作將法律推理的計算模型和法律文本聯系起來。SMILE+IBP程序根據適用因素對文本描述的案例進行分類,然后使用IBP預測和解釋它們的結果。[58]Kevin D.Ashley&Stefanie Brüninghaus,Automatically Classifying Case Texts and Predicting Outcomes,17Artificial Intelligence&L.125,139-140(2009).其他程序根據主要類型、抽象類別和主題(如“行政法”或“知識產權法”)或規范類型(例如定義、許可或義務)自動對法律文本進行分類,然后提取諸如規范特征(例如義務、責任承擔者、行動或行動對象)和監管功能(即關于法規管轄哪些實體和事件以及法規的目的及其約束的功能)的信息。[59]Enrico Francesconi&Andrea Passerini,Automatic Classification of Provisions in Legislative Texts,15Artificial Intelligence&L.1,2-3(2007);Emile de Maat,KaiKrabben&Radboud Winkels,Machine Learning Versus Knowledge Based Classification of Legal Texts,2010Proc.of the Twenty-third Ann.Conf.Legal Knowledge&Info.Sys.87.
在以往的“人工智能與法律”關于法律信息提取和文本處理的工作中,研究者可以假設法律文本具有相當同質的結構,并且符合關于內容的某些約束。然而,這些假設不適用于電子發掘,在電子發掘中,訴訟各方必須分析和產生大量與投訴和答復的指控有關的文件。“針對電子發掘的人工智能與法律工具”這部分內容的工作是,通過獲取與律師關于索賠和文件的假設有關的證據來應對這些挑戰。[60]見Kevin Ashley&Will Bridewell,Emerging AI&Law Approaches to Automating Analysis and Retrieval of Electronically Stored Information in Discovery Proceedings,18 Artificial Intelligence&L.311(2010).鑒于天量文檔的存在,這是一個信息檢索工具必然占主導地位的領域,[61]Douglas W.Oard,Jason R.Baron,Bruce Hedin,David D.Lewis&Stephen Tomlinson,Evaluation of Information Retrieval for E-discovery,18Artificial Intelligence&L.347(2010).但其中統計技術與基于法律主張和假設的模型的知識可以相互補充。[62]David D.Lewis,After word:Data,Knowledge,and E-discovery,18Artificial Intelligence&L.481(2010).人工智能工具可以發揮有價值的作用,例如在使用社交網絡技術過濾文檔,[63]Hans Henseler,Network-based Filtering for Large Email Collections in E-Discovery,18Artificial Intelligence&L.413(2010).創建用于預測編碼的相關文檔的最佳種子集(即基于機器學習的不可視的文檔分類[64]Christopher Hogan,Robert S.Bauer&Daniel Brassil,Automation of Legal Sensemaking in E-discovery,18Artificial Intelligence&L.431(2010).),以及支持律師用創新界面探索文檔。[65]Caroline Privault,Jacki O'Neill,Victor Ciriza&Jean-Michel Renders,A New Tangible User Interface for Machine Learning Document Review,18Artificial Intelligence&L.459(2010).
(四)人工智能與法律的未來:連接計算模型和法律文本的橋梁
教學大綱的第四部分轉向一些未來的“人工智能與法律”工作,彌補法律推理計算模型與法律文本之間的差距。“人工智能與法律的近期發展”這一節呈現了一些可以合理預期的發展。JeopardyTM-winning IBM Watson程序[66]David Ferrucci,Eric Brown,Jennifer Chu-Carroll,James Fan,David Gondek,Aditya A.Kalyanpur,Adam Lally,J.William Murdock,Eric Nyberg,John Prager,Nico Schlaefer&Chris Welty,Building Watson:An Overview of the Deep QA Project,31AI Magazine,Fall 2010,at 59.的 Deep QA方法可能對如何從法律決策文本中自動提取相關信息產生深遠的影響。使用Deep QA自然語言處理工具對法律決策文本中的論點圖式信息進行注釋,程序可以較為理想地篩選提供法律遵從性證據的新文本。[67]Kevin D.Ashley&Vern R.Walker,Automated Monitoring of Legal-Rule Compliance Using Deep QA:Screening Legal Documents for Argumentation Evidence (unpublished manuscript)(on file with authors).貝葉斯網絡將與論證模式相結合,[68]Matthias Grabmair&Kevin D.Ashley,A Survey of Uncertainties and their Consequences,in Probabilistic Legal Argumentation,in Bayesian Argumentation61,61-62(FrankZenker ed.,2012).以便法律論證的計算模型能夠比Waterman的定居指導計劃更系統地解釋事實、規范、道德和經驗的不確定性。[69]Waterman &Peterson,見前引④。監管要求的可廢除的邏輯模型將有助于確保業務流程的設計符合法律,[70]Guido Governatori&Sidney Shek,Rule Based Business Process Compliance,874 Proc.of the Rule ML2012@ECAI Challenge,at the Sixth Int'l Symp.on Rules Paper No.5(2012),available at http://ceur-ws.org/Vol-874/paper17.pdf.并在錄入電子合同時實現基于網絡代理的自動化。[71]Benjamin N.Grosof,Yannis Labrou&Hoi Y.Chan,A Declarative Approach to Business Rules in Contracts:Courteous Logic Programs in XML,1999 Proc.of the First ACM Conf.on Electronic Com.業務流程方法將繼續擴展到管理機構。在荷蘭移民歸化服務的Indigo項目中,法律和法規在規則引擎服務中實施,移民代理和其他用戶調用該服務來支持案例管理。規則引擎為特定情況提供任務列表,但最終由用戶決定對任務進行排序。專用工具使最終用戶能夠向規則建模者和監管者提供反饋,以持續改進法規和規則。[72]Audrey Theunisz,INDiGO:Rules-driven Business Services;Flexibility Within the Boundaries of the Law,Presentation of the Dutch Immigration and Naturalisation Service(Oct.5,2010),available at http://www.servicetechsymposium.com/soa_archive/pdf_berlin/Audrey_Theunisz_Rules_Driven.pdf.In the absence of apublished paper in English on INDiGO,this seems to be the most informative document publicly available.
(五)增編:智能教學系統和法律倫理
最后,教學大綱包括兩個主題,可以在研討班結束時討論或在早期階段時綜合討論。“法律與倫理推理的智能教學系統”這一節著重介紹了法律推理的計算模型,這些計算模型已被納入一些特定系統,這些系統旨在教授學生特定法律概念,[73]Antoinette J.Muntjewerff,ICT in Legal Education,10 Ger.L.J.669(2009).和辯證技能(如區分案件)[74]Aleven,見前引[29]。以及構造、[75]Chad S.Carr,Using Computer Supported Argument Visualization to Teach Legal Argumentation,in Visualizing Argumentation:Software Toolsfor Collaborative and Educational Sense-Making75(PaulA.Kirschner,Simon J.Buckingham Shum&Chad S.Carr eds.,2003).審查[76]KevinAshley&Ilya Goldin,Toward AI-enhanced Computer-supported Peer Review in Legal Education,2011 Proc.of the Twenty-fourth Ann.Conf.on Legal Knowledge&Info.Sys.1.和理解法律理論。[77]Collin Lynch,Kevin D.Ashley&Mohammad H.Falakmasir,Comparing Argument Diagrams,2012 Proc.of the Twenty-fifth Ann.Conf.on Legal Knowledge&Info.Sys.81.這些在線教學技術可以提供給法律學生,甚至那些參與在線法律教育或大規模開放在線課程(MOOC)的學生,那種傳統法律教育的學生現在可以在課堂上接受論證實踐的教育。
隨著人工智能程序的發展,新的法律問題會涌現,“人工智能與法律”程序也不例外。“與人工智能與法律計劃有關的法律和倫理問題”部分,著重于智能代理的法律地位、[78]Samir Chopra&Laurence White,A Legal Theory For Autonomous Artificial Agents 119(2011).智能代理的責任、[79]EmadA.R.Dahiyat,Intelligent Agents and Liability:Is It a Doctrinal Problem or Merely A Problem of Explanation?,18 Artificial Intelligence&L.103(2010).使用法律專家系統的未經授權的法律實踐[80]Taiwo A.Oriola,The Use of Legal Software by Non-Lawyers and the Perils of Unauthorised Practice of Law Charges in the United States:A Review of Jayson Reynoso Decision,18 Artificial Intelligence&L.285(2010).以及虛擬環境或智能代理環境中的知識產權等法律問題。[81]Woodrow Barfield,Intellectual Property Rights in Virtual Environments:Considering the Rights of Owners,Programmers and Virtual Avatars,39AkronL.Rev.649(2006).法學院的學生使用傳統的法律研究工具來研究這些話題,會覺得身處舒服區,但是一個有效的法律分析可以使學生對技術如何工作理解地更深。到課程結束時,學生可能因此而更好地承擔法律責任問題。
例如,一份合約與一個法律專家系統都包含法律知識,其中一些知識可能被錯誤地應用或招致有害結果。然而,這兩種技術在它們引起信賴的方式和程度上存在差異,可能對作者或知識工程師的責任有不同的影響。因此,學生可以就他們知道如何去做的事情(如分析法律責任)寫論文,但是仍然可以受益于理解法律專家系統如何選擇和運用法律知識以及如何解釋其結論。此外,通過關注知識的空白,該過程可以幫助學生了解知識工程技術的局限性,也可以設想邀請法學院學生考慮將分析智能代理的法律責任的任務作為使用“人工智能與法律”技術建模的任務。
因此,這份教學大綱傳達了一個關于“人工智能與法律”的過去和現在的工作,它的挑戰和進展的連貫的敘述。接下來的兩節重點介紹學生關于法律推理和理解法律實踐新技術的突出課程。為了方便參考,以下列出課程,并用于整理接下來兩節中的演示文稿。
“人工智能與法律”研討班大綱中的材料中學習的課程
A:關于法律規范的課程 A1課:模糊語義對法律規范的影響;A2課:法律規范的邏輯模糊性;A3課:法規結構對法律規范含義的影響;A4課:法律規范受制于未說明的條件
B:關于法律推理的課程 B1課:區分困難和簡單案例是一個關鍵的過程;B2課:類比和區分案例是可指定的過程;B3課:用案例和價值進行推理是一種理論建構;B4課:法律倡導者提出虛擬案例來檢驗法律規范
C:關于法律論證的課程 C1課:主張者采用于特定法律領域的論證方案;C2課:人們可以通過攻擊法律論證假設或識別例外來攻擊它;C3課:法律論證涉及邏輯、修辭、不確定性和敘述之間的復雜關系
D:關于法律數字文檔技術的課程 D1課:法律數字文檔技術是基于運算模型和算法的;D2課:法律數字文檔技術的過程以不同類型的文本作為輸入;D3課:數字文檔技術能夠發現與法律問題相關的文本;D4課:數字文檔技術及其運算模型需要經驗方法來測試;D5課:發現與法律問題相關的文本與應用相關文本解決法律問題不同;D6課:法律推理的計算模型是法律文本和法律問題解決之間的橋梁
五、關于法律規范、法律論證和法津推理的課程
“人工智能與法律”課程以獨特而具體的方式講述了法律學生需要學習的內容,包括有關法律規范、案件推理以及法律論點。課程大綱中有頗多地方值得玩味,學生課后如果細心琢磨,定能會心一笑——適當的潤飾能夠幫助學生逐步形成思想觀念。本部分定義了教學大綱中部分的這種時刻,并給出了相關的背景。
A:關于法律規范的課程
A1課:模糊語義對法律規范的影響
在第一個學期的某個時候,法學院的學生可能已經了解到,法律規范中概念的含義通常沒有明確規定。當他們參加“人工智能與法律”研討班時,這已經不再是新聞了,但是對于學生來說,觀察建立根據法律規范進行推理的計算機程序的實際后果可能還是有啟發性的。
法規可以被建模為邏輯程序[82]Sergot et al.,見前引[20]。或使用啟發式規則建模,但是當規則到期失效時,必須求助于其他東西:專家查詢、案例中的論點或法規結構和法規的目的。
Waterman在早期使用規則來定義產品責任、嚴格責任以及指導解決決策指定的程序中的相對過失時就遇到了這個問題。特別的是,他定義“嚴格責任”的規則時使用了其他規則中定義的術語和概念,例如“負責產品使用”和“附帶銷售”,都在其他規則中定義。[83]Waterman&Peterson,見前引④,at 16,38.然而,一些在該產品責任環境中重要的法律判斷,如“合理和恰當”或“可預見”在法律規范中沒有另外定義。有些法律概念——包括“緊急情況”“不恰當的描述”“財產”“傷害”“瑕疵”和“粗心”——無論是否在規則中定義,都是模糊的,將它們應用于具體的事實情況經常會引起爭議,并且經常可以提出合法的論據,即該概念適用或不適用。
Waterman的嚴格責任界定規則
[規則4:嚴格責任界定]
如果(原告受到產品傷害
或者(原告確實代表死者
死者被產品殺死)
或者原告的財產被產品損壞)
并且附帶銷售辯護不適用
并且(產品由被告制造
或者產品由被告銷售
或者產品由被告出租)
并且被告對產品的使用負責
并且(加州擁有案件的管轄權
或者產品的用戶是受害者
或者產品的購買者是受害者)
并且產品在銷售時有缺陷
(產品從制造到銷售沒有變化
或者(被告的期望是“產品沒有變化”
從制造到銷售
被告的期望是合理和適當的)
然后主張嚴格責任理論確實適用于原告的損失。
當遇到一個含義不明確的術語時,人類的法律分析不會停滯不前,系統設計師和知識工程師需要對人類的做法進行建模。盡管法律專業的學生可能理解“語義歧義”的概念,但目前他們對于人類律師處理語義歧義的方法、他們使用的論據類型、這些論據假設什么以及如何攻擊這些論據的思考深度還不太清楚。
Waterman列舉了四種計算技術,法律專家系統用這四種技術可以處理定義模糊的法律概念,這四種技術如下:① 使用啟發式規則(從法律專家或保險精算師那里搜集而來),試圖捕捉過去如何使用這個術語;②給出示例,并讓用戶決定在當前事實情況下術語是否滿足;③使系統能夠將當前事實情況與實例進行比較,以便確定術語是否滿足;④ 在連續的細化過程中修改系統的規則,以便捕獲概念的含義。[84]Id.at26.
“人工智能與法律”領域的許多后續工作已經解決了這些計算技術問題。例如,法律專家系統使用第一項和第二項技術來指導用戶進行實際決策。研究者特別關注第三種技術,他們使系統根據案例進行類比推理,并論證該概念適用于或不適用于新情況。這是教學大綱第三部分所討論的工作主題。一些工作已經涉及第四種技術,其中對判決的司法解釋的注釋正在被持續改進。注釋突出了解釋中可以被匹配從而分析新的事實情況的部分。[85]例如:Branting,見前引[26];Mc Laren,見前引[36];Ashley&Walker,見前引[67]。
A2課:法律規范的邏輯模糊性
雖然語義歧義只讓很少學生感到驚訝,但更少人能夠意識到法律規范中的邏輯歧義問題。大多數人似乎驚訝地獲悉,因為邏輯連接詞的范圍在自然語言中的模糊界定和法定結構的復雜性,即使是法律規范的邏輯也可能是模糊的。在形式邏輯或數學邏輯中,括號限定了邏輯或數學運算符的范圍,但在法定文本和其他自然語言文本中不是這樣。萊曼·艾倫(Layman Allen)提供了許多示例,這些示例表明,即使是簡單的法定規則也有多種邏輯解釋,立法機關可能基本不知道這些解釋。這與為了促進立法妥協而故意包含的語義模糊形成鮮明對比。例如,路易斯安納的法規規定,“任何人不得撥打或建立本地電話連接……匿名使用淫穢、褻瀆、粗俗、下流、淫穢或不當的語言、淫穢性質的建議或提議,以及任何形式的威脅”。[86]Allen&Engholm,見前引[22],at384[quoting Statev.Hill,157So.2d462,462(1963)].但是,如果要違反規定,電話是否必須包括淫穢語言和威脅,還是只要包含其中一項就夠了?當然,在刑法環境中,答案可能意味著無罪。同樣地,學生也了解到,在解釋保險單和合同時,邏輯上的模糊性可能是至關重要的。鑒于我們不能假設今天的學生理解閱讀和起草法律規范的必要性,這就是一堂重要的課。
為了逐步規范化法令,Allen提出了一個程序,即系統地列舉各種不同的邏輯可能性,以便人們可以從各種不同的邏輯解釋中進行選擇。然而,他強調說,選擇是立法機關的事,最好是在起草過程中完成。當開發包含法定規則的法律專家系統時,知識工程師還需要從備選方案中進行選擇。他們試圖選擇立法機關可能中意的替代方案,但他們的選擇并不具有權威性,它只是知識工程師對法規的解釋。[87]Id.at396.如果法律已經頒布,除了原始法規之外的任何形式的法規都代表了一種解釋。重要的是,任何聲稱與法規相對應的陳述都不會比法規本身更多或更少。或者,法律專家系統中的規則可以體現專家在法律領域的觀點的啟發性規則。專家可以以解決其他方式重新概念化或重新特征化法定術語,根據專家的經驗解決句法(和語義)模糊問題并且滿足系統的目的。
Allen的工作還著重提供一種流程圖式的幫助,讓學生了解復雜法規的規范化和概述縮進的實用,以理解一項復雜法令。他通過一個復雜的稅收條款IRC Sec354來說明這一點。管理某些重組中的股票和證券的交易,就像《美國國內收入法》的其他規定一樣,“從句法角度來看簡直太糟糕了”。[88]Id.at388.然后他把它與一個標準化版本進行比較,該版本根據該條款的邏輯提供了流程圖。[89]Id.at393.它說明了通過法定規則的條件得出結論的替代路徑,并使人們更容易看到是否有得出結論的路徑。學生們開始意識到,有可能以更加系統的方式起草和提出復雜的法律規范,以幫助他們理解法規,并以此作為起草合同語言的目標。
A3課:法規結構對法律規范含義的影響
Allen的稅法示例還引出了這樣一個問題:當法定條款通過引用納入其他條款(可能涉及其他例外情況)或更糟時,當其他條文提供未明確相互參照的例外情況時,繪制邏輯路徑的問題。本課程還引導學生思考一項規定在法律解釋中相對于其他規定在法律或法規中的地位的重要性。包含信息的法令或法典的層級結構有助于解決其他不明確的術語信息問題,這在民法解釋中經常出現。
“人工智能與法律”研究者在對這種現象進行建模方面并沒有取得很大進展。[90]But seeBench-Capon&Coenen,見前引[21];Tom Routen,Hierarchically Organised Formalisations,1989 Proc.of the Second Int'l Conf.on Artificial Intelligence &L.242.然而,他們經常遇到這些問題并且常常會感到沮喪。在使用機器學習從法定文本中自動提取信息的工作中,例如,在合理地假設某條規定的部分和子部分的概要結構提供了語義上有價值的信息的情況下,有能力的人類讀者甚至可能不需要弄清楚在條款的末尾是否有未標記的段落是前一小節的子部分或獨立的子部分。
A4課:法律規范受制于未說明的條件
正如法律規范可能有未引用的例外情況,它也可能有未陳述的條件,例如,它不是違憲的,它不是先發制人的,或者它可以在不違反法律原則的情況下適用。Allen提出了一個問題,即如何知道應該包括哪些未聲明的條件、何時應用這些條件以及如何解決是否應用規則的問題。對于學生和知識工程師來說,這些都是棘手的問題。雖然可以認為所謂的解釋原則解決了這些問題,Allen指出盧埃林令人信服地將解釋原則描述為充數的東西。[91]Layman Allen&Charles Saxon,Some Problems in Designing Expert Systems to Aid Legal Reasoning,1987 Proc.of the First Int'l Conf.on Artificial Intelligence&L.94,105.
在《基于邏輯的法律推理模型的發展障礙》一書中,Berman和Hafner令人信服地指出,即使事實和適用法律達成一致,對手仍然可以產生合理的贊成和反對論點,法庭也會得出不同的結論。這種法律上的不確定性是由以下未陳述的條件中固有的沖突造成的,這些條件包括法律規范是否真的應該被適用;適用時是否違背潛在原則、在特定環境中規則的開放性概念意味著什么以及如何解決不一致的解釋原則和不一致的先例。由于這種法律上的不確定性,他們認為,以演繹邏輯為導向的法規模型是不能成功的。[92]Berman&Hafner,見前引[23]。
Berman和Hafner引用了里格斯·帕默爾(Riggs Palmer)[93]等法律不確定性的例子。Riggs對殺害他祖父的孫子是否會繼承祖父遺囑中的遺產提出了困惑。該規則的明確條件“死者財產的任何繼承人可以要求得到死者財產”是滿足的。但是,應用該規則將違反“任何法律規范均不適用于實施對他人造成嚴重損害的重罪行為的一方當事人的利益,這帶來了該規則適用于他利益的條件”原則。這樣的原則是關于規則的規則,并且帶來了技術上的要求,邏輯系統將需要支持對所有規則的規則進行量化。
更重要的是,Berman和Hafner總結,法律不確定性現象導致了一個更深刻的問題:基于邏輯的計算模型不適合對法律人的推理進行建模。技術問題在于,在古典邏輯中,不可能有效地證明(或論證)一個命題及其對立面。然而,他們的例子表明,即使倡導者以相同的前提(即公理、規則和公認的事實)開始,他們仍然會產生法律上合理但矛盾的論點。[94]Berman&Hafner,見前引[23],at191.實際上,法學教授經常要求法學院的學生在分析考試問題時提出正反兩方的論點,并要求學生提出解決方案。
從Berman和Hafner的描述中可知,法學院的學生很難不去思考他們作為人類推理者是如何處理法律不確定性的。鑒于這些語義和句法模糊、隱含的例外情況和未陳述的條件的問題,律師應當對法律規范本身進行推理,而不是簡單地運用法律規范進行推理,這是顯而易見的。律師使用論據來說服自己和其他人一個概念意味著什么,例外是否適用,或者未陳述的條件是否滿足。對于法學院學生以及“人工智能與法律”研究者來說,這門課是根據支持和反對應用規則的需要,推理(推敲)法律規則。
正如《教學大綱》中闡述的那樣,“人工智能與法律”研究者已經試圖用帶有條件和例外的論點模式來模擬其中一些類型的論點(包括用案例、價值和原則進行推理),從而得到剩余的教學課程。[95]或者,人工智能與法律研究人員試圖找到這些應用,其中邏輯上的這些限制不會產生負面的實際后果。
B:關于法律推理的課程
B1課:區分困難問題和簡單案例是一個關鍵的過程
在應用法律規范的過程中,存在如此多的潛在沖突,以至于學生可能想知道人類推理者如何區分簡單案件和疑難案件。
如果疑難案件是指那些即使律師雖然同意事實認定,但對其結果或解釋存在矛盾的合理觀點的案件,那么法律專家在結果和結果的解釋方面是否存在容易達成一致的問題?毫無疑問,一些法律決定對于一方來說沒有提出任何有爭議的法律問題,法律從業者通常能迅速作出幾十個法律決定。
在一年級的法律寫作或法律程序課程中,法學院的學生可能以哈特與富勒[96]例如:Berman&Hafner,見前引[23],at185-186.之間的法理學辯論的形式遇到過這個問題,但這是一個法學院的學生每學期末都會反復面對的問題。當然,法學院的學生必須根據課程所涵蓋的法律規范和決定,決定在考試中詳細提出哪些問題,以及忽略哪些問題,這一決定包括評估教師情景中精心設計的優勢和劣勢所帶來的機會。的確,評估學生在壓力下、靈活有效地作出這些決定的能力,是法學院教師布置論文型考試問題的原因之一。因此,幫助法學院學生思考如何作出這些決定是一個及時而有用的教訓。
在Anne Gardner的合同考試程序中,她第一次提供了一種算法型啟發式方法來區分難題和易題。(未命名的)項目的輸入是法學院學生處理要約和承諾的合同考試問題的表示,輸出是對問題的分析,將事件描述為要約和承諾,并確定所涉及的法律問題。Gardner的立場是,肯定有簡單的案例。至少我們一直認為問題很簡單。如果沒有簡單的案例,一切都可以解釋,答案將永遠無法躲避我們。從系統設計者的角度出發,她指出,確定案件是否容易的方法也必須是容易的。她用于區分困難案例和簡單案例的啟發式方法如下所示,在Rissland的特征描述中進行了擴充。[97]Rissland,見前引[17],at 1970,n.62;Gardner,見前引[19],at 54-55,160-161.
Gardner用于區分困難案例和簡單案例的啟發式方法
對于規則中的每個謂詞,
如果常識知識規則提供了答案,那么CSK-Answer為真,否則為假。
如果問題與謂詞的positive examples匹配,則Pos-Examples為真,否則為假。
如果問題與謂詞的negative examples匹配,則Neg-Examples為真,否則為假。
如果,CSK-應答
如果(Pos-Examples 或Neg-Examples)->問題很難
如果(只有Pos-Examples和Neg-Examples其中之一)>問題簡單
如果(Pos-Examples和Neg-Examples)>問題很難
如果CSK Answer
如果(Pos-Examples或Neg-Examples)->問題簡單
如果(只有Pos-./Neg-Examples中的一個)
如果(只同意-1w/CSK-Answer)->問題很簡單,否則問題很難
如果(Pos-Examples和Neg-Examples)>問題很難
對于法律專業的學生來說,當他們在思考律師如何決定對哪些謂詞進行辯論,以及他們實際上(學生)如何決定發展哪些考試問題的時候,思考Gardner的方法是很有意義的,Gardner程序中的策略可以以算法形式表示為一組步驟,并提供了一個模型,使學生能夠改編成更實際的策略。學生首先可能會需要算法來進行案例比較。
在Gardner的程序中,這些例子不是完全成熟的例子,充其量是捕捉諸如“立即”之類的變量的范例、標準或極值的案例片段。然而,簡單的正反實例的直接匹配是不夠的,需要一種方法來更穩健地將問題與示例進行比較。如果考慮到將問題情景的事實與法院判定法律適用性的案件進行比較,則該算法將是對學生考試策略的更有用的模型。判斷問題是困難還是簡單取決于與其他案件的類比。如果正面的例子與事實非常接近,而負面的例子則不是,那么這也許不是一個困難的問題。
B2課:類比和區分案例是可指定的過程
考慮一種區分法律難題和易題的算法,自然會考慮比較案例的算法的設計。簡而言之,它引導學生思考法律類比的要點,如何定義“相關相似性”和“相關差異”,以及如何評估類比的強度。Gardner的例子顯然沒有包含足夠的事實信息來比較案例的相似度,評估它們的相似性如何證明以與案例相同的方式處理問題場景是正確的,或者評估它們的差異如何證明不這樣做是正當的。
法學院的學生都知道他們需要類比和區分案例。許多蘇格拉底式的課堂討論都涉及學生在課本案例中就某一特定問題進行討論。課程論文考試要求學生對那些案例和問題情景進行類比或區分。目前尚不清楚學生是否理解類比和區別是什么,以及它們為什么在法律分析中很重要。
如前所示,教學大綱提供了許多“人工智能與法律”研究者試圖對法律上相關的相似點和不同點進行建模的方法的實例。它們側重于確定具有法律意義的事實模式,范圍包括:① 專家認為其存在或缺席對一個問題有影響的一般事實描述;② 根據專家所說,并且在案件中證實的典型事實模式,典型地在不同程度上加強一方關于某一問題的主張或論點;③ 法官解釋中關鍵事實的摘錄,以證明他或她對某一特定問題的決定是正確的。
研究者通過權利要求、權利要求要素或其他問題以及潛在的價值或原則來對這些模式進行索引,然后將索引與原因相關聯。因此,計算機程序可以識別法律上相關的相似點和不同點,使用它們來類比和區分案例,并解釋類比和區別對于問題決策的重要性。這些任務集中于基礎價值在相關性中發揮作用的方式。
對法學院學生來說,比較在何種程度上捕捉或省略了法律上相關的考慮是有益的。例如,描述符、規模和因素用作重要事實模式的檢查表。一方面,這些列表支持根據不存在的事實模式對問題進行推理,并且它們與用于解釋它們為什么重要的原因或價值明確關聯;另一方面,這些列表是固定的,它們需要隨著新模式的出現而更新。標準解釋是動態的,因為當一個人將案件及其解釋輸入數據庫時,他可以對法官認為關鍵的解釋片段進行注釋。然后,解釋性片段可以與它們相關的原因或價值相關聯,或者通過它們相關的價值進行索引。在處理新案例時,考慮到這些事實可以用不同的術語表示,解釋片段可以與新案例的事實相匹配。
無論如何,法律的重要事實模式可以與潛在的原因、價值觀和原則相關聯。這種聯系是很重要的,因為,正如伯曼和哈夫納所指出的那樣,[98]Berman&Hafner,見前引[34]。事實所產生的有時相互競爭的價值觀念是有關如何確定一個問題情景的法律爭論的關鍵焦點,也是法理學努力的一個主要焦點,以證明法律類推作為一種解釋現象是正當的。如何在場景分析中表示模式和價值的權重或重要性,以及如何解決競爭價值,已經證明是有爭議的。雖然用數字表示權重有助于計算處理,但研究人員往往發現,針對法律從業人員和法官的解釋和爭論沒法用數字處理權重。他們還認為,不能使用固定的層次結構對價值的權重進行建模,在這種情況下,就需要一些對背景敏感的方法來設置權重。最后,隨著社會價值觀的改變,權重會隨著時間的推移而變化。例如,在互聯網普及的相對較短的時期內,社會上不同代際群體之間對隱私的價值的評估就在不斷變化。
B3課:用案例和價值進行推理是一種理論建構
Bench-Capon和Sartor在用實例和價值進行推理的模型中,將模型描述為“構建和使用理論的過程”。[99]Bench-Capon&Sartor,前引[35],第98頁。這一重要見解源于McCarty,前引[24],第285頁,“律師或法官在‘困難案件’中的任務是構建有爭議的理論、制定所需法律結果的法律規則,然后說服相關受眾,這種理論優于對手提供的任何理論”。在這種理論構建中,過去案例的結果揭示了在這些案例中出現的一組因素之間的偏好,而那些結果反過來又揭示了一組價值之間的偏好。這個理論具有解釋力。一組價值之間的誘導偏好解釋了一組因素之間的偏好,而這些解釋了過去情況下的結果。該理論還可用于確定和解釋新案例的結果。
這是一個優雅的理論模型,但并非沒有問題。第一,人們可以歸納出不止一種理論,這樣人們就必須根據其解釋能力(即理論解釋的案例數量)、一致性和簡單性來評估相互競爭的理論。然而,后兩個標準并沒有被很好地理解。第二,從法理學的角度來看,法官過去在判決新問題時似乎沒有或應該使用競爭價值中的偏好。從價值觀的角度評估一個問題的建議結果本身就是一個道德決策。考慮到問題的具體事實,法官需要考慮如何應用這些數值。即使法官在以往的案件中使用價值偏好作為指導,人們也期望法官仍然需要將問題與案件進行詳細比較,以確保在新情況下應用該偏好是適當的。對于這種比較,必須對事實進行更細致的表示。無論如何,從教學的角度來看,Bench-Capon和Sartor的模型讓法學院的學生將重點放在一個具體案件所適用的法律理論上,去考察它是怎樣與判例和價值相關的,以及隱含的價值在定義相關相似性方面的作用,如何用之以進行案件的類比和區分。更具普遍性的問題是,法律從業人員在討論該如何判斷問題時,應當怎樣將價值和原則的因素納入考量。
B4課:法律倡導者提出虛擬案例來檢驗法律規范
法律從業者考慮價值和原則的一個方法是提出假設。假設是一個虛構的場景,以測試用于確定案例的提出的規則的某些屬性。讀過、聽過或看過美國最高法院口頭辯論的學生見到過假設。令法律倡導者驚愕的是,法官以提出假設而聞名。當然,在蘇格拉底式的課堂討論中,學生可能會遇到老師提出的假設。然而,學生可能沒有充分考慮在法律論證中提出假設的修辭要點:什么構成了有效的假設,假設具有什么力量,以及如何對這種論點作出反應?
“人工智能和法學”研究者在計算模擬假設推理方面取得了進展。[100]例如:Ashley,見前引⑤;Kevin D.Ashley,Teaching a Process Model of Legal Argument with Hypotheticals,17Artificial Intelligence&L.321(2009);Grabmair &Ashley,見前引[39]。對于法律專業的學生來說,這項工作有助于澄清對抗過程的性質,其中辯護律師試圖說服法院如何裁決案件。辯護律師確實在試圖說服法院,辯護律師提出的在判決正在審理中的案件的規則或測試是一個好的規則,既適用于當前案件,也適用于未來案件。一種觀點認為,辯護律師主張,根據擬議規則決定案件對適用價值的影響優于不這樣做或適用其他規則的效果。
因此,對抗性過程展開如下:倡導者提出一個規則或測試來決定在審案件,以支持他或她的客戶。法官通過提出一個假設情況來挑戰擬議的測試,其中測試結果是有爭議的。倡導者通過辯稱擬議測試下的結果是合理的,通過修改建議的測試以使結果合理或通過區分或類比假設來回應假設。[101]Ashley,Teaching a Process Model,見 前 引 [100],at 326-327;Grabmair&Ashley,見 前引 [39],at 164.
如果法官擔心擬議的規則可能過于寬泛,他或她可以構建規則適用的假設,但是將規則應用于假設的效果對規則所依據的價值有害。辯護律師可以通過辯論:
該規則不適用于可區分的假設,或者
該規則適用,但對價值的影響不像法官建議的那么嚴重,或者
該規則適用并且不利于該價值,但是與該規則相關的另一價值被提升,或者
該規則適用并且不利于價值,并且該規則應當被改變,以便不再適用于假設。如果法官擔心提議的規則可能太狹隘,則用補充論證方案。
通過研究假設推理模型及其在最高法院辯論中的應用,學生能夠理解這一重要的法律和修辭策略。
C:關于法律論證的課程
C1課:主張者采用特定法律領域的論證方案
正如前面的課程所建議的,表征“人工智能與法律”研究的進展的一個方法是,持續地搜索以識別和模擬特定的法律領域的論證方案,包括從規則、案例和有價值的論證方案等各領域中展開搜索。論證方案對應于論證所認可的領域內進行推理的典型框架;它對應于一種相信論證結論的初步理由。[102]Henry Prakken,Artificial Intelligence and Law,Logic and Argument Schemes,in Arguing on the Toulmin Model 236(David Hitchcock&Bart Verheijeds.,2006).這些論證方案中的一些與這些年來已經開發出來的法律推理計算模型有關,另一些則是全新的;研究者正在開發從證據事實到規則驅動的法律判斷的論證方案。[103]例如:Walker et al.,見前引[40]。
在法律寫作課程中,學生已經熟悉了用書面摘要證明法律結論的建議格式或方案。例如,① 陳述你的結論;② 陳述支持結論的主要規則;③ 通過引用權威、描述權威如何代表規則、討論附屬規則、分析政策和反分析來證明和解釋規則;④ 在輔助規則、支持權威、政策考慮和反分析的幫助下,將規則的要素應用于事實;⑤ 如果步驟①到④很復雜,那么通過重述你的結論來總結。[104]Richard K.Neumann,Legal Reasoning and Legal Writing:Structure,Strategy and Style 9394(6th ed.2009).在上述這些步驟中,至少有一部分可以被分解成附加方案。例如,人們可以想象將步驟④拆裝成“人工智能與法律”研究者已經實施的附加論證模式來支持或反駁這樣的斷言:提出的規則應該通過類比被應用,以支持將規則的元素應用于事實的案例,或通過反對這種類比來應用。[105]例如:Grabmair&Ashley,見前引[39],at164-166.

表1 “家庭法”規則集和作為可廢止規則的表示
C2課:人們可以通過攻擊法律論證的假設或識別例外來攻擊它
舉例來說,一個解釋法律規范應該如何應用于問題的論證方案,可以讓法律專業的學生集中于質疑規則的假設或考慮例外。目前,在“人工智能與法律”研究中,用法律規范進行推理將被視為可廢止的,并受制于用可廢止的規則進行推理的論證方案。
使用Thomas Gordon的論點圖解程序,“Carneades”[106]Gordon&Walton,見前引[38];Thomas F.Gordon,Analyzing Open Source License Compatibility Issues with Carneades,2011 Proc.of the Thirteenth Int'l Conf.on Artificial Intelligence&L.50,51;Thomas F.Gordon,Constructing Legal Arguments with Rules in the Legal Knowledge Interchange Format (LKIF),in Computable Models of the Law 162,168-169(Pompeu Casanovas,Giovanni Sartor,Núria Casellas&Rossella Rubino eds.,2008).可以在一個在由論證方案驅動的法定推理的例子中,說明通過論證的可辯駁的推理。例如,表1的左半部分顯示了基于德國民法的、涉及家庭法的四條法律規范。規則s.1601-BGB聲明,如果前者與后者“直接血統”,則person1有義務支持person2,這是規則s.1589-BGB中定義的概念。
由于經典邏輯系統無法成功地處理表1左邊的規則,因此必須采用一種方案來論證可廢止的規則。如果目標是確定哈利(Harry)是否有義務支持莎莉(Sally),并且人們知道Harry是Sally的祖先,那么一個經典的邏輯系統可以沒有困難地從規則s.1601-BGB到規則s.1589-BGB反向鏈接,從Harry是Sally的祖先可以推斷出Harry是Sally的“直系血統”,因此有義務去支持Sally。然而,假設一個人后來得知,有義務支持Sally會給Harry帶來過度的困難,作為演繹推理,規則s.91-BSHG表示Harry支持Sally的義務被排除在外。這個系統將證明兩個不一致的后果:Harry既有義務支持Sally,也沒有義務支持Sally。伯曼和哈夫納發現了這個問題。[107]Berman&Hafner,見前引[23]。經典邏輯演繹是單調的,一旦證明了一個命題,就不能僅僅因為學習新信息就收回它。這種證明一個命題及其反命題的能力意味著這個系統是不一致的并且可以證明任何事。
然而,正如伯曼和哈夫納所解釋的,[108]Id.在法律上,這種事情總是會發生的。如果研究者希望計算機能夠以現實的方式從法律規范中得出推斷,那么經典的邏輯推理就不能使用,必須使用別的東西。
在“人工智能與法律”領域,目前對“還有什么其他可為的”這個問題的回答是,具有適當論證方案的論證計算模型,用于實現可廢止的推理。首先,根據規則s.91-BSHG,person1沒有義務支持何時會導致人員“過度困難”;其次,規則s.1602-BGB規定如果person2不是“有需要”,則另有例外。
表1的右半部分顯示了可廢止的法律規范表示的不同之處。規則s.1601-BGB是可廢止的,因為該法令包含支持義務的兩個例外。首先,根據規則s.91-BSHG,當會給人帶來“不適當的困難”時,person1沒有義務提供支持;其次,規則s.1602-BGB規定了另一個例外:person2不需要支持。
因此,規則s.1601-BGB包含前提和結論,但結論只是假設(即可以證實)真實,表明即使前提為真,系統也可能掌握一些事實來推翻結論。這些可廢止條件被表示為“關鍵性問題”,識別影響規則適用性的假設和例外:是否滿足指定的基礎假設,是否應用指定的例外,這條規則有效嗎,適用排除規則嗎,是否適用一些優先級較高的沖突規則?
關于如何表達這樣的問題或者如何稱呼不同類型的可廢止性條件,學術界幾乎沒有一致意見,但是研究者普遍認為,這些可廢止性條件需要被指定,因為如由論證方案指導的,程序將測試它們。
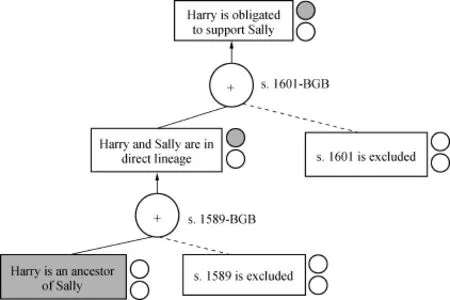
圖1 具有可廢止推理規則的“Carneades”論證圖
像Thomas Gordon的“Carneades”這樣的系統可以用可廢止的推理規則進行推理,并構造論點。圖1顯示了“Carneades”可以生成的人工準備的論證圖版本。[109]Gordon&Walton,見 前 引 [38];Gordon,Analyzing Open Source License Compatibility Issues,見 前 引 [106],at 54-55;Gordon,Constructing Legal Arguments,見前引[106],at179.聲明節點是框,論證節點是圓(用“+”表示支持,用虛線表示論證適用性的例外)。如果指定Harry有義務支持Sally的目標,Carneades規則引擎會從該目標向后推理,以找到支持該目標的可廢止的推理規則:規則s.1601和s.1589。當論證被構造和編輯時,它們在一個參數圖或圖表中被可視化。陰影聲明節點表示該語句被(相關聽眾)假定為真。節點旁邊的陰影上小圓圈表示該參數是可接受的(根據相關證明標準)。如果下面的圓圈被顯示成陰影,則語句的補語可以接受。
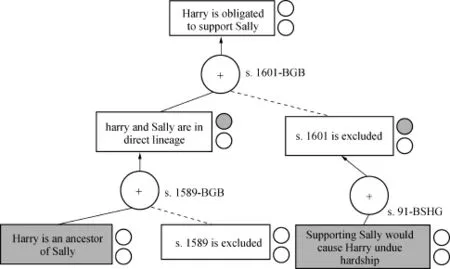
圖2 通過基于另一個規則的論點來阻止規則的可廢止結論
如果指定了擊敗該論證的目標,則程序搜索與規則相關聯的關鍵問題,以找到可應用的例外、排除或假設的失敗,從而阻止該論證的假定結論。因此,當得知有義務支持Sally會給Harry帶來不當的困難時,這個程序就會發現這樣的排斥。規則s.91-BSHG應用并阻止了論證的結論,如圖2所示。
假設有義務支持Sally會導致Harry不當的苦難不是既定的事實。相反,讓我們假定,雖然“不當困難”不是由法律規范定義的,法院在涉及某些因素的案件中認定贊成或反對不當困難。
特別地,假設存在三種情況:
Mueller:P在{PF2}中贏得不適當的困難問題;
Schmidt:D贏得了{PF2,DF1}的不當困難問題;
Bauer:P贏得了{PF2,DF1,PF3}的不當困難問題。
最后,讓我們假設:Harry和Sally從來沒有親子關系,PF2,并且Sally只需要短時間的支持,DF1。
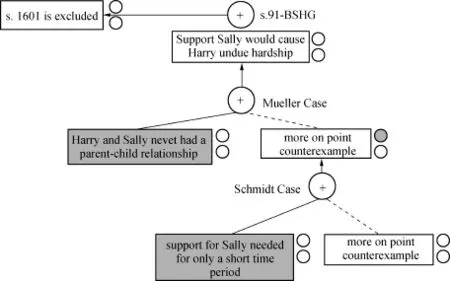
圖3 Schmidt方案的論點勝過Mueller方案,導致規則可廢止
在這種情況下,“Carneades”可以根據基于案例的推論構建支持和反對Harry有義務支持的Sally的論點,如圖3所示。[110]見前引[38]和前引[109]。與問題共享PF2的Mueller案例支持一個論點,即s.91-BSHG導致根據s.1601-BGB將義務排除在外。然而,Schmidt方案的情況更具有針對性(因為在Mueller和問題之間共享的一組因素是Schmidt和問題之間共享的那些因素的子集,即PF2和DF1),并且結果相反。按照HYPO[111]Ashley,見前引⑤,at 784.的術語,Schmidt方案勝過Mueller方案。
C3課:法律論證涉及邏輯、修辭、不確定性和敘述之間的復雜關系
雖然家庭法的例子很簡單,法學院的學生可能仍然對“Carneades”將生成多種類型的法律論點并整合成易于解釋的視覺格式的能力印象深刻。法律專業的學生可以看到比簡單地演繹性地應用法律規范更復雜的論證結構。
這個論證也回避了一個問題,即律師如何將不確定性和修辭性的考慮因素納入他們對法律論證的評估中。法律論證是一種處理不確定性的技術(例如在法律規劃中),但不確定性也影響法律論證。這種不確定性包括關于以下方面的不確定性:證據和事實斷言的合理性,法律對事實的規范性應用,對替代結果的道德評估以及接受論點的可能性。
然后問題出現了:是否以及如何將不確定性因素引入到論證圖中。教學大綱中的一些文章處理了類“Carneades”模型中的不確定性。一種方法是在論證圖中實現說服負擔或證明負擔,如“證據的優勢”和“超越合理的懷疑”。例如,通過將證據確定性的定量度量同論證與結論聯系起來,并強制批準的弧線聯系起來,這些證明負擔有助于普瑞特定量標準。[112]Gordon&Walton,見前引[38],at 137-138;Atkinson and Bench-Capon,見前引[37]。
此外,“Carneades”的論點模型還可以通過具有不確定性推理的能力(使用貝葉斯信念網絡)來擴充;這種改變將允許發起者探索關于證據不確定性[113]Grabmair &Ashley,見前引[68]。的各種假設的后果。例如,他應該為事實或法律辯護嗎?為了評估如何最好地改善他作出有利決定的機會,辯護人可以修改代表陪審團對各種證據事實的信仰的假設概率分布,或者修改代表陪審團對各種論據的合理性的信仰的權重。同樣的工作探索了敘述在評估律師試圖符合證據的故事中的證據不確定性的作用。不同的敘述適用于不同的法律主張。對于一個故事來說似乎可信的證據可能與另一個故事無關,或者與另一個故事相矛盾。雖然用于模擬法律論證的這些方面的計算技術還處于起步階段,但是學生可以從思考潛在的現象中受益。
這就完成了如何利用“人工智能與法律”研討班來教授學生一些有關法律的經典課程的討論。這些材料還可以用于課程指導,以及輔助法律專業的學生準備從事數字時代的法律實踐。
六、法律推理的計算模型與法律實踐中數字技術的連接
學生需要了解影響法律領域的“信息革命”,以及信息革命如何影響他們法律就業的前景、法律就業的種類,以及他們在數字時代作為法律從業者的責任。一位研究法律實踐的發展趨勢及其對法學院課程影響的杰出學術觀察家最近觀察到:法學院課程因一場信息革命而變得更加復雜,這場革命正在改變當前工作和未來工作的組合。由于目前法律行業對過程和技術的重視,目前法學院盛行的實用技術技能教育和領域知識教育可能不足以滿足大部分2015[114]William D.Henderson,A Blueprint for Change,40 Pepp.L.Rev.461,501(2013).學年畢業的學生的需要。而學生對于這樣的情況毫無準備:法律正變得不那么與陪審團審判和法庭辯護相關,而是更多的與運算工程、預測編碼以及這些過程所要求的協作和技術技能相關。[115]Id.at 505-506(emphasis added).
亨德森(Henderson)提到的技術主要是文檔審查過程的自動化,以使得它能夠使用機器學習技術(也稱為預測編碼)來處理現代訴訟中的大量電子文檔。程序正在學習從現代訴訟中產生的巨大內存文件中選擇電子文檔,并依靠訴訟者將小組文檔標記為與權利主張相關的文檔,以及和辯護不相關的文檔,根據它們的相關性將它們分組。
“預測編碼本質上是機器學習在搜索相關信息時部分取代了人類。”[116]Id.at 487(emphasis added).這一發展是由電子發掘緩存的規模和多樣性驅動的。
由于數字數據的大爆炸,我們的日常生活被編碼成電子郵件、文本消息以及旨在取代電子郵件的內部知識管理平臺和數字化語音郵件,使用傳統的審查方法去審查平民或白領訴訟范圍變得昂貴得令人望而卻步。[117]Id.
強調“過程”對于面對合法就業市場的學生來說尤為重要。Henderson復述理查德·蘇斯金德(Richard Susskind)的《律師的終結》時說道。[118]Richard Susskind,The End of Lawyers?6(2010).
通過識別以法律形式的遞歸模式和司法意見,使得(從定制的法律工作到標準化、系統化、打包,以及最終商品化)這些改變成為可能,使得流程和技術的使用能夠實現常規化,并為各種法律需求提供非常便宜和高質量的解決方案。[119]Henderson,見前引[114],at479(emphasis added).
通常由美國法學院初級畢業生從事的勞動密集型工作,……現在由印度法律專業的畢業生[為法律程序外包商(LPOs)工作]來完成,他們正在學習如何設計和操作從大量數字文本中提取有用信息的過程。印度法學院的畢業生不僅得到了就業機會,而且正在學習有價值的技能,而這些技能完全不需要從美國法學院的學習中掌握。[120]Id.at487(emphasis added).
為了更好地提供有關電子發掘和其他法律信息管理過程的產品和服務,律師、律師事務所、法官和監管機構越來越依賴于對機器學習、數據挖掘、自然語言處理和信息檢索技術的評估、購買與驗證。為了便于參考,這些技術將統稱為“數字文獻技術”。雖然受到電子發掘的壓力的驅動,但數字文檔技術并不僅僅用于訴訟,它們在公司業務和法律實踐的所有領域都很重要,涉及開發管理公司文件的過程,例如稅收、合并和收購以及合規性等等。
如下所述,“人工智能與法律”研討班通過向法學院學生介紹信息處理、算法和運算工程來幫助他們理解數字文檔技術。實際上,在研討班常常是他們第一次系統地接觸這些概念。然而,從一開始就應該明確的是,教學大綱第1部分、第2部分和第3部分所討論的法律推理計算模型與當前數字文獻技術的核心不同。數字文獻技術扎根于全文法律信息檢索、計算語言學(如淺文本解析和命名實體識別)以及統計自然語言處理、機器學習和數據挖掘。這些技術的起源各不相同,以下將分述之,最后將討論把它們相互交織在一起的綜合運用。
這里相關的一點是,簡單地說,大多數課程大綱中的“人工智能與法律”工作,是用來教授學生有關法律規范、案例和論點的課程,卻不涉及與數字文檔技術相同的任務和過程。的確,數字文檔技術與學生處理法律知識的方式之間存在著鮮明的對比,即機器學習、數據挖掘、自然語言處理和信息檢索模型的效率與“人工智能與法律”模型表達之間的對比。例如,法律信息檢索需要處理大量的文檔和自然語言查詢,這讓Westlaw和Lexis非常有效,然而這些程序并不深入地處理文本;Westlaw和Lexis甚至無法分辨一個案件或議題中誰是獲勝方,更不用說如何在一個法律問題的論證中使用文本了。此外,與短語相反,這些程序不能過濾具有/不具有指定特征的文檔。
盡管有這些技術差異,“人工智能與法律”研討班可以通過教授學生以下工具來幫助他們理解數字文獻技術:① 在計算模型、算法、相關性度量和實驗評估等方面的技術的概念詞匯的描述;② 對技術中隱含的任務要求、計算模型和算法的高級描述;③ 這些技術的性能通過實驗測量的方式、程度以及這些測量的意義;④技術中隱含的計算模型能夠捕獲什么和模型會遺漏什么的一些示例;⑤技術嵌入的法律過程,包括硬件、軟件、人類技術人員和人類法律從業人員。
總之,參加“人工智能與法律”研討班為法學院學生提供了“計算”思考法律實踐過程和法律信息處理的經驗。雖然今天的學生是隨著互聯網成長起來的,并且非常熟悉萬維網的界面,但是他們可能并沒有在法律實踐中系統地思考信息處理問題。這些學生很可能在編程方面沒有什么背景,并且既沒有考慮開發算法來實現規范,也沒有考慮使用連續的細化來為每個步驟開發子算法。然而,到研討班結束時,這些學生將完成兩項工作,一是使用法律推理算法,二是使用電子發掘的算法。
對于不熟悉全文法律信息檢索如何工作的學生來說,這是一個明智的進步。諸如用于全文檢索、從大型數據集進行機器學習、數據挖掘或自然語言處理的貝葉斯信念網絡之類的技術是復雜的,并且可能拋棄法律直覺。這將有助于學生獲得介紹的計算性思維的算法,在法學院的第一年結束時,學生就已經對該算法的模型推理過程很熟悉了。
從另一方面來說,這種進展也是有意義的。如下所述,法律推理的計算模型最終將引導改善數字文檔技術的智能行為。至少一些參加“人工智能與法律”研討班的學生可以很好地自己設計這些技術,或者支持其他人設計它們。
即使法律專業的學生只是數字文檔技術的消費者或用戶,而不是設計者或改進者,對于非編程專業的法律學生來說,學習這些工具如何工作也是很有價值的。企業和政府客戶將很快需要電子發掘工具,這些工具不僅被允許,而且要求專業護理標準。接受這些工具進入職業的過程已經并將繼續由律師——以前的法學學生——去選擇工具,使用它們,指導其他人如何使用它們,解釋它們的輸出,并通過解釋它們如何工作以及它們如何可靠和有效地來向其他人(如法官)證明它們的使用是正當的。“人工智能與法律”研討班通過教給未來的律師一些有關法律數字文檔技術的寶貴經驗來為這些任務做準備。
七、關于法律數字文檔技術的課程
本部分重點介紹一些關于數字文檔技術的課程,學生可以從“人工智能與法律”研討班上學到這些課程。
D1課:法律數字文檔技術是基于運算模型和算法的
如上所述,從定制化法律服務向商品化法律服務的轉變意味著學生可以從理解“涉及法律知識的過程”的概念中受益。
“人工智能與法律”研討班通過實例向法學院學生介紹這種過程的概念。教學大綱中所討論的所有計算模型都集中在處理法律知識上。“人工智能與法律”推理模型以及數字文檔技術模型也是如此。
許多“人工智能與法律”模型是一些過程的成熟的表示,這些過程涉及法律知識及其算法實現的過程或部分過程。例如,當需要時,CABARET程序應用議程機制在基于規則和實例的推理之間切換控制。[121]Rissland&Skalak,見前引[33],at 853.學生可以檢查過程的輸出,以將CABARET的控制機制與人類問題解決者的控制機制進行比較,可能人類問題解決者切換得更少,并且更關注于識別問題和解決問題。IBP+SMILE程序利用過去的案例重新實現了預測法律結果的過程。IBP組件將問題分解為若干個小問題,對于每個小問題,基于由與該小問題相關的因素索引的案例,提出關于誰應該獲勝的假設。然后,程序測試了反例假設,即不能解釋清楚。[122]Ashley&Brüninghaus,Computer Models,見前引[30],at347.SMILE組件使用機器學習來學習如何識別案例的文本描述中的因素。在組合程序中,一個算法使用SMILE將問題輸入作為文本處理,并向IBP輸出可用因素的列表,然后IBP預測結果。[123]Ashley&Brüninghaus,Automatically Classifying Case Texts,見前引[58],at 139-140.
其他教學大綱研究論文提供了涉及機器學習和自動從文本中提取信息的過程的良好實例,包括法定文本、[124]Francesconi&Passerini,見前引[59];de Maatetal.,見前引[59]。案例文本、[125]Jackson et al.,見前引[52]。文本以及審前發現所涉及的文本。[126]Privaultetal.,見前引[65]。弗朗西斯科利(Francesconi)和同事們的工作說明了自下而上和自上而下的處理的良好結合,讓人工的注釋器集中在統計有趣的特征上,這些特征可能值得被包含于本體論中。[127]Francesconi et al.,見前引④。
用于審前電子發掘的現有數字文檔技術[128]Hoganetal.,見前引[64],at434-435.實現用于識別與訴訟相關的文檔的迭代過程。作者集中于高級訴訟人的“感悟”:收集、組織和創建復雜信息集合(即電子文檔)表示的過程,所有過程都集中在他們需要理解(即它們如何與訴訟相關)的一些問題上。[129]Robert Bauer,Teresa Jade,Bruce Hedin&Christopher Hogan,Automated Legal Sensemaking:The Centrality of Relevance and Intentionality,2008Proc.of the Second Int'l Workshopon Supporting Search&Sensemaking for Electronically Stored Info.in Discovery Session 2,Paper No.5,2,available athttp://eprints.ucl.ac.uk/9131/1/9131.pdf.目標是梳理訴訟當事人的相關性假設:如果在文件中找到,或多或少抽象的主題描述將使該文件與法律訴訟相關。[130]Hoganetal.,見前引[64],at446-448,455.本文描述了一個迭代的用戶建模過程以引出這些相關假設。這是一個以計算機為中介的連續細化過程,其中訴訟人傳達所需的信息、檢索樣本文件,并且訴訟人確認他們是否有回應。如果他們沒有回應,訴訟律師會改進這一假設。這個過程產生了訴訟律師的目標模型,與案件相關的法律和其他概念及其特殊程度,以及表達概念的各種方式。實際上,這些信息使訴訟律師的假設可操作,然后用于檢索與該假設相關的更多文件。隨著機器學習開發出感興趣概念的概率模型,工具可以幫助訴訟人員可視化新文檔與相關文檔的概念集群的關系。[131]Privaultetal.,見前引[65]。
多年來,在為匹茲堡大學法學院“人工智能與法律”研討班撰寫論文時,學生已經發展了自己對涉及法律知識的過程的表示。一些代表性的標題包括“人工智能在先鋒藝術搜索中的應用:專利文獻搜索行業的概述和預測”“基因專利申請過程的人工智能改進”“為了斷言的真相:利用人工智能協助陪審團在審判中連貫地重建事實”“通過規范違反無效規則來調整‘人工智能與法律’模型以預測訴訟結果”。
D2課:法律數字文檔技術以不同類型的文本作為輸入
數字文檔技術的基礎過程包括文本作為輸入。“人工智能與法律”研討班的學生因此可以了解計算處理文本的挑戰。
大綱中所引用的大多數法律推理計算模型都不接受文本作為輸入。取而代之的是,人類讀取問題場景或要存儲在程序知識庫中的案例的文本,提取程序所要求的信息,并以適當的格式手動表示問題或案例。因此,在某種意義上,輸入是人工處理的文本。主要的例外是上面描述的IBP+SMILE程序。
在數字文獻技術的過程和領域中存在太多的文檔,無法手工處理每個文檔。像Lexis和Westlaw這樣的合法IR供應商每天獲取數千個案例。案件文本由法院以電子方式提交,并自動在倒排索引中編索引,其中給定文檔由每個“主”字編索引(即使用從“索引”項中過濾出來的“the”“a”“an”等字)。因此,合法IR程序根據查詢搜索數百萬個文檔,“人工智能與法律”模型最多搜索數百個(但是一些模型,如SPIRE,[132]Daniels&Rissland,見前引[53]。可以連接到全文合法IR源,從而擴展了它們的搜索)。
這個模型還處理非常不同的文本。一些法律文本處理研究涉及更結構化的文本,這些文本在法律管理過程中的功能是已知的(例如法定文本或法院判決的文本)。相比之下,在電子發掘環境中,文本是在訴訟中產生的極其異構的文檔。它們不僅包括公司備忘錄和協議,還包括所有基于互聯網的通信,也包括電子郵件。電子郵件可以是來自經理和雇員之間的,或者來自雇員到其他雇員、客戶和供應商,或者來自雇員的家人和朋友等等。事實上,對于電子郵件,對誰在什么時間段與誰進行通信的社交網絡分析可以提供有價值的信息,用于選擇相關文本以進一步分析。[133]Henseler,見前引[63]。
D3課:數字文檔技術能夠發現與法律問題相關的文本
數字文獻技術往往側重于尋找與法律問題相關的信息的過程。這個過程會影響一個系統評估相關性的方式、評估系統的方式以及評估系統性能的措施。法律專業的學生會發現,IR的相關性、評估和措施在電子發掘的教學大綱材料中有簡明的定義。
相關性:在IR任務中,一個正確返回的文檔(廣義上被理解為任何信息容器),如果用戶希望看到它就被認為是相關的,否則就不相關了。
評價:相關性是一個觀點(而不是一個客觀確定的事實)的一個重要結果是檢索效率成為評價的主要焦點。絕大多數IR評估主要關注相關性的一個方面:話題性。研究者最廣泛使用的話題相關性定義是文獻中任何部分對所希望的主題的實質性處理。
度量:通過檢索每個主題具有積極評估的文檔的能力來度量檢索方法的有效性。假設二元評估(即相關與非相關),兩種有效性的措施是非常常見的報告。回溯是系統檢索到的現有相關文檔的比例,而精確度是檢索到的實際相關文檔的比例。它們一起反映了以用戶為中心的觀點,即假陽性和假陰性[134]Oard et al.,見前引[61],at 360,362,363.之間的基本折中。
法律語境中的話題是一個動態的目標。盡管Westlaw的密鑰編號系統提供了跨越不同法律領域的主題的豐富主題列表,但律師通常尋求更詳細的主題。律師試圖捕捉與他們正在研究的問題情形(即源案件)相關的目標案件中的事實模式。在電子發掘中,不存在這樣的列表。相關主題主要是為訴訟人所知的抽象描述;實際上,如上所述,數字文檔技術的提供者需要基于訴訟人對文檔相關性的確定,開發特殊的過程以來歸納主題。
教學大綱為法學院學生提供了一個可讀的說明,說明像Westlaw和Lexis這樣的全文法律信息檢索系統如何根據文檔和語料庫中術語的使用頻率來建模用戶認為重要的主題(即用戶的信息需求)。此外,這些資料還解釋了信息檢索系統如何評估文檔與用戶信息需求的相關性,在召回通常是次要重要的環境中實現高精度。[135]Turtle,見前引[49],at7-9.該系統在法律研究中工作良好,很少需要對每個相關案例進行詳盡搜索,許多好的案例足以發展對這個問題的理解,并形成關于如何決定的論點。[136]Oardetal.,見前引[61],at353.
然而,在電子發掘中,檢索“任何和所有”與主題相關的文檔是典型的目標。[137]Id.at351.也就是說,召回是有額外費用的。這個事實之所以不幸,有兩個原因。首先,研究表明,律師往往高估了他們的召回率。[138]Blair&Maron,見前引[51],at 293-294.這項(開創性)研究確定了律師的看法之間存在差距,即使用他們的具體詢問,他們會檢索到大約75%的相關證據,這些證據是在收集40000份訴訟用途的文件中找到的,研究人員能夠證明,事實上只發現了約20%的相關文件。[139]Oardetal.,見前引[61],at348-349.其次,“現在很清楚,隨著數據集越來越大,高精度搜索通常變得稍微容易一些了,但是不確定性倍增使得越來越難以成功進行特定或詳盡的搜索”。[140]Id.at349(citationomitted).
上述因素給法律從業者帶來的后果是,法律從業者需要負責理解、選擇、解釋和證明電子發掘過程和工具,鑒于供應商的替代產品和相互沖突的主張以及缺乏客觀評價,這是一項艱巨的任務。
D4課:數字文檔技術及其運算模型需要經驗方法來測試
對于那些日益面臨處理法律信息過程模型的需求的學生,無論是作為消費者還是設計師,“人工智能與法律”研討班教導一種檢驗過程模型的經驗方法。“人工智能與法律”的發展歷史已經通過經驗或思想實驗來檢驗模型,重點放在模型崩潰的例子上,然后對其進行調整。這段歷史包括發明用于評估模型的實驗技術。[141]例如:Branting,見前引[26];Ashley&Brüninghaus,Computer Models,見前引[30];Mc Laren,見前引[36]。從Berman和Hafner第一次呼吁表示基于案例推理的目的論基礎,[142]Berman &Hafner,見前引[34]。到CATO的因子層次,[143]Aleven,見前引[29],at 191-193.到IBP中的假設檢驗,[144]Ashley&Brüninghaus,Computer Models,見前引[30]。到理論歸納,[145]Bench-Capon &Sartor,見前引[35]。到論證方案,[146]Gordon&Walton,見前引[38];Atkinson&Bench-Capon,見前引[37]。到論證方案的工作進展價值判斷模型,[147]Grabmair &Ashley,見前引[39]。是示例驅動的法律信息處理模型的增量式持續改進的實例。另一個例子是假設推理模型中的迭代細化。[148]見前引[100]。
教學大綱提供了客觀評價電子發掘IR工具的挑戰和方法的處理。[149]Oardetal.,見前引[61]。它向學生介紹了TREC法律軌道,來自學術界和工業界的團隊每年與其競爭并評估應用于公開數據集的最有效的電子發掘IR工具。公開的數據集包括Tobacco訴訟和Enron丑聞中的電子郵件和其他文件的集合。TREC競賽的要求,即電子文檔數量的增加和系統有效性的三個方面對現實發現進行比較的需求,使得TREC組織者將布萊爾(Blair)和馬龍(Maron)研究[150]Blair&Maron,見前引[51]。的實驗技術擴展為使用許多法律的大規模評估。學生、律師助理和律師作為志愿相關性評估員。[151]Oardetal.,見前引[61],at367.
作為這項技術的潛在消費者,法律專業的學生應該了解到,電子發掘任務并非一成不變的。雖然TREC的競爭有三個方面,但都集中在“響應性審查:一方……被服務……要求出示文件和……必須找到并生產……對請求作出響應的任何和所有文件”。[152]Id.at 370.重點關注的三個具體方面是:① 交互式任務,即檢索所有且僅與主體機構對相關內容的定義一致的文檔;[153]Id.② 特設任務,即單遍、首遍自動搜索;[154]Id.at373.③ 相關反饋任務,即基于對第一遍結果的人類反饋的第二遍搜索。[155]Id.at375.
正如奧德(Oard)的文章所闡明的,用于評估這三個任務的技術不同,并且還有其他任務尚未發明評估技術。[156]Id.at370.“在訴訟初期,律師可以對文件集進行探索性檢索,以檢驗假設并建立案件理論。此外,律師可以搜索與特定個人活動有關的文件,以便為證人的證言做準備;作為審判方法,律師可以搜索一組通常相關的文件,以便找到他或她想作為審判中的展品進入的小子集;等等。”
有了對IR相關性、評估和措施的概念性理解,并將其應用于電子發掘,以及用于測試關于過程模型的聲明的實證和基于實例的方法,學生可以做好充足地準備,有能力以批判性地質疑供應商關于電子發掘工具的聲明,以便在他們自己的電子發掘過程中有效地使用工具,并向客戶和法官證明這些工具的效果。
D5課:發現與法律問題相關的文本與應用相關文本解決法律問題不同
在學習了一些數字文獻技術,以及一些法律推理的計算模型之后,學生將能夠很好地考慮如何將這兩種方法結合起來。
為什么這種整合是值得的?如果法律服務市場的歷史確實已經從定制、標準化、系統化和包裝發展到商品化,那么接下來人們會有什么新需求?盡管生產效率很高,但商品化的法律工作不再是解決客戶特定問題的定制工作。雖然雇用人事律師來調整商品化產品以解決客戶的問題可能太昂貴,但是計算技術仍然可以有效地執行這種“后商品化”定制。
如上所述,數字文獻技術往往側重于尋找與法律問題有關的信息的過程。相比之下,法律推理的計算模型往往側重于應用相關信息解決法律問題的過程。因此,這兩種方法具有互補的優點和缺點。
信息檢索中的相關性度量(即文檔實質上處理所需主題的統計概率)非常有效,不需要特殊的文檔表示,文檔是倒排索引中的文本。一方面,只有人可以使用這樣檢索到的文檔來解決法律問題,例如通過將文檔中包含的信息合并到法律論證中;另一方面,法律推理的計算模型采用相關度量,并且可以使用檢索到的信息來通過生成論點以解決法律問題。然而,一個缺點是,這些相關性度量只有在案例的維度、因素、關鍵事實等方面被特別表示時才能起作用。而且,除了像SPIRE[157]Daniels &Rissland,見前引[53]。或SMILE+IBP[158]Ashley&Brüninghaus,Automatically Classifying CaseTexts,見前引[58]。這樣的工作之外,程序不能自動填充特殊表示。
然而,人們開始看到正在彌合數字文檔技術和法律推理計算模型之間的鴻溝的程序。
D6課:法律推理的計算模型是法律文本和法律問題解決之間的橋梁
人工智能與法律中的一些現有和當前的工作使用法律推理的計算模型和論證作為法律文本與人類尋求的答案和論證之間的橋梁。
例如,SPIRE計劃演示了如何使用破產法問題的基于因子的計算模型(如破產計劃是否真誠地提交)將查詢引入全文法律信息檢索系統。該程序使用Hypo風格的計算模型來尋找解決法律問題的最相關案例,并使用這些案例來查詢。實際上,指示全文IR系統檢索更相似的文本。[159]Id.at131132.160de Maat et al.,見前引[59]。在實驗中,SPIRE發現新的相關案例與輸入的問題非常相似(例如涉及相同法律故事)。SPIRE用戶還可以指示感興趣的特定特征,并且程序將自動突出顯示檢索到的案例中與該特征對應的文本部分。
其他示例包括應用模式匹配[160]de Maat et al.,前引[59]。和機器學習技術廣泛監管(例如,作為定義、責任、禁止、義務、許可或處罰)功能來分類法定條文。這些技術然后可用于提取與每個功能相關聯的典型特征。[161]Francesconi et al.,見前引[48]。例如,規定“打算處理屬于本法適用范圍的個人數據的控制器必須通知擔保人”被歸類為“義務”,其相關特征為:(責任的)負擔者=“控制器”,動作=“通知”,對方=“擔保人”,客體=“處理個人數據”。這項工作旨在從立法文本中直接提取法律規范,以學習法律規范的分類和特征。最終,程序可以用如此提取的形式化規則進行推理。迄今為止,尚未有報道的工作成功地從法律文本中為此目的提取法律規范。然而,在此期間,提取的信息可以被映射到全面的概念索引(例如法律詞典、字典或本體)中,并用于支持針對與特定業務遵從性問題相關的所有法律規范的更加集中的概念查詢。
其他工作包括注釋法律決策文本,使其與基于規則的推理樹相連,這樣程序就能夠學習對以前看不見的文本進行推理。例如,努力將IBM Watson問題回答項目[162]Ferrucci et al.,見前引[66],at67.中使用的NLP技術與可廢止的邏輯模型集成,該邏輯模型將法定和規章要求表示為與法律決策中的推理鏈相關聯的規則條件樹,這些規則條件將證據輸入與事實的結論聯系起來。[163]Ashley&Walker,見前引[67]。因此,一個感興趣的命題(例如,一個法定條款已經得到滿足)被分解成一個推理樹,該推理樹由法律命題和相關的事實斷言組成,這些事實斷言的表達可以在法律決定的自然語言文本中注釋。這種使用增加了法律概念的力度,使它們可以與關于事實的常識推理緊密聯系起來,并用于促進更有效的搜索、提取和報告。例如,盡管高層次的法律概念(如“有權獲得補償”)會帶來模糊的檢索任務,但是分解這些概念的低層概念(如“醫療條件”或“發病時間”)將更適合于自動搜索和推理新文本。
給定足夠數量的帶注釋的決策,可以應用機器學習和自然語言處理,以便程序可以學習識別尚未看到的新文本中的帶注釋的模式,就像IBM的Watson程序在問題回答環境中所做的那樣。如上所述,在至少一所法學院的實驗室里,法學院的學生都參與在法律判決中注釋法定論證和證據論證的過程。[164]Law,Logic&Technology Research Laboratory,見前引[16]。通過這樣做,這些學生正在學習一種全面的法律推理模式,并遇到上面所列舉的所有課程——關于法律規范、案例、論證、數字文檔技術,以及連接它們的運算工程。
除了數字文檔技術之外,“人工智能與法律”過程模型也在各個領域得到發展。INDiGO項目和由州長[165]Governatori&Shek,見前引[70];Theunisz,見前引[72]。進行的工作基于對管理、管理和業務流程的細致描述,以及仔細考慮如何將人工智能專家系統集成到這些流程中以幫助人類。例如,在INDiGO項目中,所關注的過程不僅包括應用規則,還包括根據經驗改進它們。一個專家系統協助荷蘭的移民代理人根據大量的管理規定處理客戶。同時,系統收集和反饋根據條例產生的問題的數據,以傳遞給監管者和規則建模者,使其了解需要改進的規則的方面。以后法律過程的工程化可望進一步發展,如果法學院的學子能對其潛力多加了解,將會為自己帶來更多的機會。
八、結 論
本文介紹了一個“人工智能與法律”研討班的樣本教學大綱,該研討班能夠在數字時代講授法律和法律實踐。經過討論,得出了教材中隱含的四組教學課程。“人工智能與法律”研討班不僅教學生有關法律規范、案例和論點的寶貴教學課程,而且介紹給他們處理數字時代法律實踐的模型和算法。在這方面,研討班對學生的教育作出了及時的貢獻,并解決了當前法學院在法律職業不確定時期面臨的緊迫性問題。
法律推理的“人工智能與法律”模型和文本處理為在現實世界的應用增加了價值,包括電子發掘、可視化法律論據、預測結果、作出解決決策和法律專家系統。法律專業的學生可以作為知情的用戶以及新模型的注釋者、設計師和發明者對這項技術作出貢獻。通過研討班的學習,法學院的學生就能熟練地將這些技術應用到具體的實際環境中。比如,下一學期的“人工智能與法律”實踐課程可以作為一種實驗室課程。[166]見上文第四部分。學生可以使用上述工具建立自己的法律專家系統,或者探索如何擴展這些工具以適應法律推理的缺失特征。這些缺失特征包括案例推理和處理不確定性;[167]見前引[11]3和隨附文本(略)。嘗試將預測編碼應用于公開可用的電子發掘數據集;[168]見前引[149]和隨附文本(略)。作為自愿的相關性評估者參與Trec Legal Track,[169]Id.以及根據法律論證的計算模型,參與繪制論證圖和注釋法律文件,以便應用機器學習工具。[170]見前引[163]和隨附文本(略)。隨著“人工智能與法律”研究者開始致力于應對法律規劃建模和創造性解決法律問題的挑戰,一部分學生甚至可能貢獻新的計算模型和新的知識表示方法。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
少先隊活動(2021年2期)2021-03-29 05:40:48
中學生數理化(高中版.高二數學)(2019年6期)2019-06-24 03:37:50
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
Coco薇(2017年11期)2018-01-03 20:59:57
中國公路(2017年7期)2017-07-24 13:56:38
小康(2017年16期)2017-06-07 09:00:59
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
